:::
大家好!今天我分享的文章是来自威斯康星大学麦迪逊分校和亚马逊AWS AI实验室的最新工作,文章所属领域是推荐系统和因果推理,作者针对跨域推荐中的偏差问题提出了一种基于因果去偏的预训练推荐系统框架PreRec。
:::

原文:Pre-trained Recommender Systems: A Causal Debiasing Perspective
地址:https://arxiv.org/abs/2310.19251
代码:https://github.com/myhakureimu/PreRec
出版:WSDM '24
机构: 威斯康星大学麦迪逊分校、亚马逊
1 研究问题
本文研究的核心问题是: 如何设计一个通用的预训练推荐系统框架,能够有效处理跨域推荐中的偏差问题。
::: block-1
假设我们有一个电商平台,想要为不同国家的用户推荐商品。每个国家的用户行为和商品特征都有所不同,直接将一个国家的推荐模型应用到另一个国家往往效果不佳。我们希望能够设计一个通用的推荐框架,可以在多个国家的数据上预训练,然后快速适应到新的国家市场,同时还能处理不同国家之间的偏差问题。
:::
本文研究问题的特点和现有方法面临的挑战主要体现在以下几个方面:
- 跨域推荐中存在域内偏差和跨域偏差,这些偏差会影响模型的泛化能力。例如,不同国家的商品流行度分布不同(域内偏差),以及不同国家的用户行为模式差异(跨域偏差)。
- 现有的预训练推荐方法(如ZESRec和UniSRec)没有考虑这些偏差,可能会导致模型过拟合源域数据。
- 如何在保留通用知识的同时,有效地消除这些偏差是一个挑战。
针对这些挑战,本文提出了一种基于因果去偏的"PreRec"方法:
::: block-1
PreRec的核心思想是将推荐过程建模为一个概率图模型,并引入因果推理的思想来处理偏差。它就像一个精明的导购,不仅了解每个国家的商品和用户特点,还能识别出哪些是真正的用户偏好,哪些只是由于某个国家特定的促销活动或文化差异造成的偏差。具体来说,PreRec使用一个分层贝叶斯深度学习模型来捕获用户兴趣、商品特征、域特征和流行度等因素。在预训练阶段,它通过显式建模域内偏差(如商品流行度)和跨域偏差(如域特征),将这些偏差与通用知识分离。在推断阶段,它使用因果干预的方法来消除这些偏差的影响,只保留真正的用户-商品匹配信息。这就像PreRec在每个国家都派了一个"特工",这些特工不仅收集各自国家的数据,还能识别出哪些是该国特有的"噪音"。在给新国家的用户推荐时,PreRec就能抛开这些"噪音",专注于真正通用的推荐知识。
:::
2 研究方法
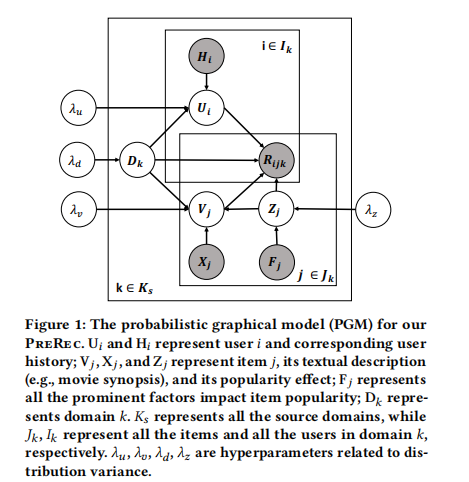
2.1 PreRec模型结构
PreRec是一种新型的预训练推荐系统,采用层次化贝叶斯深度学习框架。它的核心目标是解决多域预训练中的偏差问题,提高模型在新域上的泛化能力。PreRec的整体架构包括以下几个关键组件:
- 用户通用嵌入网络(User Universal Embedding Network):这个网络用于生成用户的通用嵌入表示。它接收用户的历史交互序列作为输入,通过一个序列模型(如Transformer)来聚合这些交互信息,最终输出用户的嵌入向量。
- 物品通用嵌入网络(Item Universal Embedding Network):这个网络用于生成物品的通用嵌入表示。它以物品的文本描述为输入,通过预训练的语言模型(如BERT)和一个单层神经网络来提取物品的语义特征,最终输出物品的嵌入向量。
- 域属性嵌入(Domain Embedding):这是一个可学习的向量,用于捕捉每个域的特有属性,如用户群体特征、促销活动等。
- 流行度嵌入(Popularity Embedding):这个组件用于建模物品在特定域内的流行度偏差。它基于物品的交互次数、流量和时间等因素计算得出。
举个例子,假设我们在构建一个跨国的电商推荐系统。对于一个来自美国的用户,用户通用嵌入网络会分析他过去购买的商品序列(如手机、耳机、充电器等),生成一个能够反映他整体兴趣的嵌入向量。对于一个新上架的手机,物品通用嵌入网络会分析其产品描述,生成一个反映手机特征的嵌入向量。同时,我们还会有一个代表"美国市场"的域属性嵌入,以及反映这款手机在美国市场受欢迎程度的流行度嵌入。
PreRec的创新之处在于,它明确地将这些不同来源的信息(用户兴趣、物品特征、域属性、流行度)分开建模,这为后续的去偏和迁移学习奠定了基础。
2.2 多域预训练
在多域预训练阶段,PreRec的目标是从多个源域中提取通用知识,同时显式建模和处理不同类型的偏差。这个过程主要包括以下几个步骤:
- 数据收集:从多个源域(例如不同国家的电商平台)收集用户-物品交互数据、物品描述文本以及相关的元数据。
- 通用表示学习:使用物品通用嵌入网络和用户通用嵌入网络,分别学习物品和用户的通用表示。这些表示应该能够捕捉到跨域的共性特征。
- 域内偏差建模:PreRec显式地建模了域内的流行度偏差。具体来说,它引入了一个流行度嵌入 Z j Z_j Zj,用于捕捉物品 j j j 在特定域内的流行度效应。这个流行度嵌入是基于物品的交互次数、总流量和时间等因素计算得出的。
- 跨域偏差建模:PreRec引入了一个域属性嵌入 D k D_k Dk,用于捕捉每个域 k k k 的特有属性。这个嵌入可以理解为域的隐藏表示,它影响着该域内的用户兴趣、物品属性和用户行为模式。
- 联合优化:PreRec通过最小化负对数似然来联合优化所有这些组件。优化目标函数如下:
L = ∑ − l o g ( f s o f t m a x ( U i T V j + D k W d + Z j W z ) ) + λ z / 2 ∑ ∣ ∣ Z j − f p o p ( F j ) ∣ ∣ 2 + λ v / 2 ∑ ∣ ∣ V j − f e ( D k , Z j ) ∣ ∣ 2 + λ u / 2 ∑ ∣ ∣ U i − f s e q ( D k , H i ) ∣ ∣ 2 + λ d / 2 ∑ ∣ ∣ D k ∣ ∣ 2 L = ∑ -log(f_softmax(U_i^T V_j + D_k W_d + Z_j W_z)) + λ_z/2 ∑ ||Z_j - f_pop(F_j)||^2 + λ_v/2 ∑ ||V_j - f_e(D_k, Z_j)||^2 + λ_u/2 ∑ ||U_i - f_seq(D_k, H_i)||^2 + λ_d/2 ∑ ||D_k||^2 L=∑−log(fsoftmax(UiTVj+DkWd+ZjWz))+λz/2∑∣∣Zj−fpop(Fj)∣∣2+λv/2∑∣∣Vj−fe(Dk,Zj)∣∣2+λu/2∑∣∣Ui−fseq(Dk,Hi)∣∣2+λd/2∑∣∣Dk∣∣2
这里, U i U_i Ui 是用户嵌入, V j V_j Vj 是物品嵌入, D k D_k Dk 是域属性嵌入, Z j Z_j Zj 是流行度嵌入, H i H_i Hi 是用户历史, F j F_j Fj 是流行度因子。
举个具体的例子,假设我们在美国、英国和加拿大的电商平台上预训练PreRec。对于一个在美国平台上很受欢迎的iPhone手机,它的表示会包含几个部分:
- 通用物品嵌入:反映iPhone的基本特征,如智能手机、iOS系统等。
- 流行度嵌入:反映这款iPhone在美国市场的高人气。
- 域属性嵌入:可能捕捉到美国用户偏好高端科技产品的特点。
通过这种方式,PreRec能够区分出哪些特征是iPhone的固有属性,哪些是由于美国市场的特殊性造成的,从而为后续的跨域推荐打下基础。
2.3 零样本推荐
零样本推荐是PreRec的一个关键能力,它允许模型在没有见过任何目标域数据的情况下,直接在新域上进行推荐。PreRec通过巧妙的因果干预机制来实现这一点。具体步骤如下:
- 消除跨域偏差:在进行零样本推荐时,PreRec首先将域属性嵌入 D k D_k Dk 设置为0。这相当于执行了一个do-操作: d o ( D k = 0 ) do(D_k = 0) do(Dk=0)。直觉上,这就好比我们在问:“如果没有任何特定域的影响,用户会如何与物品交互?”
- 保留域内偏差:虽然消除了跨域偏差,但PreRec保留了流行度嵌入 Z j Z_j Zj。这是因为流行度信息通常在不同域之间具有一定的可迁移性。
- 计算推荐分数:PreRec使用因果干预后的用户嵌入和物品嵌入来计算最终的推荐分数:
P ( R i j k ∣ d o ( U i , V j , Z j ) ) = f s o f t m a x ( U i T V j + Z j W z ) P(R_ijk|do(U_i, V_j, Z_j)) = f_softmax(U_i^T V_j + Z_j W_z) P(Rijk∣do(Ui,Vj,Zj))=fsoftmax(UiTVj+ZjWz)
这里, R i j k R_ijk Rijk 表示用户 i i i 与物品 j j j 在域 k k k 中的交互。
举个例子,假设我们要将预训练好的PreRec应用到澳大利亚的电商平台上。对于一个从未在澳大利亚市场出现过的新用户,PreRec会这样工作:
- 基于用户的历史行为(可能来自其他国家的平台)生成用户嵌入。
- 对于澳大利亚市场的每个商品,生成其通用物品嵌入。
- 计算每个商品在澳大利亚市场的流行度嵌入。
- 将域属性嵌入设为0,相当于"假设没有澳大利亚市场的特殊影响"。
- 基于以上信息计算推荐分数,并向用户推荐得分最高的商品。
这种方法的优势在于,它能够利用从其他市场学到的通用知识,同时考虑商品在新市场的受欢迎程度,但不会被源域的特殊偏好所影响。
2.4 目标域微调
随着在新域(如澳大利亚市场)积累了一定量的交互数据,PreRec可以通过微调来进一步提升推荐性能。微调过程包括以下步骤:
- 重新估计隐变量:PreRec会重新估计目标域的所有隐变量,包括用户嵌入 U i U_i Ui,物品嵌入 V j V_j Vj,域属性嵌入 D k D_k Dk,和流行度嵌入 Z j Z_j Zj。
- 端到端优化:PreRec在目标域数据上优化与预训练阶段相同的目标函数:
$$
L = ∑ -log(f_softmax(U_i^T V_j + D_k W_d + Z_j W_z))- λ_z/2 ∑ ||Z_j - f_pop(F_j)||^2
- λ_v/2 ∑ ||V_j - f_e(D_k, Z_j)||^2
- λ_u/2 ∑ ||U_i - f_seq(D_k, H_i)||^2
- λ_d/2 ∑ ||D_k||^2
$$
- 适应性推断:微调后的推断过程会考虑目标域的特性:
P ( R i j k ∣ d o ( U i , V j , D k , Z j ) ) = f s o f t m a x ( U i T V j + D k W d + Z j W z ) P(R_ijk|do(U_i, V_j, D_k, Z_j)) = f_softmax(U_i^T V_j + D_k W_d + Z_j W_z) P(Rijk∣do(Ui,Vj,Dk,Zj))=fsoftmax(UiTVj+DkWd+ZjWz)
这里,我们不再将 D k D_k Dk 设为0,而是使用学习到的目标域属性嵌入。
具体来说,假设PreRec在澳大利亚市场运行了一段时间,收集到了一些用户交互数据。微调过程会:
- 更新用户嵌入,以更好地反映澳大利亚用户的偏好。比如,可能会发现澳大利亚用户特别喜欢户外运动产品。
- 调整物品嵌入,以适应澳大利亚市
3 实验
3.1 实验场景介绍
本论文提出了一个可以跨领域预训练的推荐系统模型PreRec。实验主要验证PreRec在新的目标领域上的推荐性能,包括零样本场景和微调场景。实验涉及跨市场(不同国家的Amazon市场)和跨平台(Amazon与Online Retail)两种跨域场景。
3.2 实验设置
- Datasets:
- XMarket数据集:覆盖18个本地市场(国家)的16个不同产品类别
- Online Retail数据集:来自英国在线零售平台的数据
- 预训练数据集:印度、西班牙、加拿大
- 跨市场目标数据集:澳大利亚、墨西哥、德国、日本
- 跨平台目标数据集:Online Retail
- Baselines:Random, POP, SBERT, GRU4Rec, SASRec, ZESRec, UniSRec, PreRec_n
- Implementation details:
- 所有方法使用256维的物品和用户嵌入
- 基于GRU的序列模型使用2层GRU
- 基于自注意力的序列模型使用2层多头注意力
- 使用Adam优化器,学习率为0.0003
- 在验证集上使用平均r-NDCG@K%进行早停
- Metrics:Recall@K% 和 r-NDCG@K%
- 环境:使用一块Tesla V100 GPU进行训练
3.3 实验结果
实验1、零样本推荐实验

目的:评估PreRec在新的目标域上的零样本推荐性能
涉及图表:表1
实验细节概述:在三个源域(印度、西班牙、加拿大)上预训练PreRec,然后在五个目标域(澳大利亚、墨西哥、德国、日本、Online Retail)上进行零样本评估
结果:
- PreRec在几乎所有情况下都显著优于所有基线方法
- 在跨市场场景中,PreRec在澳大利亚数据集上获得最大改进,在日本数据集上改进最小
- 在跨平台场景(Online Retail)中,PreRec同样表现出色
实验2、消融实验
目的:验证因果去偏机制的有效性
涉及图表:表1
实验细节概述:比较PreRec与其简化版本PreRec_n(忽略了跨域和域内偏差项)的性能
结果:在几乎所有情况下,PreRec都优于PreRec_n,证明了因果去偏机制的有效性
实验3、全量微调实验
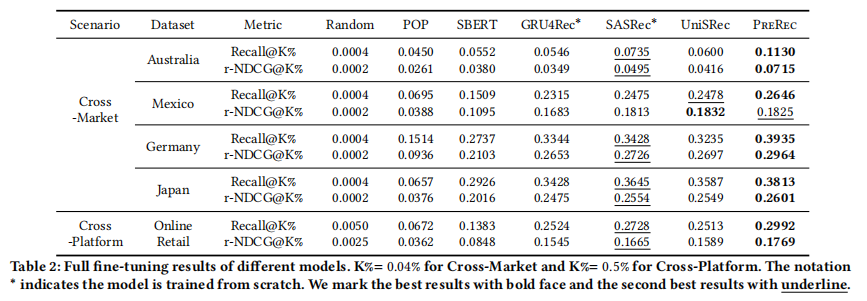
目的:评估在目标域上全量微调后PreRec的性能
涉及图表:表2
实验细节概述:在目标域的所有可用训练数据上微调模型,并与基线方法比较
结果:
- PreRec在微调后仍然在几乎所有情况下显著优于所有基线方法
- 这表明PreRec在预训练阶段提取了通用知识,即使在目标域有充足数据的情况下仍具有互补价值
- PreRec能够快速适应新域,同时不会遗忘预训练阶段学到的知识
实验4、增量微调实验
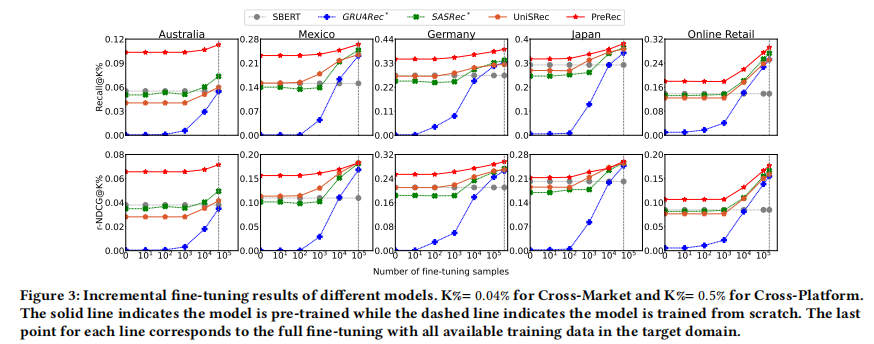
目的:研究目标域微调样本数量对模型性能的影响
涉及图表:图3
实验细节概述:使用逐渐增加的目标域训练数据对模型进行微调,观察性能变化
结果:
- PreRec在所有目标域中都优于基线方法
- 随着微调样本数量增加,PreRec的性能稳步提升,表明它在逐步适应目标域
- 即使在有10^4个目标域训练样本时,PreRec与基线方法的性能差距仍然显著
- 这表明PreRec在预训练阶段提取的知识在目标域数据有限的情况下具有重要价值
非常感谢您提供的论文和问题。下面是我根据您的要求对论文进行的总结和分析:
4 总结后记
本论文针对预训练推荐系统中的域内偏差和跨域偏差问题,提出了一种名为PreRec的因果去偏视角方法。PreRec通过引入显式和隐式的混杂因子来建模不同类型的偏差,并使用因果干预机制来消除这些偏差的影响。实验结果表明,PreRec在跨市场和跨平台的零样本和微调场景下都显著优于现有方法,为构建通用的预训练推荐系统提供了新的思路。
::: block-2
疑惑和想法:
- 论文中提到的显式和隐式混杂因子是如何具体定义和识别的?是否存在其他类型的混杂因子需要考虑?
- PreRec如何处理动态变化的用户兴趣和项目特征?是否可以引入时间序列建模来捕捉这些变化?
- 在跨语言场景下,PreRec的性能如何?是否需要额外的跨语言对齐机制?
- PreRec能否扩展到处理多模态数据(如图像、视频)的推荐任务?这将带来哪些新的挑战?
:::
::: block-2
可借鉴的方法点:
- 将因果推断与深度学习相结合的思路可以推广到其他存在偏差问题的机器学习任务中,如计算机视觉、自然语言处理等。
- 使用分层贝叶斯模型来捕捉不同层次的特征和偏差的方法值得借鉴,可以应用于其他需要建模复杂层次结构的问题。
- 通过预训练和微调相结合的方式来提高模型的泛化能力和适应性的思路可以广泛应用于迁移学习和领域适应等场景。
- 设计新的评估指标(如r-NDCG@K%)来更公平地比较不同域间的性能的做法值得借鉴,可以应用于其他需要跨域评估的任务中。
:::