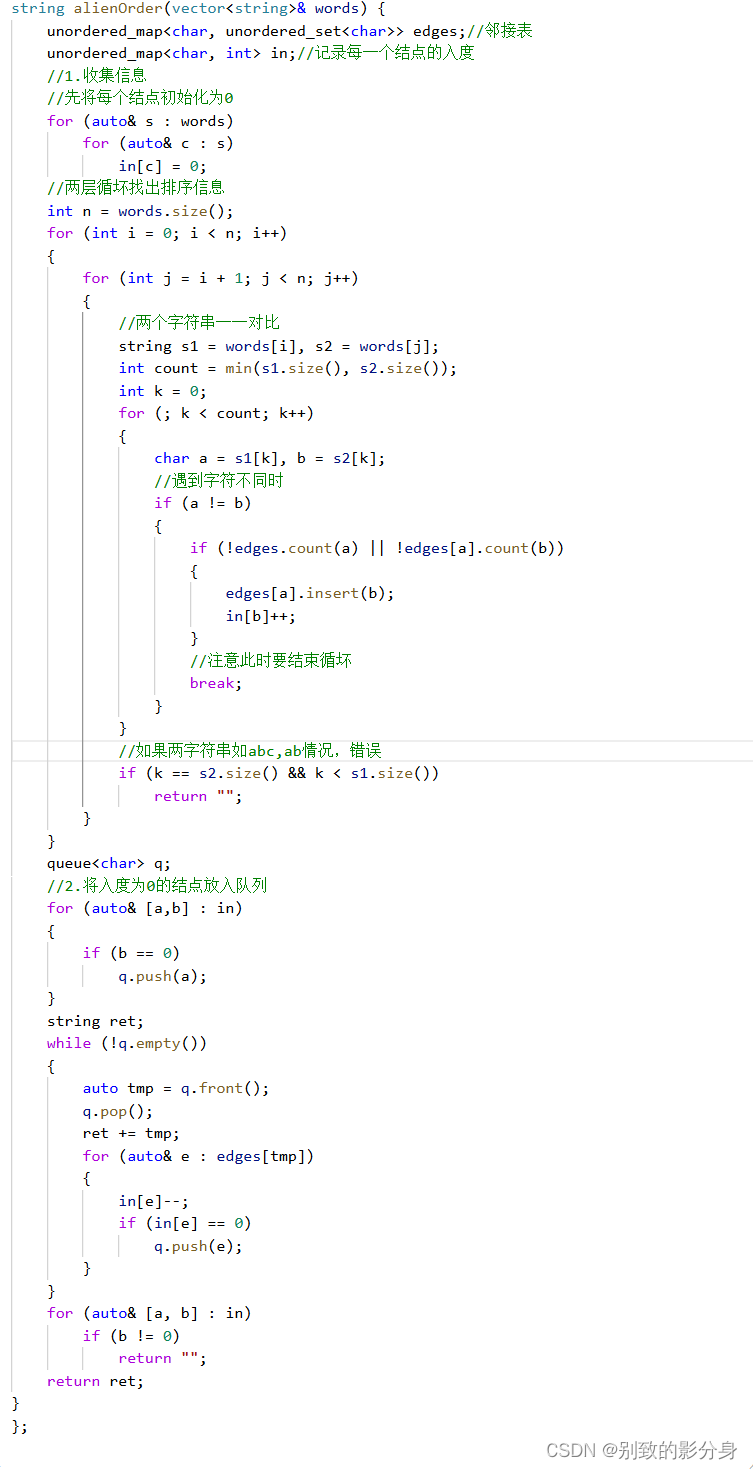
上节我们学了在 Express 里用 multer 包处理 multipart/form-data 类型的请求中的 file。
单个、多个字段的单个、多个 file 都能轻松取出来。
接下来我们就来学习一下在Nest 里使用multer。
一,Nest如何使用multer实现文件上传
首先我们先创建一个Nest项目:
nest new nest-multer-upload -p npm还需要安装下 multer 的 ts 类型的包:
npm install -D @types/multer我们在AppController 添加这样一个 handler:
import { Controller, Get, Post, UseInterceptors,UploadedFile,Body } from '@nestjs/common';
import { AppService } from './app.service';
import { FileInterceptor } from '@nestjs/platform-express';
@Controller()
export class AppController {
constructor(private readonly appService: AppService) {}
@Post('file')
@UseInterceptors(FileInterceptor('file',{
dest:'uploads'
}))
uploadFile(@UploadedFile() file:Express.Multer.File,@Body() body){
console.log('body', body);
console.log('file', file);
}
}使用 FileInterceptor 来提取 file 字段,然后通过 UploadedFile 装饰器把它作为参数传入。
然后 npm run start:dev 把服务跑起来,一保存,就可以看到这个目录被创建了:
然后我们来写前端代码,让 nest 服务支持静态文件的访问,然后让 nest 服务支持跨域,再单独跑个 http-server 来提供静态服务。
在根目录创建 index.html,编写前端代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<script src="https://unpkg.com/axios@0.24.0/dist/axios.min.js"></script>
