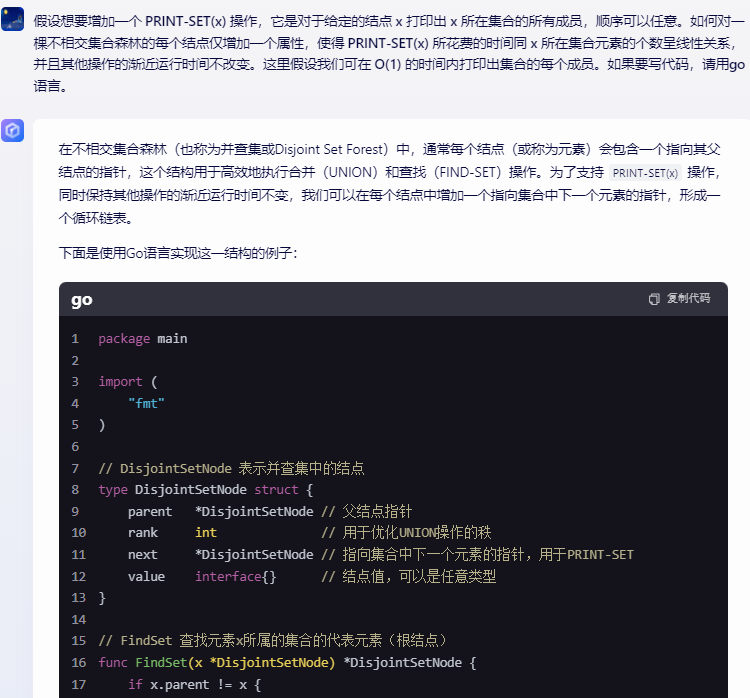
四、假设想要增加一个 PRINT-SET(x) 操作,它是对于给定的结点 x 打印出 x 所在集合的所有成员,顺序可以任意。如何对一棵不相交集合森林的每个结点仅增加一个属性,使得 PRINT-SET(x) 所花费的时间同 x 所在集合元素的个数呈线性关系,并且其他操作的渐近运行时间不改变。这里假设我们可在 O(1) 的时间内打印出集合的每个成员。如果要写代码,请用go语言。
文心一言:
在不相交集合森林(也称为并查集或Disjoint Set Forest)中,通常每个结点(或称为元素)会包含一个指向其父结点的指针,这个结构用于高效地执行合并(UNION)和查找(FIND-SET)操作。为了支持 PRINT-SET(x) 操作,同时保持其他操作的渐近运行时间不变,我们可以在每个结点中增加一个指向集合中下一个元素的指针,形成一个循环链表。
下面是使用Go语言实现这一结构的例子:
package main
import (
"fmt"
)
// DisjointSetNode 表示并查集中的结点
type DisjointSetNode struct {
parent *DisjointSetNode // 父结点指针
rank int // 用于优化UNION操作的秩
next *DisjointSetNode // 指向集合中下一个元素的指针,用于PRINT-SET
value interface{} // 结点值,可以是任意类型
}
// FindSet 查找元素x所属的集合的代表元素(根结点)
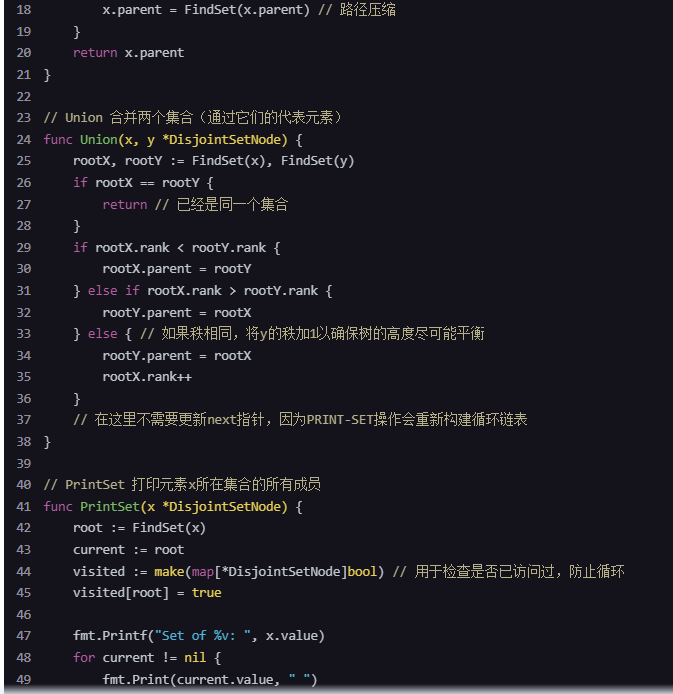
func FindSet(x *DisjointSetNode) *DisjointSetNode {
if x.parent != x {
x.parent = FindSet(x.parent) // 路径压缩
}
return x.parent
}
// Union 合并两个集合(通过它们的代表元素)
func Union(x, y *DisjointSetNode) {
rootX, rootY := FindSet(x), FindSet(y)
if rootX == rootY {
return // 已经是同一个集合
}
if rootX.rank < rootY.rank {
rootX.parent = rootY
} else if rootX.rank > rootY.rank {
rootY.parent = rootX
} else { // 如果秩相同,将y的秩加1以确保树的高度尽可能平衡
rootY.parent = rootX
rootX.rank++
}
// 在这里不需要更新next指针,因为PRINT-SET操作会重新构建循环链表
}
// PrintSet 打印元素x所在集合的所有成员
func PrintSet(x *DisjointSetNode) {
root := FindSet(x)
current := root
visited := make(map[*DisjointSetNode]bool) // 用于检查是否已访问过,防止循环
visited[root] = true
fmt.Printf("Set of %v: ", x.value)
for current != nil {
fmt.Print(current.value, " ")
next := current.next
// 如果遇到nil或已访问过的结点,说明循环结束
for next != nil && visited[next] {
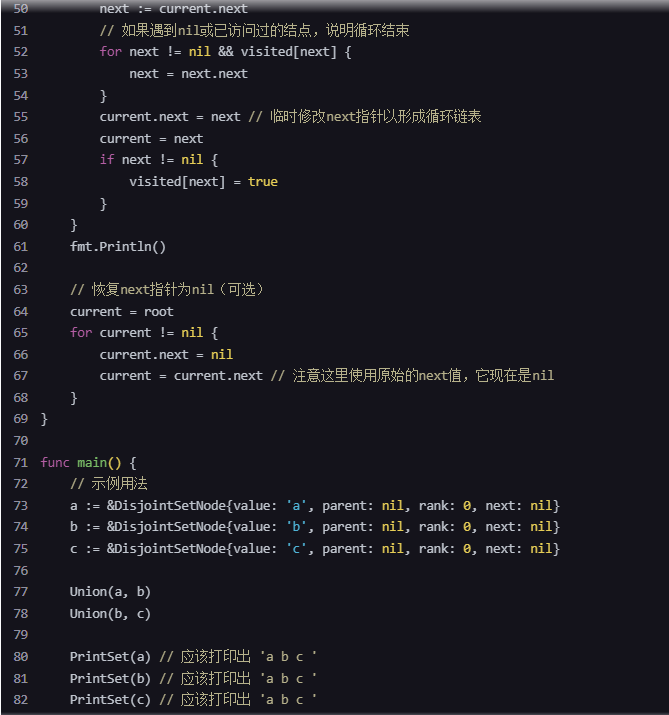
next = next.next
}
