hash function
假定存在一个Customer类
class Customer{
public:
string fname, lname;
int no;
};
其哈希函数存在三种方式
//方式一:创建可调用类型
class CustomerHash
{
public:
std::size_t operator()(const Customer& c) const{
return ......
}
};
unordered_set<Customer, CustomerHash> custest;
//方式二:创建哈希函数
size_t customer_hash_func(const Customer& c){
return ......
}
unordered_set<Customer, size_t(*)(const Customer&)> custest(20, customer_hash_func); //注意这里调用了构造函数的不同版本
//方式三:特化标准库提供的hash<T>
namespace std
{
template<>
struct hash<Customer>
{
size_t
operator()(const Customer& c) const noexcept
{ return ...... }
};
}
unordered_set<Customer> custest;
具体的hash function计算如下:标准库提供了一个hash_val的函数,可以计算出由基本类型组成的class的hash值,原理是使用了可变模板参数
template <typename... Types>
inline size_t hash_val(const Types&... args){ //提供给使用者的重载版本
size_t seed = 0;
hash_val(seed, args...); //实际调用的版本
return seed;
}
template <typename T, typename... Types>
inline void hash_val(size_t& seed, //实际调用函数的主体
const T& val, const Types&... args){
hash_combine(seed, val);
hash_val(seed, args...);
}
template <typename T>
inline void hash_val(size_t& seed, const T& val){ //实际调用函数的边界条件
hash_combine(seed, val);
}
template <typename T>
inline void hash_combine(size_t& seed, const T& val){
seed ^= std::hash<T>()(val) + 0x9e3779b9
+ (seed<<6) + (seed>>2);
}
//下面是对于 class Customer 的实际使用
class CustomerHash{
public:
std::size_t operator()(const Customer& c) const{
return hash_val(c.fname, c.lname, c.no);
}
};
- 此时可使用
CustomerHash hh; hh(Customer("Ace", "Hou", 1L)) % 11来计算该对象应存放的hash bucket position。 - 在使用该hash function创建unordered_set时可用
unordered_set<Customer, CustomerHash> set3;方式调用。
tuple

