文章目录
- 一、ForkJoin框架概述
- 1_核心概念
- 2_主要类和方法
- 1_ForkJoinPool
- 2_ForkJoinTask
- 二、启用异步模式与否的区别
- 三、ForkJoinPool的三种任务提交方式
- 四、执行逻辑及使用示例
- 1_示例:并行计算数组元素和
- 2_`forkJoinPool.submit`
- 3_`ForkJoinTask<?>`中任务的执行逻辑
- 4_fork\join中的逻辑
- 5_窃取任务的实现
- 五、线程池的大小对性能的影响
- 六、ForkJoin与传统线程池的比较
- 七、同步与异步线程池
- 1_Executors.newWorkStealingPool
- 2_ForkJoinPool.commonPool
- 3_对比与总结
- 1_共同点
- 2_不同点
- 3_窃取工作进行计算
- 八、总结
在现代计算中,高效并行处理是提升应用程序性能的关键之一。Java 7 引入的 ForkJoinPool 框架是实现高并行度和递归任务处理的强大工具。本文将详细介绍 ForkJoinPool 框架及其核心的工作窃取算法。
一、ForkJoin框架概述
ForkJoinPool 是 Java 并发包中的并行计算框架,旨在有效执行递归任务和大规模并行计算。其核心思想是通过任务拆分(fork)和任务合并(join)来实现高并行度,它体现的是一种分治思想,适用于能够进行任务拆分的 cpu 密集型运算。并利用工作窃取算法来平衡负载。
所谓的任务拆分,是将一个大任务拆分为算法上相同的小任务,直至不能拆分可以直接求解。跟递归相关的一些计算,如归并排序、斐波那契数列、都可以用分治思想进行求解。
Fork/Join 在分治的基础上加入了多线程,可以把每个任务的分解和合并交给不同的线程来完成,进一步提升了运算效率。
ForkJoinPool是ForkJoin框架执行任务的核心组件。它是工作窃取算法的执行地,负责管理工作线程和提供任务执行环境。
1_核心概念
-
ForkJoinTask:
ForkJoinTask是一个抽象类,表示一个可以并行执行的任务,有两个子类:RecursiveTask<V>:有返回值的任务。RecursiveAction:没有返回值的任务。
- 也就是说提交给 Fork/Join 线程池的任务需要继承 RecursiveTask(有返回值)或 RecursiveAction(没有返回值)
-
工作窃取算法:
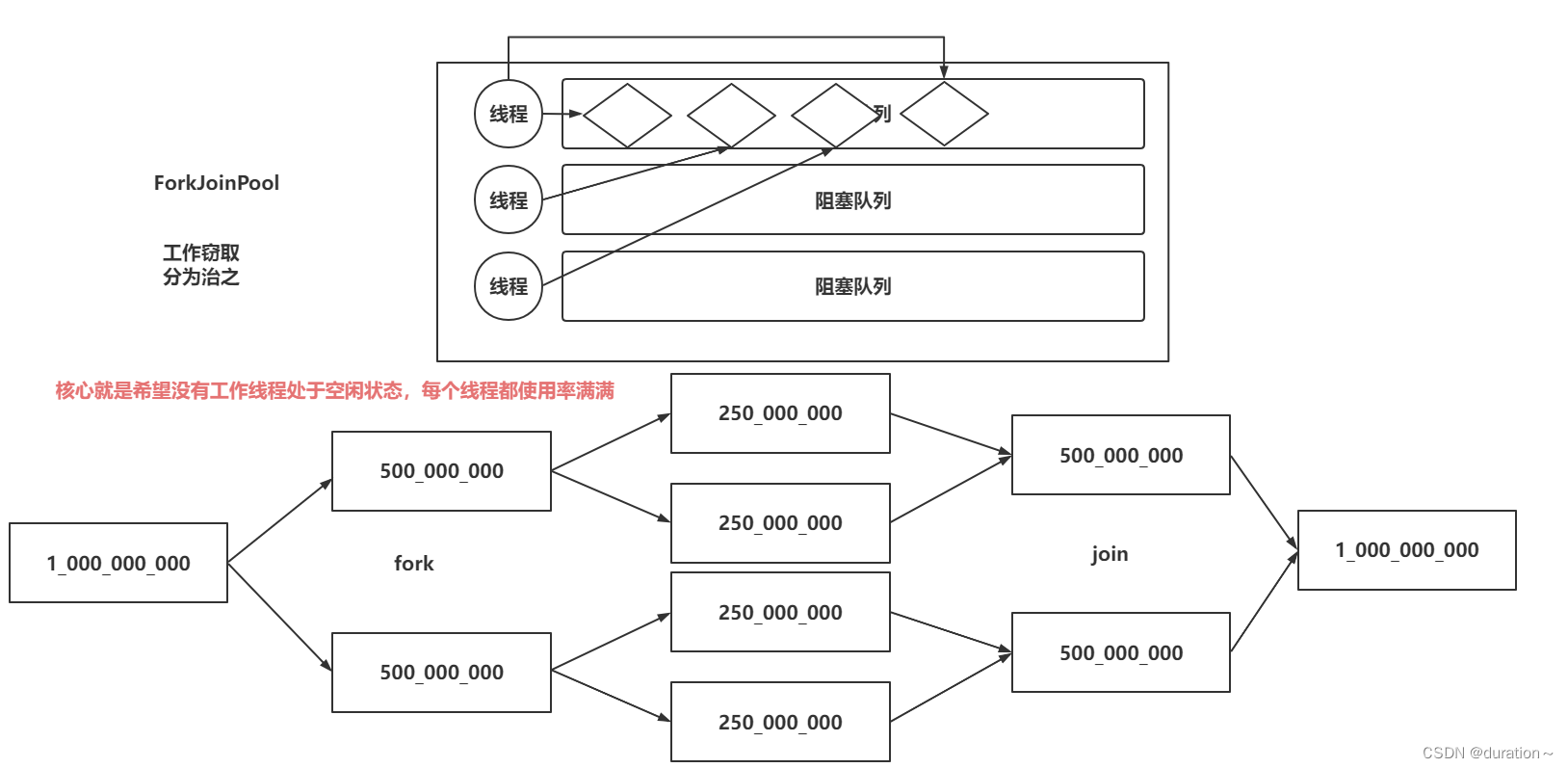
- 每个工作线程维护一个工作队列(WorkQueue),这是一个双端队列(Deque),里面存放的对象是任务(ForkJoinTask)。
- 每个工作线程在运行中产生新的任务(通常是因为调用了 fork())时,会放入工作队列的队尾,并且工作线程在处理自己的工作队列时,使用的是 LIFO 方式,也就是说每次从队尾取出任务来执行。
- 当一个线程的任务队列为空时或当前任务(join),它可以从其他忙碌线程的队列“窃取”任务来执行,极大提高了并行计算的效率。
- 默认情况下,从自己队列中获取任务执行和其他线程窃取自己队列中的任务执行是从队列相反的两端(头部、尾部)来进行的,极大的减少了竞争的情况出现。
2_主要类和方法
1_ForkJoinPool
ForkJoinPool 是核心类,负责管理和调度 ForkJoinTask 任务。
-
构造函数:
Fork/Join 默认会创建与 cpu 核心数大小相同的线程池,也就是第一个构造方法。ForkJoinPool() ForkJoinPool(int parallelism) ForkJoinPool(int parallelism, ForkJoinPool.ForkJoinWorkerThreadFactory factory, Thread.UncaughtExceptionHandler handler, boolean asyncMode)parallelism:并行度,通常设置为可用处理器的数量。factory:用于创建工作线程的工厂。handler:未捕获异常处理器。asyncMode:是否启用异步模型。
-
常用方法:
<T> T invoke(ForkJoinTask<T> task) void execute(ForkJoinTask<?> task) <T> ForkJoinTask<T> submit(ForkJoinTask<T> task)
2_ForkJoinTask
ForkJoinTask 是一个抽象类,表示一个可以并行执行的任务。
- 常用方法:
final ForkJoinTask<V> fork() // 异步执行任务 开启一个新线程(或是重用线程池内的空闲线程),将任务交给该线程处理。 final V join() // 等待任务完成并获取结果 final V invoke() // 同步执行任务并返回结果 final V get() // 获取任务结果(可能阻塞)
这里并不会每个 fork 都会创建新线程, 也不是每个 join 都会造成线程被阻塞, 而是采取了 work-stealing 原理
二、启用异步模式与否的区别
ForkJoinPool 构造函数中的 asyncMode 参数决定线程池是否启用异步模型。这一选项主要影响本地任务的调度和执行策略,窃取任务无论在哪种模式下都是 FIFO 是没有区别的,也就是从其他线程的工作队列头部窃取任务,先创建的任务会被优先处理。
-
不启用异步模型 (
asyncMode = false) 默认:- 工作线程从自己队列的尾部弹出(pop)任务(LIFO)执行,等同于”栈操作”,后续创建的任务会被优先处理,适合需要深度优先执行的任务。
- 更快地触及递归的底部,使得子任务尽快完成和合并,适合小规模和短生命周期的任务。

-
启用异步模型 (
asyncMode = true):- 工作线程从自己队列的头部弹出(poll)任务(FIFO)执行,等同于”队列操作”,先创建的任务会被优先处理,适合需要广度优先执行的任务。
- 降低某些情况下的任务窃取成本,更适合较大批量和较长生命周期的任务。
根据 JDK 官方文档,将 asyncMode 设置为 true 为从未加入的分叉任务建立本地先进先出的调度模式。在工作线程仅处理事件样式异步任务的应用程序中,这个模式可能比默认的基于本地堆栈的模式更合适。

asyncMode ? FIFO_QUEUE : LIFO_QUEUE,
可以从图中看到 asyncMode 参数的值决定了使用的队列。
根据Doug Lea的说法,FIFO 方法比 LIFO 具有以下优势:
Doug Lea 是 JDK7 中 fork/join 框架的实现者,也是 JDK 中 JUC 的核心开发者,真 Java 大神。
- 它通过让"窃贼"作为所有者在 deque 的另一侧操作来减少竞争。
- 它利用了早期生成“大型”任务的递归分治算法的性质。
上面的第二点意味着可以通过一个被盗任务的线程可以进一步分解旧的被盗任务。
三、ForkJoinPool的三种任务提交方式
ForkJoinPool 提供了三种提交任务的方式:invoke、execute 和 submit。这三种方式都利用了工作窃取算法来优化任务调度和执行。
-
invoke 方法
- 同步执行任务,并返回其结果。
- 阻塞调用线程,直到任务完成。
ForkJoinPool pool = new ForkJoinPool(); SumTask task = new SumTask(array, 0, array.length); Integer result = pool.invoke(task); -
execute 方法
- 异步执行任务,不返回结果。
- 常用于提交不需要返回结果的任务。
ForkJoinPool pool = new ForkJoinPool(); SumTask task = new SumTask(array, 0, array.length); pool.execute(task); -
submit 方法
- 异步执行任务,并返回一个
Future对象,用于获取任务结果或检查任务状态。
ForkJoinPool pool = new ForkJoinPool(); SumTask task = new SumTask(array, 0, array.length); Future<Integer> future = pool.submit(task); Integer result = future.get(); // 阻塞,直到任务完成 - 异步执行任务,并返回一个
四、执行逻辑及使用示例
1_示例:并行计算数组元素和
下面是一个使用 ForkJoinPool 进行并行计算的示例,我们将实现一个计算数组元素和的任务,并展示如何使用 RecursiveTask 来实现任务拆分和合并。
import java.util.concurrent.*;
public class ForkJoinPoolExample {
public static void main(String[] args) throws InterruptedException, ExecutionException {
ForkJoinPool forkJoinPool = new ForkJoinPool();
int[] array = new int[100];
for (int i = 0; i < array.length; i++) {
array[i] = i + 1; // 初始化数组
}
SumTask task = new SumTask(array, 0, array.length);
Future<Integer> result = forkJoinPool.submit(task);
System.out.println("Sum: " + result.get());
forkJoinPool.shutdown();
}
static class SumTask extends RecursiveTask<Integer> {
private static final int THRESHOLD = 10; // 阈值
private int[] array;
private int start;
private int end;
SumTask(int[] array, int start, int end) {
this.array = array;
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
if (end - start <= THRESHOLD) {
int sum = 0;
for (int i = start; i < end; i++) {
sum += array[i];
}
return sum;
} else {
int mid = (start + end) / 2;
SumTask leftTask = new SumTask(array, start, mid);
SumTask rightTask = new SumTask(array, mid, end);
leftTask.fork(); // 异步执行左任务
int rightResult = rightTask.compute(); // 当前线程执行右任务
int leftResult = leftTask.join(); // 等待左任务完成并获取结果
return leftResult + rightResult;
}
}
}
}
2_forkJoinPool.submit
提交任务后的执行流程分析:
1、可以看到submit方法进行校验后,会执行到externalPush中,真正处理的方法是externalPush。

2、externalPush执行流程分析如下:
-
判断工作队列数组是否为空
-
通过按位与得到当前任务分配的工作队列
-
尝试通过CAS锁定该队列
-
判断工作队列中的任务数组是否为空
-
释放锁
-
提交任务(如果前面的判断满足会直接返回,不会执行到这里)
final void externalPush(ForkJoinTask<?> task) {
WorkQueue[] ws; WorkQueue q; int m;
int r = ThreadLocalRandom.getProbe();
int rs = runState;
if ((ws = workQueues) != null && (m = (ws.length - 1)) >= 0 &&// 判断工作队列数组是否为空
(q = ws[m & r & SQMASK]) != null && r != 0 && rs > 0 &&// 通过按位与得到当前任务分配的工作队列
U.compareAndSwapInt(q, QLOCK, 0, 1)) { // 尝试通过CAS锁定该队列
ForkJoinTask<?>[] a; int am, n, s;
if ((a = q.array) != null &&// 判断工作队列中的任务数组是否为空
(am = a.length - 1) > (n = (s = q.top) - q.base)) {// 尝试添加任务
int j = ((am & s) << ASHIFT) + ABASE;
U.putOrderedObject(a, j, task);
U.putOrderedInt(q, QTOP, s + 1);
U.putIntVolatile(q, QLOCK, 0);
if (n <= 1)// 如果就只有一个任务
signalWork(ws, q);// 调用单个任务执行
return;
}
U.compareAndSwapInt(q, QLOCK, 1, 0);// 释放锁
}
externalSubmit(task); // 提交任务
}
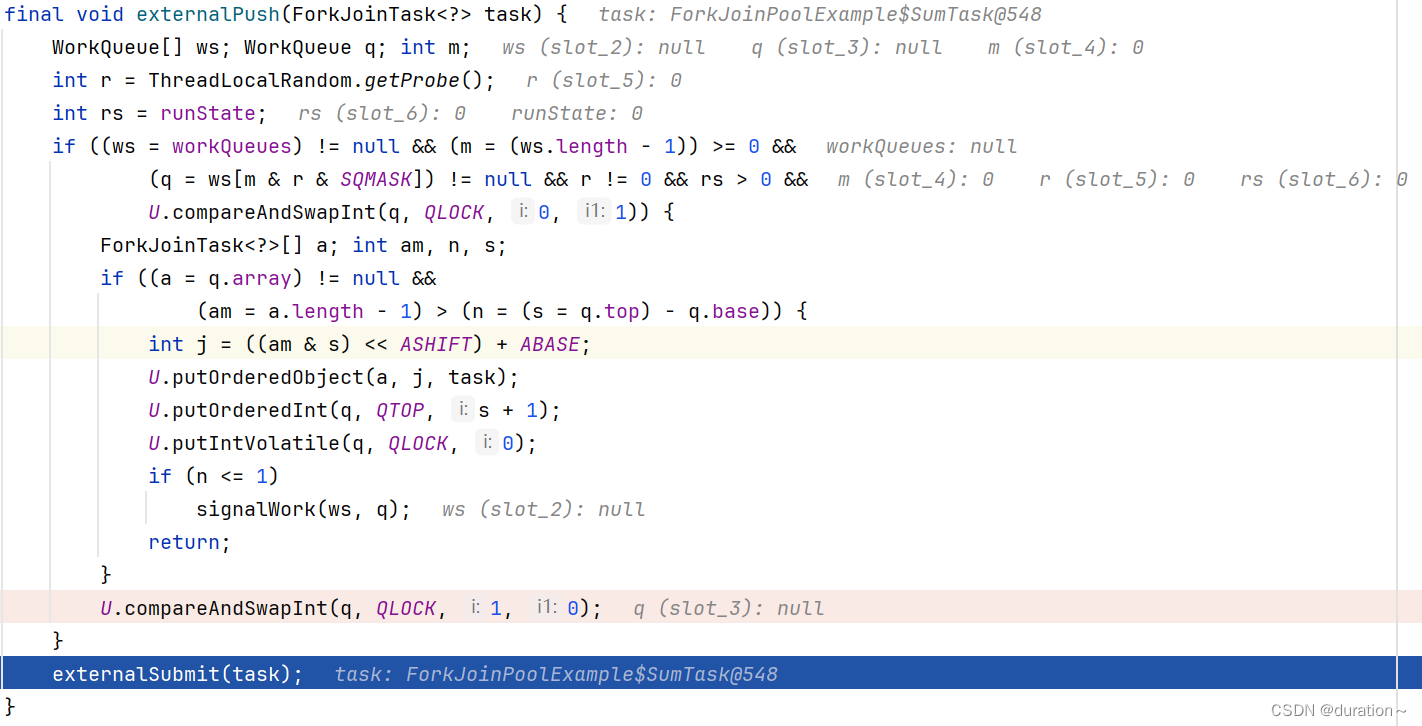
根据 debug 由于我们是第一次执行任务提交,workQueues参数为 null,所以直接进入到externalSubmit方法中。
3、externalSubmit(task);方法流程分析。主要流程是在for (;;) { 中分三次循环完成的。
- 创建工作队列数组。
workQueues = new WorkQueue[n]; - 创建一个具体的队列
q = new WorkQueue(this, null);ws[k] = q; - 大任务存放到队列中
U.putOrderedObject(a, j, task); signalWork(ws, q);这个方法有两个参数,一个是工作队列数组,还有一个是工作队列。
private void externalSubmit(ForkJoinTask<?> task) {
int r; // initialize caller's probe
if ((r = ThreadLocalRandom.getProbe()) == 0) {
ThreadLocalRandom.localInit();
r = ThreadLocalRandom.getProbe();
}
for (;;) {//死循环中
WorkQueue[] ws; WorkQueue q; int rs, m, k;
boolean move = false;
if ((rs = runState) < 0) {
tryTerminate(false, false); // help terminate
throw new RejectedExecutionException();
}
else if ((rs & STARTED) == 0 || // initialize
((ws = workQueues) == null || (m = ws.length - 1) < 0)) {
int ns = 0;
rs = lockRunState();
try {
if ((rs & STARTED) == 0) {
U.compareAndSwapObject(this, STEALCOUNTER, null,
new AtomicLong());
// create workQueues array with size a power of two
int p = config & SMASK; // ensure at least 2 slots
int n = (p > 1) ? p - 1 : 1;
n |= n >>> 1; n |= n >>> 2; n |= n >>> 4;
n |= n >>> 8; n |= n >>> 16; n = (n + 1) << 1;
workQueues = new WorkQueue[n];//1.创建了一个工作队列数组 此时还没有东西
ns = STARTED;
}
} finally {
unlockRunState(rs, (rs & ~RSLOCK) | ns);
}
}
else if ((q = ws[k = r & m & SQMASK]) != null) {
if (q.qlock == 0 && U.compareAndSwapInt(q, QLOCK, 0, 1)) {
ForkJoinTask<?>[] a = q.array;
int s = q.top;
boolean submitted = false; // initial submission or resizing
try { // locked version of push
if ((a != null && a.length > s + 1 - q.base) ||
(a = q.growArray()) != null) {
int j = (((a.length - 1) & s) << ASHIFT) + ABASE;
U.putOrderedObject(a, j, task);//3.将任务存到队列中的位置
U.putOrderedInt(q, QTOP, s + 1);
submitted = true;
}
} finally {
U.compareAndSwapInt(q, QLOCK, 1, 0);
}
if (submitted) {
signalWork(ws, q);
return;
}
}
move = true; // move on failure
}
else if (((rs = runState) & RSLOCK) == 0) { // create new queue
q = new WorkQueue(this, null);//2.构造出一个队列
q.hint = r;
q.config = k | SHARED_QUEUE;
q.scanState = INACTIVE;
rs = lockRunState(); // publish index
if (rs > 0 && (ws = workQueues) != null &&
k < ws.length && ws[k] == null)
ws[k] = q; //2.将队列存到某一个位置 // else terminated
unlockRunState(rs, rs & ~RSLOCK);
}
else
move = true; // move if busy
if (move)
r = ThreadLocalRandom.advanceProbe(r);
}
}
4、signalWork(ws, q);之后的流程分析
-
在
signalWork中有一个主要的方法就是tryAddWorker。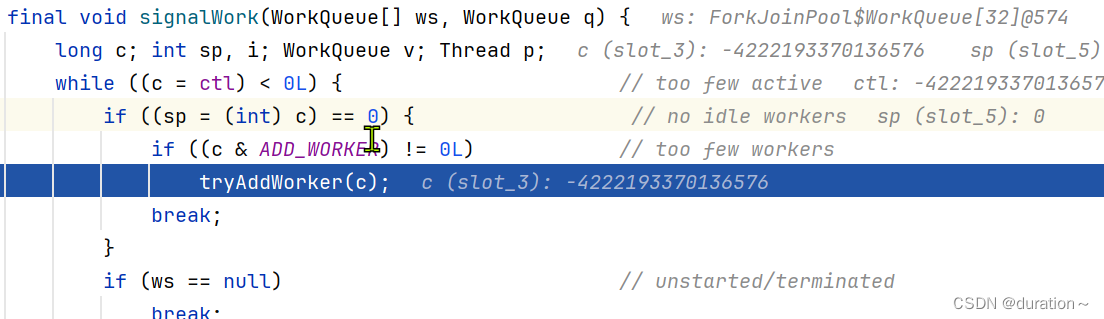
-
而在
tryAddWorker中又主要看createWorker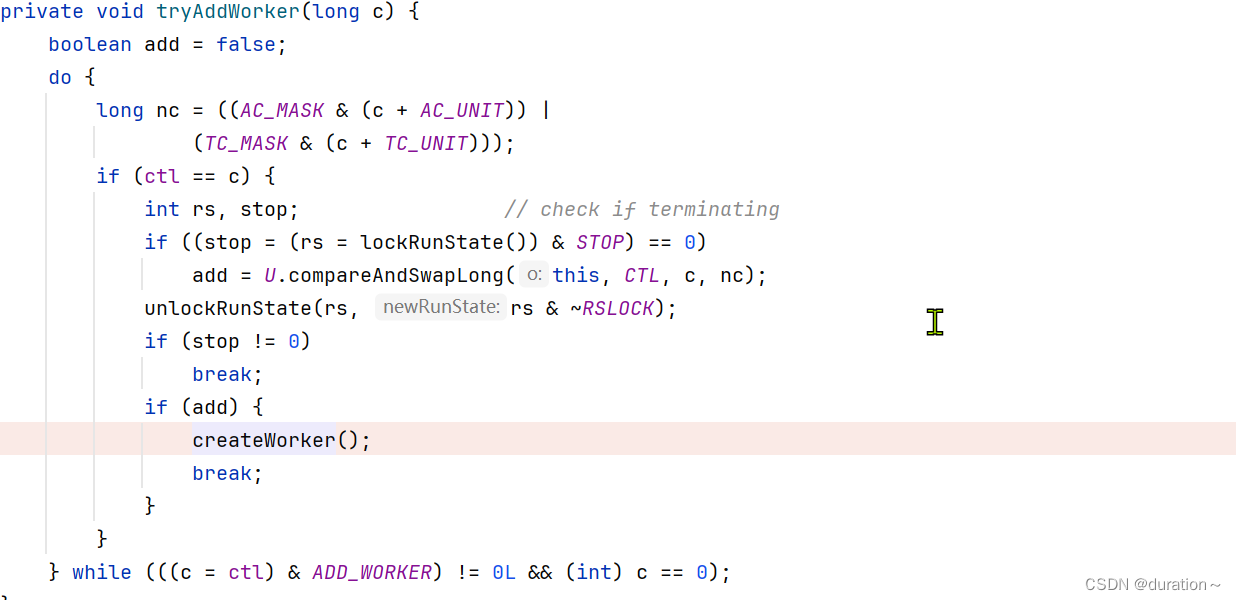
-
在
createWorker中利用 ForkJoinWorkerThreadFactory 的方法新建了一个线程并启动,然后执行任务。private boolean createWorker() { ForkJoinWorkerThreadFactory fac = factory; Throwable ex = null; ForkJoinWorkerThread wt = null; try { if (fac != null && (wt = fac.newThread(this)) != null) {//新建一个线程 wt.start();//启动线程 return true; } } catch (Throwable rex) { ex = rex; } deregisterWorker(wt, ex); return false; } -
新建的线程是
