目录
- 一、背景
- 二、多头自注意力机制的原理
- 2.1 自注意力机制
- 2.2 多头自注意力机制
- 2.3 Positional Encoding(位置编码)
- 2.4 self-attention for image
- 三、Self-attention v.s CNN
- 四、Self-attention v.s RNN
- 参考资料
一、背景
为什么是multi-head self attention?
并行的处理多种注意力模式: 每个注意力头使用不同的线性变换,这意味着它们可以从输入序列的不同子空间中学习不同的特征关联。这样一来,模型可以通过多个注意力头同时关注输入序列的不同方面,如一句话的语法结构、语义角色、主题转移等。
增加模型的学习能力和表达能力: 通过多个注意力头,由于每个头关注的特征不同,模型可以学习到更丰富的上下文信息,这样综合起来可以更加全面的理解和处理序列。
二、多头自注意力机制的原理
2.1 自注意力机制
在介绍多头自注意力机制之前,先来简单的回顾一下自注意力机制:
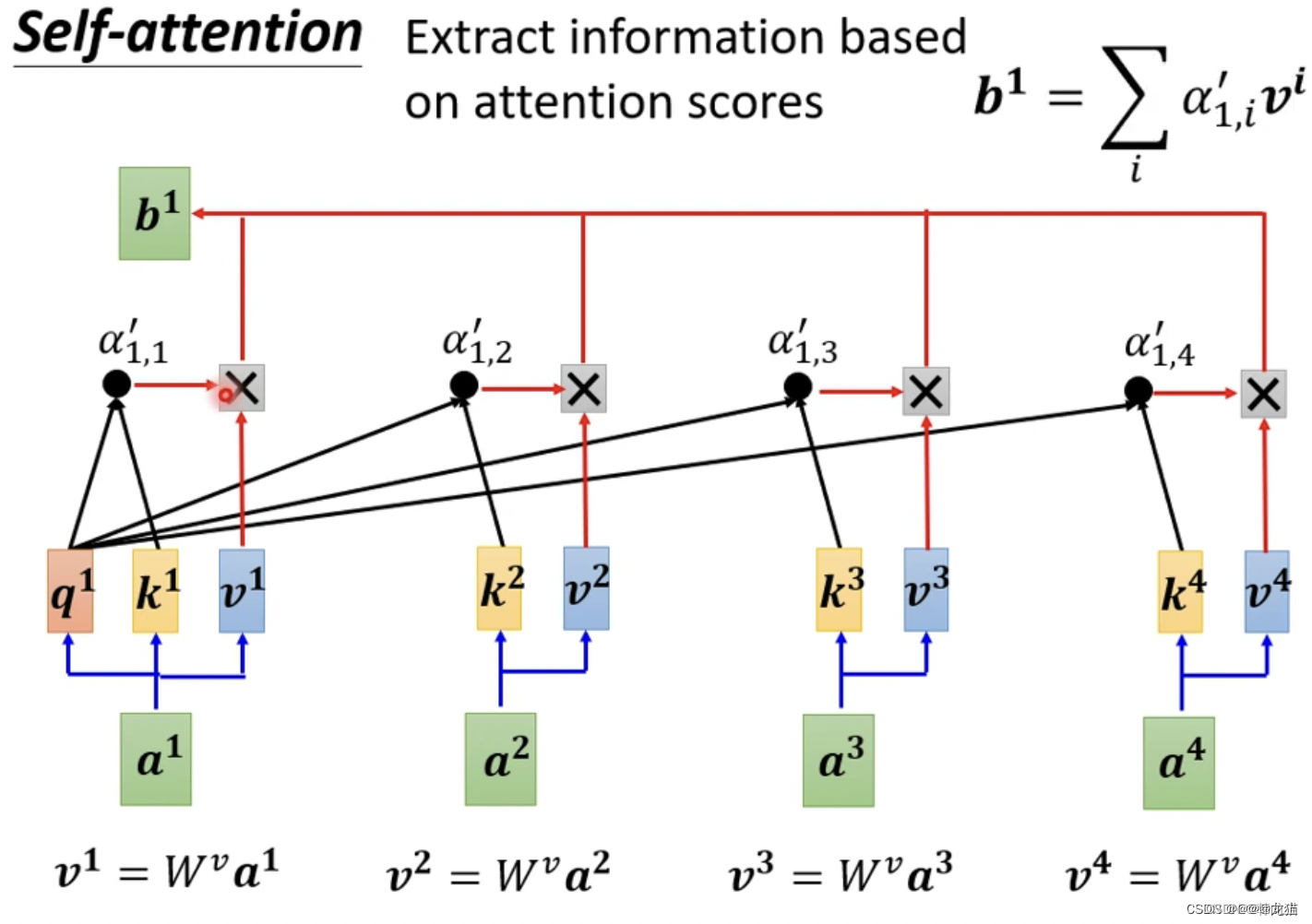
自注意力机制(Self-Attention Mechanism)是Transformer架构中的核心组件,它允许模型在处理序列数据时, 考虑序列中不同位置元素之间的相互关系。在自注意力机制中,查询(Query, Q)、键(Key, K)和值(Value, V)是三个重要的概念,它们都是从输入序列经过线性变换得到的向量。
对于Q,K,V分别代表的含义,我想用一个例子来说明一下:
我们有一段文本:“小明喜欢在晴朗的日子里去公园散步。” 如果我们想要了解 “小明” 这个词在句子中的上下文含义,我们可以看看句子中其他词与 “小明” 之间的关系。
查询(Query, Q):可以把它想象成我们要寻找信息的问题或者焦点。在上面的例子中, 小明”就是我们的查询 “,我们想要知道“小明”这个词在句子中的具体含义。
键(Key, K):可以把它看作是其他单词(或者说是输入序列中的其他部分)提供的线索,帮助我们判断它们与查询的相关程度。在我们的例子中,句子中的每一个词都可以产生一个键,用来表示它是否与“小明”相关以及相关的程度。
值(Value, V):可以理解为当一个键与查询匹配时,它能提供的额外信息。在句子中,如果一个词与“小明”相关联,那么它的值向量就会被用来增强我们对“小明”的理解。比如,“喜欢”、“晴朗的日子”和“公园散步”都与“小明”有关系,它们的值向量将被用来丰富“小明”的语境。
自注意力机制通过计算查询向量(Q)和所有键向量(K)之间的相似度(通常是点积),得到一个注意力权重矩阵,然后使用这些权重对所有值向量(V)进行加权求和,从而得到一个综合了上下文信息的新表示。总结来说,Q是询问者,K是回答者提供的线索,V是等待线索的答案,自注意力机制就是通过这些线索和答案来构建输入序列的上下文关系,进而优化模型的性能。
2.2 多头自注意力机制
多头自注意力机制顾名思义,最自注意力机制最大的不同,就是使用多个QKV来构建序列的上下文关系。
在实现过程中
q
i
,
1
,
q
i
,
2
q^{i,1}, q^{i,2}
qi,1,qi,2,
k
i
,
1
,
k
i
,
2
k^{i,1}, k^{i,2}
ki,1,ki,2,
v
i
,
1
,
v
i
,
2
v^{i,1}, v^{i,2}
vi,1,vi,2与自注意力机制的获取方式一样,以q的计算为例:
q
i
,
1
,
q
j
,
1
=
W
q
,
1
q
i
q
j
q^{i,1}, q^{j,1}=W^{q,1}q^iq^j
qi,1,qj,1=Wq,1qiqj
q
i
,
2
,
q
j
,
2
=
W
q
,
2
q
i
q
j
q^{i,2}, q^{j,2}=W^{q,2}q^iq^j
qi,2,qj,2=Wq,2qiqj
可以看到其计算方式和自注意力机制计算q时一样。
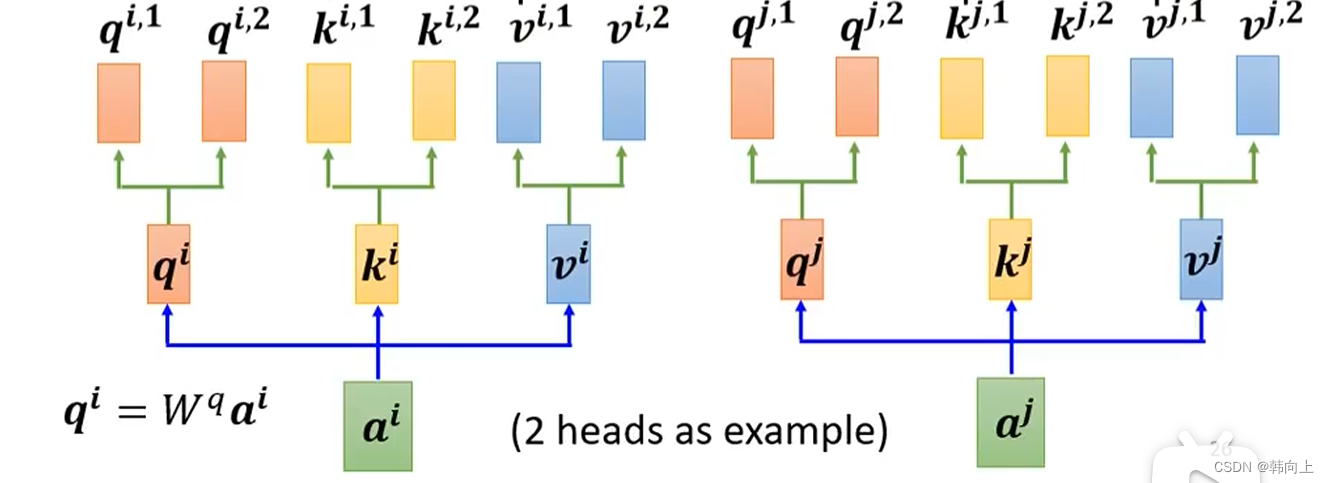
multi-head 在计算self-attention时,和单个头的self-attention类似,只不过每一个输入
a
i
a^i
ai会得到和头个数相同的输出
b
i
,
1
,
b
i
,
2
b^{i,1},b^{i,2}
bi,1,bi,2。需要注意的是,头与头对应,即
q
i
,
1
q^{i,1}
qi,1只需要与
k
i
,
1
,
v
i
,
1
k^{i,1}, v^{i,1}
ki,1,vi,1做运算。
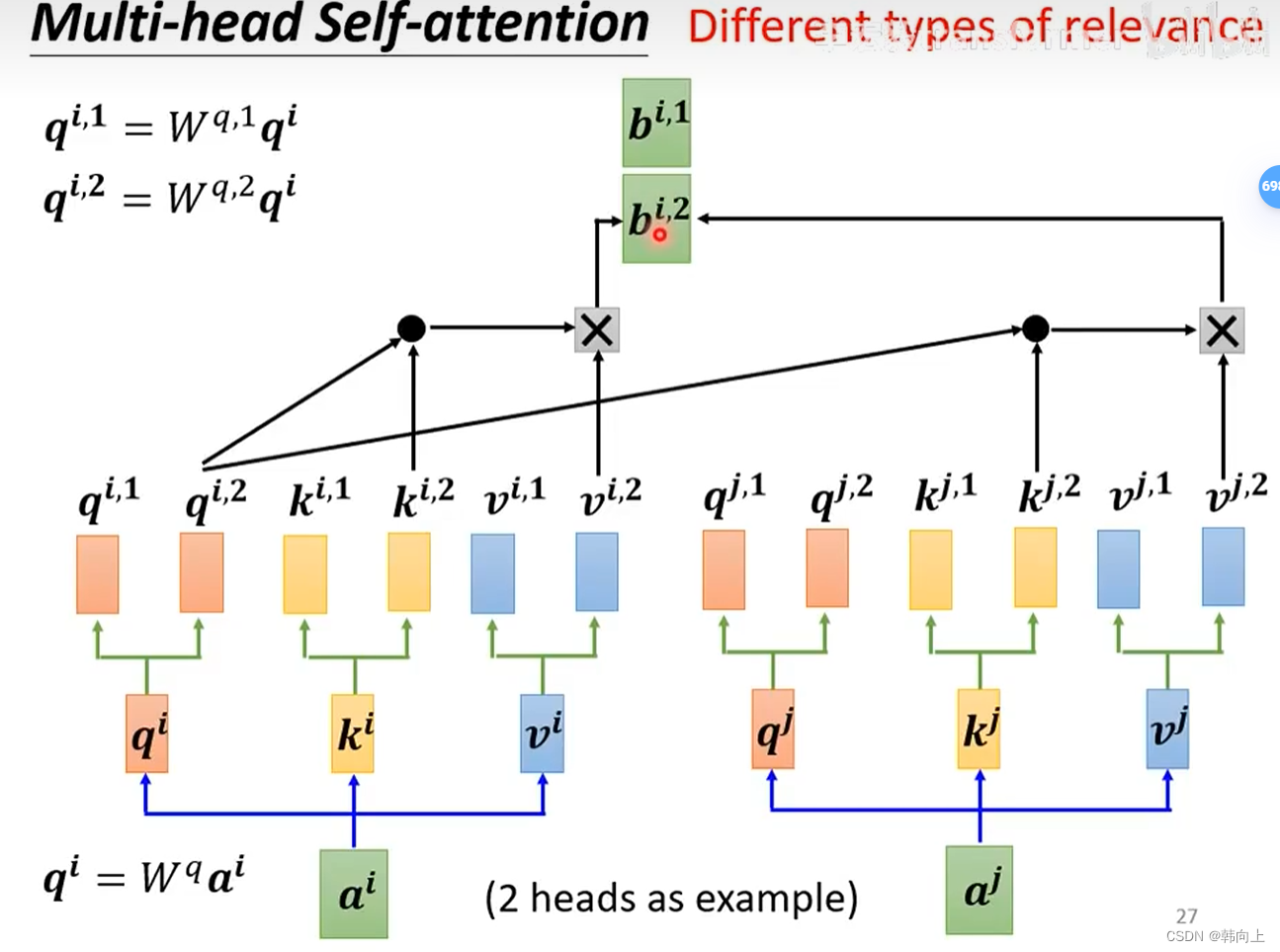
2.3 Positional Encoding(位置编码)
当前,对于一个序列而言,每一个单词出现的位置以及单词之间的距离并未被考虑进去,即第一个单词与最后一个单词的位置是等价的。但是,无论是对于一段文字序列还是一段声音信号,词语的位置不同,所表达的意思可能会发生较大的改变,不如“你不能不吃饭”和“不你不能吃饭”。
为了解决该问题,就需要用到ositional Encoding技术。对于每一个词语只需要给输入信号加上一个位置向量
e
i
e^i
ei.
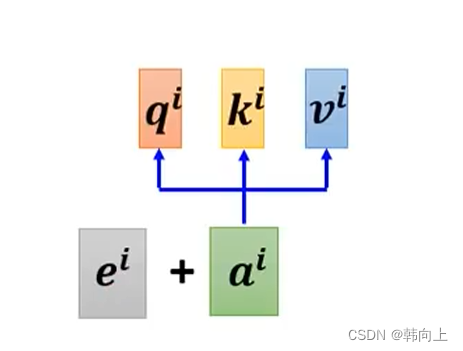
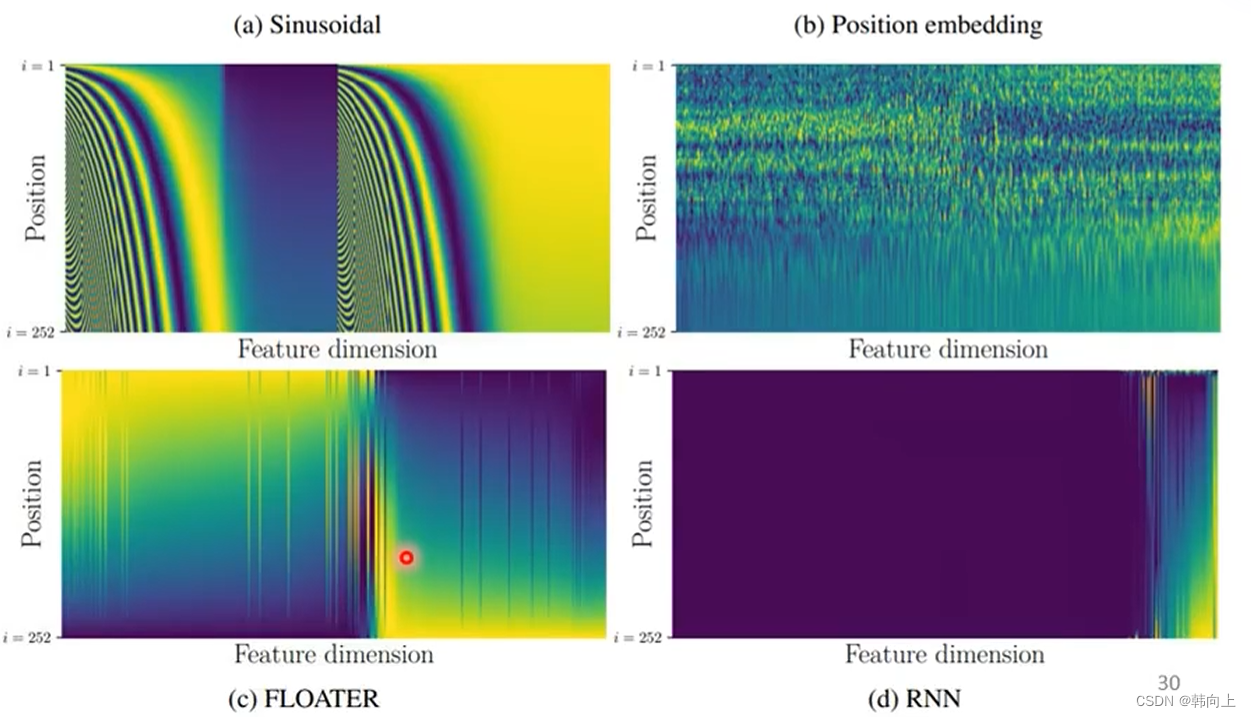
位置向量的编码方式有很多种,如下图所示:
接下来的内容与multi-head知识无关了,我只是顺着课程一块记录下来了。
2.4 self-attention for image
将一张图片看作是一个vector set, 比如下面这张图像,被划分成510的一组向量集,每一个vector是一个13大小的向量。

应用的实例:
三、Self-attention v.s CNN
先说结论:CNN是简化版的self-attention。
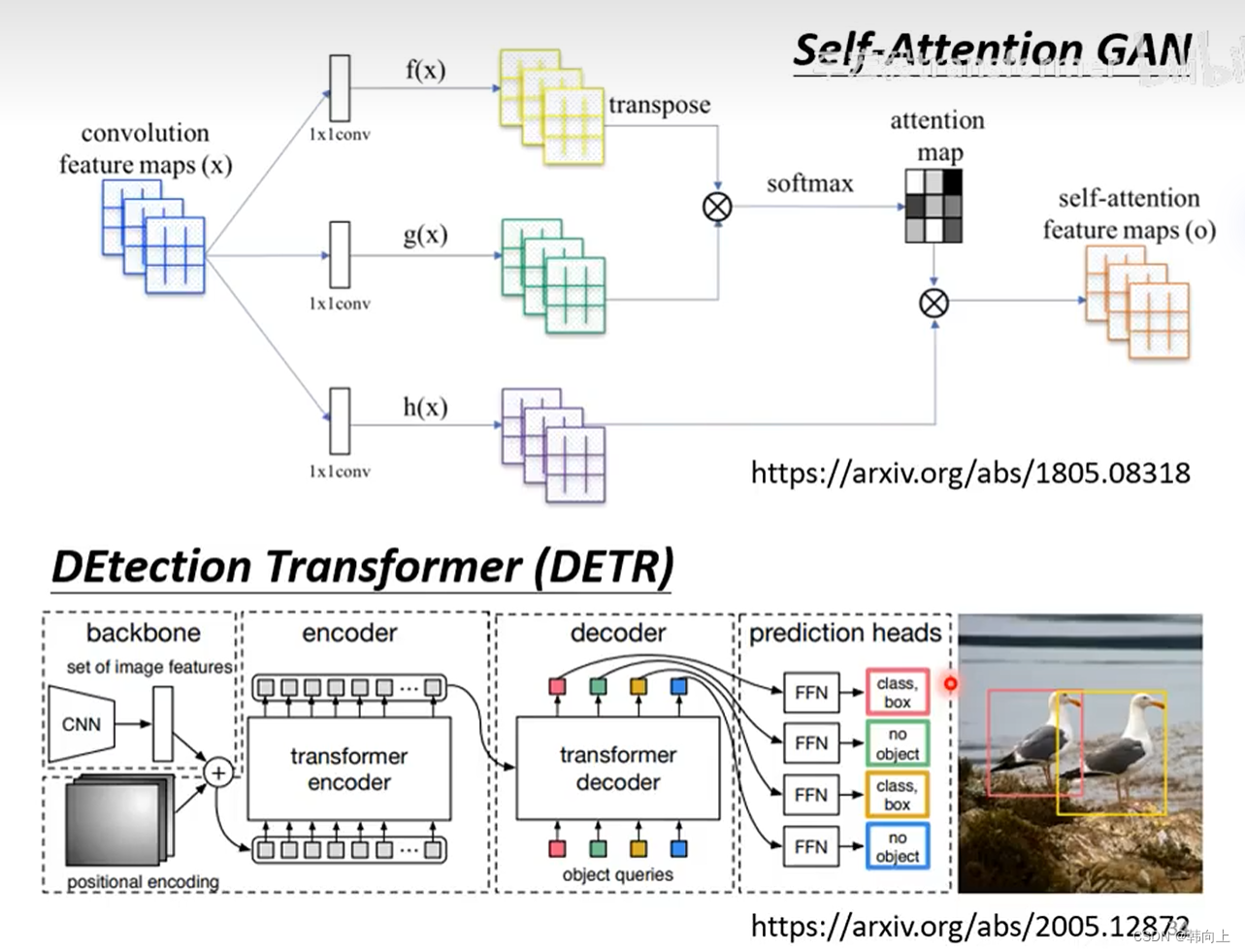
self-attention处理数据的方式: self-attention是考虑整张图像的信息,即receptive filed的范围是自己决定的,自己觉得q与谁相关。
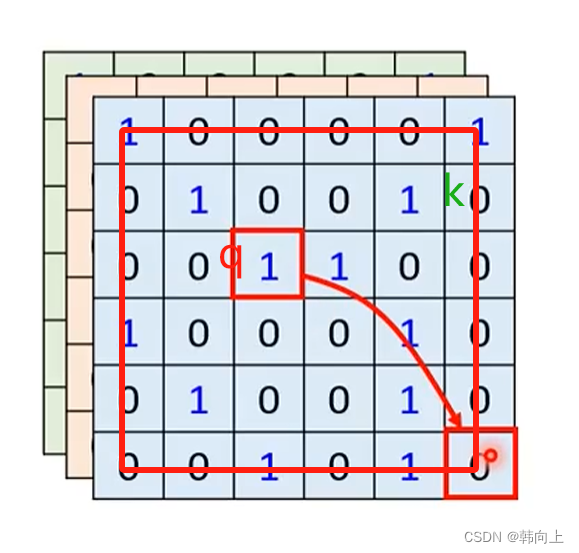
CNN处理数据的方式: CNN仅仅考虑定义范围内的receptive filed里面的信息
四、Self-attention v.s RNN
RNN 简单介绍:RNN的核心机制是其隐层状态,它可以保存先前输入的信息,从而在后续时间步骤中使用,这相当于给网络赋予了一定的“记忆”能力,使其能够处理具有长期依赖关系的数据。
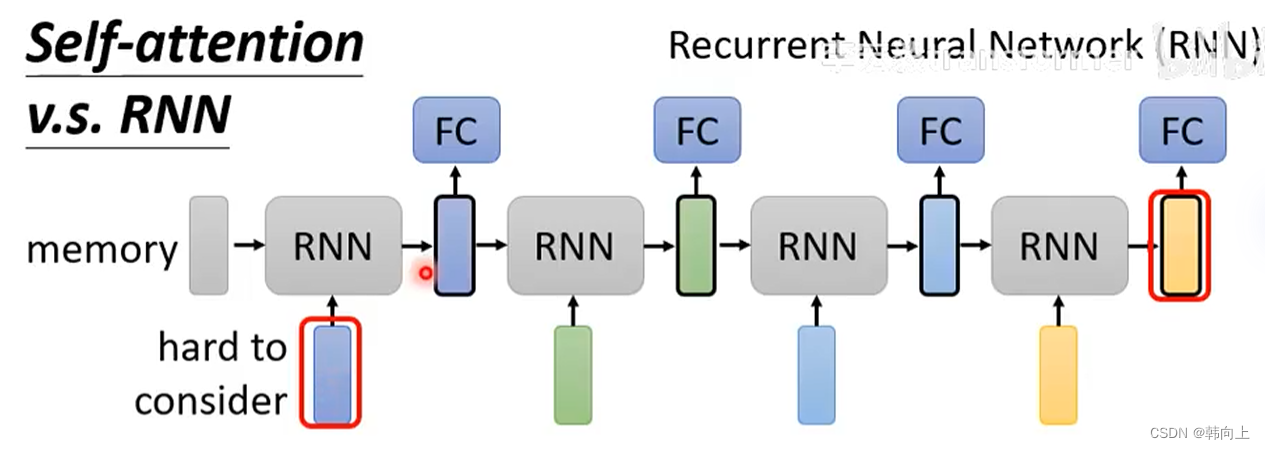
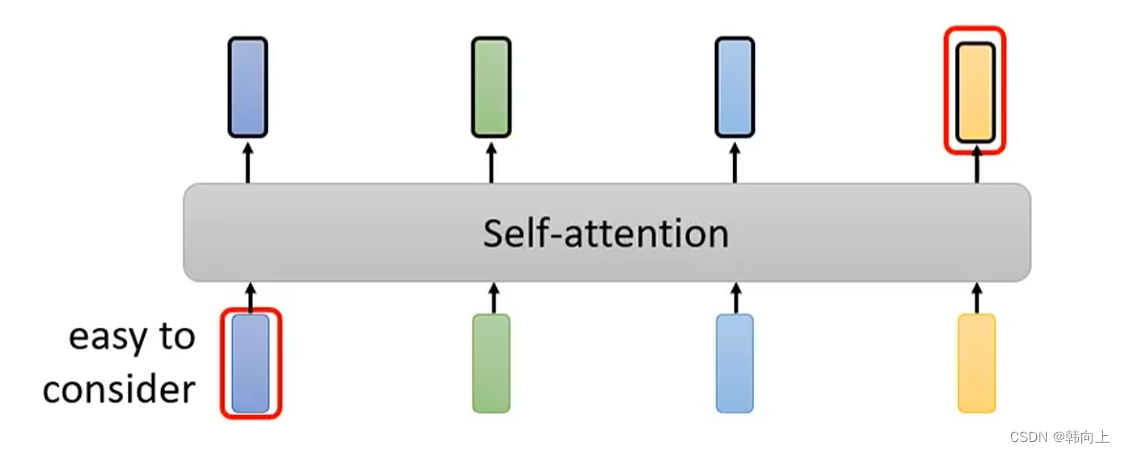
RNN与Self-attention 的不同
-
如果一段序列较长,如果需要最右边黄色的输入与最开始蓝色输入信息的关联,需要将蓝色输入一直存储在memory中,这需要较大的内存。受内存的限制,在RNN中,后面的输入很难与最开始的输入关联。
但是在Self-attention中,只要使用黄色输入的Q与蓝色输入的K进行矩阵乘法计算就能完成这个操作。 -
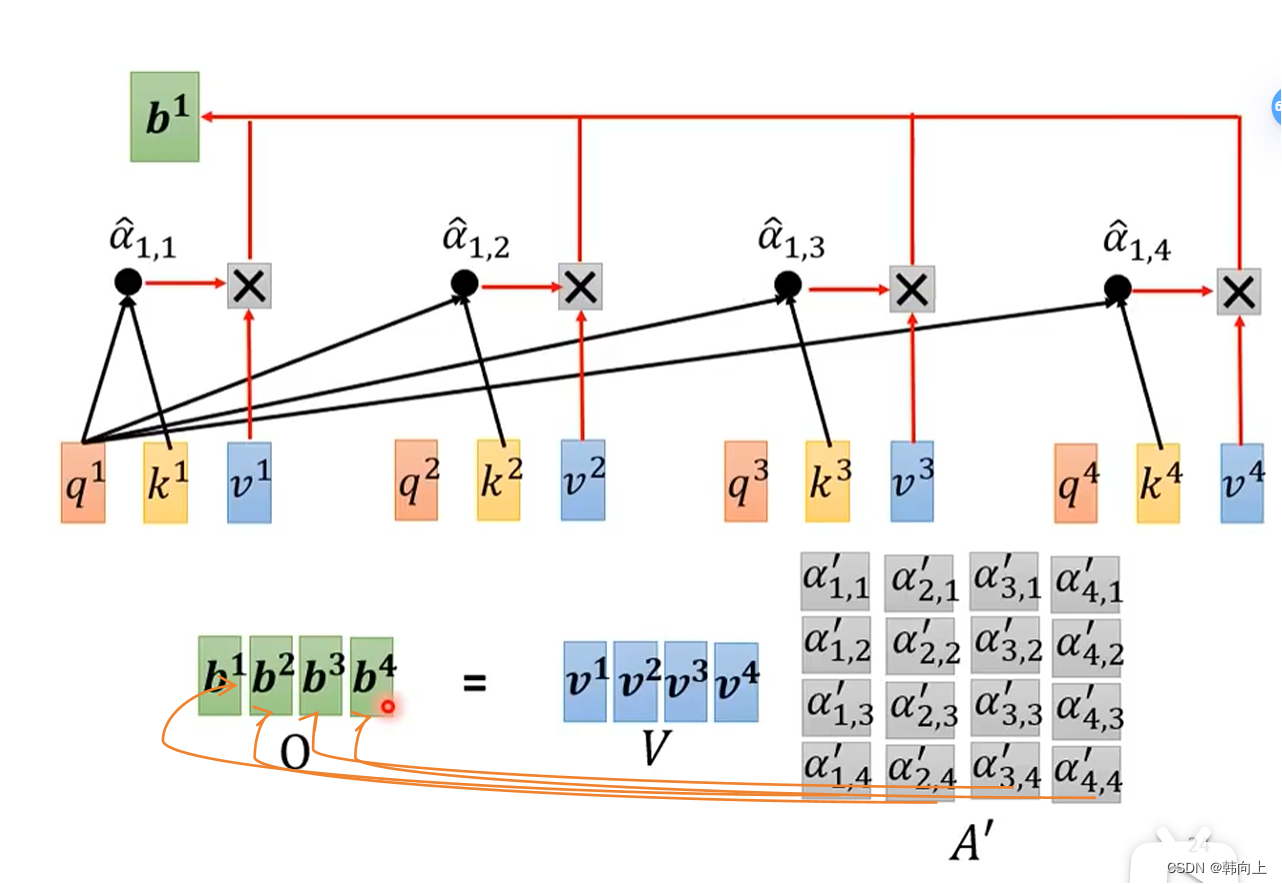
RNN是noparallel, 除了最开始的输入外,RNN中每一个输入都需要考虑前一个的输出来得到当前状态的输出,无法平行处理所有输入。
但是在self-attention中,如下图所示,它可以很轻松的平行处理所有输入。
参考资料
台大李宏毅自注意力机制和Transformer详解!
【NLP】多头注意力(Multi-Head Attention)的概念解析