目录
技术选型决策阶段
发布订阅
自定义开发
Datax
Datax+废除主外键关系和自增ID
ER模型分组
废掉库表主外键
维度划分Datax任务
基于ID同步
基于TIME时间同步
基于全表ALL同步
废掉自增ID
DataX+废除主外键关系+手动拷贝
手动拷贝
Datax+任务分组+触发器
Datax全表
Datax增量同步
触发器
发布订阅+触发器
最终同步方案
原始库副本发布订阅
全触发器处理
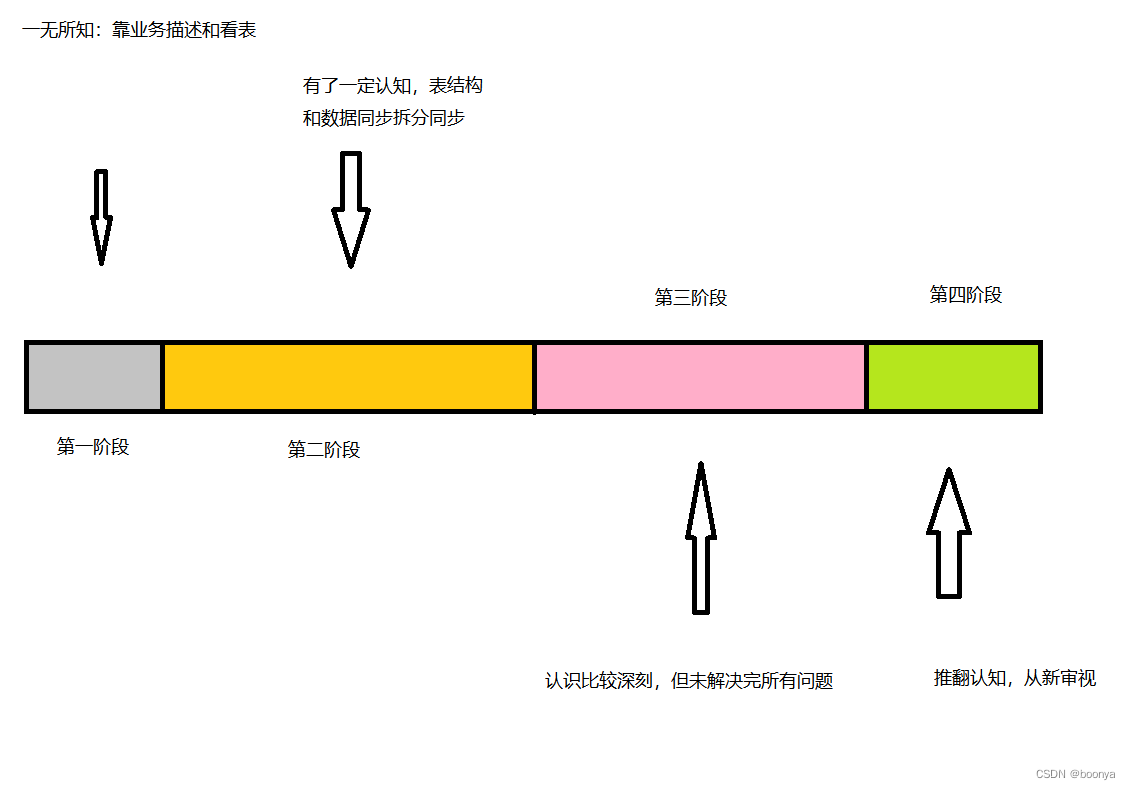
在手上目前有个Sqlserver数据同步的项目终于接近尾声了,投入过程两个人,历时跨度3年(2022-2024)。最开始决策采用阿里Datax实现数据同步+触发器编程的方式来实现。由于库表结构有严格的主外键,所以ER关系网络相当复杂,需要将这些任务进行分组处理。期间几易方案,执行方案中途都会发现问题。任务拆分几乎为零,想起什么写什么,导致项目几近放弃。
该项目大致经历了四个阶段。所以最终的结论是:数据同步一定要做好数据规范再行动,尽可能地发挥团队力量集思广益。
技术选型决策阶段
发布订阅
采用SqlServer本身的发布订阅模式就可以很好地保证数据同步和一致性了,发布SqlServer需要限制它的使用内存,否则服务器会无限占用直到内存耗尽。
它支持四种模式:快照发布、事务发布、具有可更新的事务发布、合并发布。一般我们配置事务发布就行了,可以实现一对一、一对多等发布订阅。
自定义开发
自定义开发有很大的自由度,可以按照自己企业的需求进行定制化开发,这也方便企业积累一些技术解决方案。最开的项目只是为了同步文件,后来要求数据也要同步,决策层要求使用Datax。所以Datax一直都是方案中的主角。
定制开发无疑就是按照需求将需要的数据和文件进行存储和更新,这些细节的东西这里就不讲述了。
Datax
DataX 是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
源码地址:GitHub - alibaba/DataX: DataX是阿里云DataWorks数据集成的开源版本。
对于不可变数据的定时同步Datax可以说在这方面很完美了,但是数据可变就不好操作了,时序问题、延迟问题就很麻烦。 有时候还需要对插件进行改造,比如插入失败尝试更新等等。以下是我们变更过的插件。
对Datax的JSON模板也做了扩展支持主外键模式:
reference:引用关系
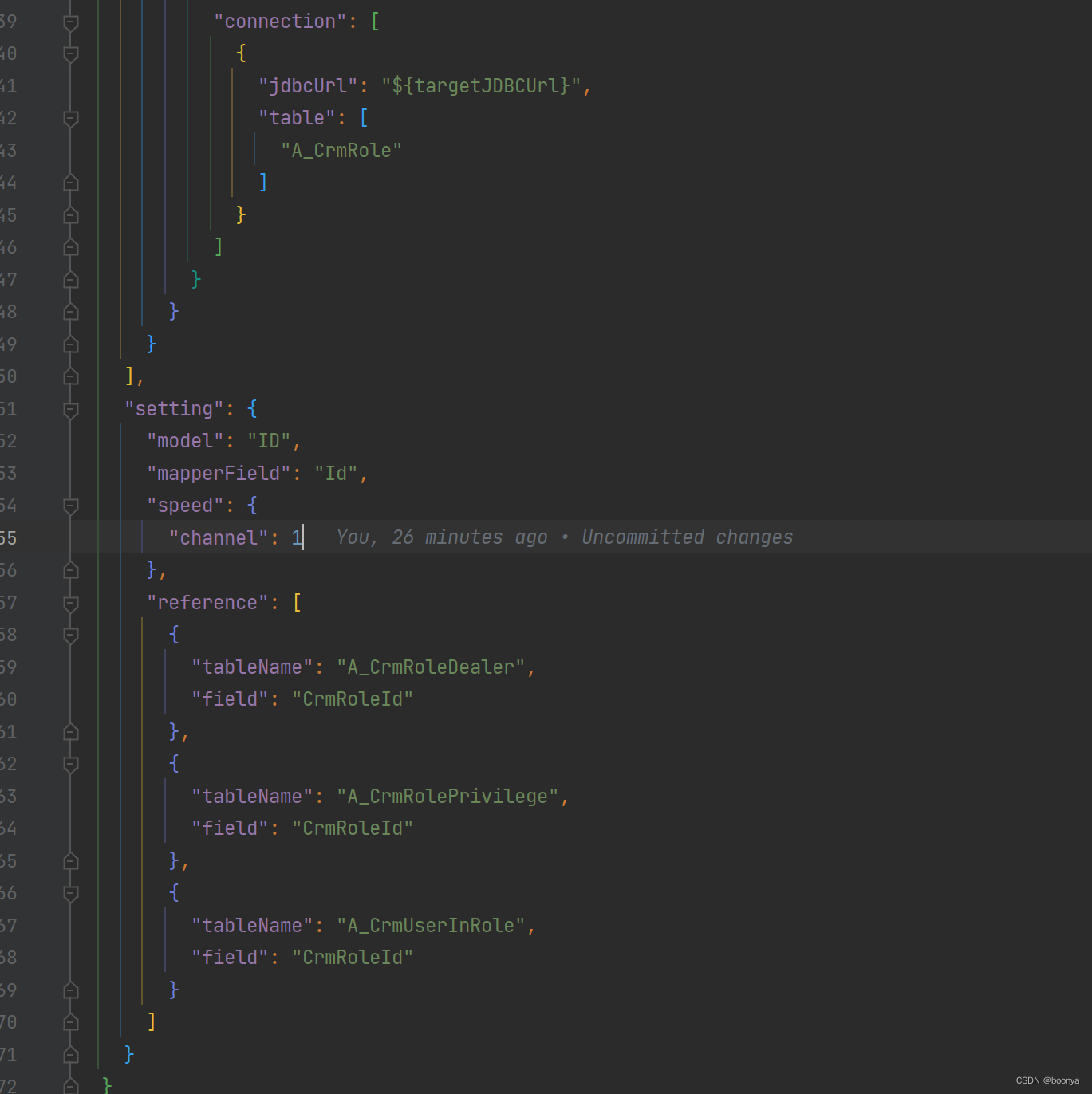
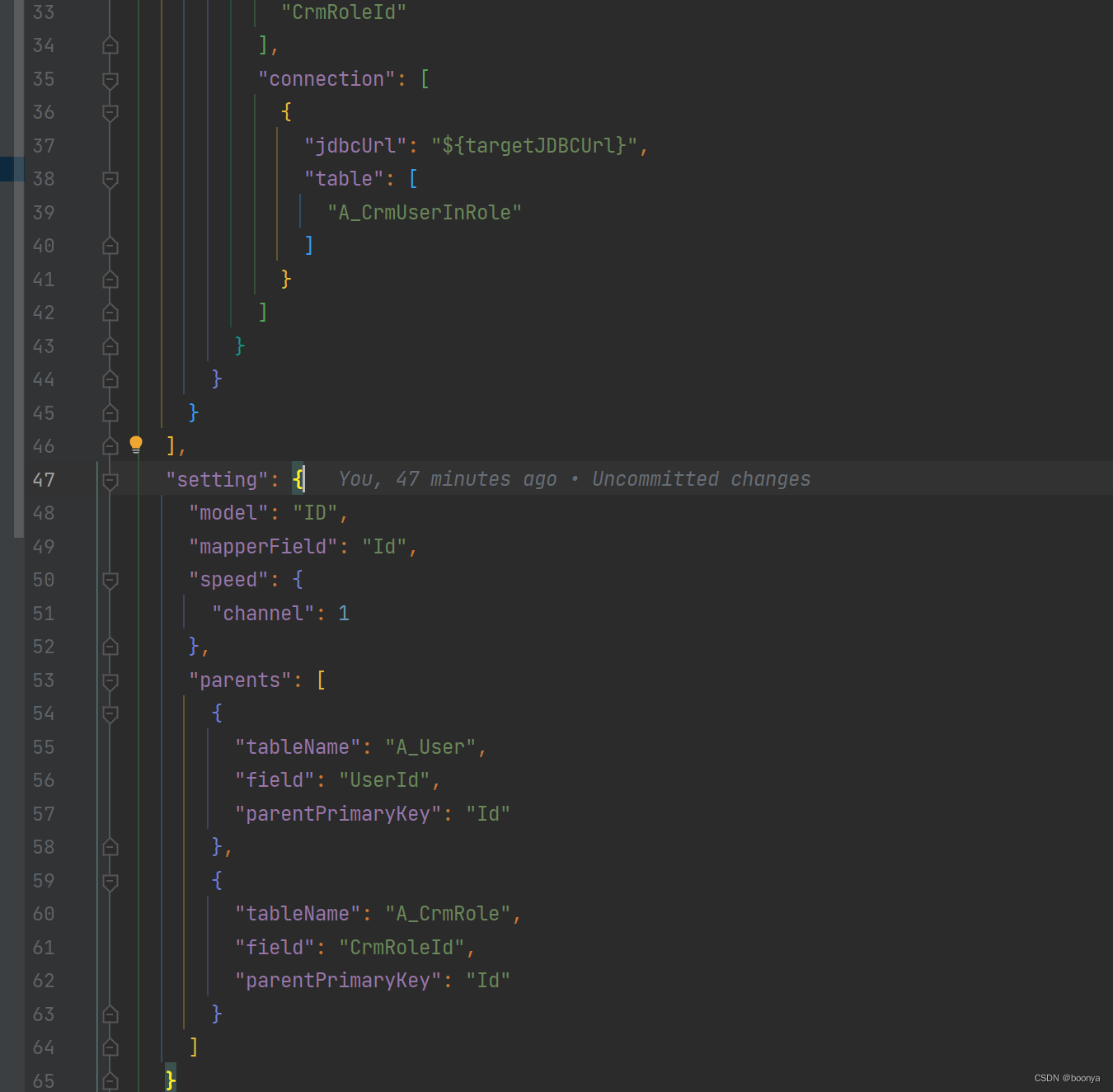
parents: 外键父表
Datax+废除主外键关系和自增ID
ER模型分组
由于原始项目并非基于Java开发,所以没有生成对应的实体。可以利用数据库实例的数据库关系图可以快速了解表的关系,下面是部分表的关系图谱。
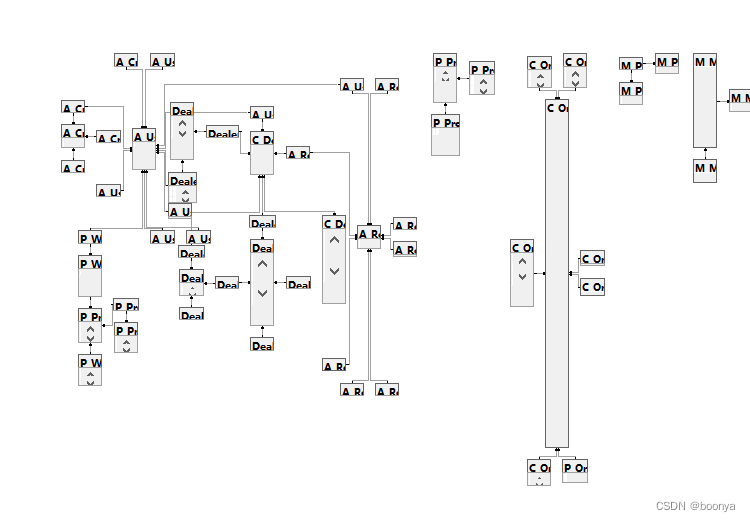
上图中有关系的表实际上是有严格插入顺序的,所以Datax在读取任务的时候需要将Json任务进行分组和优先级排序处理。
整理出来的关系按照文件夹进行分组:

文件夹内部的排序策略可以用字母和数字,一般将同一层级的放在一个文件夹下:

废掉库表主外键
将原始表的结构重新导出一份,去除掉主键和外键,以及自增ID,然后通过Datax跑存量数据,这种数据可能牵扯到更新,所以后期需要重新比对数据更新。