ForkJoinWorkerThread是 Thread 的子类。public static interface ForkJoinWorkerThreadFactory { /** * Returns a new worker thread operating in the given pool. * * @param pool the pool this thread works in * @return the new worker thread * @throws NullPointerException if the pool is null */ public ForkJoinWorkerThread newThread(ForkJoinPool pool); } public class ForkJoinWorkerThread extends Thread//Thread 的子类
到这里forkJoinPool.submit提交任务后的流程就结束了,主要做的事情就是将task任务放入到创建的workQueue中,并创建一个线程执行任务,此时也会将队列和工作线程相关联,剩下执行任务的逻辑就属于ForkJoinTask<?>的了。
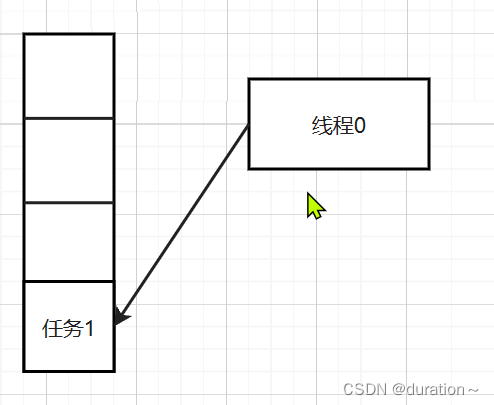
3_ForkJoinTask<?>中任务的执行逻辑
经过上面的分析我们可以知道,最后新建了一个ForkJoinWorkerThread线程,然后调用了start方法。那么我们看看这个线程类的run方法吧~

1、在run方法中我们可以看到主要的代码逻辑在pool.runWorker(workQueue);中,ForkJoinPool执行任务的过程如下:
-
判断工作队列是否需要扩容
-
阻塞调用对应WorkQueue的
runTask方法 -
如果无法获取到执行资源,就等待任务调用
final void runWorker(WorkQueue w) {
w.growArray(); // allocate queue
int seed = w.hint; // initially holds randomization hint
int r = (seed == 0) ? 1 : seed; // avoid 0 for xorShift
for (ForkJoinTask<?> t;;) {
if ((t = scan(w, r)) != null)
w.runTask(t);
else if (!awaitWork(w, r))
break;
r ^= r << 13; r ^= r >>> 17; r ^= r << 5; // xorshift
}
}
2、WorkQueue的rukTask
-
标记当前状态为忙碌
-
调用当前任务执行
-
继续执行当前队列中等待执行的任务
-
尝试从其他WorkQueue中窃取任务执行
final void runTask(ForkJoinTask<?> task) {
if (task != null) {
scanState &= ~SCANNING; // mark as busy
(currentSteal = task).doExec();//执行任务
U.putOrderedObject(this, QCURRENTSTEAL, null); // release for GC
execLocalTasks();// *** 重点
ForkJoinWorkerThread thread = owner;
if (++nsteals < 0) // collect on overflow
transferStealCount(pool);
scanState |= SCANNING;
if (thread != null)
thread.afterTopLevelExec();
}
}
注意:doExec()方法无论在runTask还是execLocalTasks中都是真正执行任务的方法,最终会调用ForkJoinTask<?>实现类的compute()方法。
final void execLocalTasks() {
int b = base, m, s;
ForkJoinTask<?>[] a = array;
if (b - (s = top - 1) <= 0 && a != null &&
(m = a.length - 1) >= 0) {
if ((config & FIFO_QUEUE) == 0) {//由asyncMode决定
for (ForkJoinTask<?> t;;) {
if ((t = (ForkJoinTask<?>)U.getAndSetObject
(a, ((m & s) << ASHIFT) + ABASE, null)) == null)
break;
U.putOrderedInt(this, QTOP, s);
t.doExec();//执行任务
if (base - (s = top - 1) > 0)
break;
}
}
else
pollAndExecAll();
}
}
4_fork\join中的逻辑
我们知道,如果在compute中使用fork会将大任务拆分成较小的任务来执行。那么流程是怎么样的呢?
1、将当前线程的工作队列取到,并将拆分的小任务放入到当前线程的工作队列中。
public final ForkJoinTask<V> fork() {
Thread t;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)//判断
((ForkJoinWorkerThread)t).workQueue.push(this);//this是拆分的小任务
else
ForkJoinPool.common.externalPush(this);
return this;
}
2、注意看放入队列的push方法,其中最主要的是p.signalWork(p.workQueues, this);这行代码。
final void push(ForkJoinTask<?> task) {
ForkJoinTask<?>[] a; ForkJoinPool p;
int b = base, s = top, n;
if ((a = array) != null) { // ignore if queue removed
int m = a.length - 1; // fenced write for task visibility
U.putOrderedObject(a, ((m & s) << ASHIFT) + ABASE, task);
U.putOrderedInt(this, QTOP, s + 1);
if ((n = s - b) <= 1) {
if ((p = pool) != null)
p.signalWork(p.workQueues, this);//这里的this是workQueue
}
else if (n >= m)
growArray();
}
}
3、根据之前的分析流程(2_forkJoinPool.submit4、signalWork(ws, q))可知,signalWork 方法会新创建一个ForkJoinWorkerThread去执行任务。
4、总结,fork会将当前拆分的任务放入当前线程的工作队列中,并且还会创建新的线程(在没达到设定的上限时)执行任务,由于新建的线程任务队列中为空,多半会去窃取当前线程工作队列中的任务。之后将循环这个流程。
大致流程如下所示:

5、当 fork执行完了之后到达图中箭头位置的点,我们发现 线程0、线程1 阻塞住,但是任务4、任务5、任务6…这些拆分的小任务都还没有执行,现在没有线程执行任务那么怎么办呢?这就要我们去了解join方法中的逻辑了。

注意:这里的join方法与线程中的是不一样的。这里的 join 方法主要是调用 doJoin 方法:
status表示任务的状态,如果小于 0 表示任务已经结束了。
private int doJoin() {
int s; Thread t; ForkJoinWorkerThread wt; ForkJoinPool.WorkQueue w;
return (s = status) < 0 ? s :
((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) ?//判断当前线程是否是工作线程
(w = (wt = (ForkJoinWorkerThread)t).workQueue).
tryUnpush(this) && (s = doExec()) < 0 ? s :
wt.pool.awaitJoin(w, this, 0L) :
externalAwaitDone();
}
6、那么这个方法主要是干了啥呢?主要去看awaitJoin方法。
从下面源码发现,主要部分还是一个死循环。
- 首先还是检查当前任务是否执行完:
if ((s = task.status) < 0)。 - 然后可以发现如果当前任务没有执行完则可能会进入
helpStealer(w, task)和helpComplete(w, cc, 0)。helpStealer:先定位的偷取者的任务队列;从偷取者的base索引开始,每次偷取一个任务执行。tryCompensate: tryCompensate主要用来补偿工作线程因为阻塞而导致的算力损失,当工作线程自身的队列不为空,且还有其它空闲工作线程时,如果自己阻塞了,则在此之前会唤醒一个工作线程。
- 根据这两个方法的方法名可以大致知晓:这两个方法是让当前线程帮助其他线程执行任务。
final int awaitJoin(WorkQueue w, ForkJoinTask<?> task, long deadline) {
int s = 0;
if (task != null && w != null) {
ForkJoinTask<?> prevJoin = w.currentJoin; // 获取给定Worker的join任务
U.putOrderedObject(w, QCURRENTJOIN, task); // 把currentJoin替换为给定任务
// 判断是否为CountedCompleter类型的任务
CountedCompleter<?> cc = (task instanceof CountedCompleter) ?
(CountedCompleter<?>) task : null;
for (; ; ) {
if ((s = task.status) < 0) // 已经完成|取消|异常 跳出循环
break;
if (cc != null) // CountedCompleter任务由helpComplete来完成join
helpComplete(w, cc, 0);
else if (w.base == w.top || w.tryRemoveAndExec(task)) //尝试执行
helpStealer(w, task); // 队列为空或执行失败,任务可能被偷,帮助偷取者执行该任务
if ((s = task.status) < 0) // 已经完成|取消|异常,跳出循环
break;
// 计算任务等待时间
long ms, ns;
if (deadline == 0L)
ms = 0L;
else if ((ns = deadline - System.nanoTime()) <= 0L)
break;
else if ((ms = TimeUnit.NANOSECONDS.toMillis(ns)) <= 0L)
ms = 1L;
if (tryCompensate(w)) { // 执行补偿操作
task.internalWait(ms); // 补偿执行成功,任务等待指定时间
U.getAndAddLong(this, CTL, AC_UNIT); // 更新活跃线程数
}
}
U.putOrderedObject(w, QCURRENTJOIN, prevJoin); // 循环结束,替换为原来的join任务
}
return s;
}
总结:假设当前线程是 线程0 ,如上图执行到 任务1.join。当前任务1没有执行完,但是线程会帮助其他线程执行拆分后的小任务,不断循环,直到任务1执行完成 也就是status<0。

5_窃取任务的实现
final class WorkQueue {
// 省略其他代码...
