Kubernetes实现应用零宕机
- 容器镜像位置
- Pod数量(应用程序实例)
- Pod中断预算
- 部署策略
- 自动回滚部署
- Probe探针
- 初始启动时间延迟
- 优雅终止期GrancePeriodSeconds
- Pod反亲和力
- 资源
- 自动缩放Autoscaling
- 总结
容器已经彻底改变了应用托管格局!它带来了许多需要复杂设置的设施。拥有多个实例,具有滚动重启、零停机、健康检查等功能。以前真是费时费力(实现 VRRP 解决方案、使用 monit 之类的应用程序监控重启、负载均衡 haproxy 之类的)!
因此,现在使用 Kubernetes 可以更轻松地访问一切,但如果您想为应用程序的生命周期构建完美的设置,您仍然必须了解它的工作原理以及根据您的情况应遵循哪种策略。
在本文中,我将解释为什么以及如何使用 Kubernetes 实现零停机应用程序。
容器镜像位置
如果您已经使用Docker一段时间,那么这看起来很简单。拉取和使用容器镜像非常简单。但是,在生产环境中,如果您不是镜像所有者,您通常不想依赖远程且不受控制的镜像注册表。为什么呢?
1.注册表可能会消失,并且无法再拉取镜像(Kubernetes上出现ImagePullBackOff错误);
2.正在使用的镜像标签被删除(相同的ImagePullBackOff错误);
3.镜像标签没有改变,但镜像内容不再相同(非不可变镜像,因此镜像哈希值不同)。集群不同节点上的镜像之间的行为不相同(取决于标签何时更改并在集群节点上拉取);
4.不符合你要求控制这些镜像的安全规范(SOC2、HIPPA…);
Pod数量(应用程序实例)
这听起来很明显,但如果你正在寻求高可用性,则你的应用程序至少需要2个Kubernetes副本(2个Pod)。例子:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 2
template:
......
我多次听到关于Kubernetes的一个常见错误是:“我不需要两个实例,因为Kubernetes执行滚动更新,因此它将在关闭当前实例之前启动一个新实例”。确实如此,但它仅适用于部署更新!
以下是不适用此规则的其它场景:
- 当丢失运行应用程序的节点时(节点崩溃、硬件故障…)。应用程序pod必须从头开始:
