在文心一言中输入:
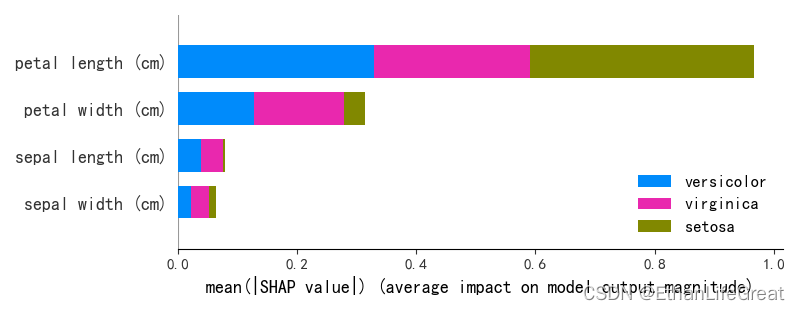
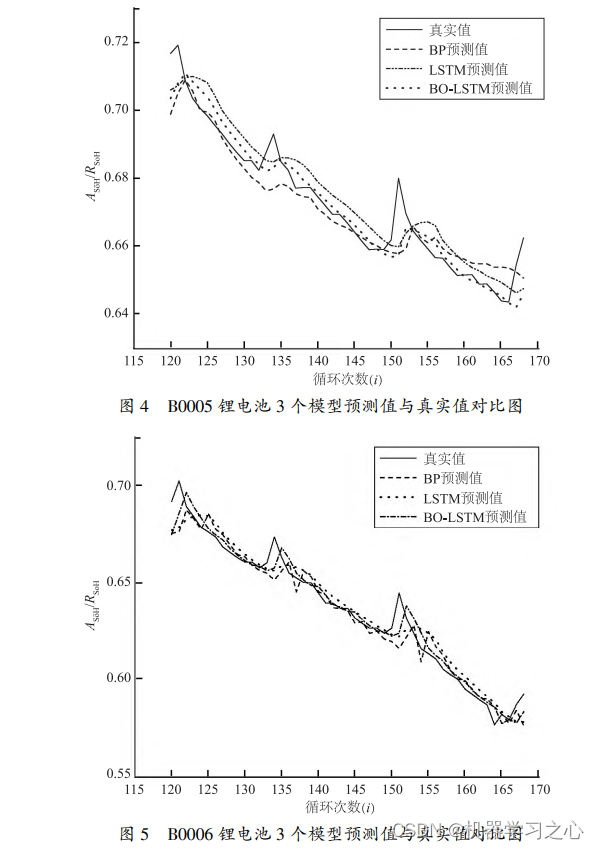
使用shap.summary_plot展示各个特征对模型输出类别的重要性
其输出的代码为(不正确):
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn import svm
import shap
# 加载数据集(这里使用iris数据集作为例子)
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化SVM模型并进行训练
clf = svm.SVC(kernel='linear', probability=True, random_state=42)
clf.fit(X_train, y_train)
# 初始化SHAP解释器
explainer = shap.Explainer(clf.predict_proba, X_train)
# 计算测试集上每个预测的SHAP值
# 注意:这里我们使用predict_proba方法,因为它返回了每个类别的概率
shap_values = explainer(X_test)
# 使用summary_plot可视化特征重要性
shap.summary_plot(shap_values, X_test, feature_names=iris.feature_names)以上代码没有静态错误,但是运行报错:
Traceback (most recent call last):
File "D:\Ethan\Projects\fattyLiver\test_shap_iris.py", line 27, in <module>
shap.summary_plot(shap_values, X_test, feature_names=iris.feature_names)
File "D:\Ethan\Projects\fattyLiver\venv\lib\site-packages\shap\plots\_beeswarm.py", line 605, in summary_legacy
feature_names=feature_names[sort_inds],
TypeError: only integer scalar arrays can be converted to a scalar index
修改为如下代码(正确):
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn import svm
import shap
# 加载数据集(这里使用iris数据集作为例子)
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化SVM模型并进行训练
clf = svm.SVC(kernel='linear', probability=True, random_state=42)
clf.fit(X_train, y_train)
# 初始化SHAP解释器
explainer = shap.Explainer(clf.predict_proba, X_train)
# 计算测试集上每个预测的SHAP值
# 注意:这里我们使用predict_proba方法,因为它返回了每个类别的概率
shap_values = explainer(X_test)
# 使用summary_plot可视化特征重要性
# shap.summary_plot(shap_values, X_test, feature_names=iris.feature_names)
list_of_2d_arrays = [shap_values.values[:, :, i] for i in range(3)]
shap.summary_plot(list_of_2d_arrays, X_test, feature_names=iris.feature_names, class_names=iris.target_names)
输出图片: