本文字数:12168;估计阅读时间:31 分钟
审校:庄晓东(魏庄)
本文在公众号【ClickHouseInc】首发
Meetup活动
ClickHouse Shanghai User Group第1届 Meetup 讲师招募中,欢迎讲师在文末扫码报名!

发布概要
本次ClickHouse 24.5版本包含了19个新功能🎁、20项性能优化🛷、68个bug修复🐛
新贡献者
一如既往,我们对 24.5 版本的所有新贡献者表示特别欢迎!ClickHouse 的受欢迎程度在很大程度上归功于社区的贡献。看到这个社区不断壮大,总是让人感到谦卑。
以下是新贡献者的名字:
Alex Katsman, Alexey Petrunyaka, Ali, Caio Ricciuti, Danila Puzov, Evgeniy Leko, Francisco Javier Jurado Moreno, Gabriel Martinez, Grégoire Pineau, KenL, Leticia Webb, Mattias Naarttijärvi, Maxim Alexeev, Michael Stetsyuk, Pazitiff9, Sariel, TTPO100AJIEX, Tomer Shafir, Vinay Suryadevara, Volodya, Volodya Giro, Volodyachan, Xiaofei Hu, ZhiHong Zhang, Zimu Li, anonymous, joe09@foxmail.com, p1rattttt, pet74alex, qiangxuhui, sarielwxm, v01dxyz, vinay92-ch, woodlzm, zhou, zzyReal666
Dynamic 数据类型
由 Pavel Kruglov 贡献
本次发布引入了一种新的实验性数据类型,用于半结构化数据。Dynamic 数据类型类似于版本 24.1 中引入的 Variant 数据类型,但你无需预先指定接受的数据类型。
例如,如果我们想允许 String、UInt64 和 Array(String) 值,我们需要定义一个 Variant(String, UInt64, Array(String)) 列类型。而对于 Dynamic 数据类型,只需定义为 Dynamic,如果需要,还可以添加任何其他类型的值。
如果你想使用这种数据类型,你需要设置以下配置参数:
SET allow_experimental_dynamic_type = 1;假设我们有一个名为 sensors.json 的文件,里面包含传感器读数。由于读数收集得不一致,这意味着我们有混合类型的值。
{"sensor_id": 1, "reading_time": "2024-06-05 12:00:00", "reading": 23.5}
{"sensor_id": 2, "reading_time": "2024-06-05 12:05:00", "reading": "OK"}
{"sensor_id": 3, "reading_time": "2024-06-05 12:10:00", "reading": 100}
{"sensor_id": 4, "reading_time": "2024-06-05 12:15:00", "reading": "62F"}
{"sensor_id": 5, "reading_time": "2024-06-05 12:20:00", "reading": 45.7}
{"sensor_id": 6, "reading_time": "2024-06-05 12:25:00", "reading": "ERROR"}
{"sensor_id": 7, "reading_time": "2024-06-05 12:30:00", "reading": "22.5C"}这是 Dynamic 类型的一个很好的用例,所以让我们创建一个表:
CREATE TABLE sensor_readings (
sensor_id UInt32,
reading_time DateTime,
reading Dynamic
) ENGINE = MergeTree()
ORDER BY (sensor_id, reading_time);现在,让我们运行下面导入数据的语句:
INSERT INTO sensor_readings
select * FROM 'sensors.json';接下来,让我们查询表,返回所有列,以及存储在 reading 列中的值的具体类型:
SELECT
sensor_id,
reading_time,
reading,
dynamicType(reading) AS type
FROM sensor_readings
Query id: eb6bf220-1c08-42d5-8e9d-1f77247897c3
┌─sensor_id─┬────────reading_time─┬─reading─┬─type────┐
1. │ 1 │ 2024-06-05 12:00:00 │ 23.5 │ Float64 │
2. │ 2 │ 2024-06-05 12:05:00 │ OK │ String │
3. │ 3 │ 2024-06-05 12:10:00 │ 100 │ Int64 │
4. │ 4 │ 2024-06-05 12:15:00 │ 62F │ String │
5. │ 5 │ 2024-06-05 12:20:00 │ 45.7 │ Float64 │
6. │ 6 │ 2024-06-05 12:25:00 │ ERROR │ String │
7. │ 7 │ 2024-06-05 12:30:00 │ 22.5C │ String │
└───────────┴─────────────────────┴─────────┴─────────┘如果我们只想检索使用特定类型的行,我们可以使用 dynamicElement 函数或等效的 dot 语法:
SELECT
sensor_id, reading_time,
dynamicElement(reading, 'Float64') AS f1,
reading.Float64 AS f2,
dynamicElement(reading, 'Int64') AS f3,
reading.Int64 AS f4
FROM sensor_readings;
Query id: add6fbca-6dcd-4413-9f1f-0566c94c1aab
┌─sensor_id─┬────────reading_time─┬───f1─┬───f2─┬───f3─┬───f4─┐
1. │ 1 │ 2024-06-05 12:00:00 │ 23.5 │ 23.5 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │
2. │ 2 │ 2024-06-05 12:05:00 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │
3. │ 3 │ 2024-06-05 12:10:00 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 100 │ 100 │
4. │ 4 │ 2024-06-05 12:15:00 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │
5. │ 5 │ 2024-06-05 12:20:00 │ 45.7 │ 45.7 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │
6. │ 6 │ 2024-06-05 12:25:00 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │
7. │ 7 │ 2024-06-05 12:30:00 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │
└───────────┴─────────────────────┴──────┴──────┴──────┴──────┘如果我们想计算 reading 列在类型为 Int64 或 Float64 时的平均值,我们可以编写以下查询:
SELECT avg(assumeNotNull(reading.Int64) + assumeNotNull(reading.Float64)) AS avg
FROM sensor_readings
WHERE dynamicType(reading) != 'String'
Query id: bb3fd8a6-07b3-4384-bd82-7515b7a1706f
┌──avg─┐
1. │ 56.4 │
└──────┘Dynamic 类型是将半结构化列添加到 ClickHouse 的一个长期项目的一部分。
从 S3 存档读取数据
由 Dan Ivanik 贡献
从 23.8 版本开始,只要存档文件在本地文件系统中,就可以读取存档文件(例如 zip/tar)中的数据。在 24.5 版本中,该功能扩展到了存储在 S3 上的存档文件。
让我们通过查询一些包含 CSV 文件的 ZIP 文件来看看它是如何工作的。我们先编写一个查询,列出嵌入的 CSV 文件:
SELECT _path
FROM s3('s3://umbrella-static/top-1m-2024-01-*.csv.zip :: *.csv', One)
ORDER BY _path ASC
Query id: 07de510c-229f-4223-aeb9-b2cd36224228
┌─_path─────────────────────────────────────────────────┐
1. │ umbrella-static/top-1m-2024-01-01.csv.zip::top-1m.csv │
2. │ umbrella-static/top-1m-2024-01-02.csv.zip::top-1m.csv │
3. │ umbrella-static/top-1m-2024-01-03.csv.zip::top-1m.csv │
4. │ umbrella-static/top-1m-2024-01-04.csv.zip::top-1m.csv │
5. │ umbrella-static/top-1m-2024-01-05.csv.zip::top-1m.csv │
6. │ umbrella-static/top-1m-2024-01-06.csv.zip::top-1m.csv │
7. │ umbrella-static/top-1m-2024-01-07.csv.zip::top-1m.csv │
8. │ umbrella-static/top-1m-2024-01-08.csv.zip::top-1m.csv │
9. │ umbrella-static/top-1m-2024-01-09.csv.zip::top-1m.csv │
10. │ umbrella-static/top-1m-2024-01-10.csv.zip::top-1m.csv │