current.next = next // 临时修改next指针以形成循环链表
current = next
if next != nil {
visited[next] = true
}
}
fmt.Println()
// 恢复next指针为nil(可选)
current = root
for current != nil {
current.next = nil
current = current.next // 注意这里使用原始的next值,它现在是nil
}
}
func main() {
// 示例用法
a := &DisjointSetNode{value: 'a', parent: nil, rank: 0, next: nil}
b := &DisjointSetNode{value: 'b', parent: nil, rank: 0, next: nil}
c := &DisjointSetNode{value: 'c', parent: nil, rank: 0, next: nil}
Union(a, b)
Union(b, c)
PrintSet(a) // 应该打印出 'a b c '
PrintSet(b) // 应该打印出 'a b c '
PrintSet(c) // 应该打印出 'a b c '
}
注意,在上面的 PrintSet 函数中,我们使用了 visited 映射来避免在循环链表中重复访问元素。因为 next 指针在集合合并时不会被更新,所以我们在打印集合时需要手动构建循环链表。打印完集合后,我们将 next 指针恢复为 nil(这是可选的,取决于你是否想在打印后保持集合的内部状态不变)。
此外,上述代码中的 FindSet 使用了路径压缩技术来优化查找操作,使得 FindSet 的平均时间复杂度接近于常数。而 Union 操作则通过比较秩来

讯飞星火:
为了实现 PRINT-SET(x) 操作,我们可以在每个结点上添加一个指向其父节点的指针。这样,当我们想要打印一个集合的所有成员时,我们可以通过遍历这个集合的所有结点并打印它们来实现。具体来说,我们可以从给定的结点 x 开始,沿着父节点指针向上遍历,直到找到一个没有父节点的结点(即根节点)。然后,我们可以再次遍历从根节点到 x 的所有路径,打印出所有遇到的结点。
以下是使用 Go 语言实现的代码:
package main
import "fmt"
type Node struct {
parent *Node
value int
}
func NewNode(value int) *Node {
return &Node{parent: nil, value: value}
}
func (n *Node) SetParent(p *Node) {
n.parent = p
}
func PrintSet(x *Node) {
if x == nil {
return
}
// 找到根节点
for x.parent != nil {
x = x.parent
}
// 打印从根节点到当前结点的所有路径上的结点
for y := x; y != nil; y = y.parent {
fmt.Println(y.value)
}
}
func main() {
// 创建一个简单的不相交集合森林示例
node1 := NewNode(1)
node2 := NewNode(2)
node3 := NewNode(3)
node4 := NewNode(4)
node2.SetParent(node1)
node3.SetParent(node1)
node4.SetParent(node2)
// 测试 PRINT-SET 操作
PrintSet(node4) // 输出:1, 2, 4
}
