多跳查询为企业提供了深入的数据洞察和分析能力,它在小红书众多在线业务中扮演重要的角色。然而,这类查询往往很难满足稳定的 P99 时延要求。小红书基础架构存储团队针对这一挑战,基于大规模并行处理(MPP)的理念,开发了一种图数据库上的分布式并行查询框架,成功将多跳查询的时延降低了 50% 以上,尤其是使 3 跳查询在在线场景从不能用到落地,极大地增强了在线业务的数据处理能力。
本文核心贡献在于:团队提出了一种从框架层面优化多跳查询时延的方案,在业务上使在线场景中使用多跳查询成为可能,在技术上实现了图数据库查询的框架级优化。全文将从以下几个方面依次展开:
-
介绍小红书使用图数据库的背景,并分析多跳查询在实际业务中因时延高而受限的现状(需求是什么)
-
深入探讨 REDgraph 架构,揭示原有查询模式的不足和可优化点(存在的问题)
-
详细阐述优化原查询模式的方案,并提供部分实现细节(改进方案)
-
通过一系列性能测试,验证优化措施的有效性(改进后效果)
本方案为具有复杂查询需求的在线存储产品提供了优化思路,欢迎业界同行深入探讨。
同时,作者再兴曾在「DataFunCon 2024·上海站」分享过本议题,感兴趣的同学欢迎点击“阅读原文”,回看完整录播视频。

1.1 图数据库在小红书的使用场景
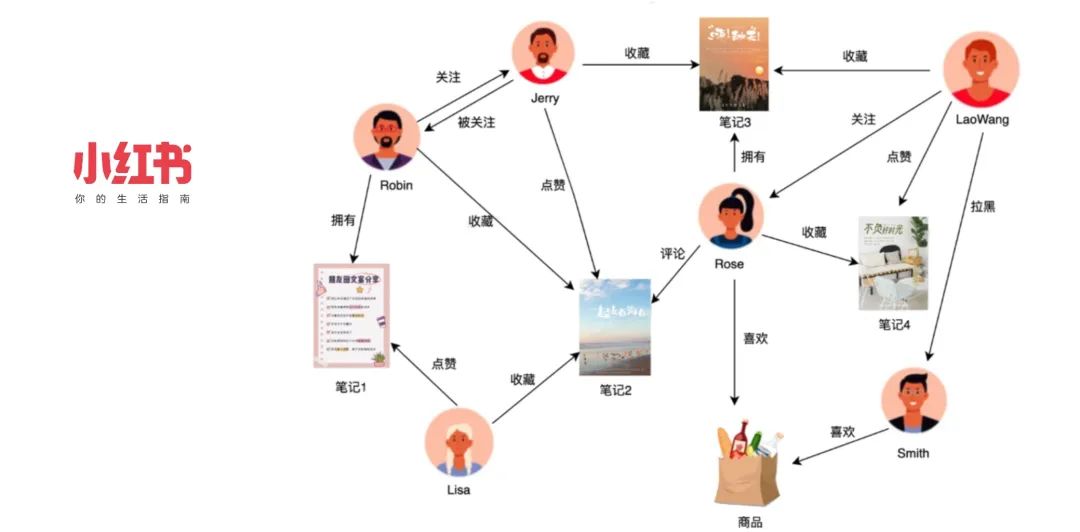
小红书是一个以社区属性为主的产品,覆盖多个领域,鼓励用户通过图文、短视频、直播等形式记录和分享生活点滴。在社交领域中,我们存在多种实体,如用户、笔记、商品等,它们之间构成了复杂的关系网络。为高效处理这些实体间的一跳查询,小红书自研了图存储系统 REDtao,满足极致性能的需求。
(参见:小红书如何应对万亿级社交网络关系挑战?图存储系统 REDtao 来了!)
面对更为复杂的多跳查询场景,我们自研了图数据库系统 REDgraph,将多跳查询的需求应用于小红书多个业务领域,包括但不限于:
-
社区推荐:利用用户间的关系链和分享链,为用户推荐可能感兴趣的好友、笔记和视频。这类推荐机制通常涉及多于一跳的复杂关系。
-
风控场景:通过分析用户和设备的行为模式,识别可能的欺诈行为(如恶意薅羊毛),从而保护平台免受滥用和作弊行为的影响。
-
电商场景:构建商品与商品、商品与品牌之间的关联模型,优化商品分类和推荐,从而提升用户的购物体验。
在传统的 SQL 产品(如 MySQL)中,想实现这些多跳查询,通常需要在一个查询语句中写多个 JOIN,这样的性能无疑是较差的。若想利用键值存储 KV 产品实现,则需要分多次发送 get 请求,并自行处理中间结果,实现过程也较为麻烦。
相比之下,图数据库的设计理念为处理这类查询提供了天然优势。在图数据库中,数据表被抽象为顶点,表之间的关系被抽象为边,并且边作为一等公民被存储和处理。这样一来,执行 n 度关系查询只需查询 n 次边表,大大简化查询过程,并提高了效率。
1.2 业务上面临的困境
小红书在社交、风控及离线任务调度等场景中均采用了图数据库,然而在实际应用过程中遇到了一些挑战。
场景一:社交推荐
在社交推荐中,我们希望能够及时地将用户可能感兴趣的好友或内容推荐给他们。例如,如果用户 A 关注了用户 B,而用户 B 点赞了笔记 C,那么用户 D(也点赞了笔记 C)就可能成为用户 A 的潜在好友,使小红书的好友社区建立更丰富的连接。
业务当然可以使用离线任务分析,基于分析结果进行推荐,但社交图谱是无时无刻不在变化,基于离线分析做出的推荐往往是滞后的。如果推荐得更及时,能更好地抓住一些潜在的用户关系,建立更丰富完善的社交图谱,赋能其他业务(如:社区兴趣小组,电商商品推荐)。
业务希望能即时向用户推送可能感兴趣的 “好友” 或 “内容”,如果能即时完成此推荐,则能有效优化用户使用体验,提升留存率。然而,由于先前 REDgraph 在某些方面的能力尚未完善,导致三跳时延比较高,所以业务一直只采用了一跳和两跳查询。