// 偷取任务的方法
final ForkJoinTask<?> pollAt(int b) {
ForkJoinTask<?>[] a; int i; ForkJoinTask<?> t;
if ((a = array) != null && (i = a.length - 1) >= 0 &&
(t = a[b & i]) != null && t != a[b & (i >>>= 1)]) {
if (t instanceof CountedCompleter) // 偷取CountedCompleter任务
((CountedCompleter<?>)t).propagateCompletion();
return t;
}
return null;
}
// 从其他队列中偷取任务
final ForkJoinTask<?> poll() {
WorkQueue[] ws; int m;
int r = ThreadLocalRandom.current().nextInt();
if ((ws = pool.workQueues) != null && (m = ws.length - 1) >= 0 &&
(ws = ws[m & r & SQMASK]) != null) {
int j = r & SMASK; // 随机选择一个队列进行偷取
WorkQueue w; ForkJoinTask<?>[] a; ForkJoinTask<?> t;
if ((w = ws[j]) != null && w.base - w.top < 0 &&
(a = w.array) != null) { // 如果队列不为空,且还有任务未执行
for (int b = r;;) { // 循环偷取任务
int n = a.length;
if (n >= NCPU || (t = w.pollAt(b & (n - 1))) == null) // 如果当前队列中没有可偷取的任务
break;
if (w.base == (b + 1)) // 如果队列被其他线程修改
return null;
if (UNSAFE.compareAndSwapObject(a, ((n - 1) & b) << ASHIFT, t, null))
return t;
if (n <= 1 || w.currentSteal != b)
break;
}
}
}
return null;
}
// 省略其他代码...
}
五、线程池的大小对性能的影响
线程池的大小直接影响到程序的性能。在ForkJoin框架中,理想的情况是线程数等于处理器核心数。
int processors = Runtime.getRuntime().availableProcessors();
ForkJoinPool pool = new ForkJoinPool(processors);
通常来讲,对于计算密集型任务,设置线程池大小为处理器核心数可获得最佳性能。对于包含IO操作或是响应中断的任务,可能需要更多的线程来维持CPU的利用率。
六、ForkJoin与传统线程池的比较
传统的线程池如Executors.newFixedThreadPool()对所有任务采用一个共享的工作队列,而ForkJoin采用工作窃取算法和每个线程一个工作队列的设计,这提高了处理并行任务的效率。
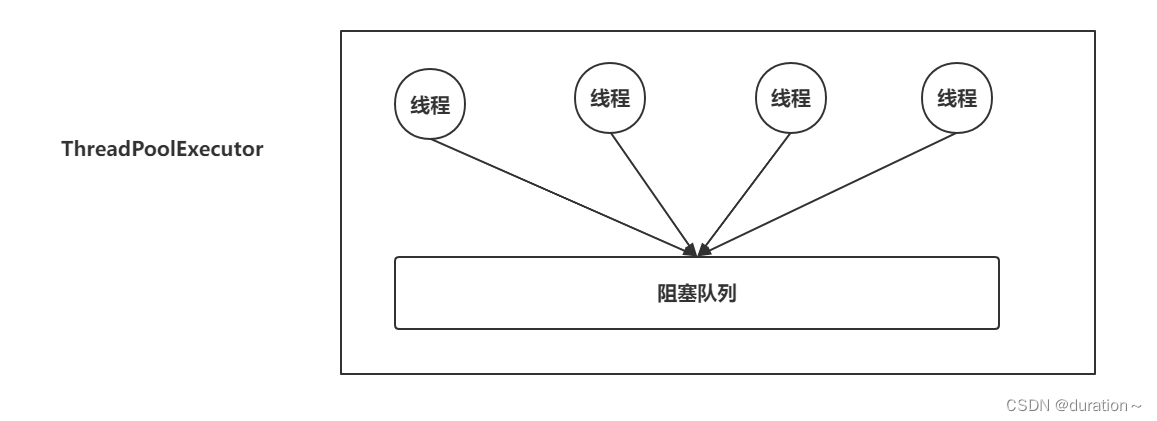
// 传统线程池使用示例
ExecutorService executorService = Executors.newFixedThreadPool(4);
executorService.submit(new Task());
// ForkJoin线程池使用示例
ForkJoinPool forkJoinPool = new ForkJoinPool();
forkJoinPool.submit(new ForkJoinTask<Void>() { /* ... */ });
对于计算密集型任务,尤其是可以进行合理拆分的任务,ForkJoin往往比传统线程池表现更好。
七、同步与异步线程池
ForkJoinPool 除了直接使用 new关键字直接创建,还可以使用 ForkJoinPool.commonPool 或 Executors.newWorkStealingPool 的方式获得 ForkJoinPool 对象。
1_Executors.newWorkStealingPool
newWorkStealingPool 简单翻译是任务窃取线程池。
newWorkStealingPool 是Java8添加的线程池。和别的Executors创建的其他4种不同,它用的是ForkJoinPool。
使用ForkJoinPool的好处是,把1个任务拆分成多个“小任务”,把这些“小任务”分发到多个线程上执行。这些“小任务”都执行完成后,再将结果合并。
之前的线程池中,多个线程共有一个阻塞队列,而newWorkStealingPool 中每一个线程都有一个自己的队列。
当线程发现自己的队列没有任务了,就会到别的线程的队列里窃取任务执行。
一般是自己的本地队列采取LIFO(后进先出),窃取时采用FIFO(先进先出),一个从尾部开始执行,一个从头开始执行,由于偷取的动作十分快速,会大量降低这种冲突,也是一种优化方式。
它有2种实现,无参:
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool
(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
有参:
就一个参数parallelism,可以自定义并行度。
public static ExecutorService newWorkStealingPool(int parallelism) {
return new ForkJoinPool
(parallelism,
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
特点
- 独立实例:每次调用 newWorkStealingPool 都会创建一个新的 ForkJoinPool 实例,不是共享的单例。
- 默认线程数量:默认情况下,线程池的并行度是 CPU 内核数,可以通过传入一个整数参数来指定并行度。
- 灵活性高:适用于需要单独管理并行度或者需要隔离不同并行任务的应用场景。
根据上面的分析我们可以看到,无论是无参构造还是有参,asyncMode 的参数都是true。这证实了我们将使用 FIFO 的队列配置。
2_ForkJoinPool.commonPool
ForkJoinPool.commonPool 是一个全局共享的 ForkJoinPool 实例(内部 static final ForkJoinPool common的变量),Java 系统在启动时就会初始化这个线程池。
特点
- 全局共享:commonPool 是一个单例,适用于应用程序中的并行计算任务。
- 默认线程数量:默认情况下,线程池的并行度(parallelism level)是 CPU 内核数减一。可以通过设置系统属性
java.util.concurrent.ForkJoinPool.common.parallelism来修改默认并行度。 - 适用范围广:适用于相对轻量级的并行任务,比如并行流操作、递归任务等。
类初始化时会使用 makeCommonPool() 方法中完成,为 ForkJoinPool 中的 common 参数赋值。该方法根据可用的处理器数量计算并行度,并创建一个新的 ForkJoinPool 实例。
private static ForkJoinPool makeCommonPool() {
final ForkJoinWorkerThreadFactory commonPoolForkJoinWorkerThreadFactory =
new CommonPoolForkJoinWorkerThreadFactory();
int parallelism = -1;
ForkJoinWorkerThreadFactory factory = null;
UncaughtExceptionHandler handler = null;
try { // ignore exceptions in accessing/parsing properties
String pp = System.getProperty
("java.util.concurrent.ForkJoinPool.common.parallelism");
String fp = System.getProperty
("java.util.concurrent.ForkJoinPool.common.threadFactory");
String hp = System.getProperty
("java.util.concurrent.ForkJoinPool.common.exceptionHandler");
if (pp != null)
parallelism = Integer.parseInt(pp);
if (fp != null)
factory = ((ForkJoinWorkerThreadFactory)ClassLoader.