维度划分Datax任务
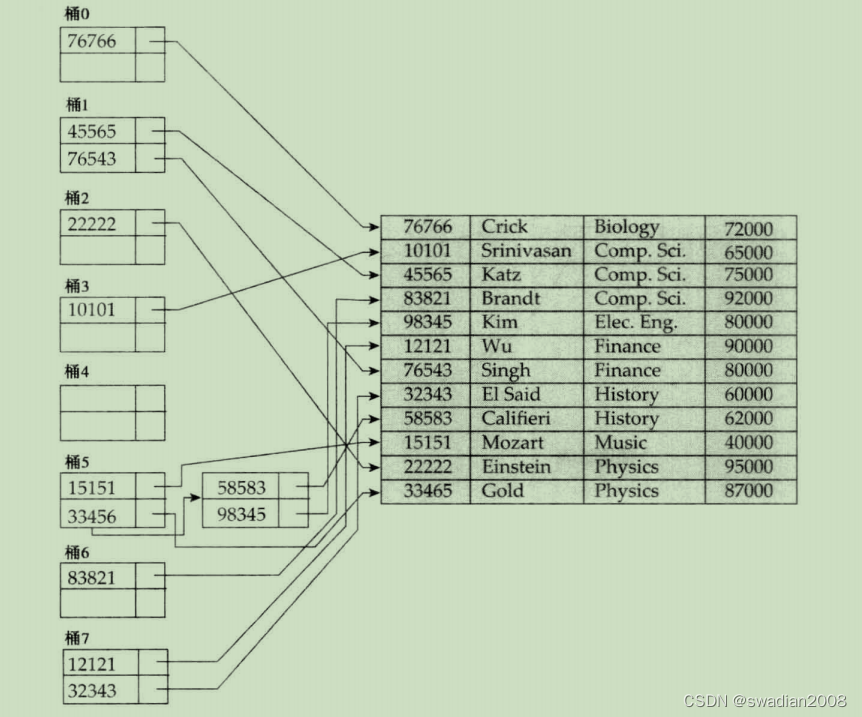
在同步的早期阶段,由于掌管业务数据库的同事描述有些需要根据ID、订单TIME和没有主键的表全表同步,所以将表任务的同步划分成了ID、TIME、ALL的维度进行同步。
基于ID同步
通过ID滑块进行Datax同步,设定迭代的ID区间,持续同步直到原始库和目标库数据一致。对于存量数据没有问题,但是涉及到数据的动态变化,此时没有考虑数据的变化。
基于TIME时间同步
通过TIME滑块进行Datax同步,设定迭代的TIME区间(订单的创建时间),持续同步直到原始库和目标库数据一致。对于存量数据没有问题,但是涉及到数据的动态变化,此时没有考虑数据的变化,以及特殊行业订单相关的数据会涉及大量的更新。
基于全表ALL同步
对于全表同步的这部分表,实际上是没有ID主键的表。现在回过头来,当时就应该从规范表结构做起,而不是对不规范臣服低头。一切数据源于规范才能有很强的可操作性。而Datax本身就是对异构数据规范化的同步。一切数据同步在于打平结构,规范输入和输出,这样才能节省时间和精力。
