前几个有个朋友留言,问我说最近两年公号发读书感悟,职场感悟,AI实践居多了,发架构思路类的内容少了。
最近准备重启架构思路类的内容,且会保持一如既往的风格:
1. 希望引发大家思考,多讨论,多互动;
2. 核心原理通俗化描述,目标是让所有人搞懂;
3. 思路,比结论重要;
本篇源自我去年看到的一篇关于ARIES算法的论文,作为重启后的第一篇,算是一个引子,希望大伙多多支持。
画外音:去掉了论文里复杂的概念、算法及公式,加入了相关概念的补充解释说明与架构思考与补充。
让我们来看数据库中一个典型的读写事务的场景。
事务T1:
1. 开始事务
2. 读取记录A的值(假设A=1)
3. 修改记录A的值(假设修改为2)
4. 提交事务
这里面可能涉及哪些技术问题呢?
问题一,数据库如何读取记录A的值?
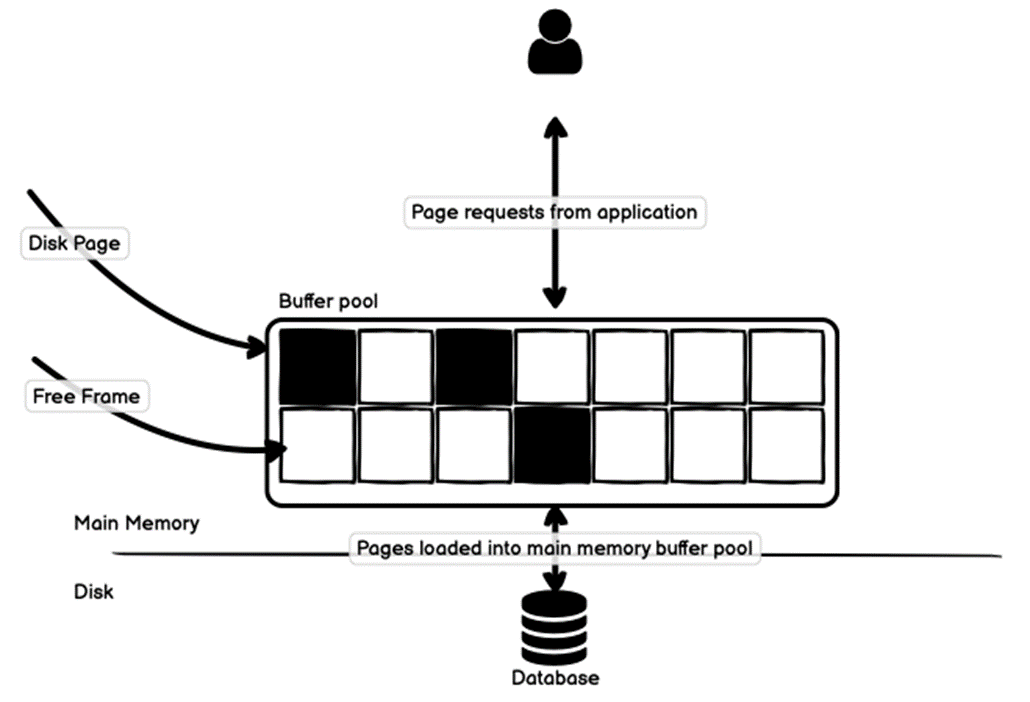
相关技术点:
1. 数据库使用缓冲池(buffer pool)机制提升读写效率;
2. 数据库以数据页(page)为单位管理缓冲池;
3. 如果被读取的数据在缓冲池中,直接从缓冲池中读取数据;
4. 否则,先将磁盘上的数据复制到缓冲池,再从缓冲池中读取数据;
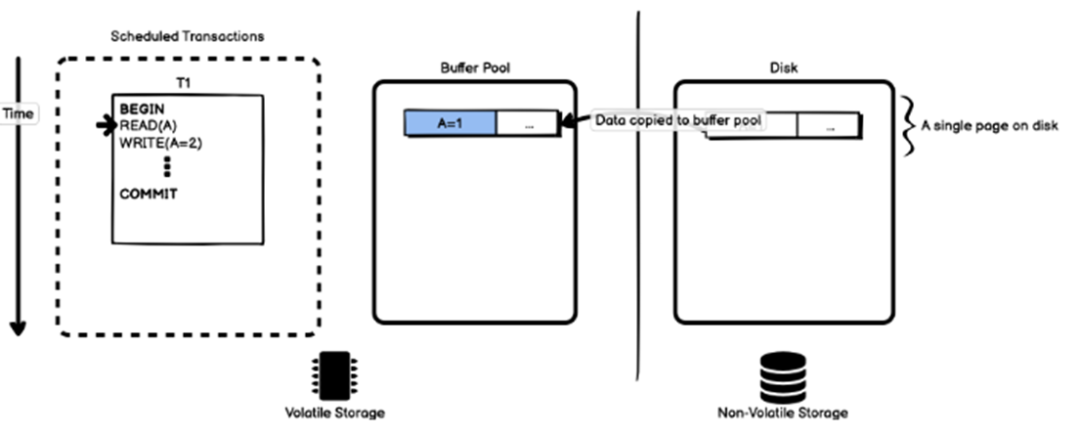
此例中,假设记录存储在一个单页上,且事先不在缓冲池中,故数据页会被复制到缓冲池。
问题二,数据库如何写入记录A的值?
