目录
- 前言
- 1、集群搭建
- 1.1、安装RabbitMQ
- 1.1.1、前置要求
- 1.1.2、安装Erlang环境
- ①创建yum库配置文件
- ②加入配置内容
- ③更新yum库
- ④正式安装Erlang
- 1.1.3、安装RabbitMQ
- 1.1.4、RabbitMQ基础配置
- 1.1.5、收尾工作
- 1.2、克隆VMWare虚拟机
- 1.2.1、目标
- 1.2.2、克隆虚拟机
- 1.2.3、给新机设置 IP 地址
- 1.2.4、修改主机名称
- 1.2.5、保险措施
- 1.3、集群节点彼此发现
- 1.3.1、node01设置
- ①设置 IP 地址到主机名称的映射
- ②查看当前RabbitMQ节点的Cookie值并记录
- ③重置节点应用
- 1.3.2、node02设置
- ①设置 IP 地址到主机名称的映射
- ②修改当前RabbitMQ节点的Cookie值
- ③重置节点应用并加入集群
- 1.3.3、node03设置
- ①设置 IP 地址到主机名称的映射
- ②修改当前RabbitMQ节点的Cookie值
- ③重置节点应用并加入集群
- ④查看集群状态
- 1.3.4、附录
- 1.4、负载均衡:Management UI
- 1.4.1、说明
- 1.4.2、安装HAProxy
- 1.4.3、修改配置文件
- 1.4.4、测试效果
- 1.5、负载均衡:核心功能
- 1.5.1、增加配置
- 1.5.2、测试
- ①创建组件
- ②创建生产者端程序
- ③创建消费端程序
- 2、仲裁队列
- 2.1 创建仲裁队列
- 2.1.1、创建交换机
- 2.1.2、创建仲裁队列
- 2.1.3、绑定交换机
- 2.2、测试仲裁队列
- 2.2.1、常规测试
- ①生产者端
- ②消费者端
- 2.2.2、高可用测试
- ①停止某个节点的rabbit应用
- ②查看仲裁队列对应的节点情况
- ③再次发送消息
- 3、流式队列(性能不如kafka)
- 3.1、启用插件
- 3.2、负载均衡
- 3.3、Java代码
- 3.3.1、引入依赖
- 3.3.2、创建Stream
- ①代码方式创建
- ②ManagementUI创建
- 3.3.3、生产者端程序
- ①内部机制说明
- ②示例代码
- 3.3.4、消费端程序
- 3.4、指定偏移量消费
- 3.4.1、偏移量
- 3.4.2、官方文档说明
- 3.4.3、指定Offset消费
- 3.4.4、对比
- 4、Federation插件
- 4.1、简介
- 4.2、Federation交换机
- 4.2.1、总体说明
- 4.2.2、准备工作
- 4.2.3、启用联邦插件
- 4.2.4、添加上游连接端点
- 4.2.5、创建控制策略
- 4.2.6、测试
- ①测试计划
- ②创建组件
- ③发布消息执行测试
- 4.3、Federation队列
- 4.3.1、总体说明
- 4.3.2、创建控制策略
- 4.3.3、测试
- ①测试计划
- ②创建组件
- ③执行测试
- 5、Shovel
- 5.1、启用Shovel插件
- 5.2、配置Shovel
- 5.3、测试
- 5.3.1、测试计划
- 5.3.2、测试效果
- ①发布消息
- ②源节点
- ③目标节点
前言
书接上回,我们讲到了RabbitMQ的基本使用和进阶用法,这篇文章我们来讲讲什么是RabbitMQ集群
基本诉求:
- 避免单点故障
- 大流量场景分摊负载
- 数据同步
工作机制:
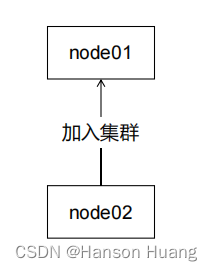
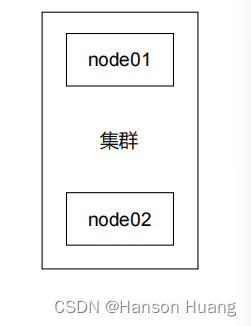
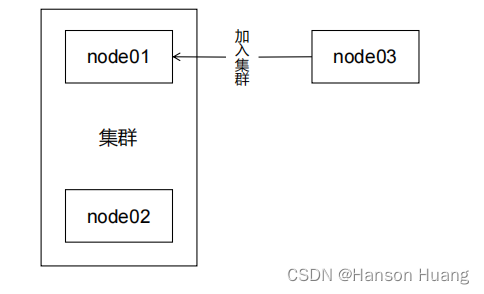
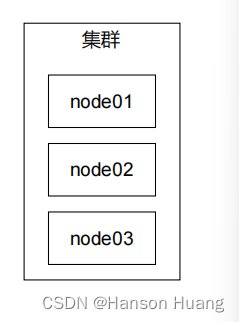
节点之间能够互相发现
1、集群搭建
1.1、安装RabbitMQ
1.1.1、前置要求
CentOS发行版的版本≥CentOS 8 Stream
镜像下载地址:https://mirrors.163.com/centos/8-stream/isos/x86_64/CentOS-Stream-8-20240318.0-x86_64-dvd1.iso
RabbitMQ安装方式官方指南:

1.1.2、安装Erlang环境
①创建yum库配置文件
vim /etc/yum.repos.d/rabbitmq.repo
②加入配置内容
以下内容来自官方文档:https://www.rabbitmq.com/docs/install-rpm
# In /etc/yum.repos.d/rabbitmq.repo
##
## Zero dependency Erlang RPM
##
[modern-erlang]
name=modern-erlang-el8
# uses a Cloudsmith mirror @ yum.novemberain.com in addition to its Cloudsmith upstream.
# Unlike Cloudsmith, the mirror does not have any traffic quotas
baseurl=https://yum1.novemberain.com/erlang/el/8/$basearch
https://yum2.novemberain.com/erlang/el/8/$basearch
https://dl.cloudsmith.io/public/rabbitmq/rabbitmq-erlang/rpm/el/8/$basearch
repo_gpgcheck=1
enabled=1
gpgkey=https://github.com/rabbitmq/signing-keys/releases/download/3.0/cloudsmith.rabbitmq-erlang.E495BB49CC4BBE5B.key
gpgcheck=1
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
metadata_expire=300
pkg_gpgcheck=1
autorefresh=1
type=rpm-md
[modern-erlang-noarch]
name=modern-erlang-el8-noarch
# uses a Cloudsmith mirror @ yum.novemberain.com.
# Unlike Cloudsmith, it does not have any traffic quotas
baseurl=https://yum1.novemberain.com/erlang/el/8/noarch
https://yum2.novemberain.com/erlang/el/8/noarch
https://dl.cloudsmith.io/public/rabbitmq/rabbitmq-erlang/rpm/el/8/noarch
repo_gpgcheck=1
enabled=1
gpgkey=https://github.com/rabbitmq/signing-keys/releases/download/3.0/cloudsmith.rabbitmq-erlang.E495BB49CC4BBE5B.key
https://github.com/rabbitmq/signing-keys/releases/download/3.0/rabbitmq-release-signing-key.asc
gpgcheck=1
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
metadata_expire=300
pkg_gpgcheck=1
autorefresh=1
type=rpm-md
[modern-erlang-source]
name=modern-erlang-el8-source
# uses a Cloudsmith mirror @ yum.novemberain.com.
# Unlike Cloudsmith, it does not have any traffic quotas
baseurl=https://yum1.novemberain.com/erlang/el/8/SRPMS
https://yum2.novemberain.com/erlang/el/8/SRPMS
https://dl.cloudsmith.io/public/rabbitmq/rabbitmq-erlang/rpm/el/8/SRPMS
repo_gpgcheck=1
enabled=1
gpgkey=https://github.com/rabbitmq/signing-keys/releases/download/3.0/cloudsmith.rabbitmq-erlang.E495BB49CC4BBE5B.key
https://github.com/rabbitmq/signing-keys/releases/download/3.0/rabbitmq-release-signing-key.asc
gpgcheck=1
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
metadata_expire=300
pkg_gpgcheck=1
autorefresh=1
##
## RabbitMQ Server
##
[rabbitmq-el8]
name=rabbitmq-el8
baseurl=https://yum2.novemberain.com/rabbitmq/el/8/$basearch
https://yum1.novemberain.com/rabbitmq/el/8/$basearch
https://dl.cloudsmith.io/public/rabbitmq/rabbitmq-server/rpm/el/8/$basearch
repo_gpgcheck=1
enabled=1
# Cloudsmith's repository key and RabbitMQ package signing key
gpgkey=https://github.com/rabbitmq/signing-keys/releases/download/3.0/cloudsmith.rabbitmq-server.9F4587F226208342.key
https://github.com/rabbitmq/signing-keys/releases/download/3.0/rabbitmq-release-signing-key.asc
gpgcheck=1
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
metadata_expire=300
pkg_gpgcheck=1
autorefresh=1
type=rpm-md
[rabbitmq-el8-noarch]
name=rabbitmq-el8-noarch
baseurl=https://yum2.novemberain.com/rabbitmq/el/8/noarch
https://yum1.novemberain.com/rabbitmq/el/8/noarch
https://dl.cloudsmith.io/public/rabbitmq/rabbitmq-server/rpm/el/8/noarch
repo_gpgcheck=1
enabled=1
# Cloudsmith's repository key and RabbitMQ package signing key
gpgkey=https://github.com/rabbitmq/signing-keys/releases/download/3.0/cloudsmith.rabbitmq-server.9F4587F226208342.key
https://github.com/rabbitmq/signing-keys/releases/download/3.0/rabbitmq-release-signing-key.asc
gpgcheck=1
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
metadata_expire=300
pkg_gpgcheck=1
autorefresh=1
type=rpm-md
[rabbitmq-el8-source]
name=rabbitmq-el8-source
baseurl=https://yum2.novemberain.com/rabbitmq/el/8/SRPMS
https://yum1.novemberain.com/rabbitmq/el/8/SRPMS
https://dl.cloudsmith.io/public/rabbitmq/rabbitmq-server/rpm/el/8/SRPMS
repo_gpgcheck=1
enabled=1
gpgkey=https://github.com/rabbitmq/signing-keys/releases/download/3.0/cloudsmith.rabbitmq-server.9F4587F226208342.key
gpgcheck=0
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
metadata_expire=300
pkg_gpgcheck=1
autorefresh=1
type=rpm-md
③更新yum库
–nobest表示所需安装包即使不是最佳选择也接受
yum update -y --nobest
④正式安装Erlang
yum install -y erlang
1.1.3、安装RabbitMQ
# 导入GPG密钥
rpm --import 'https://github.com/rabbitmq/signing-keys/releases/download/3.0/rabbitmq-release-signing-key.asc'
rpm --import 'https://github.com/rabbitmq/signing-keys/releases/download/3.0/cloudsmith.rabbitmq-erlang.E495BB49CC4BBE5B.key'
rpm --import 'https://github.com/rabbitmq/signing-keys/releases/download/3.0/cloudsmith.rabbitmq-server.9F4587F226208342.key'
# 下载 RPM 包
wget https://github.com/rabbitmq/rabbitmq-server/releases/download/v3.13.0/rabbitmq-server-3.13.0-1.el8.noarch.rpm
# 安装
rpm -ivh rabbitmq-server-3.13.0-1.el8.noarch.rpm
1.1.4、RabbitMQ基础配置
# 启用管理界面插件
rabbitmq-plugins enable rabbitmq_management
# 启动 RabbitMQ 服务:
systemctl start rabbitmq-server
# 将 RabbitMQ 服务设置为开机自动启动
systemctl enable rabbitmq-server
# 新增登录账号密码
rabbitmqctl add_user hanson 123456
# 设置登录账号权限
rabbitmqctl set_user_tags hanson administrator
rabbitmqctl set_permissions -p / hanson ".*" ".*" ".*"
# 配置所有稳定功能 flag 启用
rabbitmqctl enable_feature_flag all
# 重启RabbitMQ服务生效
systemctl restart rabbitmq-server
1.1.5、收尾工作
rm -rf /etc/yum.repos.d/rabbitmq.repo
