前言
在上一章《【课程总结】Day11(上):手势图像识别实战(LeNet模型)》课程中,我们通过使用LeNet模型实现了手势识别。在本章内容中,我们将搭建Vgg模型和ResNet模型,并应用到手势识别中。
Vgg模型
Vgg简介
VGG是一种深度卷积神经网络模型,由牛津大学的研究团队提出。它在2014年的ImageNet图像分类比赛中获得了第二名的好成绩,被广泛应用于计算机视觉领域。
论文地址:https://arxiv.org/abs/1409.1556
Vgg网络结构图
查看Vgg的论文可以看到Vgg的网络构成如下:

Vgg网络有不同的版本,本次我们使用Vgg16,即为图中D列对应的网络结构。该网络结构换另外一种展示方式如下图所示:
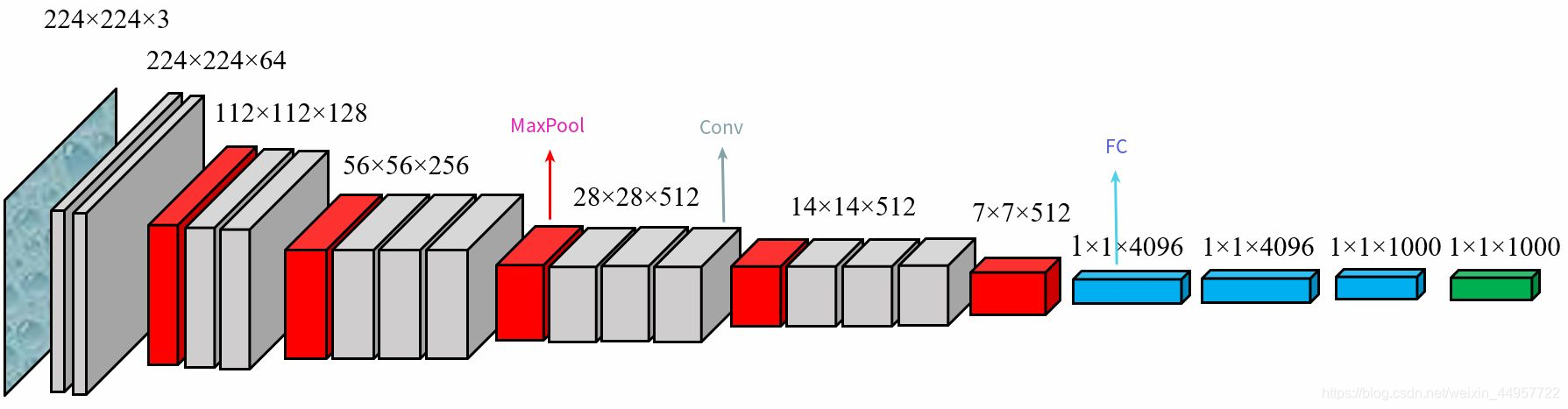
输入层
输入层是一张224×224的RGB图像,通道数为3,通道数代表RGB三个通道的像素值。
第一次卷积
经过2层的64×3×3卷积核,输出输出层为64×224×224。
- 卷积核大小为3×3,步长为1,填充为1
- 激活函数为ReLU
- 卷积次数为
2
第一次MaxPooling
经过最大池化层,图像尺寸减半,输出尺寸为64×112×112
- 池化核大小为2×2,步长为2
第二次卷积
经过2层的128×3×3卷积核,输出尺寸为128×112×112。
- 卷积核大小为3×3,步长为1,填充为1
- 激活函数为ReLU
- 卷积次数为
2
第二次MaxPooling
经过最大池化层,图像尺寸减半,输出尺寸为128×56×56
- 池化核大小为2×2,步长为2
第三次卷积
经过3层256×3×3卷积核,输出尺寸为256×56×56。
- 卷积核大小为3×3,步长为1,填充为1
- 激活函数为ReLU
- 卷积次数为
3
第三次MaxPooling
经过最大池化层,图像尺寸减半,输出尺寸为256×28×28
- 池化核大小为2×2,步长为2
第四次卷积
经过3层512×3×3卷积核,输出尺寸为512×28×28。
- 卷积核大小为3×3,步长为1,填充为1
- 激活函数为ReLU
- 卷积次数为
3
第四次MaxPooling
经过最大池化层,图像尺寸减半,输出尺寸为512×14×14
- 池化核大小为2×2,步长为2
第五次卷积
经过3层512×3×3卷积核,输出尺寸为512×14×14。
- 卷积核大小为3×3,步长为1,填充为1
- 激活函数为ReLU
- 卷积次数为
3
第五次MaxPooling
经过最大池化层,图像尺寸减半,输出尺寸为512×7×7
- 池化核大小为2×2,步长为2
全连接层
将feature map展平,输出一维尺寸为512×7×7=25088。
全链接4096
经过2层的1×1×4096的全连接层,输出尺寸为4096。
- 激活函数为ReLU
- 全链接次数为
2
全链接1000
经过1×1×1000的全连接层,输出尺寸为1000,最后通过softmax函数进行分类,输出1000个预测结果。
1000由最终分类数量决定,当年比赛需要分1000类
Vgg网络特点
- 小卷积核组:作者通过堆叠多个33的卷积核(少数使用11)来替代大的卷积核,以减少所需参数;
- 小池化核:相比较于AlexNet使用的33的池化核,VGG全部为22的池化核;
- 网络更深特征图更宽:卷积核专注于扩大通道数,池化专注于缩小高和宽,使得模型更深更宽的同时,计算量的增加不断放缓;
总结来说,Vgg这种设计可以增加网络的深度,提高特征提取的效果,同时减少了参数数量,降低了过拟合的风险。
Vgg网络搭建
import torch
from torch import nn
class ConvBlock(nn.Module):
"""
一层卷积:
- 卷积层
- 批规范化层
- 激活层
"""
def __init__(self, in_channels, out_channels,
