目前onnx可选的执行引擎非常多,覆盖了从cpu、gpu到npu,从Intel平台到AMD平台等。如下是onnxruntime所有的执行引擎。
['TensorrtExecutionProvider', 'CUDAExecutionProvider', 'MIGraphXExecutionProvider', 'ROCMExecutionProvider', 'OpenVINOExecutionProvider', 'DnnlExecutionProvider', 'TvmExecutionProvider', 'VitisAIExecutionProvider', 'QNNExecutionProvider', 'NnapiExecutionProvider', 'JsExecutionProvider', 'CoreMLExecutionProvider', 'ArmNNExecutionProvider', 'ACLExecutionProvider', 'DmlExecutionProvider', 'RknpuExecutionProvider', 'WebNNExecutionProvider', 'XnnpackExecutionProvider', 'CANNExecutionProvider', 'AzureExecutionProvider', 'CPUExecutionProvider']
我们最熟悉的执行引擎莫过于 CPUExecutionProvider了,所有的计算设备(电脑、计算盒子等)可以没有显卡、NPU等,但一定得有CPU,因此无论你的模型是用Pytorch训练的又或者是Tensorflow、MXNET、PaddlePaddle训练的,也不论你的模型网络结构是怎样的,又或者你的模型是部署在什么样的硬件环境下,我们总可以把pytorch等深度学习框架训练得到的模型转化为ONNX中间态,然后利用ONNX模型进行推理,并把ONNX迁移到任意设备上。要知道就拿Pytorch深度学习框架来说,不是所有的计算设备拥有的硬件环境可以满足安装Pytorch的,在个人笔记本上安装Pytorch或许很简单,但是在手机上或者算力更低的边缘计算设备上是安装不了Pytorch的,但是并不代表在手机上或者边缘计算设备上跑不了Pytorch训练的模型。这种情况下,ONNX就发挥了巨大作用。
但是总是用CPU推理ONNX模型往往速度不佳,难易达到低延迟、高吞吐。如果计算设备上有额外计算硬件加持并且ONNX支持该硬件那就更好了。
OK,言归正传,今天来聊一聊,在onnxruntime python api的情况下,如何正确配置好环境,让ONNX模型在拥有英伟达显卡的计算设备上进行深度加速。
在N卡上进行加速,首先,需要的硬件环境就是电脑上得有英伟达显卡,其实电脑上安装好了英伟达显卡驱动,没有安装好驱动的小伙伴可以查看这篇文章。之后就是安装CUDA工具包了,最后是下载onnxruntime-gpu依赖。
要理解用英伟达显卡加速ONNX模型,不是用onnxruntime而是onnxruntime-gpu,onnxruntime是CPU执行引擎,它没有CUDA、Tensorrt执行引擎,即使你手动指定了CUDA、Tensorrt执行引擎也没有用的。要下载onnxruntime-gpu并且手动指定执行引擎为TensorrtExecutionProvider'或者'CUDAExecutionProvider',你不指定,那么即使你下载了onnxruntime-gpu,也配置好了对应版本的CUDA,那么此时还是CPU推理,因为不论是onnxruntime还是onnxruntime-gpu,不指定执行引擎,都默认采用CPU执行引擎。其次,这两个包不能共存,下载onnxruntime-gpu之前要删除干净onnxruntime。onnxruntime的python 导包方式是
import onnxruntime
onnxruntime-gpu的python 导包方式也是
import onnxruntime
因此如果两个包共存,有时候导入的是onnxruntime,而有时候导入的是onnxruntime-gpu,会产生非常奇怪的bug 。
这里最容易犯错的地方就是安装CUDA。
经常会有小伙伴遇到:本地电脑下载安装、配置好了CUDA,也删除了onnxruntime,重新下载了onnxruntime-gpu,项目代码中的onnxruntime执行引擎也手动指定了'TensorrtExecutionProvider'或者 'CUDAExecutionProvider',为什么就是不走GPU推理,反而还是CPU?又或者遇到了:ONNX GPU推理反而比CPU还要慢的情况。这里就属于典型的CUDA版本跟onnxruntime-gpu版本不匹配。
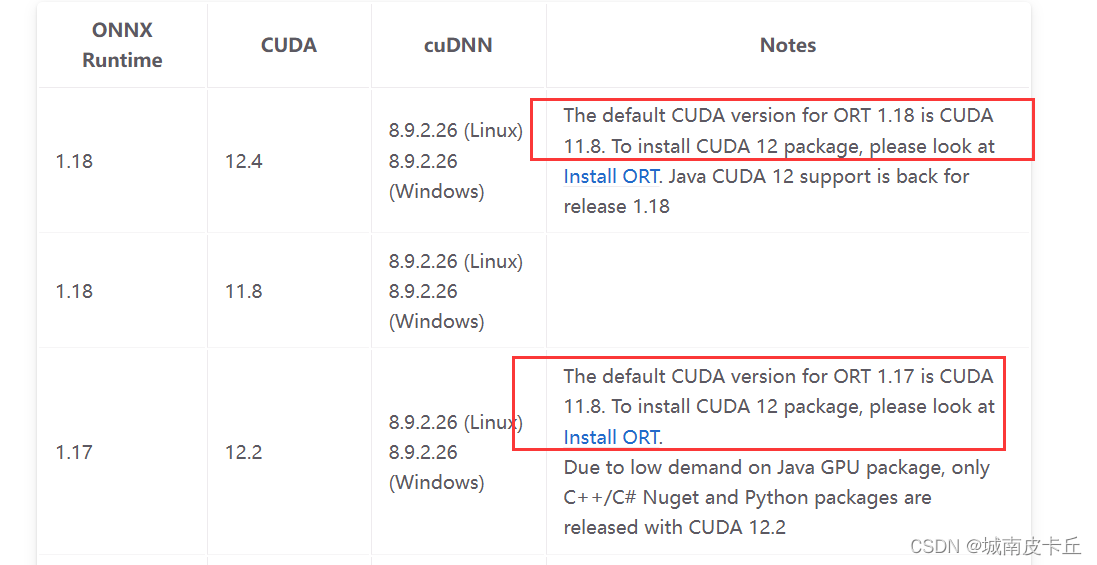
以CUDACUDAExecutionProvider为例,官方明确指出了在推理的时候,onnxruntime-gpu的版本要跟CUDA、CuDnn版本匹配
NVIDIA - CUDA | onnxruntime

但是,就拿本人的多次onnx项目部署实践经历来说,有时候这些版本并不是严格完全对应的,上面的表格版本对应关系也是官方自己测试的,应该并不是面面俱到。例如官方测试的onnxruntime-gpu版本1.15 1.16 1.17可以对应CUDA11.6 CUDA 11.7 CUDA11.8; CuDnn版本8.2.4到8.9.0

但是我测试过onnxruntime-gpu 1.16指定CUDAExecutionProvider引擎在不安装Cudnn,CUDA为11.4 11.7 11.8 12.4都可以进行加速 。但是我也有不少翻车的经历,有时候没注意CUDA跟onnxruntime-gpu的版本对应关系,ONNX项目不走GPU推理;项目走GPU推理反而比CPU还慢;项目走了GPU推理但是时快时慢,慢的时候比CPU还慢。这些情况我都遇到过,但是把版本对应起来之后,总能解决上面的问题。因此上面的版本对应关系还是非常具有参考意义的。
同时还要注意我们直接通过pip安装的onnxruntime-gpu都是官方实现帮我们编译好的,比如截止到2024.6.28,官方提供的onnxruntime-gpu 1.18 和 1.17都是在CUDA11.8环境下通过源码编译得到wheel包的,官方提示:CUDA11.8编译得到的onnxruntime在推理时可以兼容CUDA11.x,但是不能兼容CUDA12.x。但是本人通过pip安装的onnxruntime-1.16(虽然不知道是哪个版本CUDA编译而来的)在CUDA 11.4 11.7 11.8 12.4都可以进行加速

但是最正确的方式还是通过onnxruntime-gpu源码在本地用自己的CUDA编译出onnxruntime-gpu,但是编译过程繁琐而且不保证成功,我们大多数都是直接pip安装onnxruntime-gpu的wheel,但是此时务必注意版本对应关系。
那么问题来了,假如我的电脑全局安装了CUDA11.3,但是用CUDA11.3不能对onnx进行CUDA加速,需要重新安装CUDA吗?其实完全没有必要,我们完全可以利用anaconda在虚拟环境中安装指定版本的CUDA以适配onnxruntime-gpu,即本地环境多版本CUDA共存,可以参考本人的这篇文章
同理,执行引擎为 TensorrtExecutionProvider,onnxruntime也需要跟CUDA、Tensorrt版本匹配。NVIDIA - TensorRT | onnxruntime
指定引擎为TensorrtExecutionProvider需要在本地事先安装好Tensorrt,据我观察在推理的时候,是现场将onnx转Tensorrt的,但是模型不保存本地而是保存在内存中了,程序启动开始转换,程序结束Tensorrt模型销毁,并且这个转化的过程还很长,几十秒到几分钟不等,所以这就造成了一个问题,假如我写了一个脚本让模型推理一张图片,每次推理都需要重新执行这个脚本,那么模型转化的过程就包含在内了,此时表面上看时间很长,但实际上时间都花在了转化模型上。但是如果将这个模型发布为flask服务,在启动服务之前将onnx推理代码所在的类提前初始化,等个几分钟,模型先转化过去,服务在启动,模型推理速度就正常了。