AI应用开发相关目录
本专栏包括AI应用开发相关内容分享,包括不限于AI算法部署实施细节、AI应用后端分析服务相关概念及开发技巧、AI应用后端应用服务相关概念及开发技巧、AI应用前端实现路径及开发技巧
适用于具备一定算法及Python使用基础的人群
- AI应用开发流程概述
- Visual Studio Code及Remote Development插件远程开发
- git开源项目的一些问题及镜像解决办法
- python实现UDP报文通信
- python实现日志生成及定期清理
- Linux终端命令Screen常见用法
- python实现redis数据存储
- python字符串转字典
- python实现文本向量化及文本相似度计算
- python对MySQL数据的常见使用
- 一文总结python的异常数据处理示例
- 基于selenium和bs4的通用数据采集技术(附代码)
- 基于python的知识图谱技术
- 一文理清python学习路径
- Linux、Git、Docker常用指令
- linux和windows系统下的python环境迁移
- linux下python服务定时(自)启动
- windows下基于python语言的TTS开发
- python opencv实现图像分割
- python使用API实现word文档翻译
- yolo-world:”目标检测届大模型“
- 爬虫进阶:多线程爬虫
- python使用modbustcp协议与PLC进行简单通信
- ChatTTS:开源语音合成项目
- sqlite性能考量及使用(附可视化操作软件)
- 拓扑数据的关键点识别算法
- python脚本将视频抽帧为图像数据集
- 图文RAG组件:360LayoutAnalysis中文论文及研报图像分析
- Ubuntu服务器的GitLab部署
- 无痛接入图像生成风格迁移能力:GAN生成对抗网络
- 一文理清OCR的前世今生
- labelme使用笔记
- HAC-TextRank算法进行关键语句提取
34.Segment any Text:优质文本分割是高质量RAG的必由之路
文章目录
- AI应用开发相关目录
文本自动切句是个很有趣且很重要的场景,传统的句子分割方法依赖于基于规则或统计的方法,这些方法通常需要依赖于标点符号等词汇特征,例如早期方法使用决策树来确定文本中的每个标点符号是否表示句子边界,这基于标点周围的语言特征。然而,这些方法在面对缺少标点、新领域适应性差、效率不高等问题时表现不佳。
huggingface:https://huggingface.co/segment-any-text
这是一种用于改善自然语言处理(NLP)系统中文本句子分割的方法,据Segment any Text名称看,这是一个能够分割任意段落自然语言文本的工作。
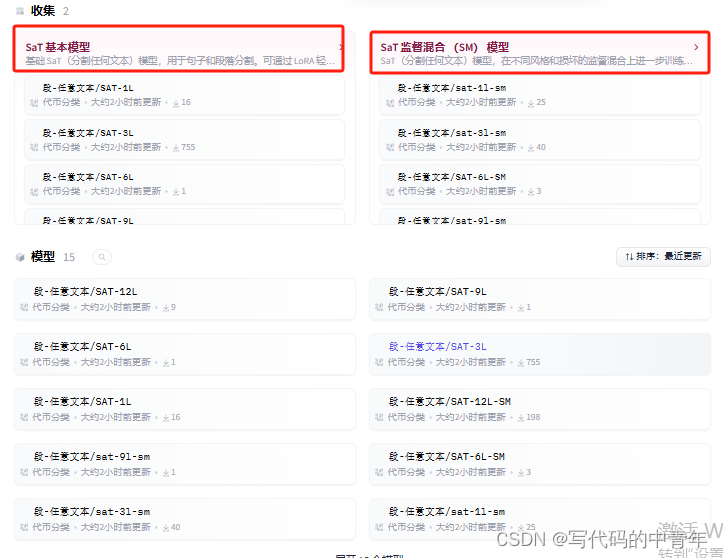
其算法主要分类基础模型和监督混合模型(SM)两类。基础 SaT(分割任何文本)模型,用于句子和段落分割。可通过 LoRA 轻松适应;SM则在不同风格和损坏的监督混合数据上进一步训练。
每种模型后边的数字表示几个transfomer层:

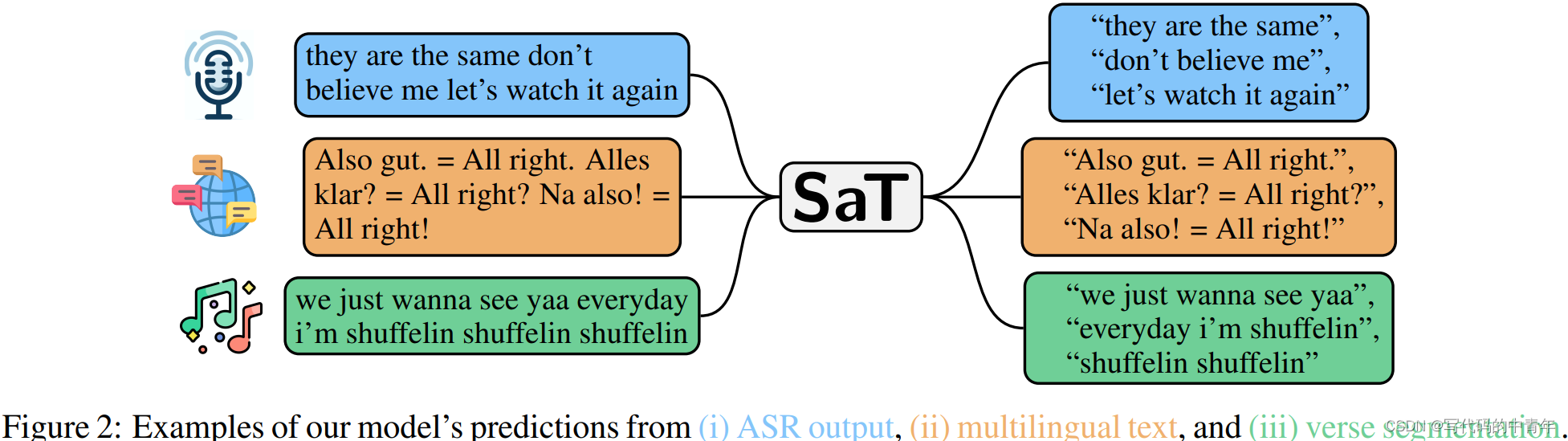
通过示例可以发现,其各种文本,是包括了无标点无格式文本、符号混乱无格式文本、语义混乱无格式文本。
可推测模型具备在文本分割需求下的语言理解能力,该工作大大增强了文本分割的适用面。
但缺陷是:
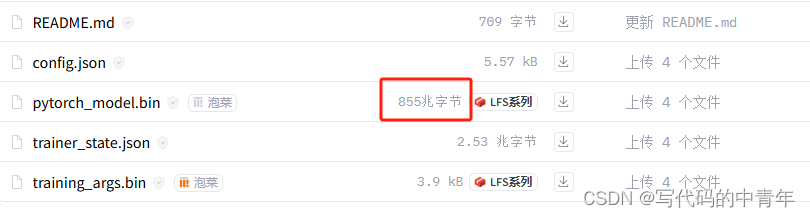
模型不小。
此次分享,各位按需使用。










![[AI MoneyPrinterTurbo] 一键成片,超级印钞机](https://img-blog.csdnimg.cn/img_convert/26b0f8c71be0ae4c6f3b6b8014d4c7ab.png)