变分自编码器(Variational Autoencoders, VAEs)是一种生成模型 Tutorial on Variational Autoencoders,它结合了概率图模型和深度学习,通过学习数据的潜在表示来生成新的数据样本。VAEs在数据生成、异常检测、数据压缩等领域具有广泛应用。以下是对变分自编码器的详细介绍。
一. 基本概念
自编码器
自编码器是一种神经网络,旨在通过压缩和解压缩过程重建输入数据。它由两个部分组成:
- 编码器(Encoder):将输入数据映射到一个低维潜在空间表示。
- 解码器(Decoder):将潜在空间表示重新映射回原始数据空间。
传统自编码器通过最小化输入数据与重构数据之间的差异来训练模型,但它们无法有效生成新数据。
变分自编码器
变分自编码器扩展了传统自编码器的能力,使其能够生成新的数据样本。VAE引入了概率图模型,通过在编码器输出潜在变量的分布,而不是固定的值,从而实现数据的生成。
二. VAE的工作原理
1. 潜在变量的分布
在VAE中,编码器输出的是输入数据的潜在分布参数(均值和标准差),而不是固定的潜在变量。具体来说,对于每个输入数据 x,编码器输出一个均值向量 μ 和一个标准差向量 σ,定义了潜在变量 z 的高斯分布 N(μ,σ)。
2. 重参数技巧(Reparameterization Trick)
为了能够通过梯度下降法进行优化,VAE使用重参数技巧。即将随机变量 z 表示为 z=μ+σ⋅ϵ,其中 ϵ 是从标准正态分布中采样的噪声。这一技巧允许误差反向传播通过随机变量 z,从而更新模型参数。
3. 损失函数
VAE的损失函数由两部分组成:
- 重构损失:测量重构数据与输入数据之间的差异,通常使用均方误差或二元交叉熵。
- KL散度(Kullback-Leibler Divergence):测量潜在变量分布 q(z∣x) 与先验分布 p(z) 之间的差异,通常假设先验分布为标准正态分布 N(0,I)。
总损失函数为:
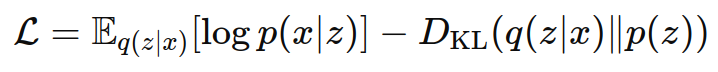
三、VAE的训练过程
- 前向传播:输入数据经过编码器,输出潜在变量的分布参数(均值和标准差)。使用重参数技巧采样潜在变量 z。
- 解码重构:将潜在变量 z 输入解码器,重构数据。
- 计算损失:计算重构损失和KL散度。
- 反向传播:通过梯度下降法最小化损失函数,更新模型参数。
四、应用场景
- 图像生成:VAE能够生成逼真的图像,如手写数字、面部图像等。
- 异常检测:通过学习正常数据的潜在分布,VAE可以检测出不符合该分布的异常数据。
- 数据压缩:VAE可以将数据压缩到潜在空间表示,再通过解码器重构原始数据。
- 数据增强:在数据不足的情况下,VAE可以生成额外的训练数据样本。
变分自编码器通过结合概率图模型和深度学习,提供了强大的生成能力和灵活的潜在表示,广泛应用于各种生成和分析任务中。