Elasticsearch 是一个强大的工具,尤其在全文检索、实时分析、机器学习、地理数据应用、日志和事件数据分析、安全信息和事件管理等场景有大量的应用。
然而,Elastic Stack 技术栈的选型及应用效能取决于正确的使用方式。选型错误或者误用 Elasticsearch 可能会导致扩展性问题、性能问题(如为解决一个问题使用非常复杂的脚本导致性能极差)等,从而使整体体验感变差。所以,本文区别于之前的正向讲解的方式,更多的讲解反例或者负面应用案例。“以史为鉴”,以便于大家更好地使用 Elasticsearch。
本系列文章会有 10 几篇左右,一篇一个知识点讲解 Elasticsearch 使用误区解读,敬请期待!
误区1:将 Elasticsearch 视为关系数据库
Elasticsearch 常被误解为 MySQL 或者 PostgreSQL 等关系数据库的直接替代品,用户除了直接替代使用外更看其全文搜索和快速聚合的能力。
然而,咱们必须清晰的认知:Elasticsearch 设计初衷不是处理复杂事务和关系数据模型的。
我们从下面几个维度逐一展开讨论:
1、该不该选型 Elasticsearch ?

个人建议先了解 Elasticsearch 的适用场景以及不适用场景,这样能清楚 Elastic Stack 技术栈更适合哪些业务需求。
例如,咱们文章之前图解的六大应用场景是非常适合的。然而,对于需要处理复杂事务、多表联查操作和高一致性要求的应用,如银行系统的交易处理和ERP系统等,Elasticsearch 则不太适合。
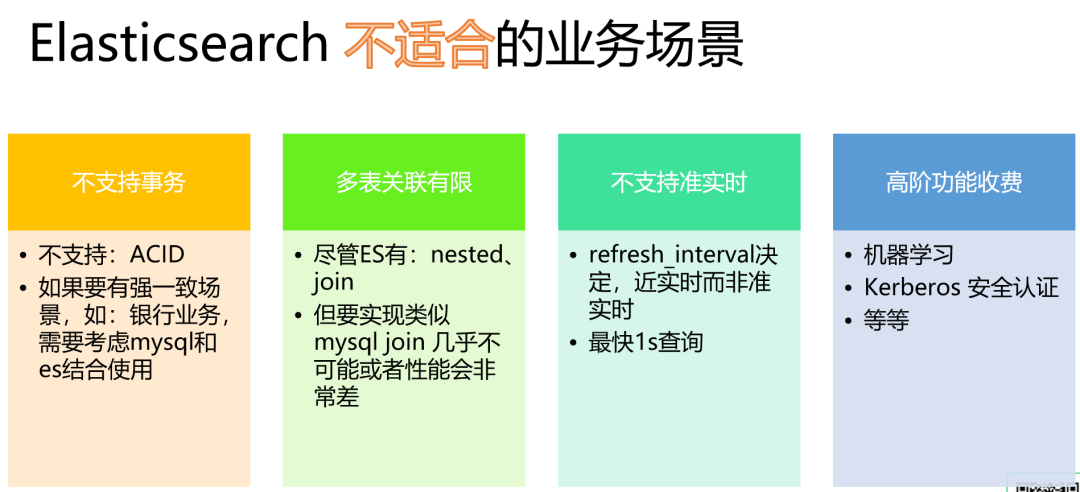
Elasticsearch 更适用场景:
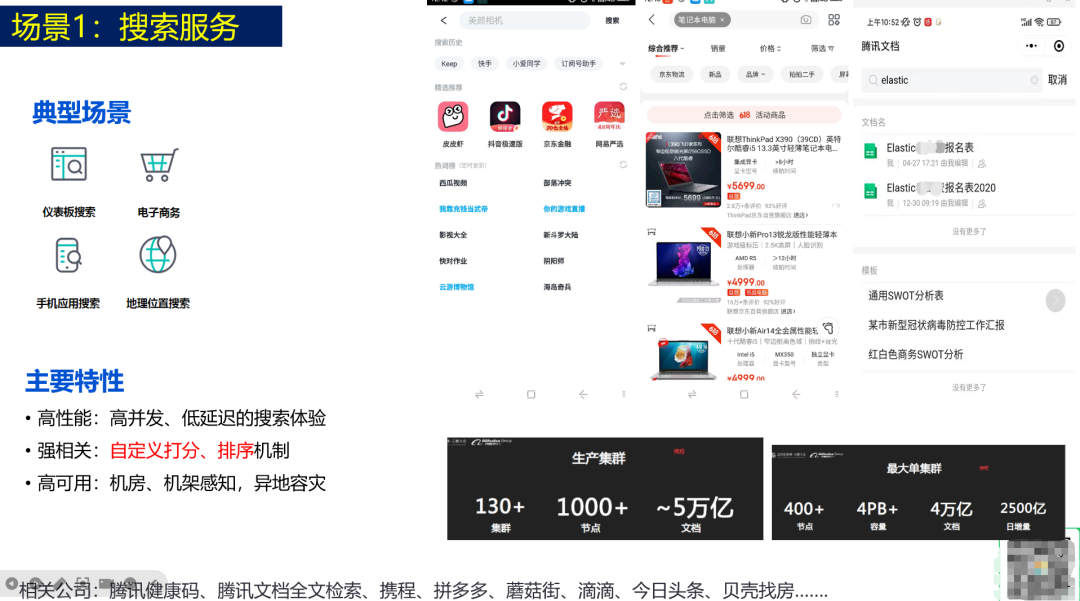
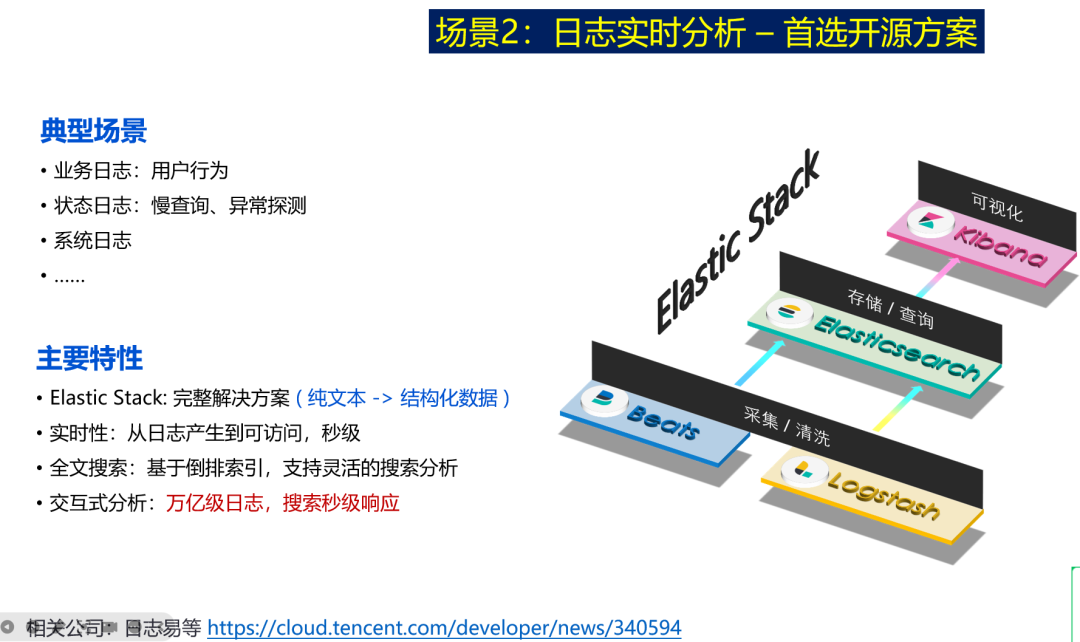
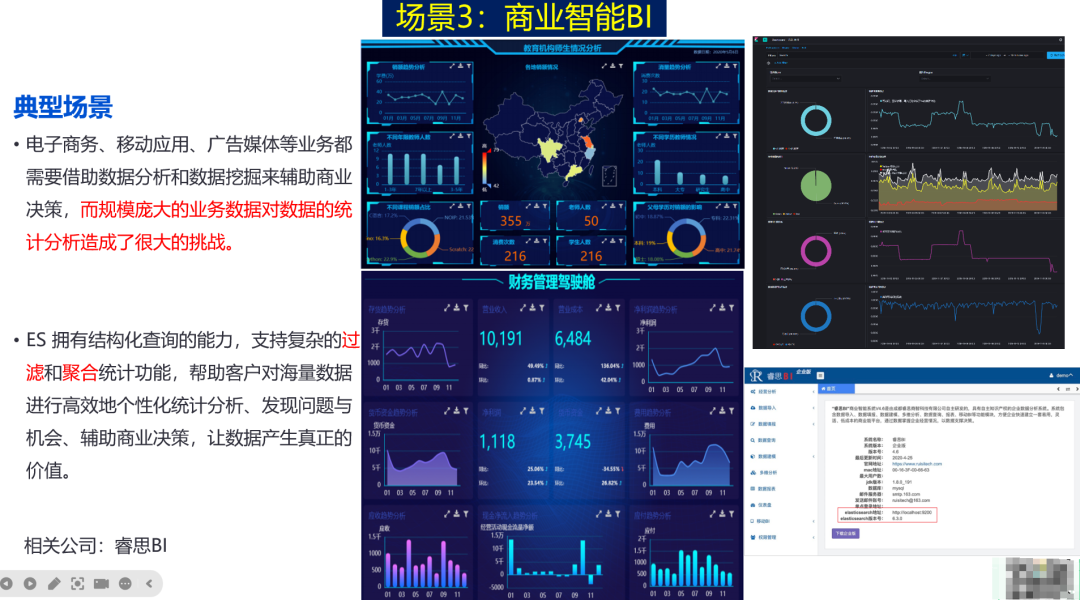
通过对比这些场景,反观自己的业务需求,就能判断是否应该选型 Elasticsearch 甚至 Elastic Stack 作为技术栈。
2、理解 Elasticsearch 的设计
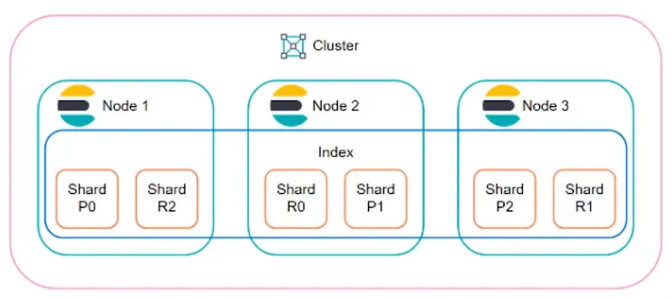
图片来自官方博客
Elasticsearch 是一种面向文档的搜索引擎,专为快速搜索大量数据而设计。
Elasticsearch 基于 Apache Lucene 构建,提供了强大的全文搜索、分析和数据聚合功能。
以下是 Elasticsearch 的主要特点:
-
全文搜索:Elasticsearch 提供了高效的全文搜索功能,能够快速检索和匹配大规模文本数据。
-
分布式架构:Elasticsearch 采用分布式架构,能够水平横向扩展,处理海量数据(PB级甚至以上都不是问题)和高并发请求。
-
数据分析:Elasticsearch 支持复杂的聚合查询,可以做多维度的快速统计和分析数据,但聚合、去重等结果不是精准的。有精准需求的企业场景也要评估和掂量一下。
-
......
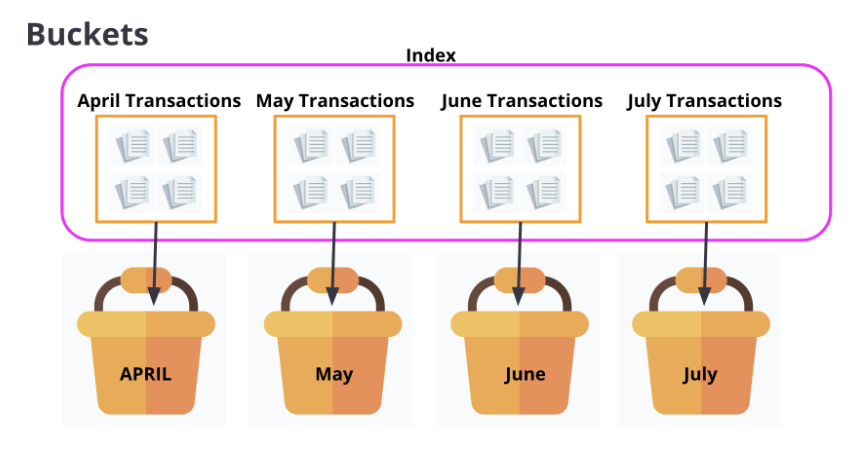
图片来自官方博客
如前所述,Elasticsearch 并不是设计用来处理关系数据和事务的。它的主要优势在于分析和搜索能力,而不是数据关系的严格维护。
3、理解 Elasticsearch 与关系数据库的比较
关系数据库(如 MySQL、Oracle 及 PostgreSQL 等)和 Elasticsearch 之间有几个关键区别:
3.1 数据模型比较
-
关系数据库使用结构化的表和行来存储数据,并通过外键和约束来维护数据的一致性。
-
Elasticsearch 则使用文档(document,本质是 JSON 格式)来存储数据,每个文档可以包含不同的字段和数据类型。
| 特性 | 关系数据库 | Elasticsearch |
|---|---|---|
| 数据存储结构 | 结构化的表和行 | 文档 |
| 数据类型 | 每个表的字段类型固定 | 每个文档可以包含不同的字段和数据类型 |
| 数据一致性 | 通过外键和约束来维护数据的一致性 | 不提供数据一致性保障 |
| 查询能力 | 支持复杂的 SQL 查询、事务和联接操作 | 主要用于全文搜索和数据聚合 |
| 事务支持 | 完整的事务支持 | 不支持事务 |
| 性能优化 | 索引、缓存和查询优化 | 分片、索引和缓存 |
| 主要优势 | 关系数据处理和数据一致性维护 | 快速搜索和高效的数据聚合 |
3.2 查询能力比较
-
关系数据库支持复杂的 SQL 查询、事务和多表关联操作,以保证数据的一致性和完整性。
-
Elasticsearch 主要侧重于全文搜索和数据聚合,不支持复杂的事务和多表关联操作。
在关系数据库中,我们可以使用复杂的 SQL 查询、事务和多表关联操作来保证数据的一致性和完整性。例如:
BEGIN TRANSACTION;
-- 更新订单状态
UPDATE orders
SET status = 'shipped'
WHERE order_id = 123;
-- 减少库存
UPDATE products
SET stock = stock - 1
WHERE product_id = 456;
-- 记录客户活动
INSERT INTO customer_activity (customer_id, activity)
VALUES (789, 'Order 123 shipped');
COMMIT;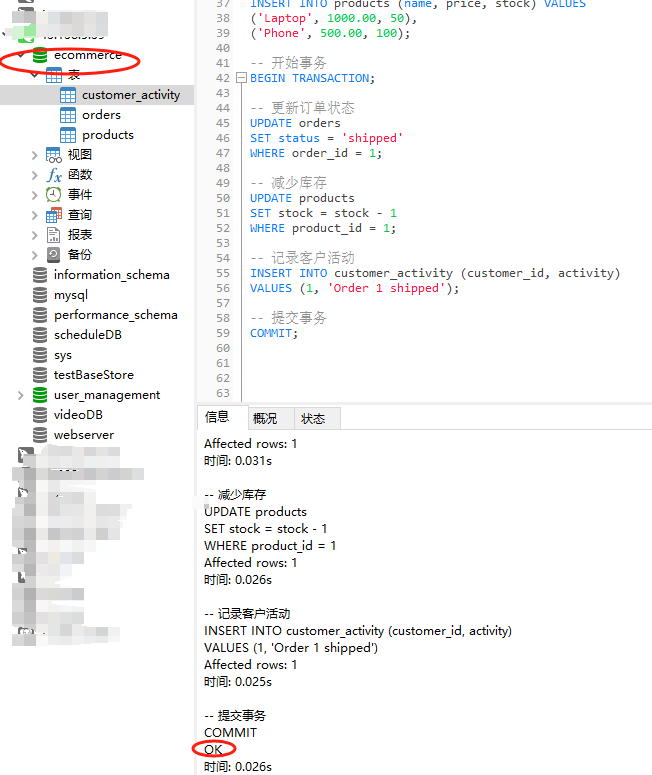
上述事务示例能确保所有相关操作(更新订单状态、减少库存和记录客户活动)要么全部成功,要么全部失败,从而保证数据的一致性(事务的本质)。
在 Elasticsearch 中,我们主要侧重于全文搜索和数据聚合分析,而不支持复杂的事务和多表关联操作。
比如:用户需求如下:
“想请教下大佬们,假设 es 中 有两个表,一个会员表,一个订单表,如果想关联查询,例如查询24年注册的所有的会员的订单总数,通过什么方式能快速查询?”
咱们文章做过剖析,Elasticsearch 不是一丁点也不支持多表关联,只是支持的力度有限,支持的形式核心有如下几种:
-
自己业务层面实现
-
Nested 嵌套数据类型
-
Join 父子文档类型
-
宽表冗余存储
-
Enrich processor 预处理方式
更深入关于多表关联的探讨,官方 2013 年的博文就已经说过,建议阅读:
https://www.elastic.co/cn/blog/managing-relations-inside-elasticsearch
《一本书讲透 Elasticsearch》第77-95页也有过深入的解读和探讨。
Elasticsearch 真正擅长的还是检索和数据统计聚合分析,如下所示:
GET /products/_search
{
"query": {
"multi_match": {
"query": "laptop",
"fields": ["name", "description"]
}
},
"aggs": {
"average_price": {
"avg": {
"field": "price"
}
}
}
}我们搜索产品名称和描述中包含“laptop”的文档,并计算这些产品的平均价格。这种查询主要用于快速检索和聚合数据,而不涉及复杂的事务和多表关联操作。
3.3性能优化比较
-
关系数据库通过索引、缓存和查询优化等技术来提高查询性能。
-
而 Elasticsearch 通过分片、索引和缓存等机制来加速搜索和数据聚合分析能力。
4、 误用 Elasticsearch 的潜在问题
将 Elasticsearch 当作关系数据库使用可能会导致以下问题:
4.1 问题1:性能不佳
复杂的事务和多表关联操作会显著降低 Elasticsearch 的性能,因为它不是为这些操作设计的。
如:我们希望在查询订单时关联多个表(例如订单、客户和产品表),但由于 Elasticsearch 并不是为这种复杂的多表关联操作设计的,导致查询性能极差。
不论 Nested 查询、Join 查询,都试图在订单文档中查找特定客户购买的特定产品,这类似于 SQL 中的 JOIN 操作。
由于 Elasticsearch 不是为这种操作设计的,在数据量级非常大之后,查询性能会受到影响,并且扩容等优化手段效果也不见得明显。
4.2 问题2:数据一致性
Elasticsearch 不提供事务支持,无法保证数据的一致性和完整性,特别是在多文档操作的情况下。
非银行金融类事务级支持场景可以大胆使用 Elasticsearch。话说回来,很多银行也在使用 ElasticStack 技术栈,比如日志场景、全文检索场景等。
4.3 问题3:索引膨胀
由于 Elasticsearch 的文档存储方式,频繁的更新操作可能导致索引膨胀,增加存储和管理的复杂性。
如下所示,我们频繁更新订单状态和产品库存,由于 Elasticsearch 的文档存储方式,这些更新导致索引膨胀,增加了存储和管理的复杂性。
POST /orders/_update/123
{
"doc": {
"status": "shipped"
}
}
POST /products/_update/456
{
"doc": {
"stock": 99
}
}每次更新都会创建一个新的文档版本,导致索引膨胀。如果订单和库存更新非常频繁,索引会迅速增长,影响性能并增加存储成本。
这个咱们选型、建模的时候要考虑。
5、正确使用 Elasticsearch 的建议
为了充分发挥 Elasticsearch 的优势,避免上述问题,以下是一些建议:
在选择 Elasticsearch 之前,明确了解你的需求和应用场景。如果需要处理复杂的事务和关系数据,关系数据库可能更适合。
在一些企业级实战场景中,可以将 Elasticsearch 与关系数据库结合使用。关系数据库用于处理事务和关系数据,Elasticsearch 用于全文搜索和数据分析。结合产生“火花”,形成“1+1>2”的组合效果。
根据数据特点和查询需求,合理设计和优化 Elasticsearch 索引、合理规范的数据建模,避免不必要的字段和过多的嵌套结构。
合理配置分片和副本数量,确保集群性能和数据高可用性。使用 Elasticsearch 提供的监控工具,定期分析和优化集群性能,及时处理潜在问题。
6、小结
Elasticsearch 是一种强大的工具,提供了全文搜索和数据聚合分析功能,但不是关系数据库的替代品。它在处理复杂事务和关系数据时并非最佳选择。理解其设计和用途,避免将其当作关系数据库使用,可以避免性能和数据一致性问题。合理设计和优化能够充分发挥 Elasticsearch 的优势,实现高效的数据搜索和分析。
正确使用 Elasticsearch 需要理解其设计理念和应用场景。结合使用关系数据库和 Elasticsearch(记住:1+1>2),可以实现更高效的数据管理和分析。
希望本文能帮助读者更好地理解和使用 Elasticsearch,避免选型和使用误区,从而实现更好的应用效果。
2024星球专享:Elastic 8.1 认证全部知识点 脑图 + 视频
https://articles.zsxq.com/id_njwt7kus4r42.html
新时代写作与互动:《一本书讲透 Elasticsearch》读者群的创新之路

更短时间更快习得更多干货!
和全球超2000+ Elastic 爱好者一起精进!
elastic6.cn——ElasticStack进阶助手

比同事抢先一步学习进阶干货!