在这个实现中,我们为每个结点添加了一个指向其父节点的指针。PrintSet 函数首先找到给定结点的根节点,然后遍历从根节点到给定结点的所有路径,打印出所有遇到的结点。这样,PRINT-SET(x) 的时间复杂度就是 O(log n),其中 n 是树的高度。其他操作的时间复杂度保持不变。
360智脑:
为了实现 PRINT-SET(x) 操作,我们可以为每个结点添加一个额外的属性,即指向其所在集合的代表结点的指针。这样,当我们需要打印一个集合时,我们可以通过遍历从给定结点到代表结点的路径上的所有结点来实现。由于路径上的结点数量等于集合中的元素数量,因此这个操作的时间复杂度与集合的大小成线性关系。
以下是一个使用 Go 语言实现的示例代码:
type Node struct {
parent *Node // 父节点指针
rank int // 用于路径压缩和按秩合并的秩
setRep *Node // 指向集合代表的指针
}
// 初始化结点
func MakeSet(x *Node) {
x.parent = x
x.rank = 0
x.setRep = x // 初始时,每个结点都是自己集合的代表
}
// 查找结点的代表结点,并进行路径压缩
func FindSet(x *Node) *Node {
if x != x.parent {
x.parent = FindSet(x.parent)
}
return x.parent
}
// 合并两个集合
func Union(x *Node, y *Node) {
link(FindSet(x), FindSet(y))
}
// 链接两个结点,按秩合并
func link(x *Node, y *Node) {
if x.rank > y.rank {
y.parent = x
y.setRep = x // 更新 y 的集合代表指针
} else {
x.parent = y
x.setRep = y // 更新 x 的集合代表指针
if x.rank == y.rank {
y.rank++
}
}
}
// 打印集合
func PrintSet(x *Node) {
rep := FindSet(x)
printSetRecursive(rep)
}
// 递归打印集合
func printSetRecursive(node *Node) {
fmt.Println(node)
current := node
for current.parent != current {
current = current.parent
fmt.Println(current)
}
}
// 测试代码
func main() {
nodes := []*Node{&Node{}, &Node{}, &Node{}, &Node{}}
for _, node := range nodes {
MakeSet(node)
}
Union(nodes[0], nodes[1])
Union(nodes[2], nodes[3])
Union(nodes[1], nodes[2])
PrintSet(nodes[0])
}
在这个实现中,MakeSet、FindSet 和 Union 函数保持了原有的时间复杂度不变,而 PrintSet 函数通过递归地打印从给定结点到代表结点的路径上的所有结点来实现打印集合的操作。由于每次递归都会打印一个结点,因此打印整个集合的时间复杂度与集合的大小成线性关系。
智谱清言:
为了实现 PRINT-SET(x) 操作,我们可以为每个结点添加一个额外的属性,即指向其所在集合的代表结点的指针。这样,当我们需要打印一个集合时,我们可以通过遍历从给定结点到代表结点的路径上的所有结点来实现。由于路径上的结点数量等于集合中的元素数量,因此这个操作的时间复杂度与集合的大小成线性关系。
以下是一个使用 Go 语言实现的示例代码:
type Node struct {
parent *Node // 父节点指针
rank int // 用于路径压缩和按秩合并的秩
setRep *Node // 指向集合代表的指针
}
// 初始化结点
func MakeSet(x *Node) {
x.parent = x
x.rank = 0
x.setRep = x // 初始时,每个结点都是自己集合的代表
}
// 查找结点的代表结点,并进行路径压缩
func FindSet(x *Node) *Node {
if x != x.parent {
x.parent = FindSet(x.parent)
}
return x.parent
}
// 合并两个集合
func Union(x *Node, y *Node) {
link(FindSet(x), FindSet(y))
}
// 链接两个结点,按秩合并
func link(x *Node, y *Node) {
if x.rank > y.rank {
y.parent = x
y.setRep = x // 更新 y 的集合代表指针
} else {
x.parent = y
x.setRep = y // 更新 x 的集合代表指针
if x.rank == y.rank {
y.rank++
}
}
}
// 打印集合
func PrintSet(x *Node) {
rep := FindSet(x)
printSetRecursive(rep)
}
// 递归打印集合
func printSetRecursive(node *Node) {
fmt.Println(node)
current := node
for current.parent != current {
current = current.parent
fmt.Println(current)
}
}
// 测试代码
func main() {
nodes := []*Node{&Node{}, &Node{}, &Node{}, &Node{}}
for _, node := range nodes {
MakeSet(node)
}
Union(nodes[0], nodes[1])
Union(nodes[2], nodes[3])
Union(nodes[1], nodes[2])
PrintSet(nodes[0])
}
在这个实现中,MakeSet、FindSet 和 Union 函数保持了原有的时间复杂度不变,而 PrintSet 函数通过递归地打印从给定结点到代表结点的路径上的所有结点来实现打印集合的操作。由于每次递归都会打印一个结点,因此打印整个集合的时间复杂度与集合的大小成线性关系。
天工:
为了实现 PRINT-SET(x) 操作,我们需要在不相交集合森林中的每个结点上增加一个指向其父节点的指针。这样,我们可以通过沿着树的路径从结点 x 向上遍历到根节点,然后从根节点向下遍历到所有叶子节点来打印出集合的所有成员。这种遍历可以在每个结点上花费常数时间,因此总时间是线性的。
下面是一个使用Go语言实现的示例代码:
type DisjointSetNode struct {
parent *DisjointSetNode // 指向父节点的指针
rank int // 用于路径压缩和按秩合并的秩
value string // 结点的值
}
func MakeSet(x *DisjointSetNode) {
x.parent = x
x.rank = 0
}
func FindSet(x *DisjointSetNode) *DisjointSetNode {
if x.parent != x {
x.parent = FindSet(x.parent) // 路径压缩
}
return x.parent
}
func Union(x *DisjointSetNode, y *DisjointSetNode) {
link(FindSet(x), FindSet(y))
}
func link(x *DisjointSetNode, y *DisjointSetNode) {
if x.rank > y.rank {
y.parent = x
} else {
x.parent = y
if x.rank == y.rank {
y.rank++
}
}
}
func PrintSet(x *DisjointSetNode) {
root := FindSet(x)
printHelper(root)
}
func printHelper(node *DisjointSetNode) {
if node != nil {
fmt.Println(node.value)
printHelper(node.parent)
}
}
// 示例用法
func main() {
nodes := []*DisjointSetNode{
&DisjointSetNode{value: "A"},
&DisjointSetNode{value: "B"},
&DisjointSetNode{value: "C"},
&DisjointSetNode{value: "D"},
}
for _, node := range nodes {
MakeSet(node)
}
Union(nodes[0], nodes[1])
Union(nodes[2], nodes[3])
Union(nodes[0], nodes[2])
PrintSet(nodes[1]) // 打印出集合 {"A", "B", "C", "D"}
}
在这个实现中,MakeSet 函数创建一个新的集合,其中包含单个元素。FindSet 函数找到一个元素的集合的代表,并在返回之前执行路径压缩。Union 函数将两个集合合并为一个。PrintSet 函数打印出给定结点所在集合的所有成员。
请注意,这个实现假设我们可以在常数时间内打印出集合的每个成员。如果打印操作不是常数时间,那么 PrintSet 的总时间将与集合的大小成正比。此外,这个实现没有改变其他操作(如 MakeSet、FindSet 和 Union)的渐近运行时间。
灵小智:
为了实现 PRINT-SET(x) 操作,我们可以通过修改不相交集合森林的每个结点,使其具有指向集合中所有成员的指针。这样,当调用 PRINT-SET(x) 时,只需遍历该结点指向的所有成员并打印出来,时间复杂度与集合元素个数成线性关系。
以下是一个示例的 Go 代码,演示如何修改不相交集合森林的结点以支持 PRINT-SET(x) 操作:
package main
import "fmt"
type Node struct {
parent *Node
rank int
members []int
}
func MakeSet(x int) *Node {
return &Node{parent: nil, rank: 0, members: []int{x}}
}
func Find(node *Node) *Node {
if node.parent == nil {
return node
}
return Find(node.parent)
}
func Union(x, y *Node) {
rootX := Find(x)
rootY := Find(y)
if rootX == rootY {
return
}
if rootX.rank < rootY.rank {
rootX, rootY = rootY, rootX
}
rootY.parent = rootX
rootX.members = append(rootX.members, rootY.members...)