</head>
<body>
<input id="fileInput" type="file" multiple/>
<script>
const fileInput = document.querySelector('#fileInput');
async function formData() {
const data = new FormData();
data.set('name','张三');
data.set('age', 24);
data.set('file', fileInput.files[0]);
const res = await axios.post('http://localhost:3000/file', data);
console.log(res);
}
fileInput.onchange = formData;
</script>
</body>
</html>先单独跑个 http-server 来提供静态服务:
npx http-server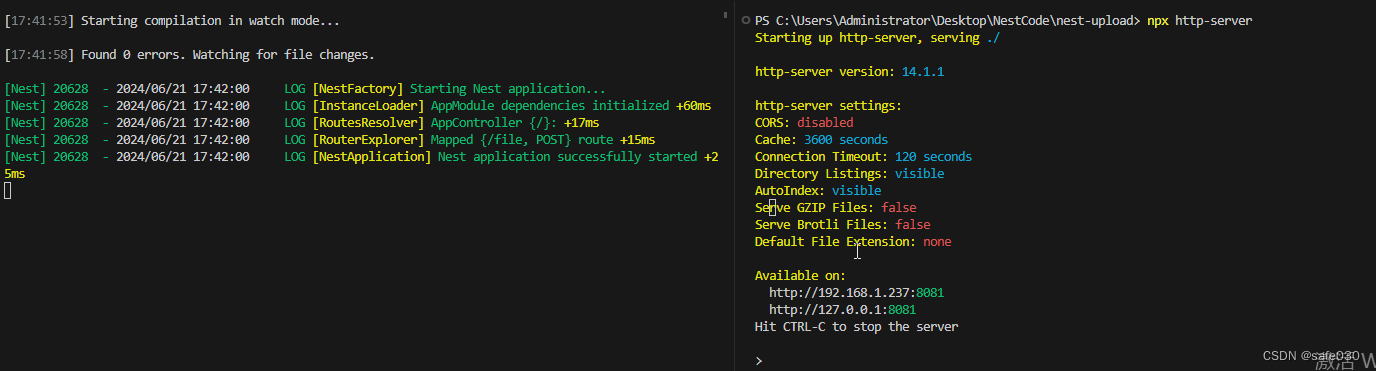
接下来我们在页面选择一个文件上传:
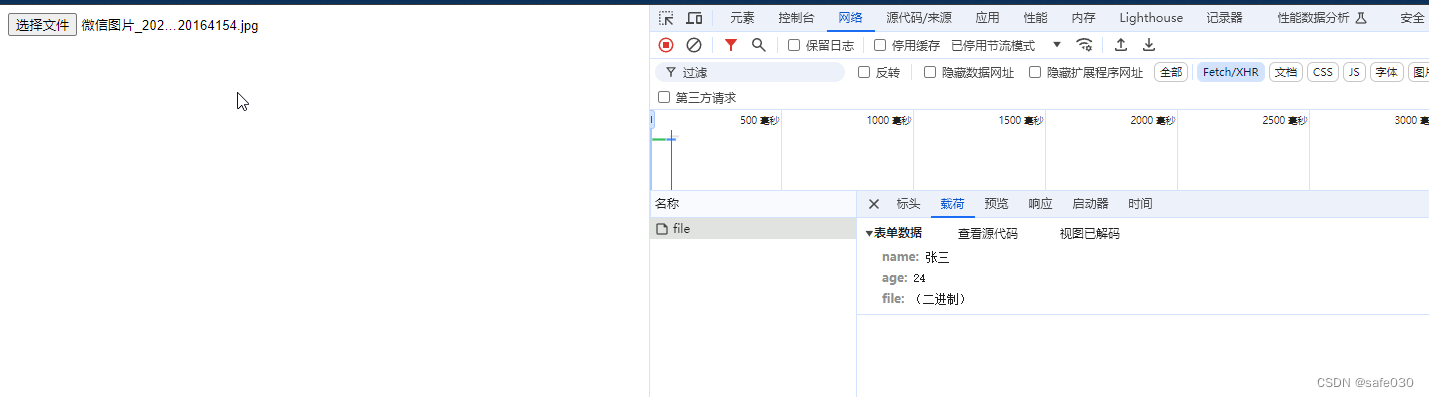
服务端就打印了file对象并存到uploads文件夹:
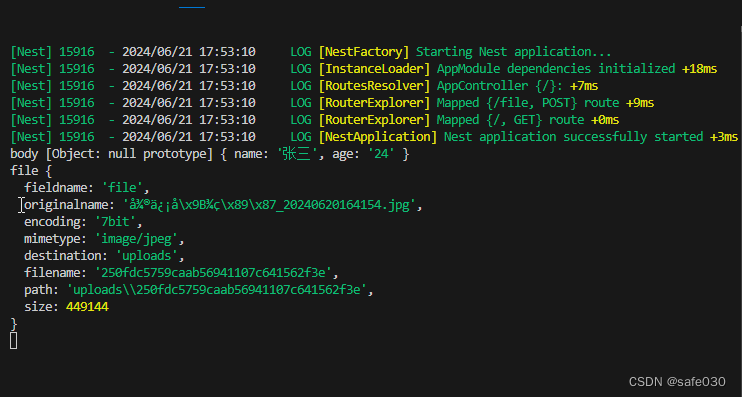
再来试下多文件上传:
// 多文件上传
@Post('files')
@UseInterceptors(FilesInterceptor('files',3,{
dest:'uploads'
}))
uploadFiles(@UploadedFiles() files:Array<Express.Multer.File>,@Body() body) {
console.log('body', body);
console.log('files', files);
}
//把 FileInterceptor 换成 FilesInterceptor,把 UploadedFile 换成 UploadedFiles,都是多加一个 s。前端代码:
<body>
<input id="fileInput" type="file" multiple />
<script>
const fileInput = document.querySelector('#fileInput');
async function formData() {
