240627_昇思学习打卡-Day9-ResNet50图像分类
文章目录
- 240627_昇思学习打卡-Day9-ResNet50图像分类
- 前言
- 残差网络
- Residual Block代码实现
- Bottleneck Block代码实现
- BN层(Batch Normalization)
- 构建ResNet50网络
- 数据集准备与加载
- 模型训练与评估
- 可视化模型预测
前言
传统CNN网络均是由一系列卷积、池化、全连接层叠加而成,在反向传播过程中梯度往往是连乘得操作,这种情况下可能就会出现梯度消失或梯度爆炸的问题。
梯度消失:梯度小于1,小于1的数连乘后无限趋近于0。靠近输入层的参数w根本不动。
梯度爆炸:梯度大于1,大于1的数连乘后趋近于无穷。靠近输入层的参数w来回震荡。
出现这种情况后,往往添加神经网络的层数可能还不如浅层网络训练的效果好,这就制约了CNN的发展
注:图中情况不是过拟合,过拟合是训练集误差低,测试集误差高,这个情况是训练集和测试集上的误差均高于浅层网络
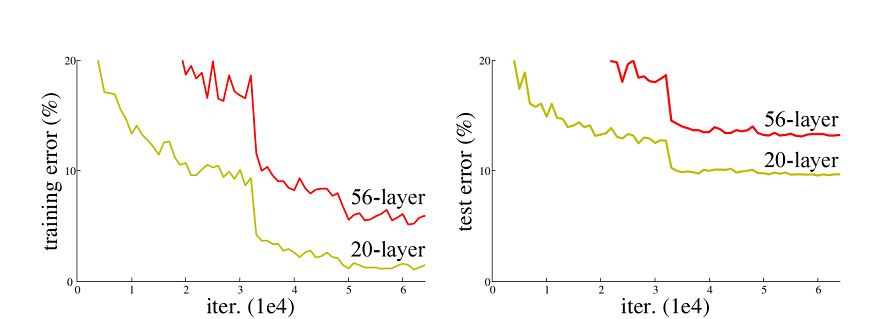
因此,2015年,何凯明大神提出了ResNet网络,在传统CNN中添加残差学习的思想。所谓残差学习,就是把上一层输出的结果拿来和这一层输出的结果进行加权求和
残差网络
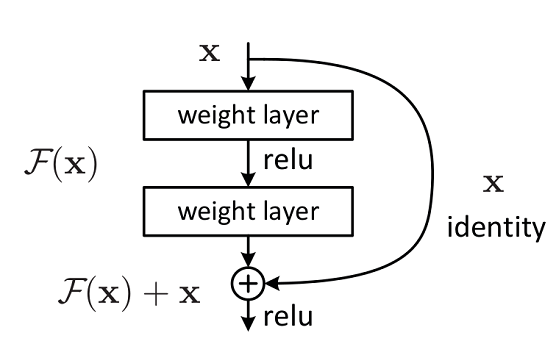
唉,传行内公式上来又乱码了,只能贴图了

可以这样类比:
当我们没有引入残差网络时,我们就相当于是开发项目时在源代码上修改代码,一旦修改错了,效果还不如原来,很难去复原源代码
当引入残差网络后,我们就相当于改项目之前把项目备份了一份,然后在项目副本上进行修改,这种情况下我们一旦改出什么纰漏,也可以和源代码进行对照。
残差网络结构主要有两种
左图是Residual Block,适用于较浅的ResNet网络,如ResNet18和ResNet34;
右图是Bottleneck Block,适用于层数较深的ResNet网络,如ResNet50、ResNet101和ResNet152。

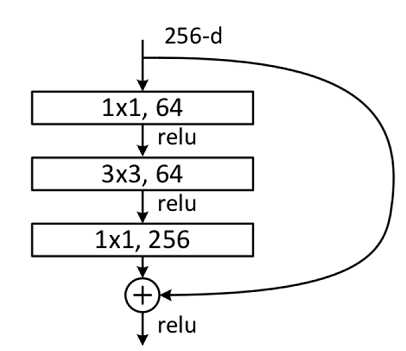
Residual Block主分支有两层卷积网络结构:
- 主分支第一层网络以输入channel为64为例,首先通过一个3×3的卷积层,然后通过Batch Normalization层,最后通过Relu激活函数层,输出channel为64;
- 主分支第二层网络的输入channel为64,首先通过一个3×3的卷积层,然后通过Batch Normalization层,输出channel为64。
最后将主分支输出的特征矩阵与shortcuts输出的特征矩阵相加,通过Relu激活函数即为Residual Block最后的输出。
Bottleneck Block主分支有三层卷积结构
分别为1×1的卷积层、3×3卷积层和1×1的卷积层,其中1×1的卷积层分别起降维和升维的作用。
- 主分支第一层网络以输入channel为256为例,首先通过数量为64,大小为1×1的卷积核进行降维,然后通过Batch Normalization层,最后通过Relu激活函数层,其输出channel为64;
- 主分支第二层网络通过数量为64,大小为3×3的卷积核提取特征,然后通过Batch Normalization层,最后通过Relu激活函数层,其输出channel为64;
- 主分支第三层通过数量为256,大小1×11×1的卷积核进行升维,然后通过Batch Normalization层,其输出channel为256。
最后将主分支输出的特征矩阵与shortcuts输出的特征矩阵相加,通过Relu激活函数即为Bottleneck Block最后的输出。
在输入相同的情况下Bottleneck Block结构相对Residual Block结构的参数数量更少,更适合层数较深的网络
主分支与shortcuts输出的特征矩阵相加时,需要保证主分支与shortcuts输出的特征矩阵shape相同(因为要加和)。如果主分支与shortcuts输出的特征矩阵shape不相同,如输出channel是输入channel的一倍时,shortcuts上需要使用数量与输出channel相等,大小为1×1的卷积核进行卷积操作;若输出的图像较输入图像缩小一倍,则要设置shortcuts中卷积操作中的stride(步长)为2,主分支第一层卷积操作的stride也需设置为2。
以下是以上两种结构的代码实现(在MindSpore框架上实现,其他框架理论相同):
Residual Block代码实现
from typing import Type, Union, List, Optional
import mindspore.nn as nn
from mindspore.common.initializer import Normal
# 初始化卷积层与BatchNorm的参数
# 使用正态分布初始化权重,以0为均值,0.02为标准差
# 初始化卷积层与BatchNorm的参数
weight_init = Normal(mean=0, sigma=0.02)
# 使用正态分布初始化gamma参数,以1为均值,0.02为标准差
gamma_init = Normal(mean=1, sigma=0.02)
class ResidualBlockBase(nn.Cell):
"""
Residual块的基类。
Residual块是深度学习模型中的一种结构,用于构建深度神经网络。该类定义了Residual块的基本结构,
包括两个卷积层、批量归一化和激活函数。子类可以通过重写构造函数和construct方法来定制具体的Residual块。
Attributes:
expansion: int,扩展率,用于计算输出通道数。
"""
expansion: int = 1 # 最后一个卷积核数量与第一个卷积核数量相等
def __init__(self, in_channel: int, out_channel: int,
stride: int = 1, norm: Optional[nn.Cell] = None,
down_sample: Optional[nn.Cell] = None) -> None:
"""
初始化ResidualBlockBase。
参数:
in_channel (int): 输入通道数。
out_channel (int): 输出通道数。
stride (int): 卷积的步长,默认为1。
norm (Optional[nn.Cell]): 批量归一化层,默认为None。
down_sample (Optional[nn.Cell]): 下采样层,默认为None。
"""
super(ResidualBlockBase, self).__init__()
# 如果没有提供批量归一化层,则使用默认的BatchNorm2d层
if not norm:
self.norm = nn.BatchNorm2d(out_channel)
else:
self.norm = norm
# 初始化第一个卷积层
self.conv1 = nn.Conv2d(in_channel, out_channel,
kernel_size=3, stride=stride,
weight_init=weight_init)
# 初始化第二个卷积层
self.conv2 = nn.Conv2d(in_channel, out_channel,
kernel_size=3, weight_init=weight_init)
self.relu = nn.ReLU()
self.down_sample = down_sample
def construct(self, x):
"""
构建Residual块的前向传播。
参数:
x: 输入数据。
返回:
经过Residual块处理后的输出数据。
"""
"""ResidualBlockBase construct."""
identity = x # shortcuts分支
out = self.conv1(x) # 主分支第一层:3*3卷积层
out = self.norm(out)
out = self.relu(out)
out = self.conv2(out) # 主分支第二层:3*3卷积层
out = self.norm(out)
# 如果存在下采样层,则对输入进行下采样
if self.down_sample is not None:
identity = self.down_sample(x)
# 将主分支输出与Shortcut(输入)相加
out += identity # 输出为主分支与shortcuts之和
out = self.relu(out)
return out
Bottleneck Block代码实现
# 定义ResidualBlock类,用于实现残差块
class ResidualBlock(nn.Cell):
# 定义扩张率,用于计算输出通道数
expansion = 4 # 最后一个卷积核的数量是第一个卷积核数量的4倍
# 初始化函数,设置输入通道数、输出通道数、步长和下采样函数
def __init__(self, in_channel: int, out_channel: int,
stride: int = 1, down_sample: Optional[nn.Cell] = None) -> None:
super(ResidualBlock, self).__init__()
# 初始化第一个1x1卷积层,用于减少输入通道数
self.conv1 = nn.Conv2d(in_channel, out_channel,
kernel_size=1, weight_init=weight_init)
# 初始化第一个批量归一化层
self.norm1 = nn.BatchNorm2d(out_channel)
# 初始化第二个3x3卷积层,用于增大特征图尺寸
self.conv2 = nn.Conv2d(out_channel, out_channel,
kernel_size=3, stride=stride,
weight_init=weight_init)
# 初始化第二个批量归一化层
self.norm2 = nn.BatchNorm2d(out_channel)
# 初始化第三个1x1卷积层,用于增加输出通道数
self.conv3 = nn.Conv2d(out_channel, out_channel * self.expansion,
kernel_size=1, weight_init=weight_init)
# 初始化第三个批量归一化层
self.norm3 = nn.BatchNorm2d(out_channel * self.expansion)
# 初始化激活函数为ReLU
self.relu = nn.ReLU()
# 初始化下采样函数,用于当输入和输出尺寸不同时进行下采样
self.down_sample = down_sample
# 构造函数,输入特征图x,输出残差学习后的特征图
def construct(self, x):
# 初始化identity为输入x,用于残差学习
identity = x # shortscuts分支
# 经过第一个卷积层和批量归一化层
out = self.conv1(x) # 主分支第一层:1*1卷积层
out = self.norm1(out)
out = self.relu(out)
# 经过第二个卷积层和批量归一化层
out = self.conv2(out) # 主分支第二层:3*3卷积层
out = self.norm2(out)
out = self.relu(out)
# 经过第三个卷积层和批量归一化层
out = self.conv3(out) # 主分支第三层:1*1卷积层
out = self.norm3(out)
# 如果存在下采样函数,则对输入x进行下采样
if self.down_sample is not None:
identity = self.down_sample(x)
# 将主分支输出和identity相加,实现残差学习
out += identity # 输出为主分支与shortcuts之和
out = self.relu(out)
# 返回残差学习后的特征图
return out
BN层(Batch Normalization)
在以上结构中,使用到了BN层,以下是BN层简要说明。(挖坑:有空写一个BN层详细讲解,文章最后已经附了一篇讲的比较好的BN层,想要深入研究可以参考这个大佬的)
Batch Normalization,翻译为“批归一化”,就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,这样做的意义在于更适合于后续的非线性激活函数(如sigmoid),至于为什么,后续详讲。
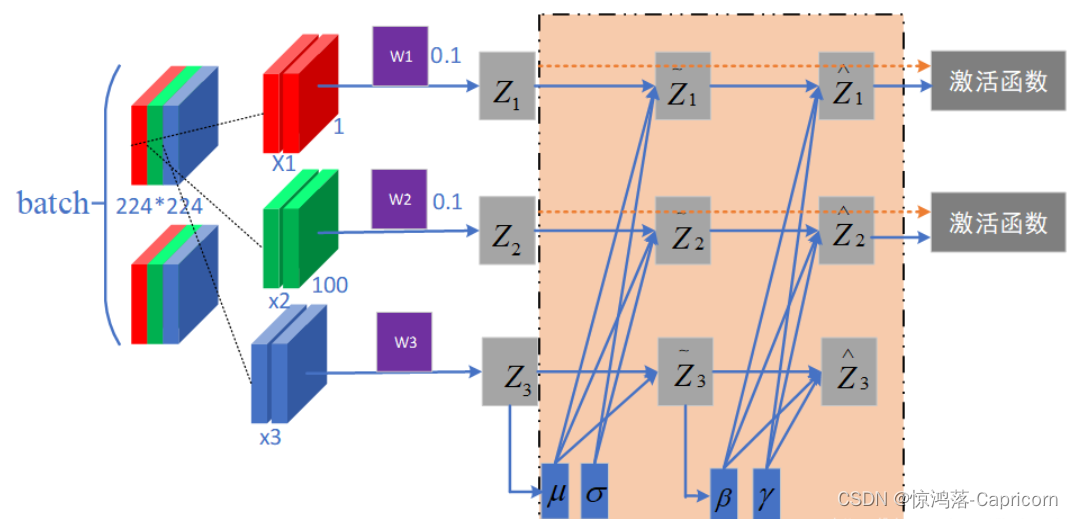
如图假如我们的batch size为2,此时载入两张三通道(RGB)的彩色图像,,然后把两张图的三个通道分别拿出来,相同的通道放在一起,求得对应均值和方差,然后用每个点的像素值减均值除方差得到该点归一化之后的像素值。
但这样操作会导致效果趋近于线性函数了,网络的表达能力就下降了。所以为了保证非线性的获得,对变换后的满足均值为0方差为1的x又进行了scale加上shift操作( y = s c a l e ∗ x + s h i f t y=scale*x+shift y=scale∗x+shift),每个神经元增加了两个参数scale和shift参数,这两个参数是通过训练学习到的,意思是通过scale和shift把这个值从标准正态分布左移或者右移一点并长胖一点或者变瘦一点,每个实例挪动的程度不一样,这样等价于非线性函数的值从正中心周围的线性区往非线性区动了动。
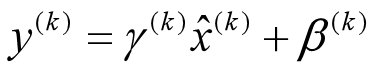
具体操作流程:

构建ResNet50网络
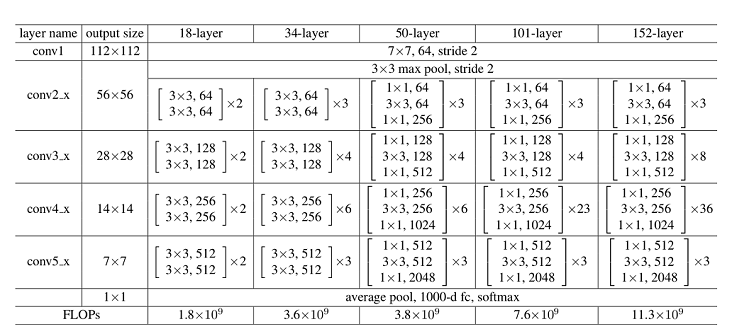
ResNet50网络共有5个卷积结构,一个平均池化层,一个全连接层,以CIFAR-10数据集为例:
- conv1:输入图片大小为 32 × 32 32\times32 32×32,输入channel为3。首先经过一个卷积核数量为64,卷积核大小为 7 × 7 7\times7 7×7,stride为2的卷积层;然后通过一个Batch Normalization层;最后通过Relu激活函数。该层输出feature map大小为 16 × 16 16\times16 16×16,输出channel为64。
- conv2_x:输入feature map大小为 16 × 16 16\times16 16×16,输入channel为64。首先经过一个卷积核大小为 3 × 3 3\times3 3×3,stride为2的最大下采样池化操作;然后堆叠3个 [ 1 × 1 , 64 ; 3 × 3 , 64 ; 1 × 1 , 256 ] [1\times1,64;3\times3,64;1\times1,256] [1×1,64;3×3,64;1×1,256]结构的Bottleneck。该层输出feature map大小为 8 × 8 8\times8 8×8,输出channel为256。
- conv3_x:输入feature map大小为 8 × 8 8\times8 8×8,输入channel为256。该层堆叠4个[1×1,128;3×3,128;1×1,512]结构的Bottleneck。该层输出feature map大小为 4 × 4 4\times4 4×4,输出channel为512。
- conv4_x:输入feature map大小为 4 × 4 4\times4 4×4,输入channel为512。该层堆叠6个[1×1,256;3×3,256;1×1,1024]结构的Bottleneck。该层输出feature map大小为 2 × 2 2\times2 2×2,输出channel为1024。
- conv5_x:输入feature map大小为 2 × 2 2\times2 2×2,输入channel为1024。该层堆叠3个[1×1,512;3×3,512;1×1,2048]结构的Bottleneck。该层输出feature map大小为 1 × 1 1\times1 1×1,输出channel为2048。
- average pool & fc:输入channel为2048,输出channel为分类的类别数。
如下示例定义make_layer实现残差块的构建
def make_layer(last_out_channel, block: Type[Union[ResidualBlockBase, ResidualBlock]],
channel: int, block_nums: int, stride: int = 1):
"""
创建一个由多个残差块组成的层。
该函数根据输入参数构建一个包含多个相同类型残差块的层。如果当前层的步长不为1或输入通道数与输出通道数不同,
则会添加一个下采样层。下采样层用于将输入特征图的尺寸调整到与残差块输出相同的尺寸,以保持维度匹配。
参数:
last_out_channel: 前一层的输出通道数。
block: 残差块的类型,可以是ResidualBlockBase或ResidualBlock。
channel: 当前层的输出通道数。
block_nums: 当前层中残差块的数量。
stride: 当前层的步长,默认为1。
返回:
一个由多个残差块组成的SequentialCell实例。
"""
down_sample = None # shortcuts分支
# 根据步长和通道数是否变化决定是否需要添加下采样层
if stride != 1 or last_out_channel != channel * block.expansion:
# 使用1x1卷积和批量归一化创建下采样层
down_sample = nn.SequentialCell([
nn.Conv2d(last_out_channel, channel * block.expansion,
kernel_size=1, stride=stride, weight_init=weight_init),
nn.BatchNorm2d(channel * block.expansion, gamma_init=gamma_init)
])
# 初始化第一个残差块,可能包含下采样
layers = []
layers.append(block(last_out_channel, channel, stride=stride, down_sample=down_sample))
# 更新输入通道数为当前层的输出通道数
in_channel = channel * block.expansion
# 堆叠剩余的残差块
# 堆叠残差网络
for _ in range(1, block_nums):
layers.append(block(in_channel, channel))
# 返回包含所有残差块的序列模型
return nn.SequentialCell(layers)
如下示例代码实现ResNet50模型的构建,通过用调函数resnet50即可构建ResNet50模型
from mindspore import load_checkpoint, load_param_into_net
# 定义ResNet网络类
class ResNet(nn.Cell):
"""
ResNet网络类。
ResNet(Residual Network)是一种深度神经网络结构,通过引入残差连接解决了深度网络中的梯度消失和爆炸问题。
参数:
- block: 残差块的类型,可以是ResidualBlockBase或ResidualBlock。
- layer_nums: 每个阶段(layer)的残差块数量列表。
- num_classes: 分类的类别数量。
- input_channel: 输入通道的数量。
"""
def __init__(self, block: Type[Union[ResidualBlockBase, ResidualBlock]],
layer_nums: List[int], num_classes: int, input_channel: int) -> None:
super(ResNet, self).__init__()
# 引入ReLU激活函数
self.relu = nn.ReLU()
# 初始化第一个卷积层
# 第一个卷积层,输入channel为3(彩色图像),输出channel为64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, weight_init=weight_init)
# 初始化批量归一化层
self.norm = nn.BatchNorm2d(64)
# 初始化最大池化层
# 最大池化层,缩小图片的尺寸
self.max_pool = nn.MaxPool2d(kernel_size=3, stride=2, pad_mode='same')
# 通过make_layer函数构建网络的四个主要层
# 各个残差网络结构块定义
self.layer1 = make_layer(64, block, 64, layer_nums[0])
self.layer2 = make_layer(64 * block.expansion, block, 128, layer_nums[1], stride=2)
self.layer3 = make_layer(128 * block.expansion, block, 256, layer_nums[2], stride=2)
self.layer4 = make_layer(256 * block.expansion, block, 512, layer_nums[3], stride=2)
# 初始化全局平均池化层
# 平均池化层
self.avg_pool = nn.AvgPool2d()
# 初始化展平层,用于将二维特征图展平为一维向量
# flattern层
self.flatten = nn.Flatten()
# 初始化全连接层,用于分类
# 全连接层
self.fc = nn.Dense(in_channels=input_channel, out_channels=num_classes)
# 定义前向传播方法
def construct(self, x):
"""
前向传播方法。
参数:
- x: 输入数据。
返回:
- 输出数据。
"""
# 经过第一个卷积层
x = self.conv1(x)
# 经过批量归一化层
x = self.norm(x)
# 经过ReLU激活函数
x = self.relu(x)
# 经过最大池化层
x = self.max_pool(x)
# 经过四个残差层
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
# 经过全局平均池化层
x = self.avg_pool(x)
# 展平特征图
x = self.flatten(x)
# 经过全连接层
x = self.fc(x)
return x
def _resnet(model_url: str, block: Type[Union[ResidualBlockBase, ResidualBlock]],
layers: List[int], num_classes: int, pretrained: bool, pretrained_ckpt: str,
input_channel: int):
"""
构建ResNet模型。
参数:
model_url: 模型下载地址。
block: ResNet中的残差块类型。
layers: 每个阶段的残差块数量列表。
num_classes: 输出类别数量。
pretrained: 是否使用预训练模型。
