目录
处理函数分类
概览介绍
KeydProcessFunction和ProcessFunction
定时器TimeService
窗口处理函数
多流转换
分流-侧输出流
合流
联合(Uniion)
连接(connect)
广播连接流(BroadcatConnectedStream)
基于时间的合流 -双流联结
窗口连接(windowjoin)
间隔联结(Interval join)
窗口同组联结(window CoGroup)
处理函数分类
窗口 | Apache Flink
处理函数分8种;datastream调用keyby()后得到keyedStream,进而调用window()得到WindowedStream,对于不同的流都可以调用process方法进行自定处理;这是传入的函数都叫处理函数;
概览介绍
flink提供8种不同的处理函数;
窗口和流都可以使用
1.ProcessFunction 是最基本的处理函数,基于DataStream直接调用process()时作为参数传入;
2.KeydProcessFunction:是对流进行分区后的处理函数,基于KeyedStream调用process()时作为参数传入。只有该方法支持定时器功能(onTime);
窗口函数,只有窗口可以使用
3.ProcessWindowFunction:是开窗之后的处理函数,也是全窗口函数的代表,基于windowedStream调用process()时作为参数传入;
4.ProcessAllWindowFunction:开窗后处理函数,基于allWindowedStream的process()时作为参数传入。
连接函数流join使用
5.CoProcessFunction:是合并两条留之后的处理函数,基于ConnectedStreams调用process()时作为参数传入;
窗口的join使用
6.ProcessJoinFunction:是间隔连接两条流字之后的处理函数,基于IntervalJOined调用process()时作为参数传入;
广播状态
7.BroadcastProcessFunction:是广播连接流处理函数,基于BroadcastConnectedStream调用process()时作为参数传入,这里BroadcastConnectedStream是一个未做keyby处理的普通DataStream,与一个广播流(BroadcastStream)连接之后的产物;
8.KeyedBroadcastFunction:是按键分区的广播连接流处理函数,同样基于BroadConnectedStream调用process()时作为参数传入;与BroadcastProcessFunction不同的是是的广播流是keyedStream,与一个广播流(BroadcastStream)连接之后的产物;
KeydProcessFunction和ProcessFunction
我们在看源码的时候看到ProcessFunction 和KeydProcessFunction结构一样,都有两个接口,一个必须实现的processElement()抽象方法,一个非抽象方法onTimer()。差别在上下文Context中KeydProcessFunction多一个获取当前分区key的方法 getCurrentKey。当使用ProcessFunction使用定时器时程序运行会报错,提示定时器只支持keyStream使用;
stream.process(new ProcessFunction< Event, String>() {
@Override
public void processElement(Event value, ProcessFunction<Event, String>.Context ctx, Collector<String> out) throws Exception {
Long currTs = ctx.timerService().currentProcessingTime();
out.collect("数据到达,到达时间:" + new Timestamp(currTs));
// 注册一个10秒后的定时器
ctx.timerService().registerProcessingTimeTimer(currTs + 10 * 1000L);
}
@Override
public void onTimer(long timestamp, ProcessFunction<Event, String>.OnTimerContext ctx, Collector<String> out) throws Exception {
out.collect("定时器触发,触发时间:" + new Timestamp(timestamp));
}
})
程序运行后报错
Caused by: java.lang.UnsupportedOperationException: Setting timers is only supported on a keyed streams.
at org.apache.flink.streaming.api.operators.ProcessOperator$ContextImpl.registerProcessingTimeTimer(ProcessOperator.java:118)
at com.atguigu.chapter07.ProcessingTimeTimerTest$1.processElement(ProcessingTimeTimerTest.java:55)
at com.atguigu.chapter07.ProcessingTimeTimerTest$1.processElement(ProcessingTimeTimerTest.java:47)
at org.apache.flink.streaming.api.operators.ProcessOperator.processElement(ProcessOperator.java:66)
at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.pushToOperator(CopyingChainingOutput.java:71)
at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.collect(CopyingChainingOutput.java:46)
at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.collect(CopyingChainingOutput.java:26)
at org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:50)
at org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:28)
at org.apache.flink.streaming.api.operators.StreamSourceContexts$ManualWatermarkContext.processAndCollect(StreamSourceContexts.java:317)
at org.apache.flink.streaming.api.operators.StreamSourceContexts$WatermarkContext.collect(StreamSourceContexts.java:411)
at com.atguigu.chapter05.ClickSource.run(ClickSource.java:26)
at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:110)
at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:66)
at org.apache.flink.streaming.runtime.tasks.SourceStreamTask$LegacySourceFunctionThread.run(SourceStreamTask.java:269)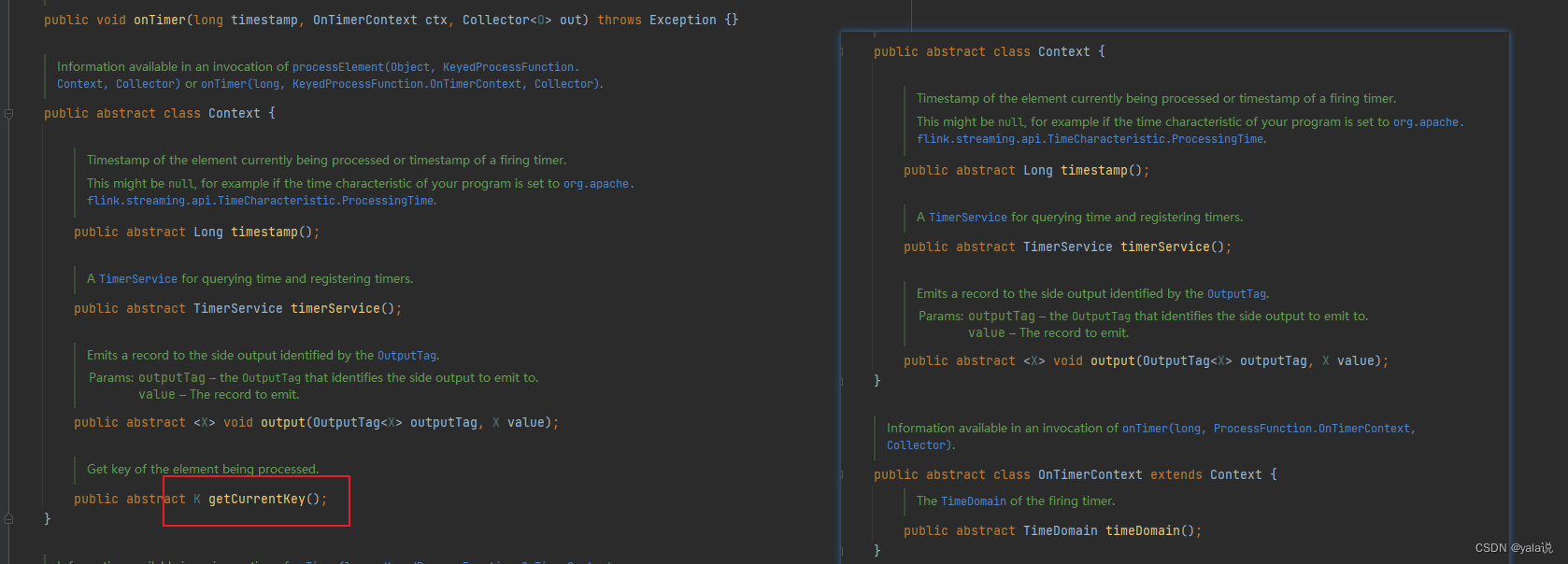
定时器TimeService
TimeService中有六个方法,可以分为基于处理时间和基于事件时间的方法两大类种;时间精度为毫秒;
获取当前处理时间 long currentProcessingTime(); 获取当前水印时间 long currentWatermark(); 注册处理时间为定时器 void registerProcessingTimeTimer(long time);
long coalescedTime = ((ctx.timestamp() + timeout) / 1000) * 1000;
ctx.timerService().registerProcessingTimeTimer(coalescedTime);注册时间时间为定时器 void registerEventTimeTimer(long time);
long coalescedTime = ctx.timerService().currentWatermark() + 1;
ctx.timerService().registerEventTimeTimer(coalescedTime);删除处理时间定时器 void deleteProcessingTimeTimer(long time);
long timestampOfTimerToStop = ...
ctx.timerService().deleteProcessingTimeTimer(timestampOfTimerToStop);删除时间时间定时器 void deleteEventTimeTimer(long time);
long timestampOfTimerToStop = ...
