文章目录
- Set接口 (HashSet 、LinkedHashSet)
- HashSet底层原理(重点理解)
Set接口 (HashSet 、LinkedHashSet)
无序不重复
- HashSet集合
HashSet 是根据对象的哈希值来确定元素在集合中的存储位置,因此具有良好的存取和查找性能。
public class HashSetDemo {
public static void main(String[] args) {
HashSet<String> set = new HashSet<>();
set.add("xiaoming");
set.add("xiaohu");
set.add("xiaohong");
set.add("xiaozhang");
set.add("xiaohu");
for (String s : set) {
System.out.println(s);
}
}
}
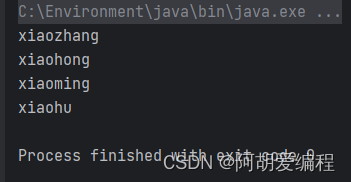
通过上述实验,我们可以看到我们存储元素的顺序时xiaoming、xiaohu、xiaohong、xiaozhang、xiaohu,但是我们遍历集合的顺序确实,xiaozhang、xiaohong、xiaoming、xiaohu这表示当我们将数据存储到HashSet集合中的时候是无序的,其中我们存储了俩个xiaohu,但是集合中却只存在一个xiaohu,这表示,元素是不允许重复的。
HashSet底层原理(重点理解)
HashSet是根据hash值来对数据进行存储的。因此我们需要了解hash表。
- JDK8 之前的哈希表是采取 数组 + 链表 来实现的
- JDK8 之后的哈希表是采取 数组 + 链表 + 红黑树 来实现的
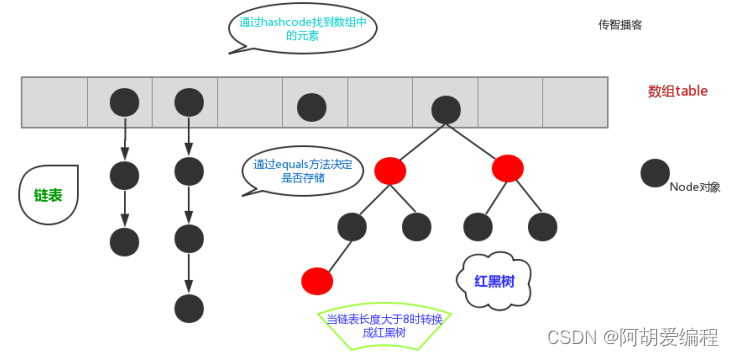
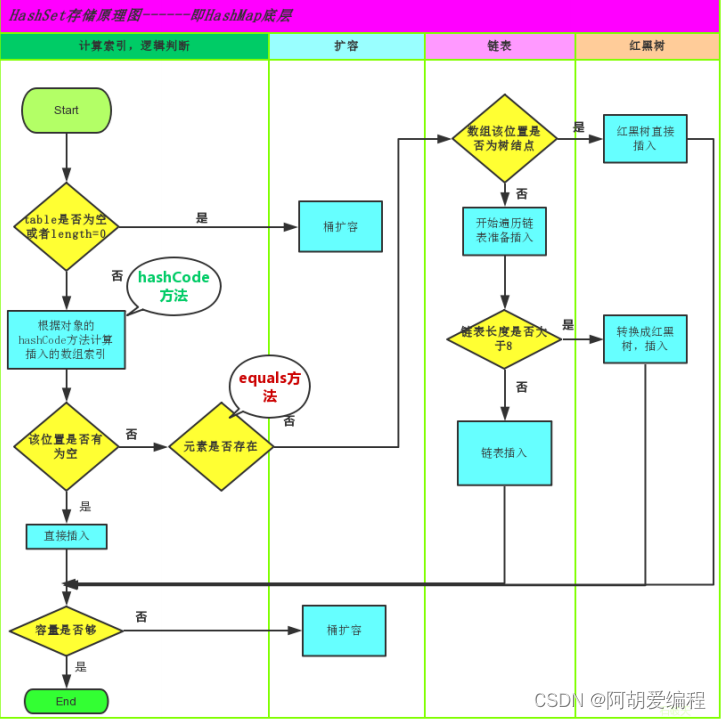
解释操作流程: - 当我们向HashSet中存储一个元素的时候,我们会先判断数组table是否为空或者length是否为0,如果为true就先进行桶扩容,否则就根据对象的hashCode()方法发来计算插入数组的索引值。
- 然后判断该数组索引上是否为空
- 如果为true,就直接插入该元素,并且对数组容量进行判断,如果容量不足就进行桶扩容,然后程序结束。
- 如果为false,就判断插入的元素是否存在,存在则不再进行插入,不存在则判断该位置是否为树的根结点,如果为true则直接进行红黑树插入,否则开始遍历链表准备插入。
- 插入之前判断链表的长度是否大于8,如果大于8就将链表转换为红黑树进行插入,如果小于8就直接进行链表插入。插入时判断数组容量是否够,如果不够就先进行桶扩容再进行插入,然后程序结束。
注意:
给HashSet中存放自定义类型元素时,需要重写对象中的hashCode和equals方法,建立自己的比较方式,才能保证HashSet集合中的对象唯一。
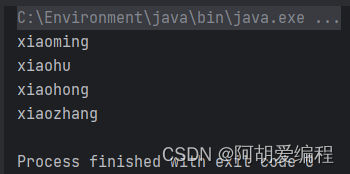
- LinkedHashSet集合
想要保证集合中的元素不重复,并且元素存储的顺序是有序的就使用该集合。
public static void main(String[] args) {
LinkedHashSet<String> set = new LinkedHashSet<>();
set.add("xiaoming");
set.add("xiaohu");
set.add("xiaohong");
set.add("xiaozhang");
set.add("xiaohu");
for (String s : set) {
System.out.println(s);
}
}
欢迎java热爱者了解文章,作者将会持续更新中,期待各位友友的关注和收藏。。。