文章目录
- 前言
- 一、简介
- 二、Background: indirect calls, Spectre, and retpolines
- 2.1 Indirect calls
- 2.2 Spectre (v2)
- 2.3 Retpolines
- Consequences
- 2.4 Static calls
- How it works
- 三、其他
- 参考资料
前言
Linux内核5.10内核版本引入新特性:Static calls。
Static calls for improved post-Spectre performance
Static calls静态调用是全局函数指针的替代方案。它们利用代码修补来实现直接调用,而不是间接调用。它们提供了函数指针的灵活性,但具有改进的性能。这在使用函数指针较多的x86 perf代码中尤为重要,因为静态调用可以将PMU处理程序的速度提高4.2%。这对于本来需要使用retpoline的情况尤其重要,因为retpoline可能会严重影响性能。
简单来说:静态调用使用代码修补将函数指针硬编码到直接跳转指令中。它们提供了函数指针的灵活性,但性能更好。
间接函数调用——调用存储在指针变量中的函数地址——从来都不是非常快速的,但Spectre硬件漏洞使情况变得更糟。CPU中用于加速间接调用的间接分支预测器不能再使用,性能相应地受到了影响。"retpoline"机制是一个聪明的技巧,证明比最初尝试的基于硬件的解决方案更快。虽然retpoline减轻了Spectre缓解的痛苦,但过去一年的经验表明它们仍然会产生一定的性能损失。因此,开发人员一直在寻找retpoline的替代方法;最近在内核列表中出现了几种解决方案。
使间接调用更快的方法是将其替换为直接调用;这样就不需要分支预测。当然,如果在任何给定情况下直接调用就足够了,开发人员会使用直接调用而不是间接调用,所以这种替换并不总是直截了当的。所有对retpoline开销的提议解决方案都努力以某种方式进行这种替换;它们从简单到复杂各不相同。
retpoline是一个软件方法来解决Spectre V2漏洞,但其开销比较大。
Static calls静态调用是retpoline的替代方法。
一、简介
本章节来自:Avoiding retpolines with static calls
2018年1月是内核社区的一个悲伤时刻。Meltdown和Spectre漏洞最终被公开,而所需的解决方案在许多方面损害了内核性能。其中一种解决方案是retpoline,但它继续带来困扰,开发人员不得不费尽心思避免间接调用,因为它们现在必须使用retpoline来实现。然而,在某些情况下,可能有一种方法可以避免retpoline并恢复大部分性能损失;经过漫长的孕育期,"静态调用"机制可能终于接近能够合并到上游的阶段。
当编译时无法确定要调用的函数的地址时,就会发生间接调用;相反,该地址存储在指针变量中,在运行时使用。这些间接调用很容易受到推测执行攻击的利用。Retpolines通过将间接调用转换为一个更复杂(且更昂贵)的代码序列来防止这些攻击,这样就无法进行推测执行。
Retpolines解决了问题,但也降低了内核的速度,因此开发人员一直渴望找到避免它们的方法。已经尝试了许多方法;其中一些在2018年末的 这篇文章 中进行了介绍。虽然其中一些技术已经合并,但静态调用一直未进入主线内核。最近,Peter Zijlstra发布了这个补丁集,其中包含其他人的工作,特别是Josh Poimboeuf,他发布了最初的静态调用实现。
这就是静态调用发挥作用的地方。静态调用使用位于可执行内存中的位置(而不是可写内存),该位置包含一个指向目标函数的跳转指令。执行静态调用需要调用特殊位置,然后跳转到实际的目标函数。这被称为经典的代码跳板,完全避免了使用 retpolines 的需要。
间接调用从可写内存中的位置起作用,可以找到跳转的目标。更改调用的目标只需在该位置存储一个新地址。相反,静态调用使用可执行内存中的位置,其中包含一个指向目标函数的跳转指令。实际执行静态调用需要"调用"这个特殊位置,它将立即跳转到真正的目标函数。静态调用位置实际上是一个经典的代码跳板。由于两个跳转都是直接的——目标地址直接在可执行代码本身中找到——不需要retpoline,并且执行速度很快。
对于Spectre-v2漏洞和Retpoline请参考:Spectre-v2 以及 Linux Retpoline技术简介
静态调用必须在使用之前进行声明;有两个宏可以完成这个任务:
#include <linux/static_call.h>
DEFINE_STATIC_CALL(name, target);
DECLARE_STATIC_CALL(name, target);
DEFINE_STATIC_CALL()创建一个新的静态调用,使用给定的名称,并最初指向函数target()。DECLARE_STATIC_CALL()则声明了在其他地方定义的静态调用的存在;在这种情况下,target()仅用于对调用进行类型检查。
实际调用静态调用的方式如下:
static_call(name)(args...);
其中,name是用于定义调用的名称。这将导致通过跳板跳转到目标函数;如果该函数返回一个值,static_call()也会返回该值。
静态调用的目标可以通过以下方式更改:
static_call_update(name, target2);
其中,target2()是静态调用的新目标。更改静态调用的目标需要对正在运行的内核进行修补,这是一项昂贵的操作。这意味着静态调用只适用于目标很少更改的情况。
在补丁集中可以找到这样的情况:跟踪点(tracepoints)。激活一个跟踪点本身就需要对代码进行修补。一旦完成,内核通过迭代遍历已附加到跟踪点的回调函数的链表来响应对跟踪点的触发。然而,在几乎所有情况下,只会有一个这样的函数。该系列中的这个补丁通过对单函数情况使用静态调用来优化该过程。由于跟踪点的目标是尽可能减少开销,因此在那里使用静态调用是有意义的。
这个补丁集还包含了一项在原始版本中找不到的进一步优化。通过跳过跳板(trampoline)进行跳转比使用retpoline要快得多,但仍然比严格必要的跳转多一个。因此,这个补丁使静态调用直接将目标地址存储到调用点(call site(s)),完全消除了跳板的需要。这可能需要更改多个调用点,但大多数静态调用不太可能有很多这样的调用点。它还需要在objtool工具中提供支持,以便在内核构建过程中定位这些调用点。
这项工作的最终结果似乎是在使用跟踪点时减少Spectre缓解的成本——4%多的减速降低到大约1.6%。经过多次修订以及对基础文本修补代码的一些改进,它似乎已经准备就绪。静态调用有望在不久的将来被合并到主线内核中。