11. │ umbrella-static/top-1m-2024-01-11.csv.zip::top-1m.csv │
12. │ umbrella-static/top-1m-2024-01-12.csv.zip::top-1m.csv │
13. │ umbrella-static/top-1m-2024-01-13.csv.zip::top-1m.csv │
14. │ umbrella-static/top-1m-2024-01-14.csv.zip::top-1m.csv │
15. │ umbrella-static/top-1m-2024-01-15.csv.zip::top-1m.csv │
16. │ umbrella-static/top-1m-2024-01-16.csv.zip::top-1m.csv │
17. │ umbrella-static/top-1m-2024-01-17.csv.zip::top-1m.csv │
18. │ umbrella-static/top-1m-2024-01-18.csv.zip::top-1m.csv │
19. │ umbrella-static/top-1m-2024-01-19.csv.zip::top-1m.csv │
20. │ umbrella-static/top-1m-2024-01-20.csv.zip::top-1m.csv │
21. │ umbrella-static/top-1m-2024-01-21.csv.zip::top-1m.csv │
22. │ umbrella-static/top-1m-2024-01-22.csv.zip::top-1m.csv │
23. │ umbrella-static/top-1m-2024-01-23.csv.zip::top-1m.csv │
24. │ umbrella-static/top-1m-2024-01-24.csv.zip::top-1m.csv │
25. │ umbrella-static/top-1m-2024-01-25.csv.zip::top-1m.csv │
26. │ umbrella-static/top-1m-2024-01-26.csv.zip::top-1m.csv │
27. │ umbrella-static/top-1m-2024-01-27.csv.zip::top-1m.csv │
28. │ umbrella-static/top-1m-2024-01-28.csv.zip::top-1m.csv │
29. │ umbrella-static/top-1m-2024-01-29.csv.zip::top-1m.csv │
30. │ umbrella-static/top-1m-2024-01-30.csv.zip::top-1m.csv │
31. │ umbrella-static/top-1m-2024-01-31.csv.zip::top-1m.csv │
└───────────────────────────────────────────────────────┘因此,我们有 31 个文件可以使用。接下来,让我们计算这些文件中共有多少行数据:
SELECT
_path,
count()
FROM s3('s3://umbrella-static/top-1m-2024-01-*.csv.zip :: *.csv', CSV)
GROUP BY _path
Query id: 07de510c-229f-4223-aeb9-b2cd36224228
┌─_path─────────────────────────────────────────────────┬─count()─┐
1. │ umbrella-static/top-1m-2024-01-21.csv.zip::top-1m.csv │ 1000000 │
2. │ umbrella-static/top-1m-2024-01-07.csv.zip::top-1m.csv │ 1000000 │
3. │ umbrella-static/top-1m-2024-01-30.csv.zip::top-1m.csv │ 1000000 │
4. │ umbrella-static/top-1m-2024-01-16.csv.zip::top-1m.csv │ 1000000 │
5. │ umbrella-static/top-1m-2024-01-10.csv.zip::top-1m.csv │ 1000000 │
6. │ umbrella-static/top-1m-2024-01-27.csv.zip::top-1m.csv │ 1000000 │
7. │ umbrella-static/top-1m-2024-01-01.csv.zip::top-1m.csv │ 1000000 │
8. │ umbrella-static/top-1m-2024-01-29.csv.zip::top-1m.csv │ 1000000 │
9. │ umbrella-static/top-1m-2024-01-13.csv.zip::top-1m.csv │ 1000000 │
10. │ umbrella-static/top-1m-2024-01-24.csv.zip::top-1m.csv │ 1000000 │
11. │ umbrella-static/top-1m-2024-01-02.csv.zip::top-1m.csv │ 1000000 │
12. │ umbrella-static/top-1m-2024-01-22.csv.zip::top-1m.csv │ 1000000 │
13. │ umbrella-static/top-1m-2024-01-18.csv.zip::top-1m.csv │ 1000000 │
14. │ umbrella-static/top-1m-2024-01-04.csv.zip::top-1m.csv │ 1000001 │
15. │ umbrella-static/top-1m-2024-01-15.csv.zip::top-1m.csv │ 1000000 │
16. │ umbrella-static/top-1m-2024-01-09.csv.zip::top-1m.csv │ 1000000 │
17. │ umbrella-static/top-1m-2024-01-06.csv.zip::top-1m.csv │ 1000000 │
18. │ umbrella-static/top-1m-2024-01-20.csv.zip::top-1m.csv │ 1000000 │
19. │ umbrella-static/top-1m-2024-01-17.csv.zip::top-1m.csv │ 1000000 │
20. │ umbrella-static/top-1m-2024-01-31.csv.zip::top-1m.csv │ 1000000 │
21. │ umbrella-static/top-1m-2024-01-11.csv.zip::top-1m.csv │ 1000000 │
22. │ umbrella-static/top-1m-2024-01-26.csv.zip::top-1m.csv │ 1000000 │
23. │ umbrella-static/top-1m-2024-01-12.csv.zip::top-1m.csv │ 1000000 │
24. │ umbrella-static/top-1m-2024-01-28.csv.zip::top-1m.csv │ 1000000 │
25. │ umbrella-static/top-1m-2024-01-03.csv.zip::top-1m.csv │ 1000001 │
26. │ umbrella-static/top-1m-2024-01-25.csv.zip::top-1m.csv │ 1000000 │
27. │ umbrella-static/top-1m-2024-01-05.csv.zip::top-1m.csv │ 1000000 │
28. │ umbrella-static/top-1m-2024-01-19.csv.zip::top-1m.csv │ 1000000 │
29. │ umbrella-static/top-1m-2024-01-23.csv.zip::top-1m.csv │ 1000000 │
30. │ umbrella-static/top-1m-2024-01-08.csv.zip::top-1m.csv │ 1000000 │
31. │ umbrella-static/top-1m-2024-01-14.csv.zip::top-1m.csv │ 1000000 │
└───────────────────────────────────────────────────────┴─────────┘每个文件大约有 100 万行数据。让我们来看一些行数据。我们可以使用 DESCRIBE 子句来了解数据的结构:
DESCRIBE TABLE s3('s3://umbrella-static/top-1m-2024-01-*.csv.zip :: *.csv', CSV)
SETTINGS describe_compact_output = 1
Query id: d5afed03-6c51-40f4-b457-1065479ef1a8
┌─name─┬─type─────────────┐
1. │ c1 │ Nullable(Int64) │
2. │ c2 │ Nullable(String) │
└──────┴──────────────────┘最后,让我们查看其中的几行数据:
SELECT *
FROM s3('s3://umbrella-static/top-1m-2024-01-*.csv.zip :: *.csv', CSV)
LIMIT 5
Query id: bd0d9bd9-19cb-4b2e-9f63-6b8ffaca85b1
┌─c1─┬─c2────────────────────────┐
1. │ 1 │ google.com │
2. │ 2 │ microsoft.com │
3. │ 3 │ data.microsoft.com │
4. │ 4 │ events.data.microsoft.com │
5. │ 5 │ netflix.com │
└────┴───────────────────────────┘
CROSS JOIN 改进
由 Maksim Alekseev 贡献
在上一个版本中,已经带来了显著的 JOIN 性能改进。从现在开始,您将会在每个 ClickHouse 版本中看到 JOIN 改进。🚀
在这个版本中,我们专注于改进 CROSS JOIN 的内存使用。
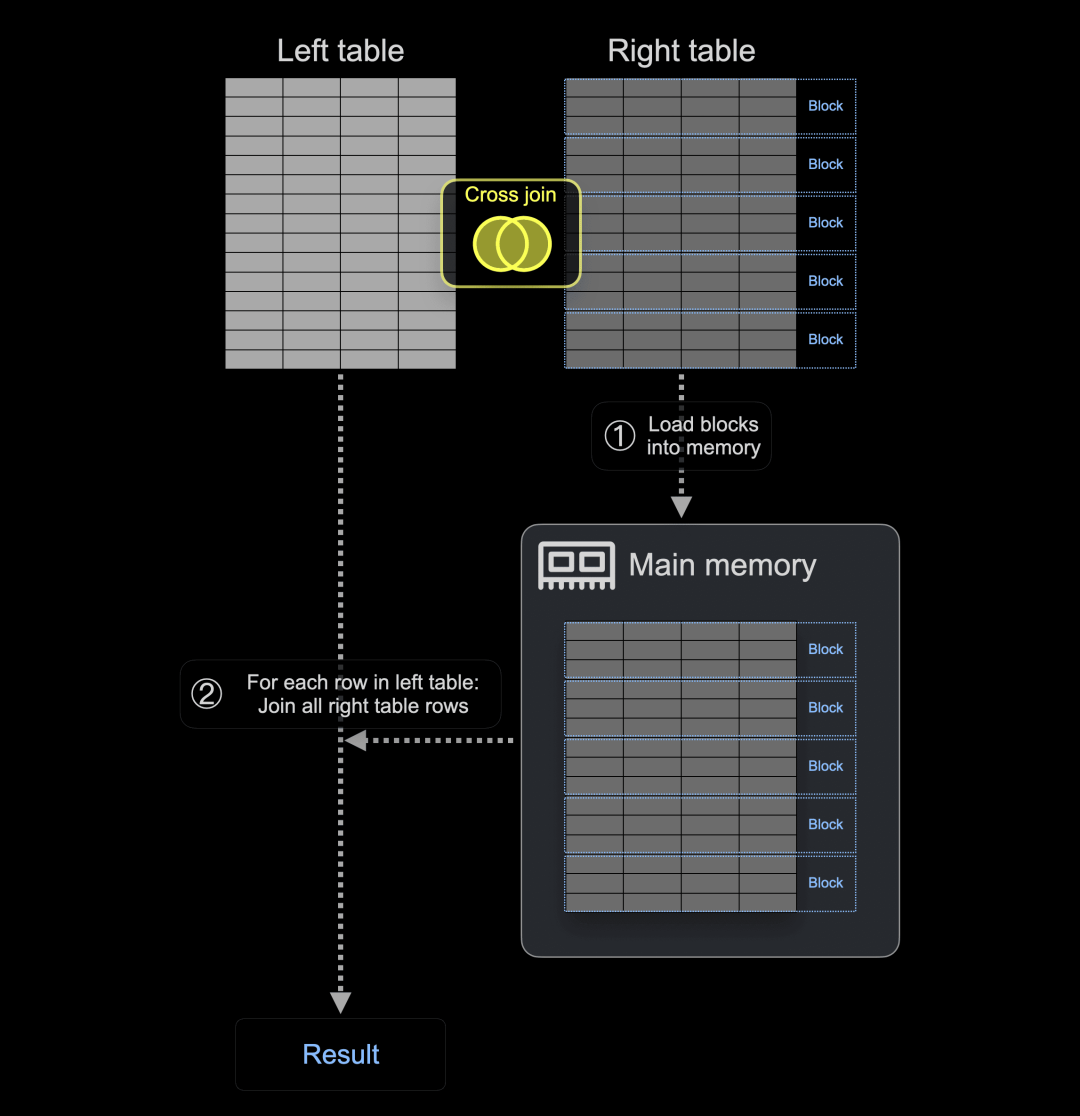
作为提醒,CROSS JOIN 在不考虑连接键的情况下产生两个表的笛卡尔积。这意味着左表的每一行都与右表的每一行组合。
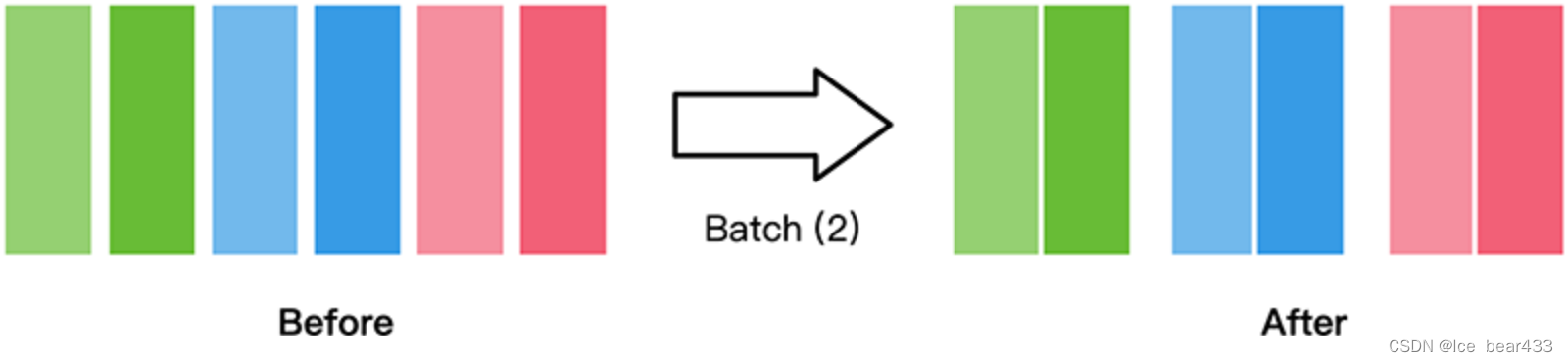
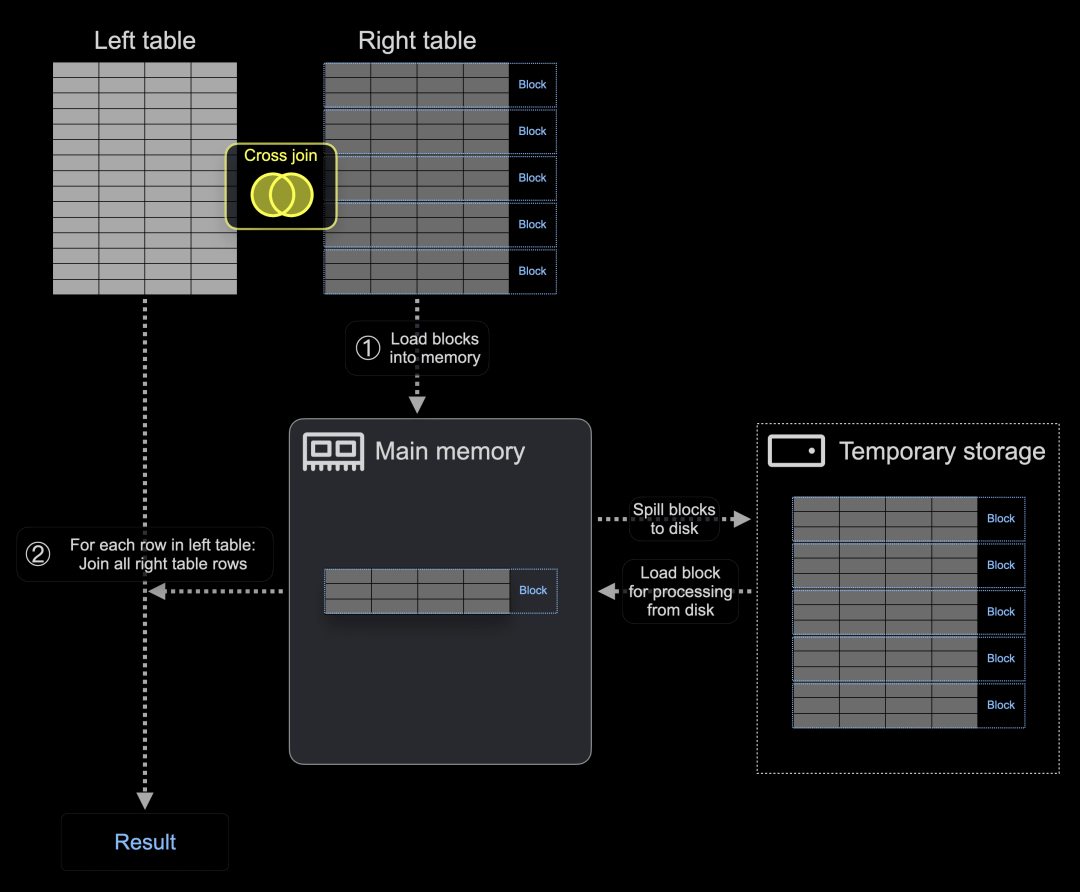
因此,CROSS JOIN 的实现不使用哈希表。相反,① ClickHouse 将右表的所有块加载到主内存中,然后,② 对于左表中的每一行,所有右表行都被连接:
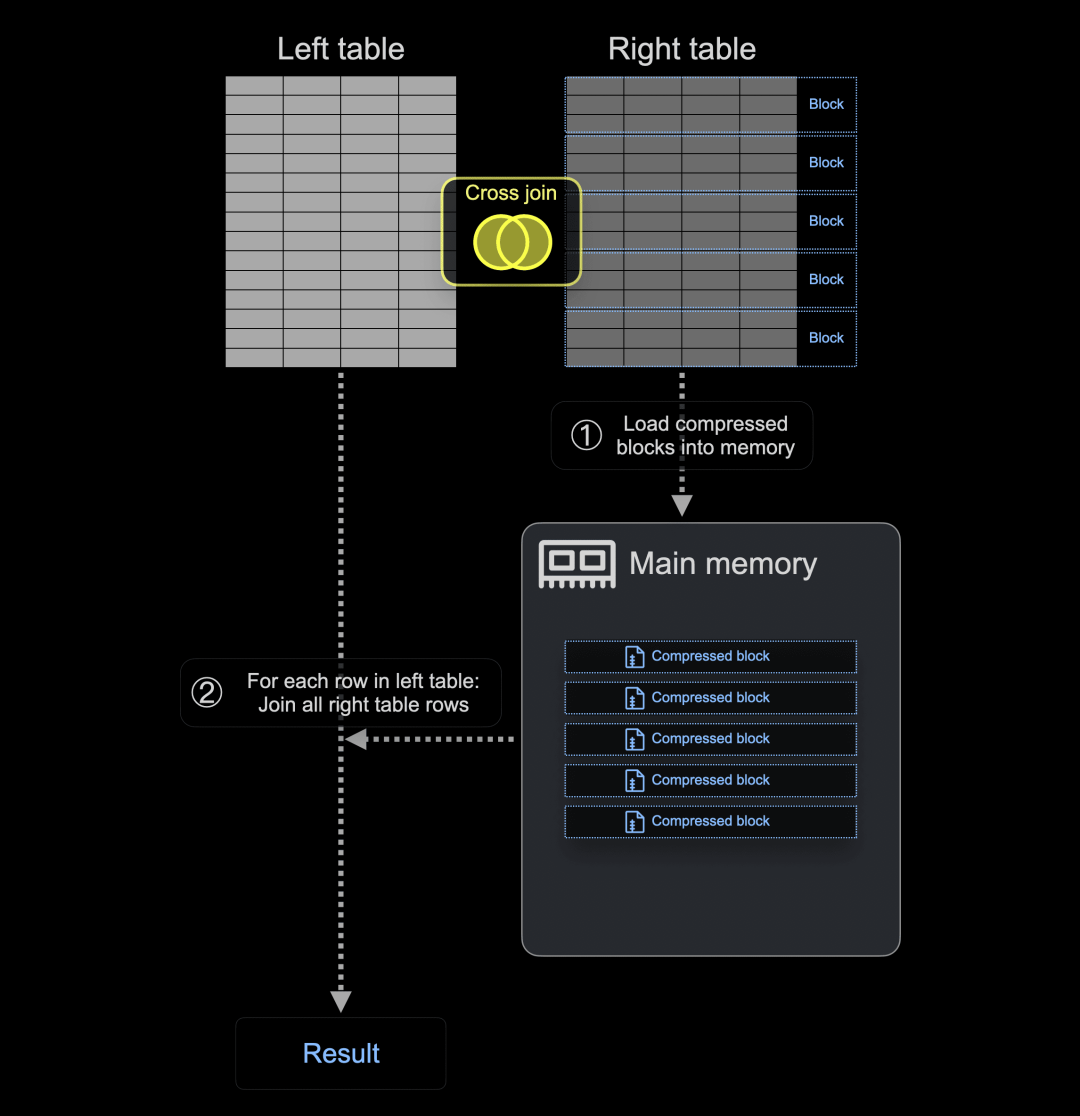
现在,在 ClickHouse 24.5 中,如果右表的块不适合内存,它们可以选择以压缩(LZ4)格式加载到主内存中,或者临时写入磁盘。
下图显示了基于两个新阈值设置 - cross_join_min_rows_to_compress 和 cross_join_min_bytes_to_compress - ClickHouse 在执行 CROSS JOIN 之前将压缩(LZ4)的右表块加载到主内存中:
为了演示这一点,我们将从公共 PyPI 下载统计中加载 10 亿行数据到 ClickHouse 24.4 和 24.5 中的一个表中:
CREATE TABLE pypi_1b
(
`timestamp` DateTime,
`country_code` LowCardinality(String),
`url` String,
`project` String
)
ORDER BY (country_code, project, url, timestamp);
INSERT INTO pypi_1b
SELEC timestamp, country_code, url, project
FROM s3('https://storage.googleapis.com/clickhouse_public_datasets/pypi/file_downloads/sample/2023/{0..61}-*.parquet');现在,我们使用 ClickHouse 24.4 运行一个 CROSS JOIN。请注意,我们使用一个包含一行的临时表作为左表,因为我们只对将右表行加载到主内存中的内存消耗感兴趣:
SELECT
country_code,
project
FROM
(
SELECT 1
) AS L, pypi_1b AS R
ORDER BY (country_code, project) DESC
LIMIT 1000
FORMAT Null;
0 rows in set. Elapsed: 59.186 sec. Processed 1.01 billion rows, 20.09 GB (17.11 million rows/s., 339.42 MB/s.)
Peak memory usage: 51.77 GiB.ClickHouse 在运行这个 CROSS JOIN 时使用了 51.77 GiB 的主内存。
我们在 ClickHouse 24.5 中运行相同的 CROSS JOIN,但禁用了压缩(通过将压缩阈值设置为 0):
SELECT
country_code,
project
FROM
(
SELECT 1
) AS L, pypi_1b AS R
ORDER BY (country_code, project) DESC
LIMIT 1000
FORMAT Null
SETTINGS
cross_join_min_bytes_to_compress = 0,
cross_join_min_rows_to_compress = 0;
0 rows in set. Elapsed: 39.419 sec. Processed 1.01 billion rows, 20.09 GB (25.69 million rows/s., 509.63 MB/s.)
Peak memory usage: 19.06 GiB.如您所见,在 24.5 版本中,即使没有压缩右表块,CROSS JOIN 的内存使用也得到了优化:ClickHouse 使用了 19.06 GiB 的主内存,而不是上面的查询中使用的 51.77 GiB。此外,CROSS JOIN 比前一个版本快了 20 秒。
最后,我们在启用了压缩的情况下(默认情况下)使用 ClickHouse 24.5 运行示例 CROSS JOIN:
SELECT
country_code,
project
FROM
(
SELECT 1
) AS L, pypi_1b AS R
ORDER BY (country_code, project) DESC
LIMIT 1000
FORMAT Null;
0 rows in set. Elapsed: 69.311 sec. Processed 1.01 billion rows, 20.09 GB (14.61 million rows/s., 289.84 MB/s.)
Peak memory usage: 5.36 GiB.因为右表的行数或数据大小超过了 cross_join_min_rows_to_compress 或 cross_join_min_bytes_to_compress 阈值,ClickHouse 将右表的块以 LZ4 压缩格式加载到内存中,结果使用了 5.36 GiB 的内存,这比在 24.4 中运行 CROSS JOIN 时减少了大约 10 倍的内存使用。请注意,压缩开销增加了查询的运行时间。
此外,自这个版本起,如果右表块的大小超过 max_bytes_in_join 或 max_rows_in_join 阈值,那么 ClickHouse 会将右表块从内存中溢出到磁盘:
我们通过在启用测试级日志记录级别的情况下运行示例 CROSS JOIN 来演示这一点。请注意,我们禁用了压缩,并使用了一个有限的 max_rows_in_join 值,以强制将右表块溢出到磁盘:
./clickhouse client --send_logs_level=test --query "
SELECT
country_code,
project
FROM
(
SELECT 1
) AS L, pypi_1b AS R
ORDER BY (country_code, project) DESC
LIMIT 1000
FORMAT Null
SETTINGS
cross_join_min_rows_to_compress=0,
cross_join_min_bytes_to_compress=0,
max_bytes_in_join=0,
max_rows_in_join=10_000;
" 2> log.txt当我们检查生成的 log.txt 文件时,我们可以看到如下条目:
TemporaryFileStream: Writing to temporary file ./tmp/tmpe8c8a301-ee67-40c4-af9a-db8e9c170d0c以及总体内存使用情况和运行时间:
Peak memory usage (for query): 300.52 MiB.
Processed in 58.823 sec.我们可以看到,此查询的内存使用量非常低,仅为 300.52 MiB,因为在 CROSS JOIN 处理过程中,每时每刻内存中只保留了右表块的一个子集。
非等值 JOIN
由 Lgbo-USTC 提供
在 24.5 版本之前,ClickHouse 只允许在 JOIN 的 ON 子句中使用等值条件。
例如,当我们在 ClickHouse 24.4 中运行这个 JOIN 查询时,会得到一个异常:
SELECT L.*, R.*
FROM pypi_1b AS L INNER JOIN pypi_1b AS R
ON (L.country_code = R.country_code) AND (L.timestamp < R.timestamp)
LIMIT 10
FORMAT Null;
Received exception from server (version 24.4.1): … INVALID_JOIN_ON_EXPRESSION现在,在 24.5 版本中,ClickHouse 对 ON 子句中的非等值条件提供了实验性支持。请注意,目前我们需要启用 allow_experimental_join_condition 设置:
SELECT
L.*,
R.*
FROM pypi_1b AS L
INNER JOIN pypi_1b AS R ON
L.country_code = R.country_code AND
L.timestamp < R.timestamp
LIMIT 10
FORMAT Null
SETTINGS
allow_experimental_join_condition = 1;敬请期待即将发布的更多 JOIN 改进!
这就是 24.5 版本的全部内容。我们非常欢迎您参加 6 月 27 日的 24.6 版本发布电话会议。请务必注册,以便获得 Zoom 网络研讨会的所有详细信息【https://clickhouse.com/company/events/v24-6-community-release-call】。
Meetup 活动讲师招募
我们正为上海活动招募讲师,如果你有独特的技术见解、实践经验或 ClickHouse 使用故事,非常欢迎你加入我们,成为这次活动的讲师,与大家分享你的经验。
点击此处或扫描下方二维码,立刻报名成为讲师!

征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com

联系我们
手机号:13910395701
邮箱:Tracy.Wang@clickhouse.com
满足您所有的在线分析列式数据库管理需求