强化学习笔记
主要基于b站西湖大学赵世钰老师的【强化学习的数学原理】课程,个人觉得赵老师的课件深入浅出,很适合入门.
第一章 强化学习基本概念
第二章 贝尔曼方程
第三章 贝尔曼最优方程
第四章 值迭代和策略迭代
第五章 强化学习实例分析:GridWorld
第六章 蒙特卡洛方法
第七章 Robbins-Monro算法
第八章 多臂老虎机
第九章 强化学习实例分析:CartPole
第十章 时序差分法
第十一章 值函数近似【DQN】
文章目录
- 强化学习笔记
- 一、状态值函数近似
- 二、动作值函数的近似
- 1 Deep Q-learning
- 三、参考资料
在前面介绍的方法中,我们的 v ( s ) v(s) v(s)、 q ( s , a ) q(s,a) q(s,a)都是用如下表格形式来呈现的:
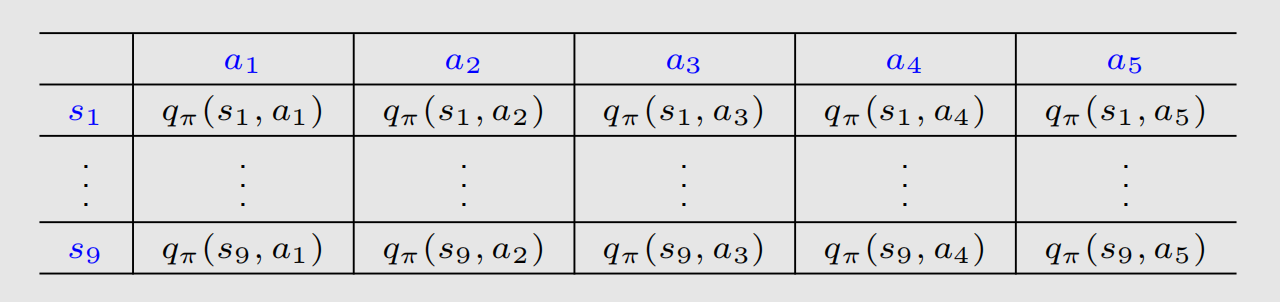
这对于 s , a s,a s,a是离散且有限的时候是可行的,如果 s , a s,a s,a连续或者 ∣ A ∣ , ∣ S ∣ |\mathcal{A}|,|\mathcal{S}| ∣A∣,∣S∣很大,前面介绍的算法,比如值迭代和策略迭代或者时序差分法就会面临两个问题:
- 计算过程需要的内存急剧上升;
- 泛化能力一般.
这时候我们引入一类新的方法——值函数估计,顾名思义, v ( s ) v(s) v(s)是 s s s的函数, q ( s , a ) q(s,a) q(s,a)是 s 、 a s、a s、a的函数,所以我们要得到这两个函数,可以用一些机器学习的方法,比如常见的曲线拟合的方法,还可以结合深度学习的方法来进行对 v ( s ) , q ( s , a ) v(s),q(s,a) v(s),q(s,a)的估计。
一、状态值函数近似
首先我们介绍比较经典的线性方法,近似值函数
v
^
(
⋅
,
w
)
\hat{v}(\cdot,\mathbf{w})
v^(⋅,w)是权向量
w
w
w的线性函数。对应于每个状态
s
s
s,有一个实值向量
x
(
s
)
≐
(
x
1
(
s
)
,
x
2
(
s
)
,
…
,
x
d
(
s
)
)
\mathbf{x}(s)\doteq(x_1(s),x_2(s),\ldots,x_d(s))
x(s)≐(x1(s),x2(s),…,xd(s)),与
w
w
w具有相同的维数。线性方法通过
w
w
w与
x
(
s
)
\mathbf{x}(s)
x(s)的内积来近似状态值函数:
v
^
(
s
,
w
)
≐
w
⊤
x
(
s
)
≐
∑
i
=
1
d
w
i
x
i
(
s
)
.
(
1
)
\hat{v}(s,\mathbf{w})\doteq\mathbf{w}^\top\mathbf{x}(s)\doteq\sum_{i=1}^dw_ix_i(s).\qquad(1)
v^(s,w)≐w⊤x(s)≐i=1∑dwixi(s).(1)
其中
x
(
s
)
x(s)
x(s)是状态
s
s
s的特征向量,这里介绍一种常见的多项式构造方法,更多的特征向量构造方法可以见参考文献2的9.5小节。假设
s
s
s是二维的,那么一个可能的构造为
x
(
s
)
=
(
1
,
s
1
,
s
2
,
s
1
s
2
)
∈
R
4
x(s)=(1,s_1,s_2,s_1s_2)\in\mathbb{R}^4
x(s)=(1,s1,s2,s1s2)∈R4,这就得到一个4维的特征向量,同理可以构造其他格式的多项式特征向量。
现在我们有了近似状态值函数的形式,那么如何估计(1)中的参数
w
w
w呢?这就用到机器学习里常用的方法——随机梯度下降。假设真实状态值函数为
v
π
(
s
)
v_{\pi}(s)
vπ(s),那么我们可以定义一个平方误差:
J
(
w
)
=
E
[
(
v
π
(
s
)
−
v
^
(
s
,
w
)
)
2
]
(
2
)
J(w)=\mathbb{E}[(v_{\pi}(s)-\hat{v}(s,\mathbf{w}))^2]\qquad(2)
J(w)=E[(vπ(s)−v^(s,w))2](2)
这里的期望是对
s
∈
S
s\in\mathcal{S}
s∈S求的,一个常见的假设是所有
s
s
s均匀分布,那么可以得到:
J
(
w
)
=
1
∣
S
∣
∑
s
(
v
π
(
s
)
−
v
^
(
s
,
w
)
)
2
J(w)=\frac{1}{|\mathcal{S}|}\sum_s(v_{\pi}(s)-\hat{v}(s,\mathbf{w}))^2
J(w)=∣S∣1s∑(vπ(s)−v^(s,w))2
为了估计
w
w
w,我们的目标是最小化
J
(
w
)
J(w)
J(w),由梯度下降法可得:
w
k
+
1
=
w
k
−
α
k
∇
w
J
(
w
k
)
w_{k+1}=w_k-\alpha_k\nabla_wJ(w_k)
wk+1=wk−αk∇wJ(wk)
由(2)式推导梯度如下:
∇
w
J
(
w
)
=
∇
w
E
[
(
v
π
(
s
)
−
v
^
(
s
,
w
)
)
2
]
=
E
[
∇
w
(
v
π
(
s
)
−
v
^
(
s
,
w
)
)
2
]
=
2
E
[
(
v
π
(
s
)
−
v
^
(
s
,
w
)
)
(
−
∇
w
v
^
(
s
,
w
)
)
]
=
−
2
E
[
(
v
π
(
s
)
−
v
^
(
s
,
w
)
)
∇
w
v
^
(
s
,
w
)
]
\begin{aligned} \nabla_wJ(w)&= \nabla_w\mathbb{E}[(v_\pi(s)-\hat{v}(s,w))^2] \\ &=\mathbb{E}[\nabla_w(v_\pi(s)-\hat{v}(s,w))^2] \\ &=2\mathbb{E}[(v_\pi(s)-\hat{v}(s,w))(-\nabla_w\hat{v}(s,w))] \\ &=-2\mathbb{E}[(v_\pi(s)-\hat{v}(s,w))\nabla_w\hat{v}(s,w)] \\ \end{aligned}
∇wJ(w)=∇wE[(vπ(s)−v^(s,w))2]=E[∇w(vπ(s)−v^(s,w))2]=2E[(vπ(s)−v^(s,w))(−∇wv^(s,w))]=−2E[(vπ(s)−v^(s,w))∇wv^(s,w)]但这样计算梯度需要对所有
s
s
s求期望,不实用,所以采用随机梯度下降的方式,任取一个样本:
w
t
+
1
=
w
t
+
α
t
(
v
π
(
s
t
)
−
v
^
(
s
t
,
w
t
)
)
∇
w
v
^
(
s
t
,
w
t
)
,
(
3
)
w_{t+1}=w_t+\alpha_t(v_\pi(s_t)-\hat v(s_t,w_t))\nabla_w\hat v(s_t,w_t),\qquad(3)
wt+1=wt+αt(vπ(st)−v^(st,wt))∇wv^(st,wt),(3)其中
s
t
∈
S
s_t\in\mathcal{S}
st∈S,但是这个迭代格式还有一个问题,我们需要知道真实的
v
π
(
s
)
v_{\pi}(s)
vπ(s),显然我们是不知道的,并且我们要估计的就是这个
v
π
(
s
)
v_{\pi}(s)
vπ(s),那么我们用一个近似值来替代迭代格式中的
v
π
(
s
)
v_{\pi}(s)
vπ(s),有如下两种方法:
- 基于蒙特卡洛学习的状态值函数逼近
假设 g t g_t gt为某个episode里的从 s t s_t st开始的累积折扣回报。那么我们可以用 g t g_t gt来近似 v π ( s t ) v_\pi(s_t) vπ(st). 迭代格式(3)算法变为
w t + 1 = w t + α t ( g t − v ^ ( s t , w t ) ) ∇ w v ^ ( s t , w t ) . w_{t+1}=w_t+\alpha_t(g_t-\hat{v}(s_t,w_t))\nabla_w\hat{v}(s_t,w_t). wt+1=wt+αt(gt−v^(st,wt))∇wv^(st,wt). - 基于TD学习的状态值函数逼近
结合TD学习方法,将 r t + 1 + γ v ^ ( s t + 1 , w t ) r_{t+1}+\gamma\hat{v}(s_{t+1},w_t) rt+1+γv^(st+1,wt)视为对 v π ( s t ) v_\pi(s_{t}) vπ(st). 的一种近似。因此,迭代格式(3)可表示为
w t + 1 = w t + α t [ r t + 1 + γ v ^ ( s t + 1 , w t ) − v ^ ( s t , w t ) ] ∇ w v ^ ( s t , w t ) . ( 4 ) w_{t+1}=w_ t + \alpha _ t [ r_ { t + 1 } + \gamma \hat { v } ( s_ { t + 1 }, w_ t ) - \hat { v } ( s_ t, w_ t ) ] \nabla _ w \hat { v } ( s_ t, w_ t ).\qquad(4) wt+1=wt+αt[rt+1+γv^(st+1,wt)−v^(st,wt)]∇wv^(st,wt).(4)
二、动作值函数的近似
上面(4)给出了结合TD learning来求 v ^ ( s , w ) \hat{v}(s,w) v^(s,w)的迭代格式,显然我们可以把 ( 4 ) (4) (4)改成SARSA或者Q-learning就能得到基于TD学习的动作值函数逼近的迭代格式,此处不再赘述,详情参考强化学习:时序差分法.下面来介绍深度强化学习里面的一个经典的模型——Deep Q-learning,也叫Deep Q-Network(DQN).
1 Deep Q-learning
DQN方法旨在最小化如下的目标函数:
J
(
w
)
=
E
[
(
R
+
γ
max
a
∈
A
(
S
′
)
q
^
(
S
′
,
a
,
w
)
−
q
^
(
S
,
A
,
w
)
)
2
]
,
J(w)=\mathbb{E}\left[\left(R+\gamma\max_{a\in\mathcal{A}(S')}\hat{q}(S',a,w)-\hat{q}(S,A,w)\right)^2\right],
J(w)=E[(R+γa∈A(S′)maxq^(S′,a,w)−q^(S,A,w))2],
参数
w
w
w出现在两个地方,求导不好求,所以DQN的一个核心思想是:采用两个网络来分别近似
q
^
(
S
′
,
a
,
w
)
\hat{q}(S',a,w)
q^(S′,a,w)和
q
^
(
S
,
A
,
w
)
\hat{q}(S,A,w)
q^(S,A,w),在更新参数时,先把
q
^
(
S
′
,
a
,
w
)
\hat{q}(S',a,w)
q^(S′,a,w)看做固定值,那么
J
(
w
)
J(w)
J(w)就只有一个地方有
w
w
w求导就相对容易,可以利用梯度下降对近似
q
^
(
S
,
A
,
w
)
\hat{q}(S,A,w)
q^(S,A,w)网络的参数进行更新。那么如何对近似
q
^
(
S
′
,
a
,
w
)
\hat{q}(S',a,w)
q^(S′,a,w)目标网络的参数进行更新呢?DQN提出可以设置一个参数
C
C
C,每迭代
C
C
C次,我们将
q
^
(
S
,
A
,
w
)
\hat{q}(S,A,w)
q^(S,A,w)网络的参数复制给target network,这样进行交替更新,最终可以得到一个近似动作值函数。
同时,提出DQN模型的论文还开创性的提出经验回放的技巧,简单来说就是将采样得到的数据 ( S , A , R , S ′ ) (S,A,R,S') (S,A,R,S′)放入一个经验缓冲区 D D D,训练神经网络时就用 D D D里面的数据进行训练,这样做的好处是可以去除观测序列中的相关性并对数据分布的变化进行平滑。
下面是DQN算法的伪代码:

自从DQN的提出,研究人员对其进行了多种改进,如Double DQN、Dueling DQN和Prioritized Experience Replay等,这些改进进一步提升了DQN的性能和稳定性。DQN的提出是深度强化学习领域的重要里程碑,它展示了深度学习在强化学习中的巨大潜力,并为后续研究奠定了基础。
学习了DQN的理论知识后,具体如何实现参考我的这篇文章:基于强化学习DQN的股票预测【DQN的Python实践】.通过具体的代码,我们可以更加深入的理解DQN模型的构造以及实现细节.
三、参考资料
- Zhao, S… Mathematical Foundations of Reinforcement Learning. Springer Nature Press and Tsinghua University Press.
- Sutton, Richard S., and Andrew G. Barto. Reinforcement learning: An introduction. MIT press, 2018.
- Mnih, V., Kavukcuoglu, K.(2015). Human-level control through deep reinforcement learning. Nature, 518(7540), 529-533.





![World of Warcraft [CLASSIC] plugin lua](https://i-blog.csdnimg.cn/direct/46cfe32d8f1a4ccdb0c7af0aa2c6c479.png)