kernel_size=3, stride=1, padding=1):
super().__init__()
self.conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride,padding=padding)
self.bn = nn.BatchNorm2d(num_features=out_channels)
self.relu = nn.ReLU()
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
class Vgg16(nn.Module):
def __init__(self, n_classes=1000):
super().__init__()
# 1, 特征抽取部分
self.feature_extractor = nn.Sequential(
# stage1
# 卷积1
ConvBlock(in_channels=3,
out_channels=64,
kernel_size=3,
stride=1,
padding=1),
# 卷积2
ConvBlock(in_channels=64,
out_channels=64,
kernel_size=3,
stride=1,
padding=1),
# 池化
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
# stage2
# 卷积1
ConvBlock(in_channels=64,
out_channels=128,
kernel_size=3,
stride=1,
padding=1),
# 卷积2
ConvBlock(in_channels=128,
out_channels=128,
kernel_size=3,
stride=1,
padding=1),
# 池化
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
# stage3
# 卷积1
ConvBlock(in_channels=128,
out_channels=256,
kernel_size=3,
stride=1,
padding=1),
# 卷积2
ConvBlock(in_channels=256,
out_channels=256,
kernel_size=3,
stride=1,
padding=1),
# 卷积3
ConvBlock(in_channels=256,
out_channels=256,
kernel_size=3,
stride=1,
padding=1),
# 池化
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
# stage4
# 卷积1
ConvBlock(in_channels=256,
out_channels=512,
kernel_size=3,
stride=1,
padding=1),
# 卷积2
ConvBlock(in_channels=512,
out_channels=512,
kernel_size=3,
stride=1,
padding=1),
# 卷积3
ConvBlock(in_channels=512,
out_channels=512,
kernel_size=3,
stride=1,
padding=1),
# 池化
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
# stage5
# 卷积1
ConvBlock(in_channels=512,
out_channels=512,
kernel_size=3,
stride=1,
padding=1),
# 卷积2
ConvBlock(in_channels=512,
out_channels=512,
kernel_size=3,
stride=1,