废掉自增ID
由于开始阶段对影响评估不足,导致目标库的ID和原始数据对不上,总数对上了,但是记录ID却完全不一样,使得我们的数据同步是不可靠的。于是只能废掉自增ID,重新开始同步。
DataX+废除主外键关系+手动拷贝
手动拷贝
由于在库表中存在大量的基础表,这些变化不是很频繁,所以决策层建议定期手动拷贝过去。但这样需要专人去处理,也时不合理的处理方式。一言堂的决策,有时候是拗不过的,所以就这样吧,无非Datax少建立一些任务而已。
Datax+任务分组+触发器
经历过主外键时序问题、主键自增问题之后,存量数据终于处理完了。对于业务数据的增量更新就提上日程了,这时候不得不说触发器就引入了。
最开始只做了update、delete类型的触发器操作,对于插入而言如果不及时,那么udpate和delete都是没有意义的。所以触发器执行不彻底也是导致数据不一致的根源,时序性很大程度依赖insert。
Datax全表
全表的处理无疑是这次数据同步的败笔,怎么说呢完全不需要这样处理。可以用ID代替,甚至后面TIME类型的都可以用ID模式去实现,只需要配置好表的逻辑先后优先级顺序。
Datax增量同步
datax的增量同步,目前好像还没有好的方式。虽然我们改造了Datax的同步插件,但是对于何时更新仍然只能靠触发器去拉起任务。除非深入去像SqlServer一样基于事务日志去做同步。
触发器
最终我们意识到,只能完全依赖触发器去处理结果集的同步,Datax仅仅作为任务表读取顺序存在。触发器的处理我们可以做到延迟1分钟以内。比如批量插入、批量更新、批量删除等等,以及数据一致性检查都可以保证数据最终一致性。
发布订阅+触发器
在使用原始库作为触发器时经常会遇到锁表的情况,触发器太多,有时候一个操作触发连锁反应,导致锁表影响工厂作业。所以我们考虑采用订阅副本上做触发器,然后同步到云上。
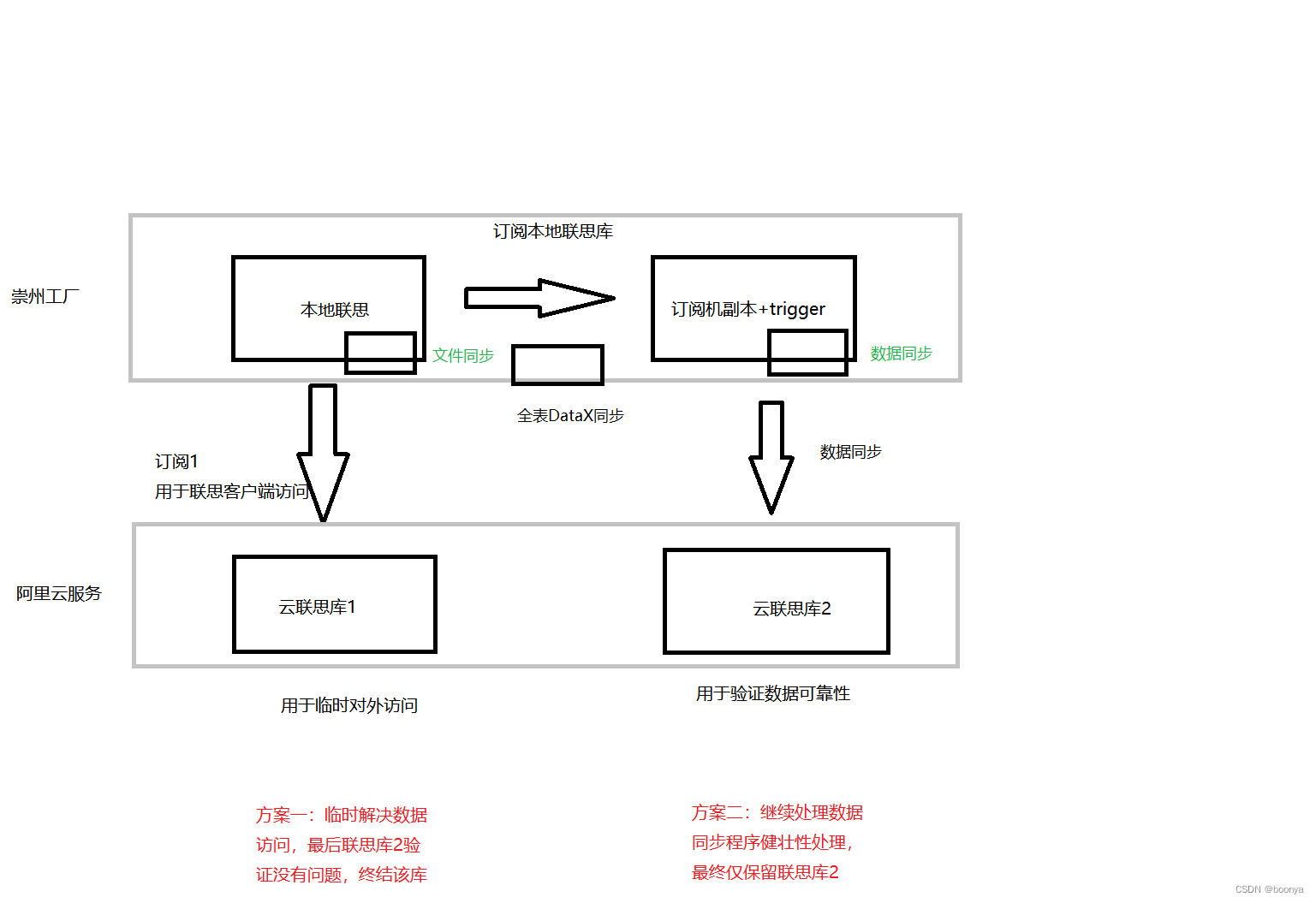
云上两个示例,也方便验证自定义数据同步的可靠性。
最终同步方案
分清楚数据同步阶段,对于定量数据不可变直接用Datax就够了,对于需要变更的加上触发器来处理。
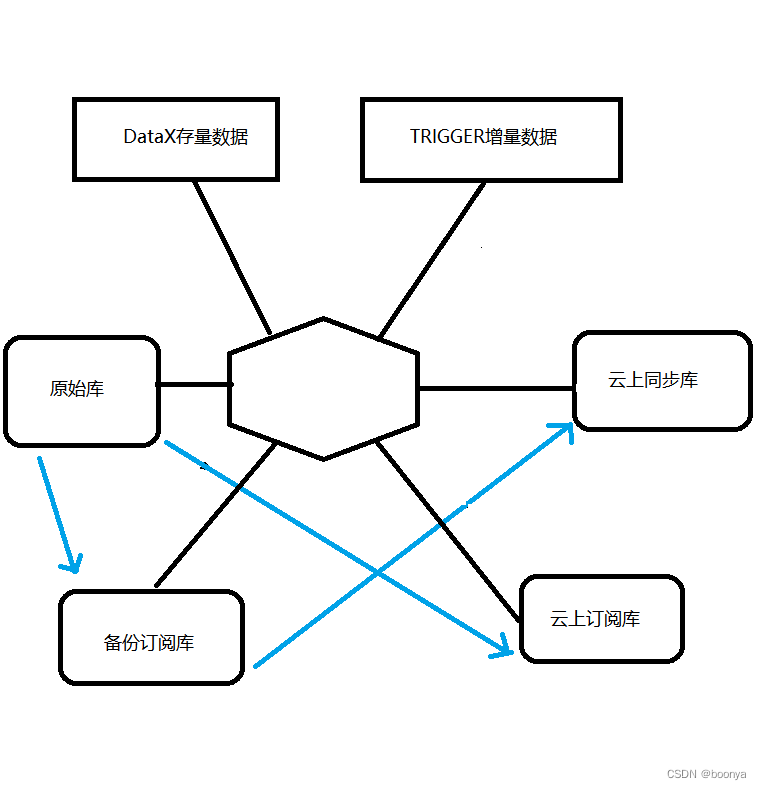
原始库副本发布订阅
在原始库上建立发布表配置,采用事务发布。然后在订阅副本用快照去订阅库表的数据同步,这样能够防止因为触发器而影响工厂作业,同时保证了内网数据的一致性,来源一致性。
全触发器处理
最终方案我们采用了全触发器操作,insert、update、delete以及数据校验不一致处理。在备份迁移的过程中还没有建立触发器,那么这段时间的数据更新也要检查出来进行同步更新。以下是文件和数据的触发器记录表。

所有的触发器都采用生产者消费者模式去处理,以insert的operateTime为基线,提高并发处理update和delete记录。最终我们能够保证延迟在一分钟以内,当然还取决于是否积压未消费是否有大批量插入等等。
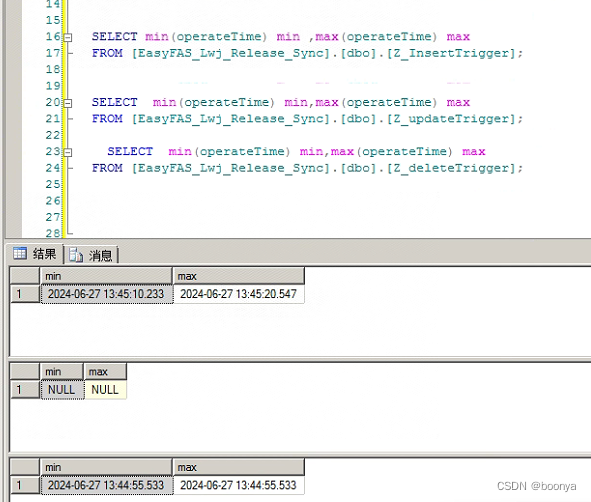
这个项目拖延至今,中间也是有不同的项目穿插,真花这么久没有结果问题就很严重了。期间还搞了文件同步,文件中转以及上阿里云OSS等等,都在这个项目中。方案整的磕磕巴巴,中转同步也是客户端不稳定等等,真的太耗费心力了。
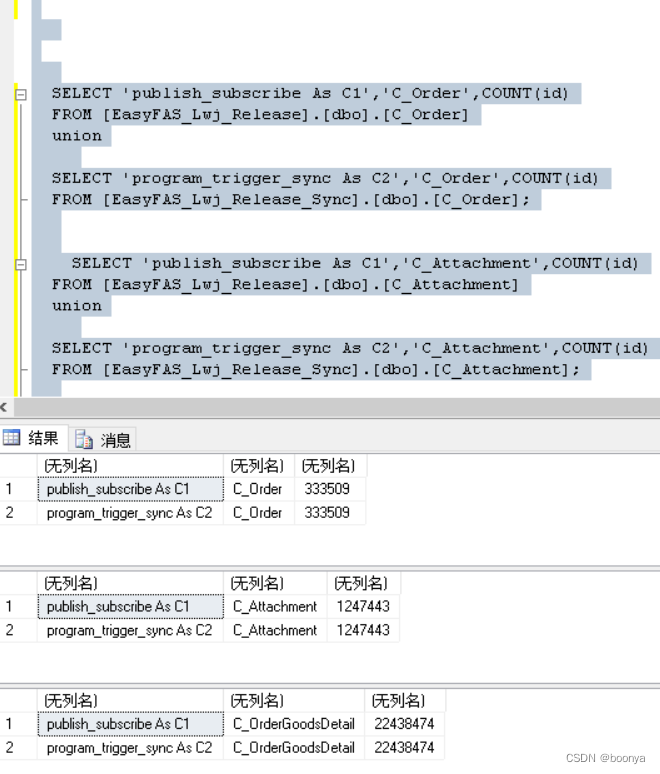
云上核心表同步效果: