介绍
动机
在过去十年里,深度神经网络 (DNNs) 已成为机器学习 (ML) 模型的一个重要分支,能够实现跨领域多种应用中的最佳性能。这些模型由一系列包括参数化(如滤波器)和非参数化(如缩小值函数)元件组成的层次结构组成,这种模式虽然运算复杂度高且计算量大,但对于多核、并行处理器来说是非常适用的。
由于深度神经网络的计算能力和 GPU编程带来了极高的难度,因此对特定应用语言 (DSL)及编译器引发出广泛的学术与产业界兴趣。可惜的是,这些系统——无论是采用多面体结构(例如:Tiramisu [BAGHDADI2021]、 Tensor Comprehensions [VASILACHE2018 ])还是计划语言(例如:Halide[JRK2013]、TVM [CHEN2018])的——与库中的cuBLAS、cuDNN或TensorRT等核心数据处理库中的算法相比,速度往往远低。
本项目的主要前提是:基于blocked算法的编程范式 [LAM1991] 可以促进神经网络高性能计算内核的构建。
重新考察了传统GPU上“单程序多数据”(SPMD[AUGUIN,1983])执行模型,并提出一种略有变化的版本:在该版本中,将计算程序置于固定状态,而不是线程。例如,在矩阵乘法方面,CUDA和Triton的区别在于:
CUDA计算编程模型
(Scalar Program, Blocked Threads)
Triton编程模型
(Blocked Program, Scalar Threads)
#pragma parallel
for(int m = 0; m < M; m++)
#pragma parallel
for(int n = 0; n < N; n++){
float acc = 0;
for(int k = 0; k < K; k++)
acc += A[m, k] * B[k, n];
C[m, n] = acc;
}
#pragma parallel
for(int m = 0; m < M; m += MB)
#pragma parallel
for(int n = 0; n < N; n += NB){
float acc[MB, NB] = 0;
for(int k = 0; k < K; k += KB)
acc += A[m:m+MB, k:k+KB]
@ B[k:k+KB, n:n+NB];
C[m:m+MB, n:n+NB] = acc;
}
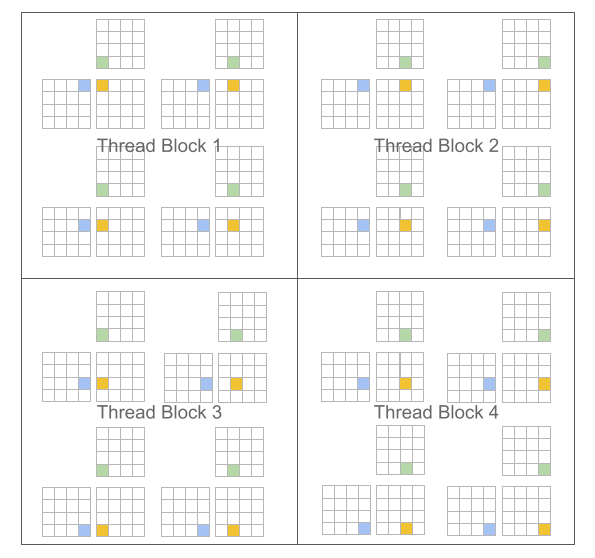
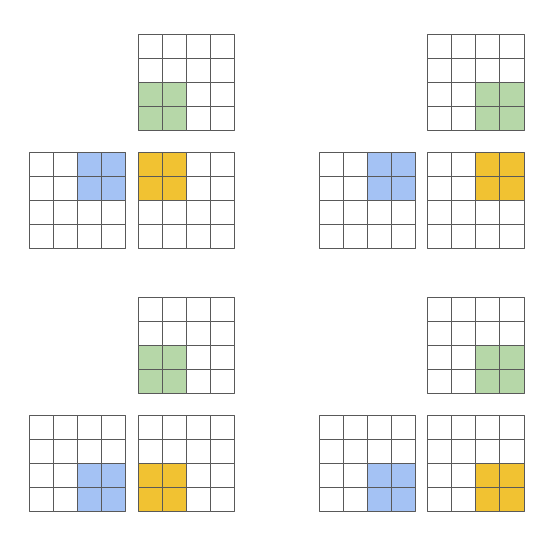
该方法的一个重要优势是,它可以采用块式结构架构,从而为编程者提供了更多选择性,并让他们在实现稀疏算法时能获得与存在的DSL语言相比更大的灵活性。同时,编译器还可以将这些语言用于进行数据局部化和并行化优化。
挑战¶
我们提出的范式带来的主要挑战是工作调度,即如何对每个程序实例完成的工作进行分区,以便在现代 GPU 上高效执行。为了解决这个问题,Triton编译器大量使用块级数据流分析,这是一种基于目标程序的控制和数据流结构静态调度迭代块的技术。最终的系统实际上运行得非常好:我们的编译器设法自动应用了各种有趣的优化(例如,自动合并、线程摆动、预取、自动矢量化、张量核心感知指令选择、共享内存分配/同步、异步复制调度)。当然,做这一切并非易事;本指南的目的之一是让您了解它是如何工作的
相关工作