场景二:社区生态与风险控制
小红书致力于促进社区生态的健康发展,对优质内容创作者提供奖励。然而,这也吸引了一些作弊用户想薅羊毛。例如,作弊用户可能会通过组织点赞来提升低质量笔记的排名,将低质笔记伪造成优质笔记以赚取奖励。
风控业务需要对这种行为予以识别并防范,借助图数据库的多跳查询,我们构建出一个包含用户和笔记为顶点、点赞为边的复杂关系图(“用户->笔记-> ... ->用户->笔记“)。随后,对每篇笔记查询其多度关系(笔记 -> 用户 -> 笔记 -> 用户)上作弊用户的比例,若比例高于一定阈值,把笔记打上作弊标签,系统便不对作弊用户和作弊笔记发放奖励。
打标行为往往是实时消费消息队列去查询图数据库,如果查询动作本身比较慢,则会造成整体消费积压。例如,如果一个查询任务本应在 12:00 执行,但由于性能问题直到 12:10 才开始触发,那么在这十分钟的延迟期间,一篇劣质笔记已成为优质笔记,作者薅羊毛成功。等到发现这是作弊用户时,显然「为时晚矣」,因为损失已经造成了。
具体来说,社交推荐场景要求三跳的 P99 低于 50 毫秒,风控场景则要求三跳的 P99 低于 200 毫秒,这是目前 REDgraph 所面临的一大难题。那为何一至二跳可行,三跳及以上就难以实现呢?对此,我们基于图数据库与其他类型系统在工作负载的差异,做了一些难点与可行性分析。
1.3 难点与可行性分析
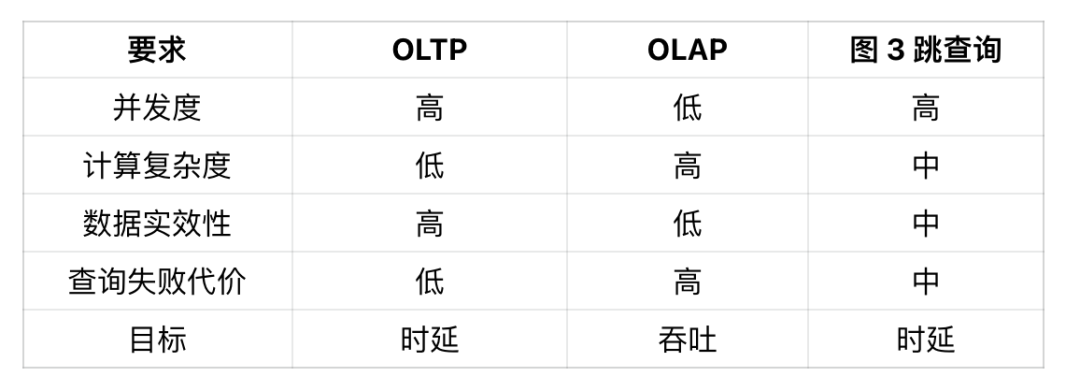
首先在并发方面,OLTP 的并发度很高,而 OLAP 则相对较低。图的三跳查询,服务的仍然是在线场景,其并发度也相对较高,这块更贴近 OLTP 场景。
其次在计算复杂度方面,OLTP 场景中的查询语句较为简单,包含一到两个 join 操作就算是较为复杂的情况了,因此,OLTP 的计算复杂度相对较低。OLAP 则是专门为计算设计的,因此其计算复杂度自然较高。图的三跳查询则介于 OLTP 和 OLAP 之间,它虽不像 OLAP 那样需要执行大量的计算,但其访问的数据量相对于 OLTP 来说还是更可观的,因此属于中等复杂度。
第三,数据时效性方面,OLTP 对时效性的要求较高,必须基于最新的数据提供准确且实时的响应。而在 OLAP 场景中则没有这么高的时效要求,早期的 OLAP 数据库通常提供的是 T+1 的时效。图的三跳查询,由于我们服务的是在线场景,所以对时效性有一定的要求,但并不是非常高。使用一小时或 10 分钟前的状态进行推荐,也不会产生过于严重的后果。因此,我们将其定义为中等时效性。
最后,查询失败代价方面。OLTP 一次查询的成本较低,因此其失败的代价也低;而 OLAP 由于需要消耗大量的计算资源,因此其失败代价很高。图查询在这块,更像 OLTP 场景一些,能够容忍一些失败,但毕竟访问的数据量较大,在查一遍代价稍高,因此同样归属到中等。
总结一下:图的三跳查询具备 OLTP 级别的并发度,却又有比一般 OLTP 大得多的数据访问量和计算复杂度,所以比较难在在线场景中使用。好在其对数据时效性的要求没那么高,也能容忍一些查询失败,所以我们能尝试对其优化。
此外正如上文指出的,在小红书业务场景中,三跳查询的首要目标还是降低延迟。有些系统中会考虑牺牲一点时延来换取吞吐的大幅提升,而这在小红书业务上是不可接受的。如果吞吐上不去,还可以通过扩大集群规模来作为兜底方案,而如果时延高则直接不能使用了。

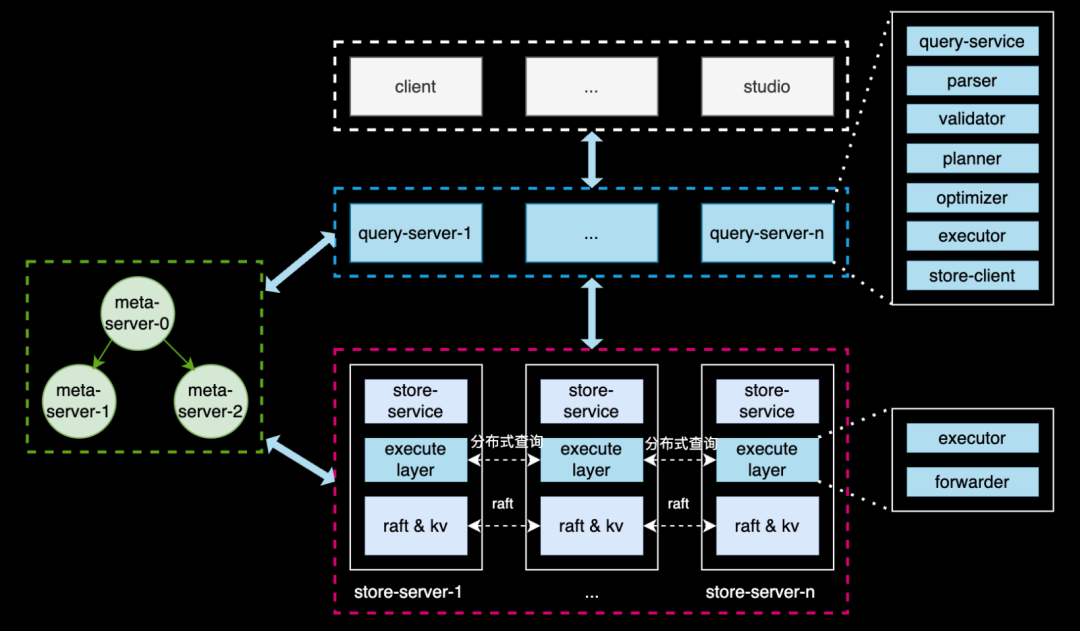
2.1 REDgraph 架构
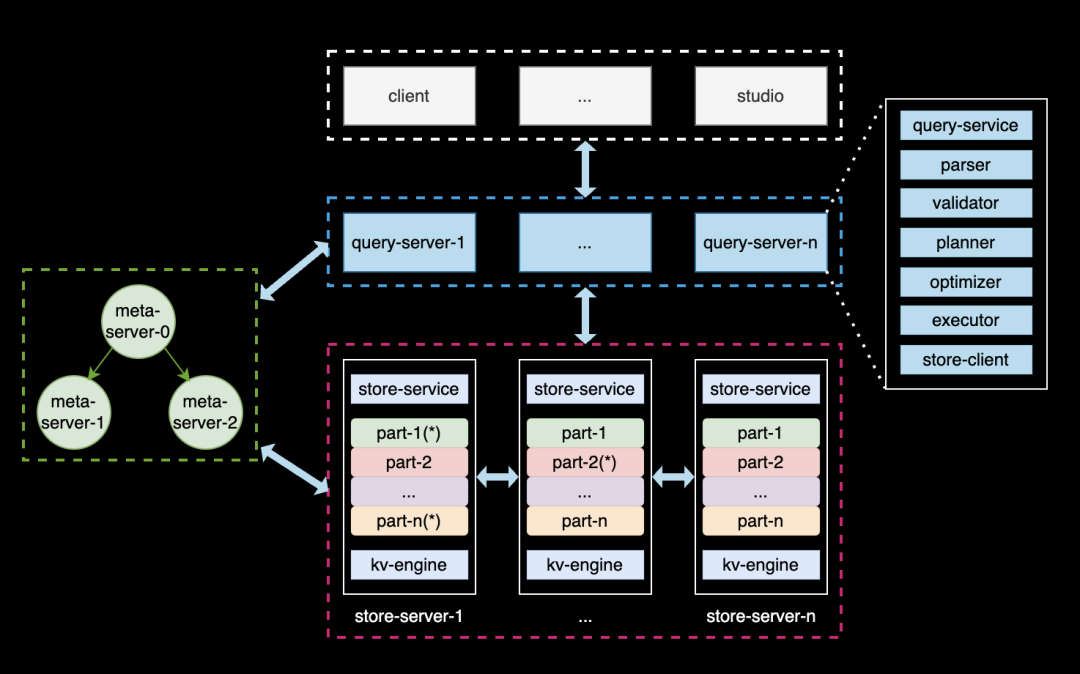