1.2、克隆VMWare虚拟机
1.2.1、目标
通过克隆操作,一共准备三台VMWare虚拟机
| 集群节点名称 | 虚拟机 IP 地址 |
|---|---|
| node01 | 192.168.200.100 |
| node02 | 192.168.200.150 |
| node03 | 192.168.200.200 |
1.2.2、克隆虚拟机
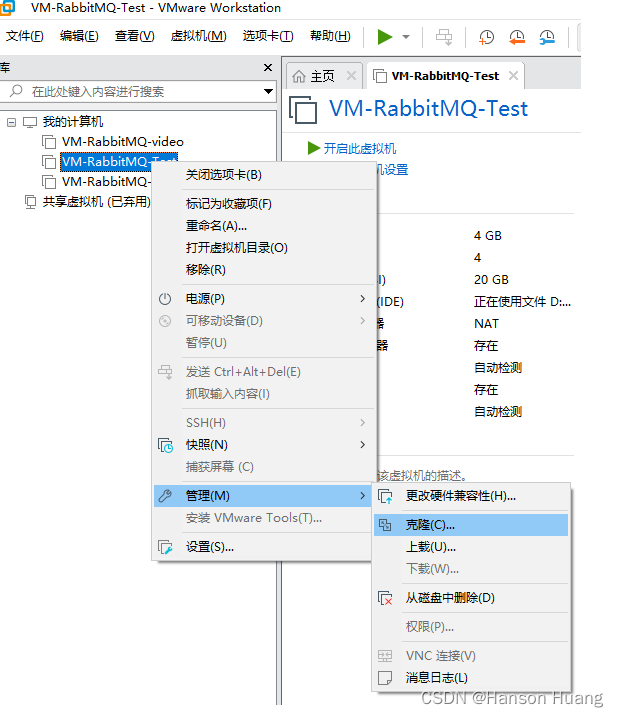
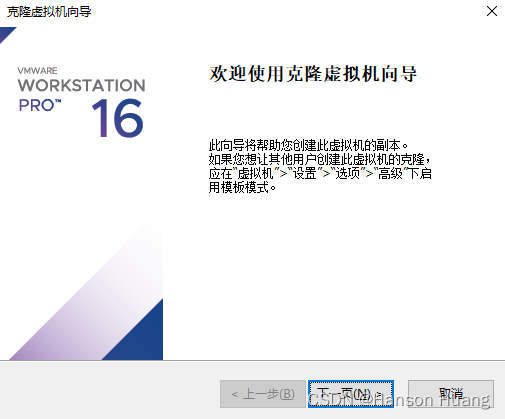
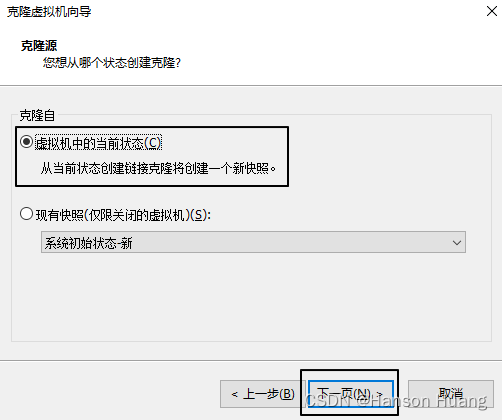
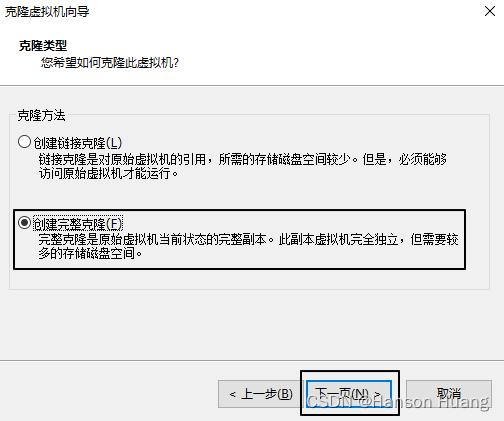
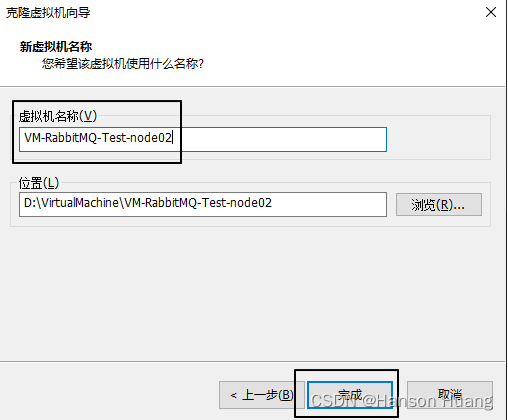
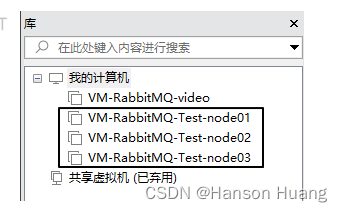
1.2.3、给新机设置 IP 地址
在CentOS 7中,可以使用nmcli命令行工具修改IP地址。以下是具体步骤:
- 查看网络连接信息:
nmcli con show
- 停止指定的网络连接(将
<connection_name>替换为实际的网络连接名称):
nmcli con down <connection_name>
- 修改IP地址(将
<connection_name>替换为实际的网络连接名称,将<new_ip_address>替换为新的IP地址,将<subnet_mask>替换为子网掩码,将<gateway>替换为网关):
# <new_ip_address>/<subnet_mask>这里是 CIDR 表示法
nmcli con mod <connection_name> ipv4.addresses <new_ip_address>/<subnet_mask>
nmcli con mod <connection_name> ipv4.gateway <gateway>
nmcli con mod <connection_name> ipv4.method manual
- 启动网络连接:
nmcli con up <connection_name>
- 验证新的IP地址是否生效:
ip addr show
1.2.4、修改主机名称
主机名称会被RabbitMQ作为集群中的节点名称,后面会用到,所以需要设置一下。
修改方式如下:
vim /etc/hostname
1.2.5、保险措施
为了在后续操作过程中,万一遇到操作失误,友情建议拍摄快照。
1.3、集群节点彼此发现
1.3.1、node01设置
①设置 IP 地址到主机名称的映射
修改文件/etc/hosts,追加如下内容:
192.168.200.100 node01
192.168.200.150 node02
192.168.200.200 node03
②查看当前RabbitMQ节点的Cookie值并记录
[root@node01 ~]# cat /var/lib/rabbitmq/.erlang.cookie
NOTUPTIZIJONXDWWQPOJ
③重置节点应用
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl start_app
1.3.2、node02设置
①设置 IP 地址到主机名称的映射
修改文件/etc/hosts,追加如下内容:
192.168.200.100 node01
192.168.200.150 node02
192.168.200.200 node03
②修改当前RabbitMQ节点的Cookie值
node02和node03都改成和node01一样:
vim /var/lib/rabbitmq/.erlang.cookie
③重置节点应用并加入集群
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster rabbit@node01
rabbitmqctl start_app
1.3.3、node03设置
①设置 IP 地址到主机名称的映射
修改文件/etc/hosts,追加如下内容:
192.168.200.100 node01
192.168.200.150 node02
192.168.200.200 node03
②修改当前RabbitMQ节点的Cookie值
node02和node03都改成和node01一样:
vim /var/lib/rabbitmq/.erlang.cookie
③重置节点应用并加入集群
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster rabbit@node01
rabbitmqctl start_app
④查看集群状态
rabbitmqctl cluster_status
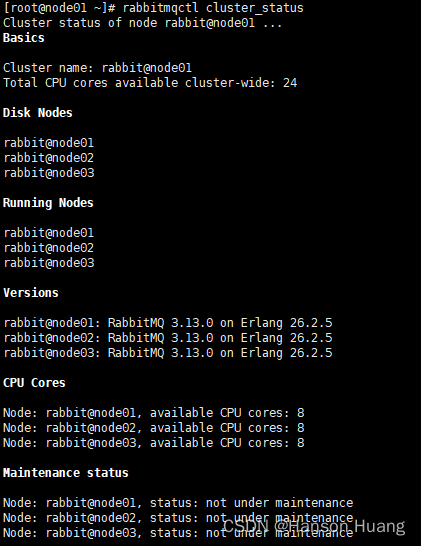
1.3.4、附录
如有需要踢出某个节点,则按下面操作执行:
# 被踢出的节点:
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl start_app
# 节点1
rabbitmqctl forget_cluster_node rabbit@node02
1.4、负载均衡:Management UI
两个需要暴露的端口:
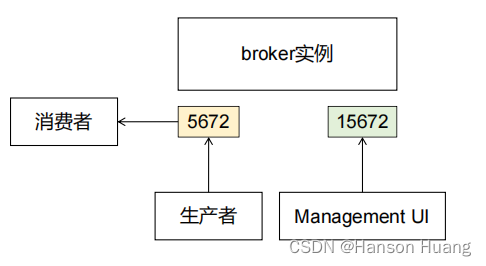
目前集群方案:
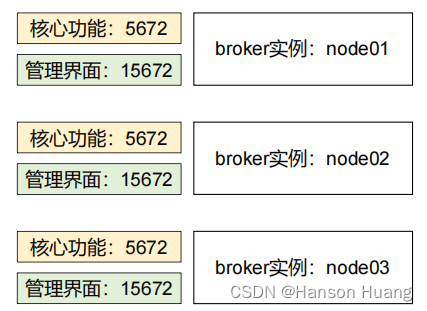
管理界面负载均衡:
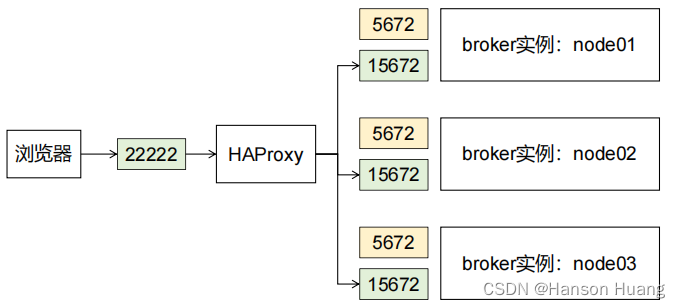
核心功能负载均衡:
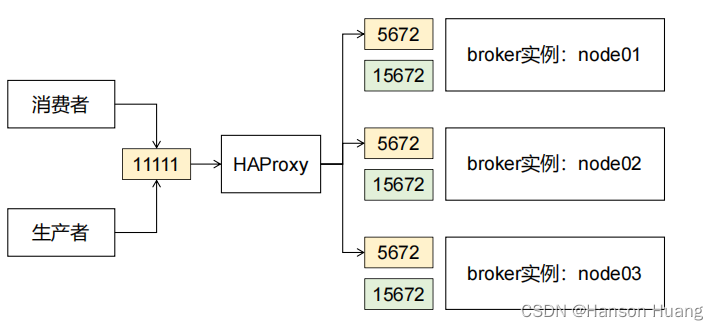
1.4.1、说明
- 其实访问任何一个RabbitMQ实例的管理界面都是对集群操作,所以配置负载均衡通过统一入口访问在我们学习期间就是锦上添花
- 先给管理界面做负载均衡,然后方便我们在管理界面上创建交换机、队列等操作
1.4.2、安装HAProxy
yum install -y haproxy
haproxy -v
systemctl start haproxy
systemctl enable haproxy

1.4.3、修改配置文件
配置文件位置:
/etc/haproxy/haproxy.cfg
在配置文件末尾增加如下内容:
frontend rabbitmq_ui_frontend
bind 192.168.200.100:22222
mode http
default_backend rabbitmq_ui_backendbackend rabbitmq_ui_backend
mode http
balance roundrobin
option httpchk GET /
server rabbitmq_ui1 192.168.200.100:15672 check
server rabbitmq_ui2 192.168.200.150:15672 check
server rabbitmq_ui3 192.168.200.200:15672 check
设置SELinux策略,允许HAProxy拥有权限连接任意端口:
setsebool -P haproxy_connect_any=1
SELinux是Linux系统中的安全模块,它可以限制进程的权限以提高系统的安全性。在某些情况下,SELinux可能会阻止HAProxy绑定指定的端口,这就需要通过设置域(domain)的安全策略来解决此问题。
通过执行
setsebool -P haproxy_connect_any=1命令,您已经为HAProxy设置了一个布尔值,允许HAProxy连接到任意端口。这样,HAProxy就可以成功绑定指定的socket,并正常工作。
重启HAProxy:
systemctl restart haproxy
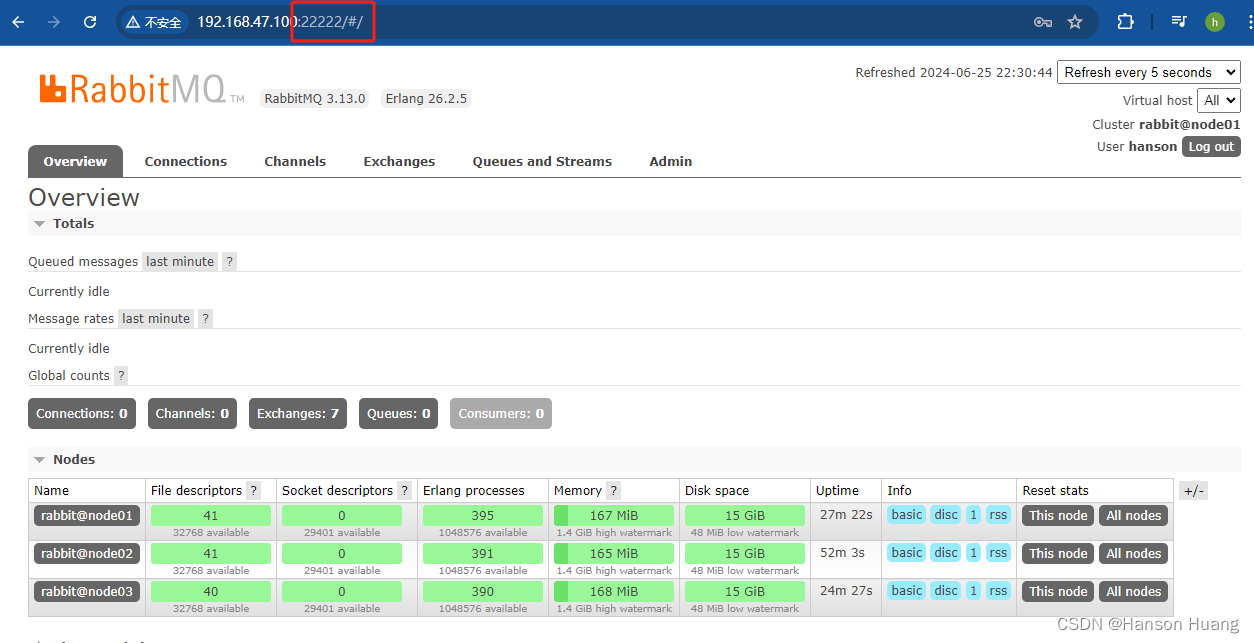
1.4.4、测试效果
1.5、负载均衡:核心功能
1.5.1、增加配置
frontend rabbitmq_frontend
bind 192.168.200.100:11111
mode tcp
default_backend rabbitmq_backendbackend rabbitmq_backend
mode tcp
