聚合查询的概念
- 聚合查询(Aggregation Queries)是Elasticsearch中用于数据汇总和分析的查询类型。
- 它不同于普通的查询,而是用于执行各种聚合操作,如计数、求和、平均值、最小值、最大值、分组等。
聚合查询的分类
分桶聚合(Bucket Aggregations)
-
类似于SQL中的GROUP BY操作,根据指定的条件对数据进行分组统计。
-
可以进行嵌套分桶,即在一个分桶的基础上再进行细分。
-
示例:按照手机的品牌进行分桶统计数量,再在小米手机的分桶基础上按照档次进行二次分桶。
-
语法格式
GET /index/_search
{
"size": 0,
"aggs": {
"aggregation_name": {
"bucket_type": {
"bucket_options": {
"bucket_option_name": "bucket_option_value",
...
},
"aggs": {
"sub_aggregation_name": {
"sub_aggregation_type": {
"sub_aggregation_options": {
"sub_aggregation_option_name": "sub_aggregation_option_value",
...
}
}
}
}
}
}
}
}
#解析
# index: 替换为要执行聚合查询的索引名称。
# aggregation_name: 替换为自定义的聚合名称。
# bucket_type: 替换为特定的桶聚合类型(如 terms、date_histogram、range 等)。
# bucket_option_name 和 bucket_option_value: 替换为特定桶聚合选项的名称和值。
# sub_aggregation_name: 替换为子聚合的名称。
# sub_aggregation_type: 替换为特定的子聚合类型(如 sum、avg、max、min 等)。
# sub_aggregation_option_name 和 sub_aggregation_option_value: 替换为特定子聚合选项的名称和值
指标聚合(Metrics Aggregations)
-
主要用于计算数值字段的统计信息,如平均值、最大值、最小值、求和、去重计数等。
-
示例:计算某个班级、某个学科的最高分、最低分等。
-
语法格式
GET /index/_search
{
"size": 0,
"aggs": {
"aggregation_name": {
"aggregation_type": {
"aggregation_field": "field_name"
// 可选参数
}
}
// 可以添加更多的聚合
}
}
# 解析
#index:要执行聚合查询的索引名称。
#size: 设置为 0 来仅返回聚合结果,而不返回实际的搜索结果,这里将hits改为0表示返回的原始数据变为0
#aggs:指定聚合操作的容器。
#aggregation_name:聚合名称,可以自定义。
#aggregation_type:聚合操作的类型,例如 terms、avg、sum 等。
#aggregation_field:聚合操作的目标字段,对哪些字段进行聚合
聚合查询的特点
-
嵌套性:聚合查询支持嵌套,即一个聚合内部可以包含别的子聚合,实现复杂的数据挖掘和统计需求。
-
灵活性:可以用于多种场景的数据分析,满足各种业务需求。
-
高效性:Elasticsearch的聚合查询基于倒排索引和优化的数据结构,使得聚合操作能够高效地执行。
常见聚合用途及应用场景
聚合指标(Aggregation Metrics):
- Avg Aggregation:计算文档字段的平均值。
- Sum Aggregation:计算文档字段的总和。
- Min Aggregation:找到文档字段的最小值。
- Max Aggregation:找到文档字段的最大值。
聚合桶(Aggregation Buckets):
- Terms Aggregation:基于字段值将文档分组到不同的桶中。
- 语法格式
GET /index/_search
{
"size": 0,
"aggs": {
"aggregation_name": {
"bucket_type": {
"bucket_options": {
"bucket_option_name": "bucket_option_value",
...
},
"aggs": {
"sub_aggregation_name": {
"sub_aggregation_type": {
"sub_aggregation_options": {
"sub_aggregation_option_name": "sub_aggregation_option_value",
...
}
}
}
}
}
}
}
}
#解析
#index: 替换为要执行聚合查询的索引名称。
#aggregation_name: 替换为自定义的聚合名称。
#bucket_type: 替换为特定的桶聚合类型(如 terms、date_histogram、range 等)。
#bucket_option_name 和 bucket_option_value: 替换为特定桶聚合选项的名称和值。
#sub_aggregation_name: 替换为子聚合的名称。
#sub_aggregation_type: 替换为特定的子聚合类型(如 sum、avg、max、min 等)。
#sub_aggregation_option_name 和 sub_aggregation_option_value: 替换为特定子聚合选项的名称和值
- Date Histogram Aggregation:按日期/时间字段创建时间间隔的桶。
- 语法格式
GET /index/_search
{
"size": 0,
"aggs": {
"date_histogram_name": {
"date_histogram": {
"field": "date_field_name",
"interval": "interval_expression"
},
"aggs": {
"sub_aggregation": {
"sub_aggregation_type": {}
}
}
}
}
}
#解析
#index:替换为要执行聚合查询的索引名称。
#date_histogram_name:替换为自定义的 date_histogram 聚合名称。
#date_field_name:替换为要聚合的日期类型字段名。
#interval_expression:指定用于分桶的时间间隔。时间间隔可以是一个有效的日期格式(如 1d、1w、1M),也可以是一个数字加上一个时间单位的组合(如 7d 表示 7 天,1h 表示 1 小时)。
#sub_aggregation:指定在每个日期桶内进行的子聚合操作。
#sub_aggregation_type:替换单独子聚合操作的类型,可以是任何有效的子聚合类型。
- Range Aggregation:根据字段值的范围创建桶。
- 语法格式
GET /index/_search
{
"size": 0,
"aggs": {
"range_name": {
"range": {
"field": "field_name",
"ranges": [
{ "key": "range_key_1", "from": from_value_1, "to": to_value_1 },
{ "key": "range_key_2", "from": from_value_2, "to": to_value_2 },
...
]
},
"aggs": {
"sub_aggregation": {
"sub_aggregation_type": {}
}
}
}
}
}
#解析
# index:替换为要执行聚合查询的索引名称。
# range_name:替换为自定义的 range 聚合名称。
# field_name:替换为要聚合的字段名。
# ranges:指定范围数组,每个范围使用 key、from 和 to 参数进行定义。
# key:范围的唯一标识符。
# from:范围的起始值(包含)。
# to:范围的结束值(不包含)。
# sub_aggregation:指定在每个范围内进行的子聚合操作。
# sub_aggregation_type:替换单独子聚合操作的类型,可以是任何有效的子聚合类型。
Query DSL指标聚合多案例介绍实战
创建索引
PUT /sales
{
"mappings": {
"properties": {
"id":{
"type":"keyword"
},
"product": {
"type": "keyword"
},
"sales": {
"type": "integer"
}
}
}
}
批量插入数据
POST /sales/_bulk
{"index": {}}
{"product": "iPhone", "sales": 4}
{"index": {}}
{"product": "Samsung", "sales": 60}
{"index": {}}
{"product": "iPhone", "sales": 100}
{"index": {}}
{"product": "Samsung", "sales": 80}
{"index": {}}
{"product": "小米手机", "sales": 50}
{"index": {}}
{"product": "小米手机", "sales": 5000}
{"index": {}}
{"product": "小米手机", "sales": 200}
指标聚合实战
根据商品名称分组
GET /sales/_search
{
"aggs": {
"phone_group": {
"terms": {
"field": "product"
}
}
}
}
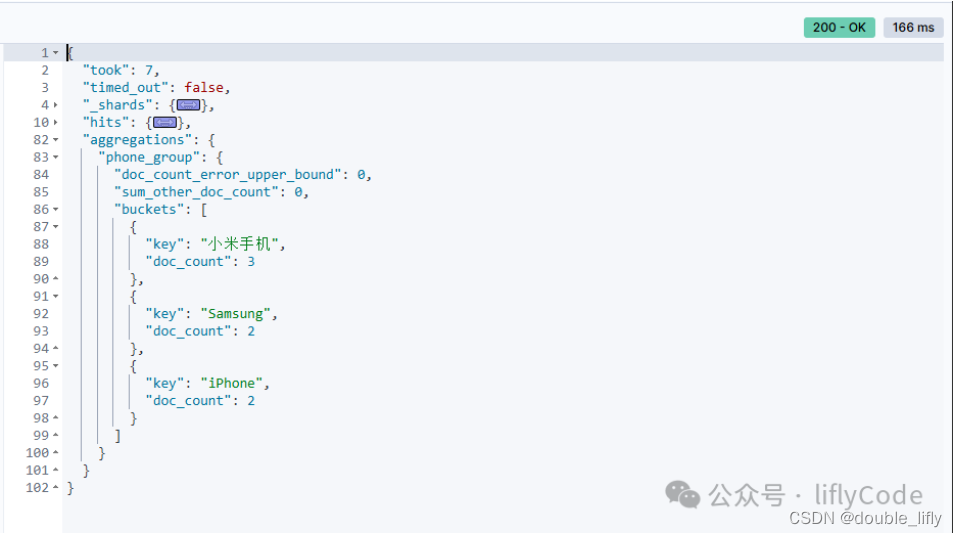
计算每组的销售总量,使用terms聚合和sum聚合来
GET /sales/_search
{
"size": 0,
"aggs": {
"product_sales": {
"terms": {
"field": "product"
},
"aggs": {
"total_salers": {
"sum": {
"field": "sales"
}
}
}
}
}
}
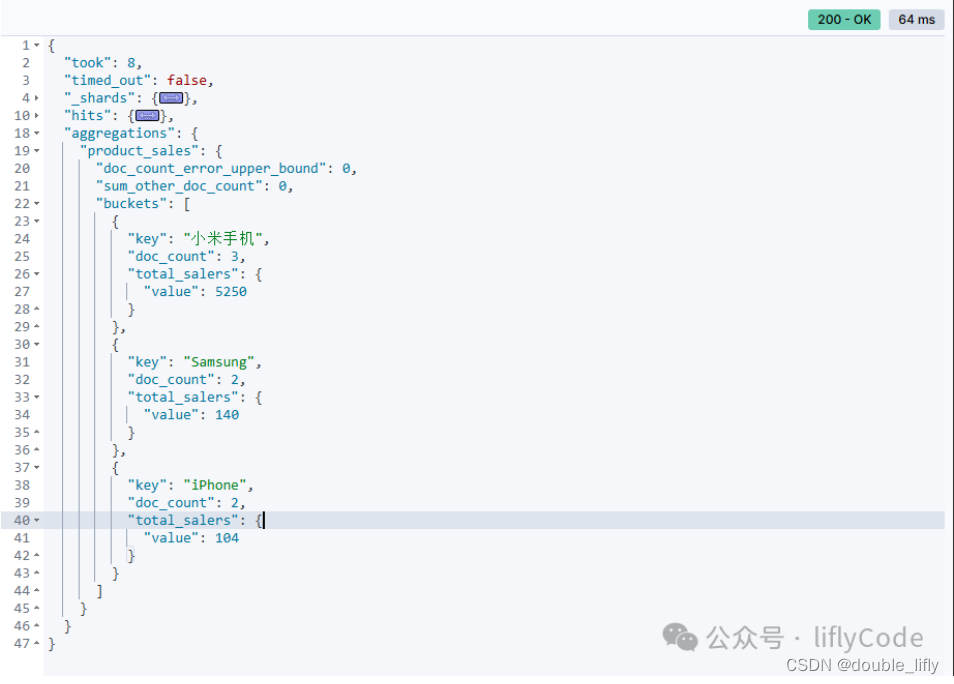
计算总和
GET /sales/_search
{
"aggs": {
"sum_sales": {
"sum": {
"field": "sales"
}
}
}
}
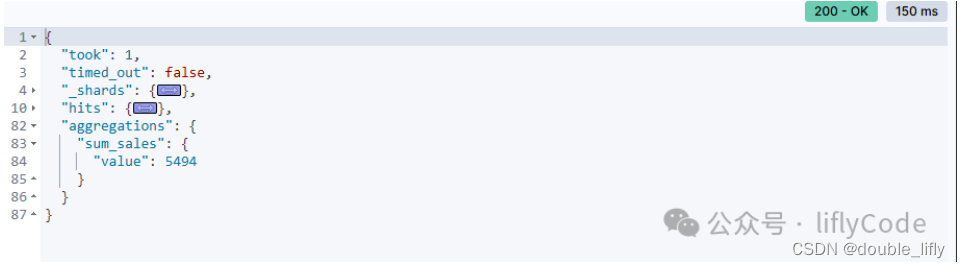
计算不同品牌的平均值
GET /sales/_search
{
"aggs": {
"product_sales": {
"terms": {
"field": "product"
},
"aggs": {
"avg_sales": {
"avg": {
"field": "sales"
}
}
}
}
}
}
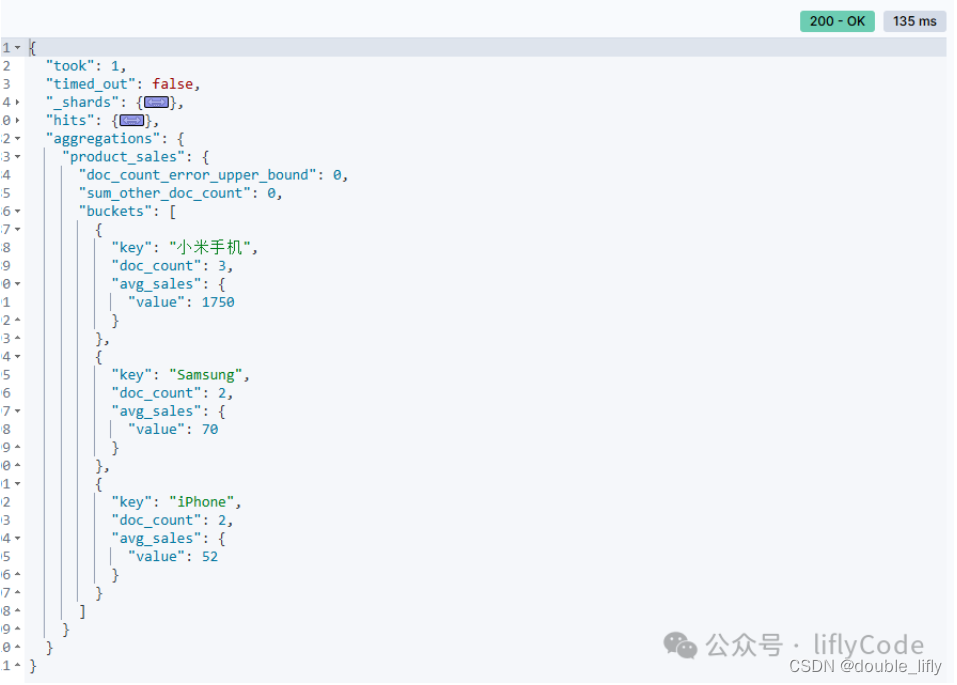
计算总商品的平均值
GET /sales/_search
{
"size": 0,
"aggs": {
"avg_sales": {
"avg": {
"field": "sales"
}
}
}
}
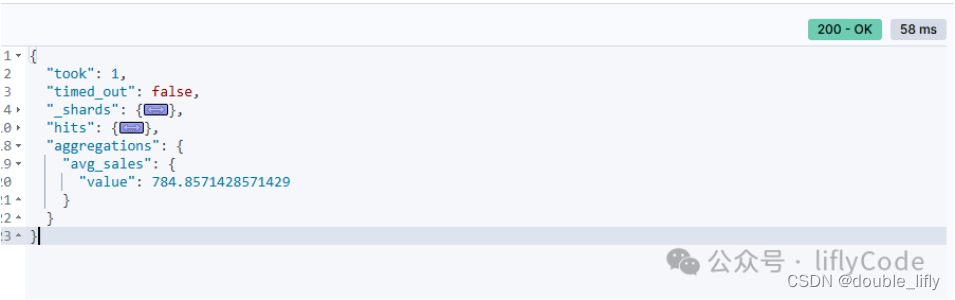
计算不同品牌的手机的最高低价
GET /sales/_search
{
"size": 0,
"aggs": {
"product_sales": {
"terms": {
"field": "product"
},
"aggs": {
"max_sales": {
"max": {
"field": "sales"
}
}
}
}
}
}
GET /sales/_search
{
"size": 0,
"aggs": {
"product_sales": {
"terms": {
"field": "product"
},
"aggs": {
"max_sales": {
"min": {
"field": "sales"
}
}
}
}
}
}
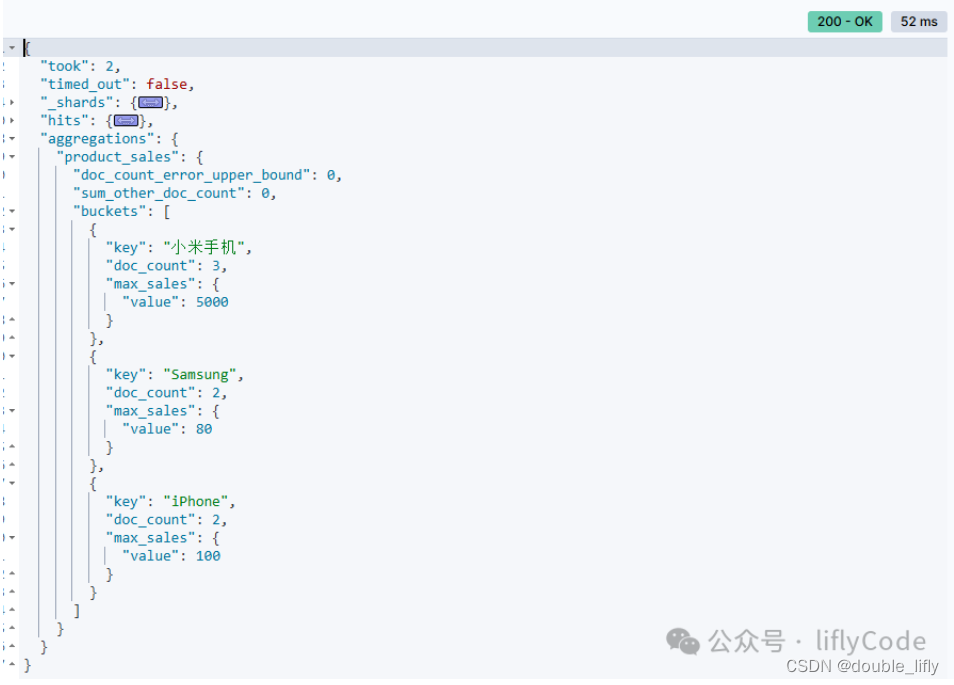
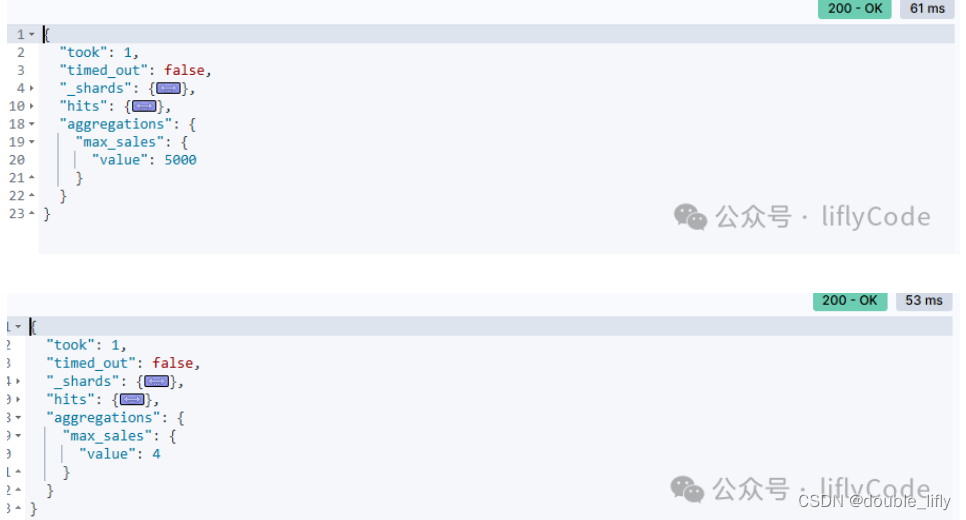
查找最大最小值
GET /sales/_search
{
"size": 0,
"aggs": {
"max_sales": {
"max": {
"field": "sales"
}
}
}
}
GET /sales/_search
{
"size": 0,
"aggs": {
"max_sales": {
"min": {
"field": "sales"
}
}
}
}
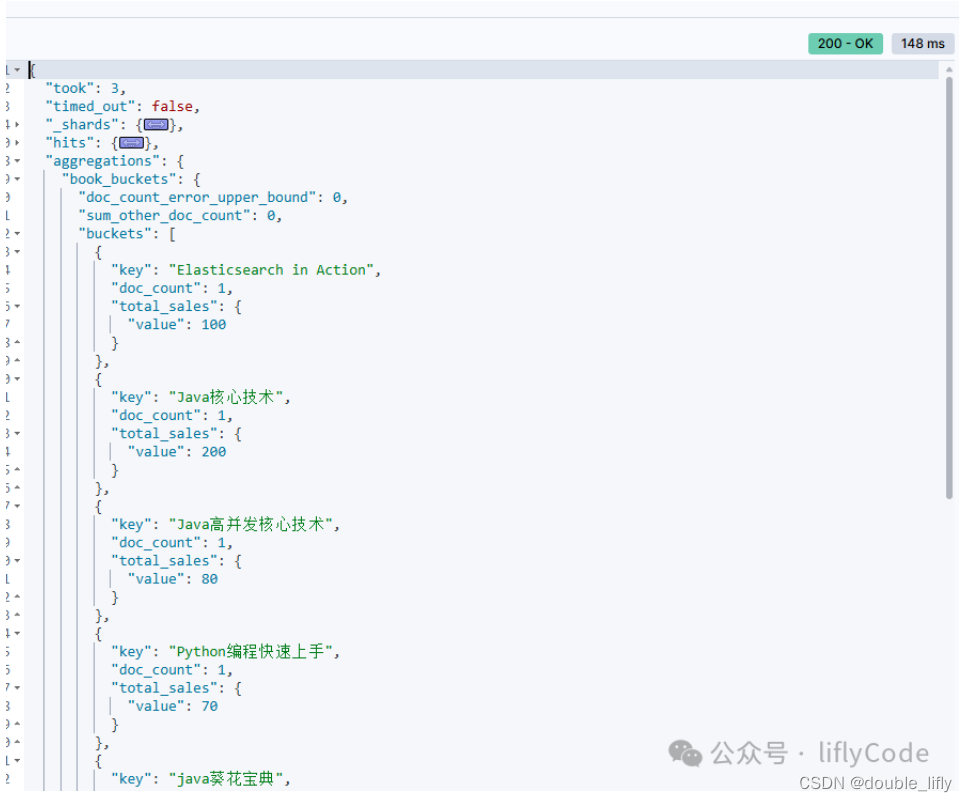
Query DSL 桶聚合Terms案例实战
使用 terms 聚合查询将图书按销售数量进行分桶,并获取每个分桶内的销售数量总和。
GET /book_sales/_search
{
"size": 0,
"aggs": {
"book_buckets": {
"terms": {
"field": "book_title"
},
"aggs": {
"total_sales": {
"sum": {
"field": "sales_count"
}
}
}
}
}
}
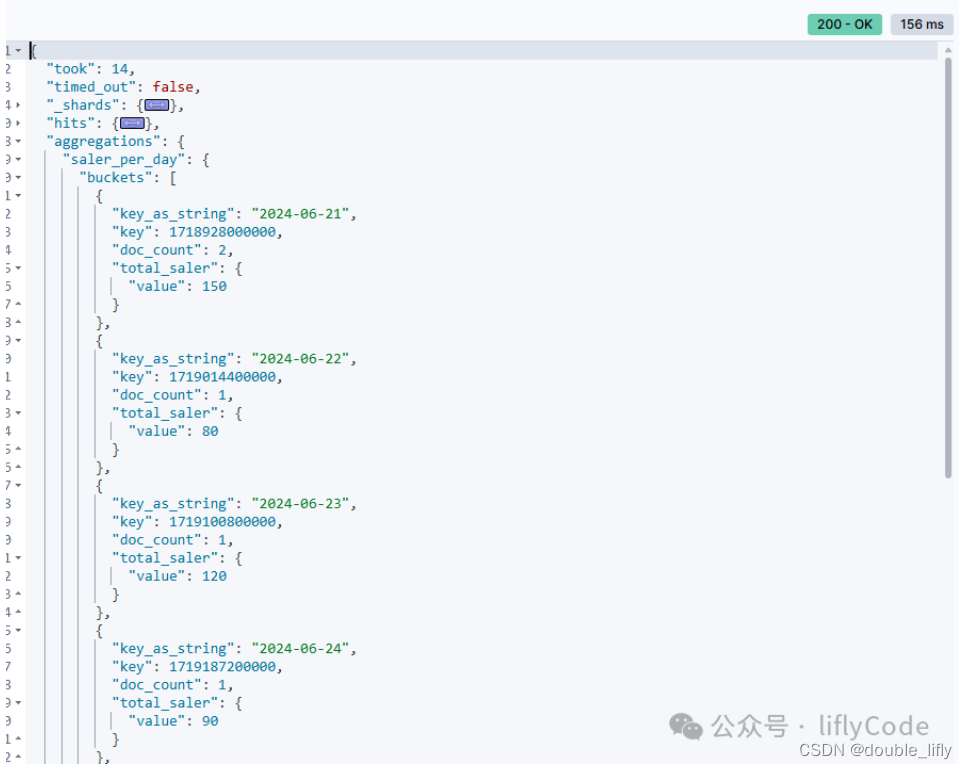
Query DSL 桶聚合Date Histogram介绍和案例实战
使用 date_histogram 聚合查询将订单按日期进行分桶,并计算每个分桶内的订单金额总和
GET /book_sales/_search
{
"size": 0,
"aggs": {
"saler_per_day": {
"date_histogram": {
"field": "date",
"calendar_interval": "day",
"format": "yyyy-MM-dd"
},
"aggs": {
"total_saler": {
"sum": {
"field": "sales_count"
}
}
}
}
}
}
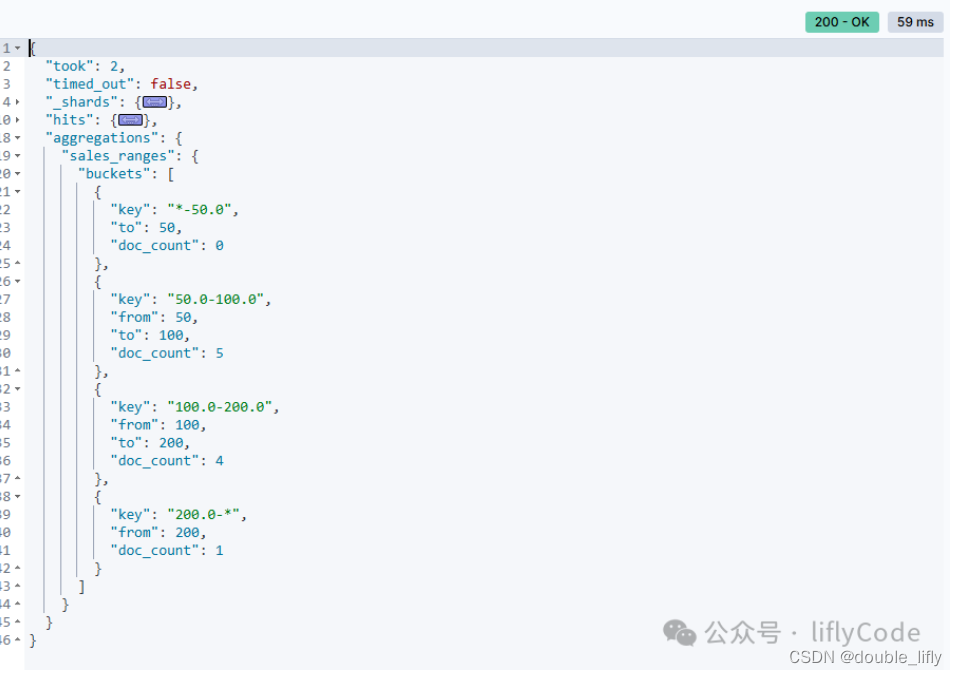
Query DSL 桶聚合Range介绍和案例实战
使用 range 聚合查询将商品按价格范围进行分桶,并计算每个分桶内的商品数量
GET /book_sales/_search
{
"size": 0,
"aggs": {
"sales_ranges": {
"range": {
"field": "sales_count",
"ranges": [
{
"to": 50
},
{
"from": 50,
"to": 100
},
{
"from": 100,
"to": 200
},
{
"from": 200
}
]
}
}
}
}
通过本篇文章的深入解析,我们不仅掌握了Elasticsearch聚合查询的基本概念与分类,还通过一系列实战案例学习了如何有效地运用分桶聚合与指标聚合进行数据挖掘与统计分析。从简单的平均值、求和计算到复杂的多层级分桶与时间序列分析,Elasticsearch的聚合功能展现了其在大规模数据处理与复杂业务分析场景中的强大能力。
记住,无论是进行市场趋势分析、用户行为洞察还是日志数据的深入挖掘,合理设计聚合查询都是解锁数据价值的关键。随着实践的深入,不断探索高级特性与优化策略,你将能更加灵活高效地应对各种数据分析挑战。
总之,Elasticsearch聚合查询是通往数据智能分析的重要桥梁,它不仅能够帮助我们快速洞察数据分布特征,还能驱动业务决策更加精准高效。希望本指南能成为你掌握Elasticsearch聚合查询技能的坚实基石,开启数据驱动决策的新篇章。
更多精彩内容,请关注以下公众号