《linux私房菜》这本书中将sed和awk一同归为行的修改这一点,虽然对,但不利于实际处理问题时的思考。因为这样的话,当我们实际处理问题时,遇到比如说统计文本打印内容时,我们选择sed还是awk进行处理呢?
也因此
grep更适合单纯的查找或匹配文本,sed更适合编辑匹配到的文本,awk更适合格式化文本,对文本进行较复杂格式处理。
这样的思路更便于我们处理问题时的思路。
比如我们的变量应用文本,需要根据环境进行编辑时,这时候使用sed来编辑脚本便是我们第一时间能想到的了。
awk
awk命令正如上面所说,可以格式化文本
体现就在于它的分隔符上,默认是空格。
修改方式有两种
awk -F":" aa.txt
awk '{FS=":"}' aa.txt
第二种会导致第一行不适用,需要在BEGIN中编写,因此直接用第一种。
awk根据分隔符可以将行内容分为多段,每段按照从左到右的顺序,用$1,$2, $3…来输出。$0输出整行。
基础使用可以输出指定列
比如说这个问题
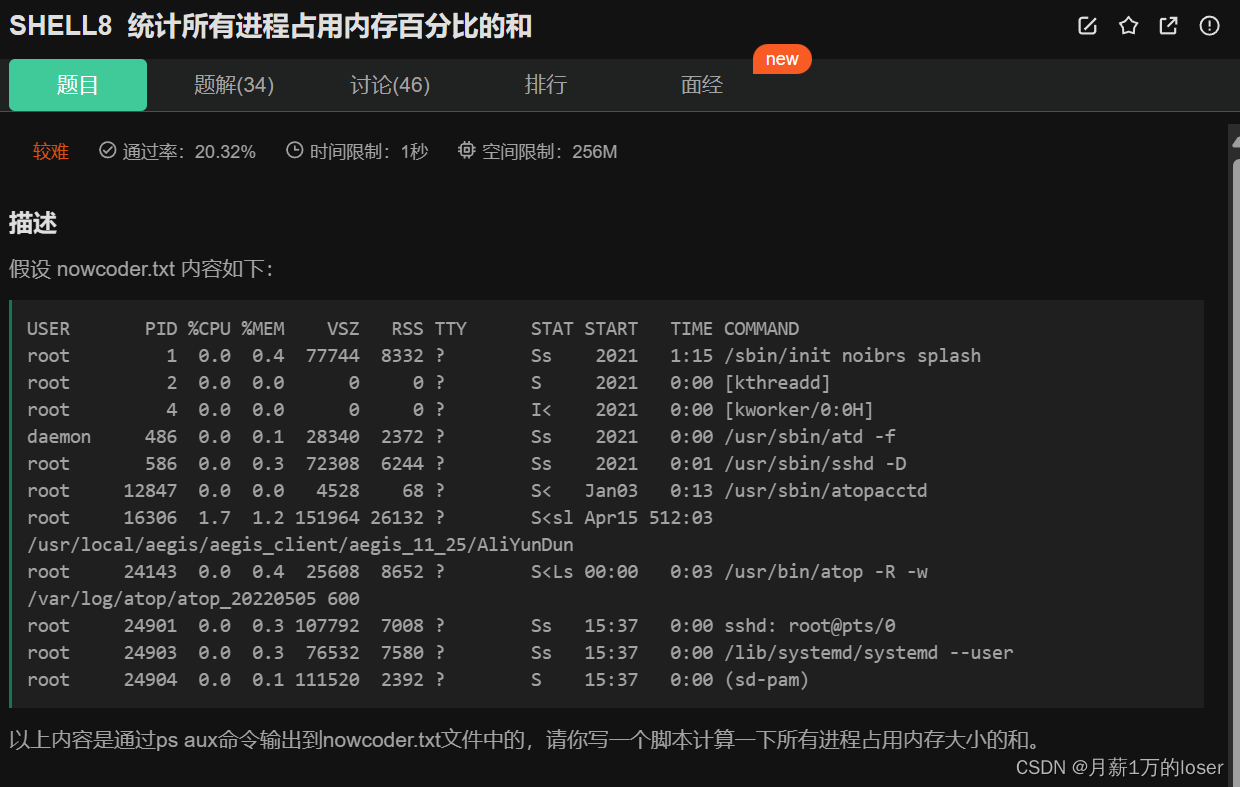
计算内存和。
a=0
b=$(cat nowcoder.txt|sed '1d'|awk -F" " '{print $4}')
echo $b
for i in $b
do
a=$(echo "$a+$i"|bc)
done
echo $a
此外awk的内容是可以包含三部分的,除了必须的逐行处理的内容,还可以包含BEGIN和END的内容。BEGIN表示逐行处理前,END表示逐行处理结束后。
也即如下
awk 'BEGIN{FS=":"} {print $3} END{print "aaa"}' aaa.txt
aaa.txt如下
a:b:c
输出如下

END可以获取到在逐行处理中的变量,下面有示例可以看到。
awk功能光如此也不足道,强的地方还在于它的逻辑处理。
我们可以在文本内部写java语法的循环判断,而不用遵守shell的循环判断语法格式
如下面这个问题,
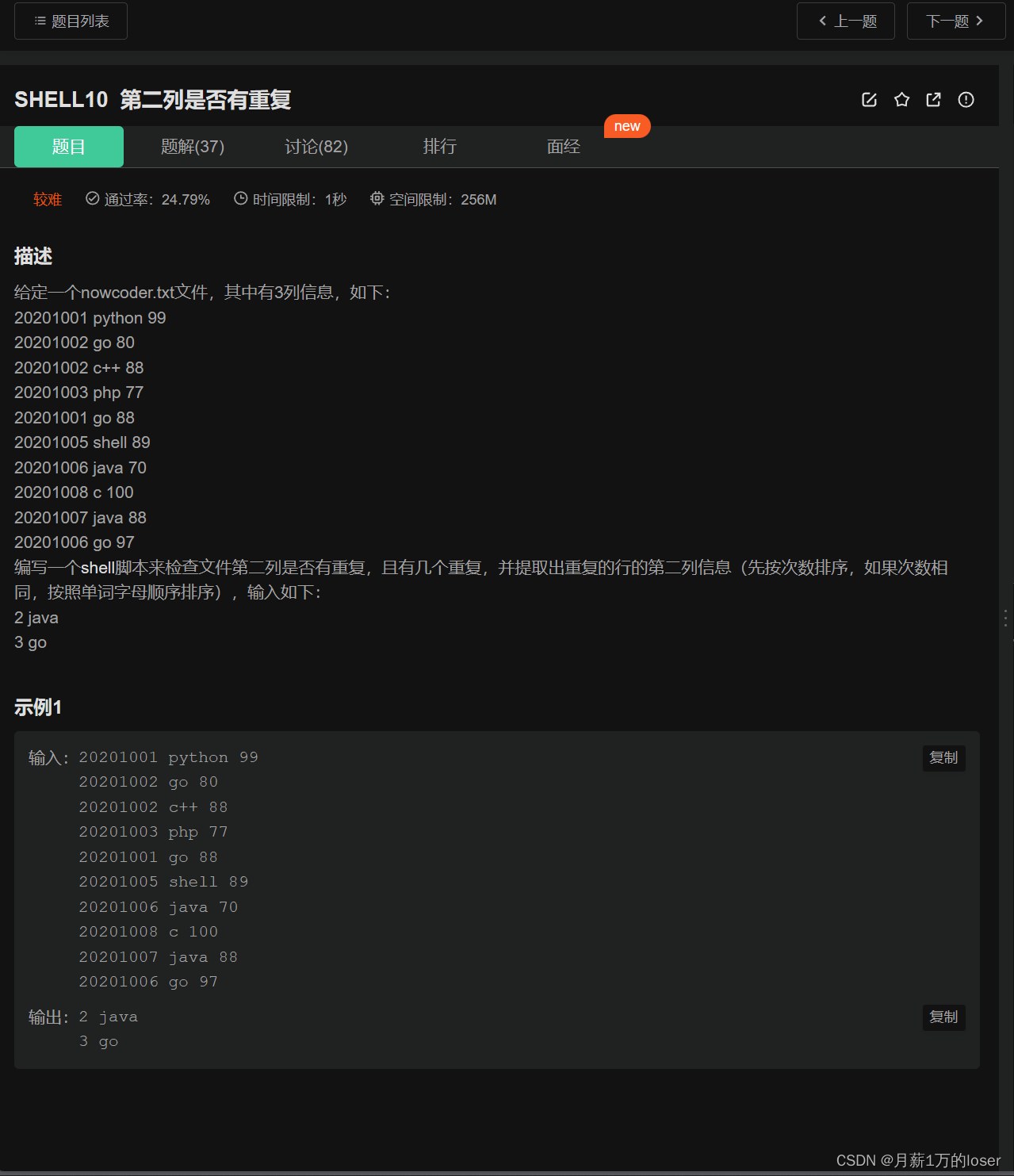
awk '{num[$2] += 1} END{for(a in num) if(num[a] >= 2) print num[a] a}' nowcoder.txt|sort -n
#除了内部循环以外也使用了一维数组。shell中变量在赋值时就会完成初始化,这种东西见仁见智吧,我不觉得有啥好用的。
shell的变量没有定义都是字符串,自然数组的指针也能是字符串。
可以看到,awk确实可以进行相对复杂的格式化处理。








![[数据集][目标检测]电力场景下电柜箱门把手检测数据集VOC+YOLO格式1167张1类别](https://img-blog.csdnimg.cn/direct/885fddbf0d7d4e6aa6cdb24587d695b9.png)