文章目录
- 引言
- Redis是什么
- 正文
- 对象
- String字符串
- 面试重点
- List
- 面试考点
- 压缩列表ZipList
- 面试题
- Set
- 面试题讲解
- Hash
- 面试重点
- HASHTABLE底层
- 面试考点
- 跳表
- 面试重点
- ZSET有序链表
- 面试重点
- 总结
引言
- 在项目和redis之间,我犹豫了一下,觉得还是了解学习一下redis,毕竟这个不会,项目哪里就缺了一块,这里先整体过完一遍。
Redis是什么
核心
- 内存存储,KV存储
解决什么问题
- 常用于缓存、消息中转、数据流引擎
Base理论
- 基本可用
- 软状态
- 最终一致性
正文
对象
- 常见的五个对象
- String字符串
- List列表
- Set集合
- Hash哈希表
- Sorted Set有序集合
String字符串

- 对象编码的三种格式
- INT
- EMBSTR:字符串长度比较小的时候,有一个对象的头和对象的内容,分配的时候在一块
- RAW:字节头和内容是分开的,适合存储大容量数据
是以阈值来进行判断是使用EMBSTR还是RAW保存
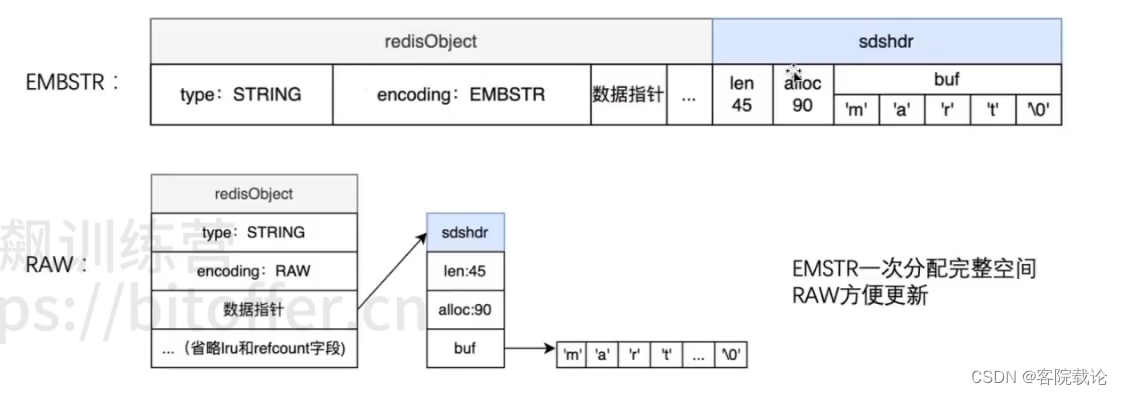
- sdshdr简单动态字符串

- 1MB取一个最小值


面试重点
EMBSTR一次性分配空间
- 重新分配,整体需要再分配,所以EMBSTR是只读的,任何写操作之后的EMBSTR都会变成RAW
- 主要是改过的,都是易变的
set一个已有的数据会发生什么?
- 同类型的话,会覆盖键或者擦除数据
浮点型数据在string会用什么表示
- 将浮点数转换为字符串保存的值,浮点数不是INT
string可以有多大
- Redis字符串最大是512MB
Redis字符串是怎么实现的?
- INT,EMBSTR,RAW,阈值是44
SDS有什么用?
- Redis是使用C语言写的
- 1.SDS包含已使用容量字段,0(1)时间快速返回有字符串长度,相比之下,C原生字符串需要O(n)。
- 2.有预留空间,在扩容时如果预留空间足够,就不用再重新分配内存,节约性能,缩容时也可以将减少的空间先保留下来,后续可以再使用。
- 3.不再以’0’作为字符串结束判断标准,二进制安全,可以很方便地存储一些二进制数据。
List

异步删除
- del命令会同步删除,阻塞客户,直到删除完成
- unlink异步删除命令,只会取消key在键空间中的关联,然后再删除

-
压缩链表ZipList

-
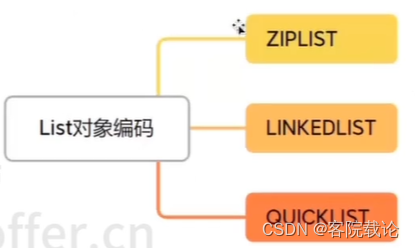
链表LiskedList

-
快表Quicklist

面试考点
怎么获得List指定范围内的数据
- 使用Lrange命令,参数为start和stop,lrange是从0开始的
删除特定的元素
LREM testlist key 1;
底层编码方式是什么样的?
- List对象的编码全部由QUICKLIST实现。QUICKLIST是一个压缩列表组成的双向链表,结合了ZIPLIST和LINKEDLIST两者的优点
压缩列表ZipList




- 连锁更新:因为数据和数据之间的耦合度太高了,一个改变了,另外一个也会改变,这里使用ListPack改变这个问题
Listpack结局连锁更新
面试题
ZIPList有什么优点
- 节约内存,访问满足局部性原则, 执行效率更快
ZIPList怎么压缩数据的
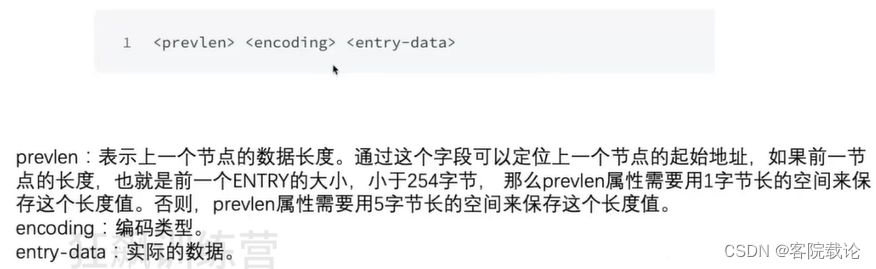
- 结构头:记录了字节数、开始位置、节点个数
- 数据部分:记录了上一个节点的长度,内容编码,内容本身
- 结尾标志:最后一个有1字节的结尾标识
ZIPList支持从后往前遍历吗
- 双端,使用prelen上一个节点的长度进行遍历
ZIPList如何从前往后遍历
- encoding包含了字符串或者整型的长度信息,使用该信息从前向后遍历
连锁更新是什么问题
- ZIPList是每一个节点都会记录上一个节点的长度,如果上一个节点小于255字节,这个记录字段就是1字节,否则就是5字节
- 由于更新某一个节点,会导致长度变化,如果从255以内,变得超过了255,会影响下一个节点的长度。
如何解决连锁更新
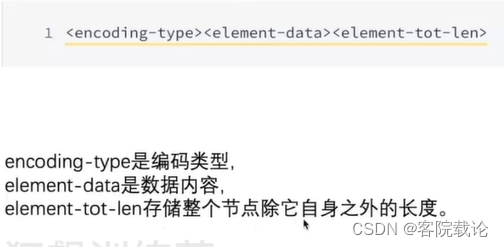
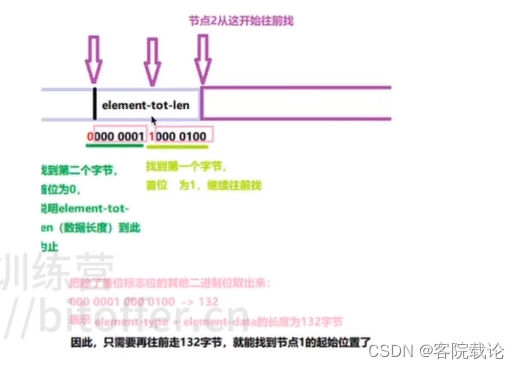
- 使用ListPack解决,每一个节点是记录自身的长度,并且上一个节点用来记录的字段和当前的节点是邻接的,所以通过特殊字段向前遍历实现。
Set

编码模式

面试题讲解
set是有序的吗
- set的底层实现是整数集和HASHTABLE,前者是有序的,后者是无序的
求两个set的交集
SINNER SETA SETB
set的编码格式
- Set使用整数集合和字典作为底层编码,当元素都是整数同时元素个数不超过512个,会使用整数集合编码,否则使用字典编码,
为什么使用两中编码原因
- Set的底层编码是整数集合和字典,当元素数量小并且全部是整数的时候,会使用整数集合编码,更加的节约内存。元素数量变大会使用字典编码,查找元素的速度会更快。
Hash


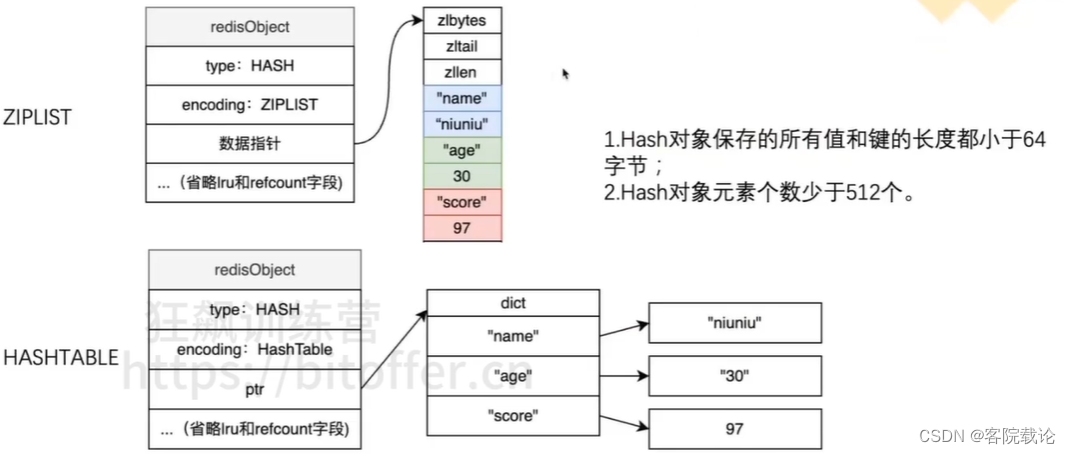
底层实现原理
- 数据量小,查询更快,使用ZIPLIST
- 数据量大,使用HASHTABLE

面试重点
HASH的编码方式
- ZIPLIST:元素较小,并且单个元素较少的情况
- HASHTABLE:元素较多,并且单个元素很多的情况
HASH为什么使用两种编码方式
- 采用两种编码方式的原因是ZIPLIST更节约内存,所以在小数据量时使用。而数据多起来了,需要HASHTABLE提高更高的查找性能、更新性能。
HASHTABLE底层
- 补充一个,还有上面的HASH数据结构
具体代码
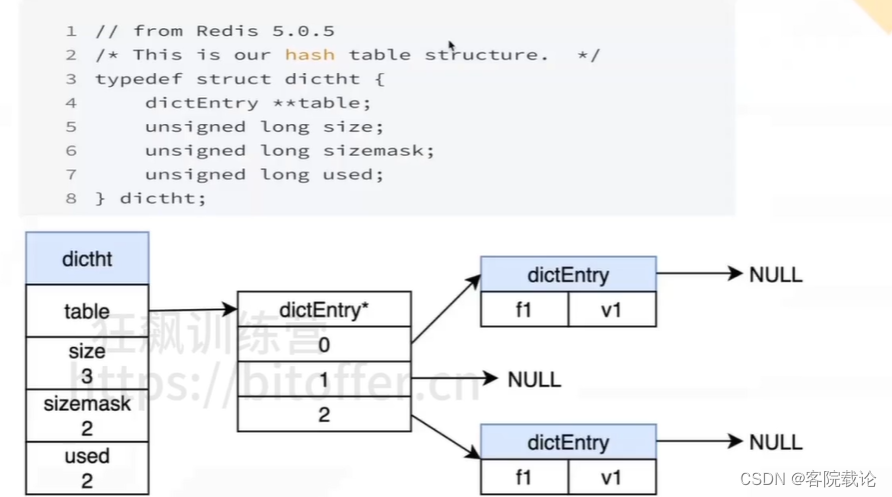
- rehashidx表示当前表格是否再使用,触发扩容之后,这个状态就变为0
- 有针对字典的操作,就会移动复制一次对应的元素
- 注意查找和新增的操作
- 查询是在零表
- 增加是新表

渐进式扩容
- 有对于字典的请求,就执行一次复制,迁移复制一个key-value
- 最后记得恢复最终的表格,是h[0]指向迁移之后的元素

扩容和缩容的时间
- 负载因子为k,那么k=ht[0].used/ht[0].size
- 扩容:
- 1.负载因子大于等于1,说明此时空间已经非常紧张。新数据是在链表上叠加的,越来越多的数据如果此时服务器没有执行BGSAVE或者BGREWRITEAOF这两个复制命令,就会发生扩容。
- 2.负载因子大于5,这时候说明HASHTABLE真的已经不堪重负了,此时即使是有复制命令在进行也要进行Rehash扩容。
- 缩容:
- 1.当负载因子小于0.1,即负载率小于10%,此时进行缩容,新表大小为第一个大于等于原表used的2次方幂,缩容也受复制命令影响。
面试考点
查看HASHTABLE中所有元素数量的计算时间复杂度是多少?
- 有一个used字段,时间复杂度是O(1)
一个数据在HASHTABLE中的存储位置,是怎么计算的?
- 通过hash函数计算出key的哈希值,然后与哈希掩码做与运算,得到索引值,索引值就是在HASHTABLE中的存储位置。
HASHTABLE如何扩容
- 渐进式Rehash操作来完成
- 首先程序会为HASHTABLE的1号表分配空间,空间大小是第一个大于等于0号表大小*2的2^n。在rehash进行期间,标记位rehashidx从0开始,每次对字典的键值对执行增删改查操作后,都会将rehashidx位置的数据迁移到1号表,然后将rehashidx加1,随着字典操作的不断执行,最终0号表的所有键值对都会被rehash到1号表上。之后,1号表会被设置成0号表,接着在1号表的位置创建一个新的空白表。
什么时候扩容?什么时候缩容?
扩容
- 当以下两个条件中的任意一个被满足时,哈希表会自动开始扩容:
- 服务器目前没有在执行BGSAVE或者BGREWRITEAOF,并且负载因子>=1服务器目前正在执行BGSAVE或者BGREWRITEAOF,并且负载因子>=5
缩容 - 当哈希表的负载因子小于0.1时,程序会自动开始对哈希表进行收缩操作。
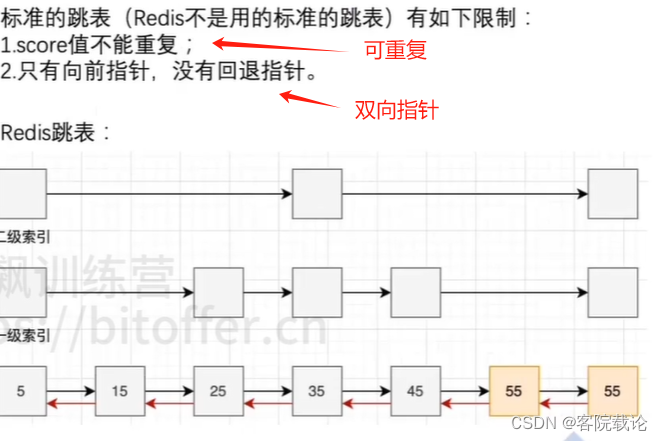
跳表
- 和树的查询效率一样,是logn


跳表查询数据的过程 - 高级索引产生是随机的
- 二级索引跳跃的距离较长,一级索引短一点,普通索引,最短
- 找35,通过二级索引,一次就行。
- 找45,通过二级索引,找到35,再找以及索引,就找到45
- 总结
- 超过目标值,索引降级重新查找
- 小于目标值,继续使用高级索引
插入节点的方式
- 时间复杂度是logn

Redis中的跳表设定
具体实现

层高是怎么确定的

面试重点
跳表是什么?和普通的链表有什么区别?
- 跳表也算链表,不过相对普通链表,增加了多级索引,通过索引可以实现O(logN)的元素查找效率。
跳表的查找过程
- 从高级索引往后查找,如果下个节点的数值比目标节点小,则继续找,否则不跳过去,而是用下级索引往下找
调表查询节点总数的时间复杂度
- O(1),表头结构中定义了统计节点数量的字段
跳表中一个结点的层高是怎么定义的
- 跳表在插入新节点之前会计算一个随机的层高,具体来说,跳表的每一个节点一开始默认都是1层,然后每增加一层的概率都是 25%,在5.0.5版本最高为64层
插入一条数据的时间复杂度
- logN
- 查找类似二分查找,平均时间复杂度就是logN
跳表插入数据会影响其他节点的层高吗
- 不会的,节点层高在创建时就确认的,新插入的节点,只会影响每一层的前一跳和后一跳的关联指针。
ZSET有序链表

重在于对文档敲一敲,即使部队这文档也能够顺利使用
底层编码格式
底层编码的具体实现

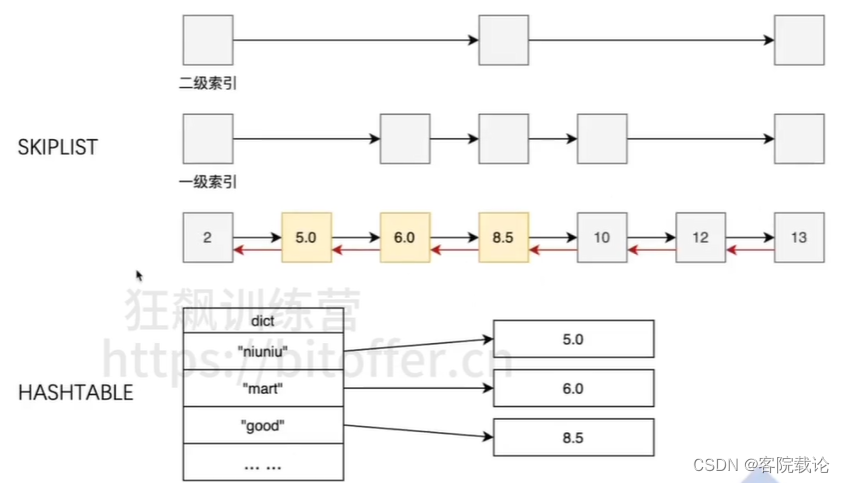
跳表:范围查找
HASHTABLE:提供按成员查找分数的能力
面试重点
Zset如何添加元素?如何移除元素
- zadd和zrem实现
Zset如何从大到小查找范围
- zrange从小到大查找,zrevrange逆序查找
Zset底层编码的方式
- ZSet就是有序集合对象,ZSet对象的底层有两种编码方式:ziplist或者如果一个ZSet对象中的所有元素同时满足:元素数量小于128个 以及 所有元素成员的长度都小于64字节,那么会使用ziplist编码,否则使用 skiplist+字典 编码。
Zset计算总的元素数的时间复杂度
- 无论是ZIPLIST编码,还是SKIPLIST的编码,查询节点总数的平均时间复杂度都是O(1),因为对应结构的表头结构中都定义了一个保存节点数量的字段,查询节点总数时会直接返回这个字段。
Zset为什么要使用两种编码方式实现
- hash使用单值查找,跳表使用的是范围查询
Zset为什么不使用B+树,而是使用跳表
- B+树的数据都存在叶子节点中,而且它是多叉树层,这两个特点使得它适合磁盘存储。而Redis是一个内存数据库,B+树层高低的优势荡然无存,所以选择了实现更加简单的跳表。
- 而且跳表的插入性能更高,虽然两者的插入平均时间复杂度相当,但是跳表插入数据后只需要修改前进和后退指针即可,而B+树还需要维护树的平衡,细节上有额外开销。
总结
- 这是redis的基础对象已经学完了,后面的东西就是跳着学习了,得加快进度了,这个周末是要把redis差不多学习完的。