getSystemClassLoader().loadClass(fp).newInstance());
if (hp != null)
handler = ((UncaughtExceptionHandler)ClassLoader.
getSystemClassLoader().loadClass(hp).newInstance());
} catch (Exception ignore) {
}
if (factory == null) {
if (System.getSecurityManager() == null)
factory = commonPoolForkJoinWorkerThreadFactory;
else // use security-managed default
factory = new InnocuousForkJoinWorkerThreadFactory();
}
if (parallelism < 0 && // default 1 less than #cores
(parallelism = Runtime.getRuntime().availableProcessors() - 1) <= 0)//这一步会将并行度设置为 CPU 内核数减一
parallelism = 1;
if (parallelism > MAX_CAP)
parallelism = MAX_CAP;
return new ForkJoinPool(parallelism, factory, handler, LIFO_QUEUE,//使用LIFO的队列模式
"ForkJoinPool.commonPool-worker-");
}
ForkJoinPool.commonPool使用后进先出(LIFO)队列配置,而Executors.newWorkStealingPool使用先进先出的方法(FIFO)配置。
3_对比与总结
1_共同点
- 工作窃取算法:二者都使用工作窃取算法来优化并行任务处理。
- 任务类型:都适用于
ForkJoinTask及其子类,如RecursiveTask和RecursiveAction。
2_不同点
-
实例共享:
ForkJoinPool.commonPool是全局共享单例,适合对所有并行计算任务使用统一的线程池。Executors.newWorkStealingPool每次调用都会创建一个新的实例,适合需要单独管理不同任务群或不同并行度的场景。
-
并行度设置:
ForkJoinPool.commonPool的并行度可以通过系统属性来更改,但所有使用commonPool的任务共享同一个并行度配置。Executors.newWorkStealingPool可以灵活指定并行度,每个创建的线程池实例可以有不同的并行度。
-
使用场景:
ForkJoinPool.commonPool适合全局共享并行线程池的轻量并行任务,比如并行流操作。Executors.newWorkStealingPool适合需要隔离不同任务群的场景,例如不同模块有不同的并行处理需求,或者某些任务需要特定的并行度配置。
选择使用哪种线程池应根据具体的应用场景和需要,并考虑共享性、灵活性和并行度的需求。通过合理选择适合的线程池,可以有效提升应用程序的并行处理能力和整体性能。
3_窃取工作进行计算
有了同步线程池,ForkJoinPool.commonPool只要任务仍在进行中,就会将线程放入池中。
因此,工作窃取的程度并不取决于任务粒度水平。
异步Executors.newWorkStealingPool的管理更强,允许工作窃取级别取决于任务粒度级别。
我们使用ForkJoinPool类的 getStealCount获得工作窃取级别:
long steals = forkJoinPool.getStealCount();
确定Executors.newWorkStealingPool和ForkJoinPool.commonPool的工作窃取计数给我们带来了不同的行为:
Executors.newWorkStealingPool ->
Granularity: [1], Steals: [6564]
Granularity: [10], Steals: [572]
Granularity: [100], Steals: [56]
Granularity: [1000], Steals: [60]
Granularity: [10000], Steals: [1]
ForkJoinPool.commonPool ->
Granularity: [1], Steals: [6923]
Granularity: [10], Steals: [7540]
Granularity: [100], Steals: [7605]
Granularity: [1000], Steals: [7681]
Granularity: [10000], Steals: [7681]
当Executors.newWorkStealingPool的粒度从精细变为粗(1到10,000)时,工作窃取水平就会降低。
因此,当任务没有分解时,窃取计数为1(粒度[granularity]为10000)。
ForkJoinPool.commonPool有不同的行为。
工作窃取水平总是很高,受到任务粒度变化的影响并不大。
从技术上讲,我们的素数示例支持异步处理事件式任务。
这是因为我们的实现不会强制结果的加入。
可以证明,Executors.newWorkStealingPool在解决问题时提供了最佳资源利用。
八、总结
ForkJoinPool 通过任务拆分和工作窃取机制,实现了高效的并行计算,非常适合需要递归计算和大规模并行处理的场景。通过合理选择是否启用异步模式,以及合适的任务提交方式,ForkJoinPool 能显著提升应用程序的并行处理能力和整体性能。
希望本文能帮助您更好地理解 ForkJoinPool 框架及其工作窃取算法,并能在实际项目中有效应用。
















![【PWN · ret2libc | protobuf】[2024CISCN · 华中赛区]protoverflow](https://i-blog.csdnimg.cn/direct/a6a9f832a7644da8b1038372bd962faa.png)