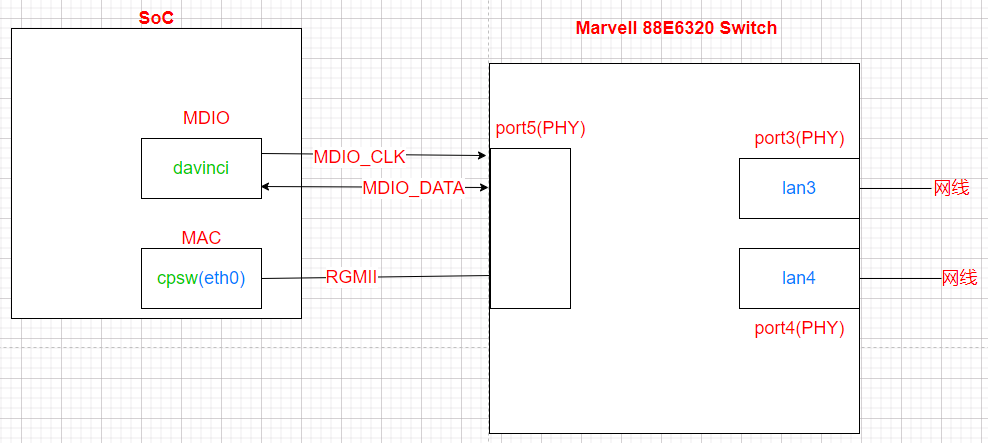
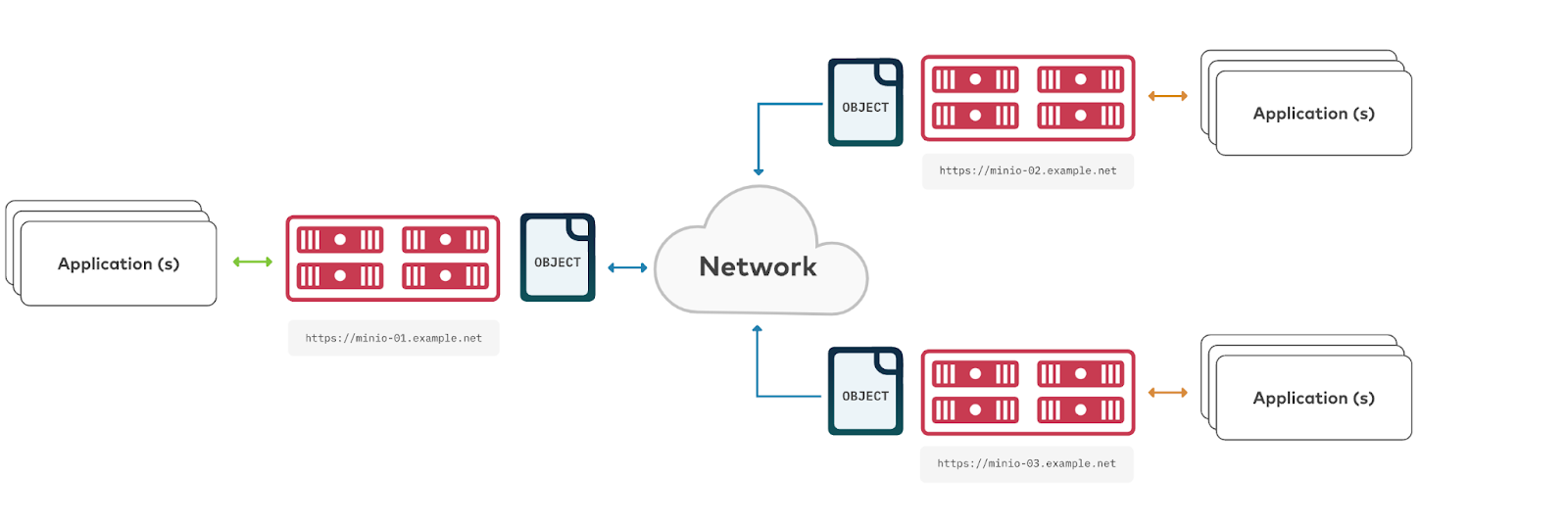
Yolo v5实现细节
SiLU激活函数
swish和SiLU激活函数:其中β是常量或者是可学习的参数
首先引入swish函数的表达形式:

f
(
x
)
=
x
⋅
sigmoid
(
β
x
)
f(x)=x \cdot \operatorname{sigmoid}(\beta x)
f(x)=x⋅sigmoid(βx)
如果β = 1即SiLU激活函数:
f ( x ) = x ⋅ sigmoid ( x ) f(x)=x \cdot \operatorname{sigmoid}(x) f(x)=x⋅sigmoid(x)
如果β = 0, Swish 变成了 缩放线性函数 f(x) = x/2。如果β → ∞,sigmoid 分量接近 0-1 函数。
可以大致地把Swish 视为一个平滑函数,它在线性函数和ReLU函数之间进行非线性插值,如果将插
值程度设置为可训练参数,则模型可以控制β
hardswish ( x ) = { 0 , if x ≤ − 3 x , if x ≥ 3 x ( x + 3 ) 6 , otherwise \operatorname{hardswish}(x)=\left\{\begin{array}{ll} 0, & \text { if } x \leq-3 \\ x, & \text { if } x \geq 3 \\ \frac{x(x+3)}{6}, & \text { otherwise } \end{array}\right. hardswish(x)=⎩ ⎨ ⎧0,x,6x(x+3), if x≤−3 if x≥3 otherwise
Hardswish激活函数,在MobileNetV3架构中被提出,相较于swish函数,具有数值稳定性好,计算速度快等优点。
v5网络结构

6.0之后版本的改进部分:
- 用Conv(k=6,s=2,p=2)代替Focus层,主要是为了方便模型导出
- 使用SPPF代替SPP层
- 减少P3主干层C3
- 将SPPF放在主干的后面
- 更新超参数
backbone部分:yolov5s的版本:(官方的yaml配置文件)
[
[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
关于YOLOv5的网络结构其实网上相关的讲解已经有很多了。网络结构主要由以下几部分组成:
- Backbone: New CSP-Darknet53
- Neck: SPPF, New CSP-PAN
- Head: YOLOv3 Head
下面是我根据yolov5l.yaml绘制的网络整体结构,YOLOv5针对不同大小(n, s, m, l, x)的网络整体架构都是一样的,只不过会在每个子模块中采用不同的深度和宽度,分别应对yaml文件中的depth_multiple和width_multiple参数。
CBL模块(ConvBNSiLU)
CONV模块是一个标准的卷积模块,卷积层+BN层+激活函数SiLU。
class Conv(nn.Module):
# Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initializes a standard convolution layer with optional batch normalization and activation."""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""Applies a convolution followed by batch normalization and an activation function to the input tensor `x`."""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Applies a fused convolution and activation function to the input tensor `x`."""
return self.act(self.conv(x))

Bottleneck模块
Bottleneck1在backbone中使用带有残差的部分,Bottleneck2不带有残差的部分。(通过add变量来进行控制)
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5):
"""Initializes a standard bottleneck layer with optional shortcut and group convolution, supporting channel
expansion.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
"""Processes input through two convolutions, optionally adds shortcut if channel dimensions match; input is a
tensor.
"""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))

C3模块
结构作用基本相同均为CSP架构,只是在修正单元的选择上有所不同,其包含了3个标准卷积层以及多个Botteneck模块。
之前的v6.0之前使用的是BottleneckCSP模块,在新版本中被替换为C3模块进行使用。
CSP结构是在CSPNet(Cross Stage Partial Network)论文中提出的
- 每一个block按照特征图的channel维度拆分成两部分
- 一份正常走网络,另一份直接concat到这个block的输出
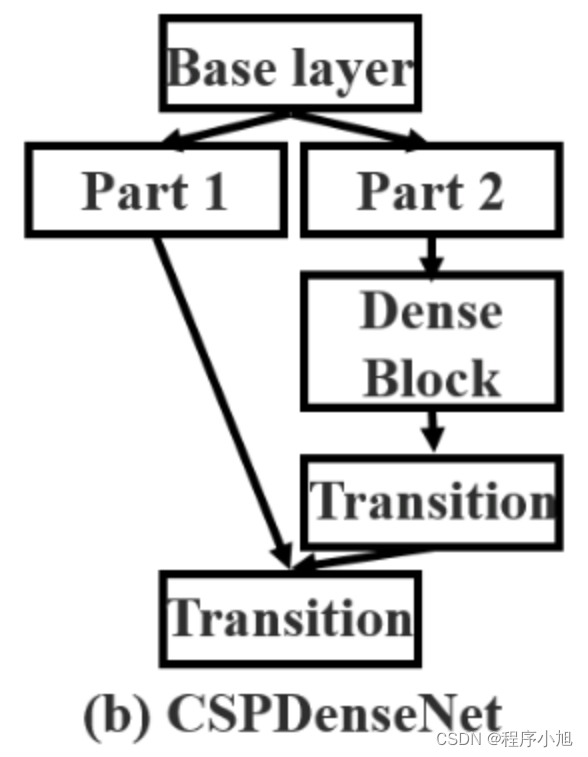
在v4网络中的cspDarknet即为将csp网络结构与Darknet53网络结构进行结合所得到的一个新的网络架构。
给出v5中常用到的C3部分的网络结构图如下所示:

class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
"""Initializes C3 module with options for channel count, bottleneck repetition, shortcut usage, group
convolutions, and expansion.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
"""Performs forward propagation using concatenated outputs from two convolutions and a Bottleneck sequence."""
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
之前部分的涉及到的模块信息主要是backbone主干部分的网络结构信息,后面spp部分和之后的部分是netual和head部分。
SPPF模块
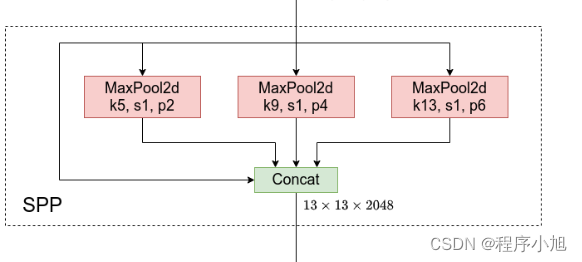
使用1 * 1的CBL和maxpooling,对输入进行特征提取和特征融合与SPP不同之处在于增加特征由浅入深的提取过程。
Spp部分主要使用在yolo v3+spp的部分中和yolo v4的网络中。
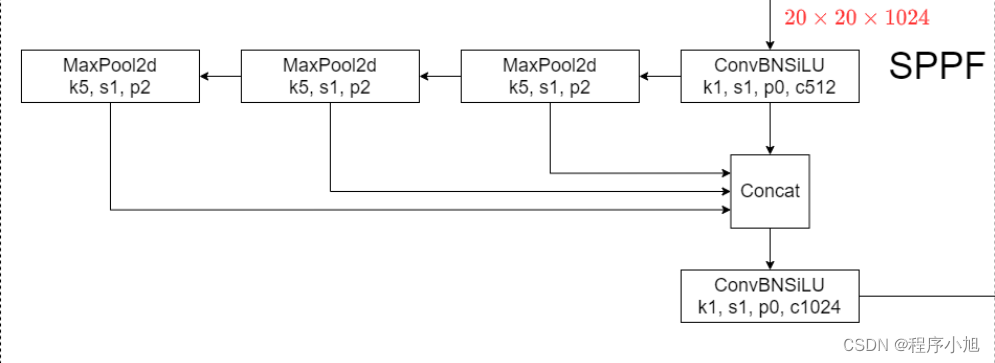
SPPF的三个maxpooling之间使用了串联的连接方式,在进行连接之后再次进入CBL模块中进行使用。
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5):
"""
Initializes YOLOv5 SPPF layer with given channels and kernel size for YOLOv5 model, combining convolution and
max pooling.
Equivalent to SPP(k=(5, 9, 13)).
"""
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
"""Processes input through a series of convolutions and max pooling operations for feature extraction."""
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter("ignore") # suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))
最后在给出YOLO v5的最终的网络特征图的过程中,需要注意的一点是v5给出的三个预测特征层的缩放倍数,都是8的整数倍(相比较与输入的图片来说)
在Neck部分另外一个不同点就是New CSP-PAN了,在YOLOv4中,Neck的PAN结构是没有引入CSP结构的,但在YOLOv5中作者在PAN结构中加入了CSP。详情见上面的网络结构图,每个C3模块里都含有CSP结构。

head部分网络结构
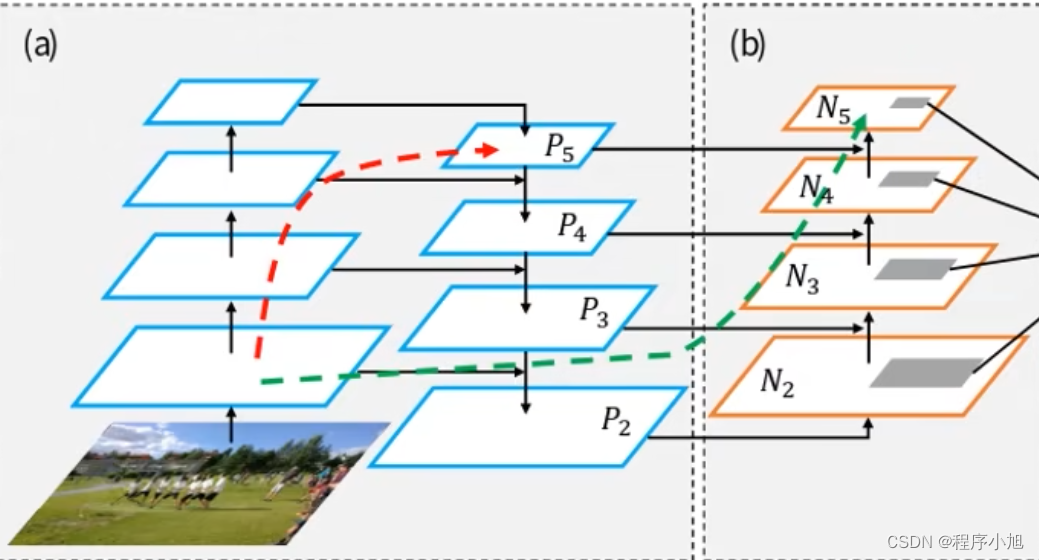
FPN网络结构
作用将Backbone上的不同特征图进行融合操作。

在主干网络的部分会使用到1x1的卷积核来调整特征图的通道数,便于进行融合的相关操作。而在head部分进行融合操作的时候要使用到,二倍的上采样操作来进行缩放便于进行进一步的特征融合操作。
在进行上采样的过程中并没有使用到转置卷积的相关操作,而是使用了邻近插值算法来进行实现的

给出一个更为具体使用FPN网络的结构模型:

PAN网络结构
PAN网络结构是在之前提出的FPN网络结构的基础上,进一步改进所得到的网络结构。在v4和v5的head部分都用到了PAN网络结构的思想来实现网络模型。
通过PAN得到最终的预测特征层的相关的信息。
在FPN的基础上又底层在反向低层进行一个融合的操作。
训练策略
在YOLOv5源码中使用到了很多训练的策略,这里简单总结几个我注意到的点,还有些没注意到的请大家自己看下源码:
-
Multi-scale training(0.5~1.5x),多尺度训练,假设设置输入图片的大小为640 × 640,训练时采用尺寸是在0.5× 640~ 1.5×640之间随机取值,注意取值时取得都是32的整数倍(因为网络会最大下采样32倍)。
-
AutoAnchor(For training custom data),训练自己数据集时可以根据自己数据集里的目标进行重新聚类生成Anchors模板。
-
Warmup and Cosine LR scheduler,训练前先进行Warmup热身,然后在采用Cosine学习率下降策略。
-
EMA(Exponential Moving Average),可以理解为给训练的参数加了一个动量,让它更新过程更加平滑。
-
Mixed precision,混合精度训练,能够减少显存的占用并且加快训练速度,前提是GPU硬件支持。
-
Evolve hyper-parameters,超参数优化,没有炼丹经验的人勿碰,保持默认就好。