前言
在日常的工作学习生活中,用一种好的方法去学习,可以更加有效,比如费曼学习法:将学到的知识用自己的组织的语言表达出来,如果能够清晰明白的向别人解释清楚,那么就说明你是真的懂了,学会了。如果不能够很好的表述出来,或者被别人问倒了,那说明有不懂的细节存在,需要再次对所学的知识进行巩固。所以在平时学习的时候,可以多与别人交流,将所学的知识讲述给别人听,当没有太多人可以交流的时候,也可以通过向自己提问题的方式,看看自己能否真正的回答好这些问题,或者通过写文章,将所学的知识用自己的话写出来,这也是检验自己学习成果的一种方法。发现自己过去存在的一个比较差的习惯,在学习相关知识时,只以摘抄式的方式记笔记,而缺少复盘,没有融入自己的思考,浮于表面,当做题或者面试时接受别人的提问时,问题立马就出现了,自己没法解决这些问题,在短时间内没能很好的解释这个知识点,心里只有一些相对模糊的概念。所以什么才是真正的懂得?那就是需要看清事物与问题的本质,将所学真正的知识进行内化。在准备面试的时候也是一样,可以从不同的角度多问自己几个问题,明白了底层的逻辑和原理,记忆起来也会更加简单。这篇文章会介绍线程池相关的一些知识,从以下几个方面进行探讨:
- 为什么要使用线程池(线程池解决了什么问题)
JDK中线程池的设计思想,运行流程- 深入了解底层源码的一些实现细节
理解线程池所要解决的问题
说到多线程,常常就与处理多个任务相关联,所以从多线程的使用场景说起,更深的层次还要理解什么是进程、线程和线程。
- 计算机如何同时处理多个任务?
计算机如何在同一时间处理多个任务呢?在 Java 当中,可以通过创建多个线程实现。系统为每个任务都创建一个线程,将不同的任务交由不同的线程进行处理,这样就实现了同一时间处理多个任务,相当于把不同的任务分配给不同的人来处理解决。
- 线程池的概念?主要用于解决什么问题?
线程池主要用于解决线程复用的问题。如果为每个任务都分配一个线程来处理,那么当任务量很大时,就需要创建大量的线程来处理这些任务。这种方案的问题是:一方面,系统是没办法无限制的创建线程的,操作系统能够创建的线程的数量是有最大值限制的,另一方面,如果任务时多时少,那么就需要频繁的创建和销毁线程;而创建、销毁都是需要一定的系统开销的。所以就有了线程池,大致的思想如下:系统事先创建好一定数量的线程,放到一个池子里面,当一个任务过来,就从池子里拿出一个线程来处理这个任务,处理完后,在将线程放回池子当中。如果任务太多,池子里已经没有空闲的线程来处理这些任务了,就将这些没办法即时处理的任务放入到一个等待队列当中,等池子里有空闲的线程了,再从队列中取出任务进行处理,这样就实现了线程的复用,避免频繁创建和销毁线程所带来的系统开销。具体的设计思想与上面的所说的有所偏差,我们来看看
JDK当中是如何设计和实现一个线程池的。
- 说说
JDK中线程池的设计思想与运行流程?
ThreadPoolExecutor是JDK中线程池的实现类,顶层接口Executor定义了一个执行任务的抽象方法,ExecutorService接口在Executor接口的基础上,规范了线程池需要有的一些功能:比如关闭线程池(关闭后线程池不能再接收新的任务)、线程池的状态(是否关闭)、提交异步任务等。
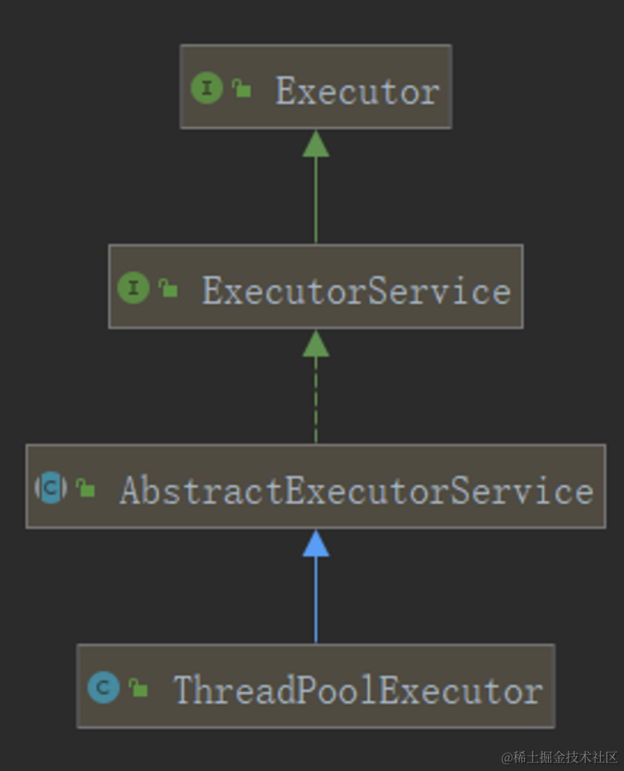
- 问题:1、线程池是怎么定义的,线程是如何存储在池子当中的?
JDK 当中定义了一个集合
HashSet<Worker>用来维护被创建出来的线程对象。线程池状态(
rs) :标记线程池的状态,根据状态量来控制线程池应该做什么。活跃线程数(
wc) :标识现在池子里的活跃线程数,以此判断要创建核心线程还是非核心线程。JDK 中用一个 Integer 变量(
ctl)来保存线程池状态和活跃线程数。通过对这个变量的与、或、非等计算,可以计算我们想要的一些数据,如通过:runStateOf方法获取当前线程池的状态、workerCountOf方法获取活跃线程数。阻塞队列通过workQueue.offer(command)往任务队列当中添加任务,如果队列满了,任务无法添加到对垒当中,会返false
- 解释一下
JDK线程池的构造函数参数?这些参数的作用?- 核心线程数:核心线程&非核心线程的概念:核心线程默认情况下会常驻于线程池当中(即使没有执行什么任务),非核心线程如果长时间闲置便会被销毁(相当于临时工,所以后面又有个非核心线程空闲的存活时间,以及存活的时间单位)。
- 最大线程数:核心线程的数量+非核心线程的数量。
- 非核心线程空闲时的存活时间、以及存活的时间单位。
- 任务队列:用来暂存来不及处理的任务,线程池当中没有可以用来处理任务的线程了,那么这时候就会先将任务放入到队列当中,等待有空闲的线程来进行处理。
- 线程池工厂:用来统一管理和创建线程。
- 拒绝处理策略:任务无法进行处理了(任务队列满了,线程达到最大线程数,此时不允许再创建线程来处理任务了),就会执行任务拒绝处理策略。
- 线程池的运行流程
初始时,线程池的当中的线程是空的,当一个任务过来,交由 execute 方法执行,会判断当前线程池当中的工作线程数是否小于核心线程数,优先去创建核心线程。如果核心线程已满,就会将任务暂存到任务队列当中,如果任务队列也满了,就会去创建非核心线程,如果添加非核心线程失败,就会执行任务拒绝处理策略。这里需要记住非核心线程是在队列满了之后才创建的。
- 拒绝处理的策略有哪些?
- 丢弃任务并抛出拒绝处理的异常信息
- 丢弃新来的任务,但是不抛出异常
- 丢弃队列头部(最旧的)的任务,然后重新尝试执行程序(如果再次失败,重复此过程)。
- 直接在调用线程中执行被拒绝的任务
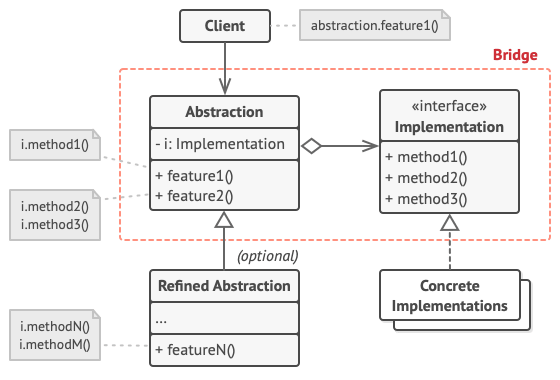
- 应用到的设计模式
策略接口:
RejectedExecutionHandler具体的拒绝策略:
AbortPolicy、DiscardPolicy、DiscardOldestPolicy、`CallerRunsPolicy
线程池使用的默认任务拒绝策略是:丢弃任务并抛出拒绝处理的异常信息:
private static final RejectedExecutionHandler defaultHandler = new AbortPolicy();
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
threadFactory, defaultHandler);
参考链接
- JDK ThreadPoolExecutor核心原理与实践 - vivo互联网技术 - 博客园
- https://redspider.gitbook.io/concurrent