const data = new FormData();
data.set('name', '张三');
data.set('age', 24);
[...fileInput.files].forEach(item => {
data.append('files', item)
})
const res = await axios.post('http://localhost:3000/files', data, {
headers: { 'content-type': 'multipart/form-data' }
});
console.log(res);
}
fileInput.onchange = formData;
</script>
</body>这样就可以上传多文件了:
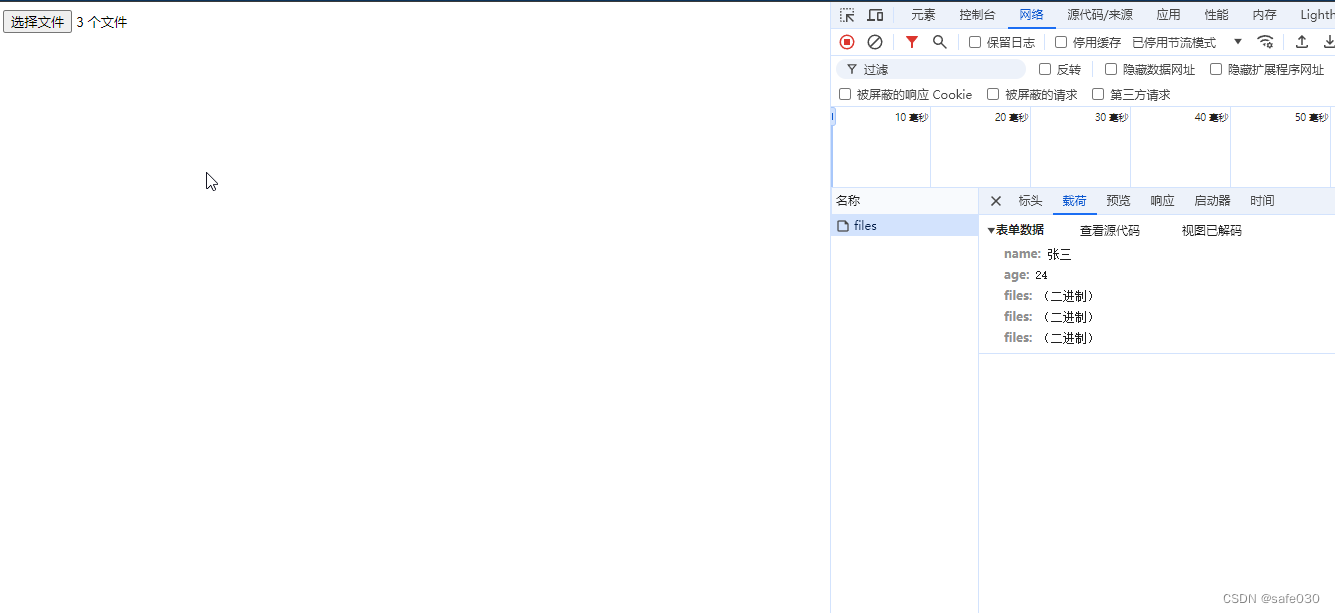
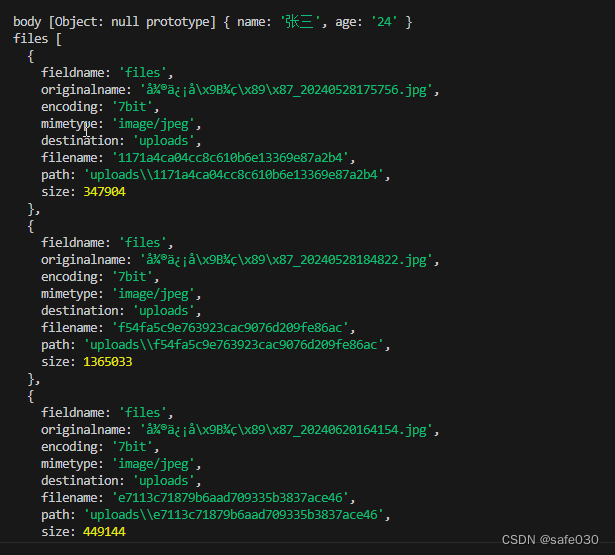
如果有多个文件的字段:
@Post('filesA')
@UseInterceptors(FileFieldsInterceptor([
{ name: 'file1', maxCount: 2 },
{ name: 'file2', maxCount: 3 }
], {
dest: 'uploads'
}))
uploadFileFields(@UploadedFiles() files: { file1?: Express.Multer.File[], file2?: Express.Multer.File[] }, @Body() body) {
console.log('body', body);
console.log('files', files);
}前端代码和之前都差不多,只是字段名和接口不一样,在这里就不一一赘述了
如果并不知道有哪些字段是 file :
@Post('filesB')
@UseInterceptors(AnyFilesInterceptor({
dest: 'uploads'
}))
uploadAnyFiles(@UploadedFiles() files: Array<Express.Multer.File>, @Body() body) {
console.log('body', body);
console.log('files', files);
}文件的校验:
像文件大小、类型的校验这种逻辑太过常见,Nest 给封装好了,可以直接用:
@Post('filesC')
@UseInterceptors(FileInterceptor('file', {