REDgraph 的整体结构如上图所示,其与当前较为流行的 NewSQL,如 TiDB 的架构构相似,采用了存算分离 + shared-nothing 的架构。奇包含三类节点:
-
Meta 服务:负责管理图数据库的元信息,包括数据模式(Schema)、用户账号和权限、存储分片的位置信息、作业与后台任务等;
-
Graph 服务:负责处理用户的查询请求,并做相应的处理,涵盖查询的解析、校验、优化、调度、执行等环节。其本身是无状态的,便于弹性扩缩容;
-
Storgae 服务:负责数据的物理存储,其架构分为三层。最上层是图语义 API,将 API 请求转换为对 Graph 的键值(KV)操作;中间层采用 Raft 协议实现共识机制,确保数据副本的强一致性和高可用性;最底层是单机存储引擎,使用 rocksdb 来执行数据的增删查等操作。
2.2 图切分方式
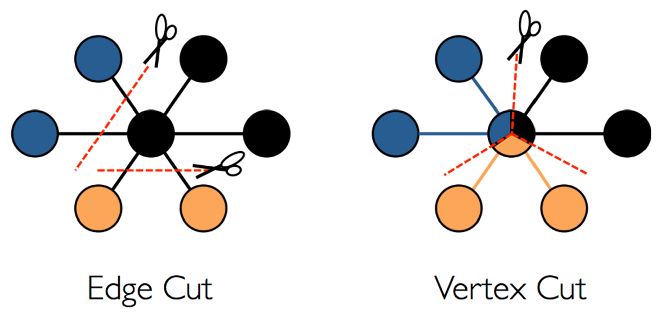
图切分的含义是,如果我们拥有一个巨大的图,规模在百亿到千亿水平,应该如何将其存储在集群的各节点之中,即如何对其切分。在工业界中,主要存在两种典型的切分策略:边切分和点切分。
边切分,以顶点为中心,这种切分策略的核心思想是每个顶点会根据其 ID 进行哈希运算,并将其路由到特定的分片上。每个顶点上的每条边在磁盘中都会被存储两份,其中一份与起点位于同一分片,另一份则与终点位于同一分片。
点切分,与边切分相对应,也就是以边为中心做哈希打散,每个顶点会在集群内保存多份。
这两种切分方式各有利弊。边切分的优点在于每个顶点与其邻居都保存在同一个分片中,因此当需要查询某个顶点的邻居时,其访问局部性极佳;其缺点在于容易负载不均,且由于节点分布的不均匀性,引发热点问题。点切分则恰恰相反,其优点在于负载较为均衡,但缺点在于每个顶点会被切成多个部分,分配到多个机器上,因此更容易出现同步问题。
REDgraph 作为一个在线的图查询系统,选择的是边切分的方案。
2.3 优化方案 1.0
· 通用性差,且在 3 跳场景中效果还不够。
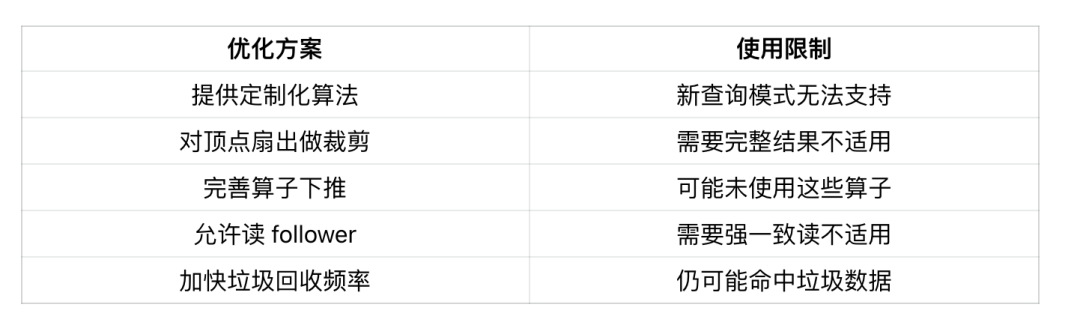
我们之前已经实施了一些优化,可以称之为优化方案 1.0。当时主要考虑的是如何快速满足用户需求,因此我们的方案包括:首先根据常用的查询模式提供一些定制化的算法,这些算法可以跳过解析、校验、优化和执行等繁琐步骤,直接处理请求,从而实现加速。其次,我们会对每个顶点的扇出操作进行优化,即每个顶点在向外扩展时,对其扩展数量进行限制,以避免超级点的影响,降低时延。此外,我们还完善了算子的下推策略,例如 filter、sample、limit 等,使其尽可能在存储层完成,以减少网络带宽的消耗。同时,我们还允许读从节点、读写线程分离、提高垃圾回收频率等优化。
然而,这些优化策略有一个共性,就是每个点都比较局部化和零散,因此其通用性较低。比如第一个优化,如果用户需要发起新的查询模式,那么此前编写的算法便无法满足其需求,需要另行编写。第二个优化,如果用户所需要的是顶点的全部结果,那此项也不再适用。第三个优化,如果查询中本身就不存在这些运算符,那么自然也无法进行下推操作。诸如此类,通用性较低,因此需要寻找一种更为通用,能够减少重复工作的优化策略。
2.4 新方案思考
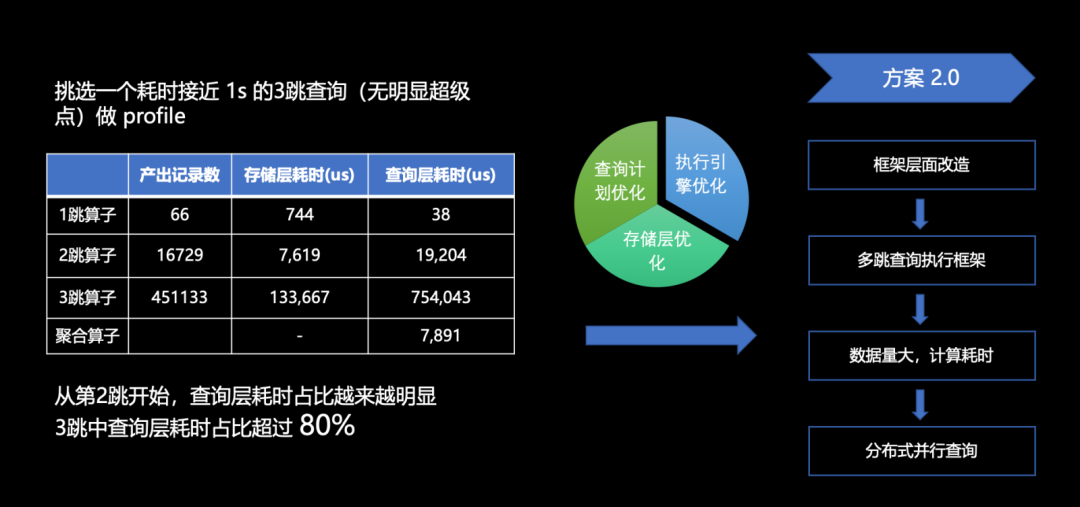
如上图所示,我们对一个耗时接近一秒的三跳查询的 profile 分析。我们发现在每一跳产出的记录数量上,第一跳至第二跳扩散了 200 多倍,第二跳至第三跳扩散了 20 多倍,表现在结果上,需要计算的数据行数从 66 条直接跃升至 45 万条,产出增长速度令人惊讶。此外,我们发现三跳算子在整个查询过程中占据了较大的比重,其在查询层的耗时更是占据了整个查询的 80% 以上。
那么应该如何进行优化呢?在数据库性能优化方面,有许多可行的方案,主要分为三大类:存储层的优化、查询计划的优化以及执行引擎的优化。
由于耗时大头在查询层,所以我们重点关注这块。因为查询计划的优化是一个无止境的工程,用户可能会写出各种查询语句,产生各种算子,难以找到一个通用且可收敛的方案来覆盖所有情况。而执行引擎则可以有一个相对固定的优化方案,因此我们优先选择了优化执行引擎。
图数据库的核心就是多跳查询执行框架,而其由于数据量大,计算量大,导致查询时间较长,因此我们借鉴了 MPP 数据库和其他计算引擎的思想,提出了分布式并行查询的解决方案。
2.5 原多跳查询执行流程
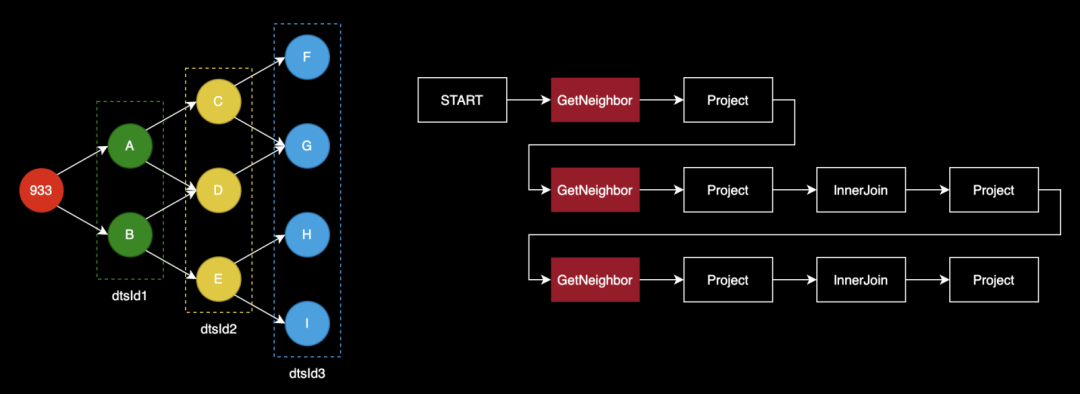
原有的多跳查询执行流程如上图所示。假设我们要查询 933 顶点的三跳邻居节点 ID,即检索到蓝圈中的所有顶点。经过查询层处理后,将生成右图所示执行计划,START 表示计划的起点,本身并无实际操作。GetNeighbor 算子则负责实际查询顶点的邻居,例如根据 933 找到 A 和 B。后续的 Project、InnerJoin 以及 Project 等操作均为对先前产生的结果进行数据结构的转换、处理及裁剪等操作,以确保整个计算流程的顺利进行。正是后续的这几个算子耗费的时延较高。
2.6 可优化点分析
2.6.1 Barrier 等待使时延增加
从上述物理执行中可以看出:查询节点必须等所有存储节点的响应返回后,才会执行后面的算子。这样即使大多数存储节点很快返回,只要有一个「慢存储节点」存在,整个查询都得 block 住。
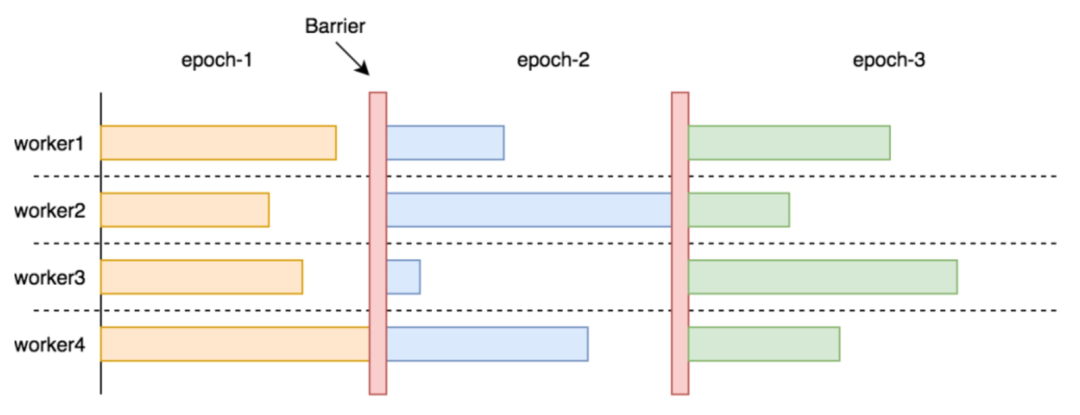
在图计算(AP)场景中,一次计算往往要经过很多轮迭代(Epoch),并且每轮迭代后都需要进行全局指标的更新,更新完再继续下一轮迭代。在 Epoch 之间插入 Barrier 做同步是有必要的。
但在图查询(TP)场景中,通常不需要全局性更新,只是在下发请求时对起点 ID 做去重,即使有往往也是在查询的最后一步,因此没有必要 barrier。
此外,图数据库负载往往呈现出“幂律分布”现象,即少数顶点邻居边多、多数顶点邻居边少;REDgraph 本身也是以边切分的方式存储数据,这就使得「慢存储节点」很容易出现。加之某个存储节点的网络抖动或节点负载高等因素,可能导致响应时间进一步延长,影响查询效率。
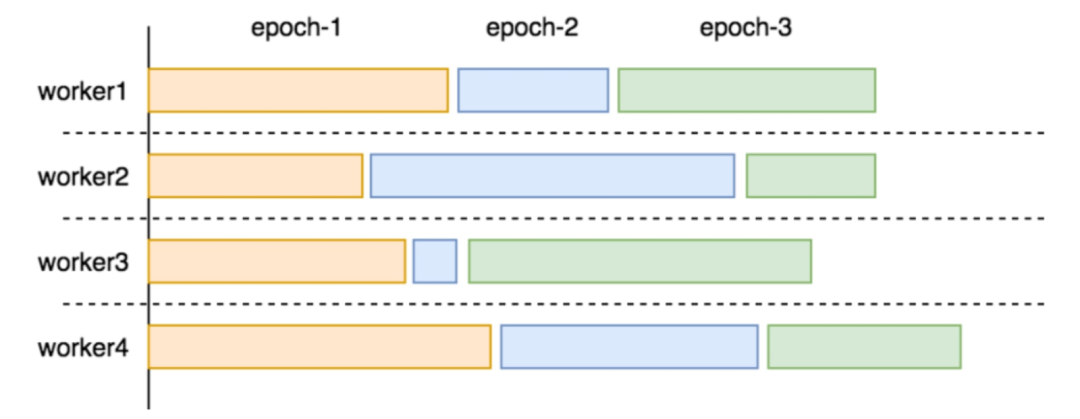
如图所示,如果查询层收到一个响应就处理一个响应(类似于 pipeline 的机制),则能避免无意义的空等,从整体上加速查询的执行。
2.6.2 查询层串行执行效率低
在整个查询计划中,只有 GetNeighbor 算子是在多个存储节点上并行执行,而其他算子是在查询节点上串行执行,这里我们想到两个问题:
-
串行执行的效率天然低于并行执行。只有在数据量太少或者计算逻辑太简单的情况下,上下文切换的开销会超过并行的收益。在正常负载的图查询场景中,数据量和计算逻辑都挺可观;
-
当多个存储节点的响应数据汇聚到查询节点时,数据量仍然相当可观。如果能在 storaged 节点上完成这些计算,将显著减少查询节点需要处理的数据量。
我们在业务的线上集群和性能测试显示:GetNeighbors 和 GetVertices 不是所有算子中最耗时的,反倒是不起眼的 Project 算子往往耗费更多时间,特别是那些紧随 GetNeighbors 和 GetVertices 之后的 Project 算子,因为它不仅需要执行数据投影,还负责将 map 展平。
这表明整个查询的主要瓶颈在于计算量大。而查询计划中大部分都是纯计算型算子,将它们并行化对于提升查询效率很有必要。
2.6.3 查询结果转发浪费 IO
如上文所说,在图查询场景中一般不需要做全局性的更新,查询节点收到各存储节点的响应后,只是简单地再次分区然后下发,所以存储节点的结果转发到查询层,再从查询节点分发到各存储节点很浪费。
如果存储节点自身具备路由和分发的能力,那可以让存储节点执行完 GetNeighbors 算子后,接着执行 Project、InnerJoin 等算子,每当遇到下一个 GetNeighbor 算子时,自行组织请求并分发给其他存储节点。其他存储节点收到后接着执行后面的算子,以此规则往复,直到最后一步将结果汇聚到查询层,统一返回给客户端。
2.7 改造后的执行流程
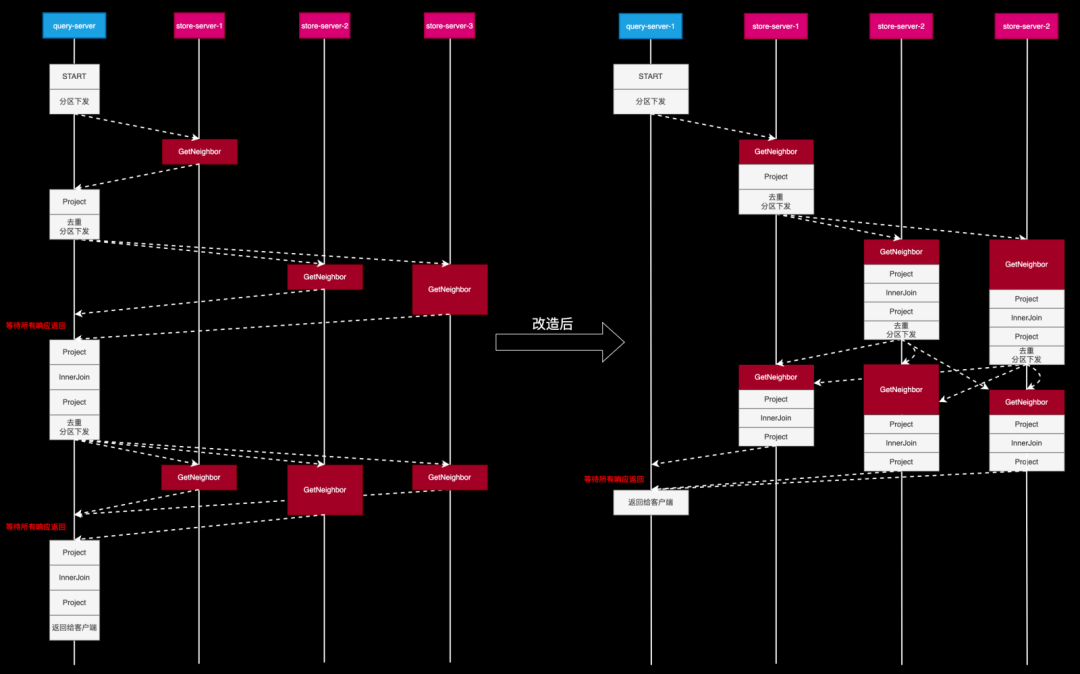
首先,查询服务器(Query Server)将整个执行计划以及执行计划所需的初始数据传输至存储服务器(Store Server),之后 Store Server 自身来驱动整个执行过程。以 Store Server 1 为例,当它完成首次查询后,便会根据结果 ID 所在的分区,将结果转发至相应的 Store Server。各个 Store Server 可以独立地继续进行后续操作,从而实现整个执行动作的并行化,并且无同步点,也无需额外转发。
需要说明的是,图中右侧白色方框比左侧要矮一些,这是因为数据由上方转到下方时,进行了分区下发,必然比在查询服务器接收到的总数据量要少。
可以看到,在各部分独立驱动后,并未出现等待或额外转发的情况,Query Server 只需在最后一步收集各个 Store Server 的结果并聚合去重,然后返回给客户端。如此一来,整体时间相较于原始模型得到了显著缩短。

分布式并行查询的具体实现,涉及到许多个关键点,接下来介绍其中一些细节。
3.1 如何保证不对 1-2 跳产生负优化
首先一个问题是,在进行改造时如何确保不会对原始的 1-2 跳产生负优化。在企业内部进行新的改造和优化时,必须谨慎评估所采取的措施是否会对原有方案产生负优化。我们不希望新方案还未能带来收益,反而破坏了原有的系统。因此,架构总体上与原来保持一致。在 Store Server 内部插入了一层,称为执行层,该层具有网络互联功能,主要用于分布式查询的转发。Query Server 层则基本保持不变。
这样,当接收到用户的执行计划后,便可根据其跳数选择不同的处理路径。若为 1 至 2 跳,则仍沿用原有的流程,因为原有的流程能够满足 1-2 跳的业务需求,而 3 跳及以上则采用分布式查询。
3.2 如何与原有执行框架兼容
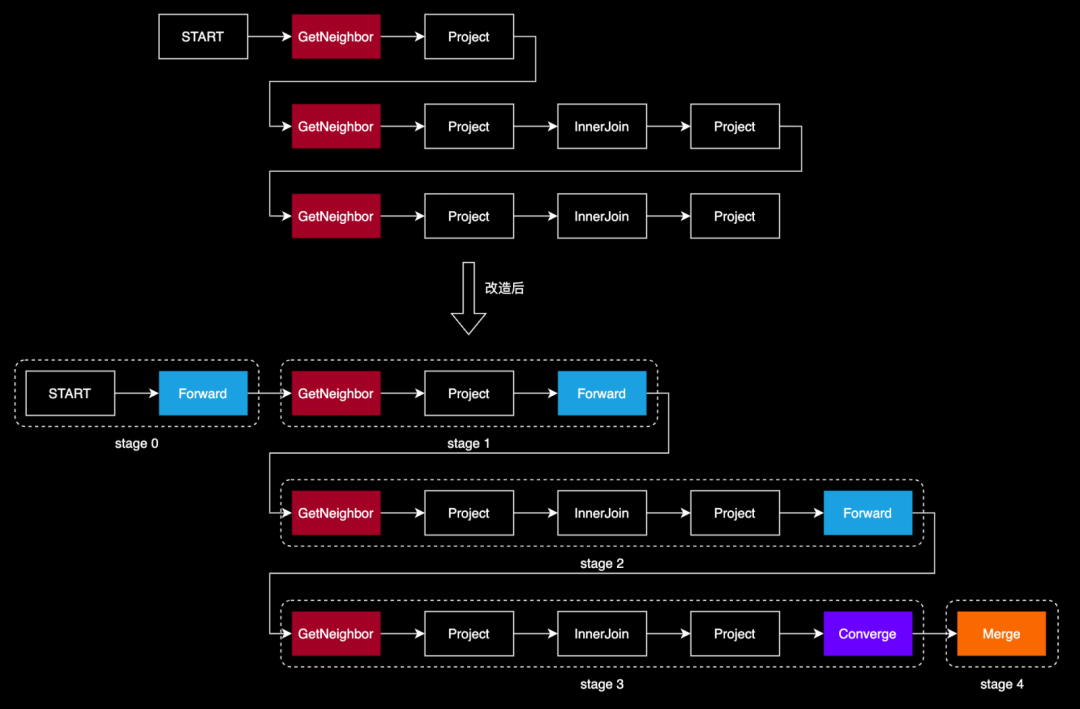
原有代码中每一个操作都是用算子方式实现。为了让分布式并行查询的实现与原有框架兼容,我们把「转发」也定义为一个算子,取名为 Forward。这一算子的功能类似于 Spark 中的 Shuffle 算子、或 OceanBase 中的 Exchange 算子,关键在于它能够确保查询在分布式环境中顺畅执行。
我们对查询计划进行了以下关键改写:
-
在每个要「切换分区才能执行的」算子前(例如 GetNeighbors、GetVertices 等),我们添加一个 FORWARD 算子。FORWARD 算子负责记录分区的依据,通常是起点 ID。
-
为了将分布式节点的查询结果有效地汇总,我们在查询计划的末端添加了 CONVERGE 算子,它指示各节点将结果发送回 DistDriver 节点,即最初接收用户请求的节点。
-
随后,我们引入了 MERGE 算子,它的作用是对所有从节点收到的结果进行汇总,并将最终结果返回给客户端。
通过这种方式,当 REDgraph-Server 准备执行 GetNeighbors、GetVertices 算子时,它会首先执行 FORWARD、CONVERGE算子,将必要的数据和查询计划转发到其他服务器。这样,其他服务器在接收到请求后,就能明确自己的任务和所需的数据,从而推动查询计划的执行。
值得注意的是,FORWARD 和 CONVERGE算子都有「转发/发送」数据的含义,不过它们的侧重点不太一样:
-
FORWARD 强调的是路由转发,并且要指定转发的依据,即 partitionKey 字段,不同的数据行会根据其 partitionKey 字段值的不同转发到不同的节点上;
-
CONVERGE 强调的是发送汇聚,具有单一确定的目标节点,即 DistDriver;
因它们只是在做转发/发送的工作,我们将这类算子统称为「路由」算子。
在改造后的查询计划中,从 START 算子开始,直到遇到「路由」算子,这多个算子都可以在某个节点本地执行的,因此我们将这一系列算子划分到一个 stage 内。整个查询计划由多个 stage 组成,其中首尾两个 stage 在 DistDriver 上执行,中间的 stage 在 DistWorker 上执行。
需要注意的是:stage 是一个逻辑概念,具体执行时,每个 stage 会依据分区和所属节点产生多个 task,这些 task 会分布在多个节点上执行,每个节点仅访问本节点内数据,无需跨网络拉取数据。这种结构化的方法极大地提高了查询的并行性和效率。
3.3 如何做热点处理
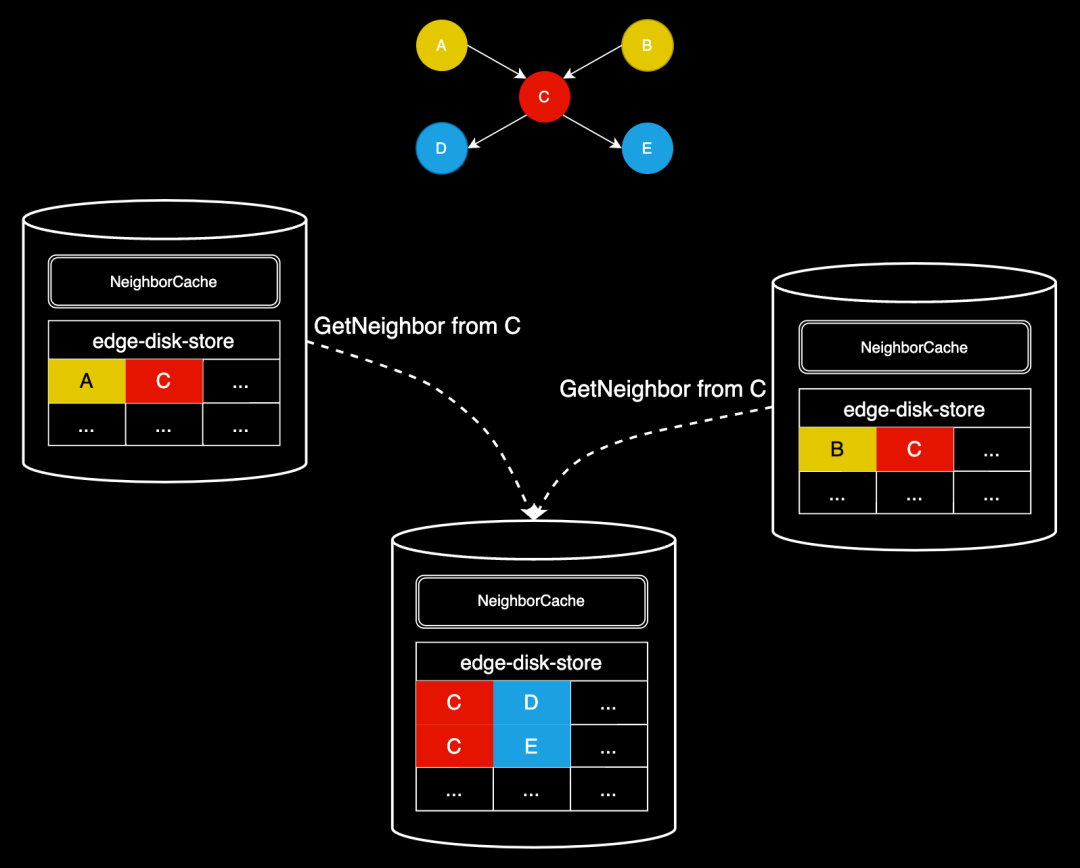
在原查询模式中,每一次在发起 GetNeighbors 算子前,查询层会对起点 ID 去重(查询计划中 GetNeighbors 算子的 dedup 为 true),收到存储节点的响应后,再依靠后续算子将结果按需展平,因此存储节点不会产生重复查询。以下图举例说明:
原查询模式的执行流程可简单描述为:
-
第一跳从存储层查到 A->C 和 B->C,返回到查询层;
-
查询层会 Project 得到两个 C,以备后面做 InnerJoin;
-
准备执行第二跳,构造起点集合时,由于 dedup 为 true,仅会保留一个 C;
-
第二跳从存储层查到 C->D 和 C->E,返回到查询层;
-
查询层执行 InnerJoin,由于此前有两个 C,所以 C->D 和 C->E 也各会变成两个;
-
查询层再次 Project 取出 dstId2,得到结果 D、D、E、E。
从步骤 4 可以看到,存储层不会产生重复查询。
改造成分布式查询后,我们只能在每个 stage 内去重。但由于缺乏全局 barrier,多个 stage 先后往某个 DistWorker 转发请求时,多个请求之间可能有重复的起点,会在存储层产生重复查询和计算,导致 CPU 开销增加以及查询时延增加。
如果每一跳产生的重复终点 ID(将会作为下一跳的起点 ID)很多,分布式查询反而会带来劣势。为解决这一问题,我们引入一套起点 ID 去重机制 —— NeighborCache,具体方案如下:
因为没有全局的 Barrier,无法在下发请求之前去重,我们选择在存储节点上提供一个 NeighborCache,其本质就是一个 map,可表示为 map<vid +="" edgetype,="" list>。在执行 GetNeighbors 算子前,存储节点会首先检查 NeighborCache,如果找到相应的条目,则直接使用这些数据填充结果集;如果没有找到,则访问存储层获取数据,并更新 NeighborCache,读取和更新 Cache 需要用读写锁做好互斥。
另外,NeighborCache 还具有如下特点:
-
每当有更新 vid + edgeType 的请求时,都会先 invalidate cache 中对应的条目,以此来保证缓存与数据的一致性;
-
即使没有更新操作存在,cache 内的每个 kv 条目存活时间也很短,通常为秒级,超过时间就会被自动删除。为什么这么短呢?