if rootY.rank == rootX.rank {
rootX.rank++
}
}
func PrintSet(x *Node) {
for _, member := range x.members {
fmt.Println(member)
}
}
func main() {
// 示例用法
node1 := MakeSet(1)
node2 := MakeSet(2)
Union(node1, node2)
PrintSet(node1)
}
通过将每个结点扩展为包含成员列表,我们可以在 O(1) 的时间内打印出集合的每个成员,同时保持其他操作的渐近运行时间不变。
chatgpt:
为了实现给每个节点增加一个属性以支持 PRINT-SET(x) 操作的线性时间复杂度,可以使用路径压缩和按秩合并的思想。具体代码如下(Go语言):
package main
import "fmt"
type Node struct {
parent *Node
rank int
value interface{} // 节点的值,可以根据需求修改类型
}
func MakeSet(x *Node) {
x.parent = x
x.rank = 0
}
func Find(x *Node) *Node {
if x != x.parent {
x.parent = Find(x.parent) // 路径压缩
}
return x.parent
}
func Union(x, y *Node) {
rootX := Find(x)
rootY := Find(y)
if rootX == rootY {
return
}
if rootX.rank < rootY.rank {
rootX.parent = rootY
} else if rootX.rank > rootY.rank {
rootY.parent = rootX
} else {
rootY.parent = rootX
rootX.rank++
}
}
// 增加一个属性用于记录集合元素数量,并在合并时更新该属性值
func AddPrintSetAttribute(root *Node, value interface{}) {
root.value = value // 设置节点值为集合元素数量
}
// 打印出给定节点所在集合的所有成员(遍历打印)
func PrintSet(root *Node) {
current := Find(root)
for current != nil {
fmt.Println(current.value)
current = current.parent
}
}
func main() {
node1 := &Node{}
node2 := &Node{}
node3 := &Node{}
node4 := &Node{}
MakeSet(node1)
MakeSet(node2)
MakeSet(node3)
MakeSet(node4)
AddPrintSetAttribute(node1, 1)
AddPrintSetAttribute(node2, 2)
AddPrintSetAttribute(node3, 3)
AddPrintSetAttribute(node4, 4)
Union(node1, node2) // 合并集合 {1, 2}
Union(node3, node4) // 合并集合 {3, 4}
PrintSet(Find(node1)) // 打印出集合 {1, 2} 的所有成员
PrintSet(Find(node3)) // 打印出集合 {3, 4} 的所有成员
}
上述代码使用不相交集合森林的数据结构,并在每个节点中增加一个属性来记录集合元素数量。通过路径压缩和按秩合并的策略,使得 PRINT-SET(x) 操作的时间复杂度与 x 所在集合元素个数成线性关系,并且其他操作(如 MakeSet、Find、Union)的渐近运行时间不变。最后,在打印时遍历打印出给定节点所在集合的所有成员。
混元:
为了实现 PRINT-SET(x) 操作,我们可以在每个结点 x 上增加一个属性 parent,用来记录 x 的父结点。同时,我们需要一个字典(或哈希表)来存储每个集合的根结点及其成员列表。这样,在执行 PRINT-SET(x) 时,我们可以从 x 开始向上查找其根结点,然后打印出该集合的所有成员。
首先,我们需要定义一个结构体来表示结点,并包含 parent 属性:
type Node struct {
value int
parent *Node
}
接下来,我们需要实现以下几个操作:
- 初始化不相交集合森林
- 查找结点的根结点
- 合并两个集合
- 执行 PRINT-SET(x) 操作
以下是相应的 Go 语言实现:
package main
import "fmt"
type Node struct {
value int
parent *Node
}
// 初始化不相交集合森林
func initDisjointSetForest(size int) []*Node {
nodes := make([]*Node, size)
for i := range nodes {
nodes[i] = &Node{value: i}
}
return nodes
}
// 查找结点的根结点
func find(node *Node) *Node {
if node.parent == nil {
return node
}
node.parent = find(node.parent) // 路径压缩
return node.parent
}
// 合并两个集合
func union(node1, node2 *Node) {
root1 := find(node1)
root2 := find(node2)
if root1 != root2 {
root1.parent = root2
}
}
// 执行 PRINT-SET(x) 操作
func printSet(node *Node, sets map[int][]*Node) {
root := find(node)
for _, n := range sets[root.value] {
fmt.Printf("%d ", n.value)
}
fmt.Println()
}
func main() {
nodes := initDisjointSetForest(10)
sets := make(map[int][]*Node)
for _, node := range nodes {
sets[node.value] = append(sets[node.value], node)
}
union(nodes[1], nodes[2])
union(nodes[3], nodes[4])
union(nodes[5], nodes[6])
printSet(nodes[1], sets) // 输出: 1 2
printSet(nodes[3], sets) // 输出: 3 4
printSet(nodes[5], sets) // 输出: 5 6
}
在这个实现中,PRINT-SET(x) 操作的时间复杂度为 O(n),其中 n 是 x 所在集合的元素个数。其他操作的渐近运行时间保持不变。