ctx.timerService().deleteEventTimeTimer(timestampOfTimerToStop);注意:另外定时器使用处理时间和时间在触发上有区别,当设置定时任务为处理时间时,即便后续没有数据写入,定时器依然可以正常触发计算,当如果设置为时间时,定时任务时间依赖水印时间线。只有当水印时间大于定时器触发时间时才会触发计算,即如果后入没有实时数据进入时,最后一个定时器一直不会触发;
窗口处理函数
ProcessWindowFunction和ProcessAllWindowFunction既是创立函数又是全窗口函数,从名称上看他更倾向于窗口函数。用法与处理函数不同。 没有ontime借口和定时器服务,一般窗口有使用窗口触发器Trigger,在作用上可以类似timeservice的作用。
源码上看:
abstract class ProcessWindowFunction[IN, OUT, KEY, W <: Window]
extends AbstractRichFunction {
/**
* Evaluates the window and outputs none or several elements.
*
* @param key The key for which this window is evaluated.
* @param context The context in which the window is being evaluated.
* @param elements The elements in the window being evaluated.
* @param out A collector for emitting elements.
* @throws Exception The function may throw exceptions to fail the program and trigger recovery.
*/
@throws[Exception]
def process(key: KEY, context: Context, elements: Iterable[IN], out: Collector[OUT])
// 如果有自定义状态,该方法调用清理
@throws[Exception]
def clear(context: Context) {}
abstract class Context {
def window: W
def currentProcessingTime: Long
def currentWatermark: Long
// 获取自定义窗口状态 对当前key,当前窗口有效
def windowState: KeyedStateStore
// 获取自定义全局状态 对当前key的全部窗口有效
def globalState: KeyedStateStore
def output[X](outputTag: OutputTag[X], value: X);
}
}
--------------用法演示------------
DataStream<Tuple2<String, Long>> input = ...;
input
.keyBy(t -> t.f0)
.window(TumblingEventTimeWindows.of(Time.minutes(5)))
.process(new MyProcessWindowFunction());
/* ... */
public class MyProcessWindowFunction
extends ProcessWindowFunction<Tuple2<String, Long>, String, String, TimeWindow> {
@Override
public void process(String key, Context context, Iterable<Tuple2<String, Long>> input, Collector<String> out) {
long count = 0;
for (Tuple2<String, Long> in: input) {
count++;
}
out.collect("Window: " + context.window() + "count: " + count);
}
}多流转换
分流-侧输出流
处理函数有一个特殊功能来处理迟到数据和进行分流,侧输出流(Side Output),再使用可以通过processElement或onTimer的下文context的output()方法就可以了;
旁路输出 | Apache Flink
一下函数都可以获取
- ProcessFunction
- KeyedProcessFunction
- CoProcessFunction
- KeyedCoProcessFunction
- ProcessWindowFunction
- ProcessAllWindowFunction
用法示例
DataStream<Integer> input = ...;
//定义
final OutputTag<String> outputTag = new OutputTag<String>("side-output"){};
SingleOutputStreamOperator<Integer> mainDataStream = input
.process(new ProcessFunction<Integer, Integer>() {
@Override
public void processElement(
Integer value,
Context ctx,
Collector<Integer> out) throws Exception {
// 发送数据到主要的输出
out.collect(value);
// 发送数据到旁路输出
ctx.output(outputTag, "sideout-" + String.valueOf(value));
}
});
//外部获取测试给出流
DataStream<String> sideOutputStream = mainDataStream.getSideOutput(outputTag);分流之前有split()在1.13版本中已经弃用,直接使用处理函数的侧输出流;
合流
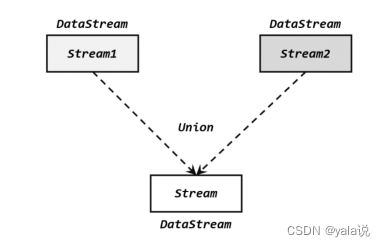
联合(Uniion)
将多个流合成一个流,而一个流中数据类型必须是相同的,因此要求多个流的数据类型必须相同才能合并,合并后流包含所有流的元素,如果流有水位线,合流之后的水位线为最小的为准;
stream1.union(Stream2,stream3,...),
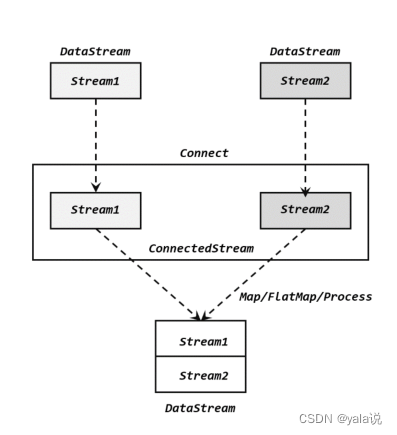
连接(connect)
connect得到的是connectedStreams,与联合有本质的不同,两个是量多流合并成一个流,数据是混在一个流中,跟一个流没什么区别,而connect合并后内部仍然各自保持自己的数据形式不变,彼此独立。因此可以处理不同类型的数据,但是只能两个流连接。如果想要得到新的DataStream,还需要自定义一个“同处理”(co-propcess)转换操作,对不同类型数据进行分别处理转换成同一种类型。
DataStream<Integer> someStream = //...
DataStream<String> otherStream = //...
ConnectedStreams<Integer, String> connectedStreams = someStream.connect(otherStream);coMap和coflatmap函数
connectedStreams.map(new CoMapFunction<Integer, String, Boolean>() {
@Override
public Boolean map1(Integer value) {
return true;
}
@Override
public Boolean map2(String value) {
return false;
}
});
connectedStreams.flatMap(new CoFlatMapFunction<Integer, String, String>() {
@Override
public void flatMap1(Integer value, Collector<String> out) {
out.collect(value.toString());
}
@Override
public void flatMap2(String value, Collector<String> out) {
for (String word: value.split(" ")) {
out.collect(word);
}
}
});CoprocessFunction
是处理函数中的亿元,与处理函数用法相识,,keyby的key类型必须相同
appStream.connect(thirdpartStream)
.keyBy(data -> data.f0, data -> data.f0)
.process(new OrderMatchResult())
.print();
public static class OrderMatchResult extends CoProcessFunction<Tuple3<String, String, Long>, Tuple4<String, String, String, Long>, String>{
// 定义状态变量,用来保存已经到达的事件
private ValueState<Tuple3<String, String, Long>> appEventState;
private ValueState<Tuple4<String, String, String, Long>> thirdPartyEventState;
@Override
public void open(Configuration parameters) throws Exception {
appEventState = getRuntimeContext().getState(
new ValueStateDescriptor<Tuple3<String, String, Long>>("app-event", Types.TUPLE(Types.STRING, Types.STRING, Types.LONG))
);
thirdPartyEventState = getRuntimeContext().getState(
new ValueStateDescriptor<Tuple4<String, String, String, Long>>("thirdparty-event", Types.TUPLE(Types.STRING, Types.STRING, Types.STRING,Types.LONG))
);
}
@Override
public void processElement1(Tuple3<String, String, Long> value, Context ctx, Collector<String> out) throws Exception {
// 看另一条流中事件是否来过
if (thirdPartyEventState.value() != null){
out.collect("对账成功:" + value + " " + thirdPartyEventState.value());
// 清空状态
thirdPartyEventState.clear();
} else {
// 更新状态
appEventState.update(value);
// 注册一个5秒后的定时器,开始等待另一条流的事件
ctx.timerService().registerEventTimeTimer(value.f2 + 5000L);
}
}
@Override
public void processElement2(Tuple4<String, String, String, Long> value, Context ctx, Collector<String> out) throws Exception {
if (appEventState.value() != null){
out.collect("对账成功:" + appEventState.value() + " " + value);
// 清空状态
appEventState.clear();
} else {
// 更新状态
thirdPartyEventState.update(value);
// 注册一个5秒后的定时器,开始等待另一条流的事件
ctx.timerService().registerEventTimeTimer(value.f3 + 5000L);
}
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<String> out) throws Exception {
// 定时器触发,判断状态,如果某个状态不为空,说明另一条流中事件没来
if (appEventState.value() != null) {
out.collect("对账失败:" + appEventState.value() + " " + "第三方支付平台信息未到");
}
if (thirdPartyEventState.value() != null) {
out.collect("对账失败:" + thirdPartyEventState.value() + " " + "app信息未到");
}
appEventState.clear();
thirdPartyEventState.clear();
}
}}广播连接流(BroadcatConnectedStream)
DataStream在调用connect()时传入的参数可以不是一个DataStream,而是一个广播流(BroadcastStream),这是合并两条流,得到的就是一个广播连接流(BroadcastConnectedStream),比较实用动态定义规则或配置的场景。下游算子收到广播规则后吧保存为状态。这就是广播状态。
广播状态底层是一个映射(map)结构来保存的。可以直接DataStream.broadcast()方法调用;
// 一个 map descriptor,它描述了用于存储规则名称与规则本身的 map 存储结构
MapStateDescriptor<String, Rule> ruleStateDescriptor = new MapStateDescriptor<>(
"RulesBroadcastState",
BasicTypeInfo.STRING_TYPE_INFO,
TypeInformation.of(new TypeHint<Rule>() {}));
// 广播流,广播规则并且创建 broadcast state
BroadcastStream<Rule> ruleBroadcastStream = ruleStream
.broadcast(ruleStateDescriptor);
//使用
DataStream<String> output = colorPartitionedStream
.connect(ruleBroadcastStream)
.process(
// KeyedBroadcastProcessFunction 中的类型参数表示:
// 1. key stream 中的 key 类型
// 2. 非广播流中的元素类型
// 3. 广播流中的元素类型
// 4. 结果的类型,在这里是 string
new KeyedBroadcastProcessFunction<Color, Item, Rule, String>() {
// 模式匹配逻辑
}
);为了关联一个非广播流(keyed 或者 non-keyed)与一个广播流(BroadcastStream),我们可以调用非广播流的方法 connect(),并将 BroadcastStream 当做参数传入。 这个方法的返回参数是 BroadcastConnectedStream,具有类型方法 process(),传入一个特殊的 CoProcessFunction 来书写我们的模式识别逻辑。 具体传入 process() 的是哪个类型取决于非广播流的类型:
- 如果流是一个 keyed 流,那就是
KeyedBroadcastProcessFunction类型; - 如果流是一个 non-keyed 流,那就是
BroadcastProcessFunction类型。
BroadcastProcessFunction 和 KeyedBroadcastProcessFunction
在传入的 BroadcastProcessFunction 或 KeyedBroadcastProcessFunction 中,我们需要实现两个方法。processBroadcastElement() 方法负责处理广播流中的元素,processElement() 负责处理非广播流中的元素。 两个子类型定义如下:
public abstract class BroadcastProcessFunction<IN1, IN2, OUT> extends BaseBroadcastProcessFunction {
public abstract void processElement(IN1 value, ReadOnlyContext ctx, Collector<OUT> out) throws Exception;
public abstract void processBroadcastElement(IN2 value, Context ctx, Collector<OUT> out) throws Exception;
}
public abstract class KeyedBroadcastProcessFunction<KS, IN1, IN2, OUT> {
public abstract void processElement(IN1 value, ReadOnlyContext ctx, Collector<OUT> out) throws Exception;
public abstract void processBroadcastElement(IN2 value, Context ctx, Collector<OUT> out) throws Exception;
public void onTimer(long timestamp, OnTimerContext ctx, Collector<OUT> out) throws Exception;
}基于时间的合流 -双流联结
窗口连接(windowjoin)
flink内置的join算子,join()和coGroup(),适用于窗口统计的,不用再进行自定义触发器,简化了开发逻辑; 等同于sql的inner join on 或 select * from table1 t1,table2 t2 where t1.id=t2.id
wehre()和 equalTo()方法制定两条流中连接的key;然后通过window()开窗口,并调用apply()传入自连接窗口函数进行计算,
stream.join(otherStream)
.where(<KeySelector>) //stream的key
.equalTo(<KeySelector>) //otherStream的key
.window(<WindowAssigner>)
.apply(<JoinFunction>)
//案例
stream1.join(stream2)
.where(r -> r.f0)
.equalTo(r -> r.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.apply(new JoinFunction<Tuple2<String, Long>, Tuple2<String, Long>, String>() {
@Override
public String join(Tuple2<String, Long> left, Tuple2<String, Long> right) throws Exception {
return left + "=>" + right;
}
})
.print();join function 不是真正的窗口函数,只是定义了窗口函数在调用是对匹配数据额具体处理逻辑。
@Public
@FunctionalInterface
public interface JoinFunction<IN1, IN2, OUT> extends Function, Serializable {
/**
* The join method, called once per joined pair of elements.
*
* @param first The element from first input.
* @param second The element from second input.
* @return The resulting element.
* @throws Exception This method may throw exceptions. Throwing an exception will cause the
* operation to fail and may trigger recovery.
*/
OUT join(IN1 first, IN2 second) throws Exception;
}
join时数据先按照key进行分组、进入对应的窗口存储,当窗口结束时,算子会先统计出窗口内两条流的数据所有组合,即做一个笛卡尔积;然后进行遍历传入joinfunction的join方法中
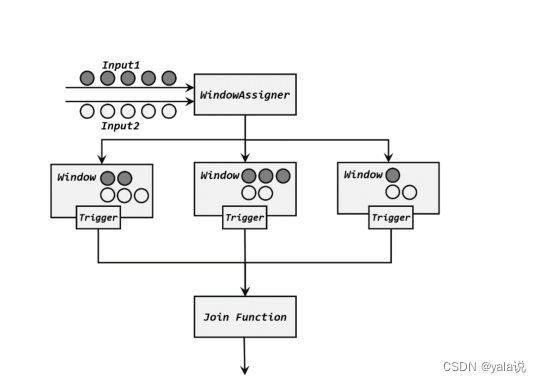
出了JoinFunction,在apply方法中还可以闯入FlatJoinFunction,使用方法类似,区别是内部join实现犯法没有返回值,使用收集器来实现。
间隔联结(Interval join)
间隔联结需要设定两个时间点,对应上界(upperBound)和下届(lowerBound),对于同一条流A的任意一个元素a,开辟一段时间间隔[a.timestamp+lowerBound,a.timestamp+upperBound],即开辟以a为中心,上下届点为边界的一个闭区间,相当于窗口。对于另外一条流B中的元素b,如果时间戳b.timestamp>=a.timestamp+lowerBound and b.timestamp<=a.timestamp+upperBoundm 那么a和b就可以匹配上;
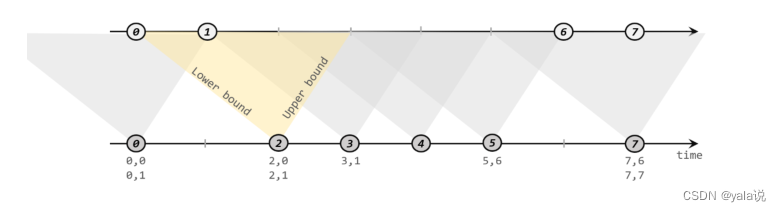
调用:
orderStream.keyBy(data -> data.f0)
.intervalJoin(clickStream.keyBy(data -> data.user))
.between(Time.seconds(-5), Time.seconds(10))
.process(new ProcessJoinFunction<Tuple3<String, String, Long>, Event, String>() {
@Override
public void processElement(Tuple3<String, String, Long> left, Event right, Context ctx, Collector<String> out) throws Exception {
out.collect(right + " => " + left);
}
})
.print();窗口同组联结(window CoGroup)
使用与join相同。将window的join替换成cogroup即可。与join不同是,cogroup传递的一个可以遍历的集合,没有做笛卡尔积。出了实现inner join还可以实现左外连接,右外连接,全外连接。
并且窗口联结底层也是通过同组联结实现
stream1.coGroup(stream2)
.where(r -> r.f0)
.equalTo(r -> r.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.apply(new CoGroupFunction<Tuple2<String, Long>, Tuple2<String, Long>, String>() {
//与join 区别是参数非单个元素,而是遍历集合
@Override
public void coGroup(Iterable<Tuple2<String, Long>> iter1, Iterable<Tuple2<String, Long>> iter2, Collector<String> collector) throws Exception {
collector.collect(iter1 + "=>" + iter2);
}
})
.print();窗口联结地城代码
stream1
.join(stream2)
.where(r -> r.f0)
.equalTo(r -> r.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.apply(new JoinFunction<Tuple2<String, Long>, Tuple2<String, Long>, String>() {
@Override
public String join(Tuple2<String, Long> left, Tuple2<String, Long> right) throws Exception {
return left + "=>" + right;
}
})
.print();
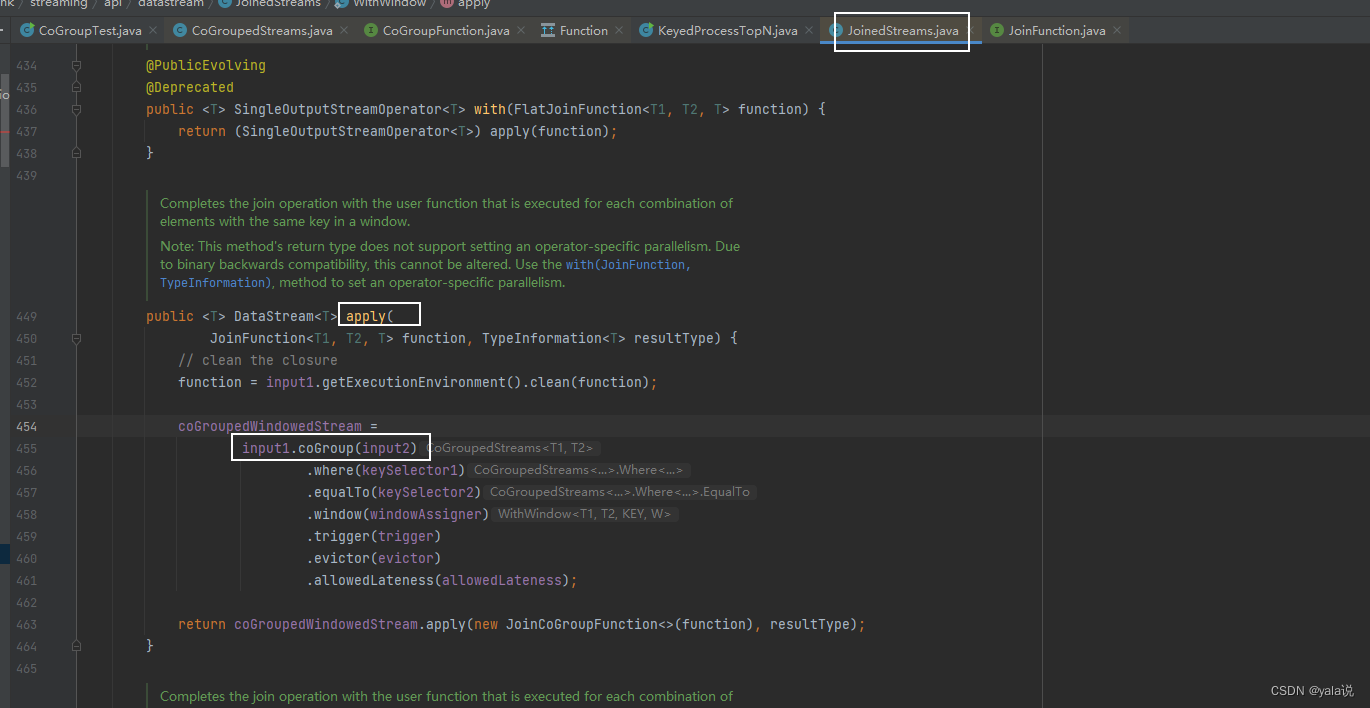
==================查看apply源码================
public <T> DataStream<T> apply(JoinFunction<T1, T2, T> function) {
TypeInformation<T> resultType =
TypeExtractor.getBinaryOperatorReturnType(
function,
JoinFunction.class,
0,
1,
2,
TypeExtractor.NO_INDEX,
input1.getType(),
input2.getType(),
"Join",
false);
// 继续点击apply 查看源码
return apply(function, resultType);
}
public <T> DataStream<T> apply(
JoinFunction<T1, T2, T> function, TypeInformation<T> resultType) {
// clean the closure
function = input1.getExecutionEnvironment().clean(function);
//源码使用coGroup,继续点击co
coGroupedWindowedStream =
input1.coGroup(input2)
.where(keySelector1)
.equalTo(keySelector2)
.window(windowAssigner)
.trigger(trigger)
.evictor(evictor)
.allowedLateness(allowedLateness);
// 点击查看实现的JoinCoGroupFunction源码
return coGroupedWindowedStream.apply(new JoinCoGroupFunction<>(function), resultType);
}
===========查看实现JoinCoGroupFunction,源码中将两个集合做笛卡尔积 ===========================
public JoinCoGroupFunction(JoinFunction<T1, T2, T> wrappedFunction) {
super(wrappedFunction);
}
@Override
public void coGroup(Iterable<T1> first, Iterable<T2> second, Collector<T> out)
throws Exception {
for (T1 val1 : first) {
for (T2 val2 : second) {
out.collect(wrappedFunction.join(val1, val2));
}
}
}
}