- 1.镜像拉取(如果节点上尚未存在):拉取时间取决于镜像大小
- 2.磁盘附件(如果有):需要几秒钟(通常观察到最多1分钟)
- 3.应用程序启动:可能会有所不同,具体取决于受影响的资源和应用程序类型(Java应用程序通常需要更长的时间才能启动)
- 4.probes:它们正在等待你的应用程序准备就绪提供服务,并增加了几秒钟的时间
- 当集群请求节点耗尽时(例如在K8S升级或节点类型更改期间)
- 要替换的节点上的 Pod 会收到SIGTERM信号以正常停止。Pod 正在从RUNNING状态切换到TERMINATING状态。此处,Kubernetes 服务已更新,以停止向TERMINATING pod 发送流量。因此,您不会再收到流量并且会出现停机时间。然后创建一个新的 Pod(请参阅上面的场景),在此期间,您不会收到任何流量。不幸的是,Kubernetes 在杀死一个 pod 之前不会启动一个新的 pod。
这就是为什么设置两个实例是避免停机的最低要求。
Pod中断预算
PodDisruptionBudget(PDB)是一个Kubernetes对象,它指定在部署、维护或任何给定时间不可用的Pod数量。这有助于确保你的应用程序保持可用,即使某些pod被终止或驱逐也是如此。让我们举一个例子,我的应用程序有三个pod(实例),我总是希望始终拥有至少两个running,我可以应用一个PDB对象,这将保证我始终至少两个正在运行的pod。
apiVersion: policy/v1betal
kind: PodDisruptionBudget
metadata:
name: my-pdb
namespace: sit
spec:
maxUnavailable: 1
selector:
matchLabels:
app: my-app
部署策略
Kubernetes部署有两种策略:
1.RollingUpdate:默认更新,部署顺利。重新创建:在启动较新版本的应用程序之后强制旧版本应用程序逐步关闭。
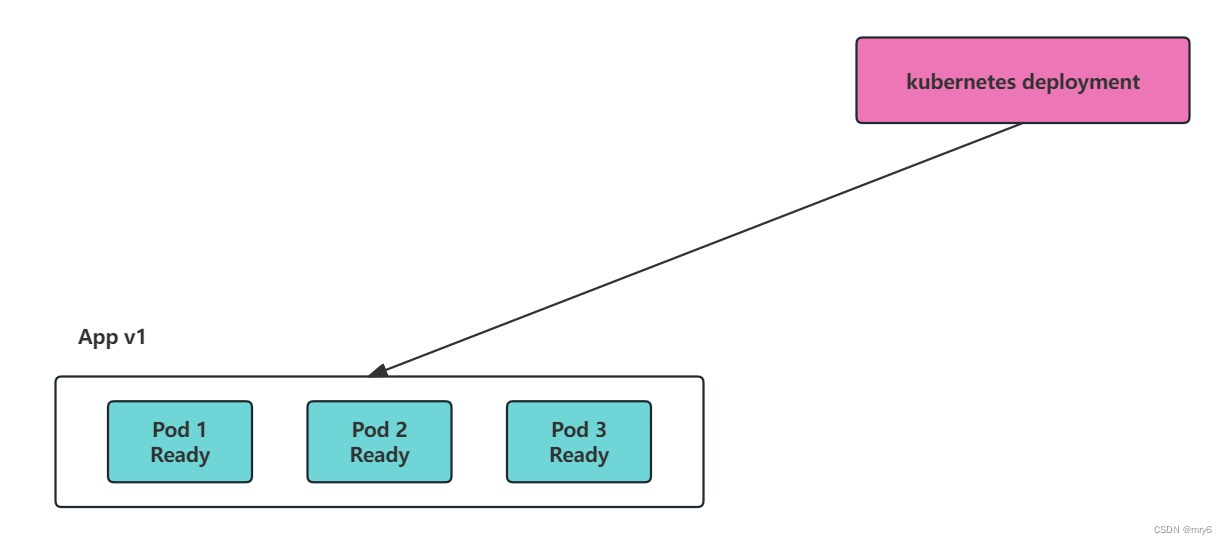
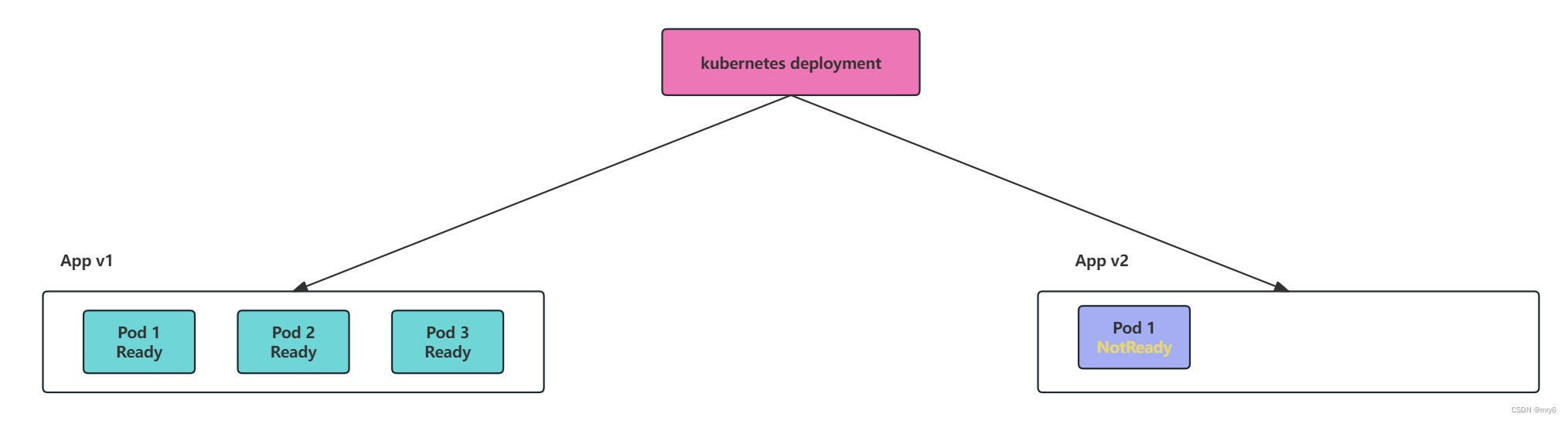


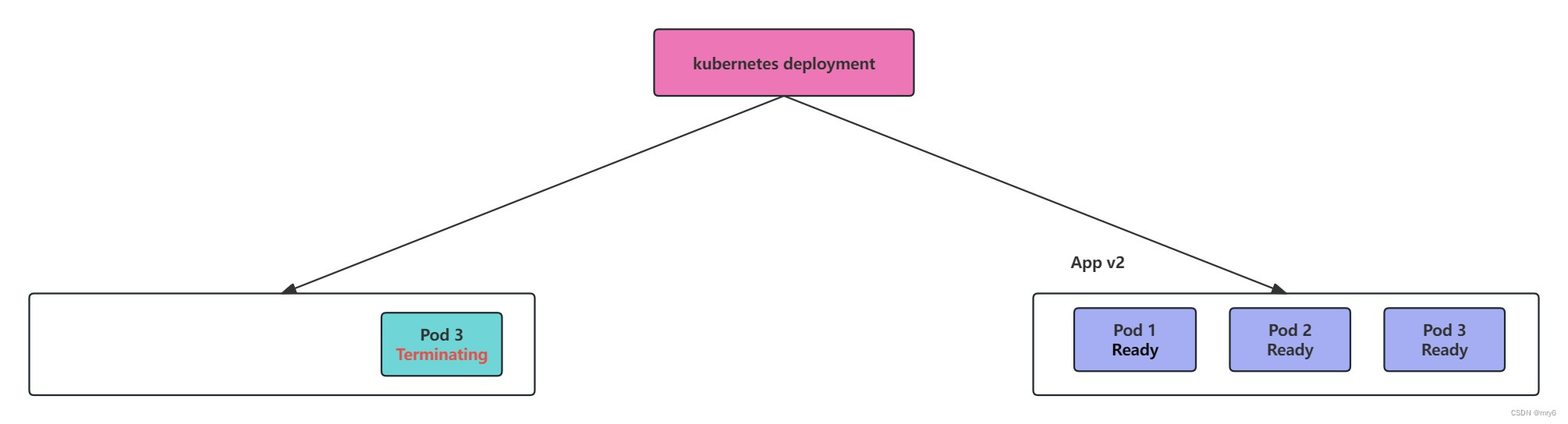