pretrained_ckpt: 预训练模型的存储路径。
input_channel: 输入通道数量。
返回:
构建好的ResNet模型。
"""
# 初始化ResNet模型
model = ResNet(block, layers, num_classes, input_channel)
# 如果需要预训练模型
if pretrained:
# 加载预训练模型
# 加载预训练模型
download(url=model_url, path=pretrained_ckpt, replace=True)
param_dict = load_checkpoint(pretrained_ckpt)
# 将预训练参数加载到模型中
load_param_into_net(model, param_dict)
return model
def resnet50(num_classes: int = 1000, pretrained: bool = False):
"""
构建ResNet-50模型。
参数:
num_classes: 输出类别数量,默认为1000。
pretrained: 是否使用预训练模型,默认为False。
返回:
构建好的ResNet-50模型。
"""
"""ResNet50模型"""
# 定义ResNet-50的预训练模型地址和存储路径
resnet50_url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/models/application/resnet50_224_new.ckpt"
resnet50_ckpt = "./LoadPretrainedModel/resnet50_224_new.ckpt"
# 调用_resnet函数构建ResNet-50模型
return _resnet(resnet50_url, ResidualBlock, [3, 4, 6, 3], num_classes,
pretrained, resnet50_ckpt, 2048)
以下我们使用ResNet50网络完成一个CIFAR-10分类任务:
数据集准备与加载
CIFAR-10数据集共有60000张32*32的彩色图像,分为10个类别,每类有6000张图,数据集一共有50000张训练图片和10000张评估图片。首先,如下示例使用download接口下载并解压,目前仅支持解析二进制版本的CIFAR-10文件(CIFAR-10 binary version)。
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/cifar-10-binary.tar.gz"
download(url, "./datasets-cifar10-bin", kind="tar.gz", replace=True)
下载后的数据集目录结构如下:
datasets-cifar10-bin/cifar-10-batches-bin
├── batches.meta.text
├── data_batch_1.bin
├── data_batch_2.bin
├── data_batch_3.bin
├── data_batch_4.bin
├── data_batch_5.bin
├── readme.html
└── test_batch.bin
然后,使用mindspore.dataset.Cifar10Dataset接口来加载数据集,并进行相关图像增强操作。
import mindspore as ms
import mindspore.dataset as ds
import mindspore.dataset.vision as vision
import mindspore.dataset.transforms as transforms
from mindspore import dtype as mstype
data_dir = "./datasets-cifar10-bin/cifar-10-batches-bin" # 数据集根目录
batch_size = 256 # 批量大小
image_size = 32 # 训练图像空间大小
workers = 4 # 并行线程个数
num_classes = 10 # 分类数量
def create_dataset_cifar10(dataset_dir, usage, resize, batch_size, workers):
"""
创建并返回CIFAR-10数据集。
根据指定的使用用途(训练或测试)、图像大小、批量大小和工作线程数,配置并返回CIFAR-10数据集。
对于训练数据集,应用了数据增强技术,包括随机裁剪和水平翻转,以提高模型的泛化能力。
对于所有数据,都进行了图像大小调整、重新缩放、归一化和通道顺序转换等预处理操作。
参数:
- dataset_dir: 数据集目录。
- usage: 数据集的使用用途,可以是"train"(训练)或"test"(测试)。
- resize: 图像要调整到的大小。
- batch_size: 每个批次的样本数量。
- workers: 数据预处理的工作线程数。
返回:
- 经过配置和预处理的CIFAR-10数据集。
"""
# 从指定目录加载CIFAR-10数据集,指定使用用途和并行工作线程数,以及启用数据打乱
data_set = ds.Cifar10Dataset(dataset_dir=dataset_dir,
usage=usage,
num_parallel_workers=workers,
shuffle=True)
# 定义数据预处理变换列表
trans = []
# 如果是训练数据集,则应用数据增强技术
if usage == "train":
# 随机裁剪图像和随机水平翻转,增加模型的泛化能力
trans += [
vision.RandomCrop((32, 32), (4, 4, 4, 4)),
vision.RandomHorizontalFlip(prob=0.5)
]
# 对所有数据进行图像大小调整、重新缩放、归一化和通道顺序转换等预处理操作
trans += [
vision.Resize(resize),
vision.Rescale(1.0 / 255.0, 0.0),
vision.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010]),
vision.HWC2CHW()
]
# 将标签转换为整型
target_trans = transforms.TypeCast(mstype.int32)
# 对图像数据应用预处理变换
# 数据映射操作
data_set = data_set.map(operations=trans,
input_columns='image',
num_parallel_workers=workers)
# 对标签数据应用类型转换变换
data_set = data_set.map(operations=target_trans,
input_columns='label',
num_parallel_workers=workers)
# 将数据集划分为指定大小的批次
# 批量操作
data_set = data_set.batch(batch_size)
return data_set
# 创建并加载训练数据集
# 获取处理后的训练与测试数据集
dataset_train = create_dataset_cifar10(dataset_dir=data_dir,
usage="train",
resize=image_size,
batch_size=batch_size,
workers=workers)
# 计算训练数据集的总步数
step_size_train = dataset_train.get_dataset_size()
# 创建并加载测试数据集
dataset_val = create_dataset_cifar10(dataset_dir=data_dir,
usage="test",
resize=image_size,
batch_size=batch_size,
workers=workers)
# 计算测试数据集的总步数
step_size_val = dataset_val.get_dataset_size()
对CIFAR-10训练数据集进行可视化。
# 导入matplotlib.pyplot库用于绘图
import matplotlib.pyplot as plt
# 导入numpy库用于处理数组
import numpy as np
# 获取数据集的迭代器,并提取第一个数据块
data_iter = next(dataset_train.create_dict_iterator())
# 提取图像数据和标签,并转换为numpy数组
images = data_iter["image"].asnumpy()
labels = data_iter["label"].asnumpy()
# 打印图像和标签的形状
print(f"Image shape: {images.shape}, Label shape: {labels.shape}")
# 打印前六个标签值
# 训练数据集中,前六张图片所对应的标签
print(f"Labels: {labels[:6]}")
# 初始化类别列表,用于存储类别名称
classes = []
# 读取类别信息文件,并填充类别列表
with open(data_dir + "/batches.meta.txt", "r") as f:
for line in f:
line = line.rstrip()
if line:
classes.append(line)
# 初始化matplotlib画图窗口
plt.figure()
# 循环处理前六张图片
for i in range(6):
# 设置子图,每个子图对应一张图片
plt.subplot(2, 3, i + 1)
# 调整图像数据格式,并进行归一化处理
# 对images列表中索引为i的图像进行转置操作。转置后的维度顺序为(高, 宽, 颜色通道),即将颜色通道维度移动到最后
image_trans = np.transpose(images[i], (1, 2, 0))
mean = np.array([0.4914, 0.4822, 0.4465])
std = np.array([0.2023, 0.1994, 0.2010])
image_trans = std * image_trans + mean
image_trans = np.clip(image_trans, 0, 1)
# 设置图片标题为对应的类别名称
plt.title(f"{classes[labels[i]]}")
# 显示处理后的图片
plt.imshow(image_trans)
# 关闭子图的坐标轴显示
plt.axis("off")
# 显示所有子图
plt.show()

模型训练与评估
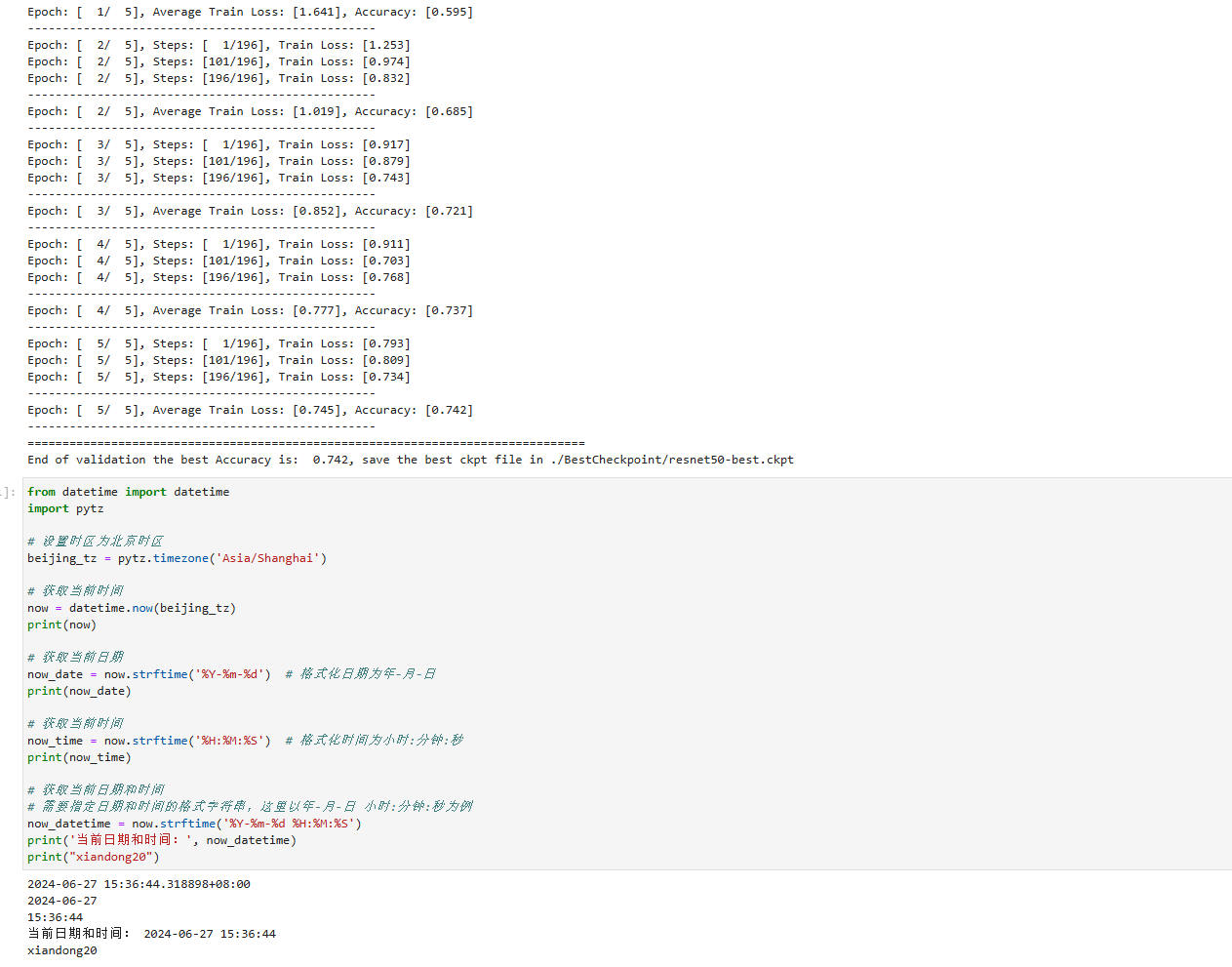
本节使用ResNet50预训练模型进行微调。调用resnet50构造ResNet50模型,并设置pretrained参数为True,将会自动下载ResNet50预训练模型,并加载预训练模型中的参数到网络中。然后定义优化器和损失函数,逐个epoch打印训练的损失值和评估精度,并保存评估精度最高的ckpt文件(resnet50-best.ckpt)到当前路径的./BestCheckPoint下。
由于预训练模型全连接层(fc)的输出大小(对应参数num_classes)为1000, 为了成功加载预训练权重,我们将模型的全连接输出大小设置为默认的1000。CIFAR10数据集共有10个分类,在使用该数据集进行训练时,需要将加载好预训练权重的模型全连接层输出大小重置为10。
此处我们展示了5个epochs的训练过程,如果想要达到理想的训练效果,建议训练80个epochs。
# 初始化ResNet50模型,使用预训练的权重
# 定义ResNet50网络
network = resnet50(pretrained=True)
# 获取ResNet50模型最后一层(全连接层)的输入通道数
# 全连接层输入层的大小
in_channel = network.fc.in_channels
# 替换原模型的全连接层为新的全连接层,用于分类任务
# 新的全连接层有in_channel个输入通道,10个输出通道(类别数)
fc = nn.Dense(in_channels=in_channel, out_channels=10)
# 重置全连接层
network.fc = fc
# 设置学习率衰减策略,使用余弦退火算法
# 设置学习率
num_epochs = 5
lr = nn.cosine_decay_lr(min_lr=0.00001, max_lr=0.001, total_step=step_size_train * num_epochs,
step_per_epoch=step_size_train, decay_epoch=num_epochs)
# 初始化优化器,使用动量优化算法
# 定义优化器和损失函数
opt = nn.Momentum(params=network.trainable_params(), learning_rate=lr, momentum=0.9)
# 定义损失函数,使用softmax交叉熵作为分类任务的损失函数
loss_fn = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
# 定义前向传播函数,用于计算模型预测的损失
def forward_fn(inputs, targets):
logits = network(inputs)
loss = loss_fn(logits, targets)
return loss
# 获取模型参数的梯度函数,用于计算损失对参数的梯度
grad_fn = ms.value_and_grad(forward_fn, None, opt.parameters)
# 定义训练步骤函数,包括前向传播、计算梯度和参数更新
def train_step(inputs, targets):
loss, grads = grad_fn(inputs, targets)
opt(grads)
return loss
# 导入操作系统模块,用于后续检查和创建目录
import os
# 初始化训练和验证数据加载器
# 创建迭代器
data_loader_train = dataset_train.create_tuple_iterator(num_epochs=num_epochs)
data_loader_val = dataset_val.create_tuple_iterator(num_epochs=num_epochs)
# 初始化最佳精度为0,用于记录模型训练过程中的最佳精度
# 最佳模型存储路径
best_acc = 0
# 定义最佳模型的保存目录
best_ckpt_dir = "./BestCheckpoint"
# 定义最佳模型的保存路径
best_ckpt_path = "./BestCheckpoint/resnet50-best.ckpt"
# 检查最佳模型保存目录是否存在,如果不存在则创建
if not os.path.exists(best_ckpt_dir):
os.mkdir(best_ckpt_dir)
import mindspore.ops as ops
def train(data_loader, epoch):
"""
训练模型。
参数:
- data_loader: 数据加载器,用于遍历训练数据。
- epoch: 当前训练的epoch数。
返回:
- train_loss: 训练过程中的平均损失。
"""
"""模型训练"""
losses = []
network.set_train(True) # 设置网络为训练模式
for i, (images, labels) in enumerate(data_loader):
loss = train_step(images, labels) # 执行一个训练步骤
if i % 100 == 0 or i == step_size_train - 1:
# 每隔100步或在训练步骤的最后打印训练损失
print('Epoch: [%3d/%3d], Steps: [%3d/%3d], Train Loss: [%5.3f]' %
(epoch + 1, num_epochs, i + 1, step_size_train, loss))
losses.append(loss)
return sum(losses) / len(losses)
def evaluate(data_loader):
"""
评估模型的性能。
参数:
- data_loader: 数据加载器,用于遍历评估数据。
返回:
- acc: 模型在评估数据集上的准确率。
"""
"""模型验证"""
network.set_train(False) # 设置网络为评估模式
correct_num = 0.0 # 预测正确个数
total_num = 0.0 # 预测总数
for images, labels in data_loader:
logits = network(images) # 获取模型的预测结果
pred = logits.argmax(axis=1) # 获取预测类别
correct = ops.equal(pred, labels).reshape((-1, )) # 判断预测是否正确
correct_num += correct.sum().asnumpy() # 累加正确数目
total_num += correct.shape[0] # 累加总数
acc = correct_num / total_num # 计算准确率
return acc
# 开始循环训练
print("Start Training Loop ...")