相关技术点:
1. 数据库直接修改缓冲池中的数据;
2. 缓冲池中的数据不能实时刷回磁盘,毕竟事务还没有提交;
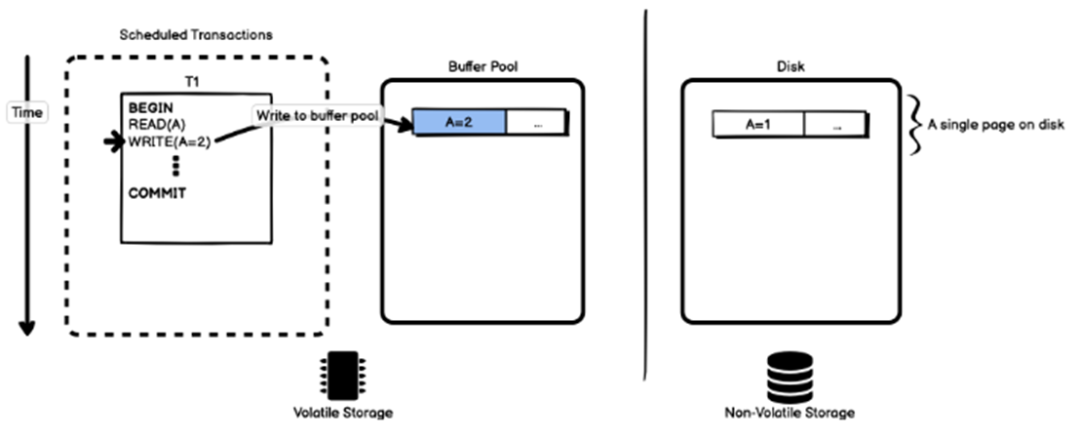
此例中,缓冲池中的数据被修改为2,磁盘上的数据仍是1(如上图)。
那么,问题来了,如果缓冲池满了,要将哪些数据刷回磁盘呢?
原则上,得做到:
1. 如果事务未提交,“脏”数据不会被刷回磁盘;
2. 如果事务已提交,数据会被刷回磁盘。
数据库的故障恢复系统(crash recovery system)也会面临类似的问题,在数据库崩溃,内存中数据丢失的时候,未提交的事务和已提交的事务,如何保证ACID特性?
再来看一个并发的事务T1和T2的复杂场景:
T1.1. 开始事务
T1.2. 读取记录A的值(假设A=1)
T1.3. 修改记录A的值(假设修改为2)
T2.1开始事务
T2.2读取记录B的值(假设B=3)
T2.3修改记录B的值(假设修改为7)
T2.4提交事务
T1.4.回滚事务
假设,记录A和记录B都在一个数据页上。
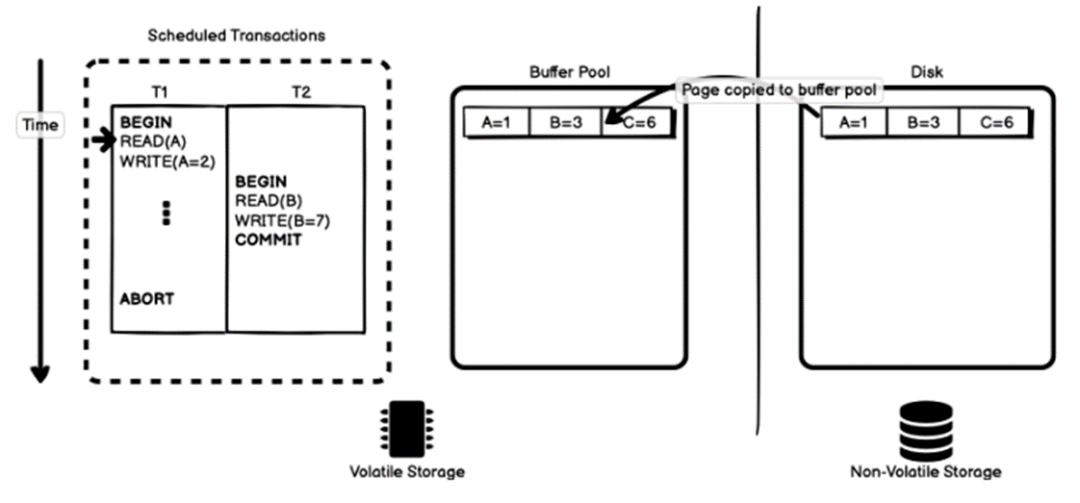
事务T1读取记录A的值,会将磁盘上的数据页复制到缓冲池,再进行读取(如上图)。
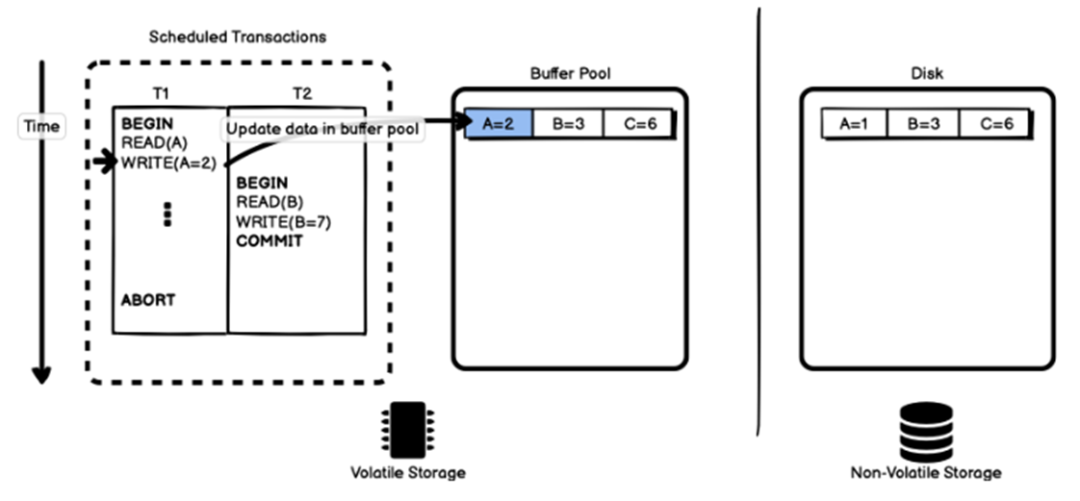
事务T1修改记录A的值,会直接修改缓冲池中的数据(如上图)。
好,这个时候,事务T2启动了。
事务T2先读取记录B的值,缓冲池中已经存在记录B所在的页,所以无需进行磁盘访问。
画外音:缓冲池的核心作用,提高读写性能。
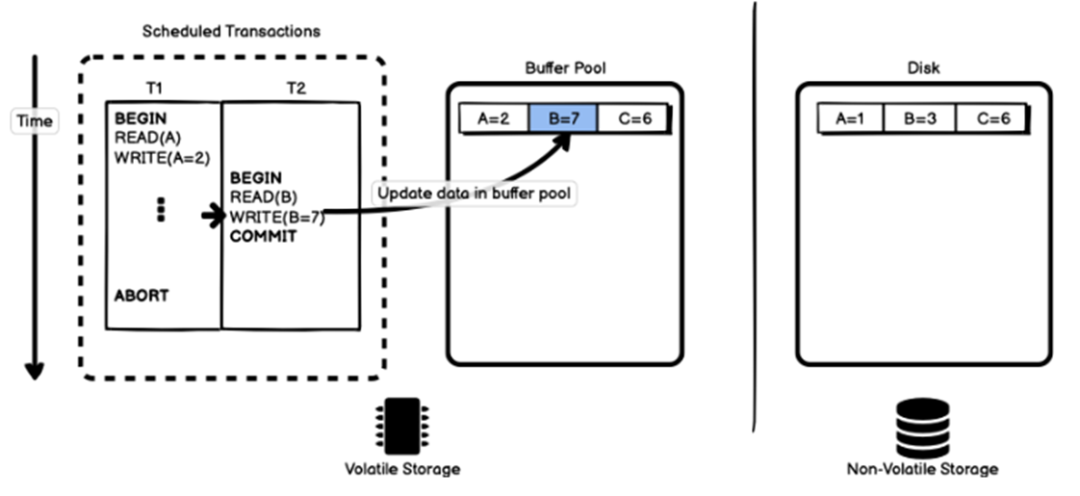
接下来,事务T2修改记录B的值,会直接修改缓冲池中的数据(如上图)。
接下来,事务T2提交了。
这个时刻,我们面临一个巨大的难题:在数据库返回应用程序事务成功之前,要不要将数据刷回磁盘?
如果不将数据刷回磁盘,就返回应用程序事务成功,那么万一数据库故障,缓冲池中的数据丢失,事务T2的ACID特性就会被破坏。
反之,如果将数据刷回磁盘,但此时事务T1还没有提交/回滚,事务T1的脏数据刷回磁盘,事务T1的ACID特性也会被破坏。
我们似乎陷入了一个两难的境地。如果是你,你会考虑用什么思路解决这个问题呢?
总结与思考:
1. 数据库使用缓冲池(buffer pool)机制提升读写效率;
2. 数据库以数据页(page)为单位管理缓冲池;
3. 数据库直接读写缓冲池中的数据;
4. 此情况,刷盘,还是不刷盘?
欢迎评论区讨论:思考,比阅读更重要。
下一篇聊解决思路。