第1关:情感分析的基本方法
情感分析简介
情感分析,又称意见挖掘、倾向性分析等。简单而言,是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。在日常生活中,情感分析的应用非常普遍,下面列举几种常见的应用场景。

图 1
1、电子商务 情感分析最常应用到的领域就是电子商务。例如淘宝和京东,用户在购买一件商品以后可以发表他们关于该商品的体验。通过分配等级或者分数,这些网站能够为产品和产品的不同功能提供简要的描述。客户可以很容易产生关于整个产品的一些建议和反馈。通过分析用户的评价,可以帮助这些网站提高用户满意度,完善不到位的地方。
2、舆情分析 无论是政府还是公司,都需要不断监控社会对于自身的舆论态度,及时感知舆情,进行情感分析有助于及时公关,正确维护好公司的品牌,以及产品和服务评价。
3、市场呼声 市场呼声是指消费者使用竞争对手提供的产品与服务的感受。及时准确的市场呼声有助于取得竞争优势,并促进新产品的开发。尽早检测这类信息有助于进行直接、关键的营销活动。情感分析能够为企业实时获取消费者的意见。这种实时的信息有助于企业制定新的营销策略,改进产品功能,并预测产品故障的可能。
根据分析载体的不同,情感分析会涉及很多主题,包括针对电影评论、商品评论,以及新闻和博客等的情感分析。对情感分析的研究到目前为止主要集中在两个方面:识别给定的文本实体是主观的还是客观的,以及识别主观的文本的极性。大多数情感分析研究都使用机器学习方法。
在情感分析领域,文本可以划分为积极和消极两类,或者积极、消极和中性(或不相关)的多类。分析方法主要分为:词法分析、基于机器学习的分析以及混合分析。
词法分析
词法分析运用了由预标记词汇组成的字典,使用词法分析器将输入文本转换为单词序列,将每一个新的单词与字典中的词汇进行匹配。如果有一个积极的匹配,分数加到输入文本的分数总池中;相反,如果有一个消极的匹配,输入文本的总分会减少。具体流程如图2所示。
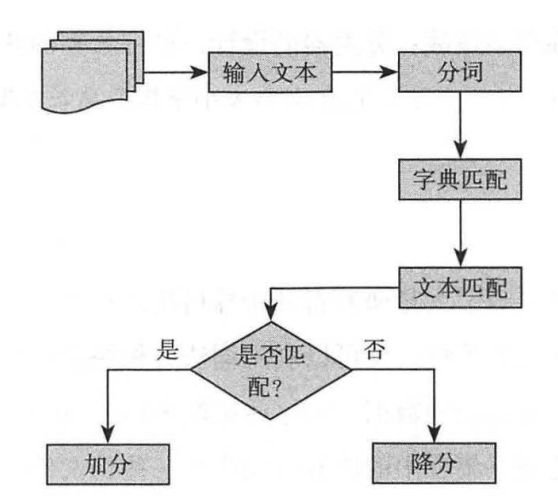
图 2 词法分析的流程
文本的分类取决于文本的总得分。目前有大量的工作致力于度量词法信息的有效性。对单个短语,通过手动标记词汇(仅包含形容词)的方式,大概能达到85%准确率,这是由评价文本的主观性所决定的。词法分析也存在一个不足:其性能(时间复杂度和准确率)会随着字典大小(词汇的数量)的增加而迅速下降。
机器学习方法
机器学习技术由于其具有高的适应性和准确性受到了越来越多的关注。在情感分析中,主要使用的是监督学习方法。它可以分为三个阶段:数据收集、预处理、训练分类。在训练过程中,需要提供一个标记语料库作为训练数据。分类器使用一系列特征向量对目标数据进行分类。
在机器学习技术中,决定分类器准确率的关键是合适的特征选择,通常来说,单个短语、 两个连续的短语以及三个连续的短语都可以被选为特征向量,当然还有其他的一些特征,如积极词汇的数量等。
机器学习技术面临很多挑战,如分类器的设计、训练数据的获取、对一些未见过的短语的正确解释等等。
混合分析
情感分析研究的进步吸引大量研究者开始探讨将两种方法进行组合的可能性,既可以利用机器学习方法的高准确性,又可以利用词法分析快速的特点。有研究者利用由两个词组成的词汇和一个未标记的数据,将这些由两个词组成的词汇划分为积极的类和消极的类。利用被选择的词汇集合中的所有单词产生一些伪文件。然后计算伪文件与未标记文件之间的余弦相似度。根据相似度将该文件划分为积极的或消极的情感。之后这些训练数据集被送入朴素贝叶斯分类器进行训练。

第2关:基于情感词典的情感分析实战
情感极性分析简介
情感极性分析是对带有感情色彩的主观性文本进行分析、处理、归纳和推理的过程。按照处理文本的类别不同,可分为基于新闻评论的情感分析和基于产品评论的情感分析。其中,前者多用于舆情监控和信息预测,后者可帮助用户了解某一产品在大众心目中的口碑,目前常见的情感极性分析方法主要是两种:基于情感词典的方法和基于机器学习的方法。本实训主要接下来将主要介绍基于情感词典的情感分析,关于基于机器学习的情感分析,将在后续实训中介绍。

图 1
基于情感词典的情感分析
基于情感词典的情感分析应该是最简单的情感分析方法了,它的思路大概为:对文档分词,找出文档中的情感词、否定词以及程度副词,然后判断每个情感词之前是否有否定词及程度副词,将它之前的否定词和程度副词划分为一个组,如果有否定词将情感词的情感权值乘以−1,如果有程度副词就乘以程度副词的程度值,最后所有组的得分加起来,大于0的归于正向,小于0的归于负向。
基于情感词典的情感分析算法流程如下:
-
将一个中文文本转换为一个有短句子字符串组成列表
-
对每一个短句子字符串进行如下操作:
- 使用 jieba 分词系统将一个短句子转换成词语、词性对的列表;
- 使用词语的词性筛选出潜在的情感词语;
- 在已有的情感词典中查找这些潜在的情感词语;
- 所查找的情感词语的情感词语分类 以及它的情感值组合成一个词典并记录到一个列表中;
- 使用相应的算法处理这个列表,得出这个小句子的情感极值。
-
将一个中文文本中的所有短句子的情感极值记录在一个列表中;
-
使用相应的算法处理这个列表, 得出整个中文文本的情感极值。
采用情感词典的情感分析算法准确度主要取决于分词的准确率以及情感词典的准确率,对句式简单的句子的识别准确率高,但对复杂句子的分析依赖于复杂的文本处理算法。
算法实现
在进行基于情感词典的情感分析之前,首先,我们需要准备好基础数据,包括有情感词典、否定词词典、程度副词词典、停用词词。然后开始进行以下步骤: 1、分词 对我们需要进行情感分析的句子进行分词,将分词结果转为字典,key 为单词,value 为单词在分词结果中的索引。
def list_to_dict(word_list):
data = {}
for x in range(0, len(word_list)): # 将分词结果转为字典
data[word_list[x]] = x # key 为单词,value 为索引
return data2、分词结果的处理 在构建好字典以后,我们需要对分词结果进行分类,找出句子中的情感词、否定词和程度副词等等,便于后续计算情感极性分值。
for word in word_dict.keys():
if word in sen_dict.keys() and word not in not_word_list and word not in degree_dic.keys():
# 找出分词结果中在情感字典中的词
sen_word[word_dict[word]] = sen_dict[word]
elif word in not_word_list and word not in degree_dic.keys():
# 分词结果中在否定词列表中的词
not_word[word_dict[word]] = -1
elif word in degree_dic.keys():
# 分词结果中在程度副词中的词
degree_word[word_dict[word]] = degree_dic[word]3、计算得分 首先设置初始权重 W 为1,从第一个情感词开始,用权重 W*该情感词的情感值作为得分(用 score 记录),然后判断与下一个情感词之间是否有程度副词及否定词,如果有否定词将W*-1,如果有程度副词,W*程度副词的程度值,此时的 W 作为遍历下一个情感词的权重值,循环直到遍历完所有的情感词,每次遍历过程中的得分 score 加起来的总和就是这篇文档的情感得分。
def socre_sentiment(sen_word, not_word, degree_word, seg_result):
"""计算得分"""
# 权重初始化为1
W = 1
score = 0
# 情感词下标初始化
sentiment_index = -1
# 情感词的位置下标集合
sentiment_index_list = list(sen_word.keys())
# 遍历分词结果(遍历分词结果是为了定位两个情感词之间的程度副词和否定词)
for i in range(0, len(seg_result)):
# 如果是情感词(根据下标是否在情感词分类结果中判断)
if i in sen_word.keys():
# 权重*情感词得分
score += W * float(sen_word[i])
# 情感词下标加1,获取下一个情感词的位置
sentiment_index += 1
if sentiment_index < len(sentiment_index_list) - 1:
# 判断当前的情感词与下一个情感词之间是否有程度副词或否定词
for j in range(sentiment_index_list[sentiment_index], sentiment_index_list[sentiment_index + 1]):
# 更新权重,如果有否定词,取反
if j in not_word.keys():
W *= -1
elif j in degree_word.keys():
# 更新权重,如果有程度副词,分值乘以程度副词的程度分值
W *= float(degree_word[j])
# 定位到下一个情感词
if sentiment_index < len(sentiment_index_list) - 1:
i = sentiment_index_list[sentiment_index + 1]
return score编程要求
在右侧编辑器中的 Begin-End 之间补充 Python 代码,完成基于情感词典对所输入文本进行情感分析,并输出情感分析结果。其中文本内容通过 input 从后台获取。
测试说明
平台将使用测试集运行你编写的程序代码,若全部的运行结果正确,则通关。
测试输入: 我喜欢和你一起玩
预期输出: Building prefix dict from the default dictionary ... Dumping model to file cache /tmp/jieba.cache Loading model cost 1.083 seconds. Prefix dict has been built successfully. # 分词过程的附件信息 情感分析值为:0.00919122712083
from collections import defaultdict
import jieba
import codecs
def seg_word(sentence): # 使用jieba对文档分词
seg_list = jieba.cut(sentence)
seg_result = []
for w in seg_list:
seg_result.append(w)
# 读取停用词文件
stopwords = set()
fr = codecs.open('./stopword.txt', 'r', 'utf-8')
for word in fr:
stopwords.add(word.strip())
fr.close()