dest: 'uploads'
}))
uploadFile3(@UploadedFile(new ParseFilePipe({
validators: [
new MaxFileSizeValidator({ maxSize: 1000 }),
new FileTypeValidator({ fileType: 'image/jpeg' }),
],
})) file: Express.Multer.File, @Body() body) {
console.log('body', body);
console.log('file', file);
}
//ParseFilePipe:它的作用是调用传入的 validator 来对文件做校验
//比如 MaxFileSizeValidator 是校验文件大小、FileTypeValidator 是校验文件类型我们来试试:
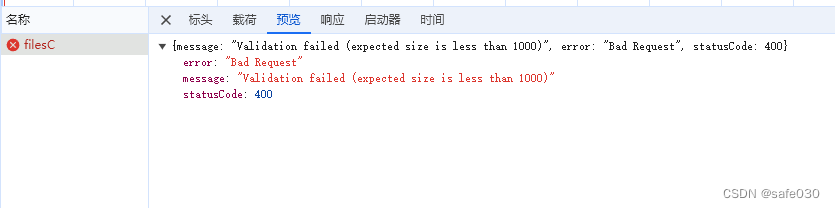
可以看到,返回的也是 400 响应,并且 message 说明了具体的错误信息
而且这个错误信息可以自己修改:
@Post('filesC')
@UseInterceptors(FileInterceptor('file', {
dest: 'uploads'
}))
uploadFile3(@UploadedFile(new ParseFilePipe({
exceptionFactory:err => {
throw new HttpException('错误信息:' + err ,400)
},
validators: [
new MaxFileSizeValidator({ maxSize: 1000 }),
new FileTypeValidator({ fileType: 'image/jpeg' }),
],
})) file: Express.Multer.File, @Body() body) {
console.log('body', body);
console.log('file', file);
}看看效果:
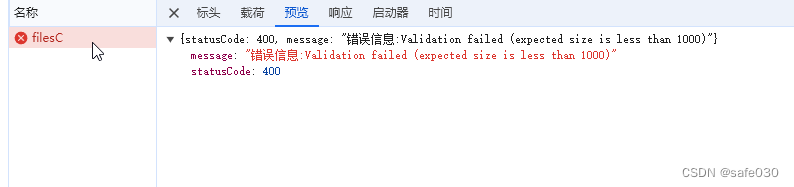
二,大文件分片上传
当文件很大的时候,上传就会变得比较慢。
假设传一个 100M 的文件需要 3 分钟,那传一个 1G 的文件就需要 30 分钟。
这样是能完成功能,但是产品的体验会很不好。
所以大文件上传的场景,需要做专门的优化。
把 1G 的大文件分割成 10 个 100M 的小文件,然后这些文件并行上传,不就快了?
然后等 10 个小文件都传完之后,再发一个请求把这 10 个小文件合并成原来的大文件。
这就是大文件分片上传的方案。
那如何拆分和合并呢?
浏览器里 Blob 有 slice 方法,可以截取某个范围的数据,而 File 就是一种 Blob。
所以可以在 input 里选择了 file 之后,通过 slice 对 File 分片。
那合并呢?
fs 的 createWriteStream 方法支持指定 start,也就是从什么位置开始写入。
这样把每个分片按照不同位置写入文件里,就完成合并了。
创建个 Nest 项目:
nest new large-file-sharding-upload在 AppController 添加一个路由:
@Post('upload')
@UseInterceptors(FilesInterceptor('files',20,{
dest:'uploads'
}))
uploadFiles(@UploadedFiles() files :Array<Express.Multer.File>,@Body() body) {
console.log('body' ,body)
console.log('files',files)
}前端代码我们这样写:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<script src="https://unpkg.com/axios@0.24.0/dist/axios.min.js"></script>
</head>
<body>
<input id="fileInput" type="file"/>
<script>
/*
对拿到的文件进行分片,然后单独上传每个分片,分片名称为文件名+index
*/
const fileInput = document.querySelector('#fileInput');
const chunkSize = 20 * 1024
async function formData() {
const file = fileInput.files[0]
const chunks = []
let startPos = 0
while(startPos < file.size) {
chunks.push(file.slice(startPos, startPos + chunkSize));
startPos += chunkSize;
}
chunks.map((chunk, index) => {
const data = new FormData();
data.set('name', file.name + '-' + index)
data.append('files', chunk);
axios.post('http://localhost:3000/upload', data);
})
console.log(res);
}
fileInput.onchange = formData;
</script>
</body>
</html>接下来我们来测试一下,这里我测试用的图片是 40k:

每 20k 一个分片,一共是 2 个分片,服务端接收到了这 2 个分片:


接下来我们来进行合并操作:
@Post('upload')
@UseInterceptors(FilesInterceptor('files',20,{
dest:'uploads'
}))
uploadFiles(@UploadedFiles() files :Array<Express.Multer.File>,@Body() body) {
console.log('body' ,body)
console.log('files',files)
// 将分片移动到单独的目录
const fileName = body.name.match(/(.+)\-\d+$/)[1];
const chunkDir = 'uploads/chunks_'+ fileName;
if(!fs.existsSync(chunkDir)){
fs.mkdirSync(chunkDir);
}
fs.cpSync(files[0].path, chunkDir + '/' + body.name);
fs.rmSync(files[0].path);
// 然后我们来合并文件
const chunkDirMerge = 'uploads/chunks_'+ fileName;
const filesMerge = fs.readdirSync(chunkDirMerge);
let count = 0;
let startPos = 0;
filesMerge.map(file => {
const filePath = chunkDirMerge + '/' + file;
const stream = fs.createReadStream(filePath);
stream.pipe(fs.createWriteStream('uploads/' + fileName, {
start: startPos
})).on('finish', () => {
count ++;
// 然后我们在合并完成之后把 chunks 目录删掉。
if(count === files.length) {
fs.rm(chunkDir, {
recursive: true
}, () =>{});
}
})
startPos += fs.statSync(filePath).size;
});
}测试一下:
接收到的文件分片:

合并之后:

至此,大文件分片上传就完成了。