1. TF-IDF算法
F-IDF(词频-逆文档频率)是一种用于衡量文本中词语重要性的方法,特别适用于信息检索和文本挖掘任务。下面会拆分为两部分深入讲解TF-IDF的计算过程,以便更好地理解。
TF-IDF的计算过程可以分为两个主要部分:词频(TF)和逆文档频率(IDF)。
1.1 TF(词频)
词频是指某个词语在文档中出现的频率。TF表示了一个词语在文档中的重要性,通常通过以下公式计算:

计算出的TF值表示了词语在单个文档中的相对重要性,值越大表示词语在文档中越重要。
1.2 IDF(逆文档频率)
逆文档频率度量了一个词语在整个文档集合中的重要性。IDF值越大,表示词语在整个文档集合中越不常见,因此在文档中的重要性越高。IDF通常通过以下公式计算:

计算出的IDF值反映了词语的全局重要性,较不常见的词语具有较高的IDF值。
1.3 TF-IDF
TF-IDF的计算是将词频(TF)和逆文档频率(IDF)相结合,以确定词语在文档中的整体重要性。计算公式如下:
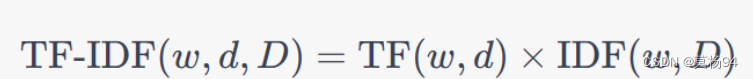
计算出的TF-IDF值表示了词语在文档 d 中的重要性,同时考虑了在整个文档集合 D 中的全局重要性。
2. BM25算法
BM25(Best Matching 25)是一种用于信息检索(Information Retrieval)和文本挖掘的算法,它被广泛应用于搜索引擎和相关领域。BM25 基于 TF-IDF(Term Frequency-Inverse Document Frequency)的思想,但对其进行了改进以考虑文档的长度等因素。
2.1 基本思想
- TF-IDF 的改进: BM25 通过对文档中的每个词项引入饱和函数(saturation function)和文档长度因子,改进了 TF-IDF 的计算。
- 饱和函数: 在 BM25 中,对于词项的出现次数(TF),引入了一个饱和函数来调整其权重。这是为了防止某个词项在文档中出现次数过多导致权重过大。
- 文档长度因子: BM25 考虑了文档的长度,引入了文档长度因子,使得文档长度对权重的影响不是线性的。这样可以更好地适应不同长度的文档。
2.2 计算公式