Java web应用性能分析之【java进程问题分析概叙】-CSDN博客
Java web应用性能分析之【java进程问题分析工具】-CSDN博客
Java web应用性能分析之【jvisualvm远程连接云服务器】-CSDN博客
Java web应用性能分析之【java进程问题分析定位】-CSDN博客
Java web应用性能分析之【系统监控工具prometheus】-CSDN博客
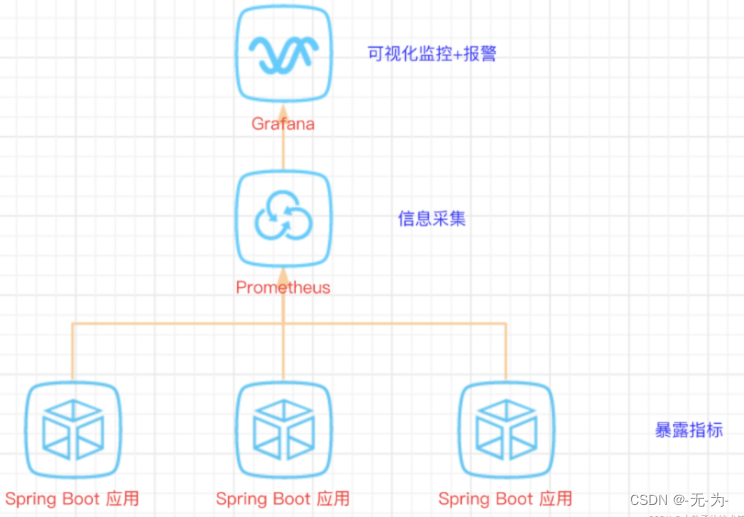
Java web应用性能分析之【prometheus+Grafana监控springboot服务和服务器监控】-CSDN博客 关于prometheus的详细使用,参考这里:【30天精通Prometheus:一站式监控实战指南】第1天:深入探索Prometheus:30天一站式监控实战指南的开篇之旅-CSDN博客
https://www.cnblogs.com/lizexiong/p/15578427.html
1.1 Exporter的来源
从Exporter的来源上来讲,主要分为两类:
- 社区提供的
Prometheus社区提供了丰富的Exporter实现,涵盖了从基础设施,中间件以及网络等各个方面的监控功能。这些Exporter可以实现大部分通用的监控需求。下表列举一些社区中常用的Exporter:
| 范围 | 常用Exporter |
| 数据库 | MySQL Exporter, Redis Exporter, MongoDB Exporter, MSSQL Exporter等 |
| 硬件 | Apcupsd Exporter,IoT Edison Exporter, IPMI Exporter, Node Exporter等 |
| 消息队列 | Beanstalkd Exporter, Kafka Exporter, NSQ Exporter, RabbitMQ Exporter等 |
| 存储 | Ceph Exporter, Gluster Exporter, HDFS Exporter, ScaleIO Exporter等 |
| HTTP服务 | Apache Exporter, HAProxy Exporter, Nginx Exporter等 |
| API服务 | AWS ECS Exporter, Docker Cloud Exporter, Docker Hub Exporter, GitHub Exporter等 |
| 日志 | Fluentd Exporter, Grok Exporter等 |
| 监控系统 | Collectd Exporter, Graphite Exporter, InfluxDB Exporter, Nagios Exporter, SNMP Exporter等 |
| 其它 | Blockbox Exporter, JIRA Exporter, Jenkins Exporter, Confluence Exporter等 |
- 用户自定义的
除了直接使用社区提供的Exporter程序以外,用户还可以基于Prometheus提供的Client Library创建自己的Exporter程序,目前Promthues社区官方提供了对以下编程语言的支持:Go、Java/Scala、Python、Ruby。同时还有第三方实现的如:Bash、C++、Common Lisp、Erlang,、Haskeel、Lua、Node.js、PHP、Rust等。
1.2 Exporter的运行方式
从Exporter的运行方式上来讲,又可以分为:
独立使用的
以我们已经使用过的Node Exporter为例,由于操作系统本身并不直接支持Prometheus,同时用户也无法通过直接从操作系统层面上提供对Prometheus的支持。因此,用户只能通过独立运行一个程序的方式,通过操作系统提供的相关接口,将系统的运行状态数据转换为可供Prometheus读取的监控数据。 除了Node Exporter以外,比如MySQL Exporter、Redis Exporter等都是通过这种方式实现的。 这些Exporter程序扮演了一个中间代理人的角色。
集成到应用中的
为了能够更好的监控系统的内部运行状态,有些开源项目如Kubernetes,ETCD等直接在代码中使用了Prometheus的Client Library,提供了对Prometheus的直接支持。这种方式打破的监控的界限,让应用程序可以直接将内部的运行状态暴露给Prometheus,适合于一些需要更多自定义监控指标需求的项目。
1.3 Exporter规范
所有的Exporter程序都需要按照Prometheus的规范,返回监控的样本数据。以Node Exporter为例,当访问/metrics地址时会返回以下内容:
# HELP node_cpu Seconds the cpus spent in each mode.
# TYPE node_cpu counter
node_cpu{cpu="cpu0",mode="idle"} 362812.7890625
# HELP node_load1 1m load average.
# TYPE node_load1 gauge
node_load1 3.0703125
这是一种基于文本的格式规范,在Prometheus 2.0之前的版本还支持Protocol buffer规范。相比于Protocol buffer文本具有更好的可读性,以及跨平台性。Prometheus 2.0的版本也已经不再支持Protocol buffer,这里就不对Protocol buffer规范做详细的阐述。
Exporter返回的样本数据,主要由三个部分组成:样本的一般注释信息(HELP),样本的类型注释信息(TYPE)和样本。Prometheus会对Exporter响应的内容逐行解析:
如果当前行以# HELP开始,Prometheus将会按照以下规则对内容进行解析,得到当前的指标名称以及相应的说明信息:
# HELP <metrics_name> <doc_string>
如果当前行以# TYPE开始,Prometheus会按照以下规则对内容进行解析,得到当前的指标名称以及指标类型:
# TYPE <metrics_name> <metrics_type>
TYPE注释行必须出现在指标的第一个样本之前。如果没有明确的指标类型需要返回为untyped。 除了# 开头的所有行都会被视为是监控样本数据。 每一行样本需要满足以下格式规范:
metric_name [
"{" label_name "=" `"` label_value `"` { "," label_name "=" `"` label_value `"` } [ "," ] "}"
] value [ timestamp ]
其中metric_name和label_name必须遵循PromQL的格式规范要求。value是一个float格式的数据,timestamp的类型为int64(从1970-01-01 00:00:00以来的毫秒数),timestamp为可选默认为当前时间。具有相同metric_name的样本必须按照一个组的形式排列,并且每一行必须是唯一的指标名称和标签键值对组合。
需要特别注意的是对于histogram和summary类型的样本。需要按照以下约定返回样本数据:
- 类型为summary或者histogram的指标x,该指标所有样本的值的总和需要使用一个单独的x_sum指标表示。
- 类型为summary或者histogram的指标x,该指标所有样本的总数需要使用一个单独的x_count指标表示。
- 对于类型为summary的指标x,其不同分位数quantile所代表的样本,需要使用单独的x{quantile="y"}表示。
- 对于类型histogram的指标x为了表示其样本的分布情况,每一个分布需要使用x_bucket{le="y"}表示,其中y为当前分布的上位数。同时必须包含一个样本x_bucket{le="+Inf"},并且其样本值必须和x_count相同。
- 对于histogram和summary的样本,必须按照分位数quantile和分布le的值的递增顺序排序。
以下是类型为histogram和summary的样本输出示例:
# A histogram, which has a pretty complex representation in the text format:
# HELP http_request_duration_seconds A histogram of the request duration.
# TYPE http_request_duration_seconds histogram
http_request_duration_seconds_bucket{le="0.05"} 24054
http_request_duration_seconds_bucket{le="0.1"} 33444
http_request_duration_seconds_bucket{le="0.2"} 100392
http_request_duration_seconds_bucket{le="+Inf"} 144320
http_request_duration_seconds_sum 53423
http_request_duration_seconds_count 144320
# Finally a summary, which has a complex representation, too:
# HELP rpc_duration_seconds A summary of the RPC duration in seconds.
# TYPE rpc_duration_seconds summary
rpc_duration_seconds{quantile="0.01"} 3102
rpc_duration_seconds{quantile="0.05"} 3272
rpc_duration_seconds{quantile="0.5"} 4773
rpc_duration_seconds_sum 1.7560473e+07
rpc_duration_seconds_count 2693
对于某些Prometheus还没有提供支持的编程语言,用户只需要按照以上规范返回响应的文本数据即可。
1.4 指定样本格式的版本
在Exporter响应的HTTP头信息中,可以通过Content-Type指定特定的规范版本,例如:
HTTP/1.1 200 OK Content-Encoding: gzip Content-Length: 2906 Content-Type: text/plain; version=0.0.4 Date: Sat, 17 Mar 2018 08:47:06 GMT
其中version用于指定Text-based的格式版本,当没有指定版本的时候,默认使用最新格式规范的版本。同时HTTP响应头还需要指定压缩格式为gzip。
自定义Prometheus监控指标
如果想开发一些通用型的监控指标,比如监控某一类方法或某一类接口的调用总次数,则通常的做法就是采用“过滤器”、“拦截器”或者“AOP”这样具备拦截功能的方法去实现。但我的建议是,如果不是万不得已,我不太推荐使用“过滤器”去做这样的事情,因为我认为它太过底层或者说太重了,而且在过滤器中,我们也不太方便去利用上层框架中已经封装好的一些内置对象;所以如果你想开发Http接口的监控指标,则建议你使用拦截器去做;如果你想开发方法的监控指标,那么则建议你使用AOP去做【只是个人理解,方法不唯一】
自定义监控步骤
实现Prometheus自定义监控的整个流程,首先,我们安装和配置了Prometheus,然后在应用程序中创建并暴露了自定义指标,最后配置Prometheus来监控这些自定义指标。
具体步骤和代码示例将在下文进行详细说明:
-
创建自定义指标:在被监控的应用程序中,使用Prometheus客户端库(如Prometheus Java Client或Prometheus Go Client)来定义和暴露自定义指标。这些客户端库提供了一些基本的指标类型,如Counter、Gauge和Histogram,可以根据应用程序的需求选择合适的指标类型。