在初次看到Triton之后,它可能给人的感觉就是这种新兴DNN上下行网络(DDN)的DSL。本节将首先介绍Triton的目的和性质,并且从两个具有重要影响力的领域——多面体编译语言以及图结构计划语言的角度进行对比。
多面体编译-Polyhedral Compilation
编译器中的多面体模型(polyhedral model)是一种高效的程序优化技术,它将复杂的循环依赖关系映射到高维几何空间,从而在编译阶段实现对计算任务的并行化和局部性优化。通过构建和操作多面体表示能有效地调度指令和数据访问,减少资源争用和缓存未命中德情况,从而提高程序执行的性能。
传统的编译器通常依靠介于原始代码和机器语言之间的 “中间表达形式” (如LLVM-IR,这个形式将控制流程信息编码到条件性或非条件性分支中),这种格式是相对低层的。这样一来,就会带来难以实现对输入程序在运行时的执行情况(比如缓存填充问题)进行静态分析、并予以自动优化等方面的问题。因此,triton使用“多边形编译器”[安科尔特,1991]来解决这个问题,该编译器通过采用有可预测控制流程的代码表示方式,实现了对数据流行为的优化。然而,这种策略在目前已经被多个语言和编译器(如Tiramisu[巴格达迪,2021]、Tensor Comprehensions [沃利克,1989]、Diesel[伊兰戈,2018]和MLIR的Affine dialect[拉特纳,2019])采用,但这种方法也存在一些局限性,后文将对此进行详细介绍。
Program Representation
多面体编译是一项广泛的研究领域,本节只是简要介绍了这个话题的基础知识,对于想更加深入地了解此话题相关核心方面内容的读者们,可以参见丰富的线性和整数编程研究文献。
for(int i = 0; i < 3; i++)
for(int j = i; j < 5; j++)
A[i][j] = 0;
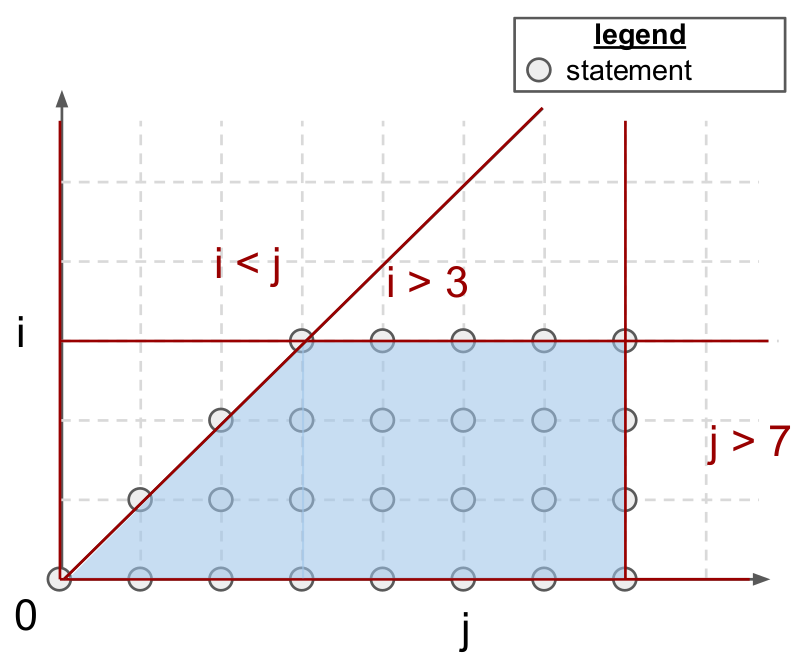
以上将等式转化成了一个二维平面表示的约束,这些约束的交集对应了二维空间上的一个多面体(polyhedron),同理可得如果是三层循环空间,那就是对应了三维空间上的一个多面体,每个约束条件对应一个二维平面,而在 n 维空间上就是一个超平面了。
多面体编译器是专注于最大化连续程序段的范围,通常称为静态控制模块(Static Control Parts- SCoP),这类程序段中的条件语句和循环限定符都是对周围循环指数以及全局假定变量进行非线性递推计算得出的。triton上文已经给出了一个例子,该程序段将所有条件语句和循环限定符都转换成仿射不等式,然后再与全局变量相乘,这些规则可以用多边形表示;在上例中:
每个点都代表一个多面体语句,也就是一个不涉及控制流转换(如 for、if 和 break)的程序句子,同时只包含了指令中所使用到的索引变量和全局参数函数在内的函数。
多面体编译优化关注的是在确保程序执行正确的前提下重组多重循环的结构,实现性能的最优化。
MLIR中Affine方言的定义使用具有多面体特征的循环和条件判断来表示,显示地表示静态控制部分(SCoP:Static Control Part),比如affine.for, affine.if, affine.parallel等,具体可以参见官方文档。在Affine的表达中,使用Dimension和Symbol两类标识符,二者在MLIR语法中均为index类型,同时MLIR也对这两类表示进行约束有助于提升分析和转换能力。从表示形式上看,Dimension以圆括号来声明,Symbol用方括号声明,Dimension即字面意思表示仿射对象的维度信息,比如映射,集合或者具体的loop循环以及一个tensor,Symbol表示的是多面体中的参数,在编译阶段是未知的。在准线性的分析表达上,Symbol当作常量对待,因此Symbol和Dimension之间可以进行乘加等线性操作,但Dimension之间的操作是非法的。另外,Dimension和symbol都遵从SSA赋值。MLIR的Affine重表达体现在通过具体的映射可以表示出多面体的变换,比如图1中的变基操作,通过affine_map语句就能够体现出来。矩阵计算中常用的关于内存的tiling操作,也可以通过affine_map表示。
优点¶
具有多面体编译的可能性的程序可以进行积极的优化和重构,这些重构实际上就是为了生成计划表(schedules)或迭代子集,并在其基础上完成迭代式转换,以推进程序并行化和数据的空间/时间局部性。这类重构包括对循环结构、异构映射、平面切分、并行计算等完成优化和转换。
多胞形编译器也能自动完成复杂的验证过程,以确保在进行优化时输入代码语义的一致性。需要注意的是,多胞形优化器并不与传统的编译策略冲突。实际上,多胞形优化器通常会作为LLVM流水线中的一个子项目进行开发,以便可以在更传统的编译过程之前执行 [GROSSER 2012]。
总的来说,多面体机器是当前最强大、应用广泛的计算机系统。它已经证明能支持矩阵乘法运算所需要的常规算法变换。而且,与现有 GPU 库相比,具备了类似的密集矩阵乘法性能[ELANGO2018]。此外,它还可以实现完全自动化运算,并不需要程序员提供任何其他规则或提示——只是源码必须符合类 C 语言的格式。
缺点
很遗憾,多边形编译器存在两大重要缺点,这使得其无法完全用于神经网络的代码生成。
首先,在编程语言中实现可能的程序转换集合范围十分广泛且随着编程语言所包含的程序语句数量以及对其进行循环操作的规模而不断增大,而在确定每一个转换是否合法时也要解决复杂的实数线性规划问题,从而使得这种编译方式计算成本昂贵。更糟糕的还有,在此方法中不仅要考虑到硬件特性(张量核心的数量、多路传输单元 (multiprocessing modules) 数量)以及语言特征(例如输入图像的形状),从而使得这种编译方式还要进行繁重的自动调整过程 [SATO2019]。
其次,这种多面体框架并不十分适用于广泛的情形; 具有 SCop 结构的神经网络通常较为常见[吉尔巴尔 2006],但其需要计算迭代索引时,必须使用由索引函数组成的可交换插值关系,而这种形式通常只在密集和相对稳定的计算中才会发生。因此,为了将该方法应用于近年来越来越重要的频谱迭代网络,triton还需要克服这种框架在稀疏或结构稠密网络上使用时所面临的困难。
相比之下,本论文提出的阻断程序表达方法在排除范围和优化效率上更为自由,并能以标准数据流分析方式实现近乎最大性能。
调度语言-Scheduling Languages¶
词义分离原则(DIJKSTRA,1982)是计算机科学界很有名的设计方法:程序应该将其核心的意图通过模块化、形式化、层次化的方式分解成不同的部分,这样能保证算法语义与实现细节之间的相互独立。 Halide 和 TVM 等系统正是在这一设计思想基础上推进了一步,他们将叙述语言中的编程方法应用于图灵机理,并以此来实现算法定义(第 1-7 行)与实现(第8-16行)之间的逻辑分割。如下所示,通过这种方式,将算法语义和实现细节分开的优点是在其他计算机程序中特别明显,可以看到定义部分(Line 1-7)与实现部分(Line 8-16)完全隔离,这意味着两者都可以单独进行优化、重构和分发。
// algorithm
Var x("x"), y("y");
Func matmul("matmul");
RDom k(0, matrix_size);
RVar ki;
matmul(x, y) = 0.0f;
matmul(x, y) += A(k, y) * B(x, k);
// schedule
Var xi("xi"), xo("xo"), yo("yo"), yi("yo"), yii("yii"), xii("xii");
matmul.vectorize(x, 8);
matmul.update(0)
.split(x, x, xi, block_size).split(xi, xi, xii, 8)
.split(y, y, yi, block_size).split(yi, yi, yii, 4)
.split(k, k, ki, block_size)
.reorder(xii, yii, xi, ki, yi, k, x, y)
.parallel(y).vectorize(xii).unroll(xi).unroll(yii);
但是这种方法可能会导致的代码并不具有完全的移植性,因为在部分情况下,调度器可以对硬件特性(例如SPMD执行模型)和指令集(如:向量乘积和加法运算)的选取而有所限制。这个问题可通过引入自动调度功能来降低其影响[MULLAPUDI 2016]。
优势
这种方法的主要优点是能让程序员只编写一次算法,而不必担心性能优化。在此过程中,他们可以根据自己的需求手动指定算法的优化,这些优化通常是由立方体编译器无法实现的,而必须使用静态数据流分析才能完成。
毫无疑问,调度语言是神经网络代码生成最流行的方法之一。为此,最流行的系统可能是 TVM,它在各种平台上提供良好的性能以及内置的自动调度机制。
缺点
这种开发简便性的提高,也会造成一定代价。首先,运用该模型所建构的现有系统在兼容现今处理器(如 V100/A100 等,并使用相同瓦片大小)时通常会显得明显较慢;这种情况下,Triton 则会比该系统更加高效。我认为,这不是语言编程的基本问题——也就是说可以通过一些简单操作解决问题——但采用这种方法构建系统会使开发过程更加艰难。更重要的是,现有编程语言所生成的并行程序通常不能使涵盖卷积操作的冗余迭代变量的边界和增量值取决于周围迭代指针值,否则将会对可能的并行计划造成重大限制——甚至使系统完全失效。这是在处理无序操作时引入浮点数滞后问题的一种有害方式,因为卷积空间可能会出现不规则的情况。
for(int i = 0; i < 4; i++)
for(int j = 0; j < 4; j++)
float acc = 0;
for(int k = 0; k < K[i]; k++)
acc += A[i][col[i, k]] * B[k][j]
C[i][j] = acc;
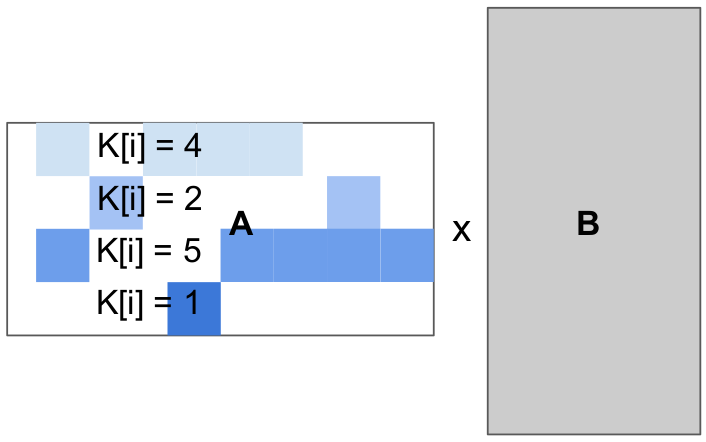
与此相反,triton所倡导的并行程序结构具有基于块的特性,可以实现采用并行迭代的程序编写方式,而且这种编写方法还能使开发者在自动分配进程和数据调整下功夫。