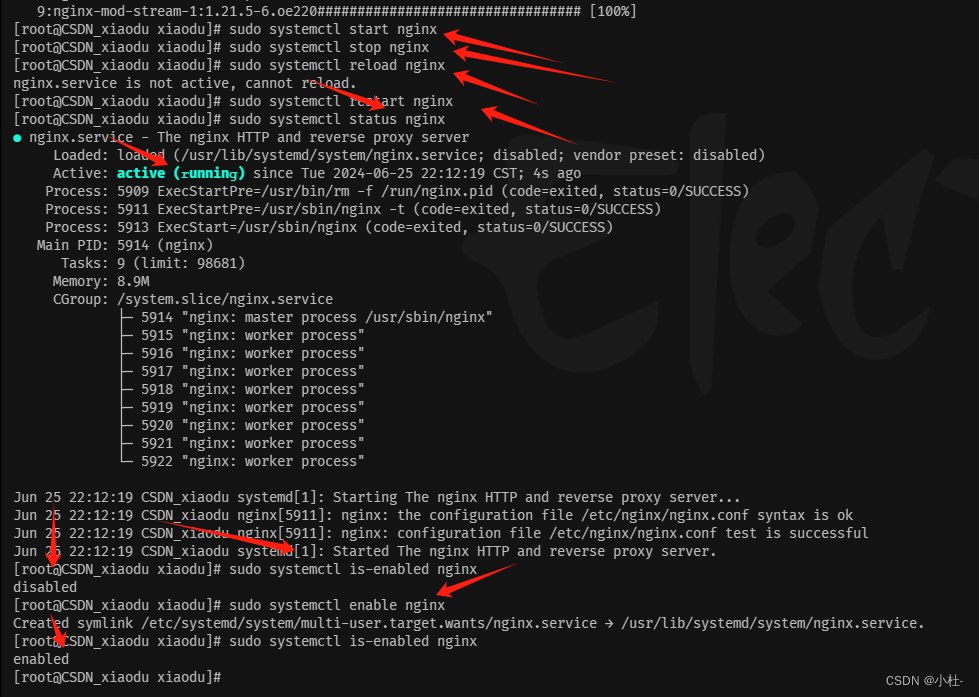
一、前言
人工智能(AI)技术的快速发展为各个领域带来了革命性的变化,其中之一就是人脸识别与图像处理技术。在这之中,AI换脸技术尤其引人注目。这种技术不仅在娱乐行业中得到广泛应用,如电影制作、视频特效等,还在社交媒体上掀起了一股风潮。AI换脸技术不仅可以实现实时的面部替换,还能够在图像和视频中生成高度逼真的换脸效果。
AI换脸技术的核心在于多种机器学习和深度学习模型的结合。它通常涉及几个关键步骤:人脸检测、人脸特征点检测、人脸对齐、换脸处理以及图像增强。每个步骤都依赖于不同的深度学习模型,以确保最终的换脸效果逼真且自然。
本项目实现了一个完整的AI换脸系统,集成了多个深度学习模型,包括YOLO人脸检测模型、68关键点检测模型、ArcFace人脸识别模型、InSwapper换脸模型以及GFPGAN人脸增强模型。通过这些模型的协同工作,我们能够从源图像中提取人脸特征,并将其无缝地替换到目标图像或视频中,生成自然的换脸效果。
接下来,我们将详细介绍这个AI换脸系统的实现细节和工作原理。通过这些介绍,读者可以深入了解AI换脸技术的实际应用和技术实现过程。
二、系统架构与工作流程
2.1 系统整体架构

2.1 主要模块与功能介绍(附代码)
该项目主要由5个主要模块组成,他们分别是人脸检测,人脸关键点检测,人脸对齐,换脸处理和图像增强。
2.1.1 人脸检测
首先我们需要检测源图像和目标图像中的人脸相关数据,获取图像中包含的人脸坐标,即由左上和右下坐标决定的矩阵框,对应的面部关键点和置信度分数。在该部分中所采用的检测模型是YOLOv8,它是最新一代的 YOLO(You Only Look Once)系列模型之一,专为实时目标检测任务而设计。它在精度和速度方面相比之前的模型均有显著提升,非常适用于需要快速响应的应用场景,如视频监控、自动驾驶和增强现实等。所以在实时换脸项目中,YOLOv8显然非常适合用于人脸检测。以下是具体步骤:
-
模型初始化
首先设定模型的参数置信度阈值和iou阈值,之后加载YOLOv8的ONNX 模型,并设置推理会话的选项。需要在初始化中获取模型的输入名称和形状,以便后续进行图像预处理。def __init__(self, modelpath, conf_thres=0.5, iou_thresh=0.4): self.conf_threshold = conf_thres self.iou_threshold = iou_thresh session_option = onnxruntime.SessionOptions() session_option.log_severity_level = 3 self.session = onnxruntime.InferenceSession(modelpath, sess_options=session_option) model_inputs = self.session.get_inputs() self.input_names = [model_inputs[i].name for i in range(len(model_inputs))] self.input_shape = model_inputs[0].shape self.input_height = int(self.input_shape[2]) self.input_width = int(self.input_shape[3]) -
图像预处理
在使用YOLOv8进行推理之前需要先调整输入图像大小并进行边界填充,还需要将图像像素值归一化到 [-1, 1] 的范围,并调整通道顺序,使其符合模型的输入要求。def preprocess(self, srcimg): height, width = srcimg.shape[:2] temp_image = srcimg.copy() if height > self.input_height or width > self.input_width: scale = min(self.input_height / height, self.input_width / width) new_width = int(width * scale) new_height = int(height * scale) temp_image = cv2.resize(srcimg, (new_width, new_height)) self.ratio_height = height / temp_image.shape[0] self.ratio_width = width / temp_image.shape[1] input_img = cv2.copyMakeBorder(temp_image, 0, self.input_height - temp_image.shape[0], 0, self.input_width - temp_image.shape[1], cv2.BORDER_CONSTANT, value=0) input_img = (input_img.astype(np.float32) - 127.5) / 128.0 input_img = input_img.transpose(2, 0, 1) input_img = input_img[np.newaxis, :, :, :] return input_img -
进行推理
在推理过程中,首先要调用 preprocess 方法对输入图像进行预处理获得符合模型要求的输入。再使用 ONNX Runtime 进行推理,得到检测结果。之后调用 postprocess 方法(下面提到)处理输出结果。def detect(self, srcimg): input_tensor = self.preprocess(srcimg) outputs = self.session.run(None, {self.input_names[0]: input_tensor})[0] boxes, kpts, scores = self.postprocess(outputs) return boxes, kpts, scores -
后处理
在执行推理后调用后处理函数解析模型输出,获取边界框、关键点和得分。同时使用非极大值抑制(NMS)去除冗余的检测框。再根据缩放比例调整边界框和关键点的坐标。def postprocess(self, outputs): bounding_box_list, face_landmark5_list, score_list = [], [], [] outputs = np.squeeze(outputs, axis=0).T bounding_box_raw, score_raw, face_landmark_5_raw = np.split(outputs, [4, 5], axis=1) keep_indices = np.where(score_raw > self.conf_threshold)[0] if keep_indices.any(): bounding_box_raw, face_landmark_5_raw, score_raw = bounding_box_raw[keep_indices], face_landmark_5_raw[keep_indices], score_raw[keep_indices] bboxes_wh = bounding_box_raw.copy() bboxes_wh[:, :2] = bounding_box_raw[:, :2] - 0.5 * bounding_box_raw[:, 2:] bboxes_wh *= np.array([[self.ratio_width, self.ratio_height, self.ratio_width, self.ratio_height]]) face_landmark_5_raw *= np.tile(np.array([self.ratio_width, self.ratio_height, 1]), 5).reshape((1, 15)) score_raw = score_raw.flatten() indices = cv2.dnn.NMSBoxes(bboxes_wh.tolist(), score_raw.tolist(), self.conf_threshold, self.iou_threshold) if isinstance(indices, np.ndarray): indices = indices.flatten() if len(indices) > 0: bounding_box_list = list(map(lambda x: np.array([x[0], x[1], x[0] + x[2], x[1] + x[3]], dtype=np.float64), bboxes_wh[indices])) score_list = list(score_raw[indices]) face_landmark5_list = list(face_landmark_5_raw[indices]) return bounding_box_list, face_landmark5_list, score_list -
绘制检测结果
最后将得到的边界框,关键点以及对应的置信度绘制在输入图像上,这里为了方便换脸后前后对比,把输入图像复制了一份,在该副本上进行绘制。得到的结果如下:

2.1.2人脸关键点检测
这里我们来介绍一个可以识别人脸图像关键点的模型,2DFAN4 模型。该模型可以检测人脸上的68个关键点,这些关键点包括眼睛、眉毛、鼻子、嘴巴和面部轮廓等。
- 模型初始化:
和上一步类似,初始化 ONNX 模型会话,设置模型路径并获取模型输入信息。 - 图像预处理
计算缩放比例和平移量,使边界框居中到 256x256 的图像中。使用 warp_face_by_translation 方法进行仿射变换,返回裁剪后的图像和仿射矩阵。转置图像通道顺序,并进行归一化处理。def preprocess(self, srcimg, bounding_box): ''' bounding_box里的数据格式是[xmin. ymin, xmax, ymax] ''' scale = 195 / np.subtract(bounding_box[2:], bounding_box[:2]).max()na translation = (256 - np.add(bounding_box[2:], bounding_box[:2]) * scale) * 0.5 crop_img, affine_matrix = warp_face_by_translation(srcimg, translation, scale, (256, 256)) crop_img = crop_img.transpose(2, 0, 1).astype(np.float32) / 255.0 crop_img = crop_img[np.newaxis, :, :, :] return crop_img, affine_matrix - 人脸关键点检测
调用 preprocess 方法,得到输入张量和仿射矩阵,再使用 ONNX 模型进行推理,得到人脸的 68 个关键点。对关键点进行归一化处理,并应用逆仿射变换,将关键点坐标转换回原图像坐标系中。将 68 个关键点转换为 5 个关键点(这里其实和上面的YOLOv8实现的功能类似)。def detect(self, srcimg, bounding_box): ''' 如果直接crop+resize,最后返回的人脸关键点有偏差 ''' input_tensor, affine_matrix = self.preprocess(srcimg, bounding_box) face_landmark_68 = self.session.run(None, {self.input_names[0]: input_tensor})[0] face_landmark_68 = face_landmark_68[:, :, :2][0] / 64 face_landmark_68 = face_landmark_68.reshape(1, -1, 2) * 256 face_landmark_68 = cv2.transform(face_landmark_68, cv2.invertAffineTransform(affine_matrix)) face_landmark_68 = face_landmark_68.reshape(-1, 2) face_landmark_5of68 = convert_face_landmark_68_to_5(face_landmark_68) return face_landmark_68, face_landmark_5of68 - 绘制检测结果
最后将得到的68个人脸面部关键点绘制在输入图像上。得到的结果如下:

2.1.3 人脸对齐
- 模型初始化
同上一步,所有onnx模型初始化的步骤都是一样的。 - 图像预处理
使用 warp_face_by_face_landmark_5 函数按人脸特征点进行裁剪和对齐。将图像像素值从原始范围 [0, 255] 转换到范围 [-1, 1]。转置图像通道顺序,使其符合模型的输入格式。def preprocess(self, srcimg, face_landmark_5): crop_img, _ = warp_face_by_face_landmark_5(srcimg, face_landmark_5, 'arcface_112_v2', (112, 112)) crop_img = crop_img / 127.5 - 1 crop_img = crop_img[:, :, ::-1].transpose(2, 0, 1).astype(np.float32) crop_img = np.expand_dims(crop_img, axis = 0) return crop_img - 特征向量提取
首先调用 preprocess 方法对输入图像进行预处理。使用 ONNX Runtime 进行推理,提取人脸特征向量(embedding)。对特征向量进行归一化处理,得到归一化后的特征向量(normed_embedding)。def detect(self, srcimg, face_landmark_5): input_tensor = self.preprocess(srcimg, face_landmark_5) # Perform inference on the image embedding = self.session.run(None, {self.input_names[0]: input_tensor})[0] embedding = embedding.ravel() normed_embedding = embedding / np.linalg.norm(embedding) return embedding, normed_embedding
该模型的主要功能是通过人脸对齐来提取人脸特征向量。人脸对齐是人脸识别任务中的关键步骤,它有助于将输入的人脸图像标准化,使其在不同的拍摄角度、光照和表情变化下具有一致的表示。
2.1.4换脸处理
前面做了那么多处理,终于我们来到了关键步骤:换脸处理!此处用到的模型是inswapper_128,该模型通过将源图像中的人脸特征嵌入到目标图像中的人脸区域,实现自然逼真的换脸效果。
- 模型初始化
继续同样地加载 ONNX 模型,并创建 ONNX Runtime 会话,并获取模型的输入名称和输入形状。和之前不同的是这一步需要加载模型矩阵,用于对源人脸特征向量进行变换。def __init__(self, modelpath): # Initialize model session_option = onnxruntime.SessionOptions() session_option.log_severity_level = 3 self.session = onnxruntime.InferenceSession(modelpath, sess_options=session_option) model_inputs = self.session.get_inputs() self.input_names = [model_inputs[i].name for i in range(len(model_inputs))] self.input_shape = model_inputs[0].shape self.input_height = int(self.input_shape[2]) self.input_width = int(self.input_shape[3]) self.model_matrix = np.load('model_matrix.npy') - 图像处理和换脸
- 图像预处理
- 人脸对齐:使用 warp_face_by_face_landmark_5 函数将目标图像按人脸特征点进行裁剪和对齐。
- 创建遮罩:使用 create_static_box_mask 创建静态盒子遮罩,方便后续将换脸结果融合回原图像。
- 归一化处理:将图像像素值从原始范围 [0, 255] 转换到 [0, 1],并进行标准化处理,使其符合模型的输入要求。
- 特征向量变换
- 源人脸特征变换:将源人脸特征向量进行变换,并归一化处理,以符合模型的输入要求。
- 模型推理
- 换脸推理:使用 ONNX Runtime 对预处理后的图像和源人脸特征向量进行推理,得到换脸结果。
- 结果处理:将换脸结果图像转换回原始图像格式。
- 融合换脸结果
- 融合处理:将换脸结果图像融合回原图像中,确保换脸区域自然逼真。
def process(self, target_img, source_face_embedding, target_landmark_5): ###preprocess crop_img, affine_matrix = warp_face_by_face_landmark_5(target_img, target_landmark_5, 'arcface_128_v2', (128, 128)) crop_mask_list = [] box_mask = create_static_box_mask((crop_img.shape[1],crop_img.shape[0]), FACE_MASK_BLUR, FACE_MASK_PADDING) crop_mask_list.append(box_mask) crop_img = crop_img[:, :, ::-1].astype(np.float32) / 255.0 crop_img = (crop_img - INSWAPPER_128_MODEL_MEAN) / INSWAPPER_128_MODEL_STD crop_img = np.expand_dims(crop_img.transpose(2, 0, 1), axis = 0).astype(np.float32) source_embedding = source_face_embedding.reshape((1, -1)) source_embedding = np.dot(source_embedding, self.model_matrix) / np.linalg.norm(source_embedding) ###Perform inference on the image result = self.session.run(None, {'target':crop_img, 'source':source_embedding})[0][0] ###normalize_crop_frame result = result.transpose(1, 2, 0) result = (result * 255.0).round() result = result[:, :, ::-1] crop_mask = np.minimum.reduce(crop_mask_list).clip(0, 1) dstimg = paste_back(target_img, result, crop_mask, affine_matrix) return dstimg
- 图像预处理
2.1.5图像增强
此处采用的模型是gfpgan_1.4,用于人脸图像增强,旨在提高图像的清晰度和质量,使得换脸效果更为自然逼真。
- 模型初始化
同上上一步一致。 - 图像处理和增强
- 图像预处理
- 人脸对齐:使用 warp_face_by_face_landmark_5 函数将目标图像按人脸特征点进行裁剪和对齐。
- 创建遮罩:使用 create_static_box_mask 创建静态盒子遮罩,方便后续将增强结果融合回原图像。
- 归一化处理:将图像像素值从原始范围 [0, 255] 转换到 [-1, 1],这有助于提高模型的性能。
- 模型推理
- 图像增强推理:使用 ONNX Runtime 对预处理后的图像进行推理,得到增强后的图像。
- 结果处理:将增强后的图像从 [-1, 1] 转换回 [0, 255] 的范围,并转换为 uint8 类型。(这一步是不是量化?)
- 融合增强结果
- 融合处理:将增强后的图像融合回原图像中,确保增强区域自然逼真。
def process(self, target_img, target_landmark_5): ###preprocess crop_img, affine_matrix = warp_face_by_face_landmark_5(target_img, target_landmark_5, 'ffhq_512', (512, 512)) box_mask = create_static_box_mask((crop_img.shape[1],crop_img.shape[0]), FACE_MASK_BLUR, FACE_MASK_PADDING) crop_mask_list = [box_mask] crop_img = crop_img[:, :, ::-1].astype(np.float32) / 255.0 crop_img = (crop_img - 0.5) / 0.5 crop_img = np.expand_dims(crop_img.transpose(2, 0, 1), axis = 0).astype(np.float32) ###Perform inference on the image result = self.session.run(None, {'input':crop_img})[0][0] ###normalize_crop_frame result = np.clip(result, -1, 1) result = (result + 1) / 2 result = result.transpose(1, 2, 0) result = (result * 255.0).round() result = result.astype(np.uint8)[:, :, ::-1] crop_mask = np.minimum.reduce(crop_mask_list).clip(0, 1) paste_frame = paste_back(target_img, result, crop_mask, affine_matrix) dstimg = blend_frame(target_img, paste_frame) return dstimg
最终结果展示
- 源图片

- 目标图片

- 最终结果

四、结论
本项目通过使用多个先进的深度学习模型,实现了高效且逼真的AI换脸功能。首先,利用YOLOface_8n模型进行人脸检测,并通过face_68_landmarks模型获取面部68个关键点,确保了检测结果的精确性和一致性。接着,arcface_w600k_r50.onnx模型提取源人脸的高维特征向量,通过对齐和归一化处理,确保特征向量的稳定性和准确性。然后,inswapper_128.onnx模型负责将源人脸特征嵌入到目标人脸图像中,实现自然逼真的人脸替换。最后,使用gfpgan_1.4.onnx模型对换脸结果进行图像增强和修复,进一步提高图像的清晰度和细节,使最终结果更加自然逼真。本项目展示了AI换脸技术的强大潜力和广泛应用前景,为影视制作、社交媒体和隐私保护等领域提供了有力的技术支持




![[leetcode]rotate-array 轮转数组](https://img-blog.csdnimg.cn/direct/042e573364104ac8b972c8fc728593cc.png)