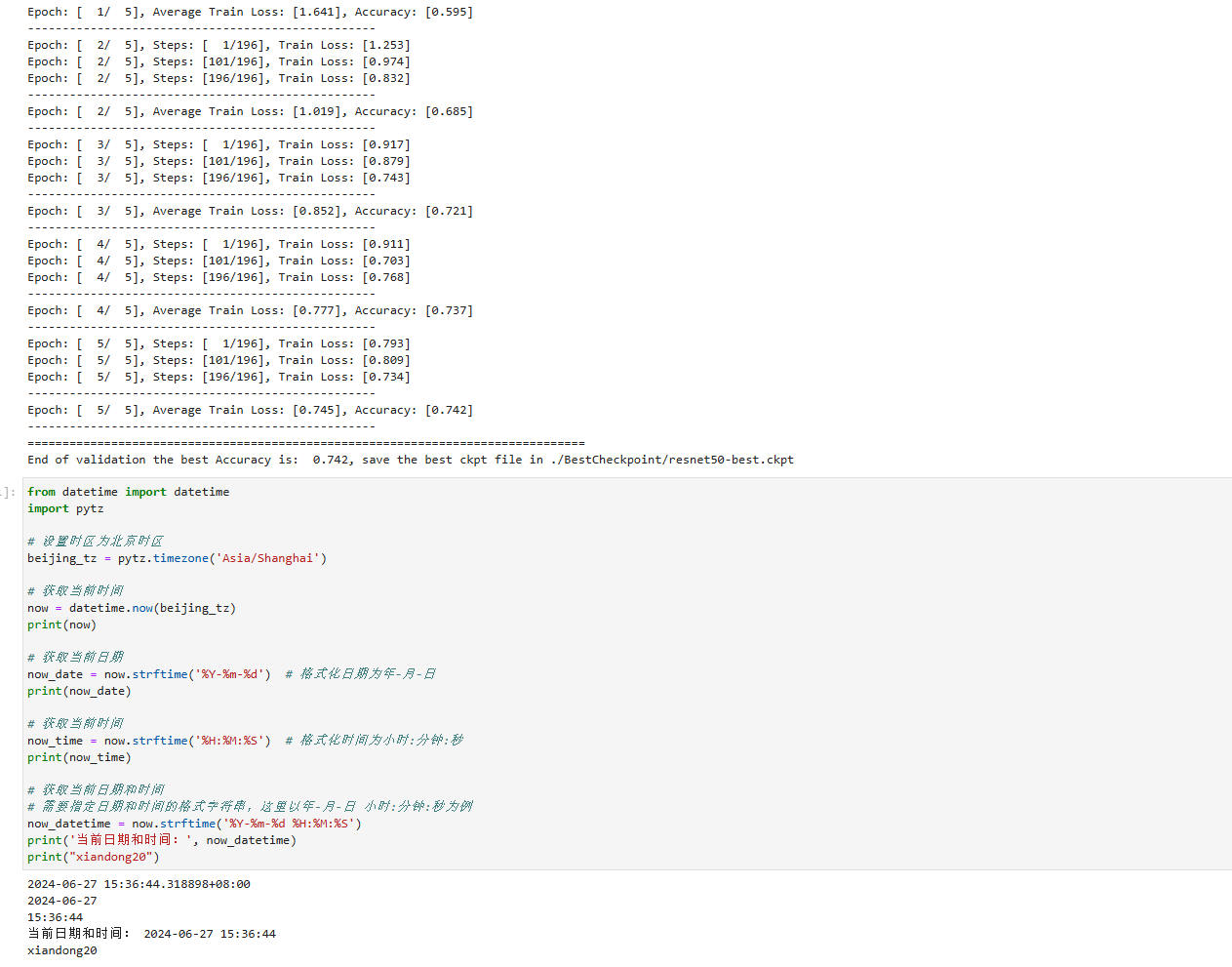
基于模型的特征选择使用一个监督机器学习模型来判断每个特征的重要性,并且仅保留最重要的特征。用于特征学习的监督模型不需要与用于最终建模的模型相同。特征选择模型需要为每个特征提供某种重要性度量,以便用这个度量对特征进行排序。决策树和基于决策树的模型提供了feature_importances_属性,可以直接编码每个特征的重要性。线性模型系数的绝对值也可以用于表示特征的重要性。之前学到过,L1惩罚的线性模型学到的是稀疏系数,它只用到了特征的一个很小的子集。这可以被视为模型本身的一种特征选择形式,但也可以用作另一个模型选择特征的预处理步骤。
与单变量选择不同,基于模型的选择同时考虑所有特征,因此可以获取交互项(如果模型能获取他们的话),想要使用基于模型的特征选择,需要使用SelectFromModel变换器:
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestClassifier
select=SelectFromModel(
RandomForestClassifier(n_estimators=100,random_state=42),threshold='median'
)
SelectFromModel类选出重要性度量(由监督模型提供)大于给定阈值的所有特征。为了得到可以与单变量特征选择进行对比的结果,我们使用中位数作为阈值,这样就可以选择一半特征。我们用包含100颗树的随机森林分类器来计算特征重要性。这是一个相当复杂的模型,也比单变量测试要强大得多。下面,实际拟合模型:
select.fit(X_train,y_train)
X_train_l1=select.transform(X_train)
print('训练集shape:{}'.format(X_train.shape))
print('训练集l1_shape:{}'.format(X_train_l1.shape))
可视化展示:
mask=select.get_support()
plt.matshow(mask.reshape(1,-1),cmap='gray_r')
plt.xlabel('Sample index')
plt.show()

这次,除了两个原始特征,其他原始特征都被选中。由于我们指定了40个特征,所以也选择了一些噪声特征。
来看一下性能:

从结果上看,利用更好的特征选择,性能也得到了提高。







![Grafana+Prometheus构建强大的监控系统-保姆级教程[监控linux、oracle]](https://img-blog.csdnimg.cn/img_convert/c6b9487a73135c000f55cbae588d32e3.png)