# 对每个训练轮次进行迭代
for epoch in range(num_epochs):
# 在训练集上进行训练,并返回当前轮次的损失值
curr_loss = train(data_loader_train, epoch)
# 在验证集上进行评估,并返回当前轮次的准确率
curr_acc = evaluate(data_loader_val)
# 打印训练进度和当前轮次的损失及准确率
print("-" * 50)
print("Epoch: [%3d/%3d], Average Train Loss: [%5.3f], Accuracy: [%5.3f]" % (
epoch+1, num_epochs, curr_loss, curr_acc
))
print("-" * 50)
# 如果当前轮次的准确率高于之前最好的准确率,则更新最佳准确率和保存模型
# 保存当前预测准确率最高的模型
if curr_acc > best_acc:
best_acc = curr_acc
# 保存模型到指定路径
ms.save_checkpoint(network, best_ckpt_path)
# 训练结束,打印最终的验证集上最佳准确率和对应的模型保存路径
print("=" * 80)
print(f"End of validation the best Accuracy is: {best_acc: 5.3f}, "
f"save the best ckpt file in {best_ckpt_path}", flush=True)
可视化模型预测
定义visualize_model函数,使用上述验证精度最高的模型对CIFAR-10测试数据集进行预测,并将预测结果可视化。若预测字体颜色为蓝色表示为预测正确,预测字体颜色为红色则表示预测错误。
由上面的结果可知,5个epochs下模型在验证数据集的预测准确率在70%左右,即一般情况下,6张图片中会有2张预测失败。如果想要达到理想的训练效果,建议训练80个epochs。
import matplotlib.pyplot as plt
# 导入必要的库和模块
def visualize_model(best_ckpt_path, dataset_val):
"""
可视化模型的预测结果。
参数:
best_ckpt_path: 字符串,表示最佳模型的检查点路径。
dataset_val: 数据集迭代器,用于获取验证数据。
返回:
无返回值,但展示了一个包含6张图片的图表,每张图片附带预测标签。
"""
# 定义分类数目
num_class = 10 # 对狼和狗图像进行二分类
# 初始化一个ResNet50模型
net = resnet50(num_class)
# 加载最佳模型的参数
# 加载模型参数
param_dict = ms.load_checkpoint(best_ckpt_path)
ms.load_param_into_net(net, param_dict)
# 获取验证数据集中的一个batch
# 加载验证集的数据进行验证
data = next(dataset_val.create_dict_iterator())
# 分别获取图片数据和标签
images = data["image"]
labels = data["label"]
# 通过模型预测图片的类别
# 预测图像类别
output = net(data['image'])
pred = np.argmax(output.asnumpy(), axis=1)
# 初始化存储类名的列表
# 图像分类
classes = []
# 从文件中读取类名
with open(data_dir + "/batches.meta.txt", "r") as f:
for line in f:
line = line.rstrip()
if line:
classes.append(line)
# 展示预测结果
# 显示图像及图像的预测值
plt.figure()
for i in range(6):
# 设置子图
plt.subplot(2, 3, i + 1)
# 根据预测是否正确设置标题颜色
# 若预测正确,显示为蓝色;若预测错误,显示为红色
color = 'blue' if pred[i] == labels.asnumpy()[i] else 'red'
plt.title('predict:{}'.format(classes[pred[i]]), color=color)
# 处理图片数据以展示
picture_show = np.transpose(images.asnumpy()[i], (1, 2, 0))
mean = np.array([0.4914, 0.4822, 0.4465])
std = np.array([0.2023, 0.1994, 0.2010])
picture_show = std * picture_show + mean
picture_show = np.clip(picture_show, 0, 1)
plt.imshow(picture_show)
plt.axis('off')
# 显示所有子图
plt.show()
# 调用函数展示模型预测结果
visualize_model(best_ckpt_path=best_ckpt_path, dataset_val=dataset_val)

参考大佬博客:
卷积神经网络学习—Resnet50(论文精读+pytorch代码复现)_resnet50论文-CSDN博客
卷积神经网络网络结构——ResNet50 - 淇则有岸 - 博客园 (cnblogs.com)
经典神经网络论文超详细解读(五)——ResNet(残差网络)学习笔记(翻译+精读+代码复现)_神经网络开源的论文-CSDN博客
【深度学习】深入理解Batch Normalization批标准化 - 郭耀华 - 博客园 (cnblogs.com)
打卡图片: