https://tcnull.github.io/nms/
https://blog.csdn.net/weicao1990/article/details/103857298
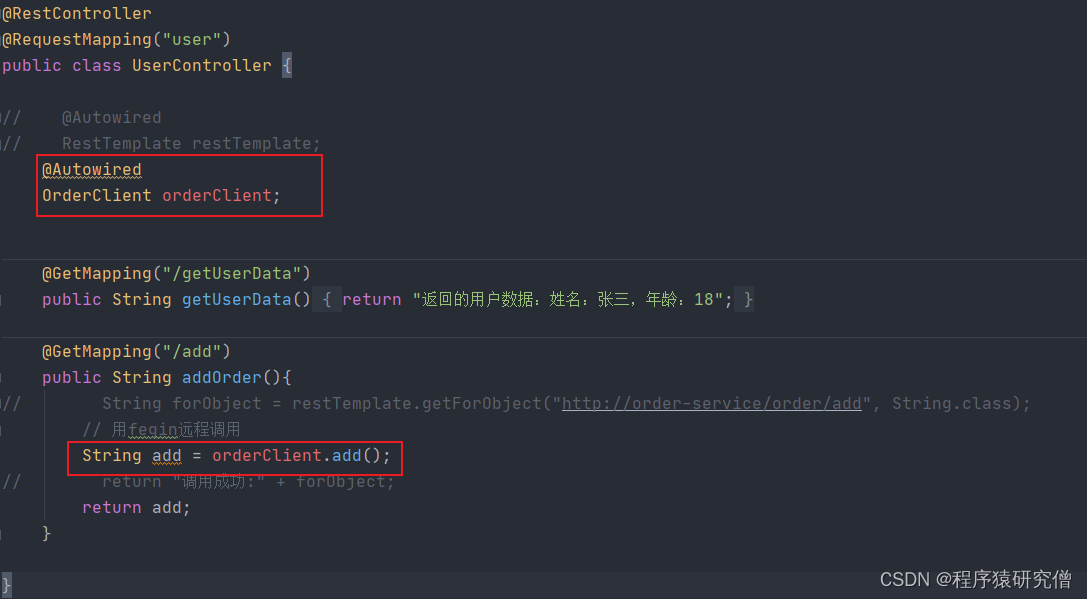
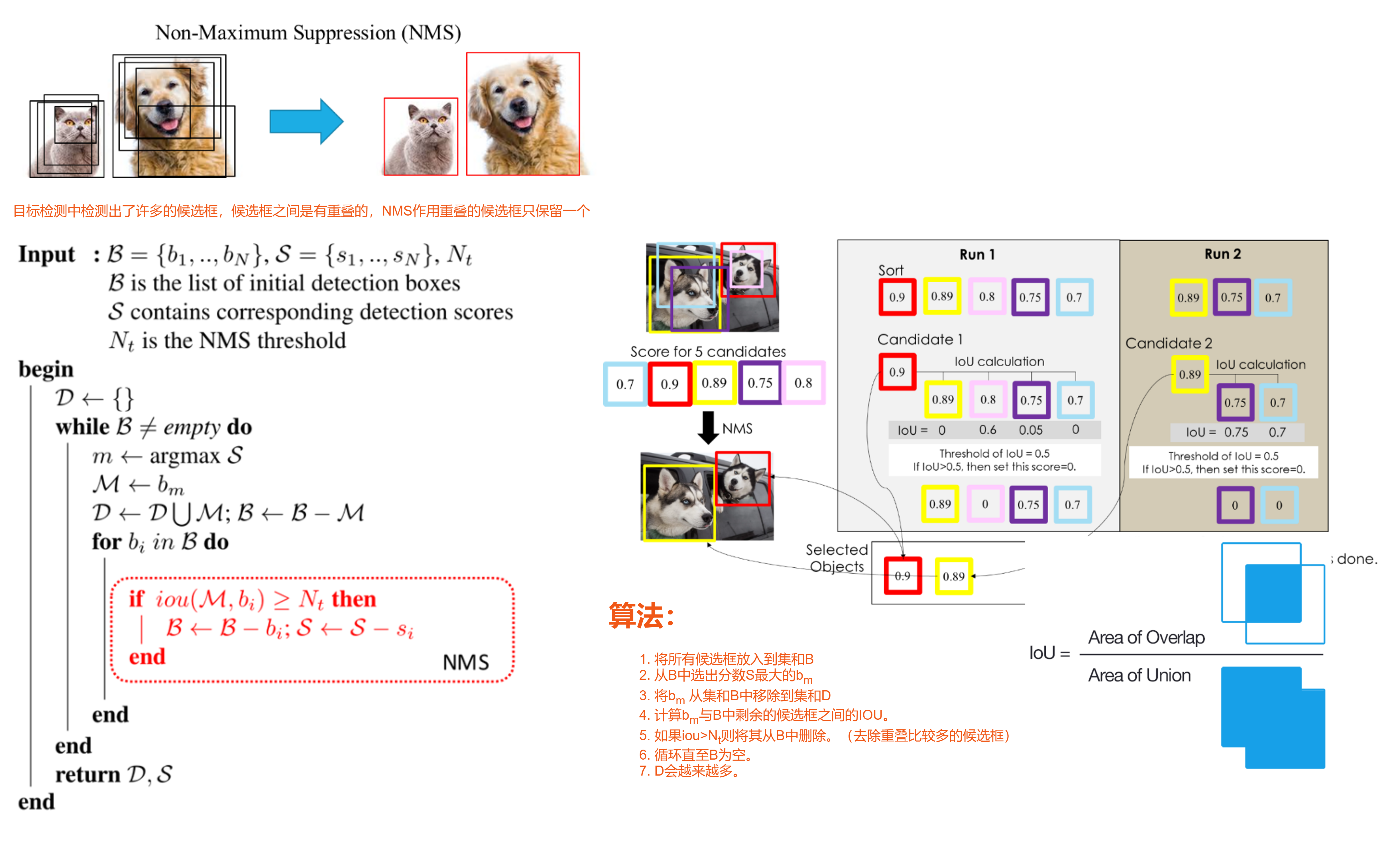 目标检测中检测出了许多的候选框,候选框之间是有重叠的,NMS作用重叠的候选框只保留一个
目标检测中检测出了许多的候选框,候选框之间是有重叠的,NMS作用重叠的候选框只保留一个
算法:
- 将所有候选框放入到集和B
- 从B中选出分数S最大的bm
- 将bm 从集和B中移除到集和D
- 计算bm与B中剩余的候选框之间的IOU。
- 如果iou>Nt则将其从B中删除。(去除重叠比较多的候选框)
- 循环直至B为空。
- D会越来越多。
def box_iou_union_2d(boxes1: Tensor, boxes2: Tensor, eps: float = 0) -> Tuple[Tensor, Tensor]:
"""
Return intersection-over-union (Jaccard index) and of boxes.
Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
Arguments:
boxes1: set of boxes (x1, y1, x2, y2)[N, 4]
boxes2: set of boxes (x1, y1, x2, y2)[M, 4]
eps: optional small constant for numerical stability
Returns:
iou (Tensor[N, M]): the NxM matrix containing the pairwise
IoU values for every element in boxes1 and boxes2
union (Tensor[N, M]): the nxM matrix containing the pairwise union
values
"""
area1 = box_area(boxes1)
area2 = box_area(boxes2)
x1 = torch.max(boxes1[:, None, 0], boxes2[:, 0]) # [N, M]
y1 = torch.max(boxes1[:, None, 1], boxes2[:, 1]) # [N, M]
x2 = torch.min(boxes1[:, None, 2], boxes2[:, 2]) # [N, M]
y2 = torch.min(boxes1[:, None, 3], boxes2[:, 3]) # [N, M]
inter = ((x2 - x1).clamp(min=0) * (y2 - y1).clamp(min=0)) + eps # [N, M]
union = (area1[:, None] + area2 - inter)
return inter / union, uniondef nms_cpu(boxes, scores, thresh):
"""
Performs non-maximum suppression for 3d boxes on cpu
Args:
boxes (Tensor): tensor with boxes (x1, y1, x2, y2, (z1, z2))[N, dim * 2]
scores (Tensor): score for each box [N]
iou_threshold (float): threshould when boxes are discarded
Returns:
keep (Tensor): int64 tensor with the indices of the elements that have been kept by NMS,
sorted in decreasing order of scores
"""
ious = box_iou(boxes, boxes)
_, _idx = torch.sort(scores, descending=True)
keep = []
while _idx.nelement() > 0:
keep.append(_idx[0])
# get all elements that were not matched and discard all others.
non_matches = torch.where((ious[_idx[0]][_idx] <= thresh))[0]
_idx = _idx[non_matches]
return torch.tensor(keep).to(boxes).long()template <typename T>
__device__ inline float devIoU(T const* const a, T const* const b) {
// a, b hold box coords as (y1, x1, y2, x2) with y1 < y2 etc.
T bottom = max(a[0], b[0]), top = min(a[2], b[2]);
T left = max(a[1], b[1]), right = min(a[3], b[3]);
T width = max(right - left, (T)0), height = max(top - bottom, (T)0);
T interS = width * height;
T Sa = (a[2] - a[0]) * (a[3] - a[1]);
T Sb = (b[2] - b[0]) * (b[3] - b[1]);
return interS / (Sa + Sb - interS);
}at::Tensor nms_cuda(const at::Tensor& dets, const at::Tensor& scores, float iou_threshold) {
/* dets expected as (n_dets, dim) where dim=4 in 2D, dim=6 in 3D */
AT_ASSERTM(dets.type().is_cuda(), "dets must be a CUDA tensor");
AT_ASSERTM(scores.type().is_cuda(), "scores must be a CUDA tensor");
at::cuda::CUDAGuard device_guard(dets.device());//管理CUDA设备上下文,并指制定使用的CUDA设备
bool is_3d = dets.size(1) == 6;
//按照第一维(索引为0)对scores降序排序,并返回一个包含排序后索引的 Tensor,std::get<1>(...) 提取排序后索引的 Tensor。
auto order_t = std::get<1>(scores.sort(0, /* descending=*/true));
//使用排序后的索引 order_t 从 dets 中选择对应的元素,返回一个新的 Tensor; dets_sorted,其中的元素按照排序后的顺序排列。
auto dets_sorted = dets.index_select(0, order_t);
//bbox个数
int dets_num = dets.size(0);
//该函数用于计算在CUDA中进行并行化计算时所需的最大列块数。其中,dets_num代表待处理的数据数量,threadsPerBlock表示每个CUDA块中的线程数量。
//函数通过将dets_num除以threadsPerBlock并向上取整得到最大列块数col_blocks。这个函数常用于确定CUDA并行计算中需要启动多少个CUDA块来处理所有数据。
const int col_blocks = at::cuda::ATenCeilDiv(dets_num, threadsPerBlock);//获取block个数
//该函数创建了一个名为mask的空Tensor,其大小为dets_num * col_blocks,数据类型为长整型(at::kLong)。该Tensor的属性与dets相同。
at::Tensor mask = at::empty({dets_num * col_blocks}, dets.options().dtype(at::kLong));//创建一个空容器 D
dim3 blocks(col_blocks, col_blocks);//定义了一个二维网格,其维度为col_blocks行col_blocks列
dim3 threads(threadsPerBlock);//定义了一个线程块,其维度为threadsPerBlock;
cudaStream_t stream = at::cuda::getCurrentCUDAStream();//获取当前的CUDA流,用于异步计算。
if (is_3d) {
//std::cout << "performing NMS on 3D boxes in CUDA" << std::endl;
AT_DISPATCH_FLOATING_TYPES_AND_HALF(
dets_sorted.type(), "nms_kernel_cuda", [&] {
nms_kernel_3d<scalar_t><<<blocks, threads, 0, stream>>>(
dets_num,
iou_threshold,
dets_sorted.data_ptr<scalar_t>(),
(unsigned long long*)mask.data_ptr<int64_t>());
});
}
else {
//该函数是PyTorch CUDA扩展中的一个宏定义,用于在CUDA代码中处理浮点类型数据(包括float、double、half)的泛型编程。
//它会根据传入的输入数据类型,自动选择对应的CUDA内核函数进行计算。
//这样可以避免为每种数据类型编写重复的代码,提高代码的可维护性和可扩展性。
//相当与模板类
AT_DISPATCH_FLOATING_TYPES_AND_HALF(
dets_sorted.type(), "nms_kernel_cuda", [&] {
nms_kernel<scalar_t><<<blocks, threads, 0, stream>>>(
dets_num,
iou_threshold,
dets_sorted.data_ptr<scalar_t>(),
(unsigned long long*)mask.data_ptr<int64_t>());
});
}
//将mask_cpu的数据拷贝到主机内存中
at::Tensor mask_cpu = mask.to(at::kCPU);
unsigned long long* mask_host = (unsigned long long*)mask_cpu.data_ptr<int64_t>();
//创建一个空的remv Tensor,其大小为col_blocks,数据类型为unsigned long long。用于记录每个block中哪些线程被标记为无效。
std::vector<unsigned long long> remv(col_blocks);
memset(&remv[0], 0, sizeof(unsigned long long) * col_blocks);
//创建一个空的keep Tensor,其大小为dets_num,数据类型为long。用于存放整个筛选后的索引。
at::Tensor keep = at::empty({dets_num}, dets.options().dtype(at::kLong).device(at::kCPU));
int64_t* keep_out = keep.data_ptr<int64_t>();
int num_to_keep = 0;
for (int i = 0; i < dets_num; i++) {
int nblock = i / threadsPerBlock;//第几个block
int inblock = i % threadsPerBlock;//block中第几个threads
//判断当前线程是否被标记为无效
if (!(remv[nblock] & (1ULL << inblock))) {
keep_out[num_to_keep++] = i;
unsigned long long* p = mask_host + i * col_blocks;//实际上将所有的形式设置成one hot形式。
for (int j = nblock; j < col_blocks; j++) {
remv[j] |= p[j];//按位或运算,并将结果保留在remv数组中
}
}
}
AT_CUDA_CHECK(cudaGetLastError());//检测CUDA 是否发生错误
return order_t.index(
{keep.narrow(/*dim=*/0, /*start=*/0, /*length=*/num_to_keep)//从张量keep中选择制定维度、起始位置和长度的子张量
.to(order_t.device(), keep.scalar_type())});
}template <typename T>
__global__ void nms_kernel(const int n_boxes, const float iou_threshold, const T* dev_boxes, unsigned long long* dev_mask) {
const int row_start = blockIdx.y;
const int col_start = blockIdx.x;
// if (row_start > col_start) return;
const int row_size = min(n_boxes - row_start * threadsPerBlock, threadsPerBlock);//当前block行可以放多少个box
const int col_size = min(n_boxes - col_start * threadsPerBlock, threadsPerBlock);//获取block列可以放多少个box
__shared__ T block_boxes[threadsPerBlock * 4];
if (threadIdx.x < col_size) {//将当前block列的box拷贝到shared memory
block_boxes[threadIdx.x * 4 + 0] = dev_boxes[(threadsPerBlock * col_start + threadIdx.x) * 4 + 0];
block_boxes[threadIdx.x * 4 + 1] = dev_boxes[(threadsPerBlock * col_start + threadIdx.x) * 4 + 1];
block_boxes[threadIdx.x * 4 + 2] = dev_boxes[(threadsPerBlock * col_start + threadIdx.x) * 4 + 2];
block_boxes[threadIdx.x * 4 + 3] = dev_boxes[(threadsPerBlock * col_start + threadIdx.x) * 4 + 3];
}
__syncthreads();//同步
if (threadIdx.x < row_size) {
const int cur_box_idx = threadsPerBlock * row_start + threadIdx.x;//当前block行box的索引
const T* cur_box = dev_boxes + cur_box_idx * 4;//当前block行box的指针
int i = 0;
unsigned long long t = 0;
int start = 0;
if (row_start == col_start) {
start = threadIdx.x + 1;//自己的IOU就不算了
}
for (i = start; i < col_size; i++) {
if (devIoU<T>(cur_box, block_boxes + i * 4) > iou_threshold) {//计算各自的IOU
t |= 1ULL << i;//以二进制的形式表示重叠关系成立
}
}
const int col_blocks = at::cuda::ATenCeilDiv(n_boxes, threadsPerBlock);//列block数
dev_mask[cur_box_idx * col_blocks + col_start] = t;//将重叠关系写入shared memory
}
}