在 2017 年的 WWDC 上,苹果发布了许多令人兴奋的框架和 API 供我们开发人员使用。在所有新框架中,最受欢迎的框架之一肯定是Core ML。Core ML 是一个可用于将机器学习模型集成到您的应用程序中的框架。Core ML 最好的部分是您不需要有关神经网络或机器学习的广泛知识。Core ML 的另一个额外功能是,只要将其转换为 Core ML 模型,您就可以使用预先训练的数据模型。出于演示目的,我们将使用 Apple 开发者网站上提供的 Core ML 模型。事不宜迟,让我们开始学习 Core ML。
什么是 Core ML
Core ML 可让您将各种类型的机器学习模型集成到您的应用中。除了支持具有 30 多种层类型的广泛深度学习之外,它还支持标准模型,例如树集成、SVM 和广义线性模型。由于 Core ML 建立在 Metal 和 Accelerate 等低级技术之上,因此它可无缝利用 CPU 和 GPU 来提供最高的性能和效率。您可以在设备上运行机器学习模型,因此数据无需离开设备即可进行分析。
- Apple 关于 Core ML 的官方文档
Core ML 是一个全新的机器学习框架,在2017年的 WWDC 上发布,与 iOS 11 一起发布。借助 Core ML,您可以将机器学习模型集成到您的应用中。让我们回顾一下。什么是机器学习?简而言之,机器学习是一种让计算机无需明确编程即可学习的应用。训练好的模型是将机器学习算法与一组训练数据相结合的结果。
作为应用程序开发人员,我们主要关心的是如何将这个模型应用到我们的应用程序中来做一些非常有趣的事情。幸运的是,借助 Core ML,Apple 可以轻松将不同的机器学习模型集成到我们的应用程序中。这为开发人员构建图像识别、自然语言处理 (NLP)、文本预测等功能开辟了许多可能性。
现在你可能想知道将这种类型的 AI 引入你的应用程序是否非常困难。这是最好的部分。Core ML 非常易于使用。在本教程中,你将看到我们只需要 10 行代码即可将 Core ML 集成到我们的应用程序中。
很酷吧?让我们开始吧。
演示应用程序概述
我们尝试制作的应用程序相当简单。我们的应用程序让用户可以拍摄某物的照片或从照片库中选择一张照片。然后,机器学习算法将尝试预测图片中的物体是什么。结果可能并不完美,但您将了解如何在应用程序中应用 Core ML。

入门
首先,转到 Xcode 并创建一个新项目。为该项目选择单视图应用程序模板,并确保语言设置为 Swift。

创建用户界面
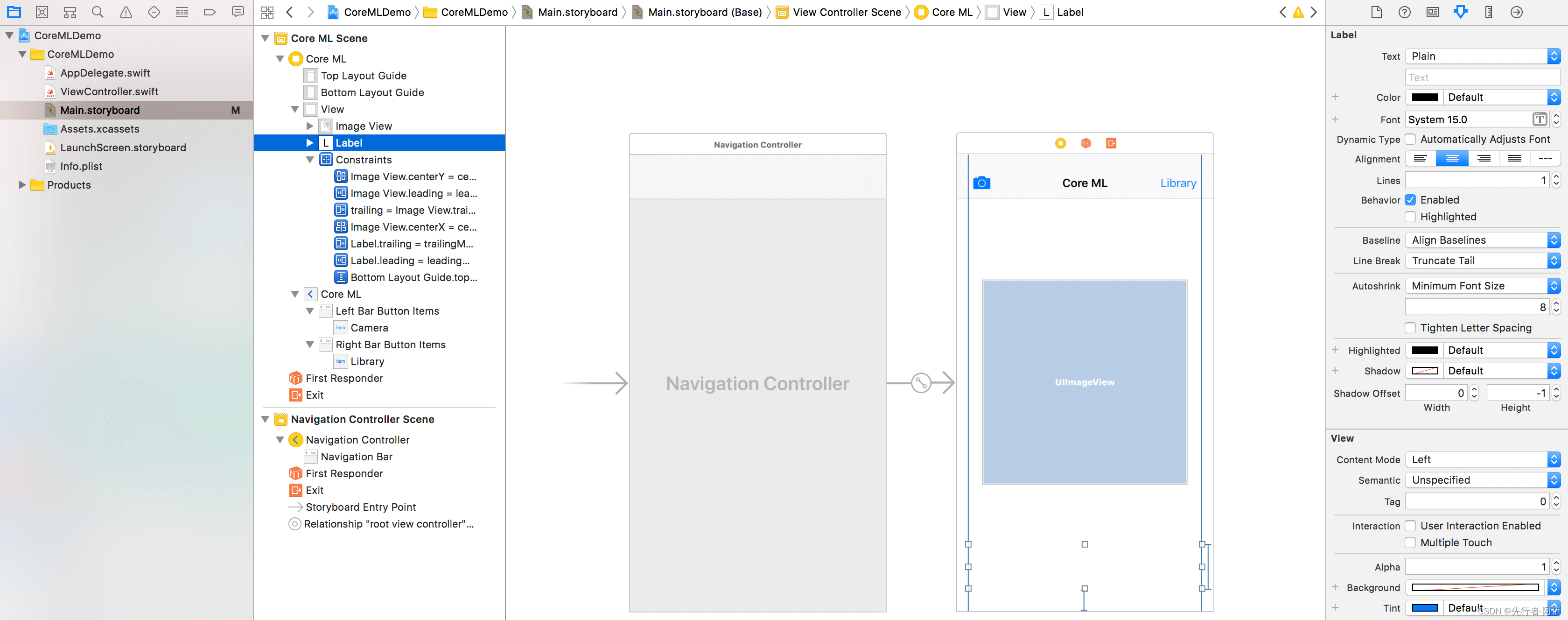
让我们开始吧!我们要做的第一件事是前往并向Main.storyboard视图添加几个 UI 元素。在情节提要中选择视图控制器,然后转到 Xcode 菜单。点击Editor-> Embed In-> Navigation Controller。完成后,您应该会看到导航栏出现在视图顶部。将导航栏命名为 Core ML(或您认为合适的任何名称)。

接下来,拖入两个栏按钮项:导航栏标题两侧各一个。对于左侧的栏按钮项,转到并将Attributes Inspector更改System Item为“相机”。在右侧栏按钮项上,将其命名为“库”。这两个按钮让用户从自己的照片库中选择一张照片或使用相机拍摄一张照片。
最后需要的两个对象是 aUILabel和 a UIImageView。将 置于UIImageView视图的中央。将图像视图的宽度和高度更改为 ,使其299x299成为正方形。现在对于 UILabel,将其一直放置到视图的底部,并将其拉伸,使其接触两端。这样就完成了应用程序的 UI。
虽然我没有介绍如何自动布局这些视图,但强烈建议您尝试这样做以避免任何错位的视图。如果您无法做到这一点,请在您将用于运行该应用程序的设备上构建故事板。
实现相机和照片库功能
现在我们已经设计了 UI,让我们开始实现。我们将在本节中实现库和相机按钮。在 中ViewController.swift,首先采用UINavigationControllerDelegate类所需的协议UIImagePickerController。
class ViewController: UIViewController, UINavigationControllerDelegate
接下来,您需要创建单击栏按钮项的相应操作。现在在ViewController类中插入以下操作方法:
import UIKit
class ViewController: UIViewController, UINavigationControllerDelegate {
@IBOutlet weak var imageView: UIImageView!
@IBOutlet weak var classifier: UILabel!
override func viewDidLoad() {
super.viewDidLoad()
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
}
}接下来,您需要创建单击栏按钮项的相应操作。现在在ViewController类中插入以下操作方法:
@IBAction func camera(_ sender: Any) {
if !UIImagePickerController.isSourceTypeAvailable(.camera) {
return
}
let cameraPicker = UIImagePickerController()
cameraPicker.delegate = self
cameraPicker.sourceType = .camera
cameraPicker.allowsEditing = false
present(cameraPicker, animated: true)
}
@IBAction func openLibrary(_ sender: Any) {
let picker = UIImagePickerController()
picker.allowsEditing = false
picker.delegate = self
picker.sourceType = .photoLibrary
present(picker, animated: true)
}总结一下我们在每个操作中所做的工作,我们创建了一个常量,即UIImagePickerController。然后我们确保用户无法编辑拍摄的照片(无论是从照片库还是相机中)。然后我们将委托设置为其自身。最后,我们将呈现UIImagePickerController给用户。
因为我们没有将UIImagePickerControllerDelegate类方法添加到ViewController.swift,所以我们会收到错误。我们将使用扩展来采用委托:
extension ViewController: UIImagePickerControllerDelegate {
func imagePickerControllerDidCancel(_ picker: UIImagePickerController) {
dismiss(animated: true, completion: nil)
}
}如果用户取消拍摄图像,上面的代码将处理应用程序。它还将类方法分配UIImagePickerControllerDelegate给我们的 Swift 文件。您的代码现在应该看起来像这样。
import UIKit
class ViewController: UIViewController, UINavigationControllerDelegate {
@IBOutlet weak var imageView: UIImageView!
@IBOutlet weak var classifier: UILabel!
override func viewDidLoad() {
super.viewDidLoad()
// Do any additional setup after loading the view, typically from a nib.
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
@IBAction func camera(_ sender: Any) {
if !UIImagePickerController.isSourceTypeAvailable(.camera) {
return
}
let cameraPicker = UIImagePickerController()
cameraPicker.delegate = self
cameraPicker.sourceType = .camera
cameraPicker.allowsEditing = false
present(cameraPicker, animated: true)
}
@IBAction func openLibrary(_ sender: Any) {
let picker = UIImagePickerController()
picker.allowsEditing = false
picker.delegate = self
picker.sourceType = .photoLibrary
present(picker, animated: true)
}
}
extension ViewController: UIImagePickerControllerDelegate {
func imagePickerControllerDidCancel(_ picker: UIImagePickerController) {
dismiss(animated: true, completion: nil)
}
}确保返回故事板并连接所有出口变量和操作方法。
要访问你的相机和照片库,你还有最后一件事要做。转到你的Info.plist和两个条目:隐私 - 相机使用说明和隐私 - 照片库使用说明。从 iOS 10 开始,你需要指定你的应用需要访问相机和照片库的原因。

好的,就是这样。现在您可以开始本教程的核心部分了。
集成核心 ML 数据模型
现在,让我们稍微转换一下思路,将 Core ML 数据模型集成到我们的应用中。如前所述,我们需要一个预先训练的模型才能与 Core ML 配合使用。您可以构建自己的模型,但在本演示中,我们将使用 Apple 开发者网站上提供的预先训练的模型。
进入苹果的机器学习开发者网站,一直滚动到页面底部。你会发现 4 个预先训练好的 Core ML 模型。

在本教程中,我们使用Inception v3模型,但您可以随意尝试其他三个模型。下载Inception v3模型后,将其添加到 Xcode 项目中并查看显示的内容。
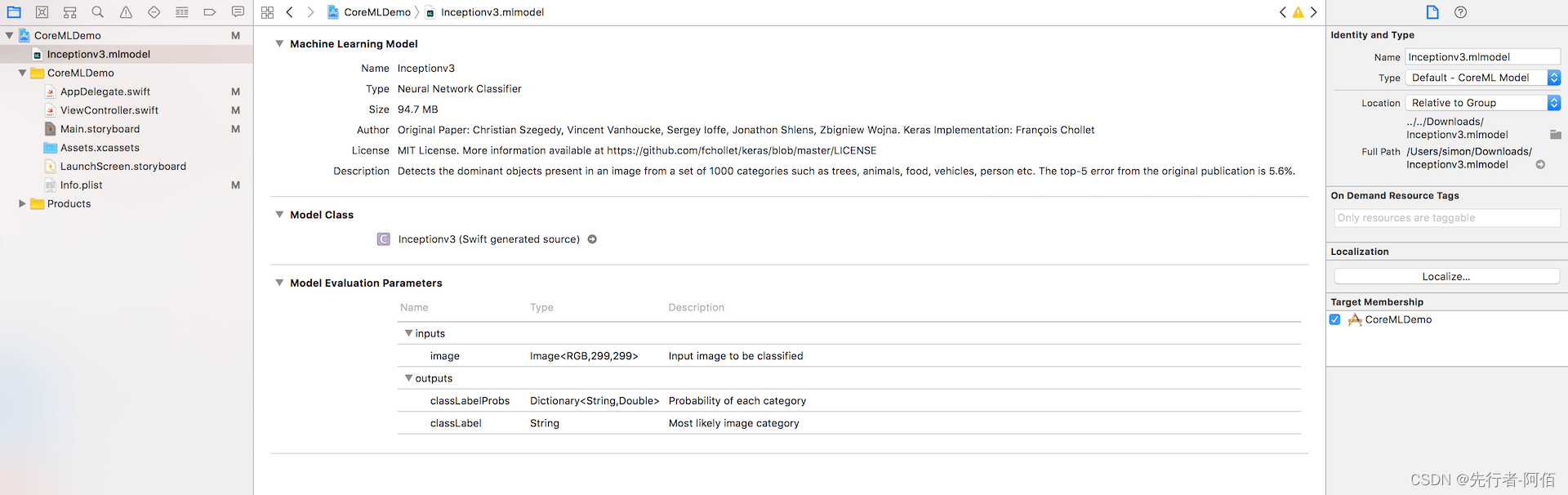
在上面的屏幕中,您可以看到数据模型的类型,即神经网络分类器。您必须注意的其他信息是模型评估参数。它告诉您模型所接受的输入以及模型返回的输出。这里它接受一个 299×299 的图像,并返回最相似的类别以及每个类别的概率。
您会注意到的另一件事是模型类。这是Inceptionv3从机器学习模型生成的模型类(),我们可以直接在代码中使用。如果单击旁边的箭头Inceptionv3,您可以看到该类的源代码。

现在,让我们在代码中添加模型。回到ViewController.swift。首先,在最开始导入 CoreML 框架:
import CoreML 接下来,model在类中为模型声明一个变量Inceptionv3,并在方法中初始化它viewWillAppear():
var model: Inceptionv3!
override func viewWillAppear(_ animated: Bool) {
model = Inceptionv3()
}我知道你在想什么。
“好吧,Sai,我们为什么不早点初始化这个模型呢?”
“在函数中定义它有什么意义viewWillAppear?”
好吧,亲爱的朋友们,重点是,当您的应用程序尝试识别图像中的物体时,速度会快得多。
现在,如果我们回过头来看Inceptionv3.mlmodel,我们会看到该模型唯一需要的输入是尺寸为的图像299x299。那么我们如何将图像转换为这些尺寸呢?好吧,这就是我们接下来要解决的问题。
转换图像
在 的扩展中ViewController.swift,更新代码如下。我们实现imagePickerController(_:didFinishPickingMediaWithInfo)处理选定图像的方法:
extension ViewController: UIImagePickerControllerDelegate {
func imagePickerControllerDidCancel(_ picker: UIImagePickerController) {
dismiss(animated: true, completion: nil)
}
func imagePickerController(_ picker: UIImagePickerController, didFinishPickingMediaWithInfo info: [String : Any]) {
picker.dismiss(animated: true)
classifier.text = "Analyzing Image..."
guard let image = info["UIImagePickerControllerOriginalImage"] as? UIImage else {
return
}
UIGraphicsBeginImageContextWithOptions(CGSize(width: 299, height: 299), true, 2.0)
image.draw(in: CGRect(x: 0, y: 0, width: 299, height: 299))
let newImage = UIGraphicsGetImageFromCurrentImageContext()!
UIGraphicsEndImageContext()
let attrs = [kCVPixelBufferCGImageCompatibilityKey: kCFBooleanTrue, kCVPixelBufferCGBitmapContextCompatibilityKey: kCFBooleanTrue] as CFDictionary
var pixelBuffer : CVPixelBuffer?
let status = CVPixelBufferCreate(kCFAllocatorDefault, Int(newImage.size.width), Int(newImage.size.height), kCVPixelFormatType_32ARGB, attrs, &pixelBuffer)
guard (status == kCVReturnSuccess) else {
return
}
CVPixelBufferLockBaseAddress(pixelBuffer!, CVPixelBufferLockFlags(rawValue: 0))
let pixelData = CVPixelBufferGetBaseAddress(pixelBuffer!)
let rgbColorSpace = CGColorSpaceCreateDeviceRGB()
let context = CGContext(data: pixelData, width: Int(newImage.size.width), height: Int(newImage.size.height), bitsPerComponent: 8, bytesPerRow: CVPixelBufferGetBytesPerRow(pixelBuffer!), space: rgbColorSpace, bitmapInfo: CGImageAlphaInfo.noneSkipFirst.rawValue) //3
context?.translateBy(x: 0, y: newImage.size.height)
context?.scaleBy(x: 1.0, y: -1.0)
UIGraphicsPushContext(context!)
newImage.draw(in: CGRect(x: 0, y: 0, width: newImage.size.width, height: newImage.size.height))
UIGraphicsPopContext()
CVPixelBufferUnlockBaseAddress(pixelBuffer!, CVPixelBufferLockFlags(rawValue: 0))
imageView.image = newImage
}
}突出显示的代码的作用是:
- 第 7-11 行:在该方法的前几行中,我们从
info字典中检索选定的图像(使用UIImagePickerControllerOriginalImage键)。UIImagePickerController一旦选择了图像,我们也会关闭。 - 第 13-16 行:由于我们的模型仅接受尺寸为 的图像
299x299,因此我们将图像转换为正方形。然后我们将正方形图像分配给另一个常数newImage。 - 第 18-23 行:现在,我们将 转换为
newImage。CVPixelBuffer对于不熟悉 的人来说CVPixelBuffer,它基本上是一个将像素保存在主内存中的图像缓冲区。您可以CVPixelBuffers在此处了解更多信息。 - 第 31-32 行:然后,我们获取图像中存在的所有像素,并将它们转换为与设备相关的 RGB 颜色空间。然后,通过将所有这些数据创建为
CGContext,我们可以在需要渲染(或更改)其某些底层属性时轻松调用它。这就是我们在接下来的两行代码中通过平移和缩放图像所做的事情。 - 第 34-38 行:最后,我们将图形上下文变为当前上下文,渲染图像,从顶部堆栈中移除上下文,并设置
imageView.image为newImage。
现在,如果您不理解大部分代码,不用担心。这确实是一些高级Core Image代码,超出了本教程的范围。您需要知道的是,我们将拍摄的图像转换为数据模型可以接受的内容。我建议您尝试一下这些数字,看看结果如何,以便更好地理解。
使用 Core ML
无论如何,让我们把焦点转移回 Core ML。我们使用 Inceptionv3 模型来执行对象识别。使用 Core ML,要做到这一点,我们只需要几行代码。将以下代码片段粘贴到该imageView.image = newImage行下方。
guard let prediction = try? model.prediction(image: pixelBuffer!) else {
return
}
classifier.text = "I think this is a \(prediction.classLabel)."就是这样!该类Inceptionv3有一个生成的方法prediction(image:)来预测给定图像中的对象。在这里,我们将该方法与变量(即调整大小后的图像)一起传递。一旦返回pixelBuffer类型的预测,我们就会更新标签以将其文本设置为已识别的内容。Stringclassifier
现在是时候测试应用程序了!在模拟器或您的 iPhone(安装了 iOS 11 测试版)中构建并运行应用程序。从您的照片库中选择一张照片或使用相机拍摄一张照片。应用程序会告诉您图片的内容。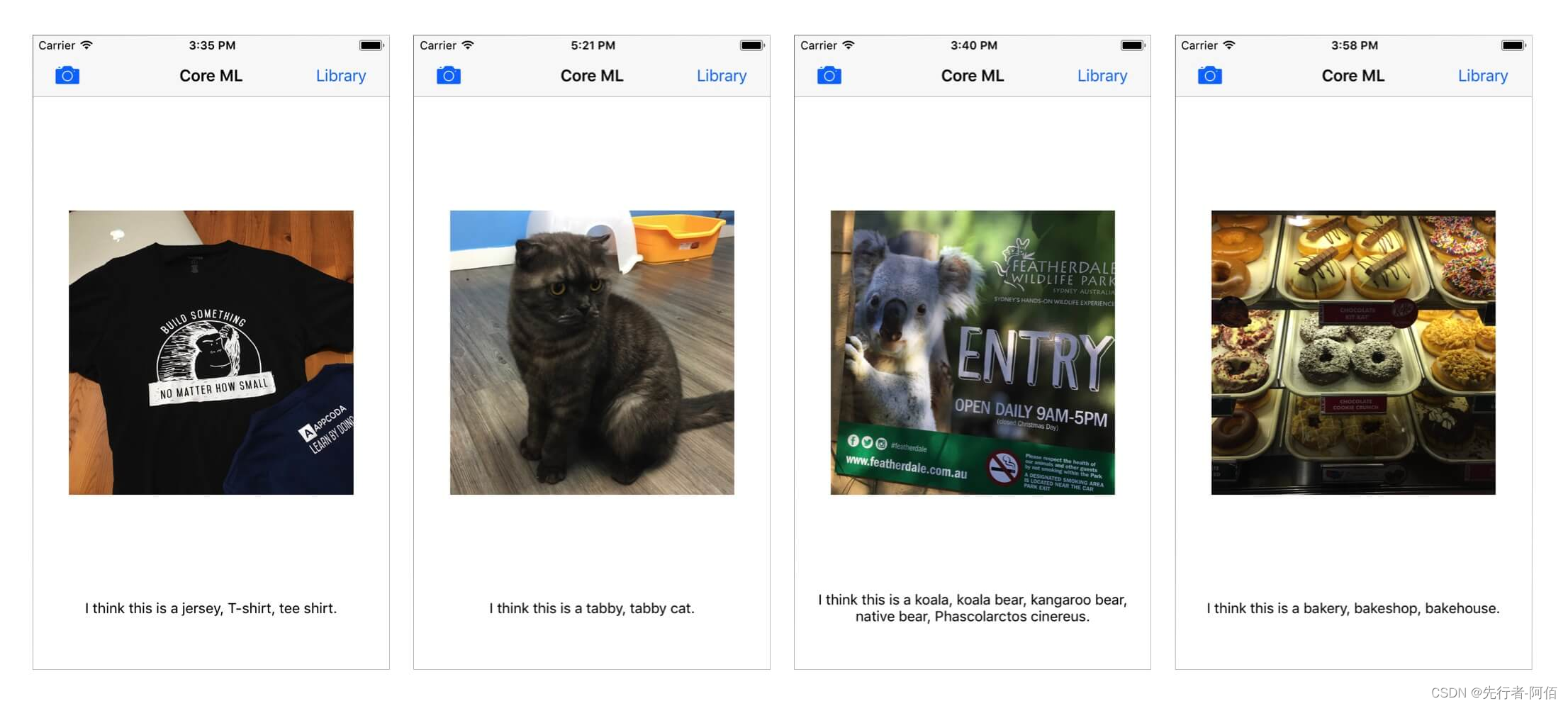
在测试应用时,您可能会注意到应用无法正确预测您指向的内容。这不是代码的问题,而是训练模型的问题。
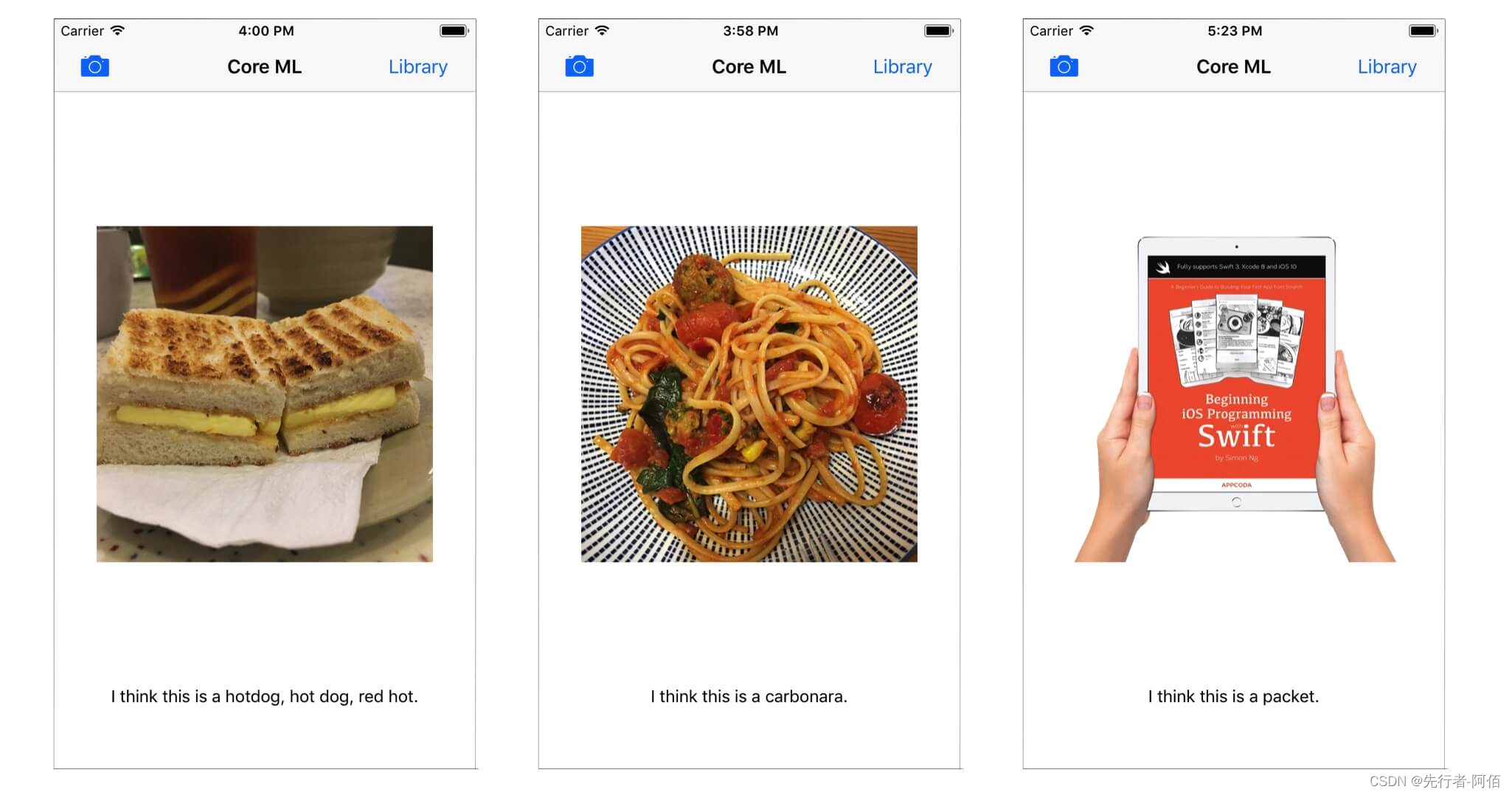
有关 Core ML 框架的更多详细信息,您可以参考官方 Core ML 文档。您还可以参考 Apple 在 WWDC 2017 期间关于 Core ML 的会议:
- Core ML 简介
- 深入了解核心机器学习
您对 Core ML 有什么看法?请给我留言并告知我。