一 分词基础
NLP:搭建了计算机语言和人类语言之间的转换



1 精确分词,试图将句子最精确的分开,适合文本分析
>>> import jieba
>>> content = "工信处女干事每月经过下属科室"
>>> jieba.cut(content,cut_all = False)
<generator object Tokenizer.cut at 0x0000026F1DA55DE0>
>>> jieba.lcut(content cut_all = False)
File "<stdin>", line 1
jieba.lcut(content cut_all = False)
^
SyntaxError: invalid syntax
>>> jieba.lcut(content, cut_all = False)
Building prefix dict from the default dictionary ...
Dumping model to file cache C:\Users\ADMINI~1\AppData\Local\Temp\jieba.cache
Loading model cost 0.797 seconds.
Prefix dict has been built successfully.
['工信处', '女干事', '每月', '经过', '下属', '科室']
2 全模式分词,把句子中所有的可以成词的词语都扫描出来,速度很快,但是不能消除歧义
>>> jieba.lcut(content, cut_all = Ture)
Traceback (most recent call last):
>>> jieba.lcut(content, cut_all = True)
['工信处', '处女', '女干事', '干事', '每月', '月经', '经过', '下属', '科室']
3 搜索引擎模式分词, 在精确模式的基础上,对长词再次切分,提高召回率,适用于搜索引擎分词
>>> jieba.cut_for_search(content)
<generator object Tokenizer.cut_for_search at 0x0000026F1DA55DE0>
>>> jieba.lcut_for_search(content)
['工信处', '干事', '女干事', '每月', '经过', '下属', '科室']
4 繁体字

5 用户自定义字典
jieba内部有自己的一个词典库,但是允许用户自己自定义补充词典

>>> import jieba
>>> jieba.lcut("八一双鹿更名为八一南昌篮球队")
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\ADMINI~1\AppData\Local\Temp\jieba.cache
Loading model cost 0.729 seconds.
Prefix dict has been built successfully.
['八', '一双', '鹿', '更名', '为', '八一', '南昌', '篮球队']
>>> jieba.load_userdict("./userdict.txt")
>>> jieba.lcut("八一双鹿更名为八一南昌篮球队")
['八一双鹿', '更名', '为', '八一', '南昌', '篮球队']

cmd常用编辑命令:
退出python环境,ctrl+z, 然后回车
创建文件:vim
写文件
6 中英文分词工具 hanlp
中文分词
import hanlp
tokenizer = hanlp.load('CTB6_CONVSEG')
tokenizer('工信处女干事每月经过下属科室')
英文分词
import hanlp
tokenizer = hanlp.utils.rules.tokenizer_english('CTB6_CONVSEG')
tokenizer('Mr. Hankcs bought hankcs.com for 1.5 thousand dollars.')
(1) 命名实体识别:把任意的专有名词,识别出来




import hanlp
//中文实体识别
recongnizer = hanlp.load(hanlp.pretrained.ner.MSRA_NER_BERT_BASE_ZH)
recongnizer (list('上海华安工业(集团)公司董事长谭旭光和秘书张晚霞来到美国纽约现代艺术博物馆参观'))
//英文实体识别
recongnizer = hanlp.load(hanlp.pretrained.ner.CONLL03_NER_BERT_BASE_UNCASED_EN)
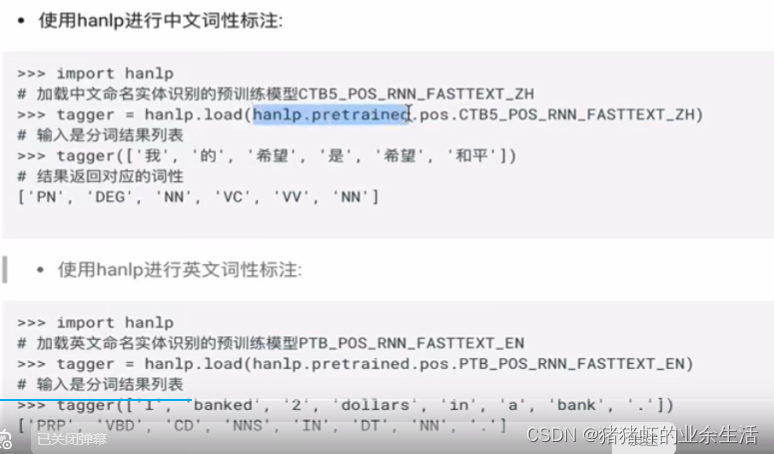
6 词性标注,每一个次不仅要分开,还要标记词性。是建立在分词的基础上


>>> import jieba.posseg as pseg
>>> pseg.lcut("我爱北京天安门")
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\ADMINI~1\AppData\Local\Temp\jieba.cache
Loading model cost 0.725 seconds.
Prefix dict has been built successfully.
[pair('我', 'r'), pair('爱', 'v'), pair('北京', 'ns'), pair('天安门', 'ns')]
二 文本张量
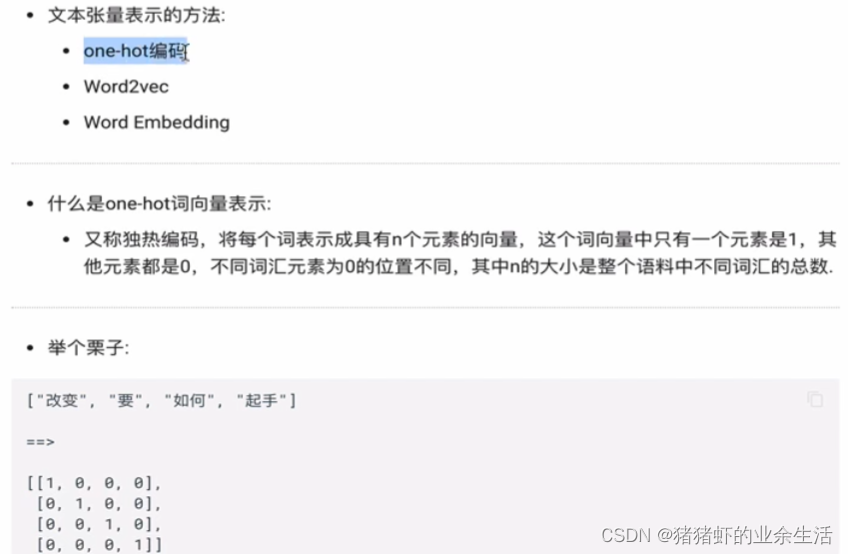
1 ONE-HOT
- 维度灾难,数据多长,就需要多长的维度
- 数据之间的相似性无法衡量,余弦相似度计算,相似度,所有结果都是0

矩阵里面的每一行数据,表示一个词。计算机能识别,一一对应



(1)one-hot编码器实现
from sklearn.externals import joblib
from keras.preprocessing.text import Tokenizer
vocab = {"周杰伦","陈奕迅"," 王力宏", "李宗盛 " }
//num_words=None:意味着不限制词汇表的大小
//char_level=False:表示按词处理文本,而不是按字符
t = Tokenizer(num_words = None, char_level = False)
t.fit_on_texts(vocab) //使用提供的词汇表对Tokenizer进行训练,构建词汇索引
for token in vocab:
zero_list = [0]*len(vocab) //创建一个与词汇表长度相等的全零列表zero_list
//t.texts_to_sequences([token])将词转换为其对应的索引序列。
//[0][0]从嵌套列表中提取实际的索引值
//-1调整索引,使其从0开始。
token_index = t.texts_to_sequences([token])[0][0] -1
zero_list [token_index ] = 1
print(token, " one-hot 编码是:",zero_list )
//使用joblib.dump保存训练好的Tokenizer对象到指定路径
tokenizer_path = "./Tokenizer"
joblib.dump(t,tokenizer_path)
李宗盛 one-hot 编码是: [1, 0, 0, 0]
周杰伦 one-hot 编码是: [0, 1, 0, 0]
陈奕迅 one-hot 编码是: [0, 0, 1, 0]
王力宏 one-hot 编码是: [0, 0, 0, 1]
(2)one-hot编码器使用
from sklearn.externals import joblib
t = joblib.load("./Tokenizer");
token = "周杰伦"
token_index = t.texts_to_sequences([token])[0][0] -1
zero_list = [0]*4
zero_list[token_index] = 1
print(token, "one-hot code :",zero_list)

(3)one-hot 编码优劣

2 word2vec
- 重要假设,离得越近的词语相似度越高
- 中心词的上下文是由什么来规定的,由窗口大小来限定
- 窗口限制外的非上下文词,太多了,导致负样本太多,所以只能采样一部分来作为负样本
- 如何评估词向量:可视化;输出相关度比较高的词语;类比实验
缺点

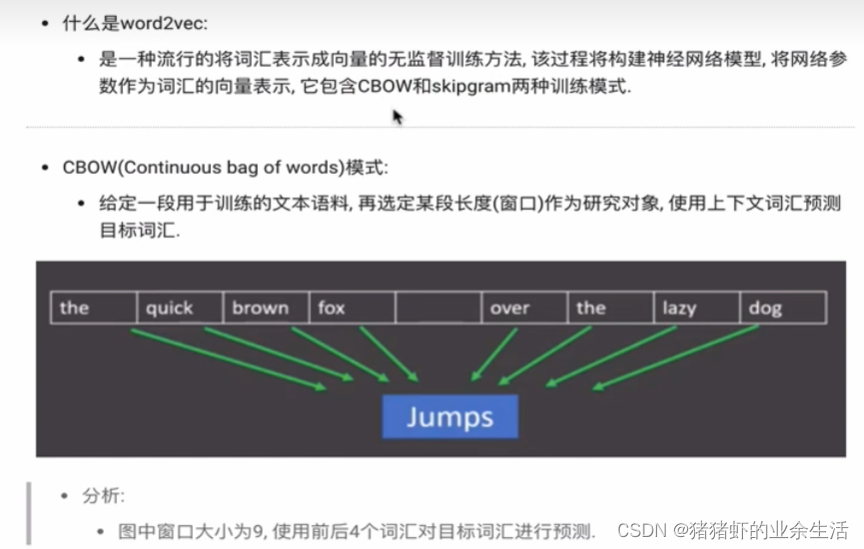
(1) CBOW
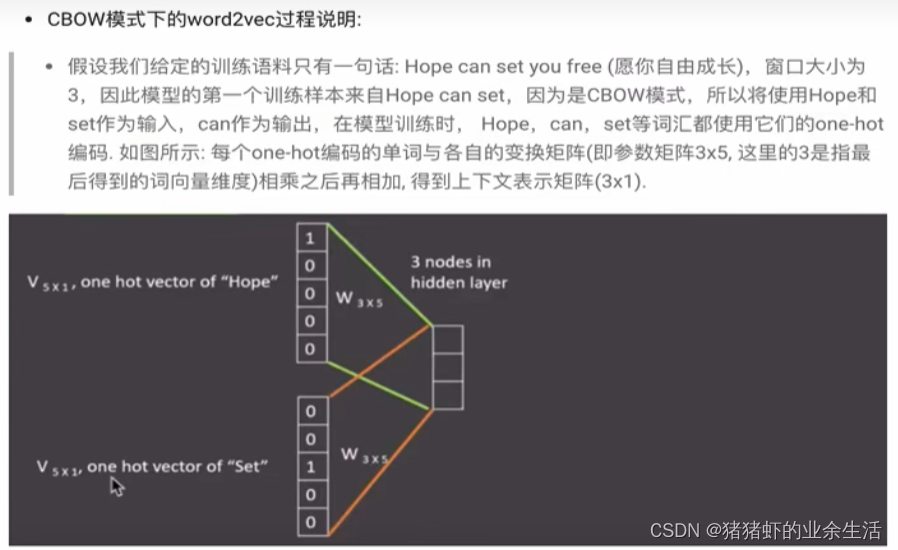
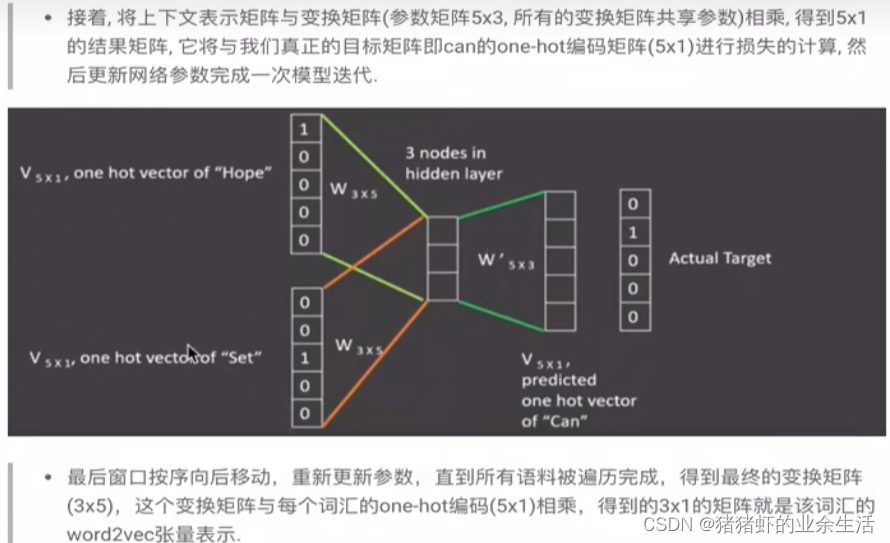
(2) skipgram
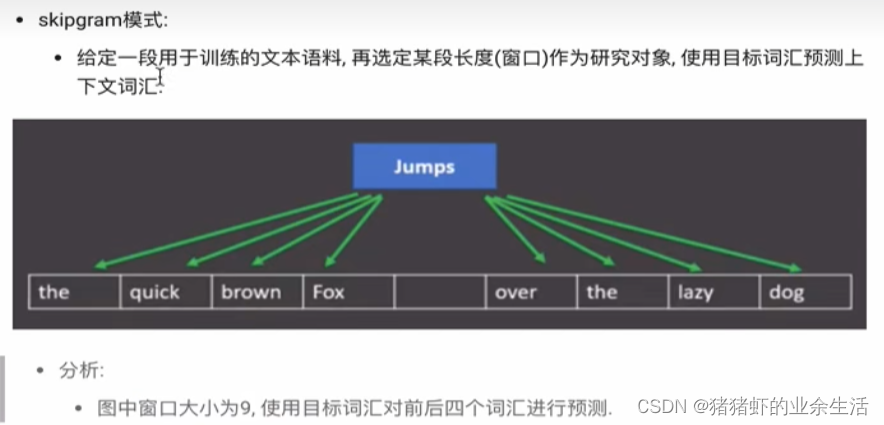
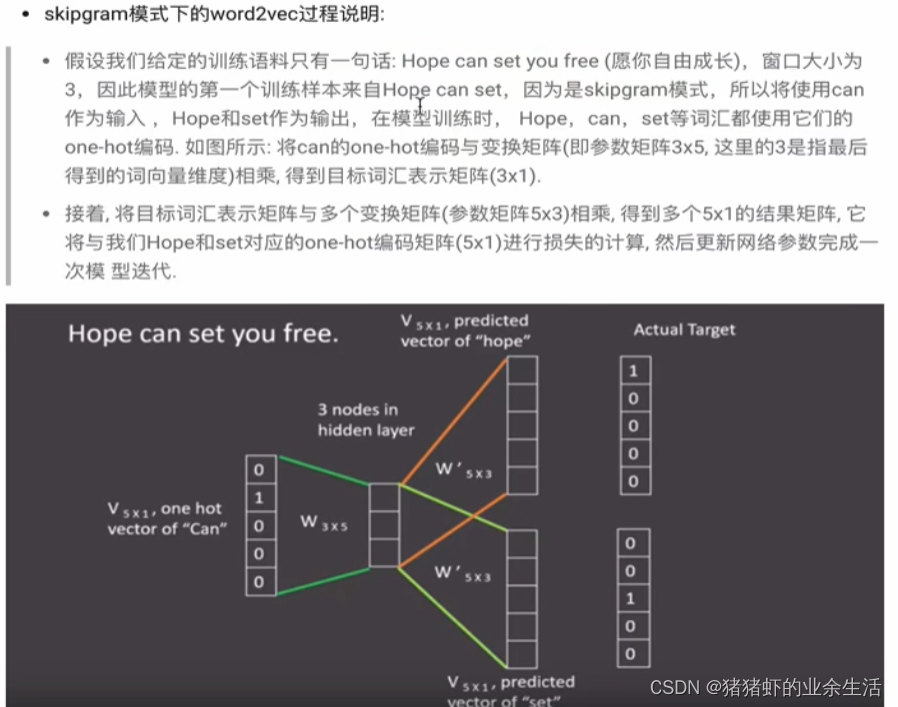

(3) skipgram
(4) 案例运行

cmd上进入python环境运行
- 数据准备
mkdir data
unzip data/enwik9.zip -d data
head -10 data/enwik9
perl wikifil.pl data/enwik9 >data/fil9
head -c 80 data/fil9


- 训练词向量
三 CMD 内安装jupyter
参考链接,可在不同地方安装该插件
-
直接打开CMD,然后直接输入
pip install jupyter即安装完毕 -
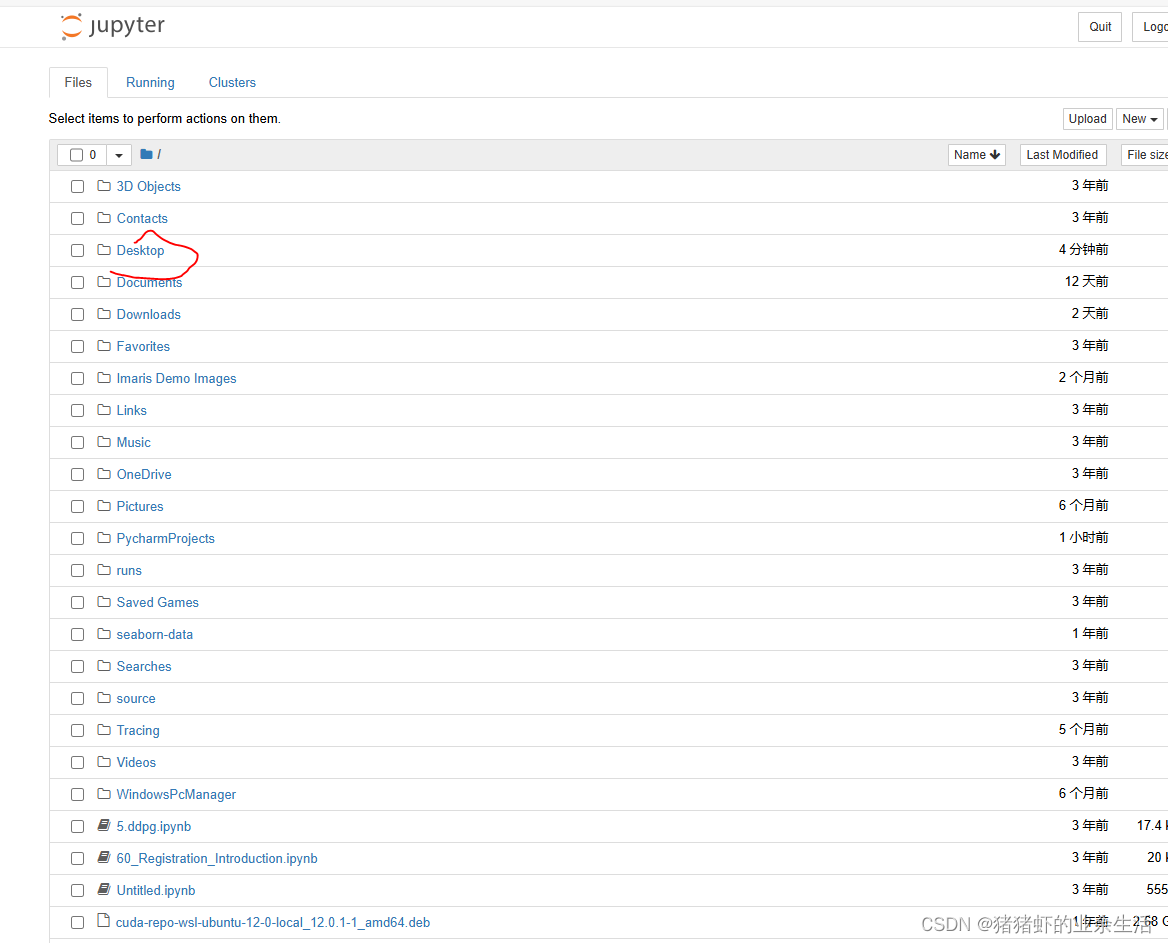
然后输入
jupyter notebook即运行jupyter,会出现一个网页,然后选Desktop,右上角创建Folder,最后在Folder里面创建.py文件即可







![[电子电路学]电路分析基本概念1](https://img-blog.csdnimg.cn/direct/d62ffa0f718145248c1e2e57131bd65f.png)
![[Java基础揉碎]反射](https://i-blog.csdnimg.cn/direct/c5e489ebe34d4a608021495397eb8517.png)