作者: GreenGuan 原文来源: https://tidb.net/blog/bc405c21
引言
TiDB 是一个存算分离的架构,资源管控对这种分离的架构来说实现确实有非常大的难度,TiDB 从 7.1 版本开始引入资源管控的概念,在社区也有不少伙伴测试,测试结果大部分在 RU 的隔离上得到了验证,资源管控在业务上带来的价值是利用提高用户密度的方式来降低成本,同时还可以通过资源管控的方式抑制不同类型的业务来避免集群抖动,但是随着我们业务在不断发展,用户在增加,集群的资源也在变化(缩容,扩容),在这种动态发展的模式下,如何评估我们的 TiDB 动态容量,以及什么架构才能发挥资源管控的最大能力是本文讨论的点,本文会从业务的角度作为切入点来反向观察集群的状态。
资源管控验证目标
- OLTP vs OLTP 是否存在相互影响情况,包括 业务层(TPS、QPS、duration)
- OLTP vs OLAP 是否存在相互影响情况,包括 业务层(TPS、QPS、duration)
- OLAP vs OLAP 是否存在相互影响情况,包括 业务层(TPS、QPS、duration)
环境介绍
最小化部署 3pd,3tidb,3tikv
TiDB 节点:为了公平 pd 和 tidb 为混合部署,所有组件类如 Prometheus grafana alertmanager pd(L|UI)都放在一个 pd 机器上,让剩余的两个 tidb 的计算节点负载相同
TiKV 节点:单机多实例部署,每个实例在部署 tikv 时都做了资源隔离,这样做的意义在于当 tikv 节点跑满时,最多用到 16c
resource_control: memory_limit: 150G cpu_quota: 1600%
实验设计
TiDB 是存算分离的分布式数据库,多种不同类别的 SQL 难免会集中到一个 tidb 的计算节点上,而数据库中我们分为 OLTP 类业务和 OLAP 类业务,在这里我想说明下这两种业务的区别
OLTP 类的业务特点是短小的 SQL 语句,考验的是数据库处理高并发量的能力,常用的模拟工具有 sysbench,tpcc 等工具;
OLAP 类的业务特点是计算型的 SQL 语句,考验的是数据库优化器的能力,常用的模拟工具有 tpch 等工具;
综上所述,我们可以到如下集中测试的基本场景
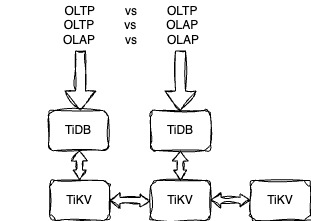
压力来自相同的计算节点
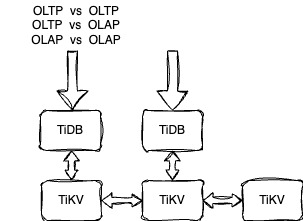
压力来自不同的计算节点
再下来我们设计一下压测的样例,压测需要有如下的限制和数据
-
基于我们的验证目标(验证资源管控是否生效),那么无论是 tidb, tikv 的各种资源 (cpu,mem,network) 就不能打满,因为打满必定受到影响
-
得到基线数据,基线数据是指无负载情况下的 qps 和 p95 响应延时,为了后续做对比
-
tidb 的资源管控组和用户为强绑定关系,我们为每个用户都单独设置一个资源组,也就是 1 对 1 的对应关系,这样可以让单租户把资源吃满
TiDB 租户和资源组对应关系
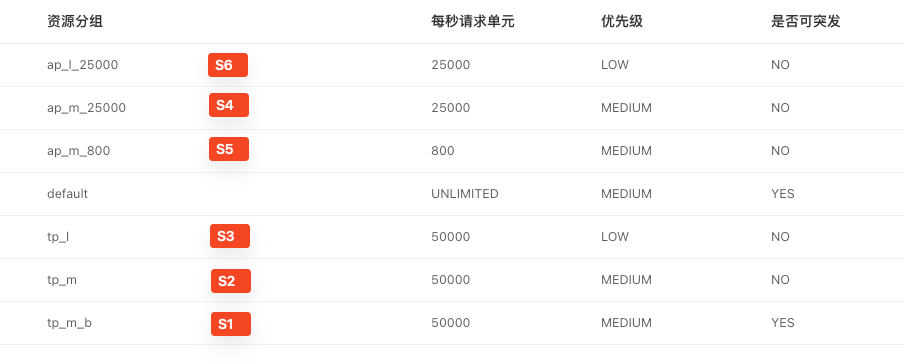
压测样例
| 压测编号 | 压测场景 | 压测样例 | 压测用户 | 备注 |
|---|---|---|---|---|
| t1_s1vss2 | oltp vs oltp | 相同 tidb | S1 vs S2 | |
| t1_s2vss1 | oltp vs oltp | 不同 tidb | S1 vs S2 | |
| t2_s1vss3 | oltp vs oltp | 相同 tidb | S1 vs S3 | |
| t2_s3vss1 | oltp vs oltp | 不同 tidb | S1 vs S3 | |
| t3_s1bvss2 | oltp vs oltp | 相同 tidb | S1(b) vs S2 | b 的是超卖场景在我们的场景中采用 64 并发 |
| t3_s2vss1b | oltp vs oltp | 不同 tidb | S1(b) vs S2 | |
| t4_s1bvss3 | oltp vs oltp | 相同 tidb | S1(b) vs S3 | |
| t4_s3vss1b | oltp vs oltp | 不同 tidb | S1(b) vs S3 | |
| t5_s2vss3 | oltp vs oltp | 相同 tidb | S2 vs S3 | |
| t5_s3vss2 | oltp vs oltp | 不同 tidb | S2 vs S3 | |
| t6_s1vss4 | oltp vs olap(Q16) | 相同 tidb | S1 vs S4 | |
| t6_s4vss1 | oltp vs olap(Q16) | 不同 tidb | S1 vs S4 | |
| t7_s1vss5 | oltp vs olap(Q16) | 相同 tidb | S1 vs S5 | |
| t7_s5vss1 | oltp vs olap(Q16) | 不同 tidb | S1 vs S5 | |
| t8_s2vss4 | oltp vs olap(Q16) | 相同 tidb | S2 vs S4 | |
| t8_s4vss2 | oltp vs olap(Q16) | 不同 tidb | S2 vs S4 | |
| t9_s2vss5 | oltp vs olap(Q16) | 相同 tidb | S2 vs S5 | |
| t9_s5vss2 | oltp vs olap(Q16) | 不同 tidb | S2 vs S5 | |
| t10_s2vss6 | oltp vs olap(Q16) | 相同 tidb | S2 vs S6 | |
| t10_s6vss2 | oltp vs olap(Q16) | 不同 tidb | S2 vs S6 | |
| t11_s1bvss6 | oltp vs olap(Q16) | 相同 tidb | S1(b) vs S6 | |
| t11_s6vss1b | oltp vs olap(Q16) | 不同 tidb | S1(b) vs S6 | |
| t12_s4vsS6 | olap vs olap (Q16) | 相同 tidb | S4 vs S6 | |
| t12_s6vsS4 | olap vs olap (Q16) | 不同 tidb | S4 vs S6 | |
| t13_s4vsS6 | olap vs olap (Q11) | 相同 tidb | S4 vs S6 | |
| t13_s6vsS4 | olap vs olap (Q11) | 不同 tidb | S4 vs S6 | |
| t14_s4vsS6 | olap vs olap (Q7) | 相同 tidb | S4 vs S6 | |
| t15_s6vsS4 | olap vs olap (Q7) | 不同 tidb | S4 vs S6 | |
| t12_s4vsS6_f | olap vs olap (Q16) | 相同 tidb | S4 vs S6 | f 的是加入了 tiflash |
| t12_s6vsS4_f | olap vs olap (Q16) | 不同 tidb | S4 vs S6 | |
| t13_s4vsS6_f | olap vs olap (Q11) | 相同 tidb | S4 vs S6 | |
| t13_s6vsS4_f | olap vs olap (Q11) | 不同 tidb | S4 vs S6 | |
| t14_s4vsS6_f | olap vs olap (Q7) | 相同 tidb | S4 vs S6 | |
| t15_s6vsS4_f | olap vs olap (Q7) | 不同 tidb | S4 vs S6 |
枯燥的压测过程和数据见压测过程章节,如果想省时间直接看结论,当然压测过程章节也会有一些解读
实验结论
-
OLTP vs OLTP:
- RU 管控方面,相同资源管控组的不同用户,在同时执行 SQL 时,不会超出资源管控所设置的最大 RU 值(超卖参数除外)
- 不同资源管控组的不同用户,在不同的 TiDB 计算节点上的 QPS 基本持平(有时还会超出基线数据),P95 相同
- 不同资源管控组的不同用户,在相同的 TiDB 计算节点上会有相互影响的情况,大约会有 8% ~ 10% 的影响
- 关于资源组的优先级,经测试不同资源管控组的优先级几乎没有差别( T5 场景);
- 如果两个不同的资源组运行在不同的计算节点则没有影响(最佳实践)
-
OLTP vs OLAP:
- 当 OLTP 平稳运行时遭遇 OLAP 业务会产生抖动,具体抖动延时需要看 OLAP 业务的 SQL 语句造成的影响
- 当 OLTP 和 OLAP 在相同计算节点上执行时,P95 会有 8% 的下降,总体可以接受
- 当 OLTP 和 OLAP 在相同计算节点上执行时,并且分配给 OLAP 业务的 RU 较少(一般为 OLAP 业务的 1/5 ),P95 会有 20% 的下降
- 当 OLTP 和 OLAP 在相同计算节点上执行时,OLAP 业务表现会有 20% 左右的衰减(不过感觉 AP 类业务多个几秒钟无所谓)
- 如果 AP 和 TP 类 SQL 分别运行在不同的 TiDB 计算节点上时,则影响最小(既做 AP 类资源限制又在计算层做资源隔离为最佳实践)
-
OLAP vs OLAP:
- 当 OLAP 和 OLAP 在相同计算节点上执行时,查询效率会有下降(实测中发现过原来 300s 跑出的语句,时间翻倍)
- 从返回结果看 OLAP 的资源优先级在实测过程中 medium 和 low 的差别不大
- 加入 TiFlash 后,OLAP 的 SQL 语句在相同与不同的计算同时执行时,耗时相差不大
- 运维方面的问题:不确定SQL 语句在 TiFlash 中占用了多少 RU
- OLAP 的业务在不同的计算节点上的效率最高
最佳实践架构
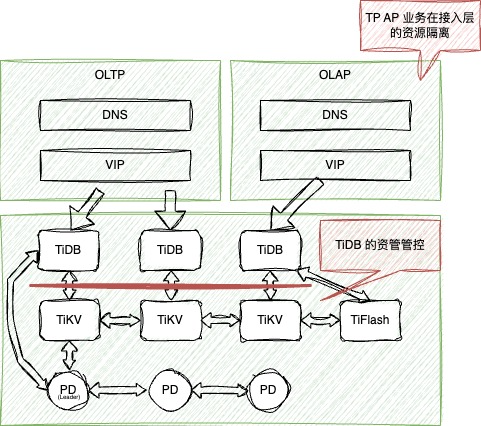
这个 TiDB 架构应该是我理解的最佳实践了,从实验数据我们可以看到,即使我们开启了资源管控,两种不同业务类型同时请求同一个计算节点时,对其他的用户也是有一些抖动的,而从运维层面来说,要么降低租户的 RU,要么在计算节点进行隔离,从架构的角度出发,计算资源用 VIP 隔离开来,来达到专机专用的目的,存储节点通过 RU 来进行限制 IO,两层保护对稳定性有正向收益
实验过程
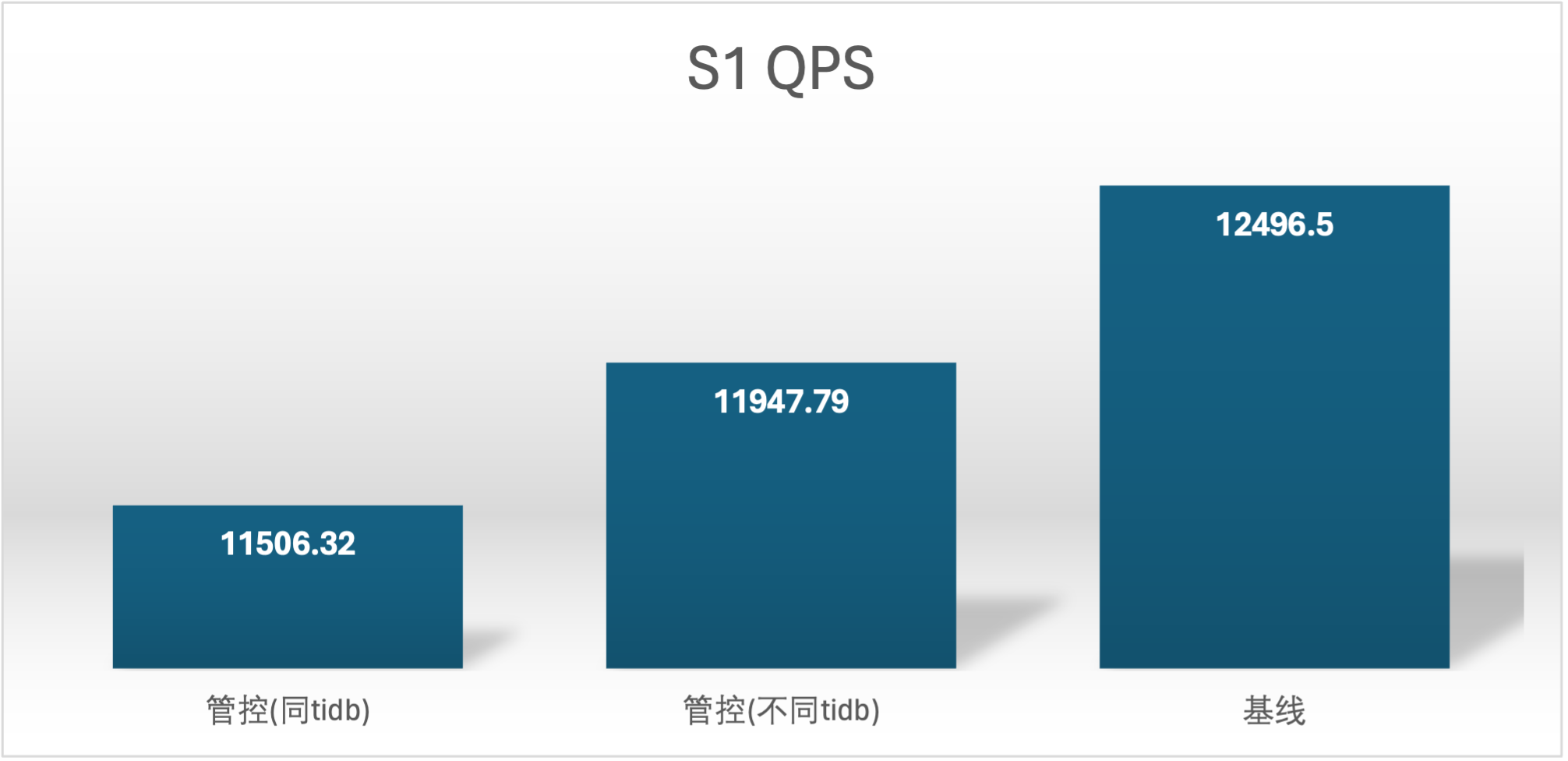
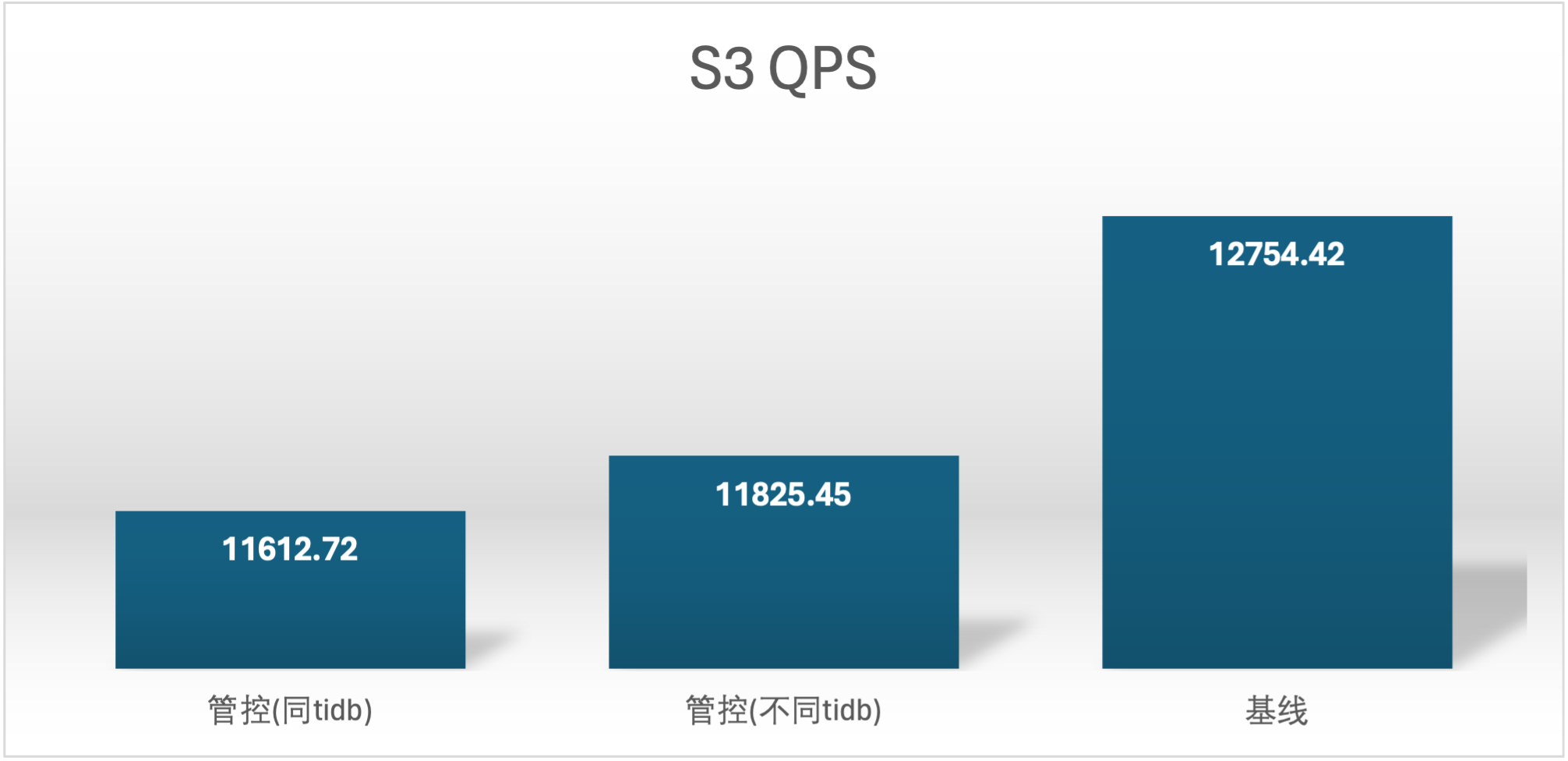
基线数据
| 用户 | 32 | 64 |
|---|---|---|
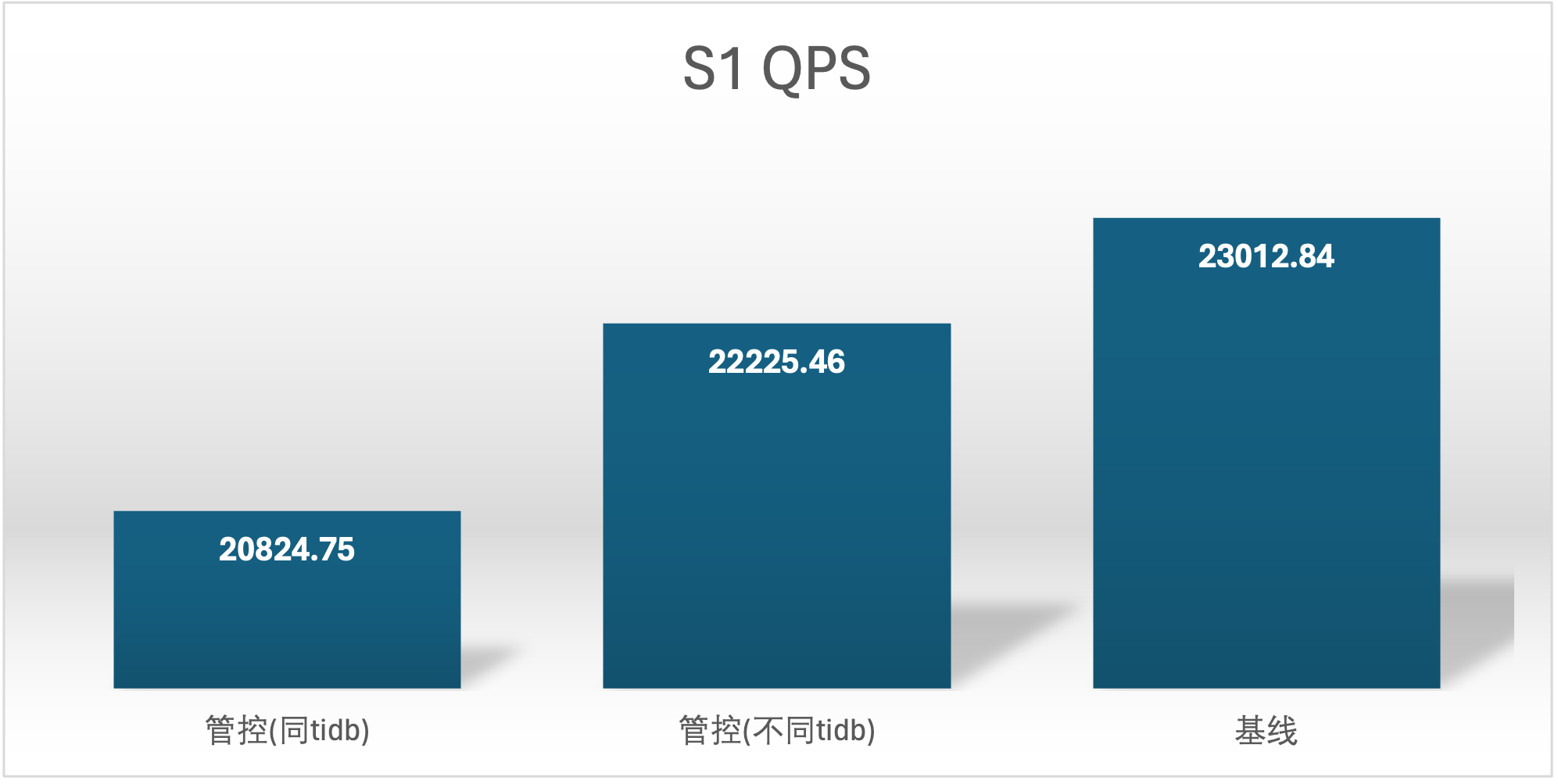
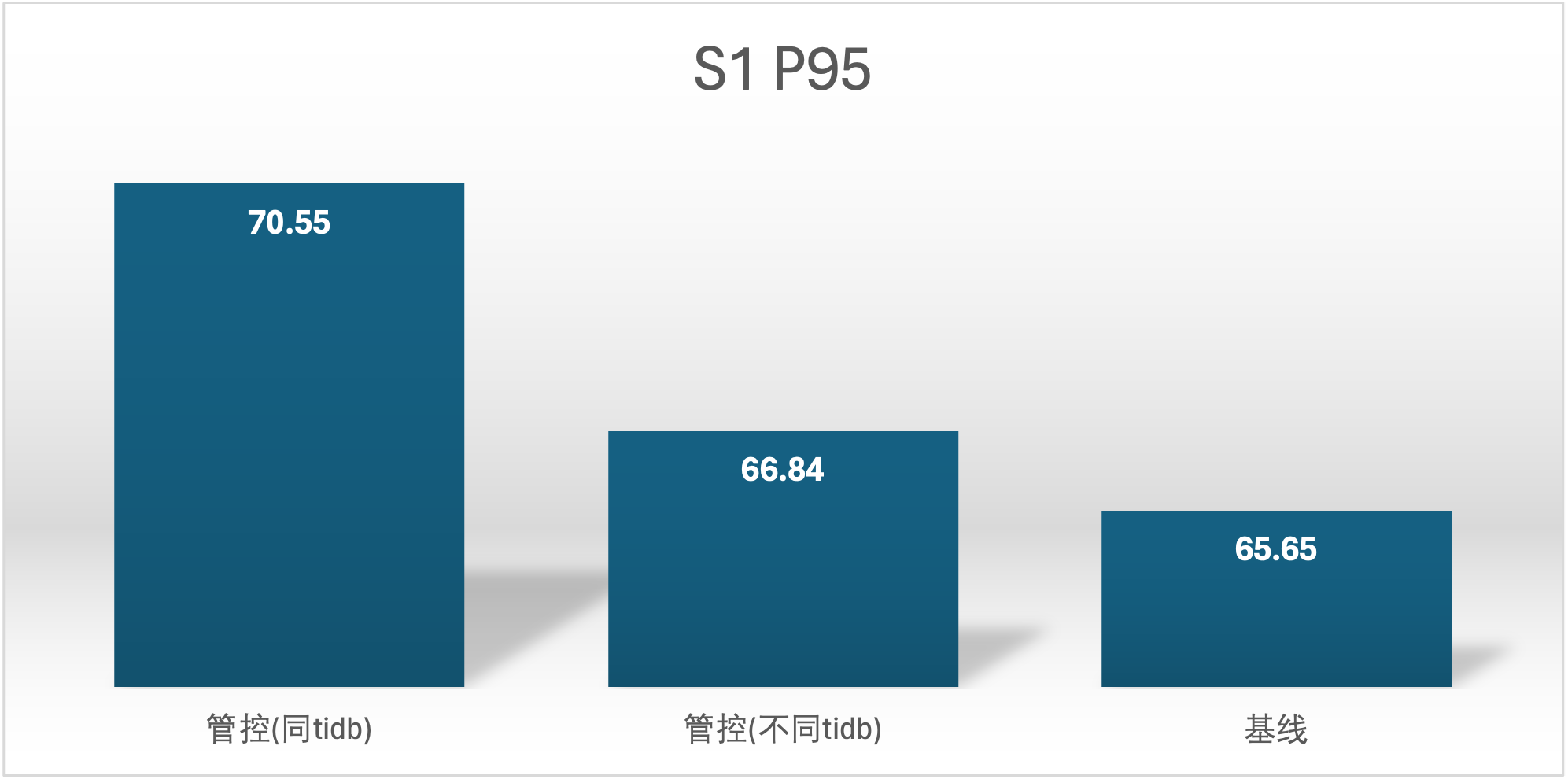
| S1 单独 | 12496.5 | 23012.84 |
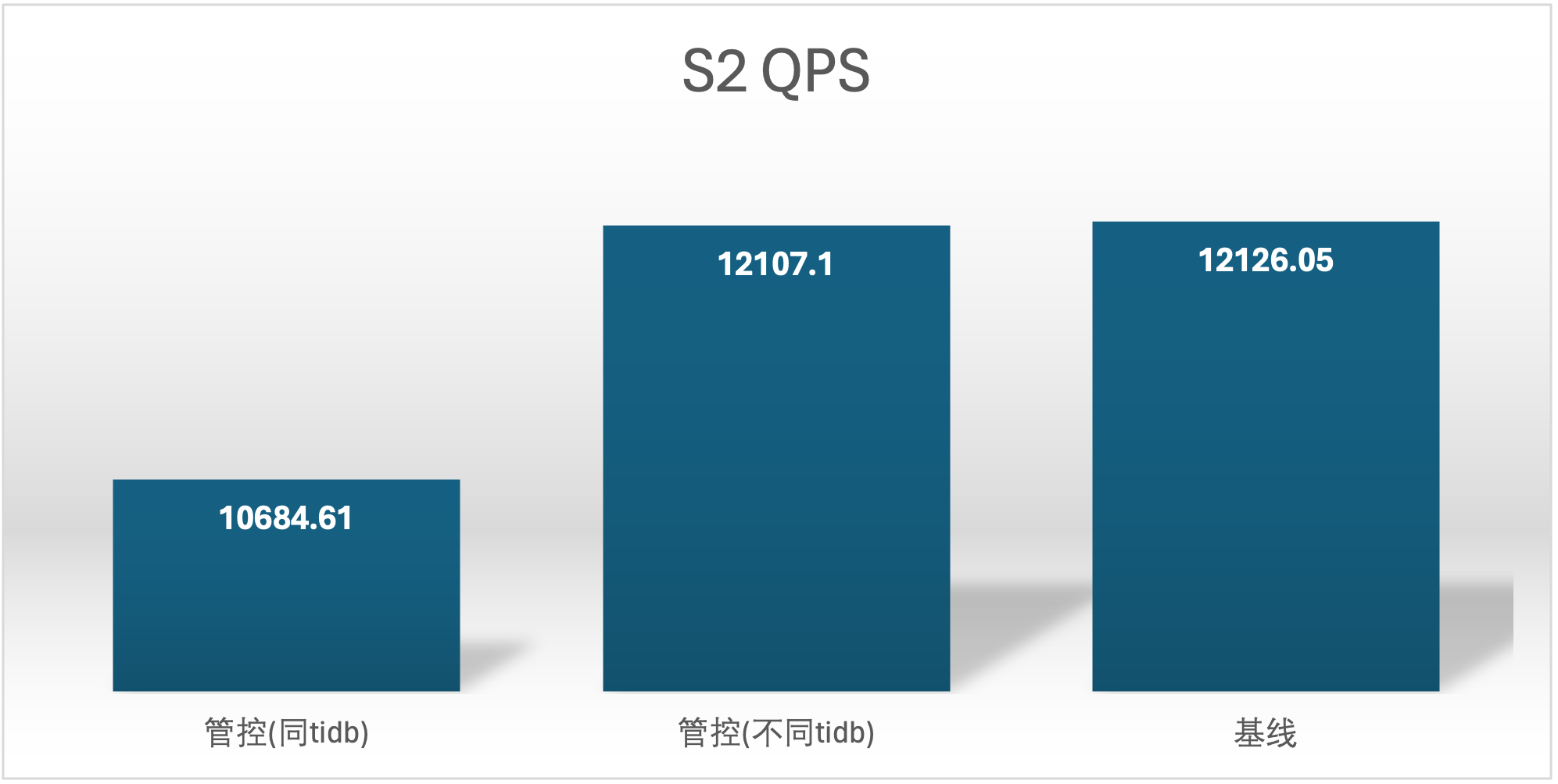
| S2 单独 | 12126.05 | 16500.92 |
| S3 单独 | 12754.42 | 16514.15 |
OLTP vs OLTP
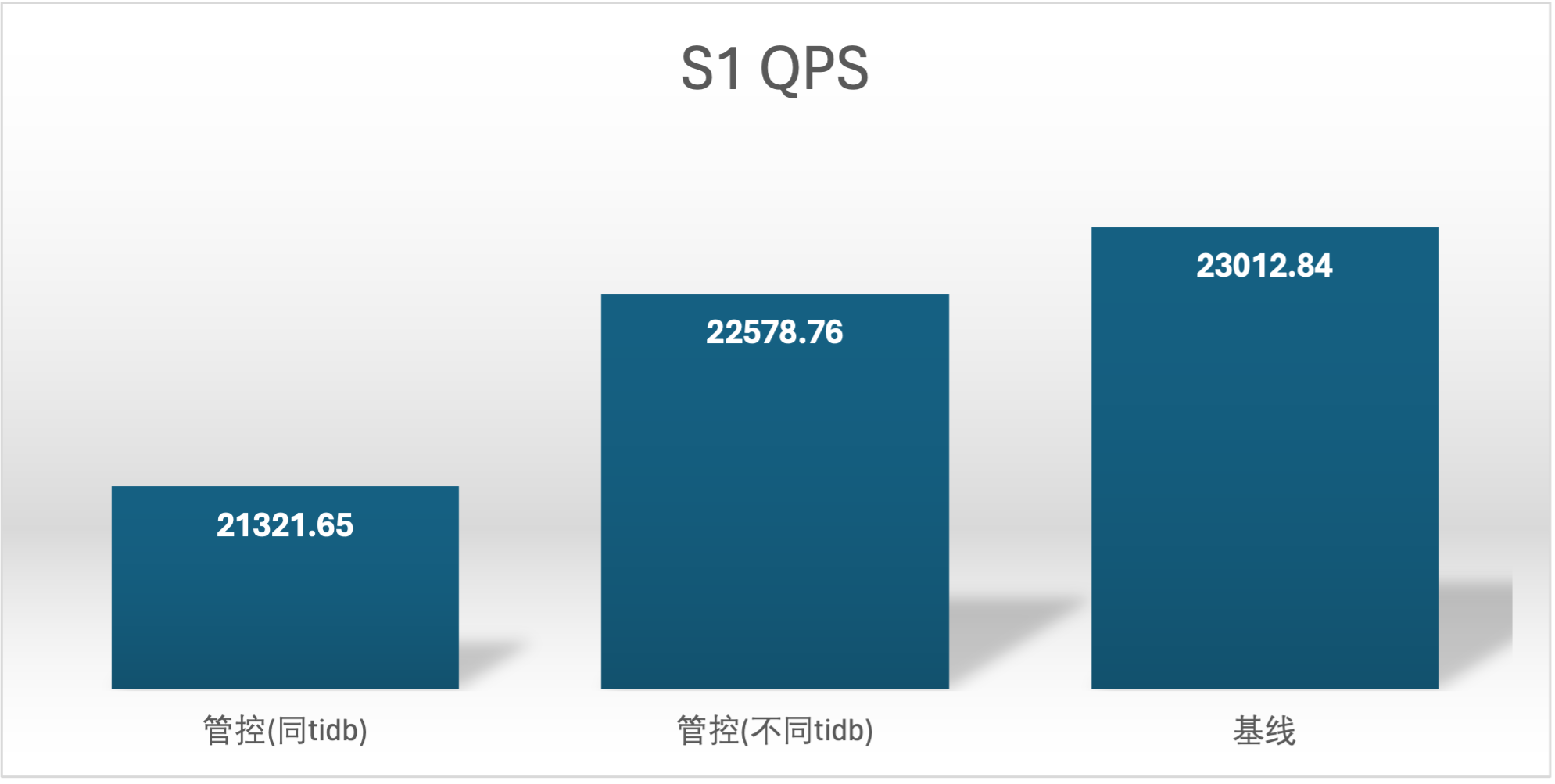
