目录
1、Java Basic I/O 中的字节流:Byte Streams
2、Java Basic I/O 中的字符流:Character Streams
3、Java Basic I/O 中的缓冲流:Buffered Streams
4、Java Basic I/O 中的打印流:PrintStream (数据扫描和格式化)
5、Java Basic I/O 中的数据流:Data Streams
6、Java Basic I/O 中的对象流:Object Streams
一个 I/O 流代表一个输入源或输出目的地。一个流可以表示许多不同类型的输入源和输出目的地,比如磁盘文件、设备、其他程序和存储阵列。
流支持许多不同类型的数据,比如字节(字节流)、基本数据类型(数据流)、字符串(字符流)和对象(对象流)。有些流只是简单地传递数据;而有些流则能以有效的方式使用和转换数据。
不管流在内部是如何工作的,所有流在程序中都是一个数据序列。程序使用输入流从输入源读取数据,而且一次只读取一个流:

程序使用输出流将数据写入输出目的地,每次也是写入一个流:
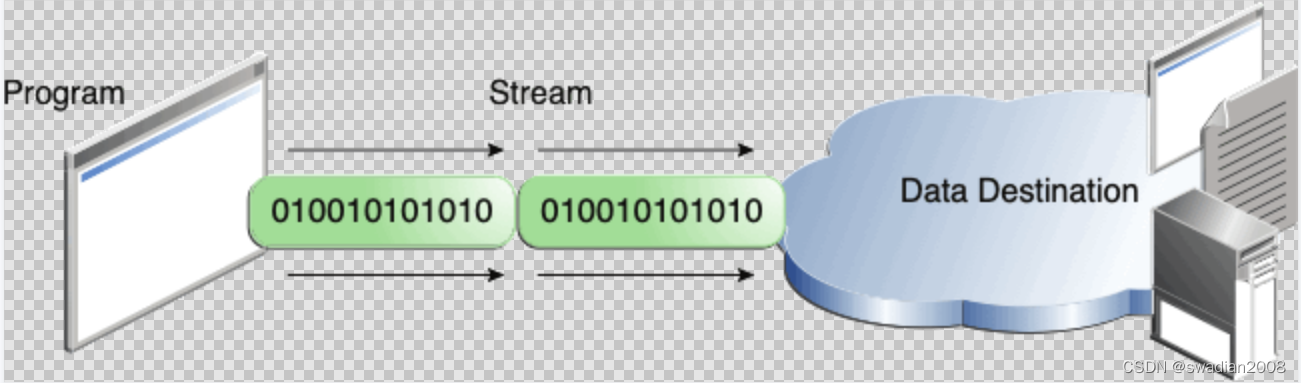
上图中的数据源和输出目的地可以是保存、生成或使用数据的任何东西,比如括磁盘文件,但数据源或输出目的也可以是另一个程序、外围设备、网络套接字或存储阵列等。
Java 中的 IO 流汇总图示:

1、Java Basic I/O 中的字节流:Byte Streams
程序使用字节流来执行 8-bit bytes 的输入和输出(8 个二进制位表示为 1 个字节)。所有的字节流都起源于 InputStream 和 OutputStream。Java 中有许多的字节流,本节使用 Java 中的文件字节流(FileInputStream 和 FileOutputStream)进行演示,其他字节流的使用方式大致相同;它们的主要区别在于流的构造方式。
下边的程序使用 FileInputStream 和 FileOutputStream 读取和复制 xanadu.txt 文件:
public class CopyBytes {
public static void main(String[] args) throws IOException {
FileInputStream in = null;
FileOutputStream out = null;
try {
in = new FileInputStream("F:\\xanadu.txt");
out = new FileOutputStream("F:\\outagain.txt");
int c;
while ((c = in.read()) != -1) {
out.write(c);
}
} finally {
if (in != null) { // 判断流是否存在,如果文件打开错误,那么流始终是null值
in.close(); // 关闭流,避免严重的资源泄漏
}
if (out != null) {
out.close();
}
}
}
}CopyBytes 会将大部分时间花费在读取输入流和写入输出流的简单循环中,每次一个字节,如下图所示:
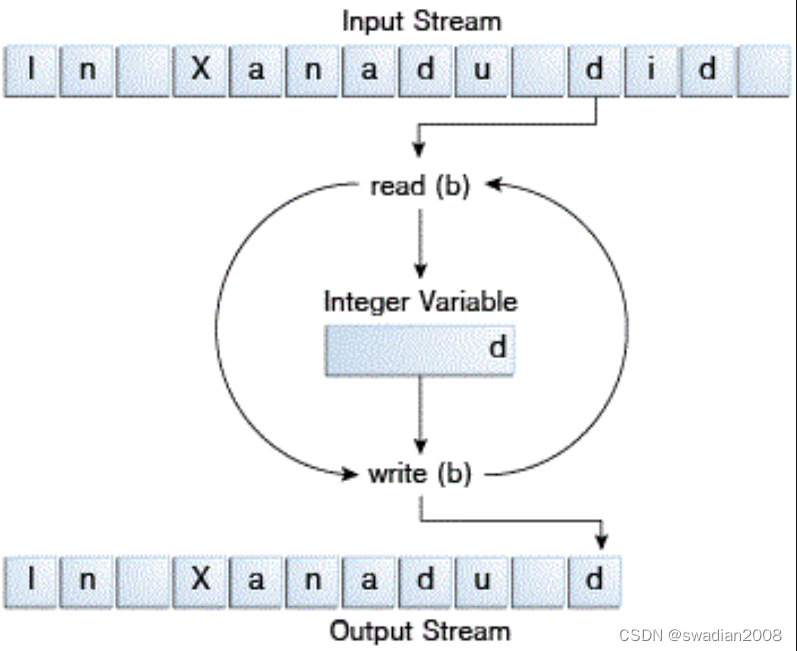
CopyBytes 看起来是一个普通的程序,但它实际上代表了一种应该避免使用的低级 I/O。由于 xanadu.txt 文件中包含的是字符数据,所以最好的方法是使用字符流,那么为什么还要存在字节流呢?那是因为所有其他流类型都是建立在字节流的基础上。
2、Java Basic I/O 中的字符流:Character Streams
Java 存储字符值使用 Unicode 字符集进行编码,字符流 I/O 自动将这种字符编码应用到本地字符串的转换过程中,在西方地区,本地字符集通常使用 ASCII 进行编码。// 编码不统一会导致乱码问题
所有的字符流类都起源于 Reader 和 Writer。与字节流一样,字符流中也有专门处理文件 I/O 的字符流类:FileReader 和 FileWriter。下边的程序使用 FileReader 和 FileWriter 读取和复制 xanadu.txt 文件:
public class CopyCharacters {
public static void main(String[] args) throws IOException {
FileReader inputStream = null;
FileWriter outputStream = null;
try {
inputStream = new FileReader("F:\\xanadu.txt");
outputStream = new FileWriter("F:\\characteroutput.txt");
int c;
