文章目录
- 引言
- 复习
- 完全背包问题——买书
- 个人实现
- 状态转换机——股票买卖V
- 个人实现
- 参考实现
- 新作
- 两数相除
- 个人实现
- 新作LRU缓存实现
- 个人实现
- unordered_map相关
- priority_queue相关
- 参考实现
- 自己复现
- 总结
引言
-
今天知道拼多多挂掉了,难受,那实习就是颗粒无收了。整的我有点失神,难受,可能后面的日子不好过吧,没什么钱了,然后奖学金评定不一定能够评上!
-
后续好好准备秋招吧,实习暂时算是告一段落了,也不再去想了,加油吧!
-
其实本来主管面就面的不好,我不应该在报什么希望,怀疑会出现像二面一样的情况,觉得免得不好,但是最终给你过了,不可能的!那种毕竟是少数吧!兄弟,加加油吧!我尽力就好了!不要再难过了!
-
不要总是心存侥幸 ,还是得脚踏实地,尽可能完成自己的计划。
复习
完全背包问题——买书
- 上一次分析链接
- 二维背包问题
- 第一次讲买药的背包问题
思路分析
- 这里暂时没有理解那个转换公式,还是使用传统的分析方式再写一遍!
个人实现
#include <iostream>
using namespace std;
const int N = 1010,M = 5;
int p[M] = {0,10,20,50,100};
int n,f[5][N];
int main(){
cin>>n;
f[0][0] = 1;
for (int i = 1; i <= 4; ++i) {
for (int j = 0; j <= n; ++j) {
for (int k = 0; k * p[i] <= n; k ++) {
f[i][j] +=f[i - 1][j - k * p[i]];
}
}
}
cout<<f[4][n];
}
状态转换机——股票买卖V
状态机模型已经做过几道题目了,具体链接如下
- 状态机——股票买卖
- 之前还做过大盗阿福,但是没有了,不过无所谓。
- 上一次的思路分析
个人实现
-
状态转换机的关键是确定有哪几种状态,然后确定状态转移方程,也就是确定了动态规划的方程,最终确定最终的结果。
-
这道题和之前的题目,有不同,没有了限定股票交易次数,所以需要重新考虑一下
-
这里去除了一个维度,但是有一个问题,这个冷冻期应该怎么处理,感觉像我下面这样处理有问题。然后这里有多重情况,应该怎么计算?先试试看吧,先这样写吧,冷冻期不能执行任何操作!
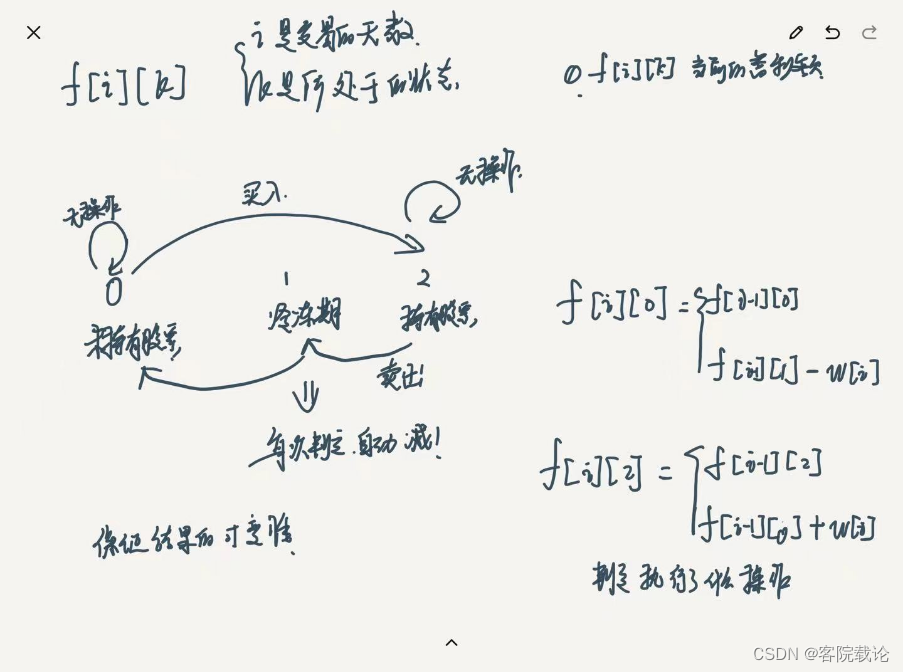
这里有一个问题,如果某一个状态选中了对应的值,那么上一个状态就会影响下一个状态,这就不满足动态规划的基本要求了!
- 暂时只能写成这样了,关于冷冻状态还不知道怎么处理!
#include <iostream>
#include <cstring>
using namespace std;
const int N = 10010,D = -1;//定义D状态表示冷冻状态
int f[N][2]; // 0表示没有持有股票,1表示持有了股票
int w[N],n;
int main(){
cin>>n;
for (int i = 1; i <= n + 1; ++i) {
cin>>w[i];
}
// 向后进行遍历
memset(f, size(f),INT_MIN);
for (int i = 1; i <= n + 1; ++i) {
f[i][0] = max(f[i - 1][0],f[i - 1][1] - w[i]);
f[i][1] = max(f[i - 1][1],f[i - 1][0] + w[i]);
}
// 返回最终结果
cout<<f[n + 1][0];
}
参考实现
- 条件是否满足,是自动判断的,然后自动转移的。
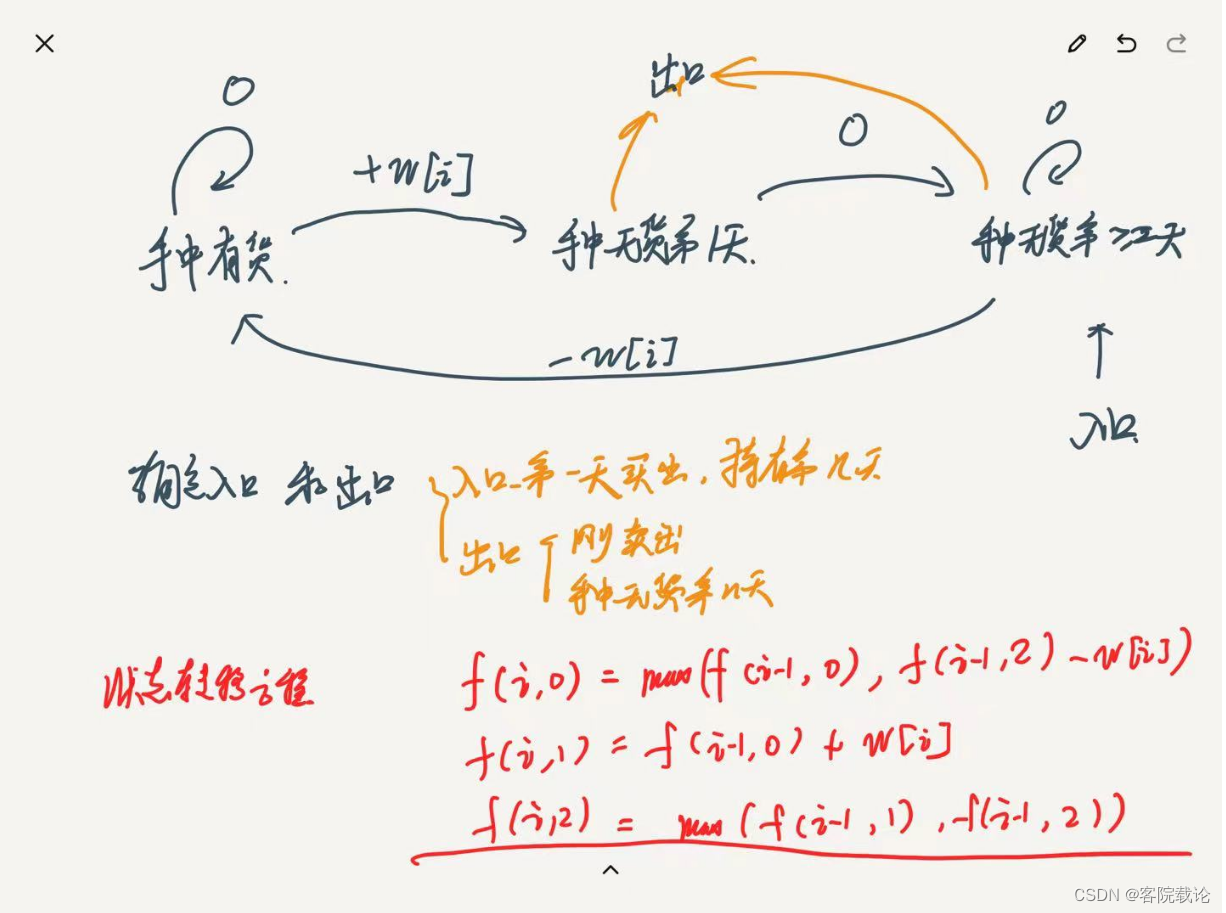
- 这里的思路和我分析的差不多,但是我缺了两部,一个是确定状态机的出口,还有就是状态机的入口。
- 这里根据这个再重写一下哈,还是自己的想法不够理智,没有自信。根源在于对立理论的未知,始终觉得不够!
#include <iostream>
#include <cstring>
#include <limits.h>
using namespace std;
const int N = 100010;//定义D状态表示冷冻状态
int f[N][3]; // 0表示没有持有股票,1表示持有了股票
int w[N],n;
int main(){
cin>>n;
for (int i = 1; i <= n; ++i) {
cin>>w[i];
}
// 向后进行遍历
// memset(f, INT_MIN,size(f));
f[0][0] = f[0][1] = INT_MIN;
f[0][2] = 0;// 定义入口状态
for (int i = 1; i <= n; ++i) {
f[i][0] = max(f[i - 1][0],f[i - 1][2] - w[i]);
f[i][1] = f[i - 1][0] +w[i];
f[i][2] = max(f[i - 1][1],f[i - 1][2]);
}
// 返回最终结果
cout<<max(f[n][1],f[n][2]);
return 0;
}
新作
两数相除
- 题目链接
个人实现
- 有以下几个考虑到东西
- 原来的数据是int类型的,但是INT_MIN的绝对值是比INT_MAX大一的,所以要使用long long进行存储,防止溢出。
- 使用移位运算的增加运算效率,进而增加运算效率
- 保存不同倍数的样本,然后直接比较大小。
#include <iostream>
#include <limits.h>
#include <vector>
using namespace std;
int divide(int x ,int y){
// x / y
typedef long long LL;
vector<LL> exp;
LL a = abs((LL)x),b = abs((LL)y),res = 0;
for (LL i = b; i <= a; b += b) exp.push_back(i);
// 判定符号
int is_minus = 1;
if ((x < 0 && y > 0) || (x > 0 && y < 0)) is_minus = -1;
// 然后从大到小进行遍历,保证结果的相似性
for (int i = exp.size() - 1; i >= 0 ;i --) {
if (a >= exp[i]) {
a -= exp[i];
res += 1ll << i;
}
}
if (res >= INT_MAX) return INT_MAX;
if (res <= INT_MIN) return INT_MIN;
if (is_minus == -1) return 0 - res;
return res;
}
int main(){
cout<<divide(10,3);
}
- 写的还是蛮快的,基本思路都是对的,然后忘记了取绝对值,还有就是移位运算使用了i,不是使用1进行移位运算的。
新作LRU缓存实现
- 题目链接
- 这道题是今天的面试题,难顶,我居然没有写出来,等会得好好再写一遍,有很多方法都没有写出来。
个人实现
-
这道题我就不卡时间了,在面试中,这道题我没有想出来,但是就算按照我的方法,还有很多东西,我自己都实现不了,这里实现以下我的方法。或者说,将我的东西进行查漏补缺一下,还是有很多东西不会。
-
- 感觉这里要实现双向链表和Hashtable的结合体,通过hashtable来实现get和put函数的O(1)访问,通过双向链表来实现对应的最近最久未访问的优先级。
-
下面这两个方法得好好背背,使劲背背,不然太难受了!
unordered_map相关
count方法相关
map.count(key)
- 1表示元素存在
- 0表示元素不存在
删除元素
map.erase(key) //直接删除对应的元素
#include <iostream>
#include <unordered_map>
using namespace std;
int main(){
unordered_map<int,int> s;
// 添加元素
s[1] = 1;
s[2] = 1;
s[3] = 1;
s[4] = 1;
// 获取map的元素个数
cout<<s.size()<<endl;
// 删除特定的元素
s.erase(1);
for (auto i : s) {
cout<<i.first<< " " <<i.second<<endl;
}
// 访问特定的元素
cout<<s[3]<<endl;
cout<<s[6]<<endl; // 访问不存在的元素,默认会返回为零
// count方法测试
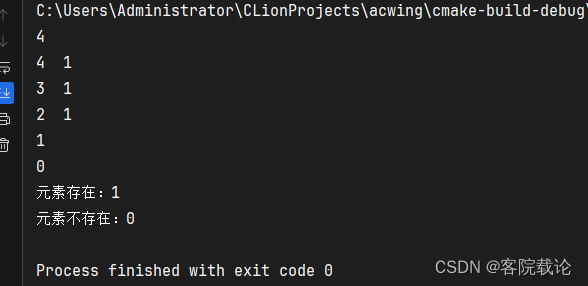
// 元素不存在就返回0,元素存在就返回1
cout<<"元素存在:"<<s.count(3)<<endl;
cout<<"元素不存在:"<<s.count(16)<<endl;
}
priority_queue相关
声明一个自定义排序函数的优先队列
- 这个声明自定义一个比较函数的方法,写法比较特殊,所以需要的好好背一下,认真记录一下哎。
#include <iostream>
#include <queue>
using namespace std;
// 使用结构体声明
struct CustomCompare{
// 两个括号
bool operator()(const int& lhs, const int& rhs) const{
return lhs > rhs;
}
};
int main(){
// 指定中间体,以及对应的比较函数的
priority_queue<int ,vector<int> ,CustomCompare> s;
s.push(6);
s.push(2);
s.push(3);
while(!s.empty()){
cout<<s.top()<<endl;
s.pop();
}
}
- 其他的就跟队列差不多,所以这里需要好好记录一下哎!!
参考实现
- 修改每一个key-value的时间戳,然后能够一瞬间找到最小的元素===》使用双链表实现
- 使用双链表进行排序,实现这种方式。
- 整体的实现方式和我的想的差不多,还是要重视一下怎么实现。
- 下面贴一下y总的代码实现思路。
class LRUCache {
public:
struct Node {
int key, val;
Node *left, *right;
Node(int _key, int _val): key(_key), val(_val), left(NULL), right(NULL) {}
}*L, *R;
unordered_map<int, Node*> hash;
int n;
void remove(Node* p) {
p->right->left = p->left;
p->left->right = p->right;
}
void insert(Node* p) {
p->right = L->right;
p->left = L;
L->right->left = p;
L->right = p;
}
LRUCache(int capacity) {
n = capacity;
L = new Node(-1, -1), R = new Node(-1, -1);
L->right = R, R->left = L;
}
int get(int key) {
if (hash.count(key) == 0) return -1;
auto p = hash[key];
remove(p);
insert(p);
return p->val;
}
void put(int key, int value) {
if (hash.count(key)) {
auto p = hash[key];
p->val = value;
remove(p);
insert(p);
} else {
if (hash.size() == n) {
auto p = R->left;
remove(p);
hash.erase(p->key);
delete p;
}
auto p = new Node(key, value);
hash[key] = p;
insert(p);
}
}
};
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache* obj = new LRUCache(capacity);
* int param_1 = obj->get(key);
* obj->put(key,value);
*/
作者:yxc
链接:https://www.acwing.com/activity/content/code/content/405014/
来源:AcWing
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
自己复现
- 时间太晚了,大概思路整对了就行了,明天抽空再做一下,这里给一个半吊子的。
#include <iostream>
#include <queue>
#include <unordered_map>
using namespace std;
class LRUCache {
public:
struct Node{
int key,value;
Node* l;
Node* r;
Node():key(-1),value(-1),l(nullptr),r(nullptr){};
Node(int k,int v):key(k),value(v),l(nullptr),r(nullptr){};
}*L,*R; // 定义两个伪端点
int n;
unordered_map<int ,Node* > s;
LRUCache(int capacity) {
n = capacity;
L = new Node();
R = new Node();
L->l = R;
R->r = L;
}
void remove(Node* t){
// 删除非两端端点的插入方法,这里删除特定的元素
}
void insert(Node* t){
// 直接在最末尾段插入元素
}
int get(int key) {
// 查看元素是否存在
if(s.count(key) == 1){
// 元素存在,返回对应的值
int res = s[key]->value;
remove(s[key]);
insert(s[key]);
return res;
}else{
// 元素不存在的话,直接返回-1
return -1;
}
}
void put(int key, int value) {
// 判定元素的是否存在,
if (s.count(key) == 1){
s[key]->value = value;
remove(s[key]);
insert(s[key]);
}else{
// 元素不存在,直接加入
// 判定是否爆表
auto p = new Node(key,value);
if (s.size() >= n){
s.erase(L->r->key); //删除元素并添加的
s[key] = p;
// 插入对应的元素
}
}
}
};
int main(){
}
总结
- 其实之前的面试已经体现出我有一个很大的问题了,就是不会的语言的基础特性,无论是java还是C++,都是没背过,今天的面试应该也是要凉的,因为很多基础的特性都不会,没有了解过。这里只是知道怎么用,但是还远远不够,所以需要好好背一下!后面这部分东西,要抓紧了解!
- pdd,我永远的痛呀,秋招应该不会去的,因为有竞业协议,进去了毕竟职业生涯就终结了。不想了,继续看吧。