论文标题:
Matching Anything by Segmenting Anything
论文作者:
Siyuan Li, Lei Ke, Martin Danelljan, Luigi Piccinelli, Mattia Segu, Luc Van Gool, Fisher Yu
导读:
在计算机视觉的征途中,多目标跟踪(MOT)扮演着至关重要的角色,尤其是在自动驾驶等前沿技术领域。然而,现有技术大多受限于特定领域的标注视频数据集,这不仅限制了模型的泛化能力,也增加了应用成本。本文介绍的MASA(Matching Anything by Segmenting Anything)方法,以其创新的无监督学习策略,为多目标跟踪领域带来了革命性的突破。©️【深蓝AI】编译
1. 背景简介
多目标跟踪是计算机视觉领域的核心问题之一,对于自动驾驶等众多机器人系统至关重要。在视频序列中,MOT的目标是识别并追踪感兴趣的对象,确保它们在不同帧之间的连续性。尽管最近在视觉基础模型方面取得了显著的进步,这些模型在目标检测、分割和深度估计方面表现出色,但在视频序列中实现目标的准确关联仍然是一个技术挑战。
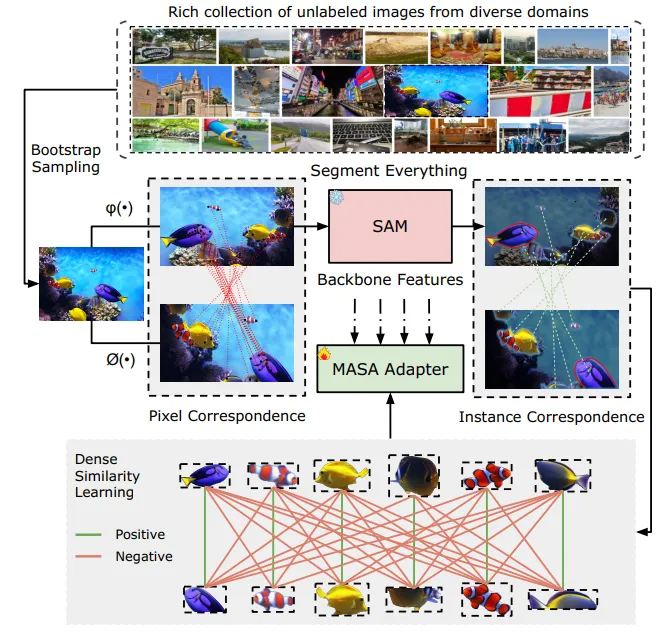
▲图1|给定任意领域的无标注图像,对原始图像和SAM的实例分割结果应用强数据增强,获得两个具有像素级对应关系的视图作为模型输入。然后,利用密集相似度学习,获得实例级对应关系。最后,通过基于SAM的基础分割模型,来实现对任一对象的跟踪能力。©️【深蓝AI】编译
2. 方案提出
最近效果卓越的多目标跟踪方法突出了学习区分性实例嵌入的重要性,这对于确保目标在不同帧中的准确关联至关重要。然而,开发有效的目标关联算法通常依赖于大量的标注数据。虽然在静态图像集上收集目标检测的标签已经是一项艰巨的任务,但在视频数据上获取跟踪标签则更加困难。因此,现有的MOT数据集往往集中在少数固定类别或具有有限标注帧的特定领域对象上。这种数据集的限制性导致了跟踪模型在跨领域和新概念上的泛化能力受限。
另外,尽管近期的研究已经在目标检测和分割的模型泛化方面取得了一定的进展,但开发一个能够泛化到任何目标的通用关联模型仍然是一个未解决的挑战。这需要进一步的研究和创新,以克服现有数据集的局限性,并开发出能够适应多样化场景和目标的跟踪算法。
本文作者的目标是开发一种能够适应任何目标或领域的匹配方法,旨在将这种通用的跟踪技术整合到各种检测和分割算法中。通过这一整合,作者希望提升这些算法跟踪它们所识别目标的能力。
3. 方法详析
■3.1 预备知识:SAM
SAM由三个模块组成:
●图像编码器:一个基于ViT的重型骨干网络,用于特征提取。
●提示编码器:对交云点、框或蒙版提示的位置信息进行建模。
●蒙版解码器:一个基于变换器的解码器,接收提取的图像嵌入和连接的提示标记,用于最终的蒙版预测。
为了生成所有可能的蒙版候选区域,SAM采用密集采样的规则网格作为点锚点,并为每个点提示生成蒙版预测。完整的流程包括使用贪婪的基于框的NMS的块裁剪、三步过滤和蒙版上的重后处理。
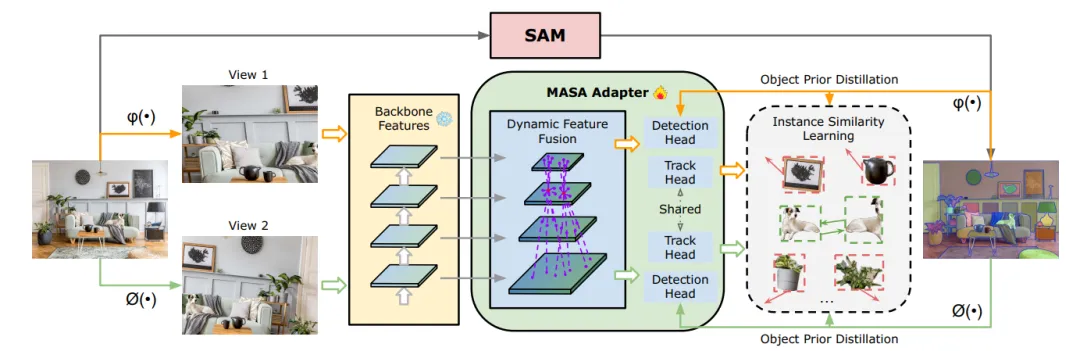
▲图2|MASA训练流程。给定任意领域的无标注图像,SAM自动为其生成实例掩码。然后对原始图像和实例分割结果应用强数据增强变换ϕ(·)和φ(·),获得两个不同视图作为模型输入。通过联合SAM检测知识蒸馏和实例相似度学习来训练MASA Adapter。©️【深蓝AI】编译
■3.2 MASA
◆MASA核心流程
为了学习实例级的对应关系,早前的研究严重依赖于手动标注的域内视频数据。然而,当前的视频数据集只包含有限范围的固定类别。这种数据集的有限多样性导致学习的外观嵌入是为特定领域定制的,在其普遍泛化方面存在挑战。
UniTrack通过对原始图像或视频进行对比自监督学习技术,展示了可以学习通用的外观特征。这些表示利用大量未标注图像的多样性,可以在不同的跟踪领域中泛化。然而,它们通常依赖于干净、以物体为中心的图像,如ImageNet中的图像,或如DAVIS17中的视频,并专注于帧级相似性。这种专注使它们无法充分利用实例信息,导致在包含多个实例的复杂领域中难以学习到区分性的实例表示。
为了解决这些问题,作者提出了MASA训练流程。核心思想是从两个方面增加多样性:训练图像的多样性和实例的多样性。作者首先构建了一个来自不同领域的丰富的原始图像集合,以防止学习到特定领域的特征。这些图像还包含复杂环境中的大量实例,以增强实例多样性。给定图像I,通过对同一图像采用两种不同的增强方法来模拟视频中的外观变化。通过应用强数据增强ϕ(I)和ϕ(I),构建了I的两个不同视图V1和V2,从而自动获得像素级对应关系。
如果图像是干净的且只包含一个实例,如ImageNet中的图像,可以应用帧级相似性。然而,对于包含多个实例的图像,作者需要进一步挖掘这些原始图像中包含的实例信息。基础的分割模型SAM提供了这种能力。SAM自动将属于同一实例的像素分组,还提供了检测到的实例的形状和边界信息,这对于学习区分特征非常有价值。
◆MASA Adapter
MASA Adapter旨在将现有的开放世界分割和检测模型(如SAM、Detic和Grounding-DINO)扩展到对象跟踪任务中。MASA Adapter与这些模型的冻结骨干特征协同工作,确保其原有的检测和分割能力得以保留。但并非所有预训练的特征都适合跟踪,因此研究者首先需要将这些冻结的骨干特征转换为更适合跟踪的新特征。
鉴于物体形状和大小的多样性,作者构建了一个多尺度特征金字塔。对于像Detic和Grounding-DINO这样的层次化骨干(如Swin Transformer),直接使用FPN(特征金字塔网络)。对于使用平原ViT(Vision Transformer)骨干的SAM,通过转置卷积和最大池化对单尺度特征进行上采样和下采样,生成比例为1/4、1/8、1/16、1/32的层次化特征。为了有效学习不同实例的判别特征,需要使一个位置的对象能够感知其他位置实例的外观。因此,使用可变形卷积生成动态偏移,并在空间位置和特征层次上聚合信息。
对于基于SAM的模型,作者还引入了Dyhead模型中的任务感知和尺度感知注意力机制,因为检测性能对于自动生成蒙版非常重要,如图3(b)所示。在获取转换后的特征图后,通过对视觉特征应用RoI-Align(区域兴趣对齐)提取实例级特征,然后通过一个由4个卷积层和1个全连接层组成的轻量级跟踪头部处理,生成实例嵌入。
此外,作者引入了一个目标先验蒸馏分支,作为训练期间的辅助任务。该分支使用标准的RCNN检测头部学习包围每个实例的SAM蒙版预测的边界框。这有效地从SAM中学习了详尽的目标位置和形状知识,并将这些信息蒸馏到转换后的特征表示中。这一设计不仅增强了MASA Adapter的特征,从而提高了关联性能,还通过直接提供预测的框提示加速了SAM的everything模式。
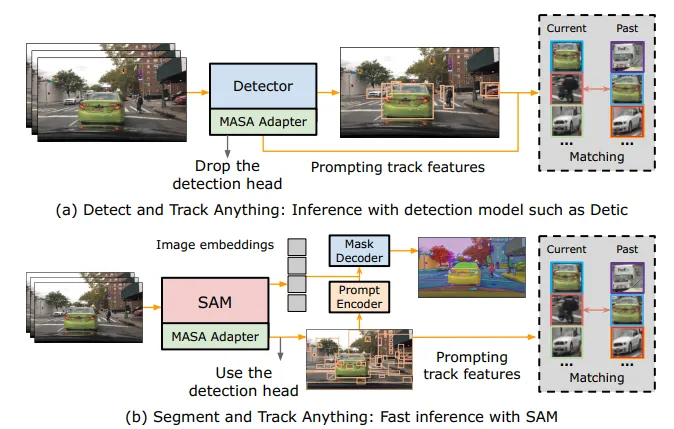
▲图3|统一模型的推理流程©️【深蓝AI】编译
◆推理
作者展示了MASA Adapter的统一模型的测试流程,如图3所示。当将MASA Adapter与目标检测器结合使用时,在训练过程中学习的MASA检测头会被移除。此时,MASA Adapter仅作为一个跟踪器使用。检测器预测边界框,然后利用这些边界框提示MASA Adapter,MASA Adapter检索相应的跟踪特征以进行实例匹配。为了实现精确的实例匹配,本文采用了一种简单的双Softmax最近邻搜索方法。
4. 实验