while ((c = inputStream.read()) != -1) {
outputStream.write(c);
}
} finally {
if (inputStream != null) {
inputStream.close();
}
if (outputStream != null) {
outputStream.close();
}
}
}
}CopyCharacters 和 CopyBytes 类非常相似。区别在于 CopyCharacters 使用 FileReader 和 FileWriter 进行输入和输出,而不是 FileInputStream 和 FileOutputStream。需要注意的是 CopyBytes 和 CopyCharacters 都使用了 int 变量进行读写。但在 CopyCharacters 中,int 变量保存的是最后 16 bits 的字符值;在 CopyBytes 中,int 变量保存的是最后 8 bits 的字符值。// 一次读取一个字符而不是一次一个字节
字符流通常是字节流的“包装器”。字符流使用字节流执行物理I/O,而字符流处理字符和字节之间的转换。例如,FileReader 使用 FileInputStream,而 FileWriter 使用 FileOutputStream。
Java 提供了通用的子节流转换为字符流的桥接流类: InputStreamReader 和 OutputStreamWriter。当程序中没有预先满足需求的字符流类时,可以使用它们来创建字符流。
面向行的字符流 I/O
字符流 I/O 通常使用比单个字符更大的单位。常见的单位是行:一行字符串,末尾带有行结束符。行结束符可以是回车符("\r")或者换行符("\n")等。
接下来修改 CopyCharacters 的程序,会使用到两个新的类:BufferedReader 和 PrintWriter。在后文中还会具体介绍这两个类,现在我们仅关注使用他们来支持面向行的 I/O 流。
public class CopyLines {
public static void main(String[] args) throws IOException {
BufferedReader inputStream = null;
PrintWriter outputStream = null;
try {
inputStream = new BufferedReader(new FileReader("F:\\xanadu.txt"));
outputStream = new PrintWriter(new FileWriter("F:\\characteroutput.txt"));
String l;
while ((l = inputStream.readLine()) != null) {
outputStream.println(l);
}
} finally {
if (inputStream != null) {
inputStream.close();
}
if (outputStream != null) {
outputStream.close();
}
}
}
}输入流调用 readLine() 方法返回一行字符串。CopyLines 使用 println() 输出每一行数据,println() 自动附加了当前操作系统的行结束符。当然,除了字符和行外,Java 还有许多方法来组织文本的输入和输出方式,比如 Scanning 和 Formatting,后边也会继续介绍到。
3、Java Basic I/O 中的缓冲流:Buffered Streams
在上边的示例中,我们看到的都是无缓冲的 I/O。这意味着每个读或写的请求都是由底层操作系统直接处理。无缓冲的 I/O 会大大降低程序的运行效率,因为每个 I/O 请求经常会触发磁盘访问、网络活动或其他一些相对耗时的操作。// 一个流的数据:字节 -> 字符 -> 行字符串 -> 缓冲区
所以,为了减少这种开销,Java 实现了缓冲 I/O 流。缓冲输入流从内存(缓冲区)读取数据;只有当缓冲区为空时,才会调用本地输入流 API 继续读取数据。类似地,缓冲输出流将数据写入缓冲区,只有当缓冲区已满时,才会调用本地输出流 API 写入数据。// 对缓冲区进行操作
我们可以把非缓冲流包装为缓冲流,只需将非缓冲 I/O 的对象传递给缓冲流类的构造函数就可以了。比如修改 CopyCharacters 示例中的非缓冲 I/O 为使用缓冲 I/O:
inputStream = new BufferedReader(new FileReader("F:\\xanadu.txt"));
outputStream = new BufferedWriter(new FileWriter("F:\\characteroutput.txt"));Java 提供了四种缓冲流包装类:BufferedInputStream 和 BufferedOutputStream 用来创建缓冲字节流,BufferedReader 和 BufferedWriter 用来创建缓冲的字符流。
