文章目录
- 一、安装
- 1.步骤
- 2.报错
- (1) can not run elasticsearch as root
- (2) could not find java in JAVA_HOME or bundled at ...
- (3) Error: Could not find or load main class XXX.JavaVersionChecker
- (4)BindTransportException[Failed to bind to [9300-9400]]
- (5)max virtual memory areas vm.max_map_count [65530] is too low
- (6)the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
- 二、Kibana
- 1.安装
- 2.报错
- (1)cluster. Error: No Living connections
- (2)FATAL Port 5601 is already in use. Another instance of Kibana may be running!
- 三、核心概念
- 1.逻辑设计
- 2.物理设计
- 四、IK分词器
- 1.安装
- 2.功能测试
- 3.扩展字典
- 五、Rest
- 其他
- elasticdump插件导入导出数据
- 参考
一、安装
1.步骤
- 在 Elasticsearch Service 上创建部署时,将自动设置一个主节点和两个数据节点。
- 通过从 tar 或 zip 存档安装,可以在本地启动 Elasticsearch 的多个实例,以查看多节点集群的行为。
- 下载
cd /usr/local # 进入此目录
curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.3.2-linux-x86_64.tar.gz
- 解压
tar -xvf elasticsearch-7.3.2-linux-x86_64.tar.gz
mv elasticsearch-7.3.2 elasticsearch7
- 创建非root用户
groupadd devGroup # 添加用户组devGroup
useradd es -g devGroup -p password # -g 指定组 -p 密码
chown es:devGroup -R elasticsearch7/ # -R 处理指定目录以及其子目录下的所有文件
- 启动
su es # 切换用户es
/usr/local/elasticsearch7/bin/elasticsearch # 启动Elasticsearch
- 访问
浏览器中访问http://ip地址:9200
2.报错
(1) can not run elasticsearch as root
进入elasticsearch-7.3.2/bin目录下执行./elasticsearch时出现了这个错误,原因就是es因为安全问题拒绝使用root用户启动。解决办法就是创建非root用户。
(2) could not find java in JAVA_HOME or bundled at …
出现这个问题,要么是没装jdk,要么是环境变量有问题。于是我突然意识到自己还没装jdk,下面来安装jdk。
- 下载安装包
下载jdk-8u333-linux-x64.tar.gz
- 将安装包上传至Linux系统中去
由于我是部署在自己的云服务器上,因此用的xshell内置的ftp文件传输工具将下载的tar.gz上传至linux服务器上。
- 解压
sudo tar -zxvf jdk-8u333-linux-x64.tar.gz
- 创建路径
mkdir /usr/local/java
- 将解压后的jdk移动至新建的文件夹中去
sudo mv jdk1.8.0_333 /usr/local/java
- 配置系统环境变量
看到网上很多教程都是修改的用户配置文件/etc/profile,实际上应该修改的是系统配置文件。
vim ~/.bashrc # 编辑系统配置文件
按下i,然后将以下配置粘贴到最末尾:
export JAVA_HOME=/usr/local/java/jdk1.8.0_333
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
然后按下esc键,输入:wq并回车保存配置。
- 检验jdk是否成功安装
java -version
(3) Error: Could not find or load main class XXX.JavaVersionChecker
额,想不到在排除了以上几个问题后,启动Elasticsearch服务时还是抽风了。
出现这个问题的原因就是,我们需要切换到非root用户去启动Elasticsearch服务,但实际上Elasticsearch被我们安装到了root目录下。
- 将Elasticsearch移动到用户目录中去
mv elasticsearch-7.3.2 /usr/local
- 再次启动
cd /usr/local/elasticsearch-7.3.2/bin # 进入目录
su es # 切换用户es
./elasticsearch # 启动Elasticsearch
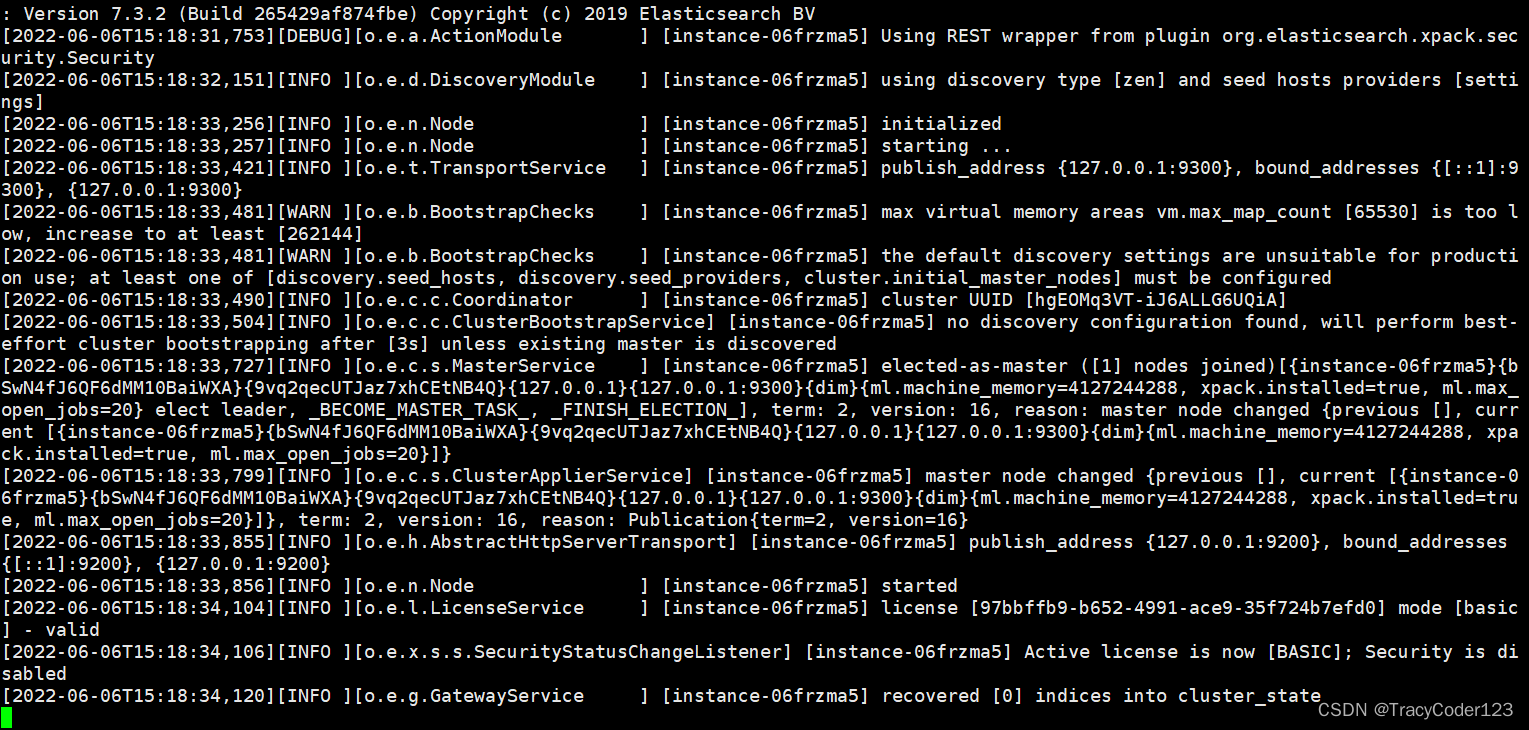
感动,这次终于成功了:
(4)BindTransportException[Failed to bind to [9300-9400]]
报这个错说明服务器ip配置不对,修改elasticsearch.yml中network.host为内网ip。
(5)max virtual memory areas vm.max_map_count [65530] is too low
报这个错说明系统虚拟内存默认最大映射数为65530,无法满足ES系统要求,需要调整为262144以上。
#修改文件
sudo vim /etc/sysctl.conf
#添加参数
...
vm.max_map_count = 262144
#重新加载配置
sysctl -p
(6)the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
报这个错说明缺少默认的配置,至少应该配置以下配置中的一个:
discovery.seed_hosts: 集群主机列表
discovery.seed_providers: 基于配置文件配置集群主机列表
cluster.initial_master_nodes: 启动时初始化的参与选主的node,生产环境必填
### (7)BindTransportException[Failed to bind to [9300-9400]]; nested: BindException
配置文件中的ip地址得是内网ip。
# 二、配置
Elasticsearch 有三个配置文件,存放在 config 目录下:
```java
elasticsearch.yml 用于配置 Elasticsearch
jvm.options 用于配置 Elasticsearch JVM 的设置
log4j2.properties 用户配置 Elasticsearch 日志
- 参考:
JVM 参数设置
日志配置
重要Elasticsearch配置
重要的系统参数
二、Kibana
1.安装
- 下载
首先进入https://www.elastic.co/cn/downloads/past-releases/kibana-7-3-2下载好与Elasticsearch相同版本的安装包。然后把下载好的安装包上传到服务器上去。
- 解压
tar -xvf kibana-7.3.2-linux-x86_64.tar.gz # 解压,注意换成你的压缩包名
mv kibana-7.3.2-linux-x86_64 kibana7 # 重命名
cd kibana7 # 进入目录
- 修改配置
vim config/kibana.yml # 修改配置文件,修改以下内容
server.port: 5601 # 端口
server.host: "172.16.16.4" # 内网ip
elasticsearch.hosts: ["http://172.16.16.4:9200"] # Elasticsearch的url
- 修改权限,用非root用户操纵kibana
chown es:devGroup -R kibana7/
然后启动Elasticsearch服务和kibana。
- 启动kibana
cd /usr/local/kibana7/bin # 进入目录
su es # 切换用户es
./kibana # 启动
- 访问
浏览器中访问http://ip地址:5601/app/kibana
2.报错
(1)cluster. Error: No Living connections
出现这个问题说明是没连上Elasticsearch,看一下elasticsearch.yml配置是否有问题,尤其是一些涉及到ip的地方。所有涉及到ip的地方我都写的服务器内网ip,而不是外网ip、localhost、127.0.0.1这些。
(2)FATAL Port 5601 is already in use. Another instance of Kibana may be running!
端口占用问题。
# 找到进程IP
fuser -n tcp 5601
# 然后kill掉这个进程
kill -9 进程IP
三、核心概念
| 关系型数据库 | Elasticsearch |
|---|---|
| 数据库 | 索引 |
| 表 | types(逐渐会被弃用) |
| 行 | documents |
| 字段 | fields |
1.逻辑设计
一切都是JSON。
-
文档
索引和搜索的最小单位,就是一条条数据
文档可以嵌套 -
类型
每个字段的类型,可以不设置,让es去猜;也可以提前设置,就和关系型数据库差不多了。 -
索引
相当于数据库,是大量文档的集合。索引存储了映射类型的字段和其他设置,他们被存到了各个分片上。
2.物理设计
- 节点和分片如何工作

- 一个集群至少有一个节点,一个节点就是一个Elasticsearch进程
- 一个节点默认有5个分片,每个分片也会有一个复制分片
- 分片和对应的复制分片不会在同一个节点中,保障分布式系统的高可用性
- 每个分片都包含了一个包含倒排索引的文件目录,倒排索引使得在不扫描全部文档的情况下,就能知道哪些文档包含特定的关键字。
- 倒排索引
底层采用lucene倒排索引作为底层,这种结构适用于快速的全文搜索。对于每个倒排索引,都包含了一个不重复的列表,即,对于每个词,都有一个包含它的文档列表。
doc_1:She crunched her apple noisily.
doc_2:He took another bite of apple.
| term | doc_1 | doc_2 |
|---|---|---|
| She | √ | × |
| crunched | √ | × |
| her | √ | × |
| apple | √ | √ |
| noisily | √ | × |
| He | × | √ |
| took | × | √ |
| another | × | √ |
| bite | × | √ |
| of | × | √ |
- score计算
假如搜索her apple,doc_1的得分应该比doc_2更高。
| term | doc_1 | doc_2 |
|---|---|---|
| her | √ | × |
| apple | √ | √ |
| total | 2 | 1 |
- Elasticsearch的索引和Lucene索引
一个es的索引包含多个分片,每个分片包含一个Lucene索引。
四、IK分词器
一个中文分词器,提供了两个算法ik_smart和ik_max_word。默认的中文分词器把一句话分成一个一个的字,肯定是不行的,因此要使用ik中文分词器。
ik_max_word: 会将文本做最细粒度的拆分,比如会将"中华人民共和国国歌"拆分为"中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌",会穷尽各种可能的组合;
ik_smart: 会做最粗粒度的拆分,比如会将"中华人民共和国国歌"拆分为"中华人民共和国,国歌"。
1.安装
- 下载和es相同版本的插件安装包:https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.3.2
- 解压安装包到 ElasticSearch 所在文件夹中的plugins目录中
- 再启动ElasticSearch,查看IK分词器插件是否安装成功
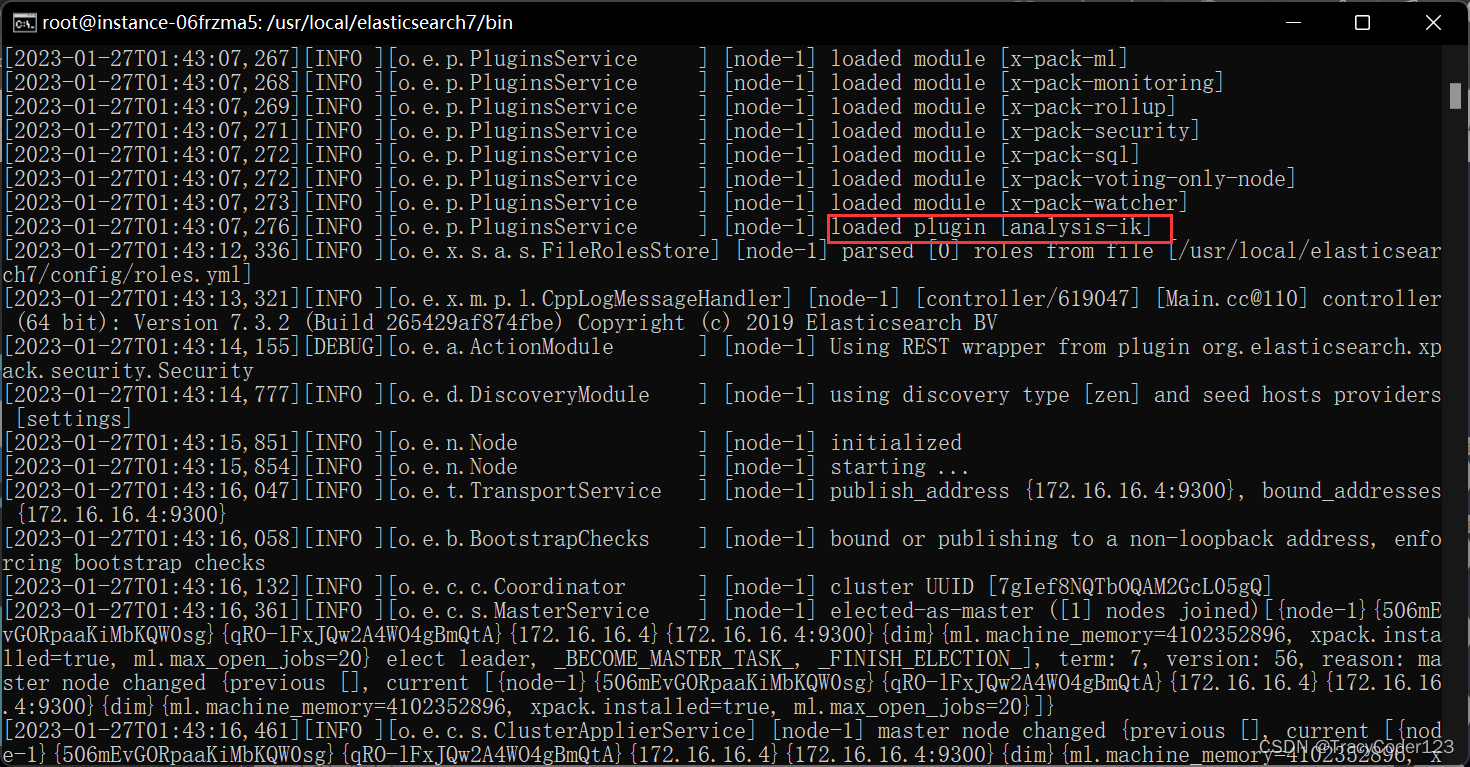
2.功能测试
在kibana dev中测试以下两个rest请求,能得到不同的结果:
GET _analyze
{
"analyzer": "ik_smart",
"text": "中国共产党"
}
GET _analyze
{
"analyzer": "ik_max_word",
"text": "中国共产党"
}
3.扩展字典
由于自带的词库不一定有某些词,因此可以对词库进行扩充。
比如,当我们作如下请求的时候:
GET _analyze
{
"analyzer": "ik_smart",
"text": "爱国人士王二麻"
}
会得到以下分词结果:
{
"tokens" : [
{
"token" : "爱国人士",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "王",
"start_offset" : 4,
"end_offset" : 5,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "二",
"start_offset" : 5,
"end_offset" : 6,
"type" : "TYPE_CNUM",
"position" : 2
},
{
"token" : "麻",
"start_offset" : 6,
"end_offset" : 7,
"type" : "CN_CHAR",
"position" : 3
}
]
}
我们想将王二麻作为一个词分出来,然而词库中并没有这个词,所以,我们需要对词库进行扩充。
在ik分词器文件的config目录中新建自定义的字典文件,以.dic为后缀。
my.dic
王二麻
然后打开 IKAnalyzer.cfg.xml 文件,把自定义的字典添加到IK的字典中:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">my.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
重启es,词库中就有王二麻这个词了,可以测试一下。
五、Rest
使用postman操纵Elasticsearch:教程在此,对于几种分词器也有说明
数据类型:Elasticsearch 7.X 数据类型
其他
elasticdump插件导入导出数据
- 先安装node.js
教程在此
- 导入导出命令
1 在es目录下安装elasticdump插件
npm install elasticdump -g
2 启动es服务
3 导出数据为json格式
在自己电脑上,进入准备存放json文件的目录,执行以下命令
elasticdump --input http://ip地址:9200/zhsf_3_0 --output ./zhsf_3_0_mapping.json --type=mapping
elasticdump --input http://ip地址:9200/zhsf_3_0 --output ./zhsf_3_0.json --type=data
第一条复制结构,第二条复制数据
4 通过json文件导入数据
elasticdump --input ./zhsf_4_0_mapping.json --output http://localhost:9200/zhsf_4_0 --type=mapping
elasticdump --input ./zhsf_4_0.json --output "http://localhost:9200/zhsf_4_0"
参考
Elasticsearch中文文档
教程
博客1
博客2
博客3
博客4