# 去除停用词
return list(filter(lambda x: x not in stopwords, seg_result))
def classify_words(word_dict): # 词语分类,找出情感词、否定词、程度副词
# 读取情感字典文件
sen_file = open('./sentiment_score.txt', 'r+', encoding='utf-8')
# 获取字典文件内容
sen_list = sen_file.readlines()
# 创建情感字典
sen_dict = defaultdict()
# 读取字典文件每一行内容,将其转换为字典对象,key为情感词,value为对应的分值
for s in sen_list:
# 每一行内容根据空格分割,索引0是情感词,索引1是情感分值
sen_dict[s.split(' ')[0]] = s.split(' ')[1]
# 读取否定词文件
not_word_file = open('./notDic.txt', 'r+', encoding='utf-8')
# 由于否定词只有词,没有分值,使用list即可
not_word_list = not_word_file.readlines()
# 读取程度副词文件
degree_file = open('./degree.txt', 'r+', encoding='utf-8')
degree_list = degree_file.readlines()
degree_dic = defaultdict()
# 程度副词与情感词处理方式一样,转为程度副词字典对象,key为程度副词,value为对应的程度值
for d in degree_list:
degree_dic[d.split(',')[0]] = d.split(',')[1]
# 分类结果,词语的index作为key,词语的分值作为value,否定词分值设为-1
sen_word = dict()
not_word = dict()
degree_word = dict()
# 分类
for word in word_dict.keys():
if word in sen_dict.keys() and word not in not_word_list and word not in degree_dic.keys():
# 找出分词结果中在情感字典中的词
sen_word[word_dict[word]] = sen_dict[word]
elif word in not_word_list and word not in degree_dic.keys():
# 分词结果中在否定词列表中的词
not_word[word_dict[word]] = -1
elif word in degree_dic.keys():
# 分词结果中在程度副词中的词
degree_word[word_dict[word]] = degree_dic[word]
sen_file.close()
degree_file.close()
not_word_file.close()
# 将分类结果返回
return sen_word, not_word, degree_word
def list_to_dict(word_list):
data = {}
for x in range(0, len(word_list)):
data[word_list[x]] = x
return data
def get_init_weight(sen_word, not_word, degree_word):
# 权重初始化为1
W = 1
# 将情感字典的key转为list
sen_word_index_list = list(sen_word.keys())
if len(sen_word_index_list) == 0:
return W
# 获取第一个情感词的下标,遍历从0到此位置之间的所有词,找出程度词和否定词
for i in range(0, sen_word_index_list[0]):
if i in not_word.keys():
W *= -1
elif i in degree_word.keys():
# 更新权重,如果有程度副词,分值乘以程度副词的程度分值
W *= float(degree_word[i])
return W
def socre_sentiment(sen_word, not_word, degree_word, seg_result): # 计算得分
# 权重初始化为1
W = 1
score = 0
# 情感词下标初始化
sentiment_index = -1
# 情感词的位置下标集合
sentiment_index_list = list(sen_word.keys())
# 任务:完成基于情感词典对情感得分的计算
# ********** Begin *********#
for i in range(0, len(seg_result)):
# 如果是情感词(根据下标是否在情感词分类结果中判断)
if i in sen_word.keys():
# 权重*情感词得分
score += W * float(sen_word[i])
# 情感词下标加1,获取下一个情感词的位置
sentiment_index += 1
if sentiment_index < len(sentiment_index_list) - 1:
# 判断当前的情感词与下一个情感词之间是否有程度副词或否定词
for j in range(sentiment_index_list[sentiment_index], sentiment_index_list[sentiment_index + 1]):
# 更新权重,如果有否定词,取反
if j in not_word.keys():
W *= -1
elif j in degree_word.keys():
# 更新权重,如果有程度副词,分值乘以程度副词的程度分值
W *= float(degree_word[j])
# 定位到下一个情感词
if sentiment_index < len(sentiment_index_list) - 1:
i = sentiment_index_list[sentiment_index + 1]
# ********** End **********#
return score
def setiment_score(sententce):
# 1.对文档分词
seg_list = seg_word(sententce)
# 2.将分词结果列表转为dic,然后找出情感词、否定词、程度副词
sen_word, not_word, degree_word = classify_words(list_to_dict(seg_list))
# 3.计算得分
score = socre_sentiment(sen_word, not_word, degree_word, seg_list)
return score第3关:基于 SnowNLP 的情感分析实战
情感分析方法
情感分析即对带有主观色彩的文本进行正向、负向、中性等感情色彩进行确定的方法。情感分析的一般步骤为:输入大量真实的评论文本,通过情感分析对每条评论进行正向负向中性判断,再进行统计分析,从而得出作品的好评度。
目前主流的情感分析方法有:基于情感词典的情感分析、基于机器学习的情感分析。

图 1
1、基于情感词典的情感分析 情感词典法,即基于情感词,否定词、副词等大量词库,利用相关计算公式对每条评论进行打分,最后基于得分判断评论的褒贬性。得分为正即为正向评论,如果是负分则是负向评论,0是中性评论。其中情感词、程度词、否定词来自于情感词库,其权重的确定由具体所使用的的模型来确定。算法步骤如图2所示。

图 2 基于情感词典的情感分析
需要注意的是,根据算法对计算出的得分进行的判断,不一定是真实的结果。为了使得判断结果更可信,常常可以通过人工标注对大量评论进行真实准确地判断,再对比算法判断和人工标注的判断来检验算法的准确性。词典匹配的情感分析语料适用范围更广,但受限于语义表达的丰富性。
2、基于机器学习的情感分析 情感分析本质上是一个二分类的问题,通过采用机器学习的方法识别,选取文本中的情感词作为特征词,将文本矩阵化,利用逻辑回归,朴素贝叶斯,支持向量机等方法进行分类。最终分类效果取决于训练文本的选择以及正确的情感标注。算法逻辑如图3所示。

图 3 基于机器学习的情感分析
认识 SnowNLP
SnowNLP 是一个基于 python 的自然语言处理库,可以方便地处理中文文本内容,处理英文内容的包主要有 TextBlob , SnowNLP 则是受 TextBlob 的影响而开发的,和 TextBlob 不同的是,它并没有使用用 NLTK ,所有的算法都是自己实现的,并且自带了一些训练好的字典。
在我们进行自然语言处理的实际开发中,SnowNLP 是一个很好的工具。SnowNLP 的功能有很多,如中文分词、词性标注、文本分类、情感分析等等。SnowNLP 在实际应用的过程中,我们需要先根据文本创建一个 SnowNLP 对象,再使用对应的方法进行想要的操作。
示例:对文本进行分词
from snownlp import SnowNLPs = SnowNLP(u'这个东西真心很赞') # 对文本进行分词print(s.words)
输出结果: ['这个', '东西', '真心', '很', '赞']
基于 SnowNLP 进行情感分析
SnowNLP 库中的已经训练好的情感分析模型是基于商品的评论数据而得出的,因此,在实际使用的过程中,需要根据自己的情况,重新训练模型。在使用 SnowNLP 进行情感分析时,会得到一个返回值,返回值代表的是文本为正面情绪的概率,越接近1表示正面情绪,越接近0表示负面情绪。
示例:文本情感分析
from snownlp import SnowNLPs = SnowNLP(u"今天我很快乐。你怎么样呀?"); # 对文本进行情感分析print("[sentiments]",s.sentiments);
输出结果: [sentiments] 0.971889316039116
在实际的项目中,可以根据需要对实际的数据重新训练情感分析的模型,训练步骤大致分为如下的几个步骤:
-
准备正负样本,并分别保存;
-
利用 SnowNLP 训练新的模型;
-
保存好新的模型以供情感分析。
编程要求
在右侧编辑器中的 Begin-End 之间补充 Python 代码,完成基于 SnowNLP 对所输入文本进行情感分析,并输出情感分析结果。其中文本内容通过 input 从后台获取。
测试说明
平台将使用测试集运行你编写的程序代码,若全部的运行结果正确,则通关。
测试输入: 今天很欢乐
预期输出: 积极情绪
from snownlp import SnowNLP
def Analysis():
text = input()
result=0
# 任务:使用 SnowNLP 模块,对 text文本进行情感分析,将分析结果保存到result变量中
# ********** Begin *********#
s=SnowNLP(text)
result=s.sentiments
# ********** End **********#
return result



![【PWN · ret2libc | protobuf】[2024CISCN · 华中赛区]protoverflow](https://i-blog.csdnimg.cn/direct/a6a9f832a7644da8b1038372bd962faa.png)