刷新缓冲区
缓冲区刷新的作用就是立刻把缓冲区的数据写入存储,而不用等待缓冲区被填满。
有些缓冲 I/O 输出类支持自动刷新,可以通过构造函数参数来进行指定。当启用自动刷新后,一些关键的事件会触发缓冲区刷新。比如,每次调用 println() 或 format() 方法的时候。如果需要手动刷新缓冲区,可以调用 flush() 方法,flush() 方法对任何类型的缓冲输出流都有效。
4、Java Basic I/O 中的打印流:PrintStream (数据扫描和格式化)
扫描器:使用 Java 提供的扫描器包装输入流读取文件中的数据,代码示例如下:// 不常用
public class ScanXan {
public static void main(String[] args) throws IOException {
Scanner s = null;
try {
// 通过控制台输入 new Scanner(System.in)
s = new Scanner(new BufferedReader(new FileReader("F:\\xanadu.txt")));
while (s.hasNext()) {
System.out.println(s.next());
}
} finally {
if (s != null) {
s.close();
}
}
}
}注意:ScanXan 类在处理 Scanner 对象时,调用了 Scanner 的 close() 方法。即使扫描器不是流,但也需要关闭它来指示本次操作已经完成,可以关闭底层流。
Formatting 格式化(打印流)
格式化是由流对象 PrintWriter(字符流类)或 PrintStream(字节流类)的实例实现的。一般在 Java 中唯一使用打印流的地方是调用 System.out 和 System.err 方法的时候。
与所有字节流和字符流对象一样,PrintStream 和 PrintWriter 的实例也实现了一组用于字节和字符标准输出的写入方法。此外,PrintStream 和 PrintWriter 还提供了一组将内部数据格式化输出的方法,这些方法中有两种级别的格式化:
- print() 和 println() 以标准方式格式化单个值。
- format() 基于格式化字符串来编排任何数量的值,有许多精确的格式化选项。
调用 print() 或 println() 方法,会使用 toString() 方法转换值,然后输出。示例代码如下:
public class Root {
public static void main(String[] args) {
int i = 2;
double r = Math.sqrt(i);
System.out.print("The square root of ");
System.out.print(i);
System.out.print(" is ");
System.out.print(r);
System.out.println(".");
i = 5;
r = Math.sqrt(i);
System.out.println("The square root of " + i + " is " + r + ".");
}
}调用 format() 方法,可以使用格式化来编排值。示例代码如下:
public class Root2 {
public static void main(String[] args) {
int i = 2;
double r = Math.sqrt(i);
System.out.format("The square root of %d is %f.%n", i, r); // format
}
}上述打印流在命令行环境与用户进行交互的场景中也有所涉及,Java 提供了两种命令行交互支持:标准流和控制台。因为日常使用得不是很多,所以标准流和控制台的命令行交互详情请查阅 Java 官方文档。
5、Java Basic I/O 中的数据流:Data Streams
数据流支持基本数据类型(boolean、char、byte、short、int、long、float 和 double)和字符串类型(String)的二进制 I/O。所有的数据流都实现了 DataInput 或 DataOutput 接口。其中使用得最多的是 DataInputStream 和 DataOutputStream。
对于 DataInputStream 和 DataOutputStream 使用的示例程序如下:
public class DataStreams {
static final String dataFile = "F:\\invoicedata.txt";