-
暴露自定义指标和配置Prometheus监控自定义指标:为了让Prometheus能够抓取我们的自定义指标,我们需要在应用程序中暴露一个接口供Prometheus访问。在Prometheus服务器的配置文件(prometheus.yml)中,添加一个新的job配置来告诉Prometheus从应用程序中收集自定义指标。在该配置中,需要指定应用程序的地址和端口,以便Prometheus能够访问到应用程序的指标。至此才将指标真正暴露出来。
-
重启Prometheus服务器,使其加载新的配置。
-
自定义指标展示:在Prometheus的Web界面中,可以通过查询语言(PromQL)来查询和可视化自定义指标。例如,可以使用PromQL的sum()函数计算一个Counter类型的指标的总和,或者使用rate()函数计算一个Gauge类型的指标的速率。
需要注意的是,自定义指标的定义和暴露要符合Prometheus的数据模型和规范,以便Prometheus能够正确解析和处理这些指标。此外,还需要考虑指标的命名和标签的使用,以便更好地组织和管理指标数据。
自定义监控实操--springboot自定义监控
Java web应用性能分析之【prometheus+Grafana监控springboot服务和服务器监控】_grafana 导入 prometheus-CSDN博客
1.添加maven依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
2.开启监控端点:application.properties
#监控的端点
management.endpoints.web.exposure.include=*
#应用程序名称,在prometheus 上会显示
management.metrics.tags.application=${spring.application.name}
#tomcat 指标需要开启
server.tomcat.mbeanregistry.enabled=true
3.定义监控指标
@Service
@Slf4j
public class AccountServiceImpl implements IAccountService {
@Autowired
private MeterRegistry registry;
//入金笔数
private Counter depositCounter;
// 出金笔数
private Counter withdrawCounter;
//入金金额
private DistributionSummary depositAmountSummary;
// 出金金额
private DistributionSummary withdrawAmountSummary;
//余额
private BigDecimal balance = new BigDecimal(1000);
@PostConstruct
private void init() {
depositCounter = registry.counter("deposit_counter", "currency", "btc");
withdrawCounter = registry.counter("withdraw_counter", "currency", "btc");
depositAmountSummary = registry.summary("deposit_amount", "currency", "btc");
withdrawAmountSummary = registry.summary("withdraw_amount", "currency", "btc");
Gauge.builder("balanceGauge", () -> balance)
.tags("currency", "btc")
.description("余额")
.register(registry);
}
@Override
// 充值操作
public void depositOrder(BigDecimal amount) {
log.info("depositOrder amount:{}", amount);
try {
//余额增加
balance = balance.add(amount);
//充值笔数埋点
depositCounter.increment();
//充值金额埋点
depositAmountSummary.record(amount.doubleValue());
} catch (Exception e) {
log.info("depositOrder error", e);
} finally {
log.info("depositOrder result:{}", amount);
}
}
@Override
//提现操作
public void withdrawOrder(BigDecimal amount) {
log.info(" withdrawOrder amount:{}", amount);
try {
if (balance.subtract(amount).compareTo(BigDecimal.ZERO) < 0) {
throw new Exception("提现金额不足,提现失败");
}
//余额减少
balance = balance.subtract(amount);
// 提现笔数埋点数据
withdrawCounter.increment();
// 提现金额埋点
withdrawAmountSummary.record(amount.doubleValue());
} catch (Exception e) {
log.info("withdrawOrder error", e);
} finally {
log.info("withdrawOrder result:{}", amount);
}
}
}
4.定义监控指标:业务代码适配
在业务代码中埋点,这里就直接在controller中完成,一般都是在aop中操作,减少代码侵入。
@RestController
@RequestMapping(ControllerConstants.PATH_PREFIX + "/account")
public class AccountController {
@Autowired
IAccountService accountService;
/**
* 充值
*/
@RequestMapping(value = "/deposit", method = RequestMethod.GET)
public void deposit(@RequestParam("amount") BigDecimal amount) {
accountService.depositOrder(amount);
}
/**
* 提现
*/
@RequestMapping(value = "/withdraw", method = RequestMethod.GET)
public void withdraw(@RequestParam("amount") BigDecimal amount) {
accountService.withdrawOrder(amount);
}
}
5.暴露监控指标:
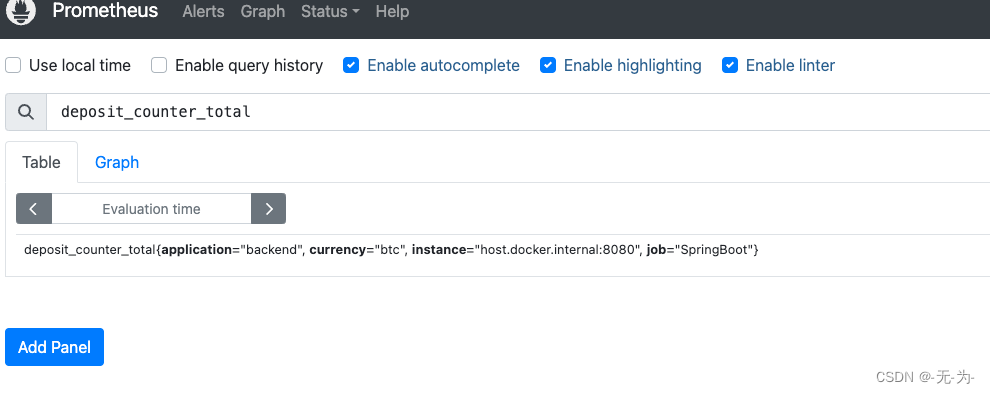
启动服务查看自定义指标;访问actuator/prometheus接口,如果能查询以下指标则配置成功
##充值笔数
deposit_counter_total
## 充值总金额
deposit_amount_sum
##提现笔数
withdraw_counter_total
##提现总金额
withdraw_amount_sum
## 余额
balanceGauge

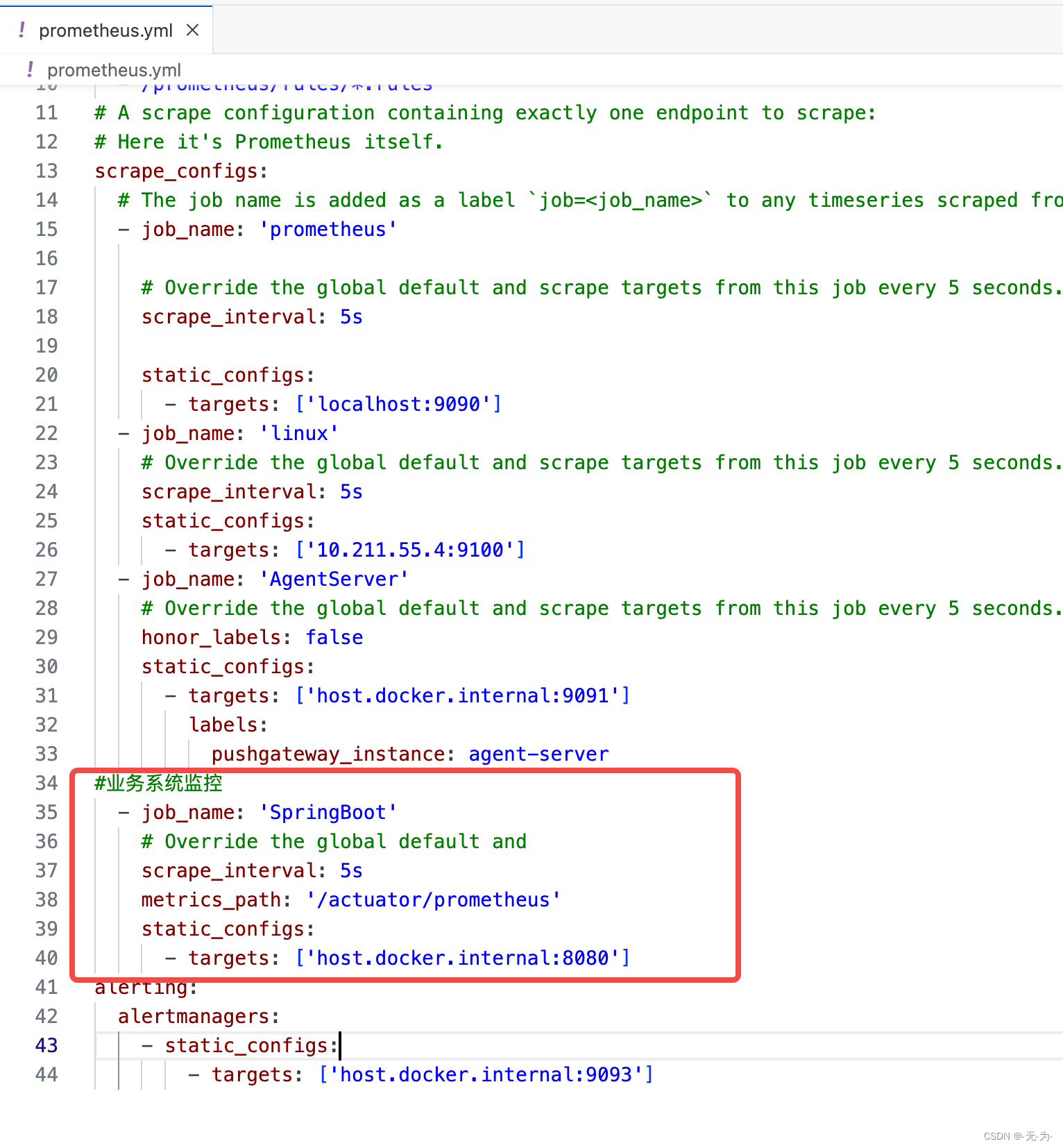
6.暴露监控指标和Prometheus server配置
配置业务系统采集点和采集频次
#业务系统监控
- job_name: 'SpringBoot'
# Override the global default and
scrape_interval: 5s
metrics_path: '/actuator/prometheus'
static_configs:
- targets: ['host.docker.internal:8080']
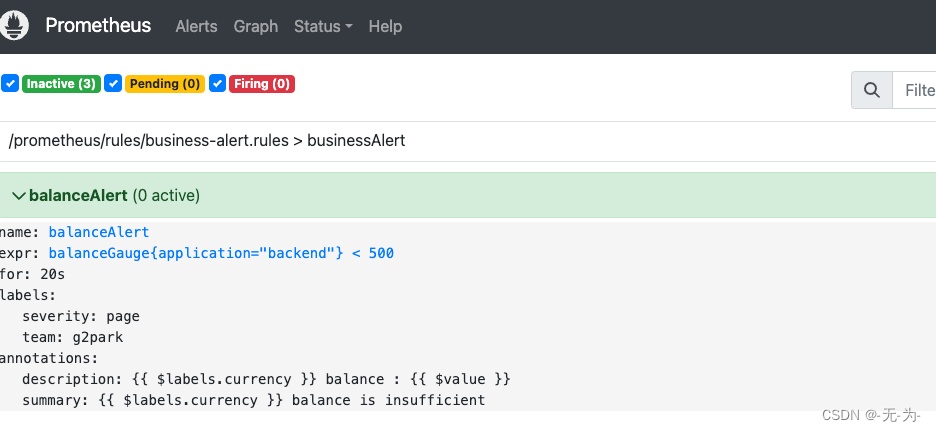
告警配置:告警规则配置,在容器启动时用主机的/data/prometheus目录映射到容器的/prometheus目录,因此在主机/data/prometheus/目录创建rules文件夹,并创建告警文件business-alert.rules,这里告警对余额小于 500 则进行告警
groups:
- name: businessAlert
rules:
- alert: balanceAlert
expr: balanceGauge{application="backend"} < 500
for: 20s
labels:
severity: page
team: g2park
annotations:
summary: "{{ $labels.currency }} balance is insufficient "
description: "{{ $labels.currency }} balance : {{ $value }}"
重启Prometheus server ,验证采集的监控指标
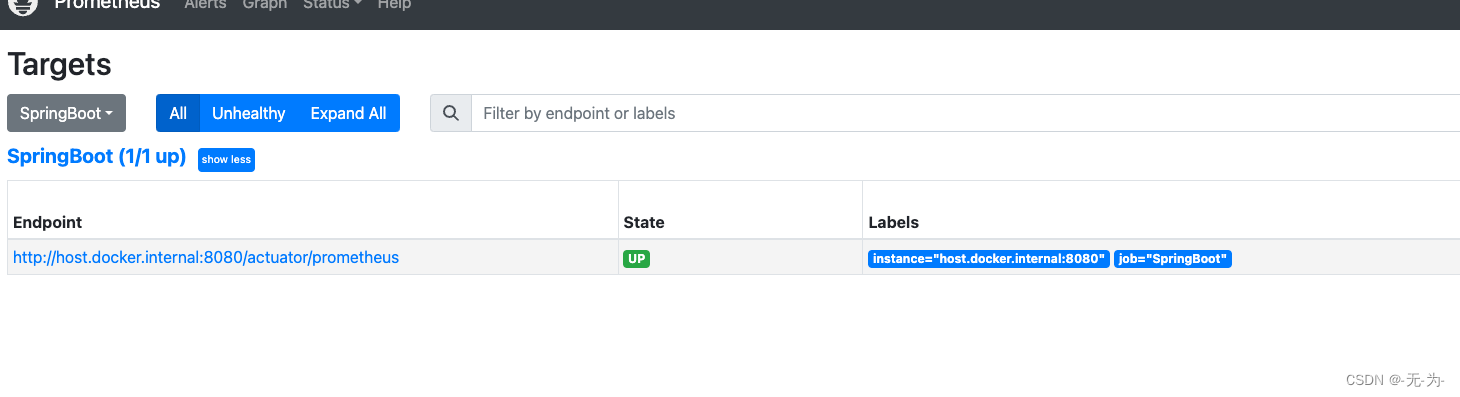
已生效
在SpringBoot中自定义指标并使用Prometheus监控报警_springboot prometheus 自定义-CSDN博客
7.grafana配置
启动 Grafana,点击新增面板,创建三种图表,分别为余额走势、提现与充值金额占比、提现与充值笔数走势图,如下
余额走势,报表类型为Stat
sum(balanceGauge{application="backend"})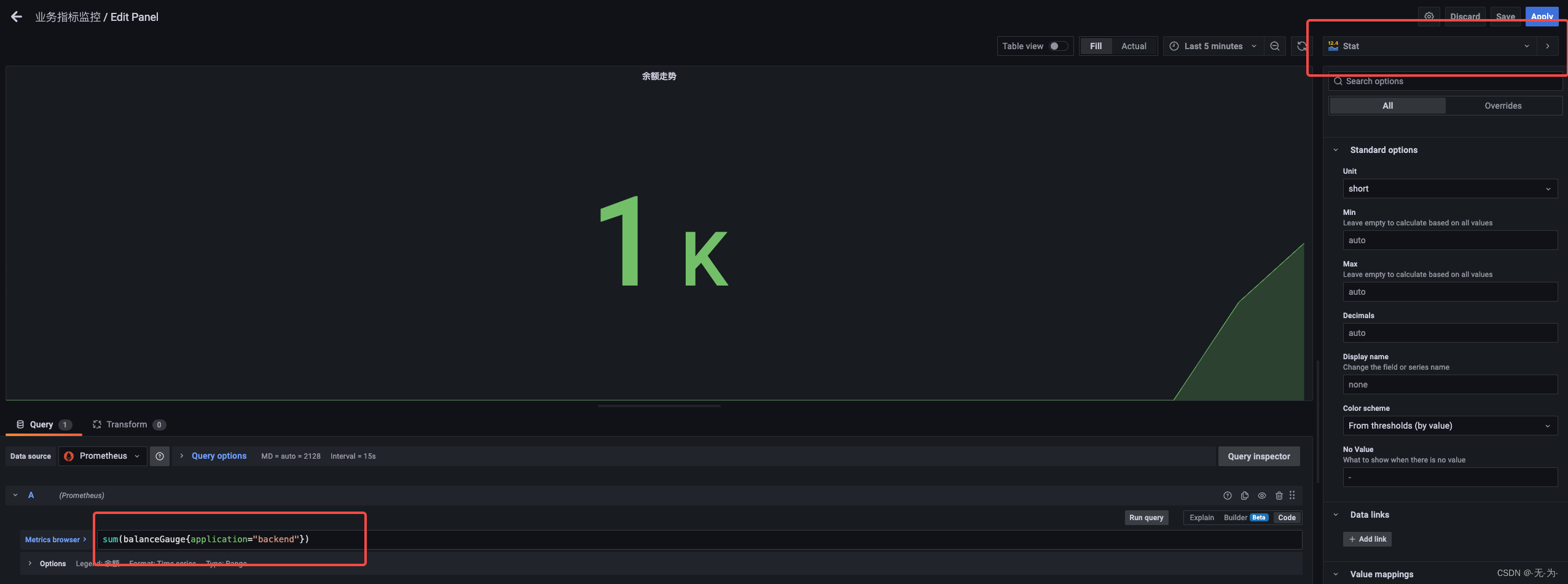
提现与充值金额占比,报表类型为Pie chart
withdraw_amount_sum{application="backend"}
deposit_amount_sum{application="backend"}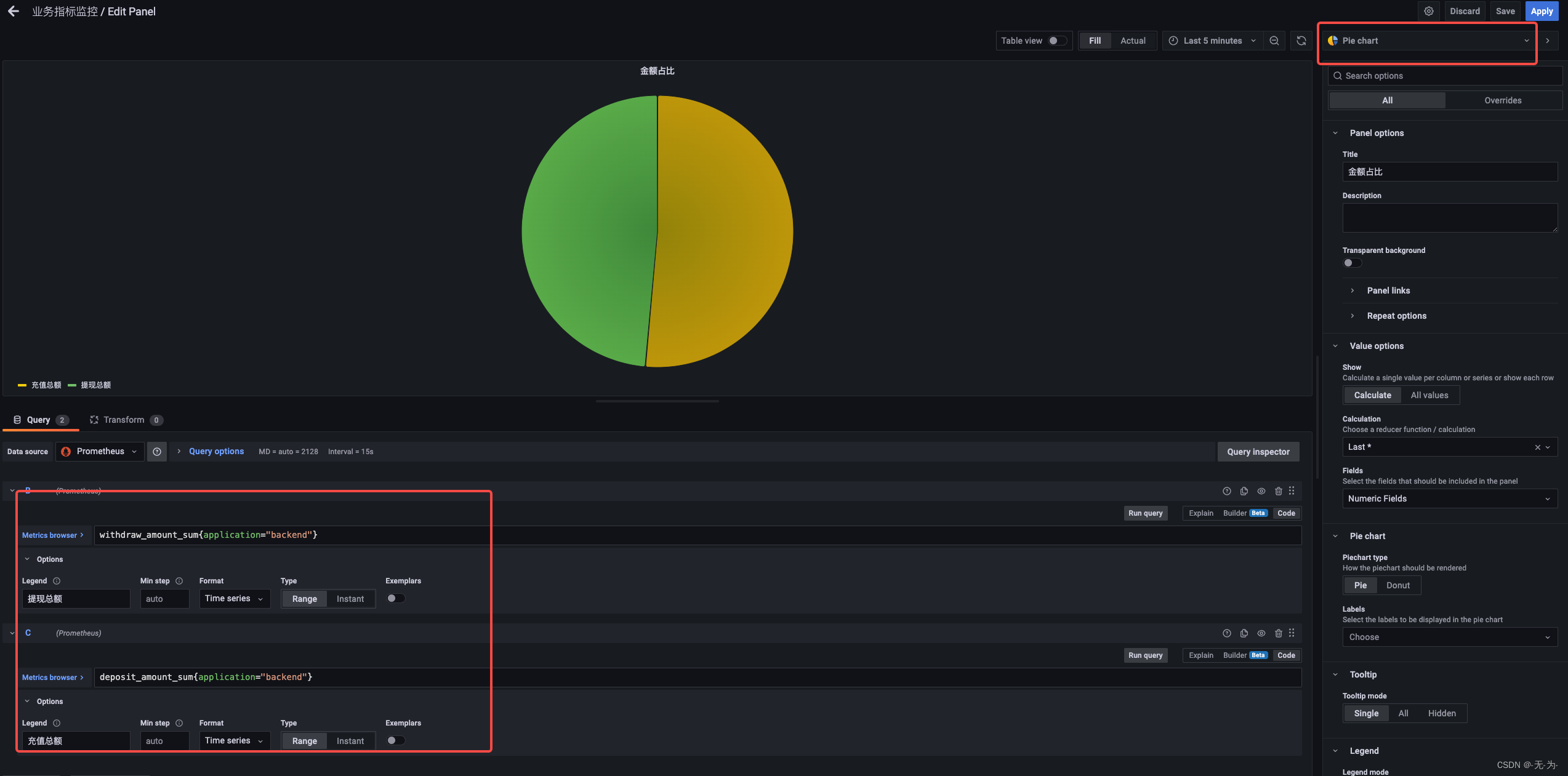
提现与充值笔数走势图,报表类型为Time series
increase(deposit_counter_total{application="backend"}[5m])
increase(withdraw_counter_total{application="backend"}[5m])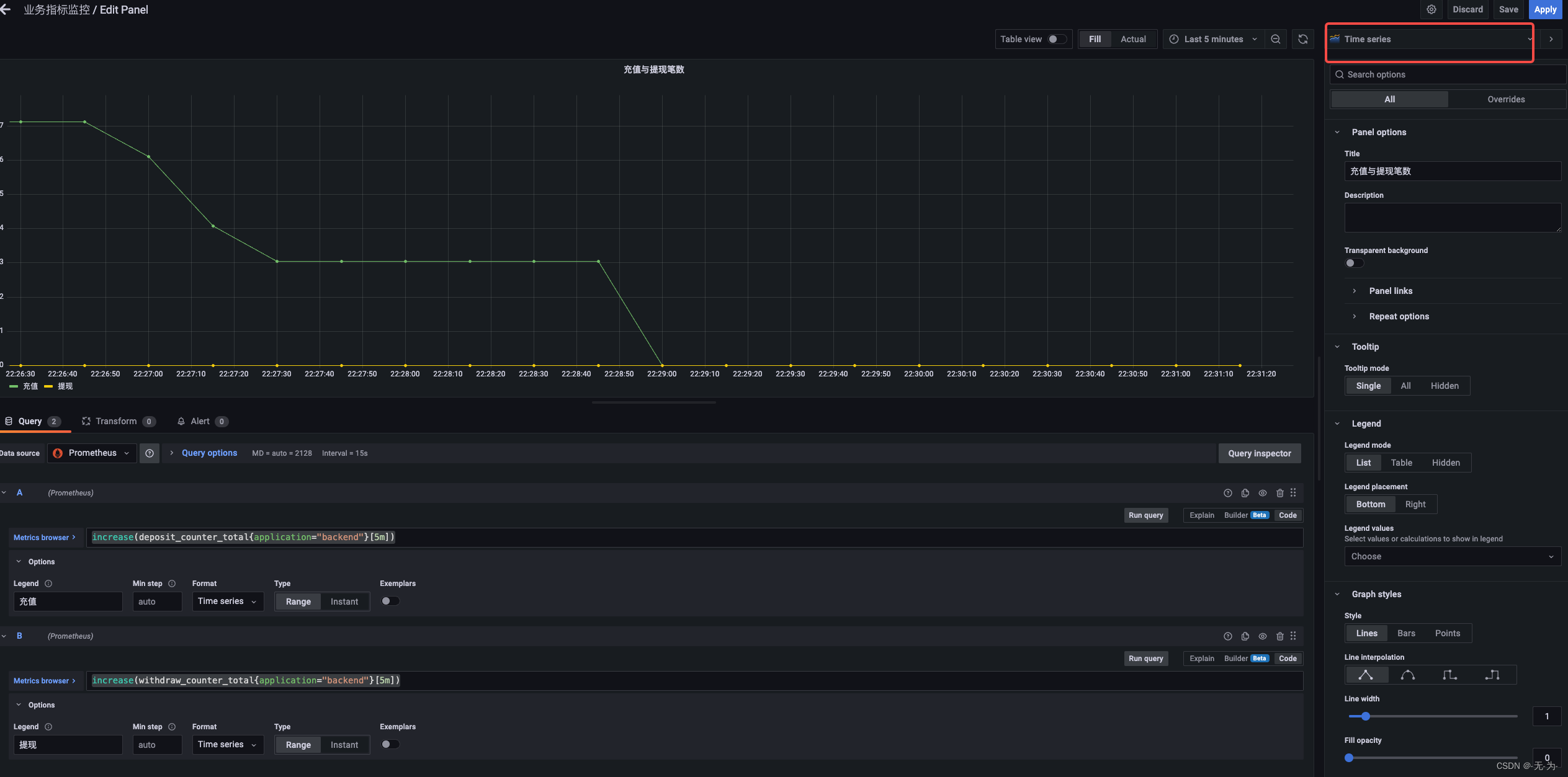
自定义容器监控:cAdvisor
后面还是会详细讲解cAdivisor,这里只是做一个简单介绍。
cAdvisor 是谷歌开源的一款通用的容器监控解决方案。cAdvisor 不仅可以采集机器上所有运行的容器信息,还提供了基础的查询界面和 HTTP 接口,更方便与外部系统结合。所以,cAdvisor很快成了容器指标监控最常用组件,并且 Kubernetes 也集成了 cAdvisor 作为容器监控指标的默认工具。
cAdvisor 的安装与使用
下面我们以 cAdvisor 0.37.0 版本为例,演示一下 cAdvisor 的安装与使用。
cAdvisor 官方提供了 Docker 镜像,我们只需要拉取镜像并且启动镜像即可。
由于 cAdvisor 镜像存放在谷歌的 gcr.io 镜像仓库中,国内无法访问到。这里我把打好的镜像放在了 Docker Hub。你可以使用 docker pull lagoudocker/cadvisor:v0.37.0 命令从 Docker Hub 拉取。
Docker是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linux/Windows/Mac机器上。容器镜像正成为一个新的标准化软件交付方式。
例如,可以通过以下命令快速在本地启动一个Nginx服务:
docker run -itd nginx
为了能够获取到Docker容器的运行状态,用户可以通过Docker的stats命令获取到当前主机上运行容器的统计信息,可以查看容器的CPU利用率、内存使用量、网络IO总量以及磁盘IO总量等信息。
$ docker stats CONTAINER CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS 9a1648bec3b2 0.30% 196KiB / 3.855GiB 0.00% 828B / 0B 827kB / 0B 1
除了使用命令以外,用户还可以通过Docker提供的HTTP API查看容器详细的监控统计信息。
2.1 使用CAdvisor
CAdvisor是Google开源的一款用于展示和分析容器运行状态的可视化工具。通过在主机上运行CAdvisor用户可以轻松的获取到当前主机上容器的运行统计信息,并以图表的形式向用户展示。
在本地运行CAdvisor也非常简单,直接运行一下命令即可:
docker run \ --volume=/:/rootfs:ro \ --volume=/var/run:/var/run:rw \ --volume=/sys:/sys:ro \ --volume=/var/lib/docker/:/var/lib/docker:ro \ --publish=8080:8080 \ --detach=true \ --name=cadvisor \ google/cadvisor:latest
通过访问http://localhost:8080可以查看,当前主机上容器的运行状态,如下所示:
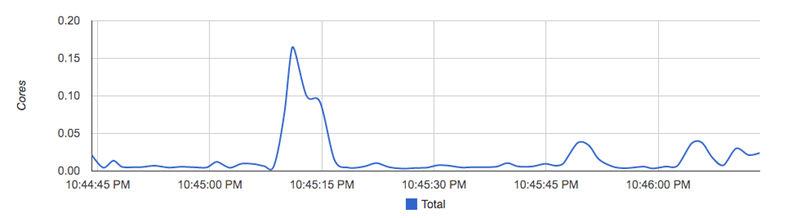
CAdvisor是一个简单易用的工具,相比于使用Docker命令行工具,用户不用再登录到服务器中即可以可视化图表的形式查看主机上所有容器的运行状态。
而在多主机的情况下,在所有节点上运行一个CAdvisor再通过各自的UI查看监控信息显然不太方便,同时CAdvisor默认只保存2分钟的监控数据。好消息是CAdvisor已经内置了对Prometheus的支持。访问http://localhost:8080/metrics即可获取到标准的Prometheus监控样本输出:
# HELP cadvisor_version_info A metric with a constant '1' value labeled by kernel version, OS version, docker version, cadvisor version & cadvisor revision.
# TYPE cadvisor_version_info gauge
cadvisor_version_info{cadvisorRevision="1e567c2",cadvisorVersion="v0.28.3",dockerVersion="17.09.1-ce",kernelVersion="4.9.49-moby",osVersion="Alpine Linux v3.4"} 1