balance roundrobin
server rabbitmq1 192.168.200.100:5672 check
server rabbitmq2 192.168.200.150:5672 check
server rabbitmq3 192.168.200.200:5672 check
重启HAProxy服务:
systemctl restart haproxy
1.5.2、测试
①创建组件
- 交换机:exchange.cluster.test
- 队列:queue.cluster.test
- 路由键:routing.key.cluster.test
②创建生产者端程序
[1]配置POM
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.1.5</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
[2]主启动类
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class RabbitMQProducerMainType {
public static void main(String[] args) {
SpringApplication.run(RabbitMQProducerMainType.class, args);
}
}
[3]配置YAML
spring:
rabbitmq:
host: 192.168.200.100
port: 11111
username: hanson
password: 123456
virtual-host: /
publisher-confirm-type: CORRELATED # 交换机的确认
publisher-returns: true # 队列的确认
logging:
level:
com.hanson.mq.config.MQProducerAckConfig: info
[4]配置类
import jakarta.annotation.PostConstruct;
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.core.ReturnedMessage;
import org.springframework.amqp.rabbit.connection.CorrelationData;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Configuration;
@Configuration
@Slf4j
public class MQProducerAckConfig implements RabbitTemplate.ConfirmCallback, RabbitTemplate.ReturnsCallback{
@Autowired
private RabbitTemplate rabbitTemplate;
@PostConstruct
public void init() {
rabbitTemplate.setConfirmCallback(this);
rabbitTemplate.setReturnsCallback(this);
}
@Override
public void confirm(CorrelationData correlationData, boolean ack, String cause) {
if (ack) {
log.info("消息发送到交换机成功!数据:" + correlationData);
} else {
log.info("消息发送到交换机失败!数据:" + correlationData + " 原因:" + cause);
}
}
@Override
public void returnedMessage(ReturnedMessage returned) {
log.info("消息主体: " + new String(returned.getMessage().getBody()));
log.info("应答码: " + returned.getReplyCode());
log.info("描述:" + returned.getReplyText());
log.info("消息使用的交换器 exchange : " + returned.getExchange());
log.info("消息使用的路由键 routing : " + returned.getRoutingKey());
}
}
[5] Junit测试类
import jakarta.annotation.Resource;
import org.junit.jupiter.api.Test;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
public class RabbitMQTest {
@Resource
private RabbitTemplate rabbitTemplate;
public static final String EXCHANGE_CLUSTER_TEST = "exchange.cluster.test";
public static final String ROUTING_KEY_CLUSTER_TEST = "routing.key.cluster.test";
@Test
public void testSendMessage() {
rabbitTemplate.convertAndSend(EXCHANGE_CLUSTER_TEST, ROUTING_KEY_CLUSTER_TEST, "message test cluster~~~");
}
}

③创建消费端程序
[1]配置POM
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.1.5</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
[2]主启动类
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class RabbitMQProducerMainType {
public static void main(String[] args) {
SpringApplication.run(RabbitMQProducerMainType.class, args);
}
}
[3]配置YAML
spring:
rabbitmq:
host: 192.168.200.100
port: 11111
username: hanson
password: 123456
virtual-host: /
listener:
simple:
acknowledge-mode: manual
logging:
level:
com.hanson.mq.listener.MyProcessor: info
[4]监听器
import com.rabbitmq.client.Channel;
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;
import java.io.IOException;
@Component
@Slf4j
public class MyProcessor {
@RabbitListener(queues = {"queue.cluster.test"})
public void processNormalQueueMessage(String data, Message message, Channel channel)
throws IOException {
log.info("消费端:" + data);
channel.basicAck(message.getMessageProperties().getDeliveryTag(), false);
}
}
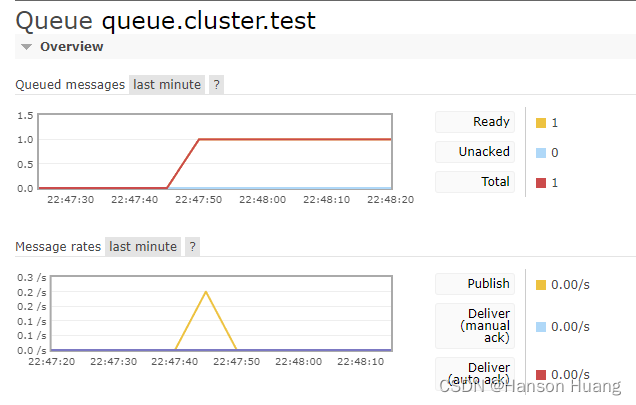
[5]运行效果

2、仲裁队列

集群化分布:
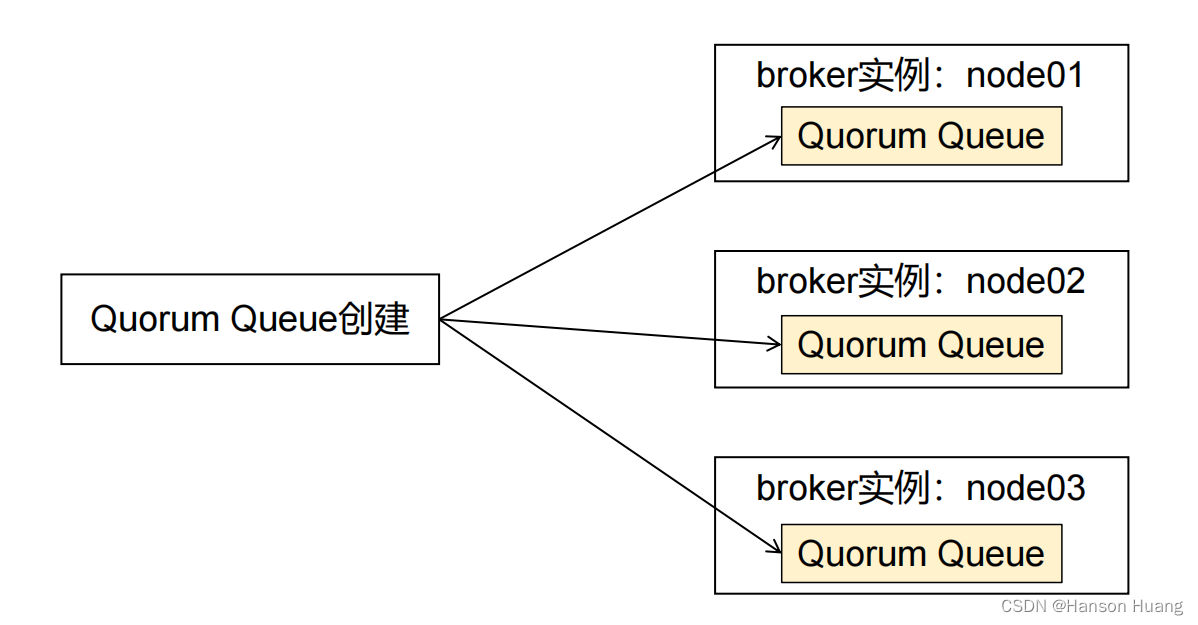
创建仲裁队列后,会自动的分布在不同的实例上面
2.1 创建仲裁队列
说明:鉴于仲裁队列的功能,肯定是需要在前面集群的基础上操作!
2.1.1、创建交换机
和仲裁队列绑定的交换机没有特殊,我们还是创建一个direct交换机即可
交换机名称:exchange.quorum.test
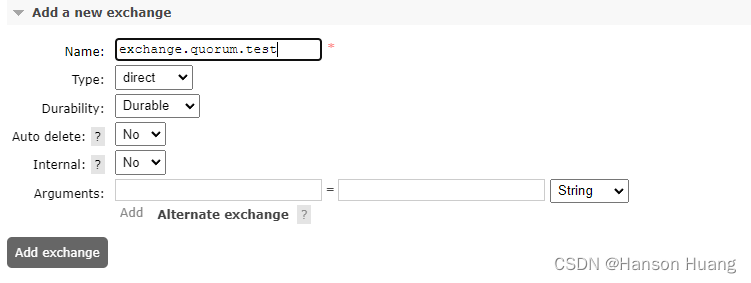
2.1.2、创建仲裁队列
队列名称:queue.quorum.test


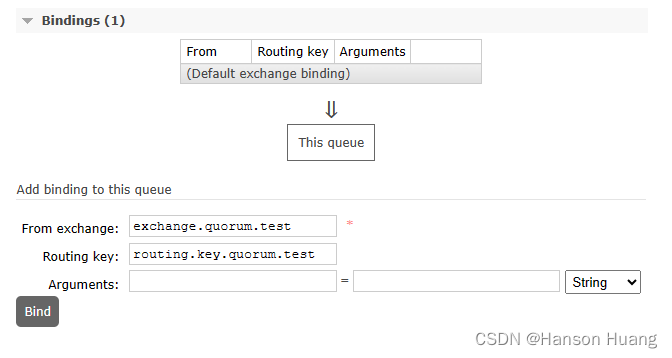
2.1.3、绑定交换机
路由键:routing.key.quorum.test
2.2、测试仲裁队列
2.2.1、常规测试
像使用经典队列一样发送消息、消费消息
①生产者端
public static final String EXCHANGE_QUORUM_TEST = "exchange.quorum.test";
public static final String ROUTING_KEY_QUORUM_TEST = "routing.key.quorum.test";
@Test
public void testSendMessageToQuorum() {
rabbitTemplate.convertAndSend(EXCHANGE_QUORUM_TEST, ROUTING_KEY_QUORUM_TEST, "message test quorum ~~~");
}

②消费者端
public static final String QUEUE_QUORUM_TEST = "queue.quorum.test";
@RabbitListener(queues = {QUEUE_QUORUM_TEST})
public void quorumMessageProcess(String data, Message message, Channel channel) throws IOException {
log.info("消费端:" + data);
channel.basicAck(message.getMessageProperties().getDeliveryTag(), false);
}

2.2.2、高可用测试
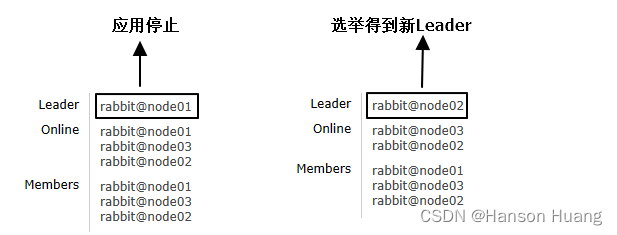
①停止某个节点的rabbit应用
# 停止rabbit应用
rabbitmqctl stop_app
②查看仲裁队列对应的节点情况
③再次发送消息
收发消息仍然正常
3、流式队列(性能不如kafka)
核心机制
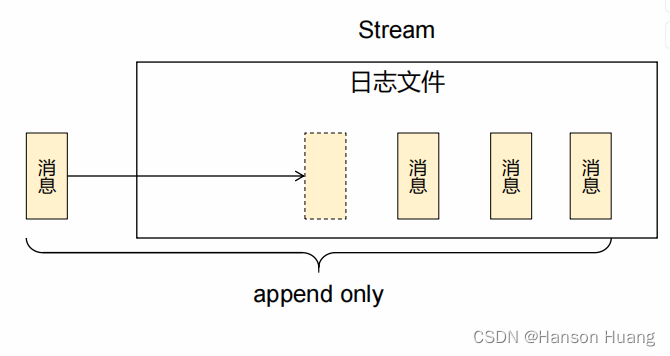
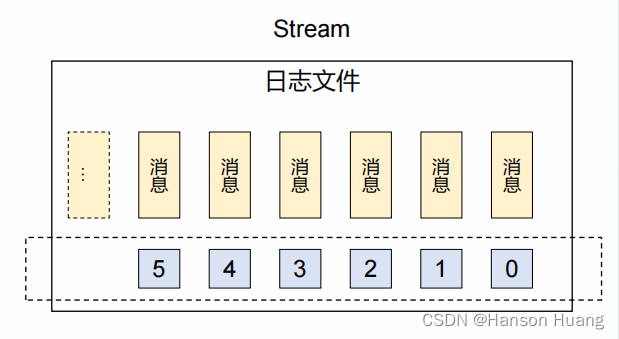
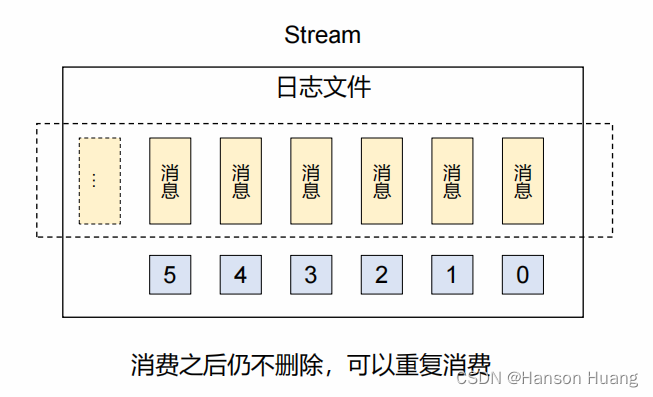
总体评价
- 从客户端支持角度来说,生态尚不健全
- 从使用习惯角度来说,和原有队列用法不完全兼容
- 从竞品角度来说,
像Kafka但远远比不上Kafka - 从应用场景角度来说:
- 经典队列:适用于系统内部异步通信场景
- 流式队列:适用于系统间跨平台、大流量、实时计算场景(Kafka主场)
- 使用建议:Stream队列在目前企业实际应用非常少,真有特定场景需要使
用肯定会倾向于使用Kafka,而不是RabbitMQ Stream - 未来展望:Classic Queue已经有和Quorum Queue合二为一的趋势,
Stream也有加入进来整合成一种队列的趋势,但Stream内部机制决定这很
难
3.1、启用插件
说明:只有启用了Stream插件,才能使用流式队列的完整功能
在集群每个节点中依次执行如下操作:
# 启用Stream插件
rabbitmq-plugins enable rabbitmq_stream
# 重启rabbit应用
rabbitmqctl stop_app
rabbitmqctl start_app
# 查看插件状态
rabbitmq-plugins list
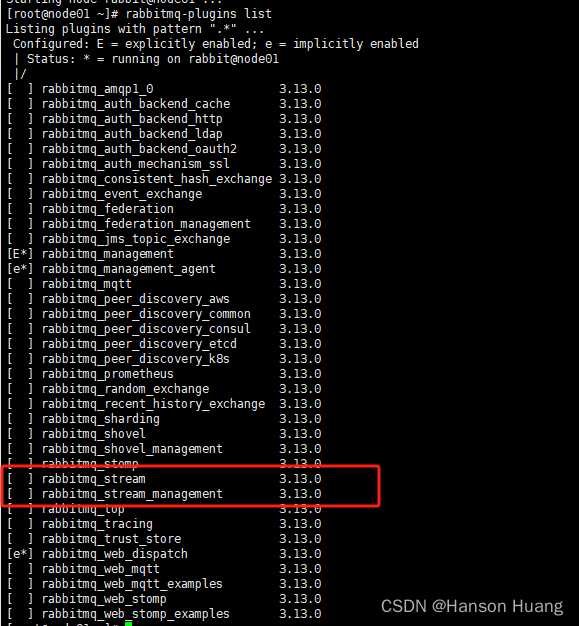
3.2、负载均衡
在文件/etc/haproxy/haproxy.cfg末尾追加:
frontend rabbitmq_stream_frontend
bind 192.168.200.100:33333
mode tcp
default_backend rabbitmq_stream_backend
backend rabbitmq_stream_backend
mode tcp
balance roundrobin
server rabbitmq1 192.168.200.100:5552 check
server rabbitmq2 192.168.200.150:5552 check
server rabbitmq3 192.168.200.200:5552 check
3.3、Java代码
3.3.1、引入依赖
Stream 专属 Java 客户端官方网址:https://github.com/rabbitmq/rabbitmq-stream-java-client
Stream 专属 Java 客户端官方文档网址:https://rabbitmq.github.io/rabbitmq-stream-java-client/stable/htmlsingle/
<dependencies>
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>stream-client</artifactId>
<version>0.15.0</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.30</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
</dependency>
</dependencies>
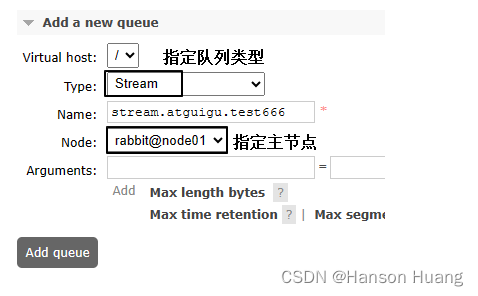
3.3.2、创建Stream
说明:不需要创建交换机
①代码方式创建
Environment environment = Environment.builder()
.host("192.168.47.100")
.port(33333)
.username("hanson")
.password("123456")
.build();
environment.streamCreator().stream("stream.atguigu.test").create();
environment.close();
②ManagementUI创建
3.3.3、生产者端程序
①内部机制说明
[1]官方文档
Internally, the
Environmentwill query the broker to find out about the topology of the stream and will create or re-use a connection to publish to the leader node of the stream.
翻译:
在内部,Environment将查询broker以了解流的拓扑结构,并将创建或重用连接以发布到流的 leader 节点。
[2]解析
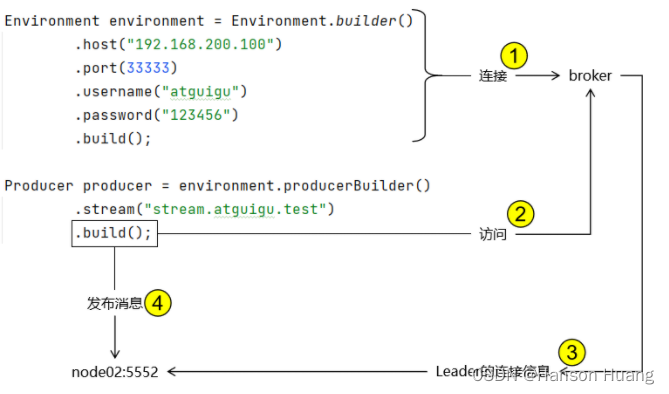
- 在 Environment 中封装的连接信息仅负责连接到 broker
- Producer 在构建对象时会访问 broker 拉取集群中 Leader 的连接信息
- 将来实际访问的是集群中的 Leader 节点
- Leader 的连接信息格式是:节点名称:端口号
[3]配置
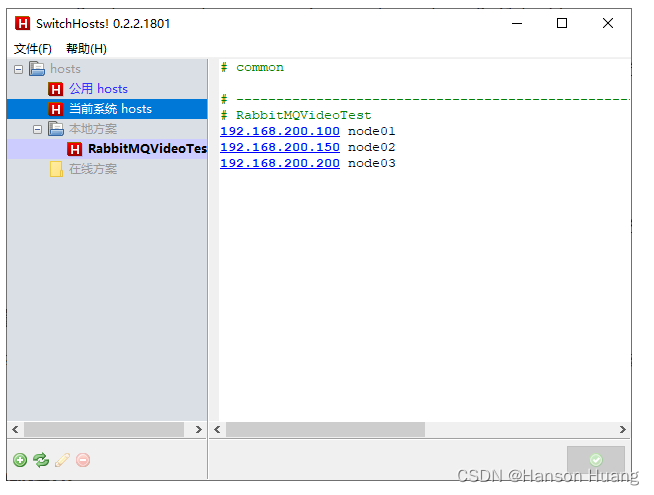
为了让本机的应用程序知道 Leader 节点名称对应的 IP 地址,我们需要在本地配置 hosts 文件,建立从节点名称到 IP 地址的映射关系
②示例代码
Environment environment = Environment.builder()
.host("192.168.200.100")
.port(33333)
.username("hanson")
.password("123456")
.build();
Producer producer = environment.producerBuilder()
.stream("stream.atguigu.test")
.build();
byte[] messagePayload = "hello rabbit stream".getBytes(StandardCharsets.UTF_8);
CountDownLatch countDownLatch = new CountDownLatch(1);
producer.send(
producer.messageBuilder().addData(messagePayload).build(),
confirmationStatus -> {
if (confirmationStatus.isConfirmed()) {
System.out.println("[生产者端]the message made it to the broker");
} else {
System.out.println("[生产者端]the message did not make it to the broker");
}
countDownLatch.countDown();
});
countDownLatch.await();
producer.close();
environment.close();
3.3.4、消费端程序
Environment environment = Environment.builder()
.host("192.168.200.100")
.port(33333)
.username("hanson")
.password("123456")
.build();
environment.consumerBuilder()
.stream("stream.atguigu.test")
.name("stream.atguigu.test.consumer")
.autoTrackingStrategy()
.builder()
.messageHandler((offset, message) -> {
byte[] bodyAsBinary = message.getBodyAsBinary();
String messageContent = new String(bodyAsBinary);
System.out.println("[消费者端]messageContent = " + messageContent + " Offset=" + offset.offset());
})
.build();
3.4、指定偏移量消费
3.4.1、偏移量

3.4.2、官方文档说明
The offset is the place in the stream where the consumer starts consuming from. The possible values for the offset parameter are the following:
- OffsetSpecification.first(): starting from the first available offset. If the stream has not been truncated, this means the beginning of the stream (offset 0).
- OffsetSpecification.last(): starting from the end of the stream and returning the last chunk of messages immediately (if the stream is not empty).
- OffsetSpecification.next(): starting from the next offset to be written. Contrary to
OffsetSpecification.last(), consuming withOffsetSpecification.next()will not return anything if no-one is publishing to the stream. The broker will start sending messages to the consumer when messages are published to the stream.- OffsetSpecification.offset(offset): starting from the specified offset. 0 means consuming from the beginning of the stream (first messages). The client can also specify any number, for example the offset where it left off in a previous incarnation of the application.
- OffsetSpecification.timestamp(timestamp): starting from the messages stored after the specified timestamp. Note consumers can receive messages published a bit before the specified timestamp. Application code can filter out those messages if necessary.
3.4.3、指定Offset消费
Environment environment = Environment.builder()
.host("192.168.200.100")
.port(33333)
.username("hanson")
.password("123456")
.build();
CountDownLatch countDownLatch = new CountDownLatch(1);
Consumer consumer = environment.consumerBuilder()
.stream("stream.atguigu.test")
.offset(OffsetSpecification.first())
.messageHandler((offset, message) -> {
byte[] bodyAsBinary = message.getBodyAsBinary();
String messageContent = new String(bodyAsBinary);
System.out.println("[消费者端]messageContent = " + messageContent);
countDownLatch.countDown();
})
.build();
countDownLatch.await();
consumer.close();
3.4.4、对比
- autoTrackingStrategy 方式:始终监听Stream中的新消息(狗狗看家,忠于职守)
- 指定偏移量方式:针对指定偏移量的消息消费之后就停止(狗狗叼飞盘,叼回来就完)
4、Federation插件

4.1、简介
Federation插件的设计目标是使RabbitMQ在不同的Broker节点之间进行消息传递而无须建立集群。
它可以在不同的管理域中的Broker或集群间传递消息,这些管理域可能设置了不同的用户和vhost,也可能运行在不同版本的RabbitMQ和Erlang上。Federation基于AMQP 0-9-1协议在不同的Broker之间进行通信,并且设计成能够容忍不稳定的网络连接情况。
4.2、Federation交换机
4.2.1、总体说明
- 各节点操作:启用联邦插件
- 下游操作:
- 添加上游连接端点
- 创建控制策略
4.2.2、准备工作
为了执行相关测试,我们使用Docker创建两个RabbitMQ实例。
特别提示:由于Federation机制的最大特点就是跨集群同步数据,所以这两个Docker容器中的RabbitMQ实例不加入集群!!!是两个独立的broker实例。
docker run -d \
--name rabbitmq-shenzhen \
-p 51000:5672 \
-p 52000:15672 \
-v rabbitmq-plugin:/plugins \
-e RABBITMQ_DEFAULT_USER=guest \
-e RABBITMQ_DEFAULT_PASS=123456 \
rabbitmq:3.13-management
docker run -d \
--name rabbitmq-shanghai \
-p 61000:5672 \
-p 62000:15672 \
-v rabbitmq-plugin:/plugins \
-e RABBITMQ_DEFAULT_USER=guest \
-e RABBITMQ_DEFAULT_PASS=123456 \
rabbitmq:3.13-management
4.2.3、启用联邦插件
在上游、下游节点中都需要开启。
Docker容器中的RabbitMQ已经开启了rabbitmq_federation,还需要开启rabbitmq_federation_management
rabbitmq-plugins enable rabbitmq_federation
rabbitmq-plugins enable rabbitmq_federation_management
rabbitmq_federation_management插件启用后会在Management UI的Admin选项卡下看到:
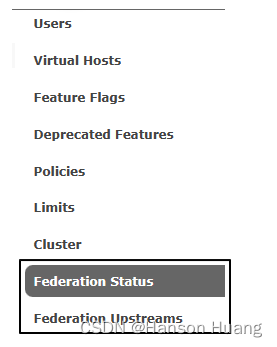
4.2.4、添加上游连接端点
在下游节点填写上游节点的连接信息:
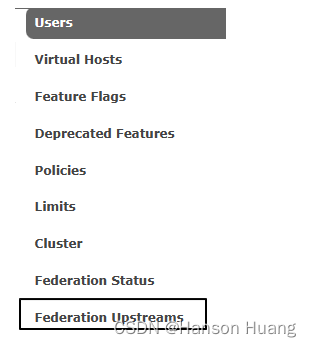
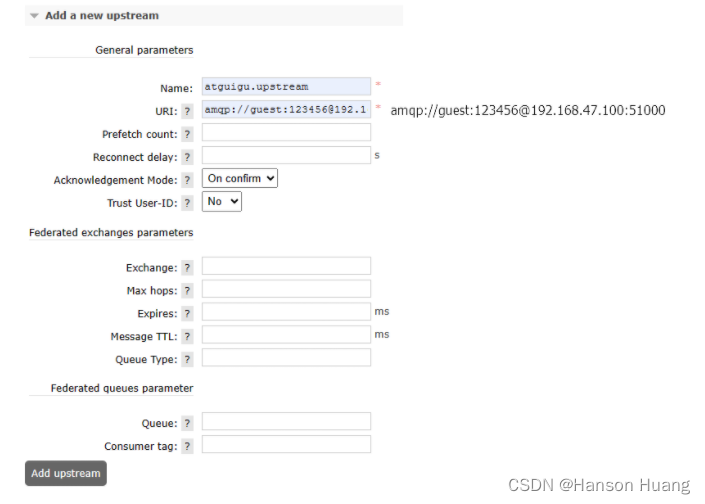
4.2.5、创建控制策略


4.2.6、测试
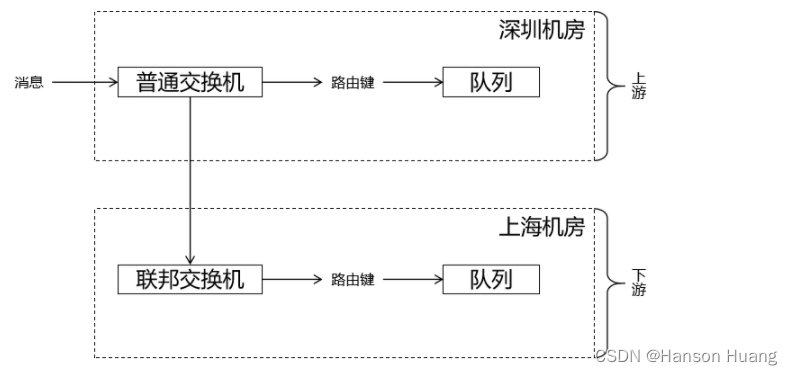
①测试计划
特别提示:
- 普通交换机和联邦交换机名称要一致
- 交换机名称要能够和策略正则表达式匹配上
- 发送消息时,两边使用的路由键也要一致
- 队列名称不要求一致
②创建组件
| 所在机房 | 交换机名称 | 路由键 | 队列名称 |
|---|---|---|---|
| 深圳机房(上游) | federated.exchange.demo | routing.key.demo.test | queue.normal.shenzhen |
| 上海机房(下游) | federated.exchange.demo | routing.key.demo.test | queue.normal.shanghai |
创建组件后可以查看一下联邦状态,连接成功的联邦状态如下:

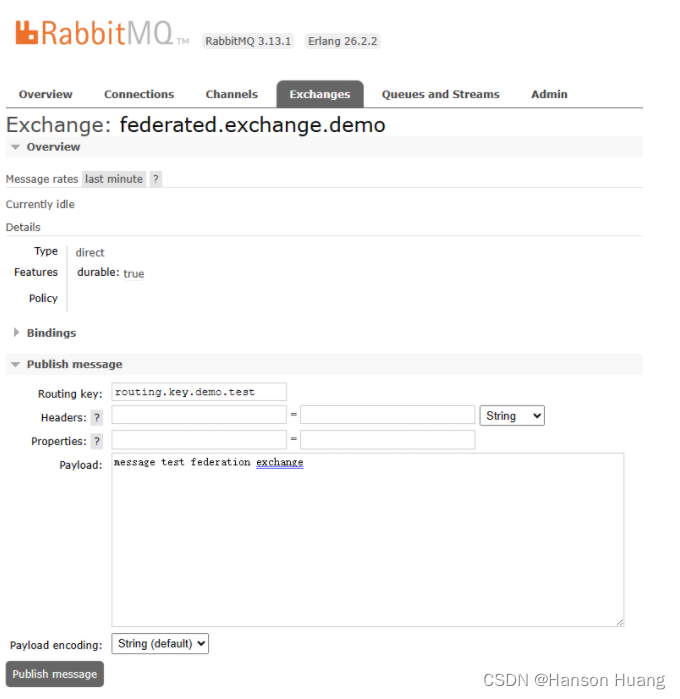
③发布消息执行测试
在上游节点向交换机发布消息:
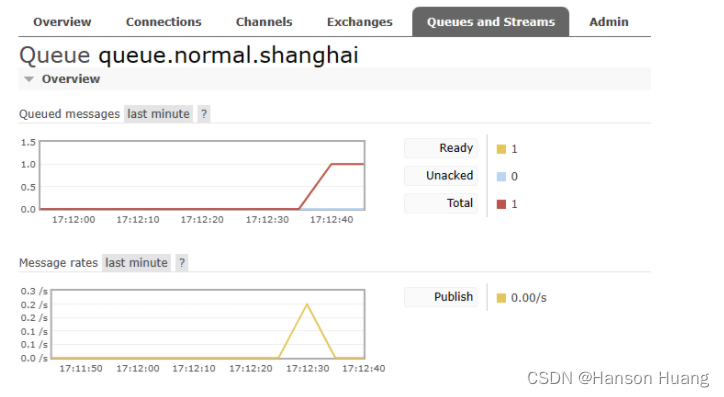
看到下游节点接收到了消息:
4.3、Federation队列
4.3.1、总体说明
Federation队列和Federation交换机的最核心区别就是:
- Federation Police作用在交换机上,就是Federation交换机
- Federation Police作用在队列上,就是Federation队列
4.3.2、创建控制策略
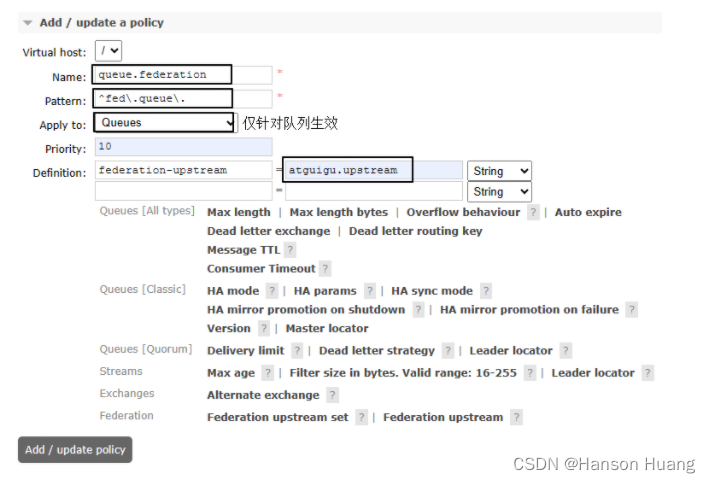
4.3.3、测试
①测试计划
上游节点和下游节点中队列名称是相同的,只是下游队列中的节点附加了联邦策略而已
| 所在机房 | 交换机 | 路由键 | 队列 |
|---|---|---|---|
| 深圳机房(上游) | exchange.normal.shenzhen | routing.key.normal.shenzhen | fed.queue.demo |
| 上海机房(下游) | —— | —— | fed.queue.demo |
②创建组件
上游节点都是常规操作,此处省略。重点需要关注的是下游节点的联邦队列创建时需要指定相关参数:
创建组件后可以查看一下联邦状态,连接成功的联邦状态如下:

③执行测试
在上游节点向交换机发布消息:
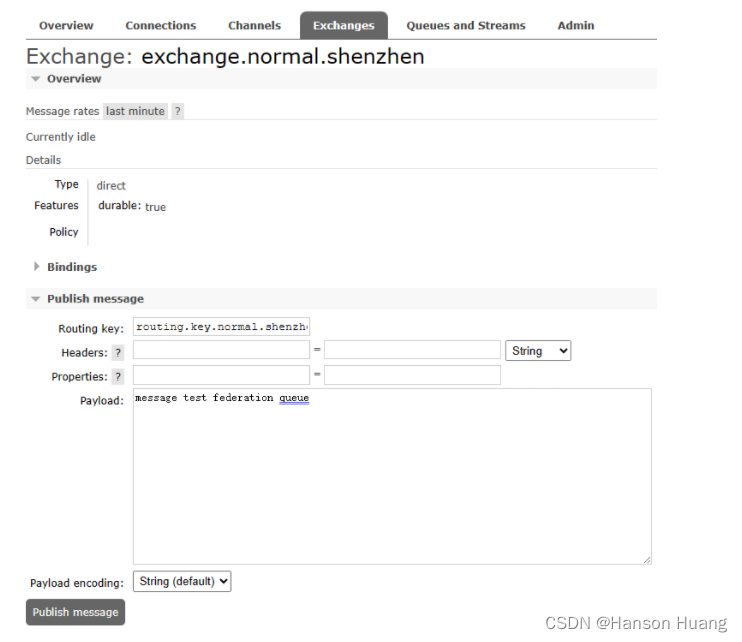
但此时发现下游节点中联邦队列并没有接收到消息,这是为什么呢?这里就体现出了联邦队列和联邦交换机工作逻辑的区别。
对联邦队列来说,如果没有监听联邦队列的消费端程序,它是不会到上游去拉取消息的!
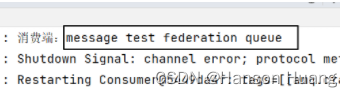
如果有消费端监听联邦队列,那么首先消费联邦队列自身的消息;如果联邦队列为空,这时候才会到上游队列节点中拉取消息。
所以现在的测试效果需要消费端程序配合才能看到:
5、Shovel
5.1、启用Shovel插件
rabbitmq-plugins enable rabbitmq_shovel
rabbitmq-plugins enable rabbitmq_shovel_management
5.2、配置Shovel
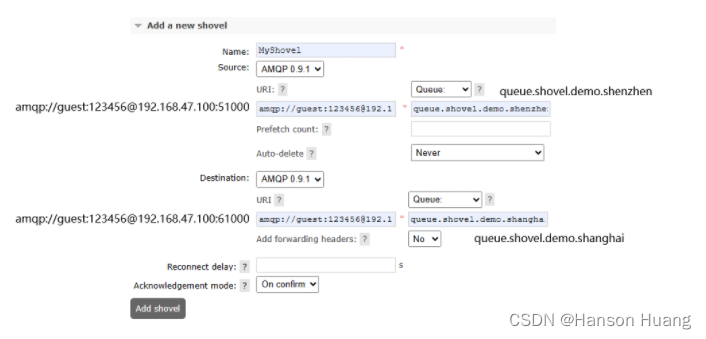
5.3、测试
5.3.1、测试计划
| 节点 | 交换机 | 路由键 | 队列 |
|---|---|---|---|
| 深圳节点 | exchange.shovel.test | exchange.shovel.test | queue.shovel.demo.shenzhen |
| 上海节点 | —— | —— | queue.shovel.demo.shanghai |
5.3.2、测试效果
①发布消息
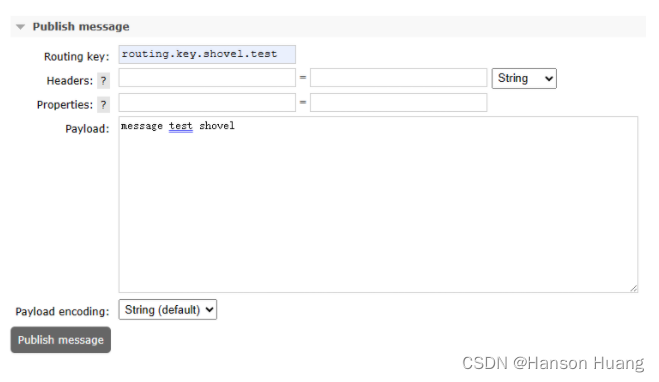
②源节点
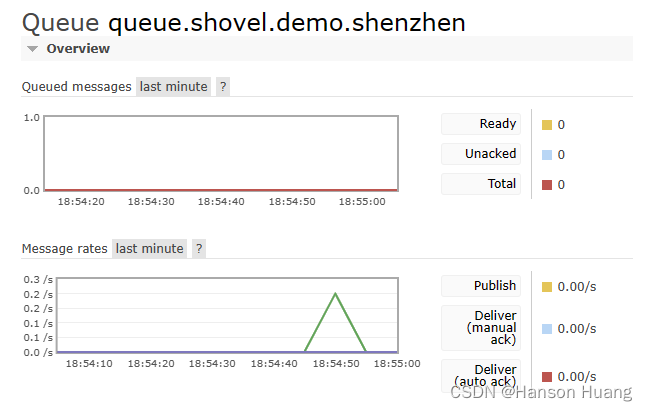
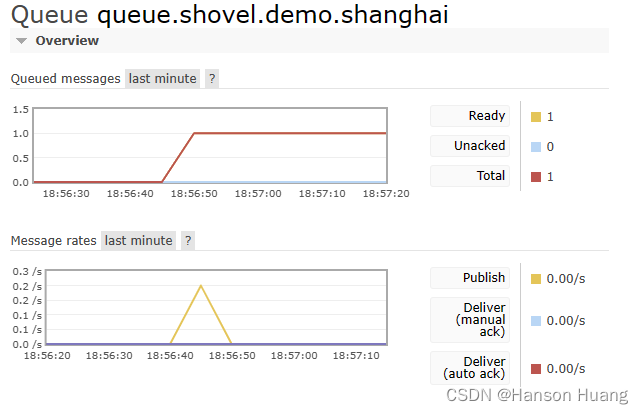
③目标节点
到此,RabbitMQ内容结束,如果对你有帮助,希望给个三连
文章代码:GitHub
如果这篇文章对您,希望可以点赞、收藏支持一下














![[windows] 无拓展名文件设置默认打开方式为记事本](https://img-blog.csdnimg.cn/direct/fd3b0629563a4c5f8572993555dfc305.png)