static final double[] prices = {19.99, 9.99, 15.99, 3.99, 4.99};
static final int[] units = {12, 8, 13, 29, 50};
static final String[] descs = {
"Java T-shirt",
"Java Mug",
"Duke Juggling Dolls",
"Java Pin",
"Java Key Chain"
};
public static void main(String[] args) throws IOException {
DataInputStream in = null;
DataOutputStream out = null;
try {
out = new DataOutputStream(new BufferedOutputStream(new FileOutputStream(dataFile)));
for (int i = 0; i < prices.length; i++) {
out.writeDouble(prices[i]);
out.writeInt(units[i]);
out.writeUTF(descs[i]);
}
out.flush(); // 刷新缓冲区
in = new DataInputStream(new BufferedInputStream(new FileInputStream(dataFile)));
double price = 0;
int unit;
String desc;
double total = 0.0;
try {
while (true) {
price = in.readDouble();
unit = in.readInt();
desc = in.readUTF();
System.out.println(String.format("You ordered %d" + " units of %s at $%.2f%n", unit, desc, price));
total += unit * price;
}
} catch (EOFException e) {
}
} finally {
if (out != null) {
out.close();
}
if (in != null) {
in.close();
}
}
}
}注意,DataStreams 通过捕获 EOFException 来检测文件的结束条件,而不是测试无效的返回值。DataInput 方法的所有实现都使用 EOFException 而不是返回值。
DataStreams 中的每个写入都有相应的专门化读取进行完全匹配。上述示例中,DataStreams 使用浮点数来表示货币的值,不过浮点数并不擅长用来表示精确的值,尤其是十进制分数,因为有些常见的值(比如 0.1)没有二进制的表示。所以,用于货币值的正确类型是 java.math.BigDecimal。但是,BigDecimal 是一种对象类型,因此它不能用于数据流。不过,BigDecimal 可以与对象流一起工作。// 数据流的局限性是它只支持基本数据类型和字符串类型
6、Java Basic I/O 中的对象流:Object Streams
数据流支持基本数据类型的 I/O,对象流用来支持对象的 I/O。大多数实现 Serializable 接口的标准类都支持对其对象的序列化。// 把对象转为二进制
对象流的类为 ObjectInputStream 和 ObjectOutputStream。这些类实现了 ObjectInput 和 ObjectOutput 接口,ObjectInput 和 ObjectOutput 是 DataInput 和 DataOutput 的子接口。所以数据流中的所有基本数据的 I/O 方法也会在对象流中实现。因此,对象流既可以操作基本数据类型也可以操作对象类型的数据。
对象流的示例代码如下:
public class ObjectStreams {
static final String dataFile = "F:\\invoicedata.txt";
static final BigDecimal[] prices = {
new BigDecimal("19.99"),
new BigDecimal("9.99"),
new BigDecimal("15.99"),
new BigDecimal("3.99"),
new BigDecimal("4.99")};
static final int[] units = {12, 8, 13, 29, 50};
static final String[] descs = {"Java T-shirt",
"Java Mug",
"Duke Juggling Dolls",
"Java Pin",
"Java Key Chain"};