对于内核镜像:
内核镜像增加了一个数据段__start_static_call_sites - __stop_static_call_sites :
// linux-5.15/include/asm-generic/vmlinux.lds.h
#define STATIC_CALL_DATA \
. = ALIGN(8); \
__start_static_call_sites = .; \
KEEP(*(.static_call_sites)) \
__stop_static_call_sites = .; \
__start_static_call_tramp_key = .; \
KEEP(*(.static_call_tramp_key)) \
__stop_static_call_tramp_key = .;
// kernel/static_call.c
int __init static_call_init(void)
{
int ret;
if (static_call_initialized)
return 0;
cpus_read_lock();
static_call_lock();
ret = __static_call_init(NULL, __start_static_call_sites,
__stop_static_call_sites);
static_call_unlock();
cpus_read_unlock();
static_call_initialized = true;
return 0;
}
early_initcall(static_call_init);
# uname -r
5.15.0-101-generic
# cat /proc/kallsyms | grep __start_static_call_sites
ffffffffa233afb0 R __start_static_call_sites
# cat /proc/kallsyms | grep __stop_static_call_sites
ffffffffa233d4b0 R __stop_static_call_sites
对于内核模块:
内核模块增加了一个.static_call_sites节:
// kernel/module.c
static int find_module_sections(struct module *mod, struct load_info *info)
{
......
#ifdef CONFIG_HAVE_STATIC_CALL_INLINE
mod->static_call_sites = section_objs(info, ".static_call_sites",
sizeof(*mod->static_call_sites),
&mod->num_static_call_sites);
#endif
......
}
/*
* The static call site table needs to be created by external tooling (objtool
* or a compiler plugin).
*/
struct static_call_site {
s32 addr;
s32 key;
};
struct module {
......
#ifdef CONFIG_HAVE_STATIC_CALL_INLINE
int num_static_call_sites;
struct static_call_site *static_call_sites;
#endif
......
}
二、Background: indirect calls, Spectre, and retpolines
2.1 Indirect calls
间接调用是C语言中最强大的功能之一,它对于在没有补充对象或函数/方法调度系统的情况下编写高级代码至关重要。
大多数C程序员都对间接调用的基本原理很熟悉,这要归功于标准库和POSIX函数,例如qsort和pthread_create。在这些函数中,每个函数都有一个函数指针,然后在内部调用该函数指针以完成所需的功能:
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
/* qsort_strcmp is just the normal stdlib strcmp, with a bit of extra parameter
* munging to match qsort's API.
*/
static int qsort_strcmp(const void *a, const void *b) {
return strcmp(*(const char **)a, *(const char **)b);
}
int main(void) {
const char *strings[] = {"foo", "bar", "baz"};
/* qsort is a generic sorting function:
* you give it the a pointer to the base address of things to sort,
* their number and individual sizes, and a *function* that can compare
* any two members and provide an ordering between them.
*
* in this case, we tell qsort to sort an array of strings, using
* `qsort_strcmp` for the ordering.
*/
qsort(&strings, 3, sizeof(char *), qsort_strcmp);
printf("%s %s %s\n", strings[0], strings[1], strings[2]);
return 0;
}
在这种情况下,间接调用发生在qsort中。但是,如果我们实现自己的函数来进行间接调用,我们可以直接看到它:
static uint32_t good_rand() {
uint32_t x;
getrandom(&x, sizeof(x), GRND_NONBLOCK);
return x;
}
static uint32_t bad_rand() {
return rand();
}
/* munge takes a function pointer, rand_func, which it calls
* as part of its returned result.
