做数据的同学经常听到一些数据相关的术语,常见的包括数据仓库,逻辑数据仓库,数据湖,数据湖仓/湖仓一体,数据网格 data mesh,数据编织 data fabric等.
笔者在这里回顾了下数据平台的发展史,也介绍和对比了下常见的概念,主要包括数据仓库,数据湖和数据湖仓,希望大家有所收获。
回顾数据平台发展历史,梳理数据平台变迁脉络,更全面准确地理解数据仓库数据湖和数据湖仓!
1 数据平台概述
所谓「数据平台,主要是指数据分析平台,其消费(分析)内部和外部其它系统生成的各种原始数据(比如券商柜台系统产生的各种交易流水数据,外部行情数据等),对这些数据进行各种分析挖掘以生成衍生数据,从而支持企业进行数据驱动的决策」:
数据分析平台既可以部署在本地,也可以部署在云端,其典型特征有:
- 数据分析平台,需要上游系统(内部或外部)提供原始数据;- 数据分析平台,会经过分析生成各种结果数据(衍生数据);
- 数据分析平台,生成的结果数据,一般主要服务于企业自身,支持企业进行数据驱动的决策,从而助力企业更好地经营:为顾客提供更好的服务,企业自身降本增效更好地运营,或发现新的商业洞察从而支持新的商业创新和新的业务增长点等(foster innovation);
- 数据分析平台,生成的结果数据,也可以服务于外部客户: 通过数据变现,为企业创造新的业务模式和利润增长点;(各种提供数据服务的公司)
- 数据分析平台,支持各种类型的数据分析应用,包括BI也包括AI;

数据(分析)平台,常见的相关术语有:数据仓库,数据湖,数据湖仓,数据中台,逻辑数仓 Logical data warehouse,数据编织 Data fabric,Data mesh 等:
- 数据仓库,数据湖,数据湖仓/湖仓一体:是数据平台主要的支撑载体,是当前使用最广泛的术语,其中数据湖仓也称湖仓一体,本质是数据湖的2.0版本;
- 国内也经常讲数据中台:数据中台在数据仓库数据湖数据湖仓的基础上,强调了将数据进行服务化API化,从而支持更快速敏捷地开发各种新型数据应用;
- 数据编织 Data fabric,数据网格 Data mesh:是随着企业云化迁移以及微服务架构兴起,逐渐流行起来的新的术语,在管理数据时更强调数据天然分布式的特性和数据产品的理念(数据是一种产品,来自不同服务由不同团队管理);
- 需要注意的是,数据仓库,数据湖与数据湖仓虽然有着明显的学术定义上的区别,但是在业界很多场景下我们并不严格区分三者;
本次分享,我们主要关注数据仓库数据湖和数据湖仓
2 数据平台发展史-从数据仓库数据湖到数据湖仓
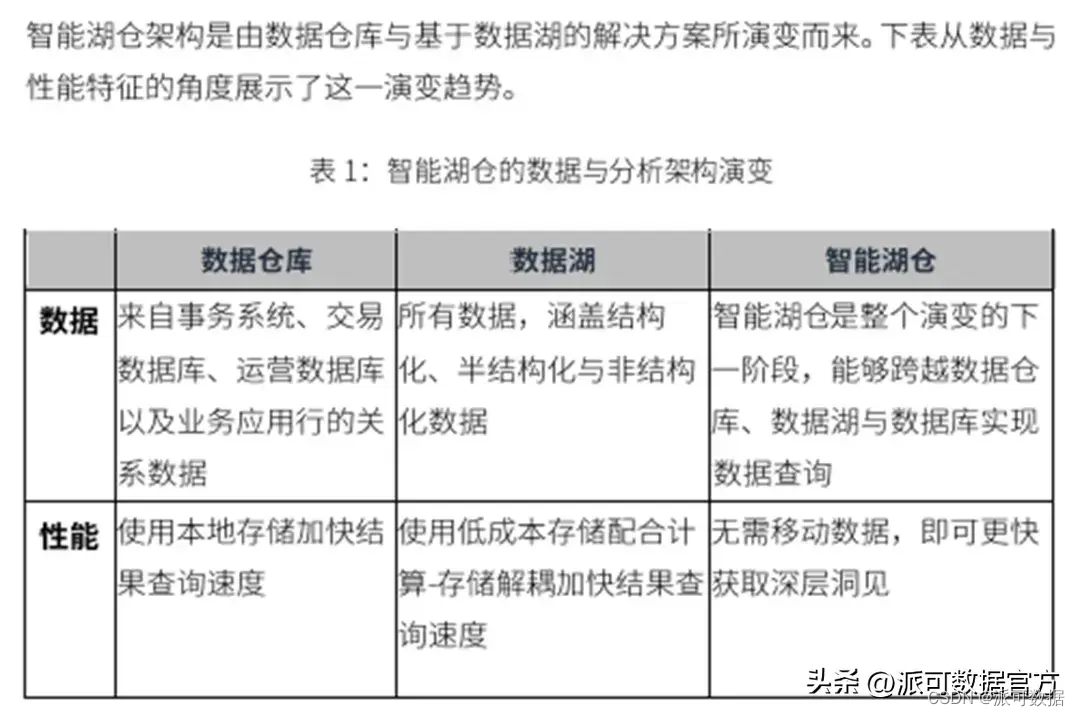
整个数据平台的发展史,其实可以用一句话简单概括下:「数据平台的发展,是随着企业信息化和数字化的逐渐推进,从数据库,数据仓库,数据湖到数据湖仓逐渐演进的」:
- 在企业信息化早期,建设了各种线上业务系统如 ERP/CRM/OA等,这些业务系统通过数据库沉淀了多种数据,其数据库一般采用的是 OLTP的关系型数据库;
- 随着信息技术的进一步发展,企业逐渐意识到数据具有价值,并可以通过各种分析方法挖掘其中的价值,支持企业的管理决策,于是逐渐有了数据仓库平台(数据仓库诞生于数据库时代);
- 随着大数据时代的到来,数据在种类和体量上都有了爆炸式的增长,数据的存储和分析处理技术也有了进一步发展,为更好地挖掘数据中的价值,出现了数据湖平台(数据湖脱胎于大数据时代,有着很强的开源和开放的基因);
- 随着企业向数字驱动进一步迈进,对数据的存储和分析处理有了更高的要求,出现了融合数据仓库和数据湖各自特点的新型数据平台,其实质是数据湖2.0,也被称为数据湖仓;
2.1 数据仓库
数据仓库(Data Warehouse),是由被誉为全球数据仓库之父的 W.H.Inmon 于1990年提出的,其相对学术的解释:「数据仓库是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化的(Time Variant)数据集合,用于支持管理决策和信息的全局共享」;
- 所谓主题:是指用户使用数据仓库进行决策时所关心的重点方面,如:收入、客户、销售渠道等;
- 所谓面向主题,是指数据仓库内的信息是按主题进行组织的,而不是像业务支撑系统那样是按照业务功能进行组织的;
- 所谓集成:是指数据仓库中的信息不是从各个业务系统中简单抽取出来的,而是经过一系列加工、整理和汇总的过程,因此数据仓库中的信息是关于整个企业的一致的全局信息。
- 所谓随时间变化:是指数据仓库内的信息并不只是反映企业当前的状态,而是记录了从过去某一时点到当前各个阶段的信息。通过这些信息,可以对企业的发展历程和未来趋势做出定量分析和预测;
- 之所以使用数据仓库而不是前台线上业务系统的OLTP数据库进行BI等数据分析,一个重要的原始是OLTP只能应对简单的关联查询,支撑基本的和日常的事务处理,不适用数据的多维度分析;而数仓底层一般是擅长多维分析的OLAP数据库(还有一个原因是数据分析属于后台系统,不能影响前台线上业务系统的性能)
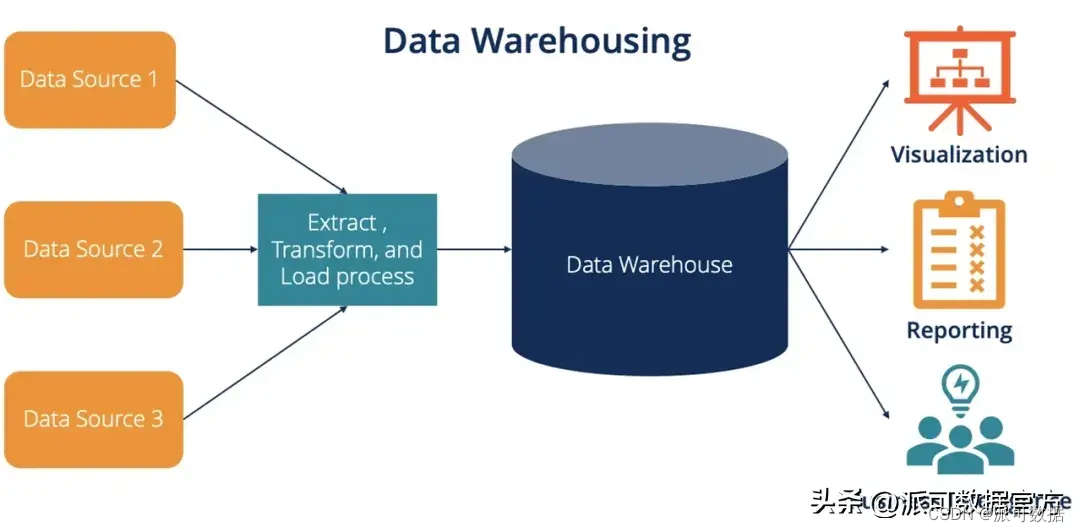
数据仓库一般具有以下特点:
- 数仓强调数据建模,需要根据领域知识按照分层建模理论,进行详细的模型设计;
- 数据由外部系统进入数仓时,需要经过清洗转化后加载进数据仓库,即 ETL;
- 数据需要ETL后进入数仓,本质是由于外部系统中的数据模型跟数仓中的数据模型是不同的(外部OLTP系统一般是按照范式设计的数据库中的表,而数仓一般是OLAP中反范式的大宽表);
- 数仓模型的建设一般耗时耗力,但数仓模型一旦创建完毕,相对来说不会轻易做出改变;
- ETL的本质是 SCHEMA ON WRITE,即数据进入数仓时经由 ETL 完成了清洗和转换,所以数仓中的数据质量较高;
- 数仓分层比较经典的有:ODS,DWD,DWS,ADS等;
- 数仓是商业智能BI的基础,主要基于建好的数仓模型,经过分析回答固定的已知问题,从而支撑BI的报表和大屏等;
- 数仓一般内置存储系统,且不对外直接暴露存储系统接口(不允许外部系统直接访问数仓底层存储系统中的数据比如文件),而是将数据抽象的表或视图的方式,通过提供数据进出的服务接口对外提供访问(最常见的数据访问方式是SQL,有的数仓对加载数据也提供了RESTFUL接口或专用的LOAD/COPY等命令);
- 数据仓库通过抽象数据访问接口/权限管理/数据本身,带来了一定的封闭性,但换取了更高的性能(无论是存储还是计算)、闭环的安全体系、数据治理的能力等,可以应对安全/合规等企业级要求;
- 数仓内置存储系统但不对外直接暴露存储系统接口,而是提供数据进出的服务接口,带来了以下优缺点:
- 数仓具有封闭性,只能使用数仓专用的分析引擎,一般不能对接三方其它引擎;
- 数仓具有封闭性,不同数仓之间的数据迁移相对较难;
- 数仓性能较好:数仓计算引擎对内置存储系统的数据存储格式有深入了解,存储和计算可以配合着做深度优化,提高数仓的性能;
- 数仓在数据治理上具有优势:有完善的元数据管理能力,完善的血缘体系等,可以对数据进行全生命周期的细粒度的治理;
关于数仓,有以下几点需要注意下:
- 传统的数仓,底层一般是基于数据库的,底层只能以表的形式存储结构化数据,如 GreenPlum,Teradata,Vertica等,成本相对较高;
- 传统的数仓,一般是存储计算耦合的架构,在横向扩展性和弹性能力上相对不足,能管理的数据量相对较小;
- 新兴的云数仓,底层一般是基于云上对象存储的,如 AWS Redshift、Google BigQuery、阿里云MaxCompute, Snowflake 等;
- 新兴的云数仓,一般是存算分离的架构,存储和计算可以独立进行扩展,有着很好的横向扩展性和弹性,可以管理大量数据;
2.2 数据湖
数据湖是大数据时代的产物,本身没有相对官方的概念,其最早是由 Pentaho 的创始人兼首席技术官James Dixon 与2010年10月提出的,其后不同厂商有所延伸和细化:
- AWS的定义相对简洁:数据湖是一个集中式存储库,允许以任意规模存储所有结构化和非结构化数据,可以按原样存储数据(无需先对数据进行结构化处理),并运行不同类型的分析 – 从控制面板和可视化到大数据处理、实时分析和机器学习,以指导做出更好的决策;
- 维基的定义:数据湖将数据以自然/原始格式存储在对象存储或文件系统中,数据湖通常把企业所有数据统一存储,包括源系统中的原始数据副本,传感器数据,社交媒体数据等,也包括转换后的数据,以用于支撑报表, 可视化, 高级数据分析和机器学习等。数据湖中的数据包括关系数据库的结构化数据(行与列)、半结构化的数据(CSV,日志,XML, JSON),非结构化数据 (电子邮件、文件、PDF)和 二进制数据(图像、音频、视频);
- Wiki: A data lake is a system or repository of data stored in its natural/raw format, usually object blobs or files. A data lake is usually a single store of data including raw copies of source system data, sensor data, social data etc., and transformed data used for tasks such as reporting, visualization, advanced analytics and machine learning);
- 数据湖是人工智能AI的基础,存储了企业内部各种原始数据,支持丰富的计算模型/范式,所以数据科学家和数据分析人员,可以采用各种统计分析,机器学习,深度学习等方法,对数据进行各种探索性分析挖掘,回答各种已知问题和未知问题,从而支撑各种AI场景;
数据湖为什么叫数据湖,而不叫数据河,数据海?一个贴切的解释是:
- “河”强调的是流动性,河终究是要流入大海的,“海纳百川”,这与企业级数据需要长期沉淀对应,因此叫“湖”比叫“河”要贴切;
- “海”是无边无界的,而“湖”是有边界的,这与企业级数据有边界向对应(这个边界就是企业/组织的业务边界),因此叫“湖”比叫“海”要贴切;
- “湖”天然是分层的,满足不同的生态系统要求,这与企业建设统一数据中心,存放管理数据的需求是一致的,“热”数据在上层,方便应用随时使用;温数据、冷数据位于数据中心不同的存储介质中,达到数据存储容量与成本的平衡;
- 还有一个有关的概念是“数据沼泽”:数据湖需要精细的数据治理,包括权限管理,一个缺乏管控、缺乏治理的数据湖最终会退化为“数据沼泽”,从而使应用无法有效访问数据,使存于其中的数据失去价值(数据湖中数据越多越需要数据治理);
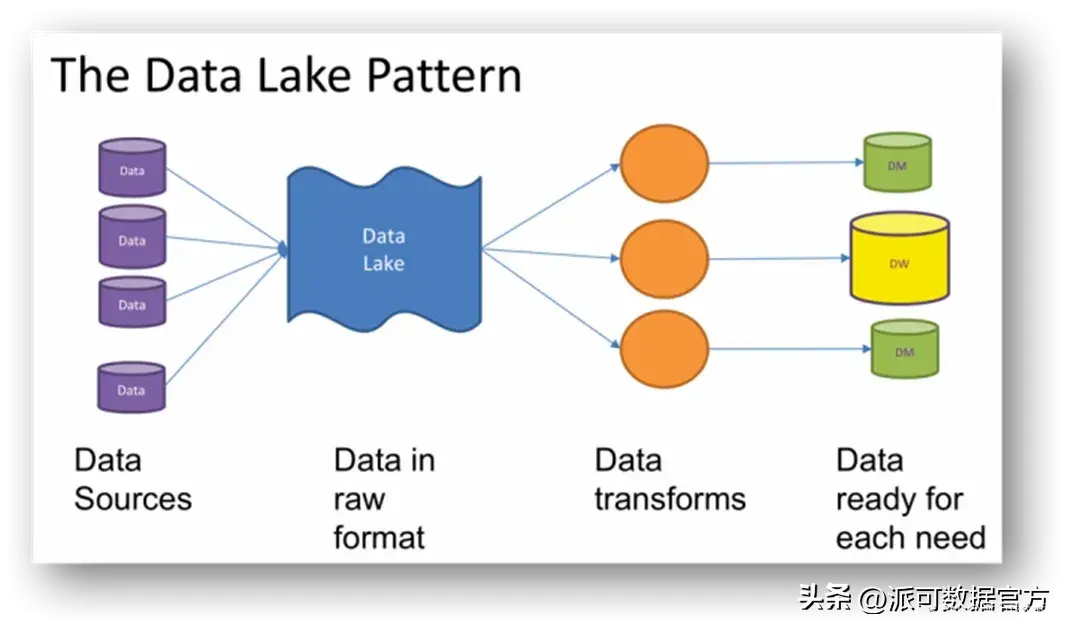
数据湖一般具有以下特点:
- 数据湖使用统一的存储系统,可以存储结构化数据(数据库的表),半结构化数据(日志,JSON,xml等),也可以存储非结构化数据(图像音视频等二级制格式);
- 数据由外部系统进入数据湖时,不需要经过清洗转化后再加载进数据湖(ETL),而是采用 ELT,直接进行抽取和加载;
- 数据湖中的数据,在后续需要针对具体场景进行分析时,才会对湖中已经存在的原始数据进行 transform 转化到特定的结构进而进行后续分析,即采用的是 schema on read 而不是 schema on write;
- 由于采用了 ELT 和 schema on read,所以数据湖落地初期不强调数据建模,不需要事先根据领域知识进行详细的模型设计,所以数据湖相对数据仓库,项目落地速度更快;
数据湖具有开放性,其开放性体现在以下几点:
- 数据湖具有开放性,体现在数据湖中的数据可以使用多种文件格式进行存储(如开源的 orc/parquet/avro等等);
- 数据湖具有开放性,体现在数据湖虽然内置了存储系统,但一般会对外开放底层存储系统的访问接口;(如可以直接访问HIVE底层表对应的HDFS/S3的文件);
- 数据湖具有开放性,也体现在数据湖中的数据可以使用多种分析引擎进行分析(本质还是因为数据湖底层存储层是开放的,所以可以支持 spark/presto/flink 等多种分析引擎);
数据湖开放性的特点,带来了以下优缺点:
- 通过底层存储系统的开放性,使得数据湖存储的数据结构可以是结构化的,可以是半结构化的,也可以是完全非结构化;
- 底层存储系统的开放性,使得上层可以对接多种分析引擎,各种引擎也可以根据自己针对的场景有针对性地进行各种性能优化;
- 但底层存储系统的开放性,也使得很多高阶的功能很难实现,例如细粒度(小于文件粒度)的权限管理和统一化的文件管理,所以数据湖中如何对数据进行全生命周期的细粒度的治理是一个难题(包括统一的完善的元数据管理和血缘体系等 );
数据湖与上云无关,底层存储可以采用文件系统也可以采用对象存储,常见的实现有:
- 自建开源 Hadoop 数据湖架构(最常见);
- 云上托管 Hadoop 数据湖架构(如阿里和AWS的EMR数据湖);
- 云上非 hadoop 数据湖,如 Azure 数据湖,阿里云OSS 数据湖,Alluxio 虚拟数据湖等(对象存储);
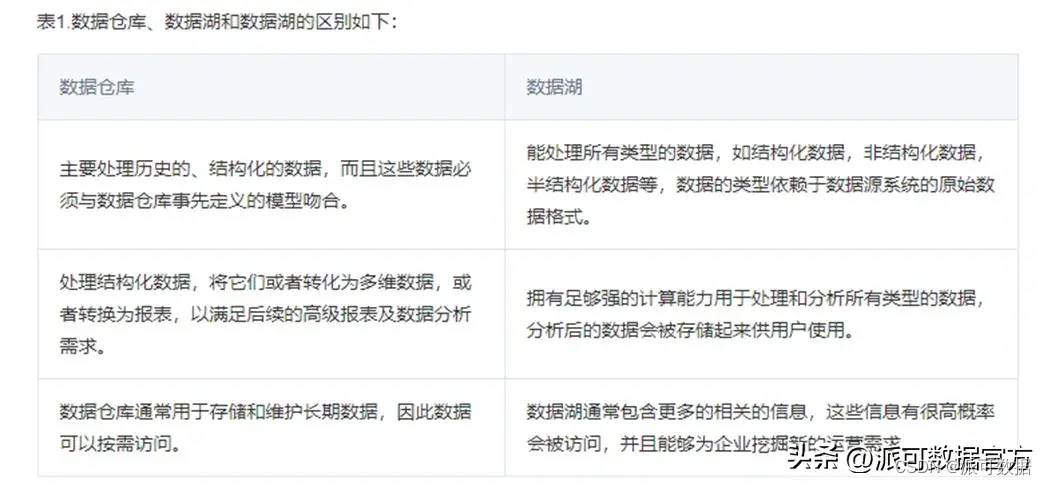
2.3 数据仓库 vs 数据湖
经过前面对数据仓库和数据湖的比较,我们可以看到,两者在设计上的根本分歧点是对包括存储系统访问、权限管理、建模要求等方面的把控:
- 数据仓库,更加关注的是数据使用效率、大规模下的数据管理、安全/合规这样的企业级需求;
- 数据仓库中,数据经过统一但开放的服务接口进入数据仓库,数据通常预先定义 schema,用户通过数据服务接口或者计算引擎访问分布式存储系统中的文件;
- 数据仓库中,通过抽象数据访问接口/权限管理/数据本身,换取了更高的性能(无论是存储还是计算)、闭环的安全体系、数据治理的能力等,这些能力对于企业长远的大数据使用都至关重要;
- 数据湖,通过开放底层文件存储,给数据入湖带来了最大的灵活性:进入数据湖的数据可以是结构化的,也可以是半结构化的,甚至可以是完全非结构化的原始日志。
- 数据湖,通过开放底层文件存储,给上层的引擎也带来了更多的灵活度:各种引擎可以根据自己针对的场景随意读写数据湖中存储的数据,而只需要遵循相当宽松的兼容性约定;
- 数据湖,开放底层文件存储允许文件系统直接访问,使得很多更高阶的功能很难实现:例如细粒度(小于文件粒度)的权限管理、统一化的文件管理,ACID事务管理等,读写接口升级也十分困难(需要完成每一个访问文件的引擎升级,才算升级完毕);
- 由于数据湖的上述特点,数据湖虽然容易落地,但随着湖中数据量的增多,一旦数据治理措施不善,数据湖容易退化为数据沼泽,数据质量低下,用户无法访问数据或不易找到需要的数据,整个数据湖的价值也就退化了;

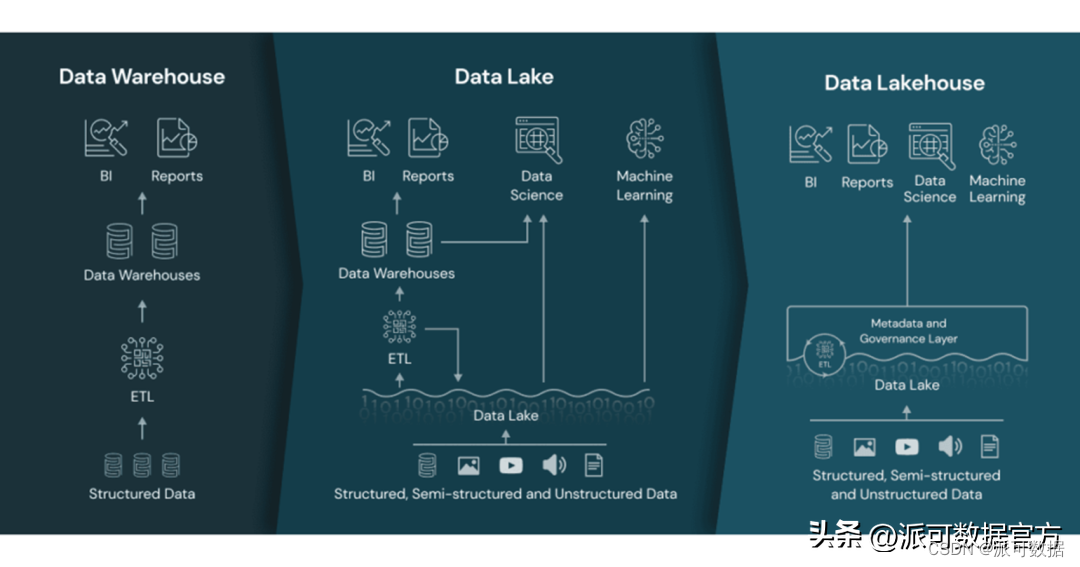
数据仓库和数据湖,各有自己的优缺点,前者主要支撑BI场景,后者主要支撑AI场景,两者并不是互斥的关系:「企业搭建数据平台时,既有BI需求也有AI需求,所以现阶段,很多数据平台是融合了数据仓库和数据湖的:使用数据湖泊作为底座,在数据湖基础上组建多个数据仓库,数据仓库支撑各种BI业务场景,数据湖泊的底座除了支撑各个数据仓库,也可以直接支撑机器学习和深度学习等AI场景;」
2.4 数据湖仓
上文讲到,企业搭建数据平台时,由于既有BI需求也有AI需求,所以现阶段,很多数据平台中融合搭建数据湖和数据仓库以应对BI和AI两大类数据分析场景,但是这样势必会造成资源的浪费,增加了数据成本。为解决数据平台中融合搭建数据仓库和数据湖造成的资源浪费问题,数据仓库和数据湖厂商都做了自己的尝试,给出了相应的解决方案:
- 数据仓库厂商,推出的方案是,在自身已有功能的基础上,开发各种连接器connector,然后以外表形式访问外部数据湖底层存储系统中的数据,从而扩展自己的功能;(如 GP/Doris 等都推出了访问HDFS数据湖的connector)
- 而数据湖厂商,推出的方案是,补齐短板,改进和增强自身功能,包括支持ACID事务,加强数据治理能力等,这种方案本质是数据湖2.0,业界倾向叫它湖仓一体或数据湖仓 lake house,以强调其整合了传统的data lake 和 data warehouse的能力;
笔者尝试使用如下一句话概括总结下数据湖仓:「数据湖仓是在数据湖的基本架构上,通过一系列以表格式 Table Format 为代表的新技术解决了数据湖泊的各种传统痛点,将数据仓库和数据湖泊功能融合在一起,使其具有了数据仓库在数据管理方面的各种优点,并直接支持 BI和AI的各种数据分析场景的新型架构」
数据湖仓最大的技术创新是,通过一系列以表格式 Table Format 为代表的新技术,为数据湖的基本架构带来了ACID事务支持,提供了对记录级别的增删改的支持,对多作业并发读写同一个表或同一个分区的的支持,从而支持了以下特性:
- 数据湖仓在数据湖的架构基础上融合了数仓式的数据管理能力:A lakehouse uses similar data structures and data management features as those in a data warehouse but instead runs them directly on data lakes,
- 数据湖仓同时直接支持BI和AI:A lakehouse allows traditional analytics, data science, and machine learning to coexist in the same system, all in an open format;
- 在数据湖仓lake house这个概念下,目前有 delta lake/hudi/iceberg 甚至 hive orc事务表这些框架来支持;
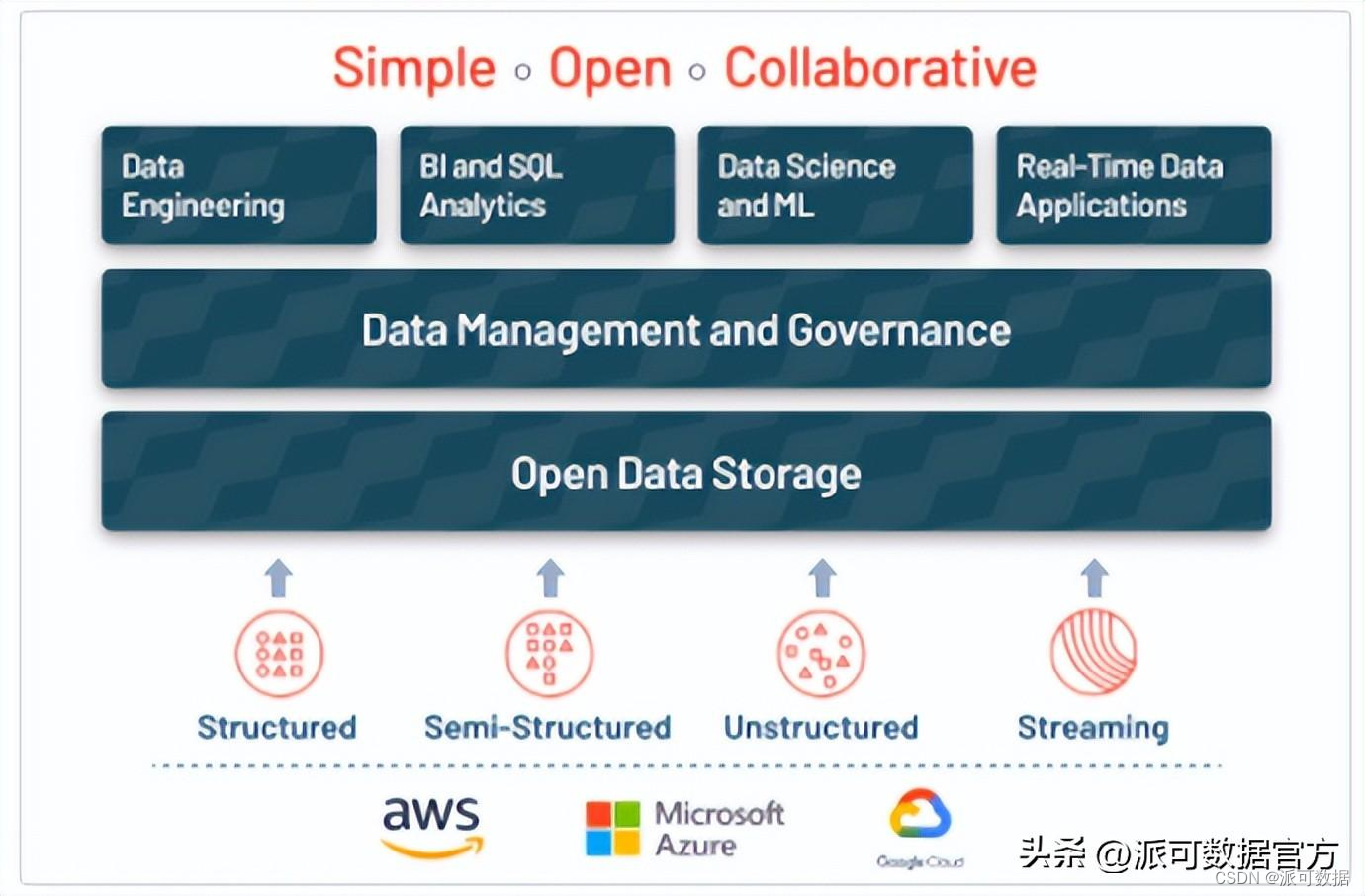
数据湖仓一般具有以下基本特征:
- 使用统一的存储引擎和开放的格式(文件格式和表格式);
- 对象存储优先;
- 支持多种分析引擎;
- 支持并发读写和事务的acid特性;
- 支持记录级别的增删改;
- 支持增量更新数据;数据湖仓通常也支持以下高级特性:
- 模式演化模式约束: schema evolution,schema enforecement
- 历史版本回溯: history
- 流式增量导入(流批一体存储)


3 数据湖仓典型框架的特性与架构
数据湖厂商,改进和增强了自身功能,包括支持ACID事务和加强数据治理能力等,融合了传统的data lake 和 data warehouse的特点,推出了数据湖2.0方案,该方案即湖仓一体或数据湖仓 lake house,在数据湖仓lake house这个概念下,目前最主流的是数据湖三剑客:delta lake/apache hudi/apache iceberg;
- Delta lake: Delta Lake是由 Apache Spark 背后的商业公司 Databricks 推出的一个致力于在数据湖之上构建湖仓一体架构的开源项目,Delta Lake 支持ACID事务,可扩展的元数据存储,在现有的数据湖(S3、ADLS、GCS、HDFS)之上实现流批数据处理的统一;
- Apache Hudi:Hudi 最初是由 Uber 的工程师为满足其内部数据分析的需求而设计的数据湖项目, 其设计目标正如其名,Hadoop Upserts Deletes and Incrementals(原为 Hadoop Upserts anD Incrementals),在开源的文件系统之上引入了数据库的表和事务的概念,支持高效的更新/删除、索引、流式写服务、数据合并、并发控制等功能特性。
- Apache Iceberg:Iceberg 最初是由 Netflix 为解决使用 HIVE 构建数据湖仓时的诸多缺陷而研发的,最终演化成 Apache 下一个高度抽象通用的开源数据湖方案,用于处理海量分析数据集的开放表格式,支持 Spark, Trino, PrestoDB, Flink and Hive等计算引擎,它具有高度的抽象和优雅的设计;
三大数据湖仓框架在官网对自身的介绍如下:
- Delta Lake is an open-source storage framework that enables building a Lakehouse architecture with compute engines including Spark, PrestoDB, Flink, Trino, and Hive and APIs for Scala, Java, Rust, Ruby, and Python.
- Apahce Hudi: Hudi is a rich platform to build streaming data lakes with incremental data pipelines on a self-managing database layer, while being optimized for lake engines and regular batch processing. brings transactions, record-level updates/deletes and change streams to data lakes!
- Apache Iceberg: Iceberg is a high-performance format for huge analytic tables. Iceberg brings the reliability and simplicity of SQL tables to big data, while making it possible for engines like Spark, Trino, Flink, Presto, Hive and Impala to safely work with the same tables, at the same time.
三者均为 Data Lake 的数据存储中间层,是文件格式 file format之上的表格式 table format,其数据管理的功能均是基于一系列的 meta 文件:
- 文件格式:文件格式描述的是单个文件中数据的组织和管理格式,如ORC/PARQUET/AVRO等;
- 表格式:表格式表述的是由一系列文件构成的逻辑集合,即表,其底层的文件与数据的组织和管理格式;
- meta 文件类似于数据库的 catalog/wal,起到 schema 管理、事务管理和数据管理的功能:
- 与数据库不同的是,这些 meta 文件是与数据文件是一起存放在存储引擎中的,用户可以直接看到;
- meta 文件通常使用行存 json/avro格式,数据文件通常使用列存 parquet/orc格式;
- Meta 文件包含有表的 schema 信息: 因此系统可以自己掌握 Schema 的变动,提供 Schema 演化的支持;
- Meta 文件包含有事务日志 transaction log: meta 文件中记录了 transaction log,所以可以提供 ACID 事务支持;
- 所有对表的变更操作都会生成一份新的 meta 文件:于是系统就有了多版本的支持,可以提供访问历史版本的能力;
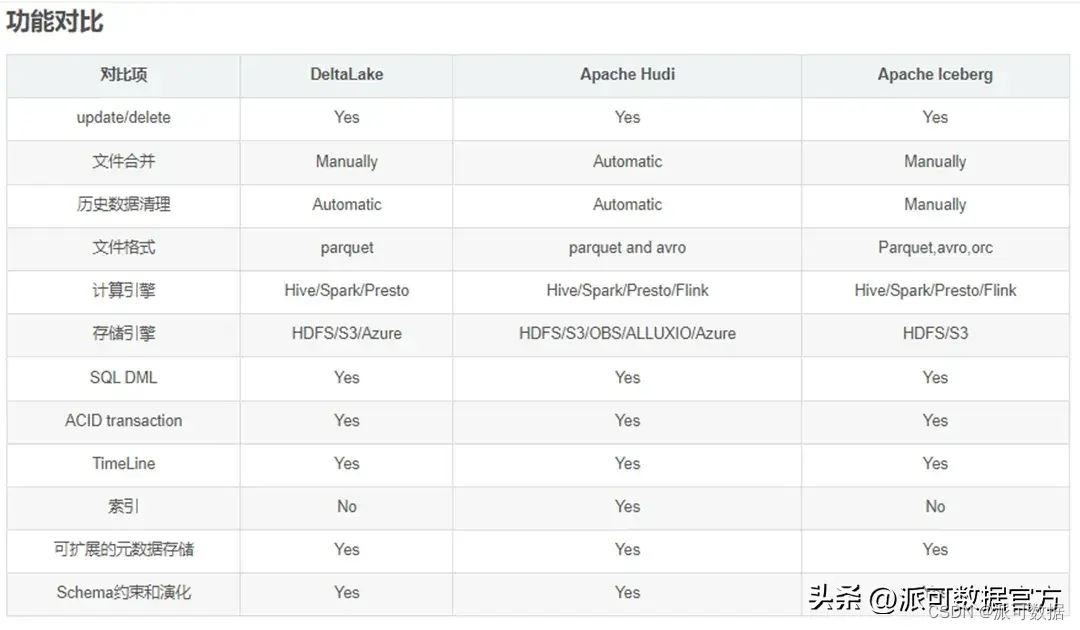
三者的相似点如下:
- 三者都是 Data Lake 的数据存储中间层,在技术实现上都是基于一系列的 meta 文件构建了file format 之上的table format;
- 三者都使用了统一的存储引擎和开放的格式(文件格式和表格式);
- 三者都能支持主流的高可用存储如 HDFS、S3,对象存储优先;
- 三者都支持记录级别的 update/delete,以增量更新数据;
- 三者都支持并发读写和事务ACID特性:即原子性、一致性、隔离性、持久性,通过避免垃圾数据的产生保证了数据质量;
- 三者都 (努力)支持流批一体存储,以流式增量导入数据;
- 三者都提供了对多查询引擎的支持:如 Spark/Hive/Presto;
- 三者都支持历史版本回溯;
- 三者都支持模式约束和演化 schema evolution,schema enforecement;
三者最初的设计初衷和对应场景并不完全相同,尤其是Hudi,其设计与另外两个相比差别更为明显,但数据湖仓要解决的问题是共同的,随着时间的发展,三者都在不断补齐自己缺失的能力,在将来会彼此趋同,成为功能相似却又各有特点的主流数据湖仓框架,目前三者的差异点主要如下:
- Hudi 为了高效的 incremental 的 upserts,设计了类似于主键的HoodieKey 的概念,表也分为 Copy On write和Merge On Read,分别为读和写进行了优化;
- Iceberg 定位于高性能的分析与可靠的数据管理,专门针对HIVE的诸多痛点进行了设计;(如 HIVE 只有目录级别而没有文件级别的统计信息,元数据分散在 MySQL 和 HDFS中写入操作原子性差,等等)
- Delta 定位于流批一体的数据处理,与SPARK的兼容性最好;
以下重点看下Iceberg的架构特点: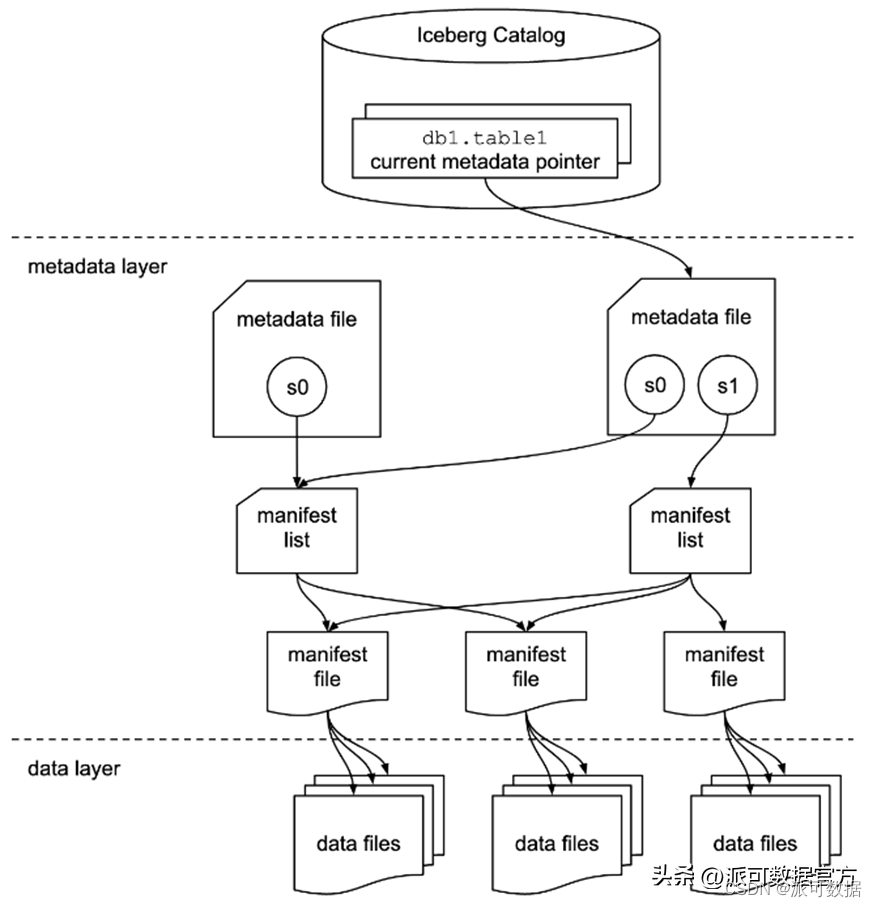
- 整体分为三层:Catalog层,元数据层和数据层;
- 元数据层本身又是多层级的体系,包括:metadata file, manifest list, manifest file;
- Metadata file: Table state is maintained in metadata files. All changes to table state create a new metadata file and replace the old metadata with an atomic swap. The table metadata file tracks the table schema, partitioning config, custom properties, and snapshots of the table contents. A snapshot represents the state of a table at some time and is used to access the complete set of data files in the table.
- Manifest file: Data files in snapshots are tracked by one or more manifest files that contain a row for each data file in the table, the file’s partition data, and its metrics. The data in a snapshot is the union of all files in its manifests. Manifest files are reused across snapshots to avoid rewriting metadata that is slow-changing. Manifests can track data files with any subset of a table and are not associated with partitions.
- Manifest list/snapshot: The manifests that make up a snapshot are stored in a manifest list file. Each manifest list stores metadata about manifests, including partition stats and data file counts. These stats are used to avoid reading manifests that are not required for an operation.
- 通过表格式在文件而不是目录级别进行管理(显著区别与HIVE的地方):This table format tracks individual data files in a table instead of directories. This allows writers to create data files in-place and only adds files to the table in an explicit commit.
4. 数据湖仓的应用现状与发展建议
对大多数尚未大规模引进数据湖仓技术的公司,笔者有如下几点建议:
- 随着数字化转型的进一步推进,BI和AI等各类数据分析需求日益递增,为更好地支撑各种数据需求,应尽早调研尝试引入数据湖仓作为企业级数据平台;(选择合适的产品/项目/场景,可以先从公司自身的数据平台着手);
- 随着数字化转型的进一步推进,大数据与云计算的结合越来越紧密,数据湖仓平台底层的存储系统更倾向于使用S3/MINIO/OZONE等对象存储,应尽早调研尝试使用对象存储(公有云私有云行业云甚至数据中心等场景,都有相应的对象存储解决方案,存算分离架构下可以通过Alluxio 等缓存框架加速分析性能);
- 随着数字化转型的进一步推进,企业愈加重视资源和应用的弹性/可扩展性以及成本,应尽早调研尝试在K8S上搭建数据湖仓平台;(大数据计算引擎如 spark/flink 等在 ON K8S 上部署方案已经成熟,AI的 tensorflow 等引擎在K8S上的部署方案也已成熟);
- 加强公司内部AI和大数据部门之间的交流合作,尝试通过数据湖仓平台满足两个部门日常各种BI/AI类数据分析需求;
文章来源于明哥的IT随笔 ,作者IT明哥。