注意:string的实现在各库中可能有所不同,但是在同一库中相同一点是,无论你的string里放多长的字符串,它的sizeof()都是固定的,字符串所占的空间是从堆中动态分配的,与sizeof()无关。 sizeof(string)=4可能是最典型的实现之一,不过也有sizeof()为28、32字节的库实现。 但是MS2015测试后sizeof(string)=40.还是跟编译器有关.
tuple大小为32而不是28的原因:tuple的大小必须是其中最大元素的倍数,complex< double>大小为16,tuple对齐后大小为32
原理
tuple原理是用可变模板参数实现的递归继承
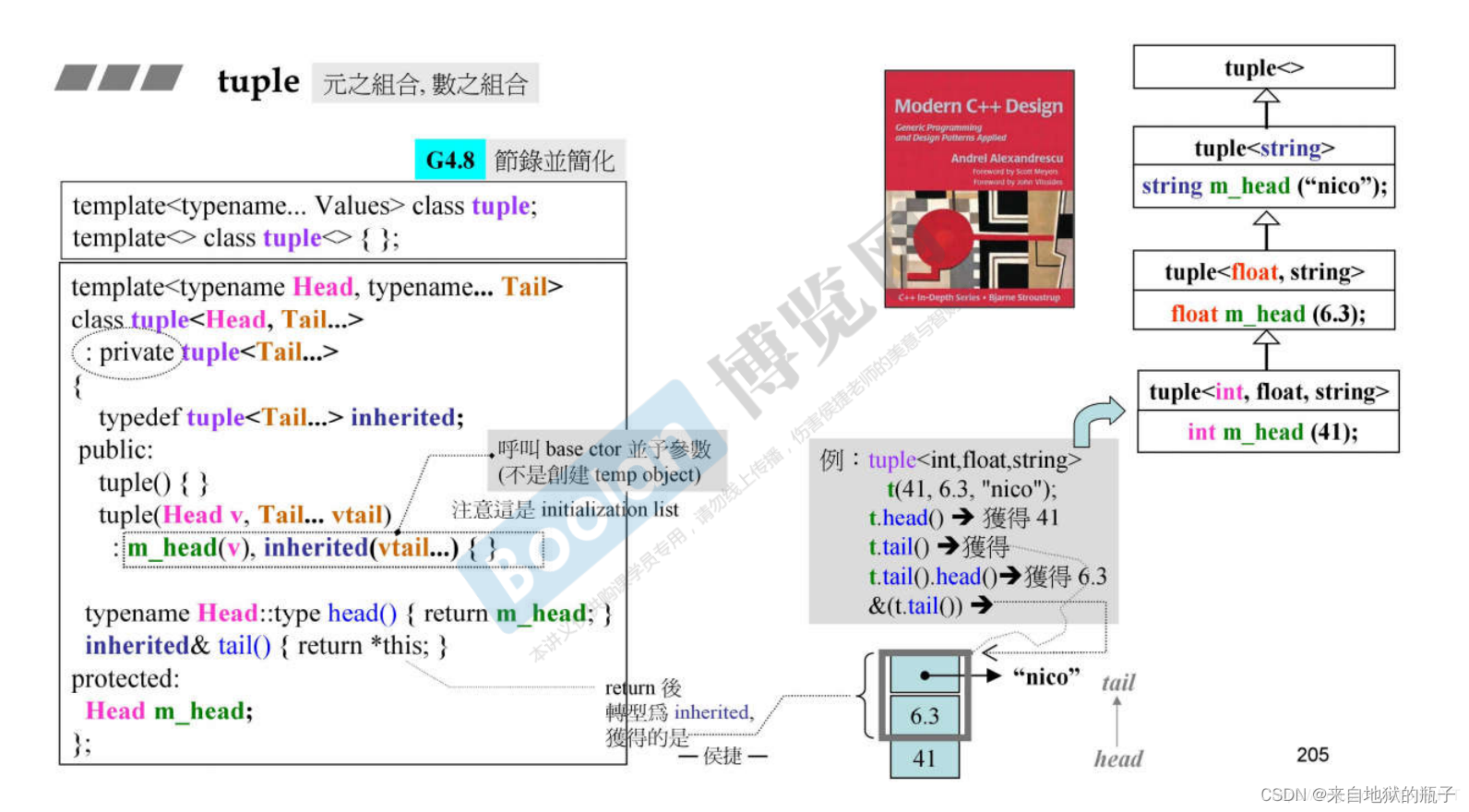
this指针指向的是父类对象的位置,即head在下面,tail在前面。
type traits
type traits用法

type traits实现
is_void实现

实质上是对基本类型定义特化版本,先把volatile和const用模板特化去除掉,然后用__is_void_helper对void特化为true_type,其他泛化版本默认为false_type
类似的有is_integer

在复杂一点的is_move_assignable等实现中并没有找到源码,猜想是编译器帮助他们完成了底层的实现。

cout

cout是一个ostream类对象
重载输入输出运算符时要注意:
通常重载输入输出(运算符)时必须是非成员函数重载,主要是为了与iostream标准库兼容。为了与标准IO库一致,重载后的符号的左侧应该是流的引用,右侧是对象的引用。(如,cout<<“hello!”;或cin>>tmp;等。)但是如果重载为类的成员函数的话,运算符左侧是对象的引用,右侧是流的引用。(ps:事实的确如此,回想一下成员函数的重载都是对象在前运算符号在后。)也就是说其形式为:
Sales_data data;
data << cout;//如果operator<<是Sales_data的成员。
因此定义重载输入输出运算符中要在类中定义友元函数,如Complex类
class Complex{
public:
Complex( double r=0, double i=0):real(r),imag(i){ };
friend ostream & operator<<( ostream & os,const Complex & c);
friend istream & operator>>( istream & is,Complex & c);
private:
double real,imag;
};
在标准库中对cout的重载

move
详细见C++新特性(标准库)
简单来说,move assignment和move ctor只拷贝指针,再把原指针的指向对象和数据清零,为浅拷贝。拷贝构造和拷贝赋值函数需要创建一块新的空间,再将原来对象的数据添加到新空间中,为深拷贝
moveable测试函数
用到的class是C++新特性(标准库)中的move-aware-class

- 其中
Vltype(buf)为临时对象,insert()调用后该对象不再使用,因此会自动调用move版本的ctor。因此Mctor在初始化数据时已经调用了700w次,这是元素的copy。 - 而在
M c11(c1);时编译器不知道c1是不是临时对象,因此采用传统的copy ctor,花费了3500ms。这是容器的copy - 如果显式告诉编译器用move版本,即
M c12(std::move(c1));,则采用Mctor。这也是容器的copy。
也可以写成模板模板参数形式
template <typename T,
template <typename T>
class Container
>
class XCls
{
private:
Container<T> c;
public:
XCLs()
{
for(long i=0; i<SIZE; ++i)
c.insert(c.end(), T());//也可以像上面一样用随机数生成
output_static_data(T());//也可以像上面一样用随机数生成
Container<T> c1(c);
Container<T> c2(std::move(c));
c1.swap(c2);
}
};
//不得在function body之内声明
template<typename T>
using Vec = vector<T, allocator<T>>;
XCls<MyString, Vec> c1;
vector的copy ctor
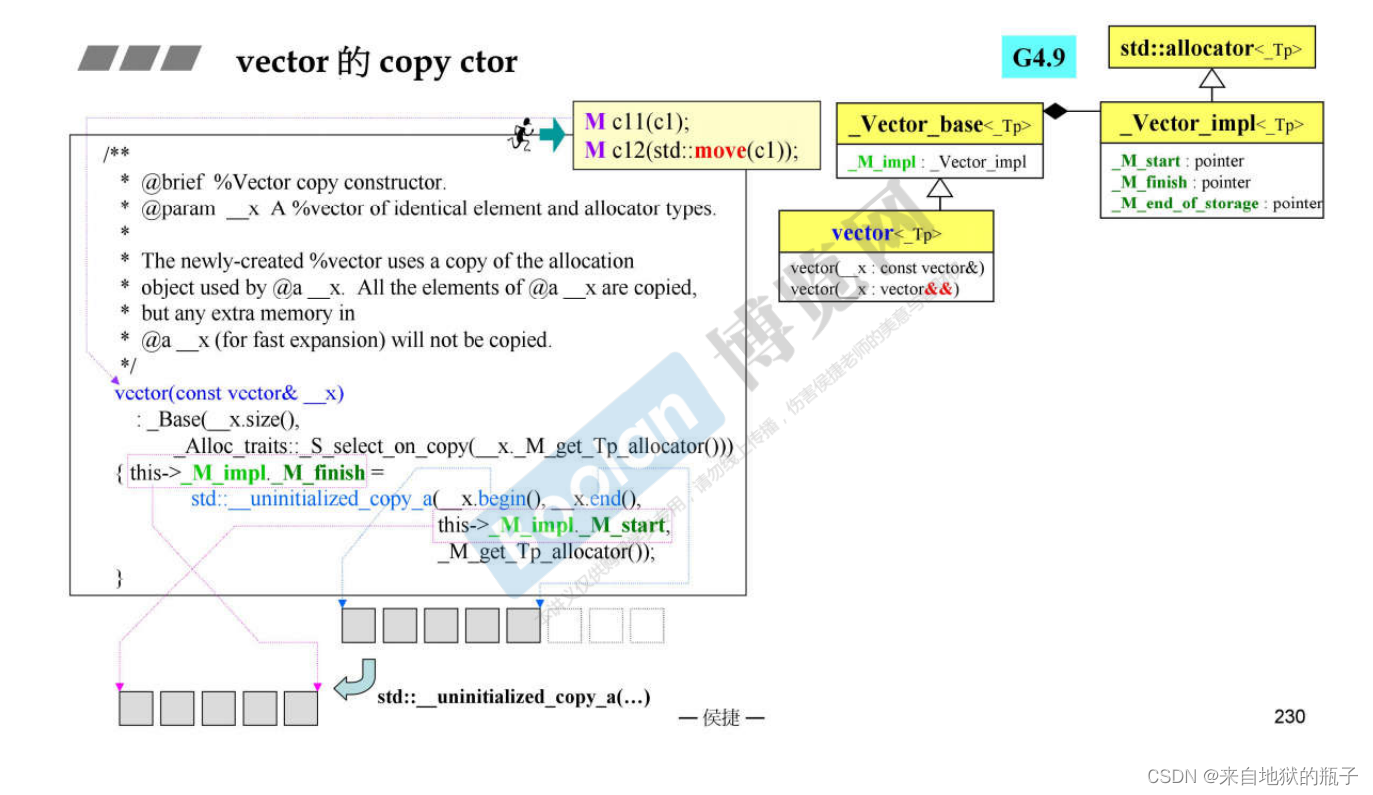
vector的move ctor
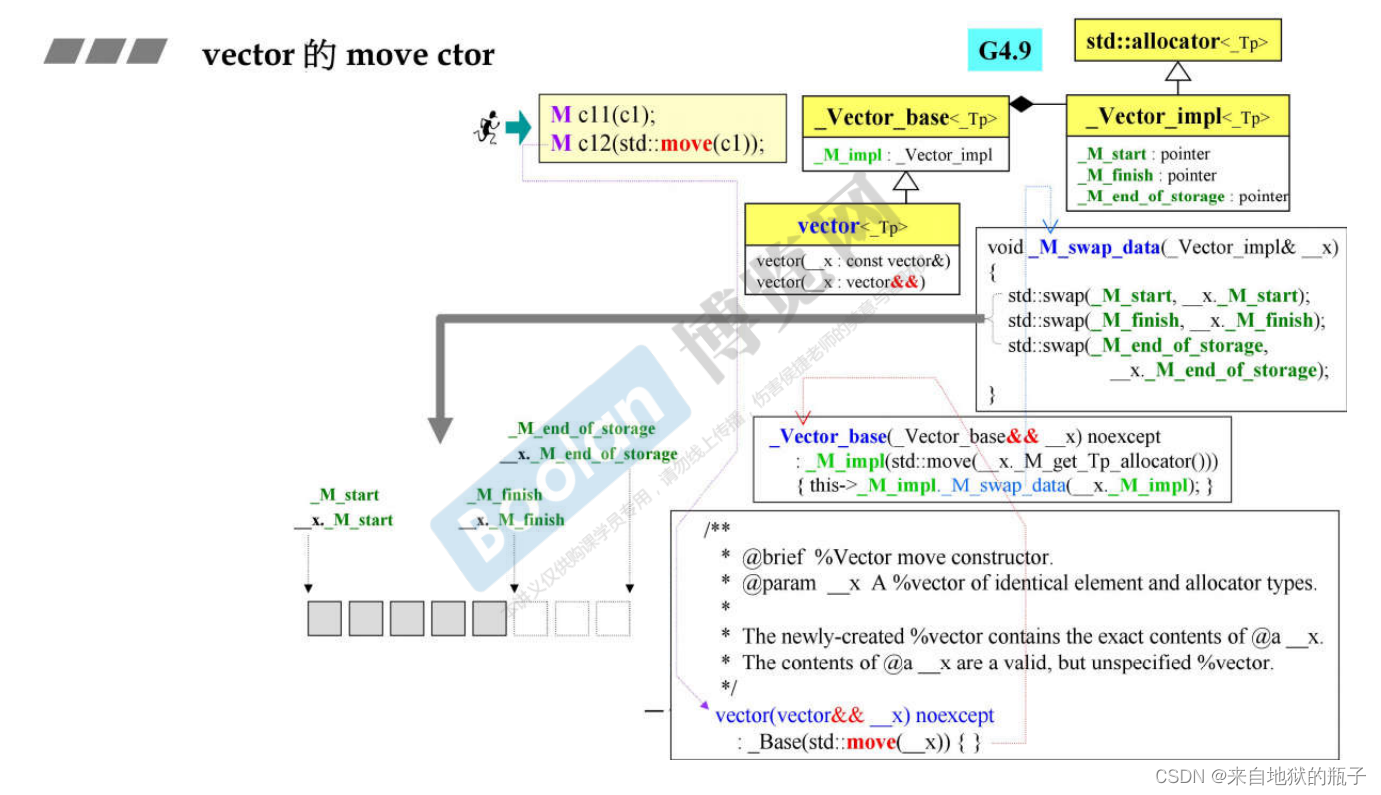
对容器做move,只是swap了三根指针
std::string是否moveable?

string带有Move版本的assignment和ctor。






![[Swift]SDK开发](https://img-blog.csdnimg.cn/img_convert/5c183c7ec092a17e505e391c343ed11f.jpeg)