-
充分性:由于在线图查询(OLTP)的特性,用户的多跳查询通常在几秒到十几秒内完成。而 NeighborCache 只是为了去重而设计,来自于不同 DistWorker 的 GetNeighbors 请求大概率不会相隔太长时间到达,所以 cache 本身也不需要存活太久;
-
必要性:从 map 结构的 key 就会发现,当 qps 较高,跳数多,顶点的邻居边多时,此 map 要承载的数据量是非常大的,所以也不能让其存活的时间太久,否则很容易 OOM;
-
-
在填充 cache 前会做内存检查,如果本节点当前的内存水位已经比较高,则不会填充,以避免节点 OOM。
通过这种起点 ID 去重机制,我们能够有效地减少重复查询,提高分布式查询的效率和性能。
3.4 如何做负载均衡
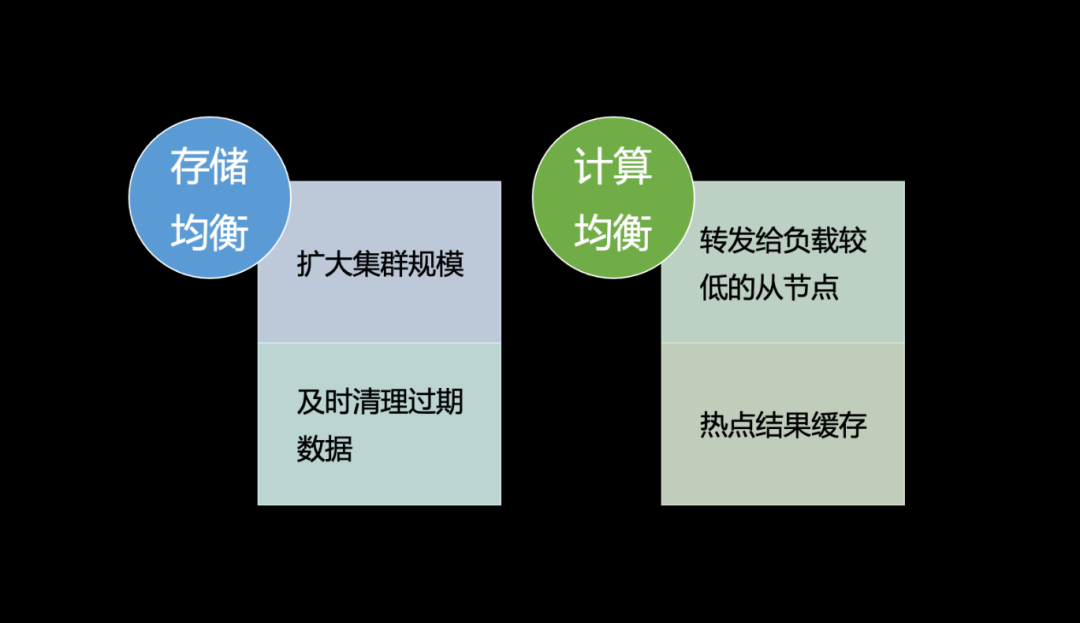
第四个问题是怎么做负载均衡,包括存储的均衡和计算的均衡。
首先,存储的均衡在以边切分的图存储里面其实是很难的,因为它天然的就是把顶点和其邻居全部都存在了一起,这是图数据库相比其他数据库的优势,也是其要承担的代价。所以目前没有一个彻底的解决方法,只能在真的碰到此问题时扩大集群规模,让数据的哈希打散能够更加均匀一些,避免多个热点都落在同一个机器的情况。而在目前的业务场景上来看,其实负载不均衡的现象不算严重,例如风控的一个比较大的集群,其磁盘用量最高和最低的也不超过 10%,所以问题其实并没有想象中的那么严重。
另外一个优化方法是在存储层及时清理那些过期的数据,清理得快的话也可以减少一些不均衡。
计算均衡的问题。存储层采用了三副本的策略,若业务能够接受弱一致的读取(实际上大多数业务均能接受),我们可以在请求转发时,查看三副本中的哪个节点负载较轻,将请求转发至该节点,以尽量平衡负载。此外,正如前文所述,热点结果缓存也是一种解决方案,只要热点处理速度足够快,计算的不均衡现象便不易显现。
3.5 如何做流程控制
在分布式查询架构中,由于前面取消全局 Barrier,使得各个 DistWorker 自行驱动查询的进行。这种设计提高了灵活性,但也带来新的挑战:
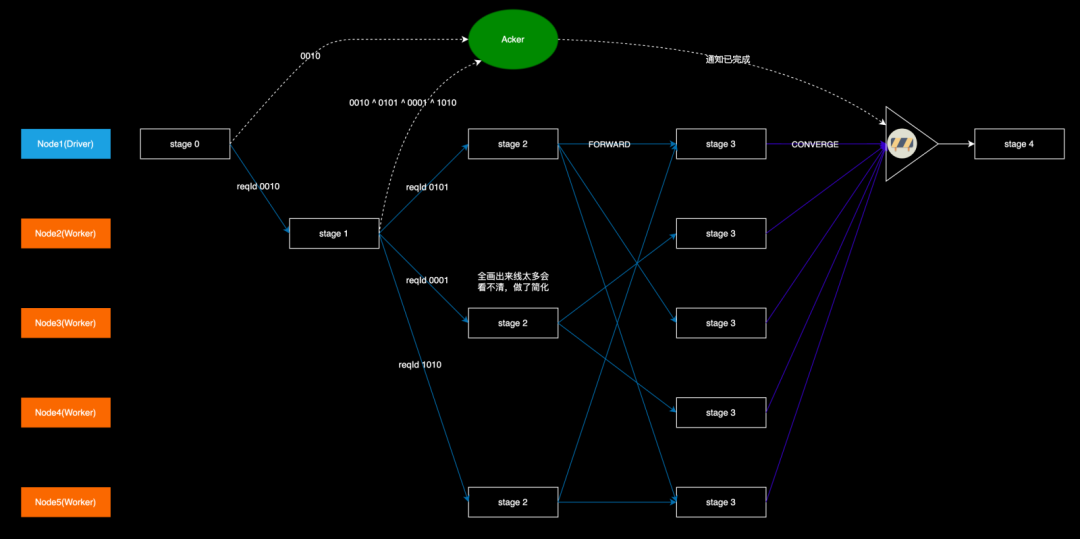
如图所示,各个 DistWorker 上 stage3 的结果需要汇聚到 DistDriver 后才能向客户端返回,但是 DistDriver 只在 stage0 的时候给 Node2 发送了请求,后面的所有转发都是由 DistWorker 自行完成的,脱离了 DistDriver 的「掌控」。这样 DistDriver 就不知道最后有多少个节点在执行 stage3,也就不知道该等待哪些 DistWorker 给它发送结果,以及何时可以开始执行 stage4。
我们引入一个进度汇报机制:在 DistDriver 上实现一个 Acker,负责接收各个 DistWorker 上报的 stage 执行进度信息。每个 stage 向外扩散时,向 Acker 发送一条消息,记录当前完成的 stage 和 即将开始的 stage 的节点数量。具体而言,就是包含两个键值对:
-
当前的 stage 编号 -> -1;
-
下一个 stage 的编号 -> 执行下一个 stage 的节点的数量;
比如 Node2 上的 stage-1 扩散到 stage-2 时,目标节点有 3 个:Node1、Node3、Node5,于是就发送 {stage-1: -1,stage-2: 3} 的消息到 DistDriver 上,表示有一个节点完成了 stage-1,有 3 个节点开始了 stage-2。而由于 stage-1 此前由 Node1 登记过 {stage-1: 1},这样一正一负就表示所有的 stage-1 都已经执行完毕。stage-2 和 stage-3 的更新和判定方式类似,当 DistDriver 发现所有的前置 stage 数量都为 0 时,就可以驱动 stage-4 。
我们实际想要的是每个 stage 数量的正负抵消能力,而非 {stage-1: -1,stage-2: 3} 的字符串。为了简化这一过程,我们便采用异或运算(相同为 0,相异为 1)跟踪各个 stage 的状态,举例说明:
-
Acker 上有一个初始的 checksum 值 0000;
-
stage-0 在扩散到 stage-1 时,生成了一个随机数 0010(这里为了表达简便,以 4 位二进制数代替),这个 0010 是 Node2 上的 stage-1 的 Id,然后把这个 0010 伴随着 Forward 请求发到 Node2 上,同时也发到 Acker 上,这样就表示 0010 这个 stage 开始了,Acker 把收到的值与本地的 checksum 做异或运算,得到 0010,并以此更新本地 checksum;
-
stage-1 执行完后扩散到 stage-2 时,由于有 3 个目标节点,就生成 3 个不相同的随机数 0101、0001、1010(需要检查这 3 个数异或之后不为 0),分别标识 3 个目标节点上的 stage-2,然后把这 3 个数伴随着 Forward 请求发到 Node1、Node3、Node5 上,同时在本地把自身的 stage Id(0010)和这 3 个数一起做异或运算,再把运算的结果发到 Acker,Acker 再次做异或运算,也就是 0010 ^ (0010 ^ 0101 ^ 0001 ^ 1010),这样 0010 就被消除掉了,也就表示 stage-1 执行完成了;
-
重复上述过程,最后 Acker 上的 checksum 会变回 0,表示可以驱动 stage-4。
注意:尽管在某个节点的 stage 扩散时检查了生成的随机数异或不为 0,但是多个节点间生成的随机数异或到一起还是可能为 0 的,比如 Node1 的 stage-2 生成的 3 个数异或后为 0001,Node3 的 stage-2 异或后为 0010,Node5 的 stage-2 异或后为 0011,0001 ^ 0010 ^ 0011 = 0。这样就会导致 stage-3 还在执行中时,DistDriver 就误认为它已经执行完毕,提前驱动 stage-4 的执行。
不过考虑到我们实际使用的是 int32 整数,出现这种的情况的概率非常低。在未来的优化中在,我们可以考虑给每个 Node 生成一个 16 位的随机 Id(由 metad 生成),并保证这些 NodeId 异或结果不为 0,当 stage 扩散时,将 NodeId 置于随机数的高位,确保分布式查询的每个阶段都能被准确跟踪和协调。
另一个重要的问题便是全程链路的超时自检,例如在 stage2 或 stage3 的某一个节点上运行时间过长,此时不能让其余所有节点一直等待,因为客户端已经超时了。因此我们在每个算子内部的执行逻辑中都设置了一些埋点,用以检查算子的执行是否超过了用户侧的限制时间,一旦超过,便立即终止自身的执行,从而迅速地自我销毁,避免资源的无谓浪费。

我们在改造工程完成后进行了性能测试,采用 LDBC 组织提供的 SNB 数据集,生成了一个 SF100 级别的社交网络图谱,规模达到 3 亿顶点,18 亿条边。我们主要考察其一跳、二跳、三跳、四跳等多项查询性能。
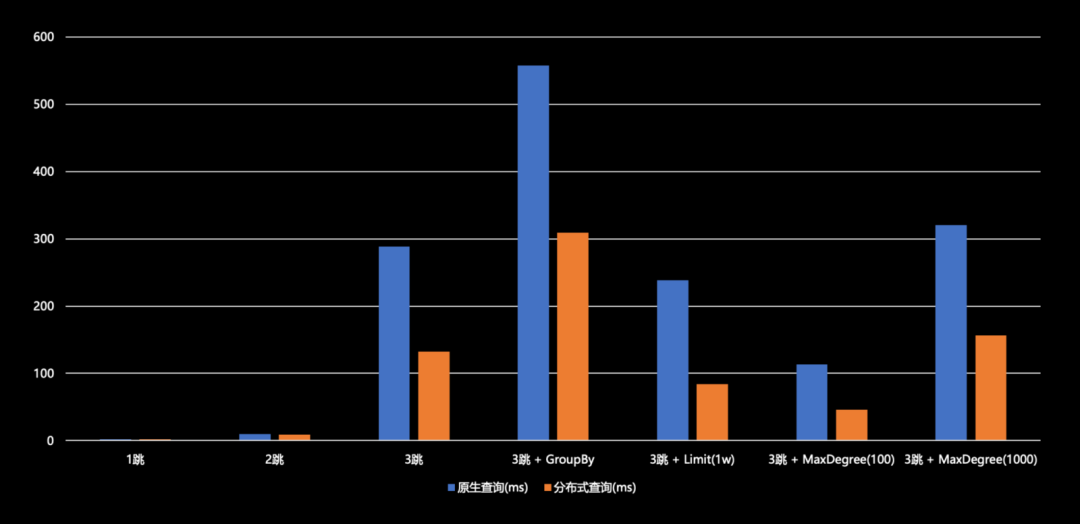
根据测试结果显示,在一跳和二跳情况下,原生查询和分布式查询性能基本相当,未出现负优化现象。从三跳起,分布式查询相较于原生查询能实现 50% 至 60% 的性能提升。例如,在 Max degree 场景下的分布式查询已将时延控制在 50 毫秒以内。在带有 Max degree 或 Limit 值的情况下,时延均在 200 毫秒以下。尽管数据集与实际业务数据集存在差异,但它们皆属于社交网络领域,因此仍具有一定的参考价值。
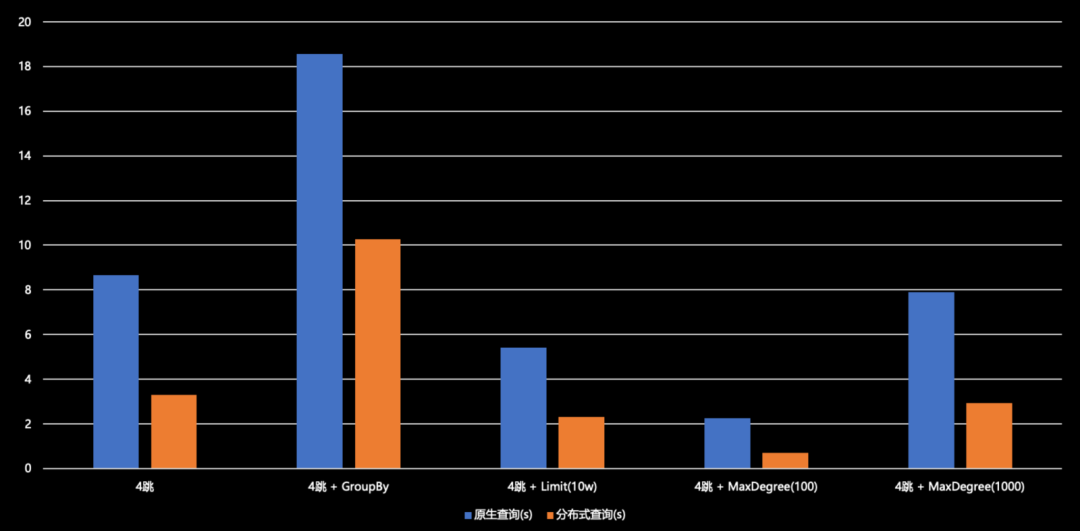
四跳查询,无论是原始查询还是分布式查询,其时延的规模基本上都在秒至十余秒的范围内。因为四跳查询涉及的数据量实在过于庞大,已达到百万级别,仅依赖分布式并行查询难以满足需求,因此需要采取其他策略。然而,即便如此,我们所提出的改进方案相较于原始查询模式仍能实现 50% 至 70% 的提升,效果还是很可观的。

在过去的较短时间内,我们基于 MPP 的理念,对 REDgraph 在分布式并行查询上进行了深入探索和实践。本方案能显著优化多跳查询的性能,并且对业务逻辑完全兼容,没有使用限制条件,属于框架级的通用优化。测试结果显示,时延降低了 50% 以上,满足在线业务场景的时延要求,验证方案的有效性。
目前,许多公司的图数据库产品在在线场景中仍使用两跳及以下的查询。这是因为多跳查询的时延无法满足在线业务的要需求,导致失去许多潜在的业务价值,也未能充分发挥图数据库的技术优势。随着小红书 DAU 的持续增长,业务数据规模朝着万亿级规模递增,业务上使用替代方案的瓶颈会逐渐展露。我们计划在今年上半年完成开发工作,并在下半年开始将这套新架构逐步应用于相关业务场景。
本方案虽然针对的是图数据库,但其探索实践对公司其他数据库产品同样具有重要的参考价值。例如,REDtable 在处理用户请求时,经常需要应对复杂或计算量大的查询,以往会建议用户修改代码来适应这些情况。现在,我们可以借鉴本方案,为这些「具有重查询需求」产品打造高性能执行框架,以增强自身的数据处理能力。
我们将继续提升 REDgraph 的多跳查询能力,并将其和 REDtao 融合,打造成一个统一的数据库产品,赋能更多业务场景。我们诚邀对技术有极致追求,志同道合的同学一起加入团队,共同推动图数据技术的发展。

-
再兴
小红书基础架构存储组工程师,负责自研分布式表格存储 REDtable(NewSQL),参与分布式图数据库 REDgraph 的研发。
-
敬德
小红书基础架构存储组工程师,负责自研图存储系统 REDtao 和分布式图数据库 REDgraph。
-
刘备
小红书基础架构存储组负责人,负责 REDkv / Redis / REDtao / REDtable / REDgraph / MySQL 的整体架构和技术演进。

基础架构 - 存储岗位
工作职责:
-
打造优秀的分布式 KV 存储系统、分布式缓存、图数据库、表格存储,为公司海量数据和大规模业务系统提供可靠的基础设施;
-
解决线上系统的疑难问题, 能从业务问题中抽象出通用的解决方案, 并落地实现;
-
团队密切配合, 共同研究和使用业内各方向最新技术,共同推动公司技术演进。
任职资格:
-
有 C/C++ 开发经验,精通多线程编程,有高并发场景下的产品设计和实现;
-
掌握分布式系统基本原理,了解 Paxos 、Raft 等一致性协议原理及应用,熟悉 RocksDB 等单机存储引擎的使用及优化;
-
熟悉算法和数据结构,解决问题思路清晰,对问题有深入钻研的兴趣;
-
对系统设计有完美追求, 对编码保持热情。
加分项:
-
有 rocksdb 、redis 、tidb 、nebula 、Lindom 等 KV / 图 / 表格数据库使用和开发、优化经验优先;
-
对开源项目有深入学习或参与的优先。
欢迎感兴趣的朋友发送简历至: REDtech@xiaohongshu.com;
并抄送至: liubei@xiaohongshu.com、 ft_storage_team@xiaohongshu.com