# HELP container_cpu_load_average_10s Value of container cpu load average over the last 10 seconds.
# TYPE container_cpu_load_average_10s gauge
container_cpu_load_average_10s{container_label_maintainer="",id="/",image="",name=""} 0
container_cpu_load_average_10s{container_label_maintainer="",id="/docker",image="",name=""} 0
container_cpu_load_average_10s{container_label_maintainer="",id="/docker/15535a1e09b3a307b46d90400423d5b262ec84dc55b91ca9e7dd886f4f764ab3",image="busybox",name="lucid_shaw"} 0
container_cpu_load_average_10s{container_label_maintainer="",id="/docker/46750749b97bae47921d49dccdf9011b503e954312b8cffdec6268c249afa2dd",image="google/cadvisor:latest",name="cadvisor"} 0
container_cpu_load_average_10s{container_label_maintainer="NGINX Docker Maintainers <docker-maint@nginx.com>",id="/docker/f51fd4d4f410965d3a0fd7e9f3250218911c1505e12960fb6dd7b889e75fc114",image="nginx",name="confident_brattain"} 0
下面表格中列举了一些CAdvisor中获取到的典型监控指标:
| 指标名称 | 类型 | 含义 |
| container_cpu_load_average_10s | gauge | 过去10秒容器CPU的平均负载 |
| container_cpu_usage_seconds_total | counter | 容器在每个CPU内核上的累积占用时间 (单位:秒) |
| container_cpu_system_seconds_total | counter | System CPU累积占用时间(单位:秒) |
| container_cpu_user_seconds_total | counter | User CPU累积占用时间(单位:秒) |
| container_fs_usage_bytes | gauge | 容器中文件系统的使用量(单位:字节) |
| container_fs_limit_bytes | gauge | 容器可以使用的文件系统总量(单位:字节) |
| container_fs_reads_bytes_total | counter | 容器累积读取数据的总量(单位:字节) |
| container_fs_writes_bytes_total | counter | 容器累积写入数据的总量(单位:字节) |
| container_memory_max_usage_bytes | gauge | 容器的最大内存使用量(单位:字节) |
| container_memory_usage_bytes | gauge | 容器当前的内存使用量(单位:字节 |
| container_spec_memory_limit_bytes | gauge | 容器的内存使用量限制 |
| machine_memory_bytes | gauge | 当前主机的内存总量 |
| container_network_receive_bytes_total | counter | 容器网络累积接收数据总量(单位:字节) |
| container_network_transmit_bytes_total | counter | 容器网络累积传输数据总量(单位:字节) |
2.2 与Prometheus集成
修改/etc/prometheus/prometheus.yml,将cAdvisor添加监控数据采集任务目标当中:
- job_name: cadvisor
static_configs:
- targets:
- localhost:8080
启动Prometheus服务:
prometheus --config.file=/etc/prometheus/prometheus.yml --storage.tsdb.path=/data/prometheus
启动完成后,可以在Prometheus UI中查看到当前所有的Target状态:
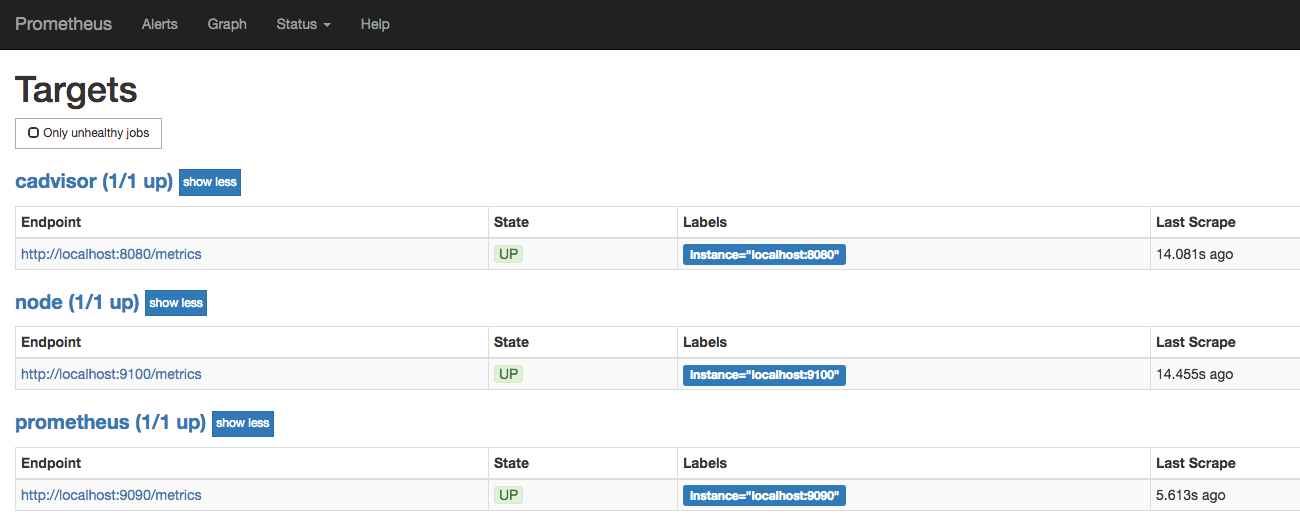
当能够正常采集到cAdvisor的样本数据后,可以通过以下表达式计算容器的CPU使用率:
sum(irate(container_cpu_usage_seconds_total{image!=""}[1m])) without (cpu)
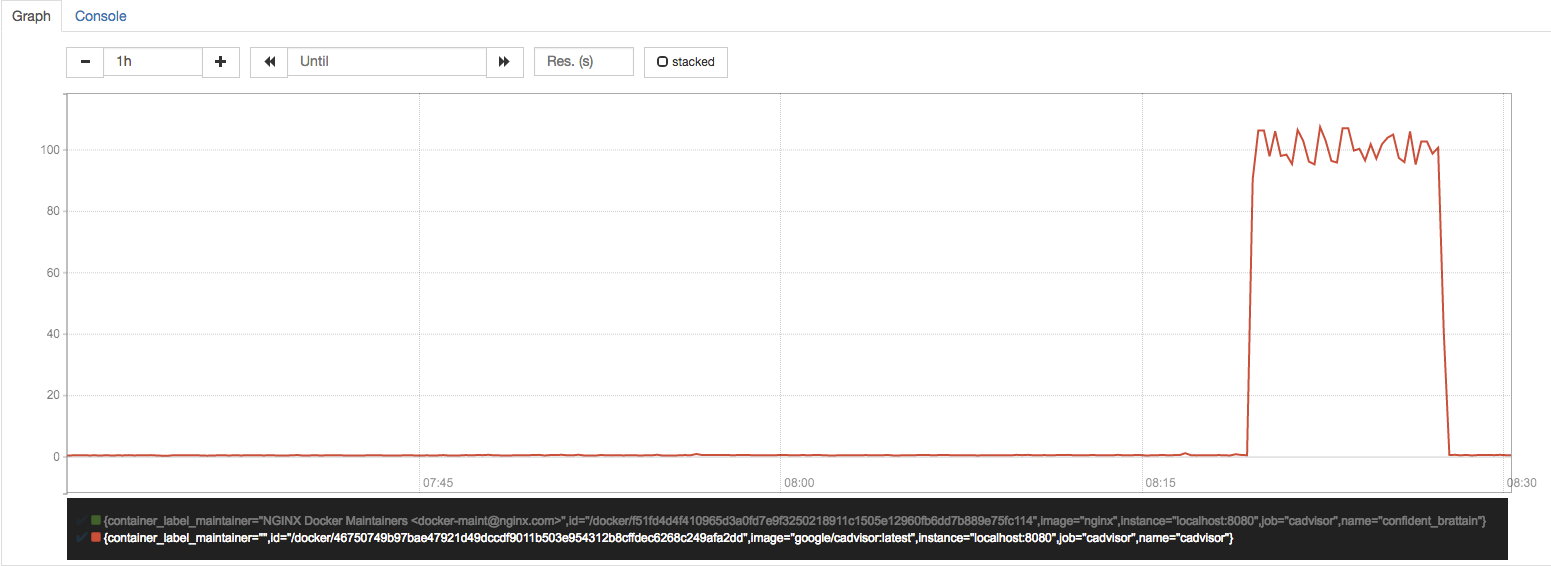
容器CPU使用率
查询容器内存使用量(单位:字节):
container_memory_usage_bytes{image!=""}
查询容器网络接收量速率(单位:字节/秒):
sum(rate(container_network_receive_bytes_total{image!=""}[1m])) without (interface)
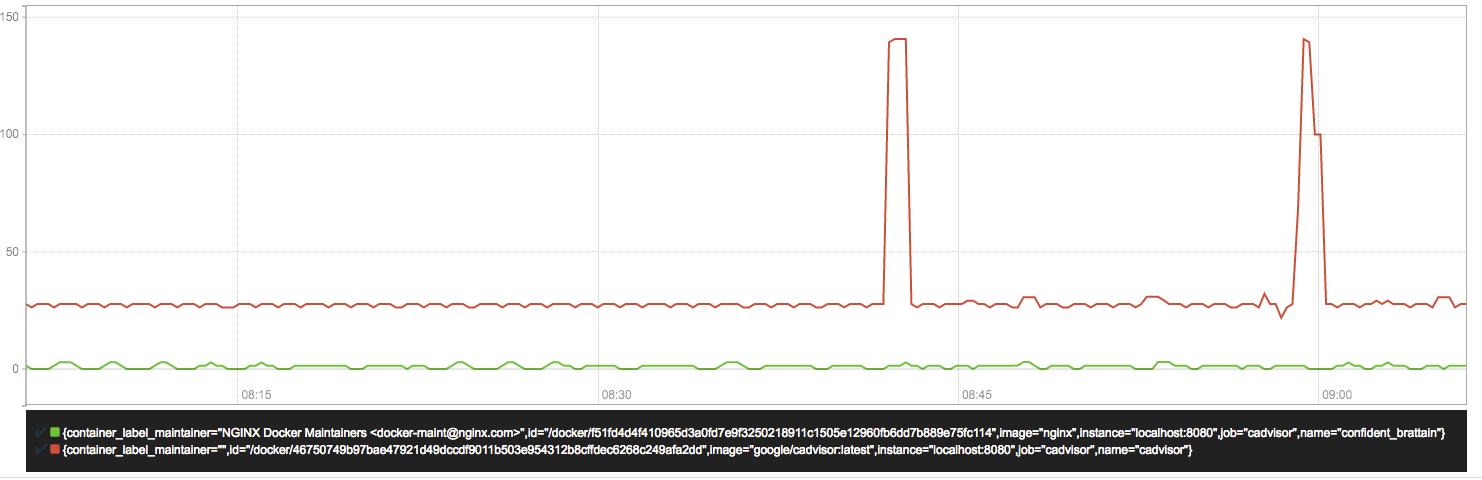
容器网络接收量字节/秒
查询容器网络传输量速率(单位:字节/秒):
sum(rate(container_network_transmit_bytes_total{image!=""}[1m])) without (interface)
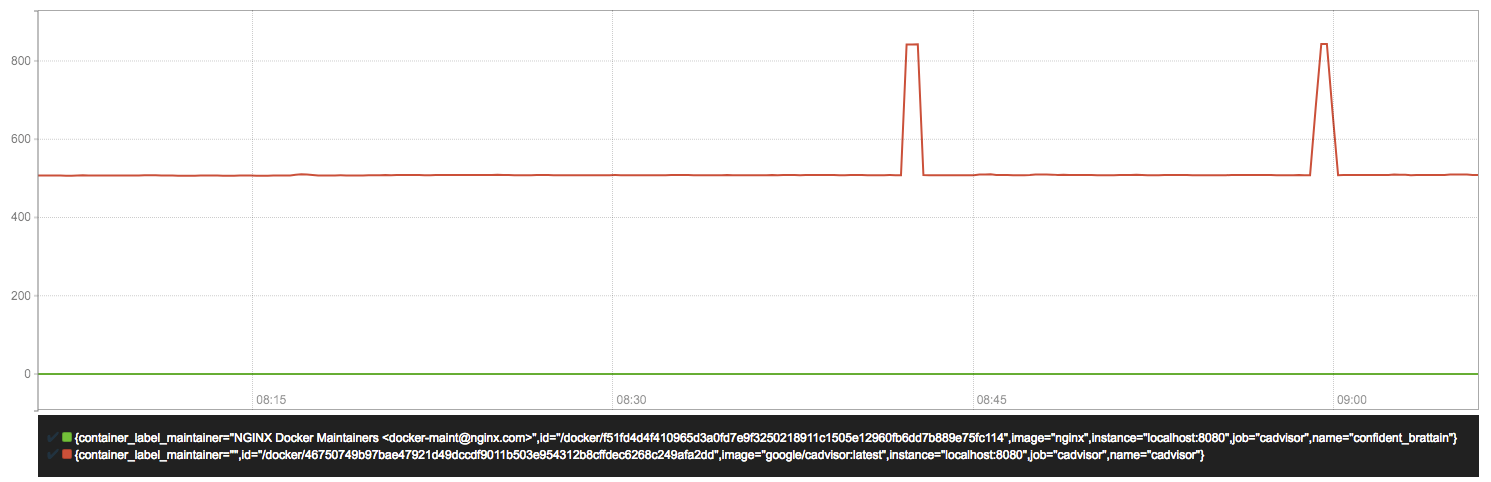
容器网络传输量 字节/秒
查询容器文件系统读取速率(单位:字节/秒):
sum(rate(container_fs_reads_bytes_total{image!=""}[1m])) without (device)
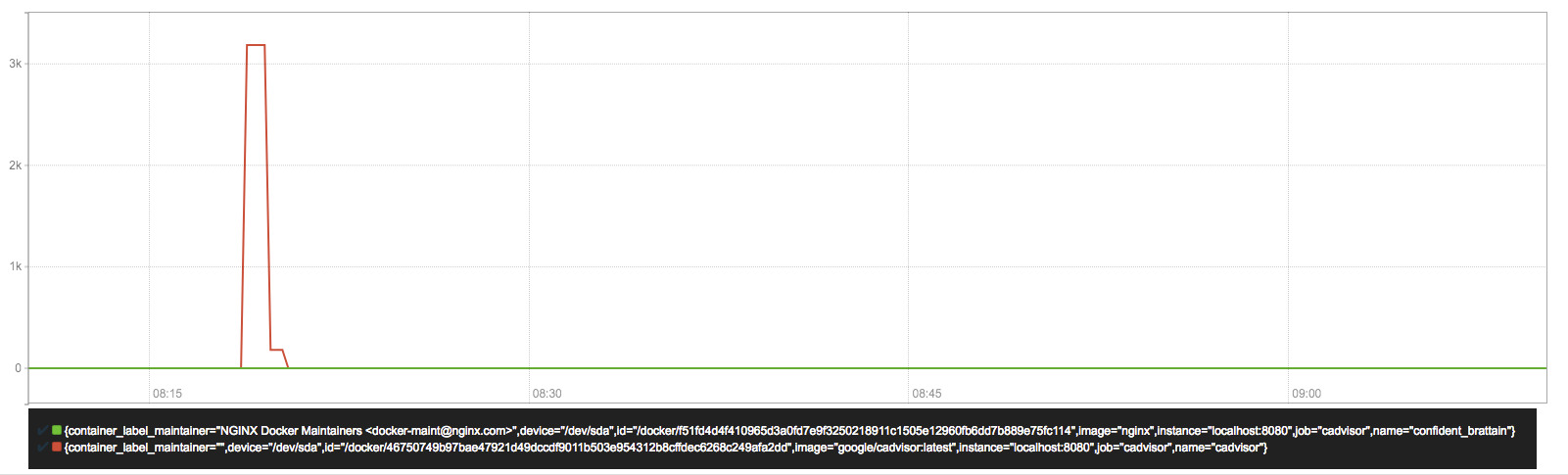
容器文件系统读取速率字节/秒
查询容器文件系统写入速率(单位:字节/秒):
sum(rate(container_fs_writes_bytes_total{image!=""}[1m])) without (device)
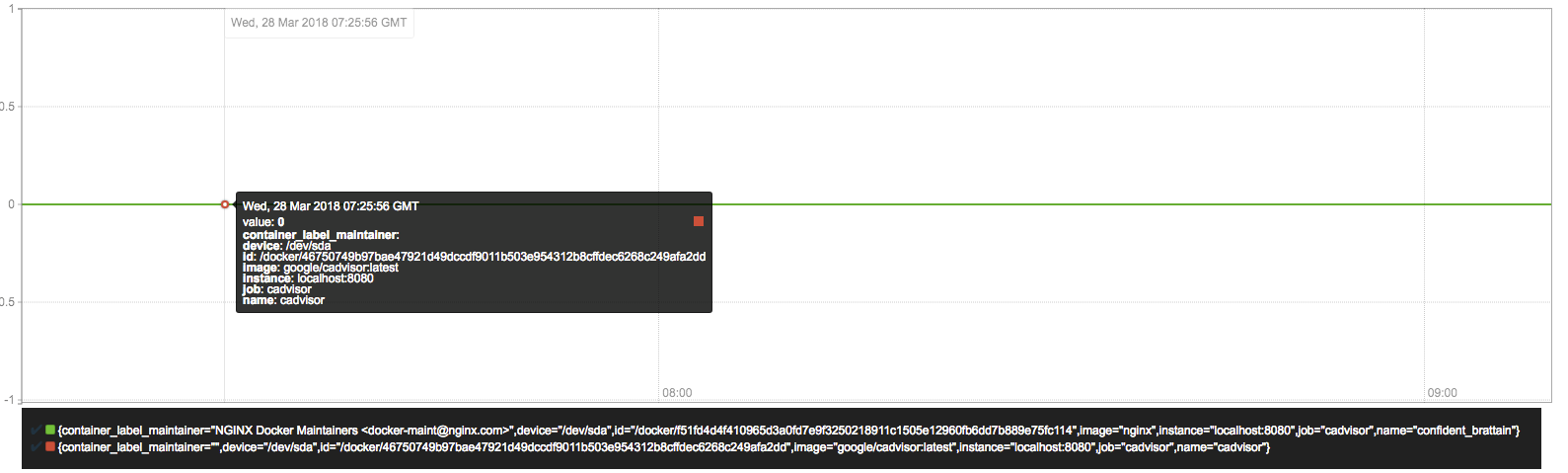
容器文件系统写入速率 字节/秒



![[数据集][目标检测]电力场景下电柜箱门把手检测数据集VOC+YOLO格式1167张1类别](https://img-blog.csdnimg.cn/direct/885fddbf0d7d4e6aa6cdb24587d695b9.png)