padding=1),
# 卷积3
ConvBlock(in_channels=512,
out_channels=512,
kernel_size=3,
stride=1,
padding=1),
# 池化
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
)
# 2, 分类
self.classifier = nn.Sequential(
nn.Flatten(),
nn.Linear(in_features=7 * 7 * 512, out_features=4096),
nn.ReLU(),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(),
nn.Linear(in_features=4096, out_features=n_classes)
)
def forward(self, x):
# 1, 提取特征
x = self.feature_extractor(x)
# 2, 分类输出
x = self.classifier(x)
return x
手势识别Vgg的应用
在【课程总结】Day11(上):手势图像识别实战(LeNet模型)中,我们已经实现了整体的流程如下:
- 数据预处理
1.1 数据读取
1.2 数据切分
1.3 数据规范化 - 批量化打包数据
- 模型搭建
- 筹备训练
- 训练模型
5.1 定义监控指标和方法
5.2 实现训练过程
5.3 开始训练
相比LeNet模型的使用过程,我们只需要对模型搭建、训练模型、模型预测部分进行适当修改即可。
模型搭建
将上述Vgg16模型代码封装到models.py中,然后在训练代码中如下引用即可:
from models import Vgg16
model = Vgg16(n_classes=10)
模型训练
在train()的方法中,修改训练后的模型名称
# ....(以上代码省略)
# 保存模型
if cur_test_acc < test_acc:
cur_test_acc = test_acc
# 保存最好模型
torch.save(obj=model.state_dict(), f="vgg16_best.pt")
# 保存最后模型
torch.save(obj=model.state_dict(), f="vgg16_last.pt")
运行结果:
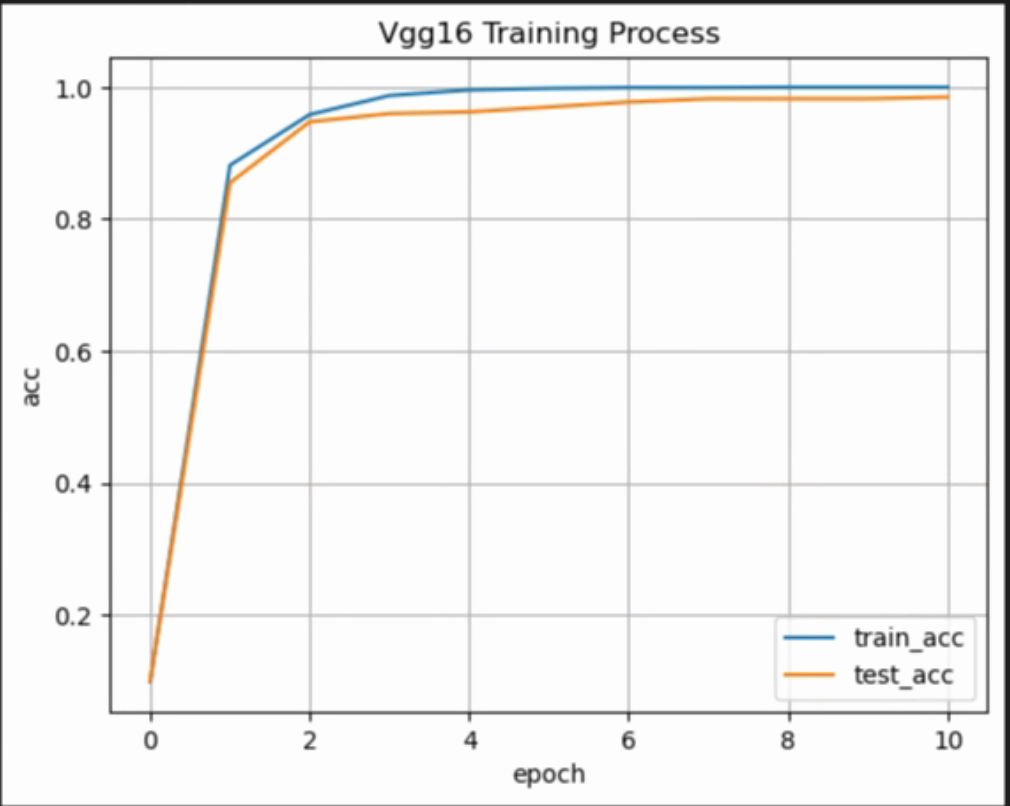
模型预测
在streamlit的前端页面中,修改模型加载部分的代码:
# 2, 加载模型
m1 = Vgg16()
m1.to(device=device)
# 加载权重
m1.load_state_dict(state_dict=torch.load(f="vgg16_best.pt", map_location=device),
strict=False)
if not isinstance(m1, Vgg16):
raise ValueError("模型加载失败")
运行结果:
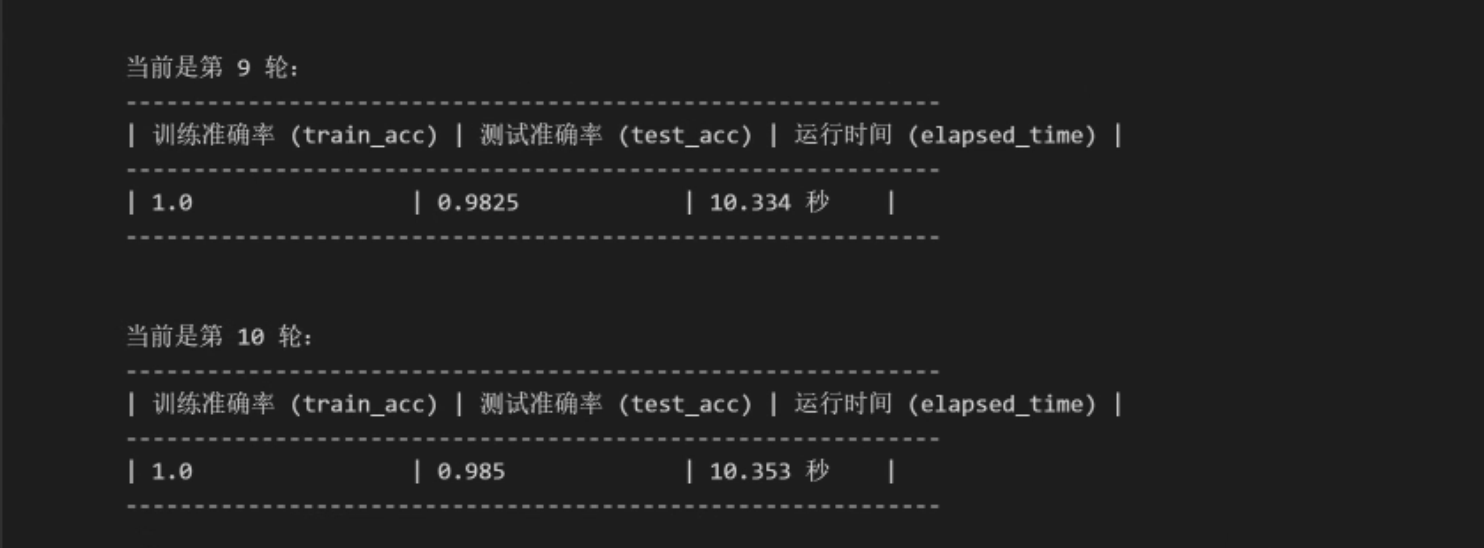
ResNet模型
ResNet简介
ResNet 网络是在 2015年 由微软实验室中的何凯明等几位大神提出,斩获当年ImageNet竞赛中分类任务第一名,目标检测第一名。该网络结构中残差思想,解决了梯度消失和梯度爆炸问题,使得神经网络更多层卷积成为可能。
ResNet引入背景
在ResNet提出之前,所有的神经网络都是通过卷积层和池化层的叠加组成的。
人们认为卷积层和池化层的层数越多,获取到的图片特征信息越全,学习效果也就越好。但是在实际的试验中发现,随着网络层数的增加,梯度在反向传播过程中逐渐变得非常小,导致深层网络难以训练的现象。

备注:关于梯度消失的详细论述不是本章重点,如须了解更详细内容,可以查看
CSDN:ResNet50超详细解析!!!
残差思想
为了避免梯度消失问题,ResNet的关键创新是引入了residual结构(残差结构),将输入信号直接跳过一到多层,与后续层的输出相加,而不是简单地经过一层层的变换。这种设计使得网络可以更轻松地学习残差映射,有助于减轻梯度消失问题。

所谓的残差结构是在正常网络的结构中,增加一个分支结构,这样网络的输出便不再是F\left ( x \right ),而是F\left ( x \right )+x
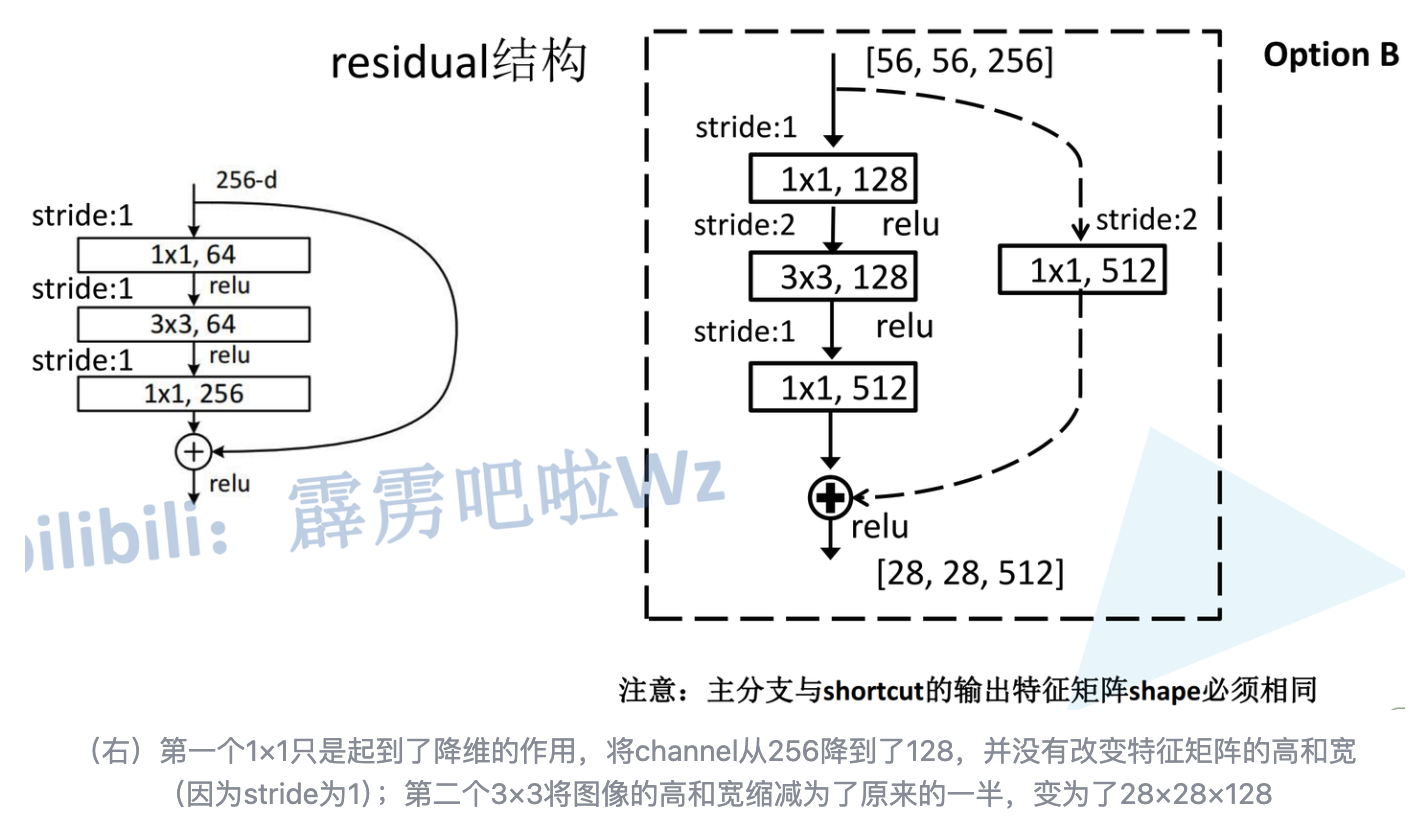
实线残差结构 VS 虚线残差结构
ResNet由实线残差结构和虚线残差结构两种:
以深层(50/101/152)为例,实线和虚线残差结构如下图所示:
残差结构代码实现
虚线残差结构
import torch
from torch import nn
class ConvBlock(nn.Module):
"""
虚线块,每一个大的重复逻辑块前面,第一个短接块就是这个
实现逻辑:
y = F(x) + Conv(x)
"""
def __init__(self, in_channels, out_channels, stride):
# 调用父类初始化方法
super().__init__()
# 1,核心处理逻辑
self.stage = nn.Sequential(
# 1 1 * 1
nn.Conv2d(in_channels=in_channels,
out_channels=out_channels[0],
kernel_size=1,
stride=stride,
padding=0,
bias=False),
nn.BatchNorm2d(num_features=out_channels[0]),
nn.ReLU(),
# 2 3 * 3
nn.Conv2d(in_channels=out_channels[0],
out_channels=out_channels[1],
kernel_size=3,
padding=1,
stride=1,
bias=False),
nn.BatchNorm2d(num_features=out_channels[1]),
nn.ReLU(),
# 3 1 * 1
nn.Conv2d(in_channels=out_channels[1],
out_channels=out_channels[2],
kernel_size=1,
stride=1,
padding=0,
bias=False),
nn.BatchNorm2d(num_features=out_channels[2]))
# 2,短路层
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels=in_channels,
out_channels=out_channels[2],
kernel_size=1,
stride=stride,
padding=0,
bias=False),
nn.BatchNorm2d(num_features=out_channels[2])
)
# 3,最后的激活
self.relu = nn.ReLU()
def forward(self, x):
# 1,短接处理
s = self.shortcut(x)
# 2,核心处理
h = self.stage(x)
# 3,两部分相加 add
h = h + s
# 4,输出 激活
o = self.relu(h)
return o
实线残差结构
class IdentityBlock(nn.Module):
"""
实线块
y = F(x) + x
"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.stage = nn.Sequential(
# 1:1 x 1
nn.Conv2d(in_channels=in_channels,
out_channels=out_channels[0],
kernel_size=1,
padding=0,
stride=1,
bias=False),
nn.BatchNorm2d(num_features=out_channels[0]),
nn.ReLU(),
# 2:3 x 3
nn.Conv2d(in_channels=out_channels[0],
out_channels=out_channels[1],
kernel_size=3,
padding=1,
stride=1,
bias=False),
nn.BatchNorm2d(num_features=out_channels[1]),
nn.ReLU(),
# 3:1 x 1
nn.Conv2d(in_channels=out_channels[1],
out_channels=out_channels[2],
kernel_size=1,
padding=0,
stride=1,
bias=False),
nn.BatchNorm2d(num_features=out_channels[2])
)
self.relu = nn.ReLU()
def forward(self, x):
h = x + self.stage(x)
o = self.relu(h)
return o
对比实线残差结构和虚线残差结构,会发现其主要的不同点在于:
虚线残差结构:
def forward(self, x):
# 1,短接处理
s = self.shortcut(x)
# 2,核心处理
h = self.stage(x)
# 3,两部分相加 add
h = h + s
# 4,输出 激活
o = self.relu(h)
return o
实线残差结构:
def forward(self, x):
h = x + self.stage(x)
o = self.relu(h)
return o
虚线残差结构和实线残差结构都是有效的残差连接方式,有助于解决梯度消失问题,提高深度神经网络的训练效果。
ResNet50
基于引入残差结构的思想,ResNet50模型结构如下图所示:
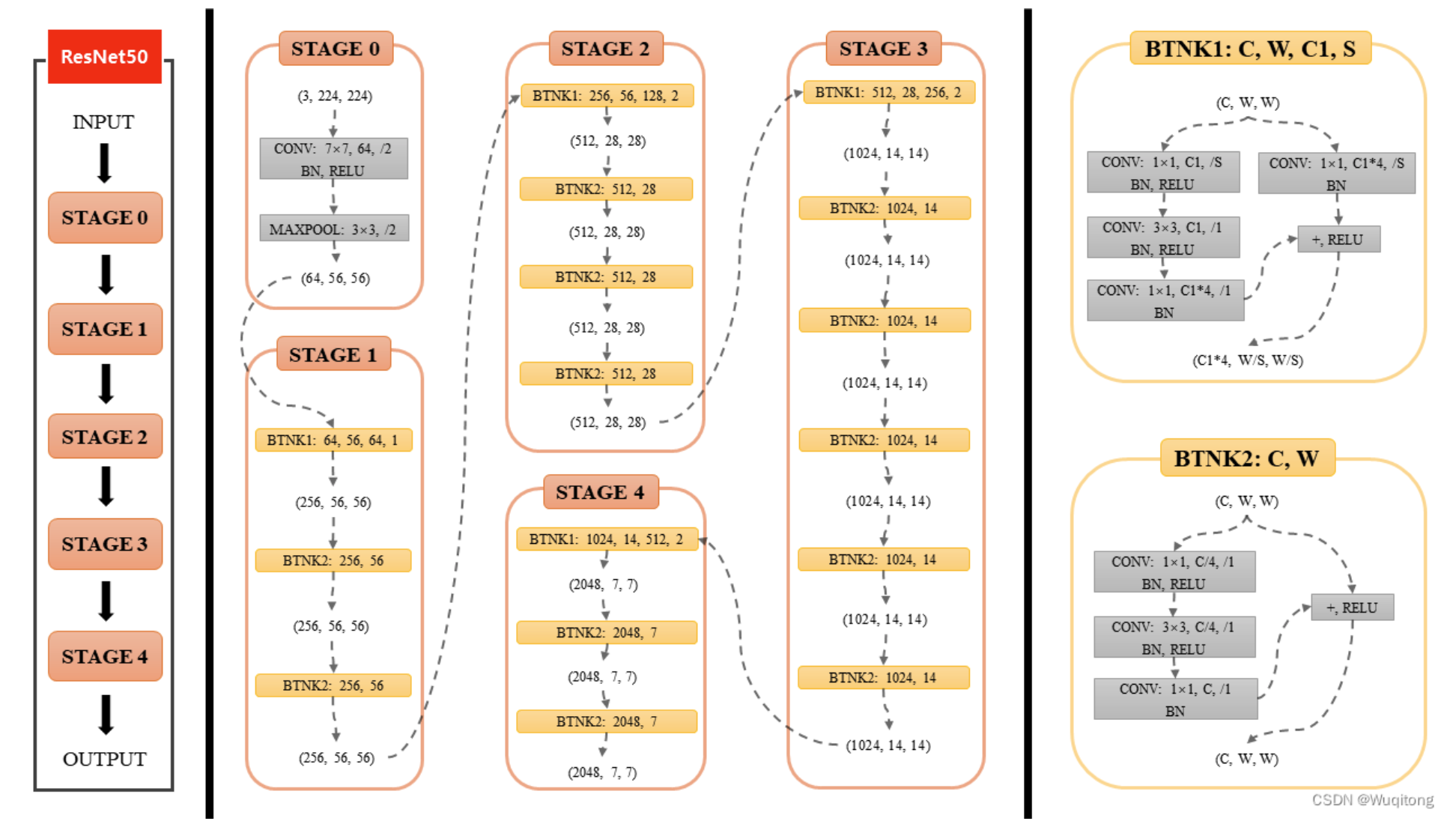
代码实现
class ResNet50(nn.Module):
"""
自定义 ResNet50
"""
def __init__(self, n_classes=1000):
super(ResNet50, self).__init__()
self.stage1 = nn.Sequential(
nn.Conv2d(in_channels=3,
out_channels=64,
kernel_size=7,
padding=3,
stride=2,
bias=False),
nn.BatchNorm2d(num_features=64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,
stride=2,
padding=1)
)
self.stage2 = nn.Sequential(
ConvBlock(in_channels=64,
out_channels=(64, 64, 256),
stride=1),
IdentityBlock(in_channels=256,
out_channels=(64, 64, 256)),
IdentityBlock(in_channels=256,
out_channels=(64, 64, 256)),
)
self.stage3 = nn.Sequential(
ConvBlock(in_channels=256,
out_channels=(128, 128, 512),
stride=2),
IdentityBlock(in_channels=512,
out_channels=(128, 128, 512)),
IdentityBlock(in_channels=512,
out_channels=(128, 128, 512)),
IdentityBlock(in_channels=512,
out_channels=(128, 128, 512))
)
self.stage4 = nn.Sequential(
ConvBlock(in_channels=512,
out_channels=(256, 256, 1024),
stride=2),
IdentityBlock(in_channels=1024,
out_channels=(256, 256, 1024)),
IdentityBlock(in_channels=1024,
out_channels=(256, 256, 1024)),
IdentityBlock(in_channels=1024,
out_channels=(256, 256, 1024)),
IdentityBlock(in_channels=1024,
out_channels=(256, 256, 1024)),
IdentityBlock(in_channels=1024,
out_channels=(256, 256, 1024))
)
self.stage5 = nn.Sequential(
ConvBlock(in_channels=1024,
out_channels=(512, 512, 2048),
stride=2),
IdentityBlock(in_channels=2048,
out_channels=(512, 512, 2048)),
IdentityBlock(in_channels=2048,
out_channels=(512, 512, 2048))
)
self.pool = nn.AdaptiveAvgPool2d(output_size=(1, 1))
self.fc = nn.Linear(in_features=2048,
out_features=n_classes)
def forward(self, x):
h = self.stage1(x)
h = self.stage2(h)
h = self.stage3(h)
h = self.stage4(h)
h = self.stage5(h)
h = self.pool(h)
h = h.view(h.size(0), -1)
o = self.fc(h)
return o
手势识别ResNet50的应用
类比Vgg16的手势识别的代码实现,我们修改以下相关内容
模型搭建
将上述Vgg16模型代码封装到models.py中,然后在训练代码中如下引用即可:
from models import ResNet50
model = ResNet50(n_classes=10)
模型训练
在train()的方法中,修改训练后的模型名称
# ....(以上代码省略)
# 保存模型
if cur_test_acc < test_acc:
cur_test_acc = test_acc
# 保存最好模型
torch.save(obj=model.state_dict(), f="resnet50_best.pt")
# 保存最后模型
torch.save(obj=model.state_dict(), f="resnet50_last.pt")
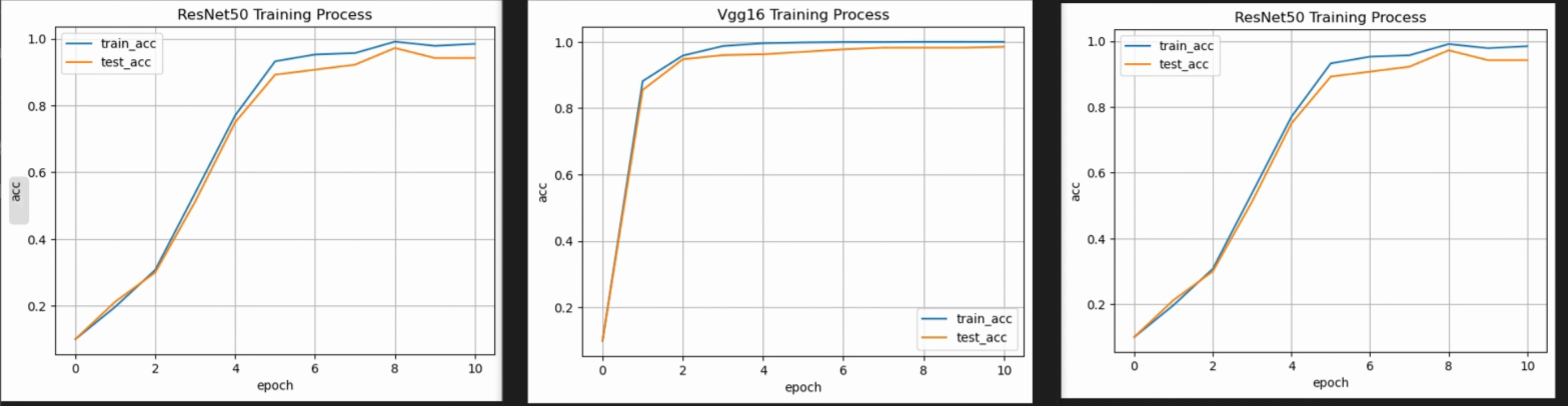
运行结果:
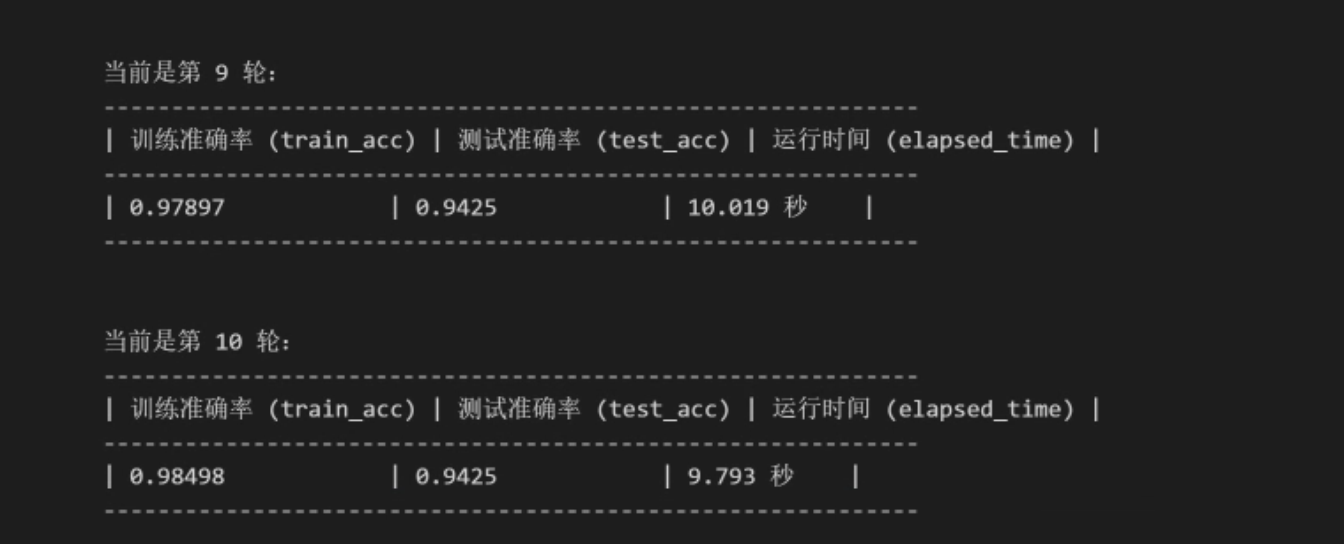
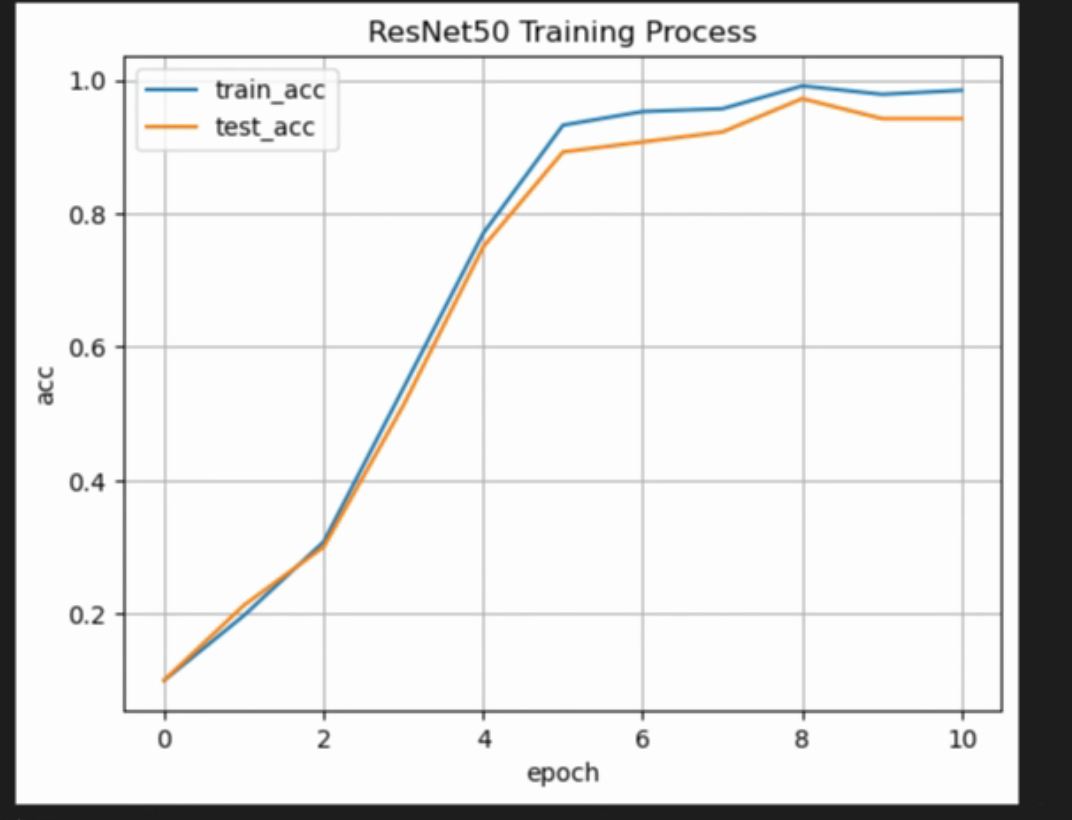
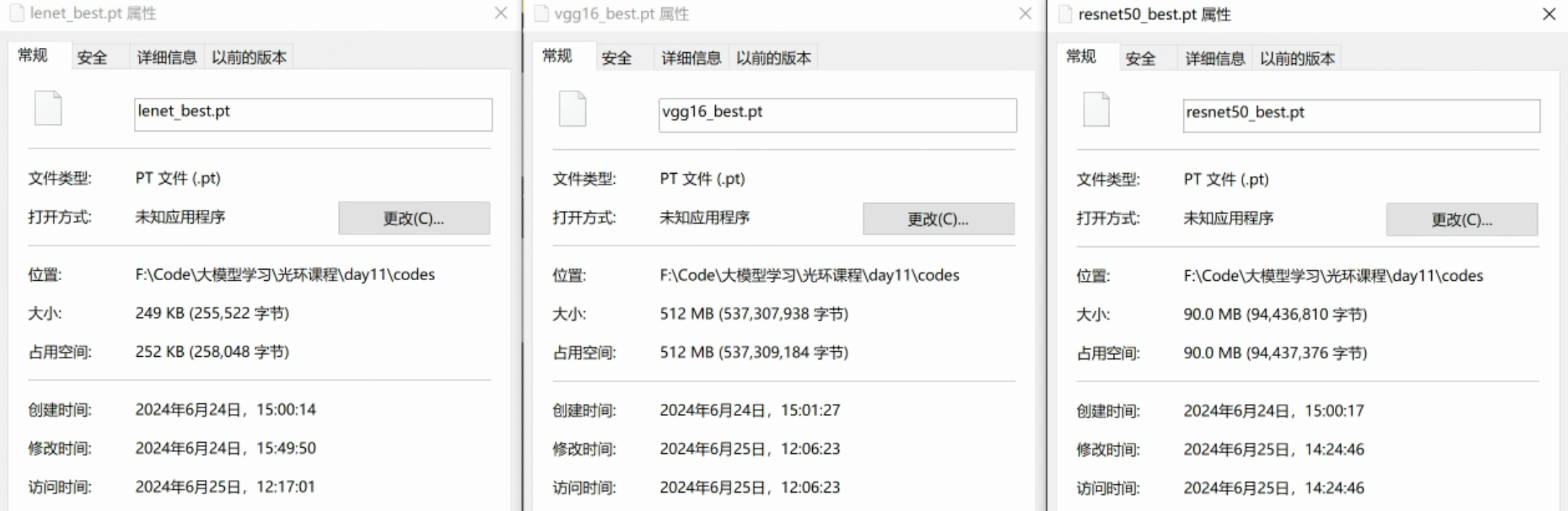
对比LeNet、Vgg16、ResNet50对比:
- Vgg16模型文件最大,LeNet模型文件最小,ResNet50模型文件适中
- Vgg16训练提升速度最快,在第4轮就已经达到90%的准确率
内容小结
- VGG是一种深度卷积神经网络模型,由牛津大学的研究团队提出。
- VGG的主要特点是更多层的卷积,同时采用了3x3卷积核,来替代大的卷积核,以减少所需参数。
- ResNet50是一种深度残差网络模型,由Microsoft Research团队提出。
- ResNet50中最核心的思想是引入残差结构,通过残差结构解决了梯度消失问题,从而提高了深度神经网络的训练效果。
参考资料
CSDN:VGG网络讲解——小白也能懂
CSDN:VGG 经典神经网络学习笔记 (附代码)
CSDN:ResNet50超详细解析!!!
知乎:ResNet(深度残差网络)原理及代码实现(基于Pytorch)