public static void main(String[] args) throws IOException, ClassNotFoundException {
ObjectOutputStream out = null;
try {
out = new ObjectOutputStream(new BufferedOutputStream(new FileOutputStream(dataFile)));
out.writeObject(Calendar.getInstance());
for (int i = 0; i < prices.length; i++) {
out.writeObject(prices[i]);
out.writeInt(units[i]);
out.writeUTF(descs[i]);
}
out.flush();
} finally {
out.close();
}
ObjectInputStream in = null;
try {
in = new ObjectInputStream(new BufferedInputStream(new FileInputStream(dataFile)));
Calendar date = null;
BigDecimal price;
int unit;
String desc;
BigDecimal total = new BigDecimal(0);
date = (Calendar) in.readObject();
System.out.format("On %tA, %<tB %<te, %<tY:%n", date);
try {
while (true) {
price = (BigDecimal) in.readObject();
unit = in.readInt();
desc = in.readUTF();
System.out.format("You ordered %d units of %s at $%.2f%n",
unit, desc, price);
total = total.add(price.multiply(new BigDecimal(unit)));
}
} catch (EOFException e) {
}
System.out.format("For a TOTAL of: $%.2f%n", total);
} finally {
in.close();
}
}
}ObjectStreams 创建了与 DataStreams 相同的应用程序,只是做了一些更改。首先,价格现在是 BigDecimal 对象,以便更好地表示分数值。其次,将 Calendar 对象写入了数据文件,用来标注日期。
对复杂对象的输入和输出
writeObject() 和 readObject() 方法使用起来很简单,但它们也包含一些非常复杂的对象管理逻辑。对于像 Calendar 这样的类,因为它只是封装了原始值,所以并不重要。但是许多对象还包含了对其他对象的引用。如果 readObject() 要从流中重构对象,它就必须能够重构该对象引用的所有对象,这些附加的对象又可能有自己的引用。所以,在这种情况下,writeObject() 需要遍历整个对象的引用网络,并将该网络中的所有对象都写入流。因此,writeObject() 的一次调用可能导致将大量对象写入流。// writeObject() 会写入对象中的对象
如下图所示,调用 writeObject() 来写入名为 a 的单个对象。该对象包含对对象 b 和 c 的引用,而 b 包含对对象 d 和 e 的引用。所以调用 writeObject(a) 不仅写入 a,而且会写入重构 a 所需的所有对象,因此关系网中的其他四个对象也会被写入。当 readObject() 读回 a 时,其他四个对象也会被读回,并且所有原始对象的引用也都会被保留。
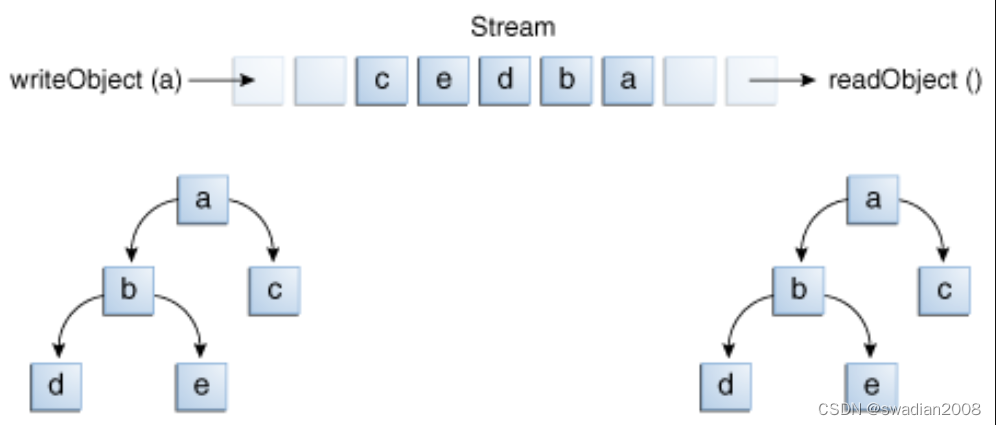
那么如果同一个流上的两个对象都包含对单例对象的引用,会发生什么呢?当它们被回读时,它们是否都指向同一个对象呢?答案是肯定的。一个流只能包含一个对象的一个副本,但它可以包含任意数量对该对象的引用。因此,如果显式地将一个对象写入同一个流两次,实际上只写入了两次引用。例如,如果下面的代码将 ob 对象两次写入流:
Object ob = new Object();
out.writeObject(ob);
out.writeObject(ob);每个 writeObject() 都必须与一个 readObject() 相匹配,所以读取流的代码看起来像这样:
Object ob1 = in.readObject();
Object ob2 = in.readObject();这将产生两个变量 ob1 和 ob2,但它们是对同一个对象的引用。
不过,如果一个对象被写入两个不同的流,那么读取两个流时将会拥有两个不同的对象。