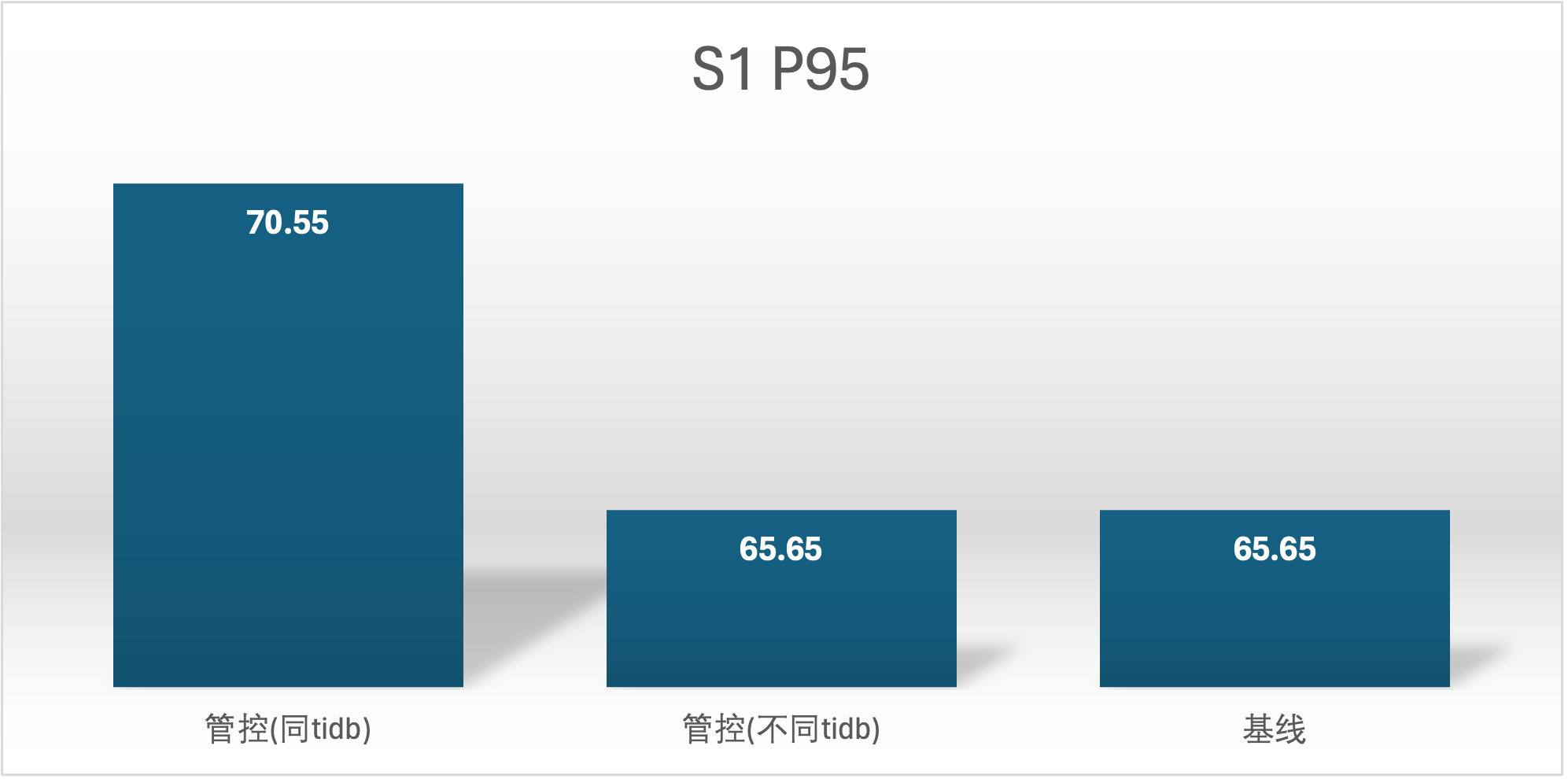
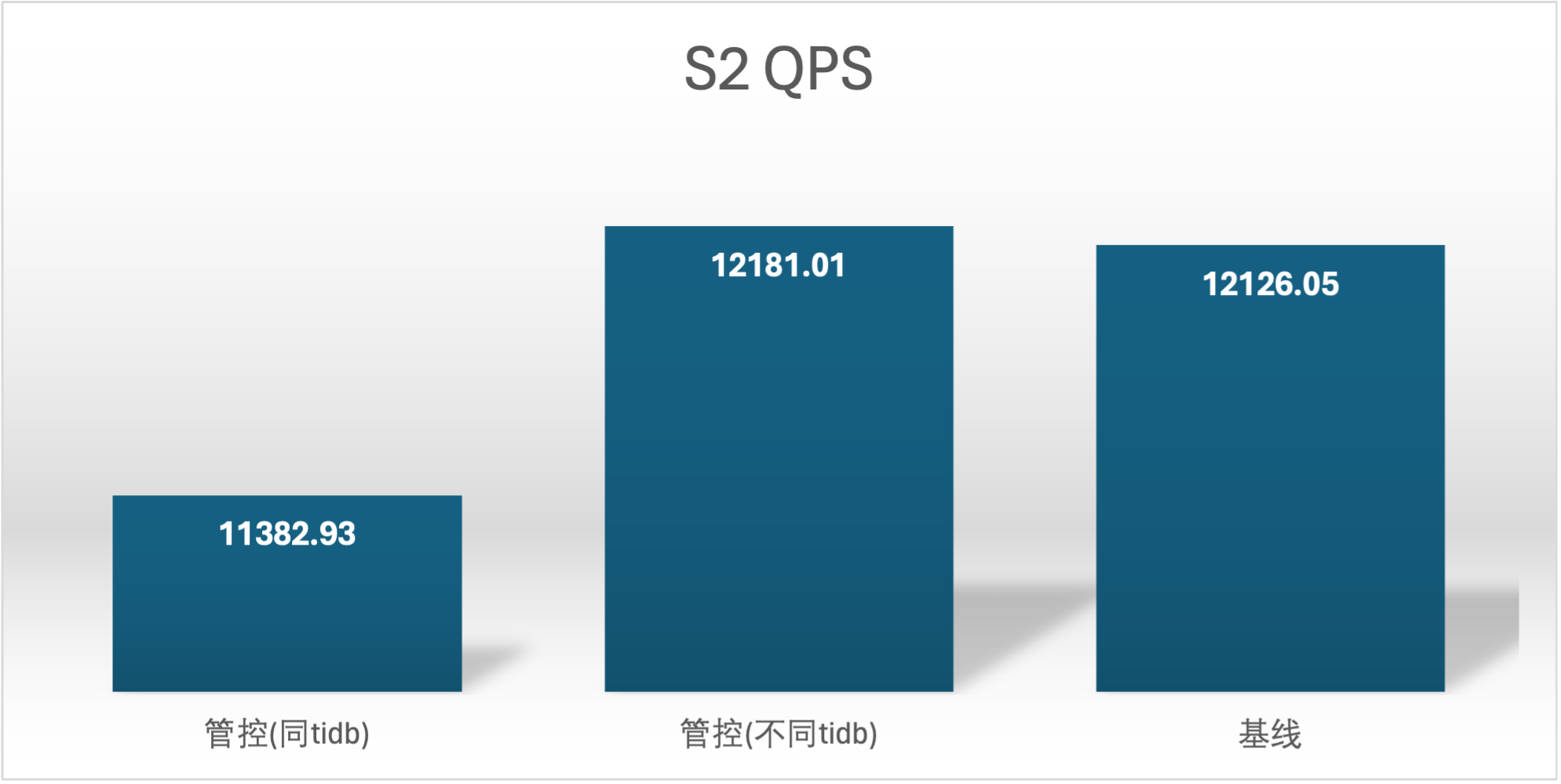
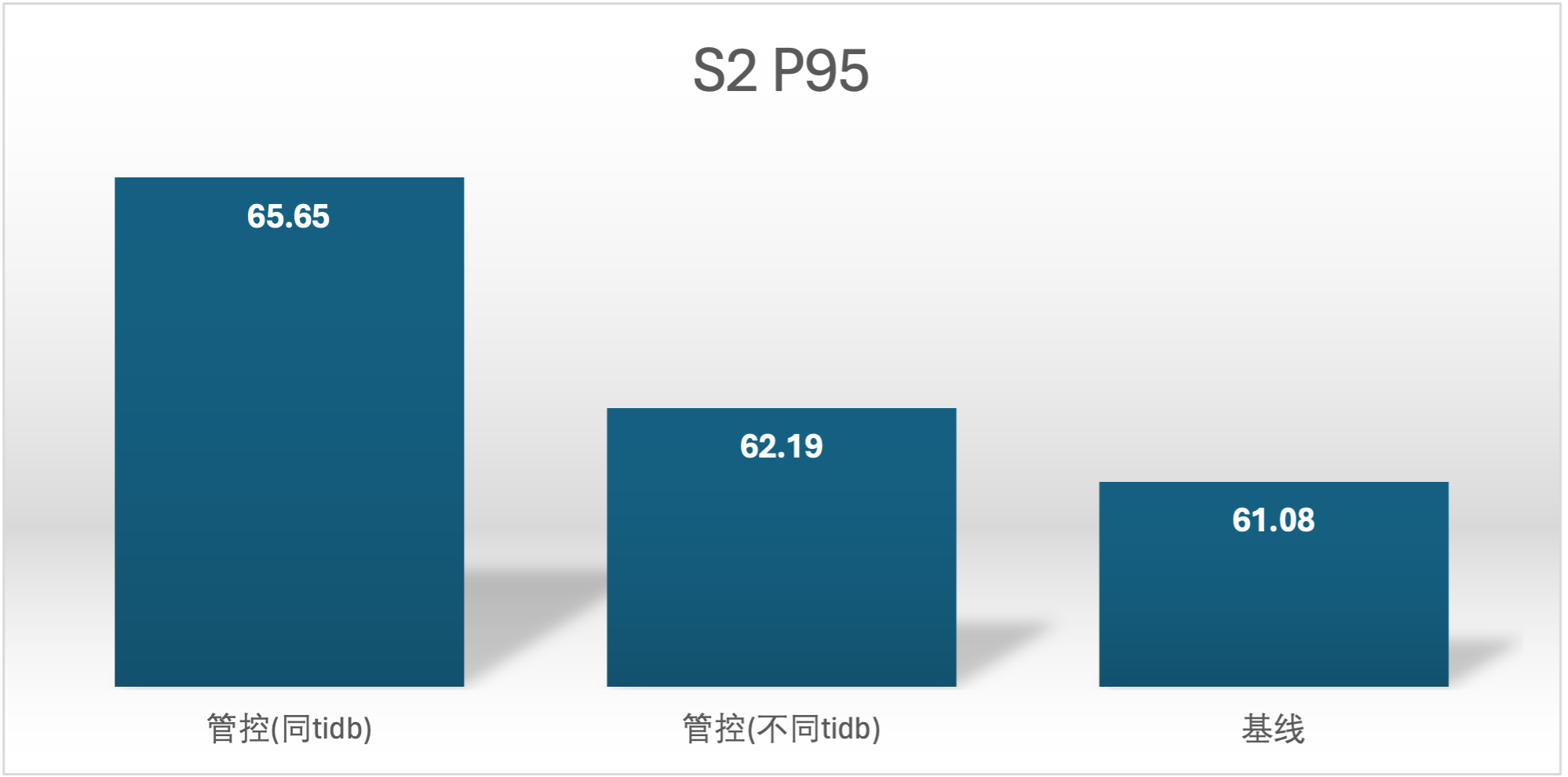
实验场景 t1_s1vss2、t1_s2vss1
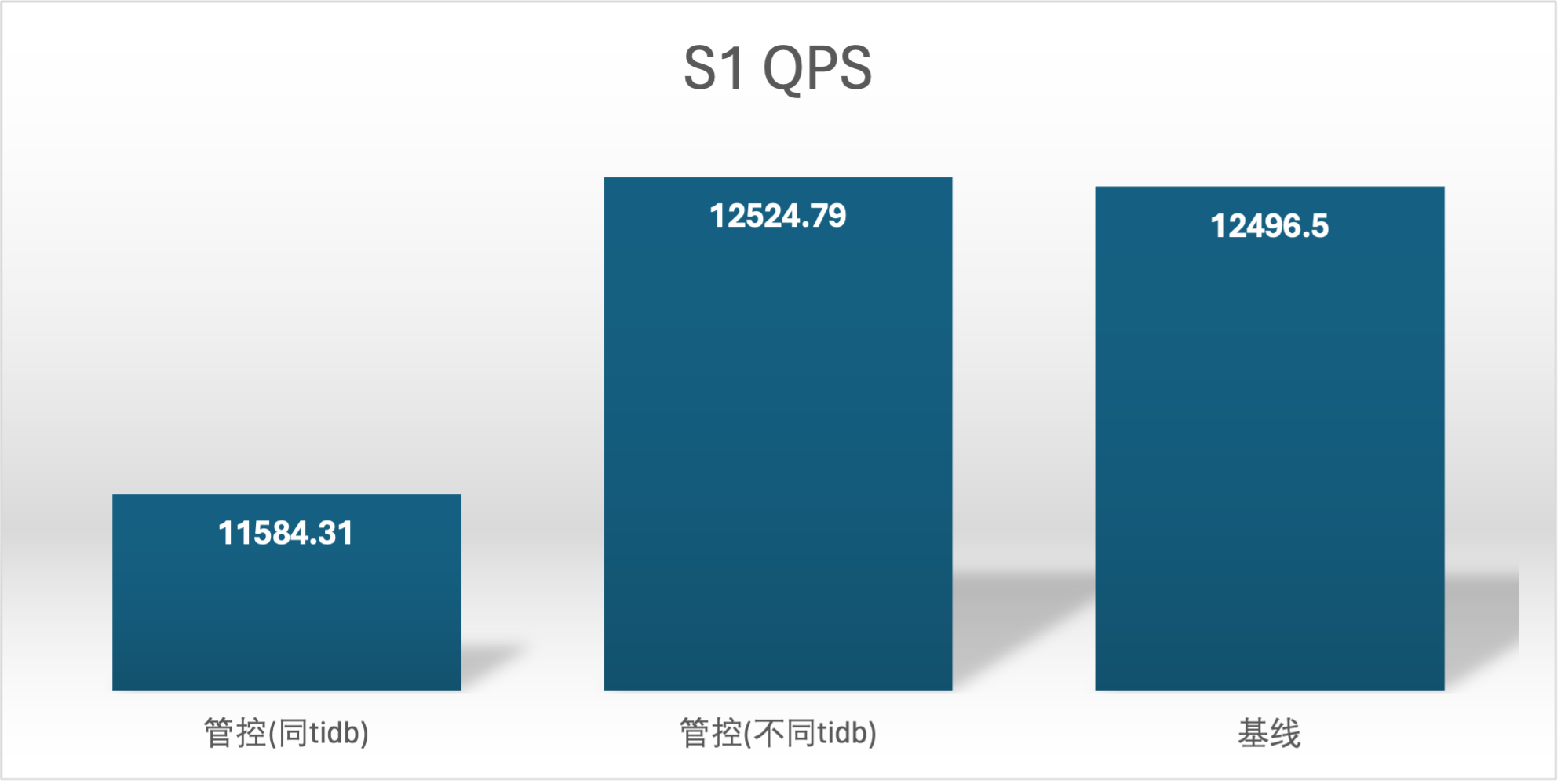
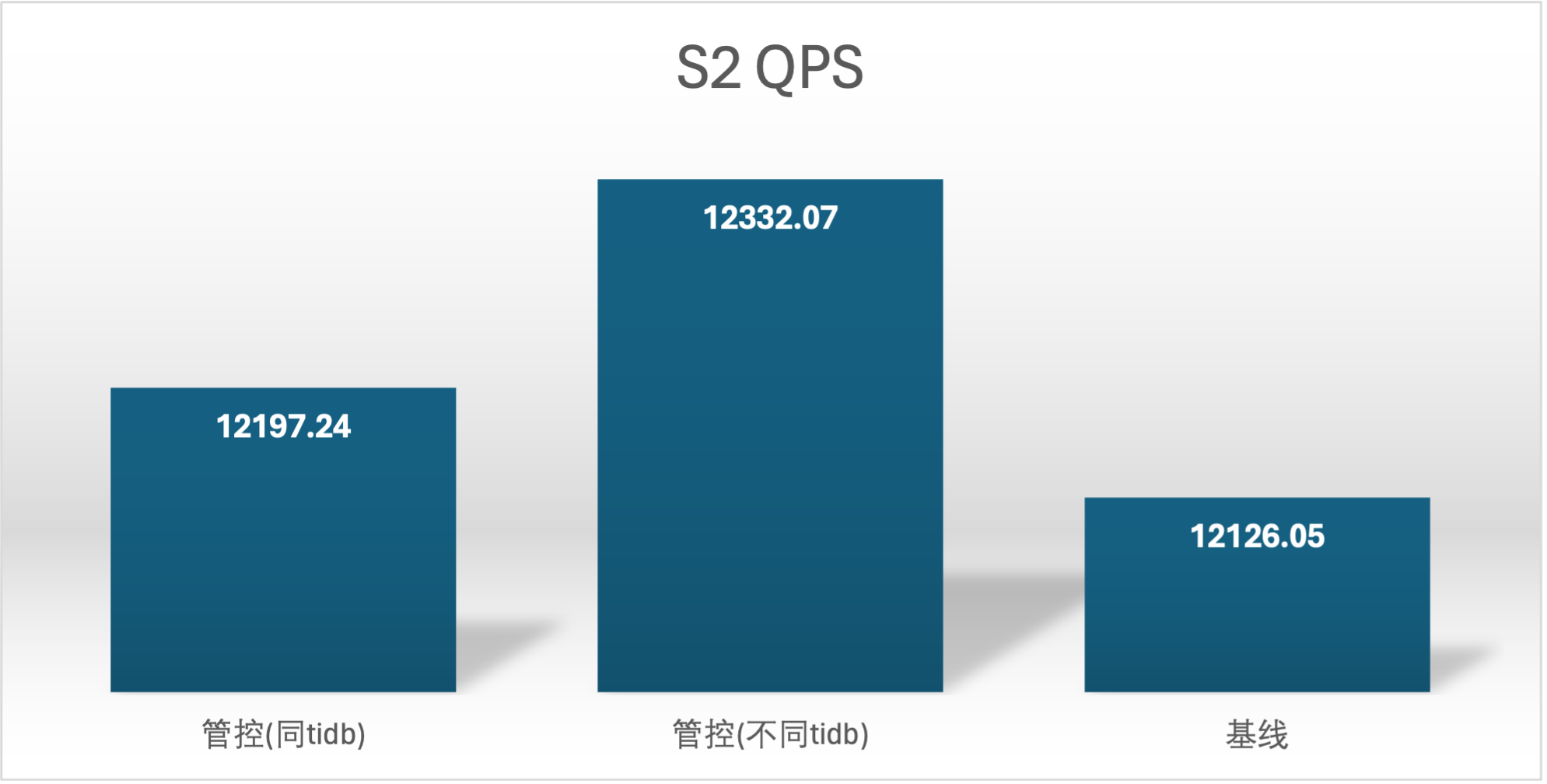
S2 QPS 的基线确是很奇怪,在进行基线压测的时候不确定集群发生了什么,导致基线 S2 用户的基线数据较低,不过不影响结论
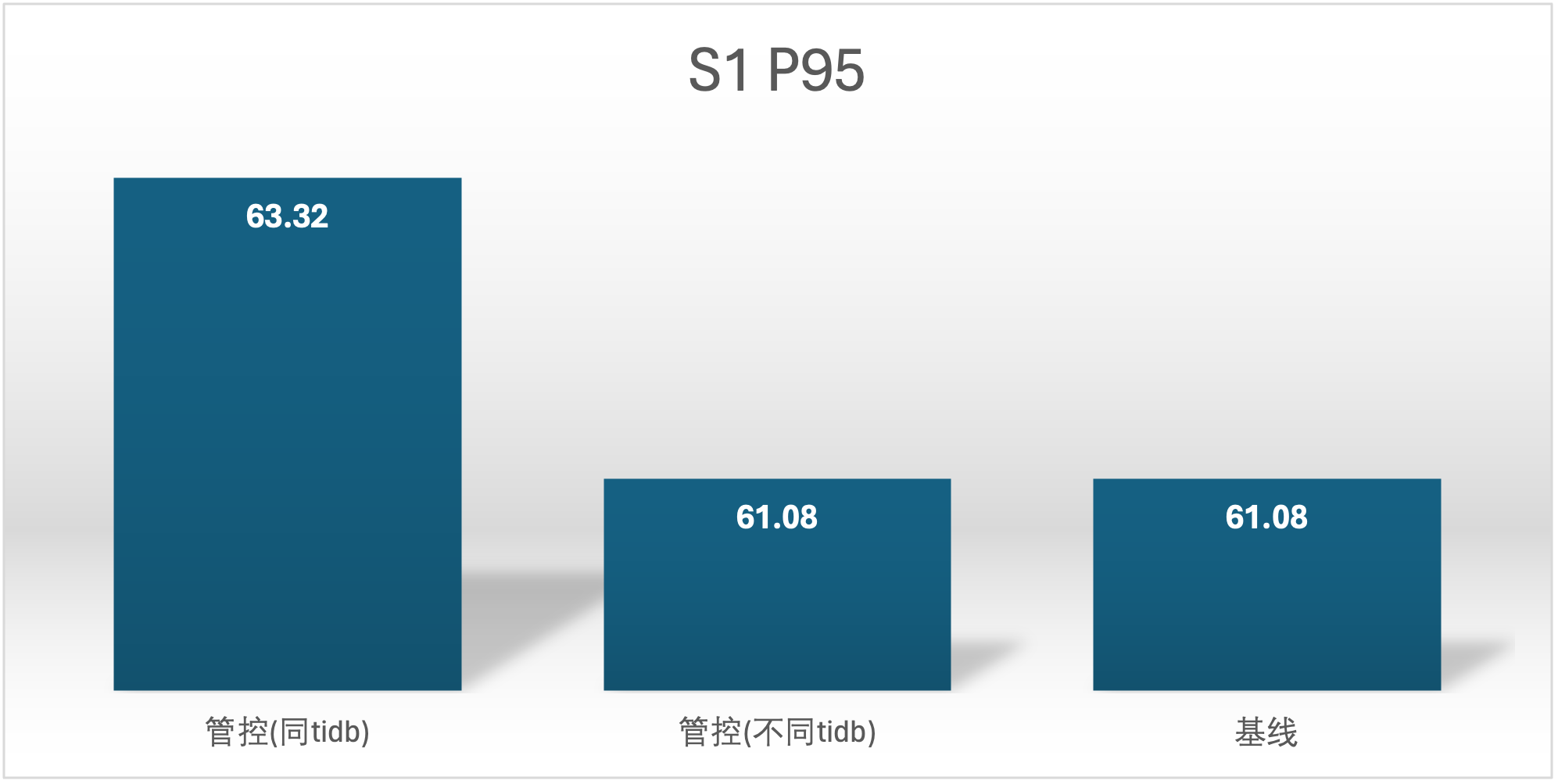
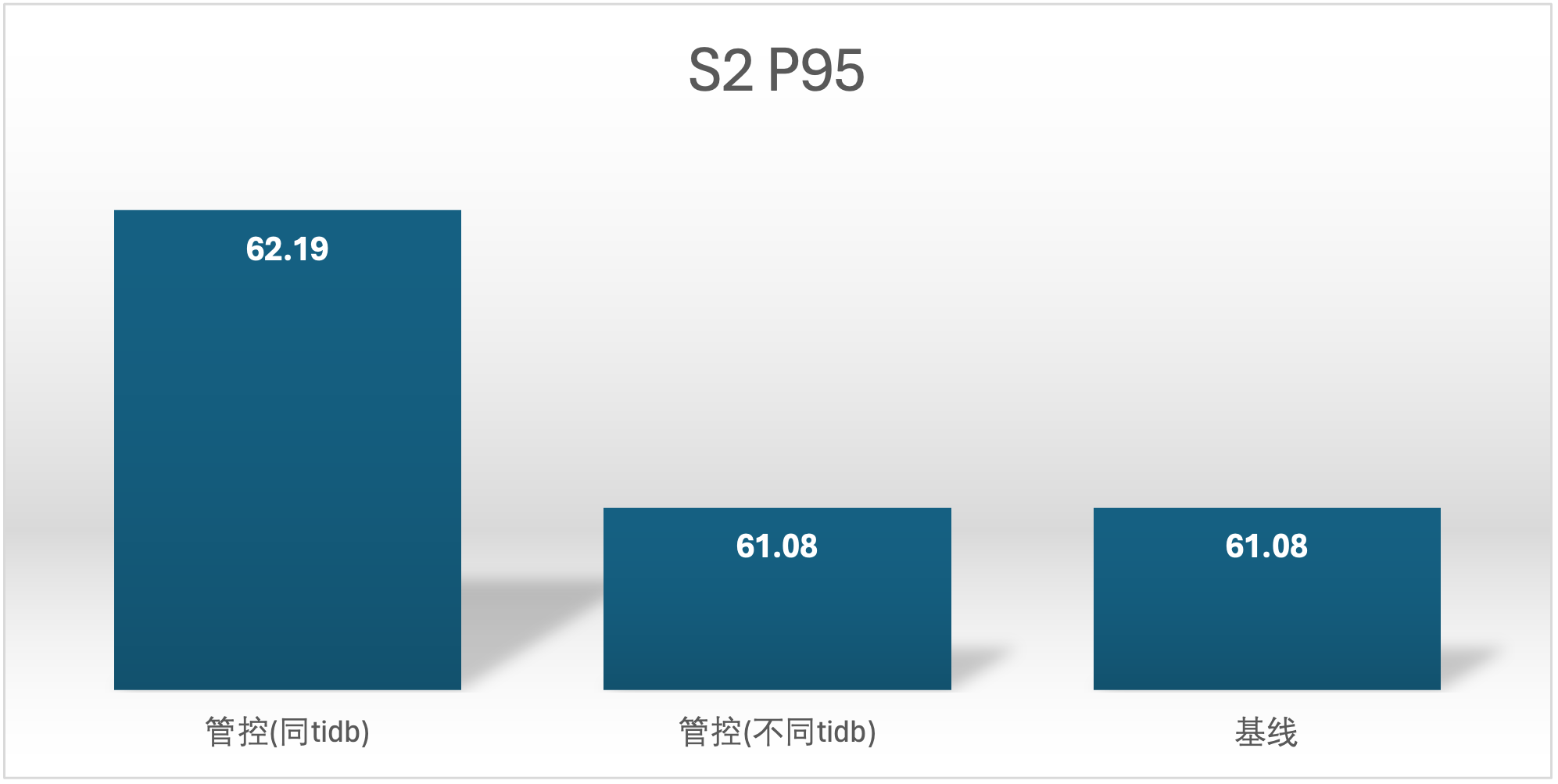
延时越小越好
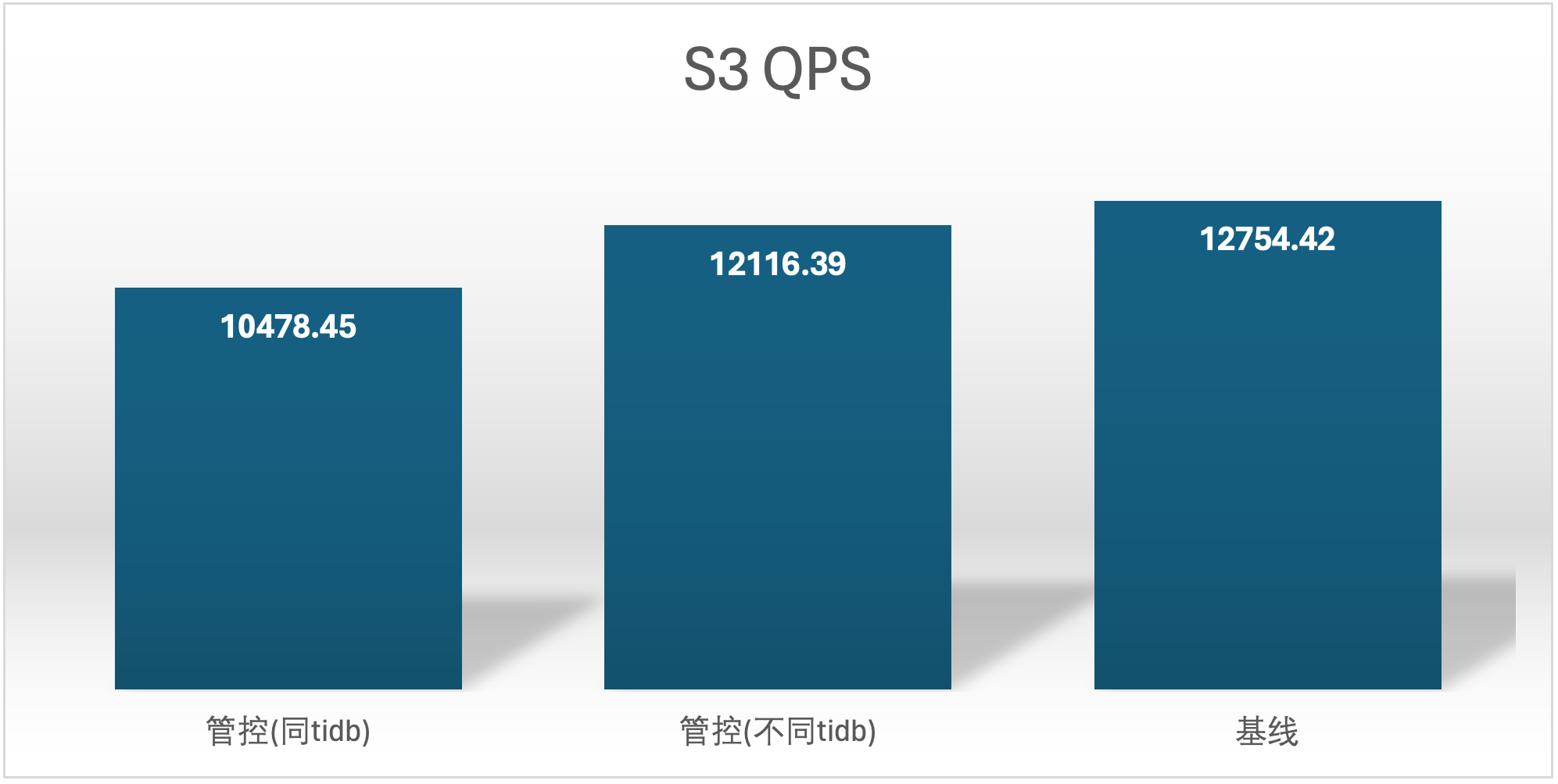
实验场景 t2_s1vss3、t2_s3vss1
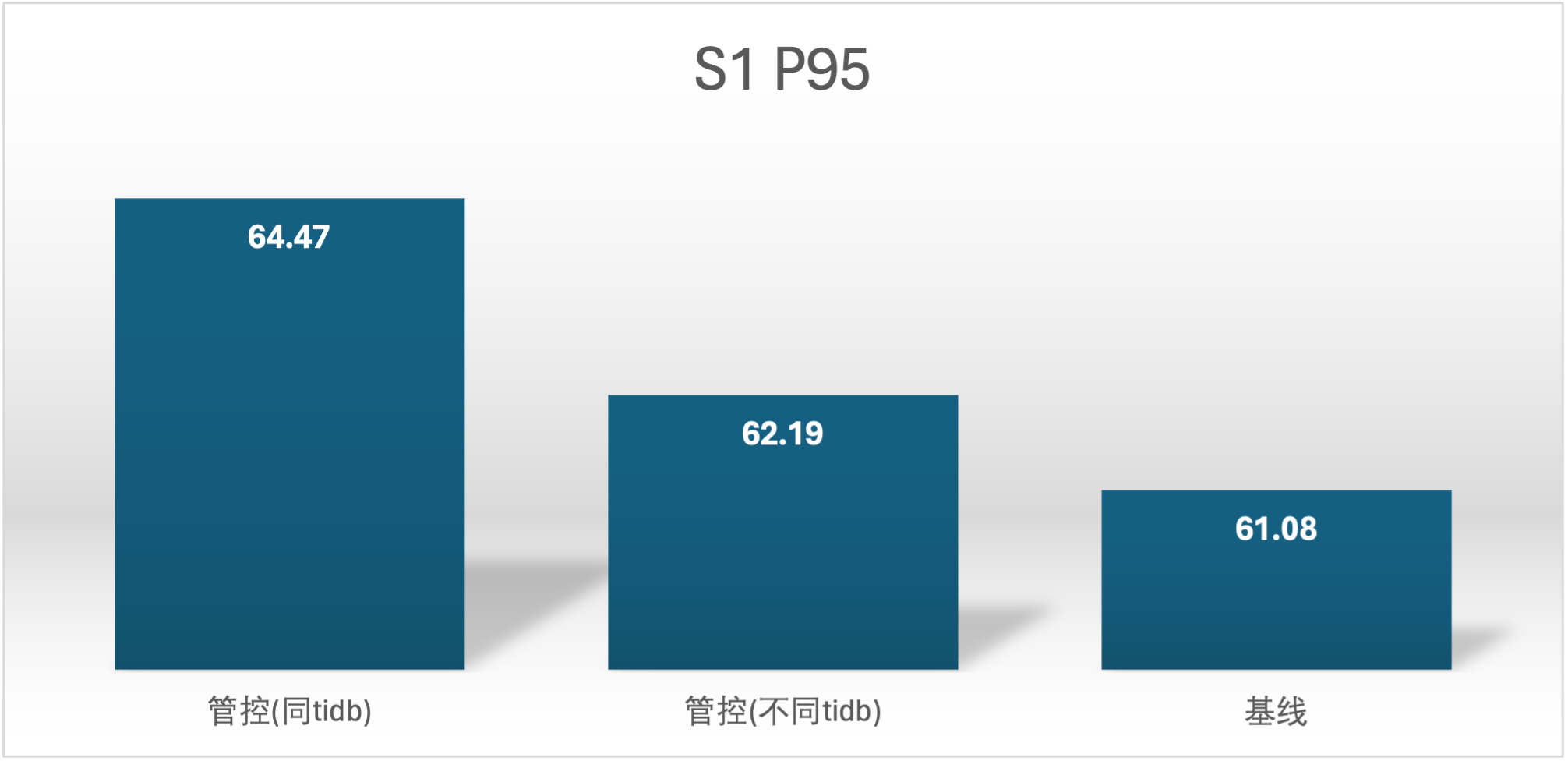
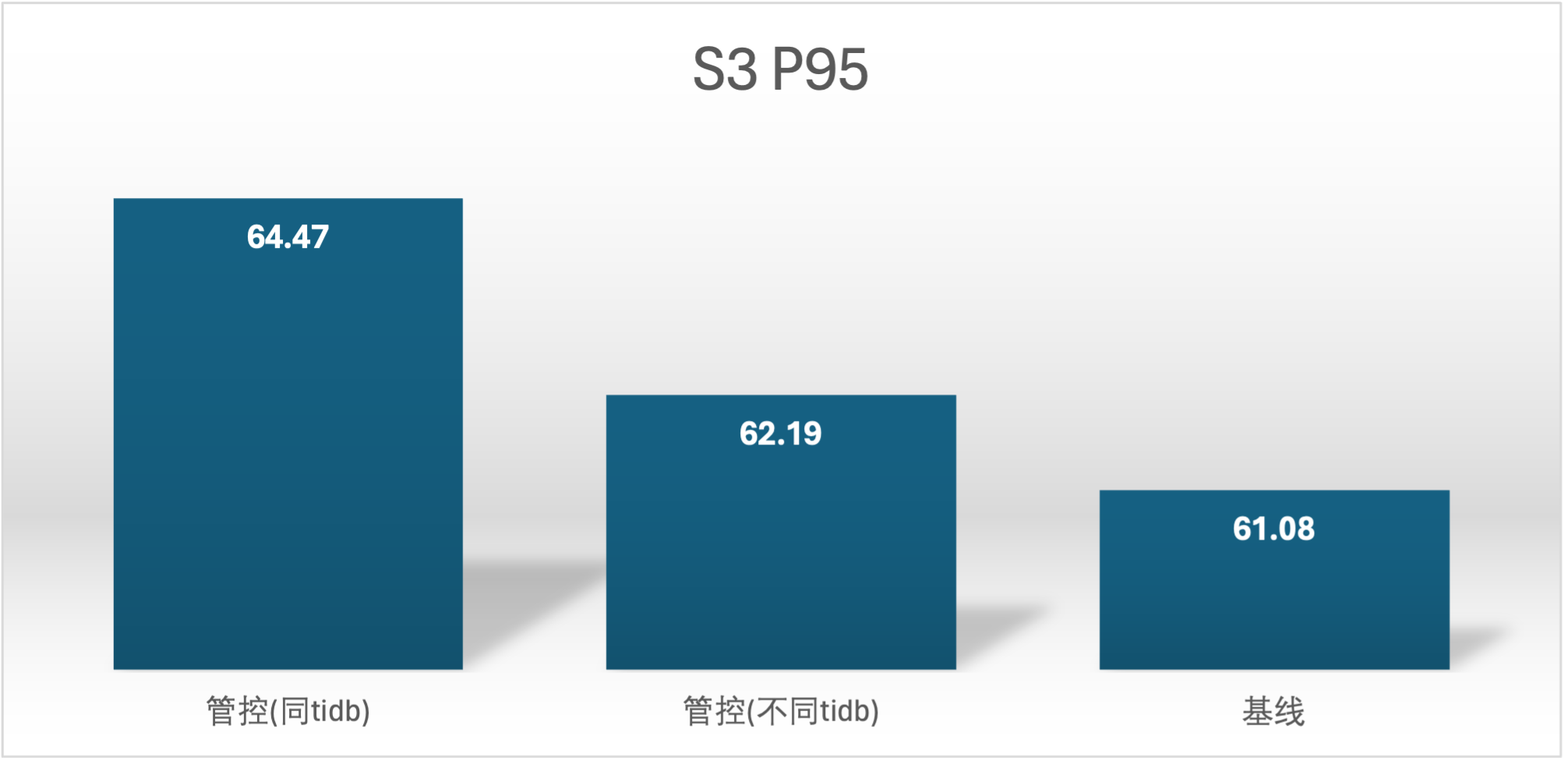
实验场景 t3_s1bvss2、t3_s2vss1b
可以看到超卖参数生效了 S1 在的 RU 在 50000,QPS 应该在 15000 ~ 16000,但是在 64 并发下来到了 20000+
在 S1 超卖的场景下,S2 在同一个 TiDB 计算节点上收到的影响比较严重大约有 12% 的影响
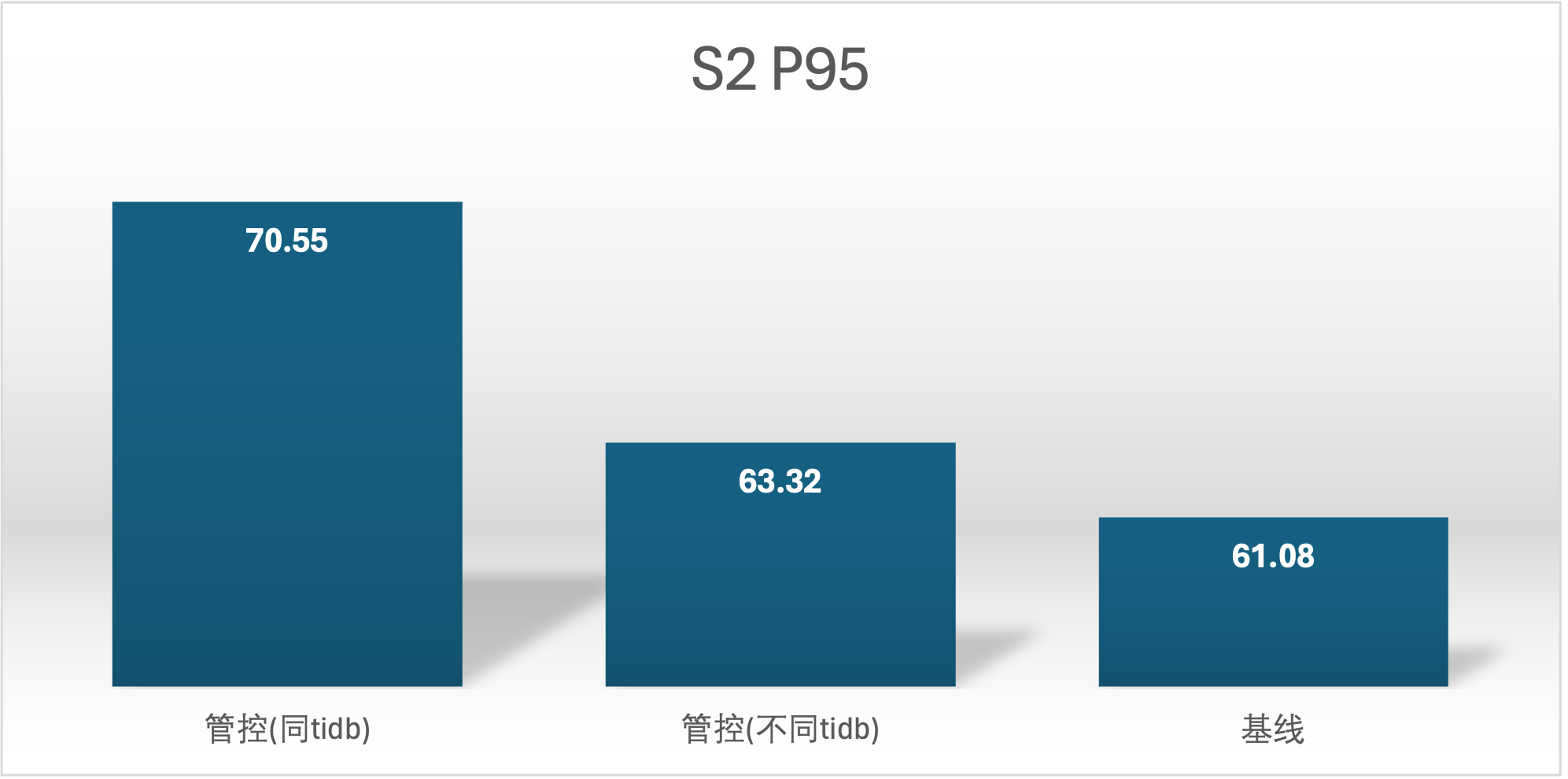
实验场景 t4_s1bvss3、t4_s3vss1b
S3 用户的优先级是 low 与 S2 用户 medium 相比,他们的 QPS 并没有差多少,S1 用户已经超卖了,讲道理应该优先保证 S1 用户的资源使用,这里难道是资源没有打满吗?