默认情况下,应用RollingUpdate策略,但是你可以使用其它选项(例如最大不可用百分比和最大激增)来调整部署的方式。当你面临繁重的流量负载并且想要控制部署速度以最大程度地减少性能影响时,这些选项非常有用。
自动回滚部署
不幸的是,自动回滚并不是Kubernetes默认的功能。一般来说,你必须使用 Helm、ArgoCD、Spinnaker等第三方工具才能实现自动回滚。
大多数人想要的很简单:如果我的应用程序无法正常启动,不要向其发送流量并回滚。
例如,对于Helm,使用Helm实现它的一些选项很有趣:
- wait
- wait-for-jobs
- atomic
为了获得运行良好的解决方案,必须设置并正确配置探针(请参阅下一节)。如果pod没有通过其活性探针正常启动,则会自动回滚。
Probe探针
探针经常被低估,但是它对于实现零停机非常重要!
验证应用程序健康状况的两个最重要的探测器是"Liveness" 和 "Readiness"探测器。
Kubernetes探针工作流程
Liveness探针可确保你的应用程序处于活动状态,并将决定pod是否存活!
如果活性探测未成功:
1.Pod停止接收流量
2.Pod重新启动,尝试恢复健康状态。任何进一步的重新启动都会应用指数退避(指数延迟)
Readiness探针决定是否将流量发送到你的Pod。
- 如果你的流量出现突发(并且活性探针正在响应),但你的应用程序开始变慢,则就绪状态可以决定停止向你的应用程序发送流量。让它恢复到更加健康的状态。
- 如果就绪探针没有响应,则不会重新启动你的Pod。它仅请求负载均衡器停止向该Pod发送流量。
初始启动时间延迟
初始启动时间可能需要延迟.它可能发生在不同的情况下:
- 你的应用程序使用大量CPU来启动(例如SpringBoot应用程序)。
- 你的应用程序需要在启动时执行更多操作(新增功能),并且你没有升级分配的CPU资源。
- 你的应用程序必须加载数据库中的架构和其中的数据,并且在数据库准备就绪之前它才可用。
这是可能发生片状启动的示例,如果你遇到这种情况或想预防它,你应该像下面这样更新initialDelaySeconds:
livenessProbe:
initialDelaySeconds: 60
httpGet:
...
注意:存在专用启动探测器,一般来说,initialDelaySeconds选项就足够了.
优雅终止期GrancePeriodSeconds
这个Kubernetes选项并不直接与零停机功能相关,而是更多地涉及忽略应用程序正常关闭的重要性的缺点效应。
仅当应用程序能够拦截 SIGTERM时,优雅终止期才能起作用!如果应用程序未编码为拦截 SIGTERM,则它只会硬终止应用程序,无论是否存在大于30秒的优雅终止期,这都可能导致数据丢失。
部管理 SIGTERM 可能会带来几个问题:
- 糟糕的用户体验:用户遇到错误,空白页面或更糟的情况
- 丢失数据:数据尚未提交,用户事务丢失
- 不可恢复的数据:刷新磁盘上的数据突然停止,你的应用程序无法处理它
还存在其它原因,但你会看到让应用程序足够快地关闭是多么重要。
硬件故障总是有可能的,因此你的应用程序应该始终能够在此类故障后恢复。然而,类似的常规故障不应该频繁发送。
多给你一点时间让你的应用程序正确停止通常是很好的做法(<5 分钟)。Kubernetes默认值为30秒,但你可以使用终止GracePeriodSeconds选项进行调整。
Pod反亲和力
Pod反关联性可让你避免同一节点上存在同一应用程序的多个实例(Pod)。当所有实例都位于同一节点上时发生节点奔溃时,你可以想象会发生停机。
为了避免这种情况,你可以要求Kubernetes避免所有Pod都位于同一节点上。存在两个版本:
1.软反亲和性Soft Anti-Affinity
a.PreferredDuringSchedulingIgnoredDuringExecution:将尽最大努力避免同一应用程序的多个实例部署在同一节点上,但如果缺乏资源,它将在同一节点上添加两个实例。这个版本具有成本效益,并且在95%的情况下都能发挥作用。
2.Hard Anti-Affinity
a.RequiredDuringSchedulingIgnoredDuringExecution:这将是一个硬性要求,不能在同一节点上有两个pod。但如果你要求同一应用程序有50个pod,则需要50个节点。
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: topology.kubernetes.io/zone
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S2
topologyKey: topology.kubernetes.io/zone
资源
资源是常见的问题之一。当设置的资源不足时,你的应用程序可以:
- 内存不足(OOM)并被内核驱逐。所以你会遇到停机、连接严重关闭等情况…
- 你设置的CPU够用了吗? 你的应用程序可能需要很长时间才能响应,甚至有时在活动检查成功之前无法启动。运行 100% 的 CPU 可能会强制自动缩放程序添加过多的实例。而您只需要利用当前的 CPU 数量即可。除非您知道自己在做什么,否则低于 100m 通常不好。
自动缩放Autoscaling
自动缩放是避免流量负载下停机的好方法。默认基于CPU(可以使用其他自定义指标)。这是自动部署更多实例(Pod)的简单方法。
自动缩放并不是魔法!你必须在Kubernetes上正确配置你的应用程序。
因此,例如,当你的pod短时间内运行超过60%的CPU时,Kubernetes会触发一个新的pod来处理负载并减少当前正在运行的应用程序的使用率。
以下是Kubernetes上述内容的实例:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
spec:
...
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
总结
Kubernetes确实有神奇的作用,但只有当应用程序尽可能是云原生且配置正确时,它才能发挥神奇作用。
总之,当你想将应用程序引入Kubernetes时,你至少应该注意:
- 最少两个实例
- 添加健康检查(探针)
- 应用程序必须处理Sigterm
- 配置自动缩放器
- 给予足够的资源
- 使用pod反亲和力
- 添加PDB
如果一切设置正确,Kubernetes体验将令人难以置信,你将大大减少应用停机情况。