*/
static uint32_t munge(uint32_t (*rand_func)(void)) {
return rand_func() & 0xFF;
}
int main(void) {
uint32_t x = munge(good_rand);
uint32_t y = munge(bad_rand);
printf("%ul, %ul\n", x, y);
return 0;
}
munge可以归结为:
munge:
push rbp
mov rbp, rsp
sub rsp, 16
mov qword ptr [rbp - 8], rdi ; load rand_func
call qword ptr [rbp - 8] ; call rand_func
and eax, 255
add rsp, 16
pop rbp
ret
观察一下:我们的调用通过一个内存或寄存器操作数([rbp - 8])来获取目标,而不是直接指定操作数值本身的直接目标(比如,call 0xacabacab ; @good_rand)。这就是使其成为间接调用的原因。
在这种情况下,我们的调用需要在运行时通过内存或寄存器中存储的地址来确定目标函数的位置,而不是在编译时就能确定目标地址。这种间接性使得代码更加灵活,可以在运行时动态地选择要调用的函数。
我们可以进一步深入!事实上,在C语言中,常见的模式是声明整个操作结构,使用每个操作作为参数来对一组独立实现的低级行为(例如,核心的POSIX I/O API)进行参数化。
这种模式通常用于实现可插拔的行为或策略模式。通过将操作封装在结构中,并将该结构作为参数传递给函数,我们可以在运行时选择不同的实现来改变程序的行为。
以下是一个示例,展示了如何使用结构来参数化低级行为:
#include <stdio.h>
// 定义操作结构
typedef struct {
void (*open)();
void (*read)();
void (*write)();
void (*close)();
} IOOperations;
// 低级实现1
void fileOpen() {
printf("打开文件...\n");
}
void fileRead() {
printf("读取文件...\n");
}
void fileWrite() {
printf("写入文件...\n");
}
void fileClose() {
printf("关闭文件...\n");
}
// 低级实现2
void networkOpen() {
printf("打开网络连接...\n");
}
void networkRead() {
printf("从网络读取...\n");
}
void networkWrite() {
printf("向网络写入...\n");
}
void networkClose() {
printf("关闭网络连接...\n");
}
// 使用操作结构的高级函数
void performIO(IOOperations *operations) {
operations->open();
operations->read();
operations->write();
operations->close();
}
int main() {
IOOperations fileIO = {fileOpen, fileRead, fileWrite, fileClose};
IOOperations networkIO = {networkOpen, networkRead, networkWrite, networkClose};
printf("执行文件操作:\n");
performIO(&fileIO);
printf("\n执行网络操作:\n");
performIO(&networkIO);
return 0;
}
比如这正是FUSE的工作方式:每个FUSE客户端都创建自己的FUSE_operations:
struct fuse_operations {
int (*getattr) (const char *, struct stat *, struct fuse_file_info *fi);
int (*readlink) (const char *, char *, size_t);
int (*mknod) (const char *, mode_t, dev_t);
int (*mkdir) (const char *, mode_t);
int (*unlink) (const char *);
int (*rmdir) (const char *);
int (*symlink) (const char *, const char *);
int (*rename) (const char *, const char *, unsigned int flags);
int (*link) (const char *, const char *);
/* ... */
int (*open) (const char *, struct fuse_file_info *);
int (*read) (const char *, char *, size_t, off_t,
struct fuse_file_info *);
int (*write) (const char *, const char *, size_t, off_t,
struct fuse_file_info *);
int (*statfs) (const char *, struct statvfs *);
/* ... */
}
毫不奇怪,这种技术不仅限于用户空间:Linux内核本身大量使用了间接调用,特别是在与体系结构无关的接口(如VFS和像procfs这样的子专用接口)以及子系统的体系结构特定内部(如perf_events)中。
在Linux内核中,使用间接调用的目的是为了实现可移植性和灵活性。通过使用函数指针和间接调用,内核可以提供通用的接口,而不必关心底层具体的实现细节。这使得内核能够在多个体系结构上运行,并且可以通过更改具体实现来改变内核的行为。
例如,Linux内核的虚拟文件系统(VFS)是一个与体系结构无关的接口,用于处理文件系统操作。它定义了一组函数指针,用于执行与文件系统相关的操作,如打开文件、读取文件、写入文件等。具体的文件系统实现可以通过设置这些函数指针来提供相应的功能。
类似地,perf_events子系统是用于性能分析的内核子系统。它利用间接调用来处理体系结构特定的事件和计数器。不同的体系结构可以提供它们自己的实现,通过设置相应的函数指针来处理特定的事件和计数器。
通过使用间接调用,Linux内核能够在不同的体系结构上实现统一的接口,并且可以根据需要进行灵活的定制和扩展。
确实如此。这种技术非常巧妙,以至于CPU工程师们为了从中挤取更多性能而兴奋不已,结果我们遭遇了Spectre漏洞(Spectre v2)。
2.2 Spectre (v2)

Spectre v2(也称为CVE-2017-5715)利用的确切机制略微超出了本文的范围,但在高层次上可以解释如下:
(1)现代(x86)CPU中包含一个间接分支预测器,用于尝试猜测间接调用或跳转的目标位置。
为了实际加速执行,CPU会对预测的分支进行推测性执行:
如果预测正确,间接调用会在短时间内完成(因为它已经在推测性执行中或已经完成推测性执行);
如果预测错误,应该会导致较慢(但仍然成功)的间接调用,而不会受到不正确推测的副作用影响。
换句话说,CPU负责回滚任何与错误预测和后续推测相关的副作用。错误推测是一种微体系结构细节,不应该表现为体系结构更改,比如修改的寄存器。
(2)回滚任何错误推测的状态是一项相对昂贵的操作,具有许多微体系结构影响:缓存行和其他状态位需要进行修复,以确保实际的程序控制流程不受失败推测的影响。
实际上,回滚整个推测状态将撤消推测的大部分优势。因此,x86和其他指令集架构会将推测状态的许多位(例如缓存行)标记为陈旧状态。
(3)这种修复行为(回滚或标记推测状态)导致了一个侧信道:攻击者可以训练分支预测器,以推测性地执行一段代码(类似于ROP小工具),该代码以数据相关的方式修改一些微体系结构状态,例如依赖于推测性获取的秘密值的缓存条目的地址。
然后,攻击者可以通过计时访问该微体系结构状态来探测它:快速访问表示存在推测性修改的状态,从而泄露了秘密信息。
最初的Spectre v2攻击主要集中在缓存行上,因为它们相对容易计时,即使是在高级别(受到沙箱限制的)语言中,这些语言无法访问x86上的clflush或其他缓存行原语。但这个概念是普遍存在的:在不泄露一些信息的情况下进行推测性执行是困难的,而随后出现的漏洞(如MDS和ZombieLoad)已经揭示了其他微体系结构特性中的信息泄露问题。
这是个坏消息:攻击者在最安全的上下文(JavaScript或其他托管代码,在沙箱中,在用户空间)中运行,理论上可以训练间接分支预测器以推测性地执行内核空间的一个小工具,从而可能泄露内核内存。
因此,内核需要一种新的缓解措施。这个缓解措施就是retpolines。
2.3 Retpolines
Retpoline(返回跳板)是一种利用永远不会执行的无限循环来防止CPU对间接跳转的目标进行推测的跳板系统。该系统还使用返回堆栈缓冲器(RSB)作为预测结构,类似于返回指令的分支预测器。为了确保无法通过恶意方式训练出无限循环的 RSB,retpolines 总是以直接调用开始,以确保 RSB 预测到一个无限循环。
Retpoline 并不是最初针对 Spectre 漏洞的缓解措施,而是在发现原始的 Spectre 缓解措施在特定的 CPU 架构(包括 AMD 和 Intel)和特定工作负载下导致相对性能下降后,由 Google 创建的。
为了缓解Spectre v2漏洞,内核需要阻止CPU对受攻击者控制的间接分支进行推测性执行。
retpoline(返回跳板)正是为此目的而设计的:间接跳转和调用周围包含一个小的代码块(thunk),它将推测性执行陷入一个无限循环中,直到错误的预测得到解决。
英特尔的Retpoline白皮书中有一些有用的插图,可以帮助理解这个过程:
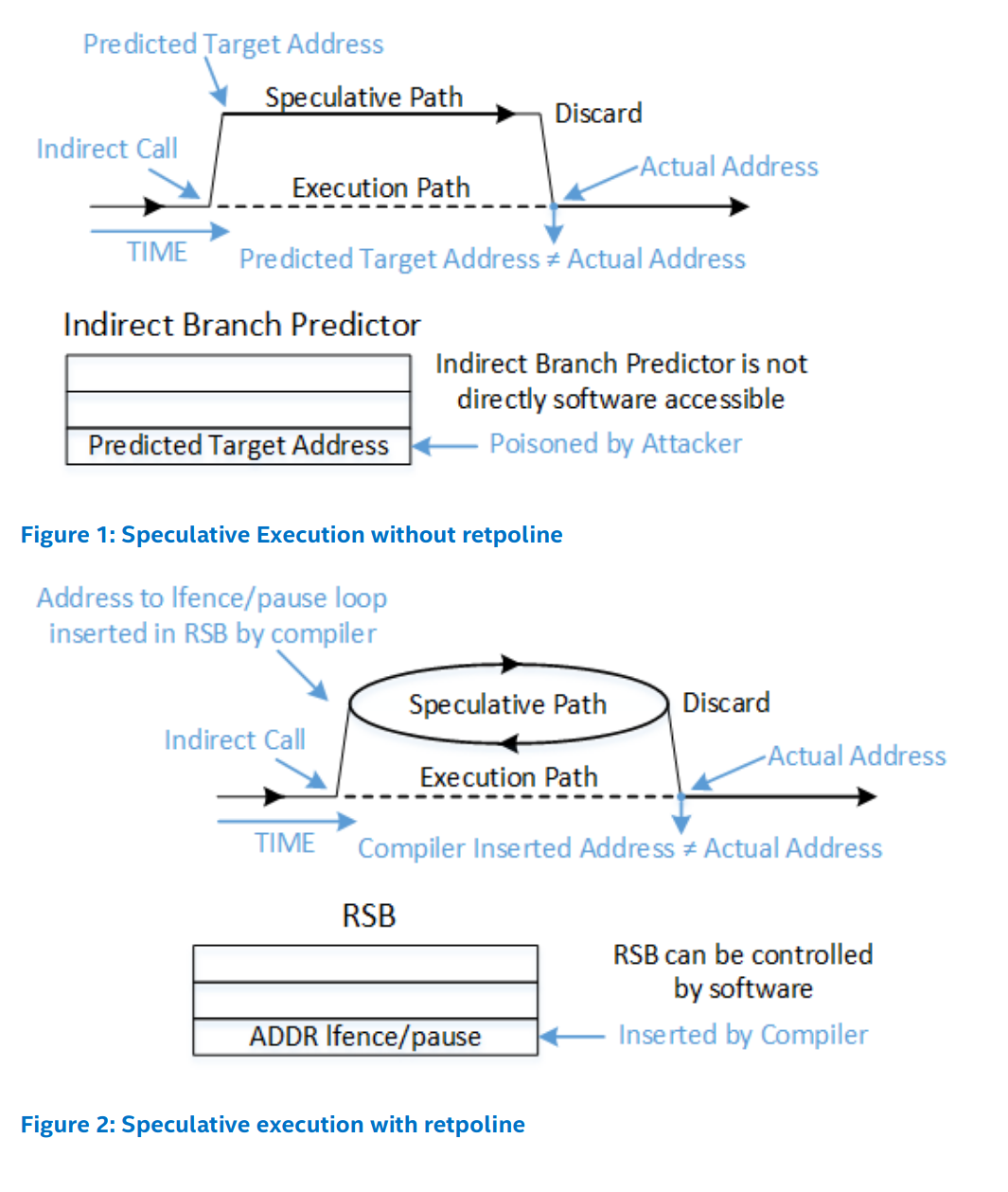
retpoline的工作原理是将间接控制流从间接分支转换为间接返回(indirect return),因此在retpoline中有“ret”(返回)这个名称。返回指令也会被预测,但是有一个额外的机制具有优先级,即返回堆栈缓冲区(Return Stack Buffer,RSB)。为了确保RSB不能被恶意训练以远离无限循环,retpoline以直接的CALL指令开始,这个CALL指令会预测RSB始终预测无限循环。
以下是间接调用retpoline的实际情况,从内核源代码中进行了显著简化:
__x86_retpoline_rax:
call .Ldo_rop_0
.Lspec_trap_0:
pause
lfence
jmp .Lspec_trap_0
.Ldo_rop_0:
mov [rsp], rax
ret
…所有这些都是为了取代一个简单的调用[rax]!
Consequences
这种技巧会产生一些不良影响:
(1)当预测正确时,速度较慢:我们用至少两个直接的CALL指令和一个RET指令替换了一个间接的CALL指令。
(2)当预测错误时,速度非常慢:我们使用PAUSE和LFENCE指令在原地旋转。
(3)它是一个ROP(Return-Oriented Programming)小工具,因此看起来像是一种利用原语。这意味着它会影响到英特尔的CET(Control-flow Enforcement Technology)和其他平台上类似的保护机制。英特尔声称新的硬件将支持“增强型IBRS”(enhanced IBRS),这将完全取代对retpolines的需求,从而可以使用CET。
(4)即使像上面那样简化,它仍然很难阅读和理解:完整的缓解措施还需要处理间接跳转、RSB填充和其他许多技巧,这些技巧是在最初的Spectre v2漏洞之后被发现的。
因此,retpoline 并没有比原始的 Spectre 缓解措施好多少。
让我们看看Linux 5.10在消除一些这些问题方面所做的工作,即Static calls机制。
2.4 Static calls
让我们来了解一下这种新的"静态调用"(static call)技术。以下是来自Josh Poimboeuf的补丁系列的API:
/* declare or define a new static call as `name`,
* initially associated with `func`
*/
DECLARE_STATIC_CALL(name, func);
DEFINE_STATIC_CALL(name, func);
/* invoke `name` with `args` */
static_call(name)(args...);
/* invoke `name` with `args` if not NULL */
static_call_cond(name)(args...);
/* update the underlying function */
static_call_update(name, func);
这里是从perf中摘录的一个示例(经过缩减和注释):
static void _x86_pmu_add(struct perf_event *event) { }
/* ... */
DEFINE_STATIC_CALL(x86_pmu_add, _x86_pmu_add);
static void x86_pmu_static_call_update(void) {
/* ... */
static_call_update(x86_pmu_add, x86_pmu.add);
/* ... */
}
static int __init init_hw_perf_events(void) {
/* ... */
x86_pmu_static_call_update();
/* ... */
}
总结一下:
(1)定义了一个空的静态函数_x86_pmu_add。
(2)使用DEFINE_STATIC_CALL宏将_x86_pmu_add命名为x86_pmu_add。
(3)定义了一个辅助函数x86_pmu_static_call_update。
辅助函数使用static_call_update来修改x86_pmu_add的底层函数,将其替换为x86_pmu.add(一个函数指针)。
(4)最后,__init函数init_hw_perf_events调用了这个静态调用的辅助函数。
结果是,之前的代码:
if (x86_pmu.add) {
x86_pmu.add(event);
}
现在变为:
static_call_cond(x86_pmu_add)(event);
这样看起来非常简洁,并且(显然)避免了使用retpoline!让我们了解一下为什么以及如何实现这种效果。
How it works
(1)Step 1: DEFINE_STATIC_CALL
在x86上,DEFINE_STATIC_CALL(x86_pmu_add,_x86_pmu_add)大致扩展为:
extern struct static_call_key __SCK__x86_pmu_add;
extern typeof(_x86_pmu_add) __SCT__x86_pmu_add_tramp;
struct static_call_key __SCK__x86_pmu_add = {
.func = _x86_pmu_add,
};
ARCH_DEFINE_STATIC_CALL_TRAMP(x86_pmu_add, _x86_pmu_add);
ARCH_DEFINE_STATIC_CALL_TRAMP:
#define __ARCH_DEFINE_STATIC_CALL_TRAMP(name, insns) \
asm(".pushsection .static_call.text, \"ax\" \n" \
".align 4 \n" \
".globl " STATIC_CALL_TRAMP_STR(name) " \n" \
STATIC_CALL_TRAMP_STR(name) ": \n" \
insns " \n" \
".type " STATIC_CALL_TRAMP_STR(name) ", @function \n" \
".size " STATIC_CALL_TRAMP_STR(name) ", . - " STATIC_CALL_TRAMP_STR(name) " \n" \
".popsection \n")
#define ARCH_DEFINE_STATIC_CALL_TRAMP(name, func) \
__ARCH_DEFINE_STATIC_CALL_TRAMP(name, ".byte 0xe9; .long " #func " - (. + 4)")
ARCH_DEFINE_STATIC_CALL_TRAMP是一个宏,用于定义静态调用的跳转函数。它展开为__ARCH_DEFINE_STATIC_CALL_TRAMP宏。
__ARCH_DEFINE_STATIC_CALL_TRAMP宏是一个特定于体系结构的宏,它生成汇编代码来定义静态调用的跳转函数。它使用内联汇编来创建一个名为".static_call.text"的节(section),并使用指定的汇编指令(insns)来定义跳转函数。汇编指令通常包括一个相对跳转指令(jmp),用于跳转到由func参数指定的目标函数。
具体来说,展开后的代码会将跳转函数的汇编代码插入到".static_call.text"节中。跳转函数的名称由name参数确定,使用STATIC_CALL_TRAMP_STR宏进行字符串化。汇编代码包括一条".byte 0xe9"指令,表示相对跳转指令(jmp)的操作码,后跟".long " #func " - (. + 4)",表示跳转目标相对于当前指令的偏移量。
扩展(通过重新格式化)为:
.pushsection .static_call.text, "ax"
.align 4
.globl "__SCT__x86_pmu_add_tramp"
"__SCT__x86_pmu_add_tramp":
.byte 0xe9
.long _x86_pmu_add - (. + 4)
.type "__SCT__x86_pmu_add_tramp", @function
.size "__SCT__x86_pmu_add_tramp", . - "__SCT__x86_pmu_add_tramp"
.popsection
.byte 0xe9:relative JMP
0xE9(E9 cd) :Jump near 后面的4个字节是偏移:一个保存jmp本身的机器码,另4个保存偏移 -->总共5个字节
具体来说,它是一个到由.long _x86_pmu_add-(.+4)计算的地址的JMP,这是“_x86_pmu_add的地址,减去当前地址(由.表示),再加4”的丑陋GAS语法。
JMP是5字节(1字节操作码,4字节)的位移,所以。+4让我们在完成整个指令后立即进入RIP。
所以这只是我们静态调用的设置。让我们看看我们是如何实际安装带有static_call_update的函数的。
(2)Step 2: static_call_update
以下是static_call_update(x86_pmu_add,x86_pmu.add)的展开:
({
BUILD_BUG_ON(!__same_type(*(x86_pmu.add), __SCT__x86_pmu_add_tramp));
__static_call_update(&__SCK__x86_pmu_add, &__SCT__x86_pmu_add_tramp, x86_pmu.add);
})
在这段代码中,static_call_update(x86_pmu_add, x86_pmu.add)调用了__static_call_update函数来更新静态调用。
__static_call_update函数的实现如下:
static inline
void __static_call_update(struct static_call_key *key, void *tramp, void *func) {
cpus_read_lock();
WRITE_ONCE(key->func, func);
arch_static_call_transform(NULL, tramp, func, false);
cpus_read_unlock();
}
该函数的作用是更新静态调用的函数指针。它接受三个参数:key表示静态调用的键(key),tramp表示跳转函数的地址,func表示要安装的新函数的地址。
函数的执行过程如下:
(1)首先,通过调用cpus_read_lock()函数获取对CPU的读锁。这可能是为了确保在更新静态调用期间不会发生竞争条件。
(2)接下来,使用WRITE_ONCE宏将新函数的地址写入静态调用的函数指针。WRITE_ONCE宏是一种用于进行原子写操作的技术,确保指针的写入是原子的,以防止并发访问问题。
(3)然后,调用arch_static_call_transform函数,该函数是体系结构特定的函数,用于转换静态调用。它可能执行一些特定于体系结构的操作,以确保跳转函数正确地跳转到新函数。
(4)最后,通过调用cpus_read_unlock()函数释放CPU的读锁。
接下来是WRITE_ONCE宏定义的部分:
#define __WRITE_ONCE(x, val) \
do { \
*(volatile typeof(x) *)&(x) = (val); \
} while (0)
#define WRITE_ONCE(x, val) \
do { \
compiletime_assert_rwonce_type(x); \
__WRITE_ONCE(x, val); \
} while (0)
实际上,这只是对具有原子性的类型进行了一个带有volatile限定符的赋值操作。
接下来是arch_static_call_transform函数:
void arch_static_call_transform(void *site, void *tramp, void *func, bool tail)
{
mutex_lock(&text_mutex);
if (tramp) {
__static_call_validate(tramp, true);
__static_call_transform(tramp, __sc_insn(!func, true), func);
}
if (IS_ENABLED(CONFIG_HAVE_STATIC_CALL_INLINE) && site) {
__static_call_validate(site, tail);
__static_call_transform(site, __sc_insn(!func, tail), func);
}
mutex_unlock(&text_mutex);
}
mutex_lock和mutex_unlock只是为了确保没有其他人在修改内核的指令文本。同时,我们也在cpus_read_lock将我们的操作与CPU的热插拔或移除进行了序列化。
在本文中,我不会讨论CONFIG_HAVE_STATIC_CALL_INLINE,因为它与普通的静态调用机制非常相似,但是有更多的组件。因此,我们将假设该配置为false,并且该代码未编译。
__sc_insn函数将两个布尔值(func和tail)映射到insn_type枚举类型。两个布尔值意味着两个位,也就是说有四种可能的insn_type状态:
enum insn_type {
CALL = 0, /* site call */
NOP = 1, /* site cond-call */
JMP = 2, /* tramp / site tail-call */
RET = 3, /* tramp / site cond-tail-call */
};
static inline enum insn_type __sc_insn(bool null, bool tail)
{
/*
* Encode the following table without branches:
*
* tail null insn
* -----+-------+------
* 0 | 0 | CALL
* 0 | 1 | NOP
* 1 | 0 | JMP
* 1 | 1 | RET
*/
return 2*tail + null;
}
这将出现在测试中。
这将引入__static_call_validate函数,它验证我们的trampoline(跳板):
static void __static_call_validate(void *insn, bool tail)
{
u8 opcode = *(u8 *)insn;
if (tail) {
if (opcode == JMP32_INSN_OPCODE ||
opcode == RET_INSN_OPCODE)
return;
} else {
if (opcode == CALL_INSN_OPCODE ||
!memcmp(insn, ideal_nops[NOP_ATOMIC5], 5))
return;
}
/*
* If we ever trigger this, our text is corrupt, we'll probably not live long.
*/
WARN_ONCE(1, "unexpected static_call insn opcode 0x%x at %pS\n", opcode, insn);
}
请记住:对于我们来说,tail始终为true,因为我们没有启用CONFIG_HAVE_STATIC_CALL_INLINE。因此,insn始终是tramp,你可能还记得它是__SCT__x86_pmu_add_tramp,带有.byte 0xe9。
最后,__static_call_transform函数是真正发生魔法的地方(稍微精简了一下):
static void __ref __static_call_transform(void *insn, enum insn_type type, void *func)
{
int size = CALL_INSN_SIZE;
const void *code;
switch (type) {
case CALL:
code = text_gen_insn(CALL_INSN_OPCODE, insn, func);
break;
case NOP:
code = ideal_nops[NOP_ATOMIC5];
break;
case JMP:
code = text_gen_insn(JMP32_INSN_OPCODE, insn, func);
break;
case RET:
code = text_gen_insn(RET_INSN_OPCODE, insn, func);
size = RET_INSN_SIZE;
break;
}
if (memcmp(insn, code, size) == 0)
return;
if (unlikely(system_state == SYSTEM_BOOTING))
return text_poke_early(insn, code, size);
text_poke_bp(insn, code, size, NULL);
}
记得__sc_insn吗(我告诉过你!):对于我们来说,tail始终为true,因此我们唯一的选择是(1, 0)和(1, 1),即JMP和RET。这一点(再次)稍后会有影响,但是两种情况下的代码几乎相同,因此我们可以忽略差异。
在这两种情况下,我们调用text_gen_insn函数,它是世界上最简单的JIT12(稍微精简了一下):
union text_poke_insn {
u8 text[POKE_MAX_OPCODE_SIZE];
struct {
u8 opcode;
s32 disp;
} __attribute__((packed));
};
static __always_inline
void *text_gen_insn(u8 opcode, const void *addr, const void *dest)
{
static union text_poke_insn insn; /* per instance */
int size = text_opcode_size(opcode);
insn.opcode = opcode;
if (size > 1) {
insn.disp = (long)dest - (long)(addr + size);
if (size == 2) {
BUG_ON((insn.disp >> 31) != (insn.disp >> 7));
}
}
return &insn.text;
}
因此,我们的目标(即x86_pmu.add)成为了相对位移,就像我们在编译时生成的thunk中一样。
其余部分是机制:根据系统状态调用text_poke_early或text_poke_bp,但效果是相同的:我们的跳板(__SCT__x86_pmu_add_tramp)在内核内存中实际上被重写为:
jmp _x86_pmu_add
to:
jmp x86_pmu.add
…或者我们希望的任何其他函数,当然要允许类型匹配!
(3)Step 3: static_call_cond
最后,让我们弄清楚如何调用这个函数。
我们的实际调用是static_call_cond(x86_pmu_add)(event),就像名称所暗示的那样,在调用底层跳板之前应该进行一次检查,对吗?
#define static_call(name) __static_call(name)
#define static_call_cond(name) (void)__static_call(name)
这里定义了两个宏。static_call宏用于直接调用静态函数,而static_call_cond宏用于在调用之前进行条件检查,但忽略返回值。
好的!让我们再来看一下那个小小的__sc_insn表生成器:如果我们底层调用为NULL,那么我们已经生成并JIT了一个简单的RET指令到我们的跳板中。
现在让我们看一下__static_call宏的展开实际上是什么样的:
({
__ADDRESSABLE(__SCK__x86_pmu_add);
&__SCT__x86_pmu_add_tramp;
})
(__ADDRESSABLE只是另一种编译器的技巧,用于确保__SCK__x86_pmu_add保留在符号表中)。
这就是全部内容:我们实际的static_call宏最终调用了__SCT__x86_pmu_add_tramp,它要么是一个将我们引导到真实调用的跳板,要么只是一个RET指令,从而完成调用。
换句话说,汇编代码看起来有两种情况:
call __SCT__x86_pmu_add_tramp
; in call + trampoline
jmp x86_pmu.add
; out of trampoline, in target (x86_pmu.add)
; target eventually returns, completing the call
or:
call __SCK__x86_pmu_add
; in call + "trampoline"
ret ; "trampoline" returns, completing the call
三、其他
每个 static_call() 位置都调用与名称关联的跳板。跳板有一个直接跳转到默认函数。对名称的更新将修改跳板的跳转目标。
如果架构具有 CONFIG_HAVE_STATIC_CALL_INLINE,则调用站点本身将在运行时被修补为直接调用函数,而不是通过跳板调用。这需要 objtool 或编译器插件来检测所有 static_call() 位置并在 .static_call_sites 节中注释它们。
对于CONFIG_HAVE_STATIC_CALL_INLINE,按行计数该变更集占了相当大的比例。这是一种更加激进的转换方式:不是重新编写跳板,而是将每个调用跳板的调用点都重写为直接调用跳板的目标函数。这样可以节省一个JMP指令,据说这个性能差异足以成为一个单独的可配置特性。
更新:Peter Zijlstra解释说,CONFIG_HAVE_STATIC_CALL_INLINE的性能优势主要来自于减少的指令缓存压力:因为跳板是无条件的,CPU将始终预取它,占用一个缓存行。避免这种预取可以带来可衡量的性能提升!
我不确定WRITE_ONCE(__SCK__x86_pmu_add->func, x86_pmu.add)实际上起到了什么作用:它将函数指针的副本存储在我们的static_call_key中,但我们实际上从未使用过它(因为我们总是调用跳板,它直接在其中修补了函数的相对位移)。调用这个指针会破坏静态调用的整个目的,因为它将成为一个间接分支。有经验的猜测是:它只适用于!CONFIG_HAVE_STATIC_CALL情况,该情况下使用了通用的间接实现。但是,当我们有一个真正的静态调用实现可用时,为什么不完全摒弃static_call_key呢?
更新:Peter也解释了这一点:它只对!CONFIG_HAVE_STATIC_CALL情况有用。特别是,它防止编译器将存储拆分成多个存储。
我认为这里还有改进的空间,特别是放宽一些锁定要求:最大文本修补大小在POKE_MAX_OPCODE_SIZE == 5中硬编码,应该可以舒适地在x86_64上使用WRITE_ONCE进行原子写入。换句话说,我不确定为什么需要cpus_read_lock和对文本的锁定,尽管可能是我想得太简单了。
更新:显然,在评审过程中考虑过这一点。问题是:它引入了对齐要求,这反过来需要将NOP指令注入到指令流中。这又增加了指令缓存压力,破坏了性能优势。此外,对于这一点,Intel和AMD的规范不够明确也存在一些担忧。
参考资料
https://blog.yossarian.net/2020/12/16/Static-calls-in-Linux-5-10





![[游戏开发][UE5]引擎使用学习记录](https://img-blog.csdnimg.cn/direct/22cc94a396ad49b090ed5a0730463252.png)

