基本介绍

1.批处理
正常你要指向三行sql语句
就是
prepareStatement.execute(sql1)-发送-执行
prepareStatement.execute(sql2)-发送-执行
prepareStatement.execute(sql3)-发送-执行
一句一句发送然后指向,这样太麻烦
批处理就把sql1、sql2和sql3整合到一个集合中,直接发送给mysql
发送一遍,直接指向-效率更高
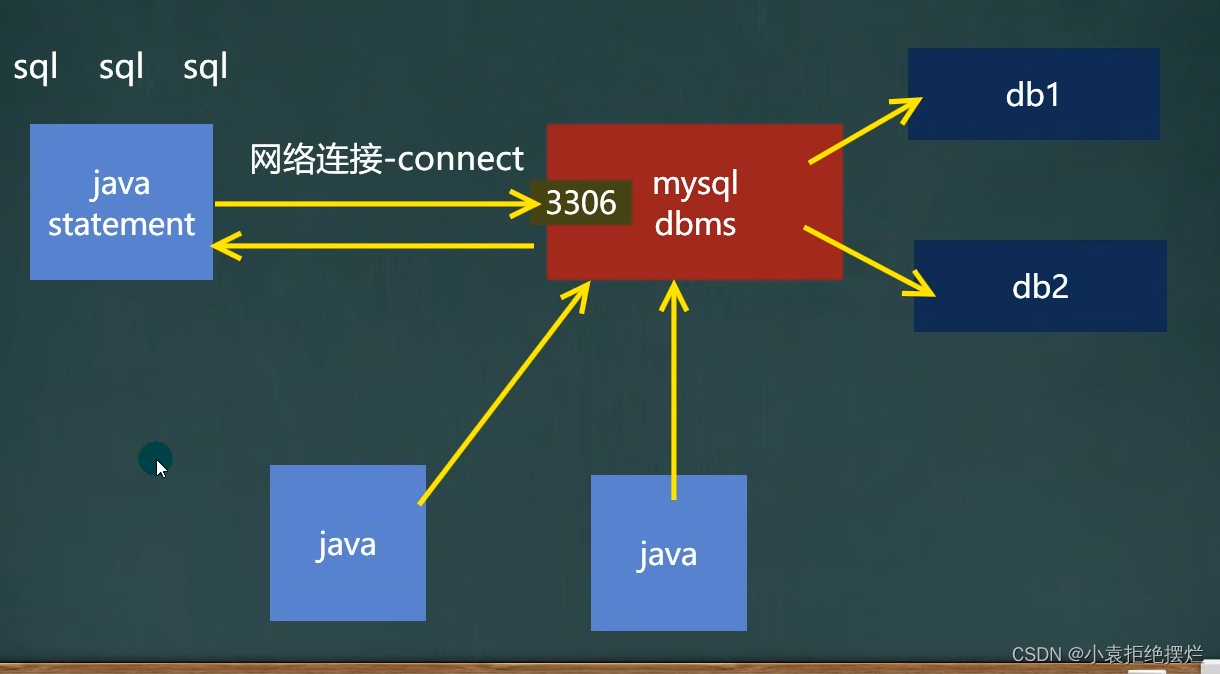
2.三个方法
添加批量sql语句-addBatch(),执行批量添加的sql语句-executeBatch(),清空之前批量添加的sql语句-clearBatch()
和Statement关联(调用)
3.使用批处理
!一定要在url后面加一个参数
?rewriteBatchedStatements=true
4.搭配preparedStatement编译次数少,运行次数也变小,效率提升很大
案例
不用批处理
就直接这样发送-执行-再发送-再执行
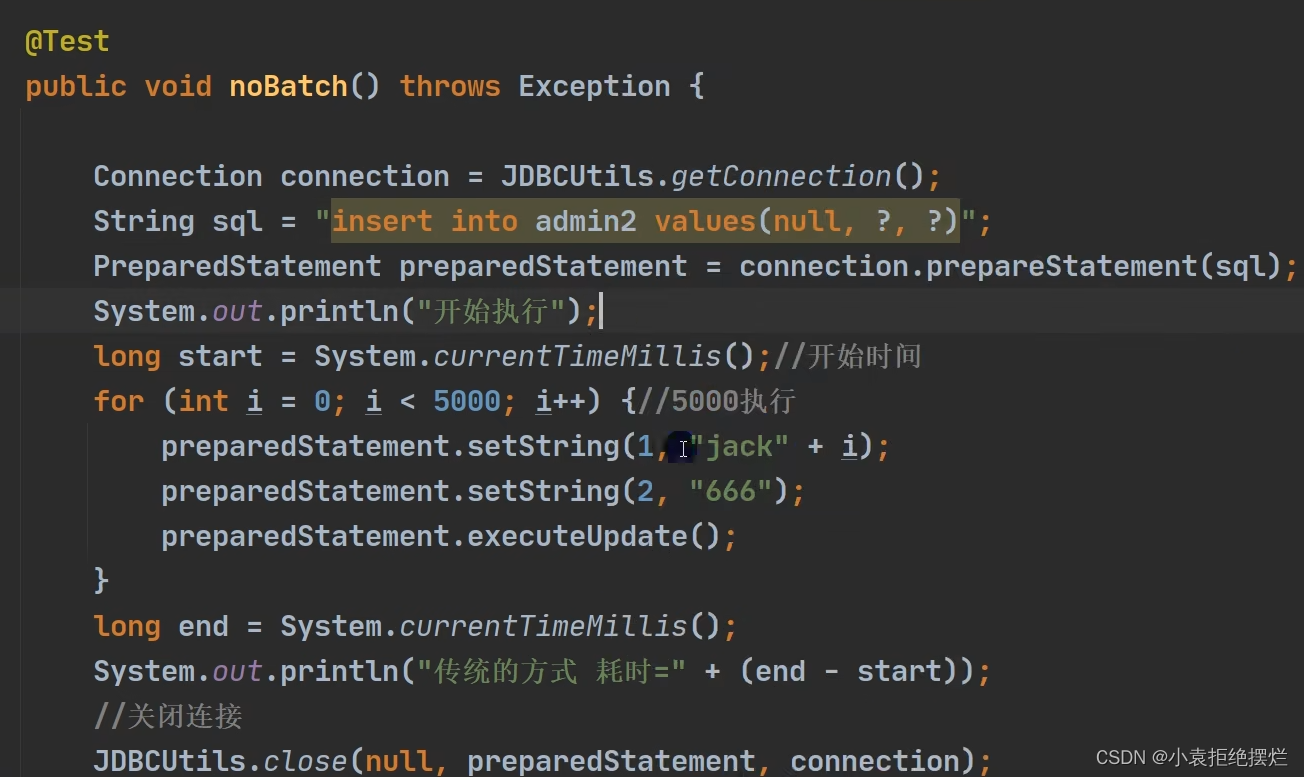
耗时将近10s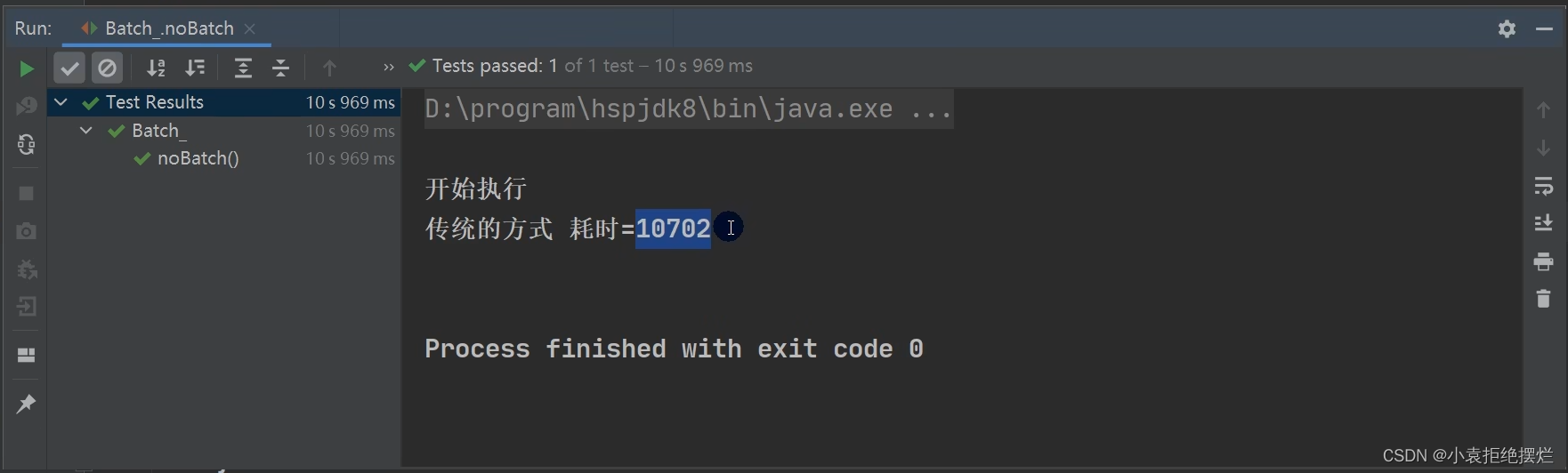
使用批处理
package yuan.hsp.JDBC;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import org.junit.jupiter.api.Test;
public class 批处理 {
@Test
public void m1() throws ClassNotFoundException, SQLException {
Class.forName("com.mysql.jdbc.Driver");
Connection connection = DriverManager
.getConnection("jdbc:mysql://localhost:3306/db02?rewriteBatchedStatements=true","root","123456");
String sql="insert into admin values (?,?)";
PreparedStatement prepareStatement = connection.prepareStatement(sql);
for(int i=0;i<5000;i++) {
prepareStatement.setString(1, "jack"+i);
prepareStatement.setString(2, "666");
//!将语句搞到批量处理包中-》看源码
prepareStatement.addBatch();
//当有1000条记录时候批量执行(这个数据量多时候写,不然那个容器也不是无限的)
if ((i+1)%1000==0) {
prepareStatement.executeBatch();//批量执行
prepareStatement.clearBatch();//清空一下
}
}
prepareStatement.close();
connection.close();
}
}
注意:1.写url记得加参数?rewriteBatchedStatements=true,不然不支持和原来效果差不多
2.可以在达到某一量级集中处理然后清空
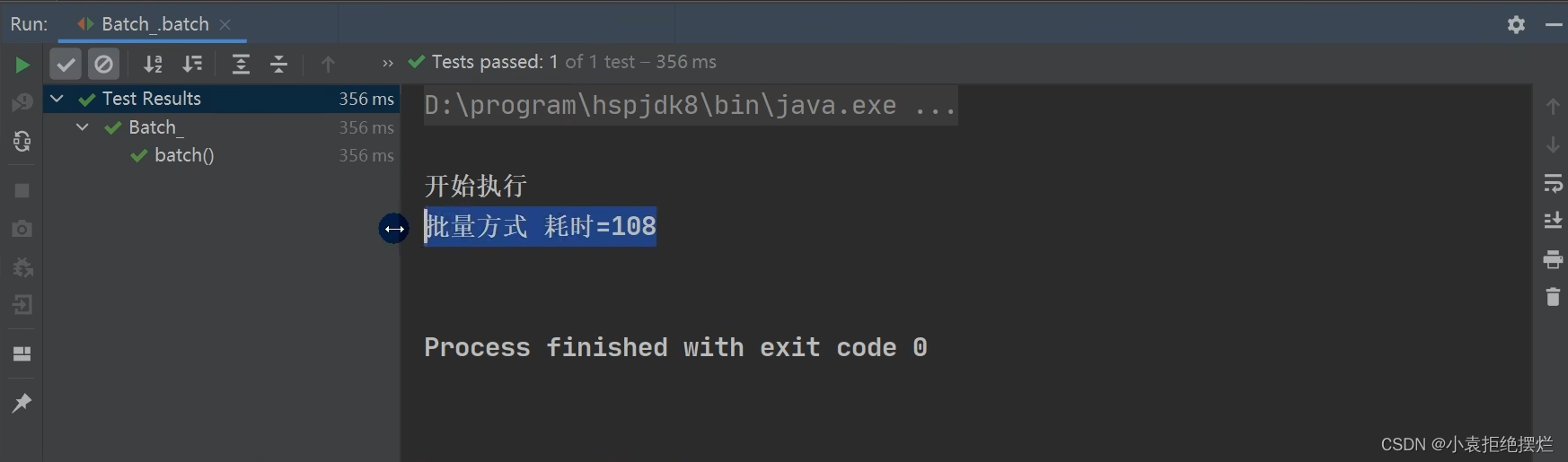
这就是差距喽
源码分析
核心addBatch()
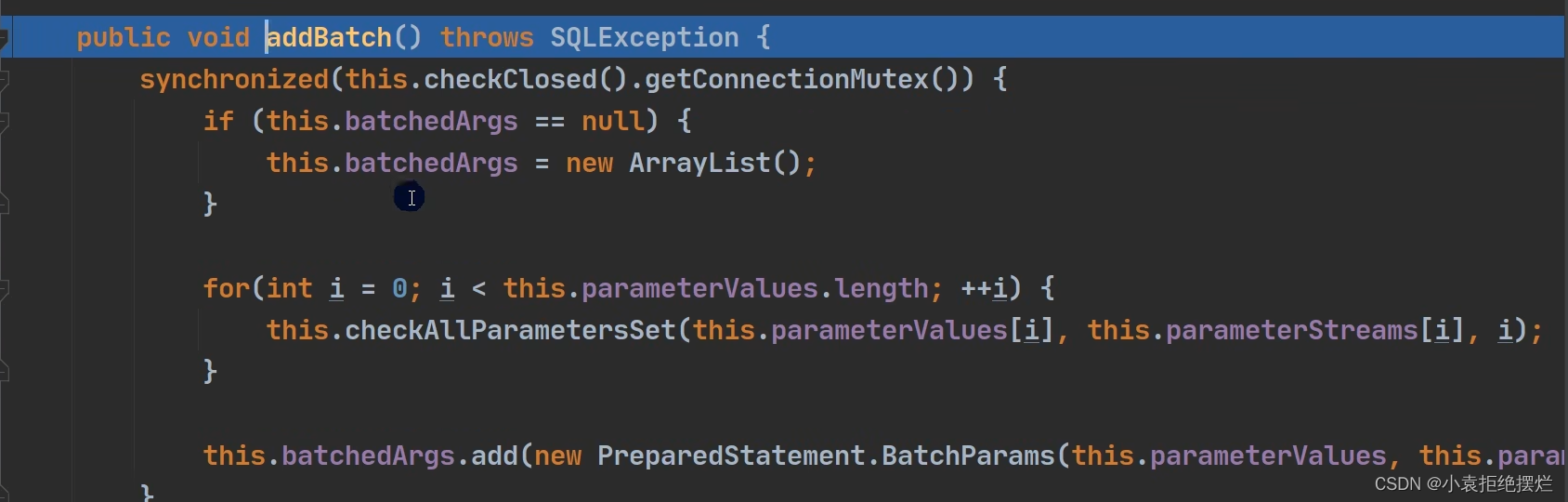
第一句if-如果还没有创建,创建一个ArrayList数组-this.batchedArgs
第二句for后面就是检查我们的?,我们给?赋的值然后重新组成语句
最后一句就是把我们第二步完的语句添加到
this.batchedArgs的elementdate数组中以字节数组保存(elementDate数组的元素是字节数组,存储我们的sql语句)
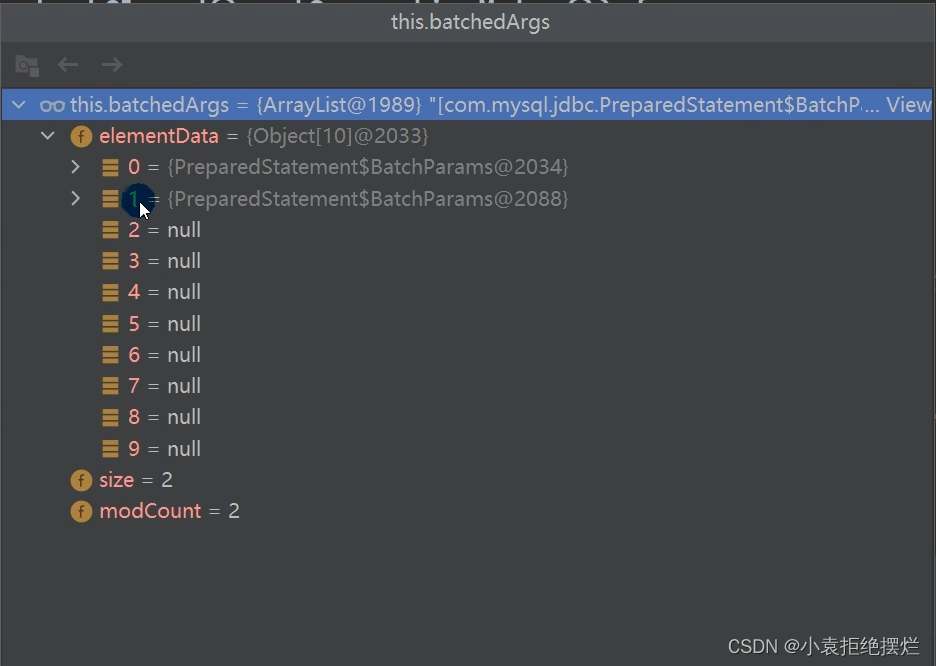
扩容底层按照ArrayList的扩容