本文将MASA与现有的监督学习方法进行了对比测试。在多个挑战性基准上,MASA的表现优于或媲美当前最先进的监督学习方法。例如,在TAO Track mAP基准测试中,MASA Adapter的零样本模型性能显著优于许多完全监督学习的模型。在Open-vocabulary MOT基准测试中,MASA Adapter在Base和Novel类别上都显示出更高的跟踪性能。

▲表1|在TAO TETA基准测试上的最新对比结果©️【深蓝AI】编译
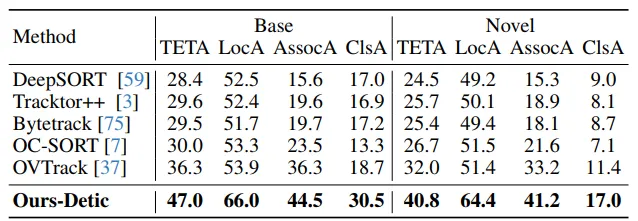
▲表2|在开放词汇多目标跟踪基准测试上的最新对比结果©️【深蓝AI】编译
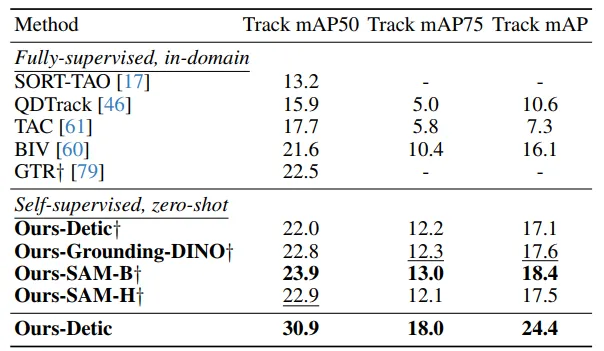
▲表3|在TAO Track mAP基准测试上的最新对比结果©️【深蓝AI】编译
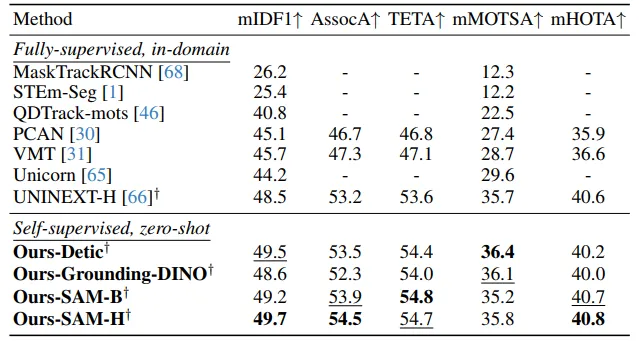
▲表4|在BDD MOTS基准测试(验证集)上的最新对比结果©️【深蓝AI】编译
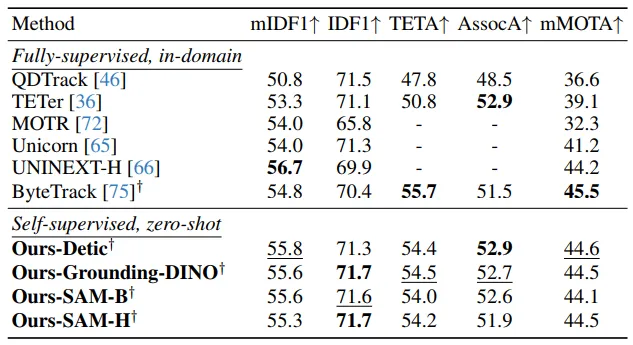
▲表5|在BDD MOT基准测试(验证集)上的最新对比结果©️【深蓝AI】编译
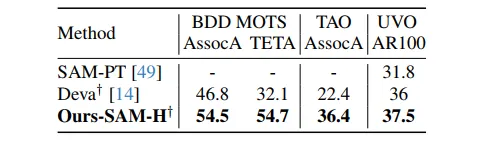
▲表6|与视频物体分割(VOS)方法的比较©️【深蓝AI】编译
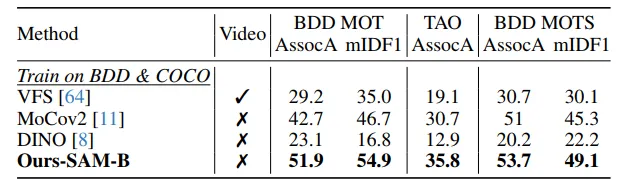
▲表7|与基于自监督学习的方法的比较©️【深蓝AI】编译

▲表8|训练策略和模型架构的影响©️【深蓝AI】编译

▲表9|不同数据增强策略、候选区建议质量和数量的消融研究©️【深蓝AI】编译
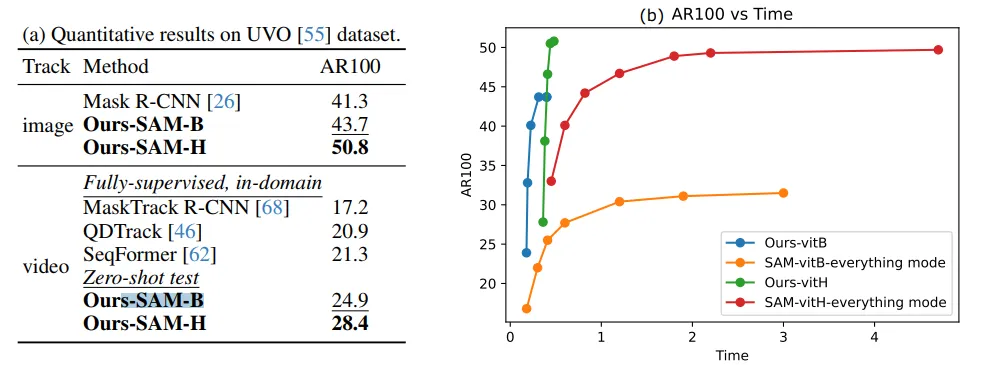
▲图4|(a) 在UVO数据集上的定量结果;(b) 将推理时间(秒)与原始SAM进行比较,通过采样不同数量的提示点©️【深蓝AI】编译

▲图5|统一模型Ours-Grounding-DINO(顶部)和Ours-SAM-H(底部)的定性结果。使用SAM-H基于检测到的边界框生成掩码©️【深蓝AI】编译
5. 结论
MASA的提出不仅在技术上实现了重大突破,还为自动驾驶、视频监控、机器人视觉等领域的应用提供了新的可能性。通过无监督学习方式,MASA从未经标记的图像中提取知识,展现出强大的零样本关联能力,预示着多目标跟踪技术新时代的到来。
编译|Deep 蓝同学
审核|Los
移步公众号【深蓝AI】,第一时间获取自动驾驶、人工智能与机器人行业最新最前沿论文和科技动态。