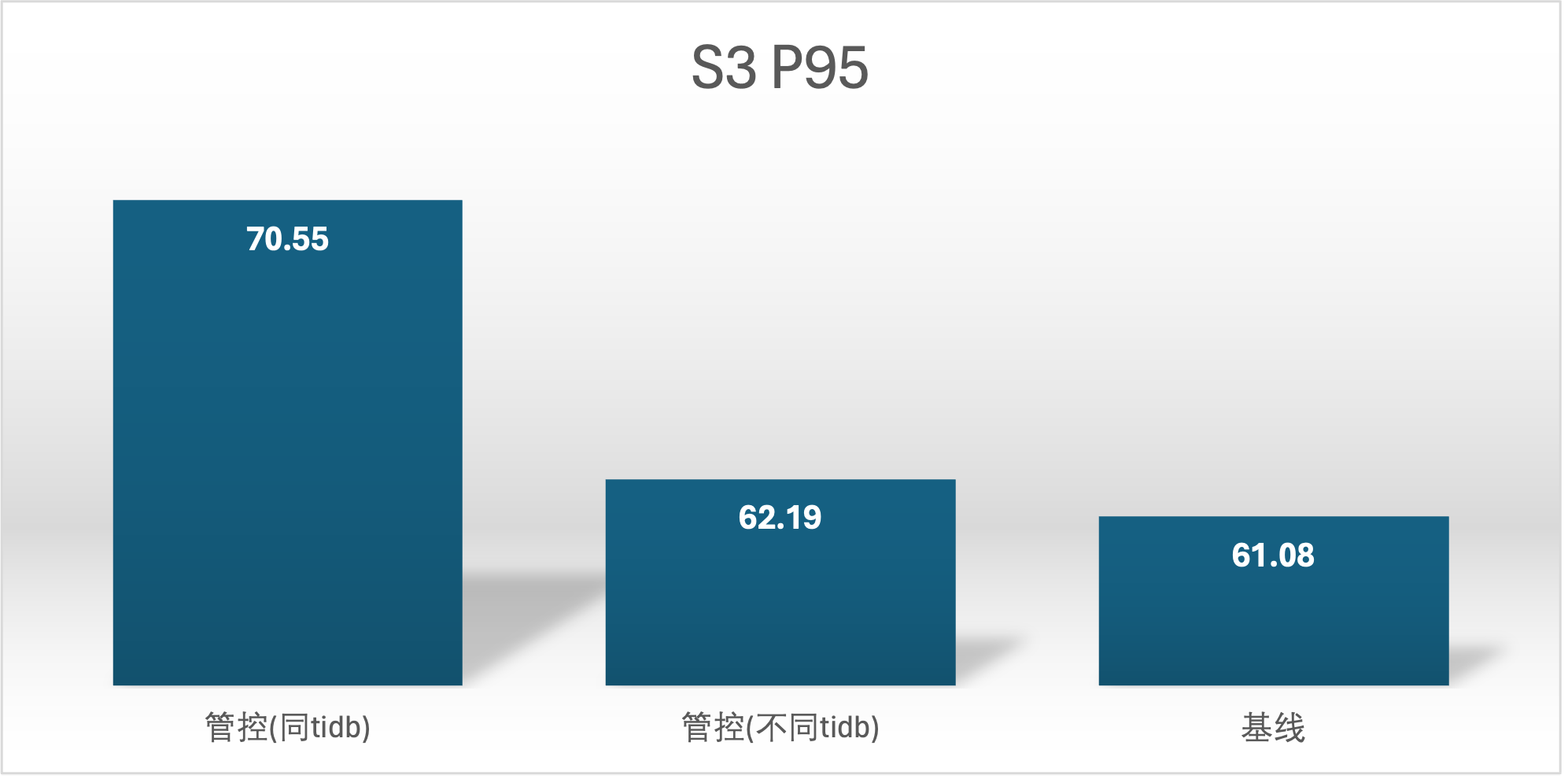
实验场景 t5_s2vss3、t5_s3vss2
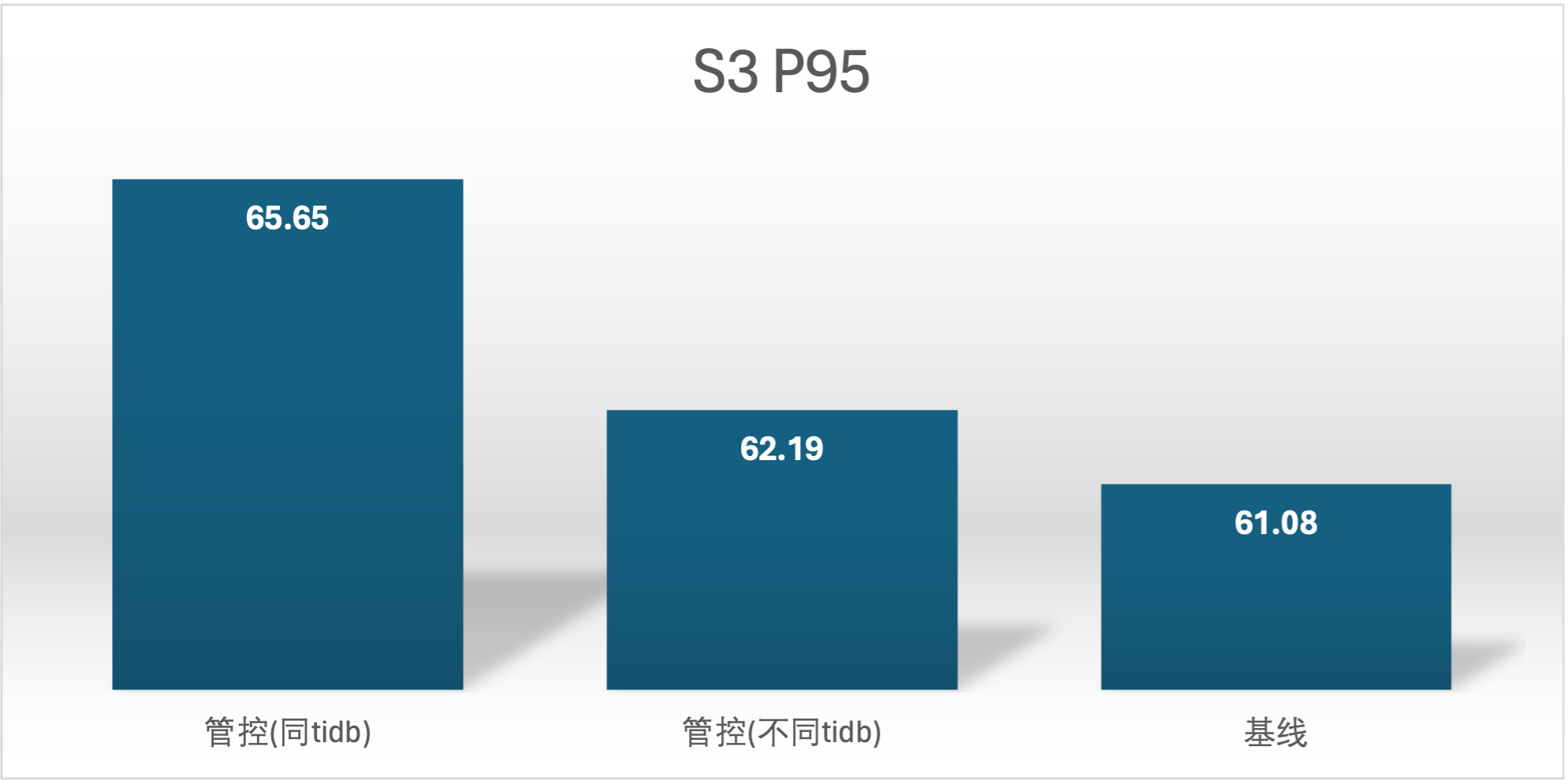
符合预期,因为在同一个 tidb 节点上会有相互影响的情况
OLTP vs OLAP
实验场景 t6_s1vss4、t6_s4vss1、t7_s1vss5、t7_s5vss1
说明:S4 和 S5 的区别为:S4 RU 25000;S5 RU 800
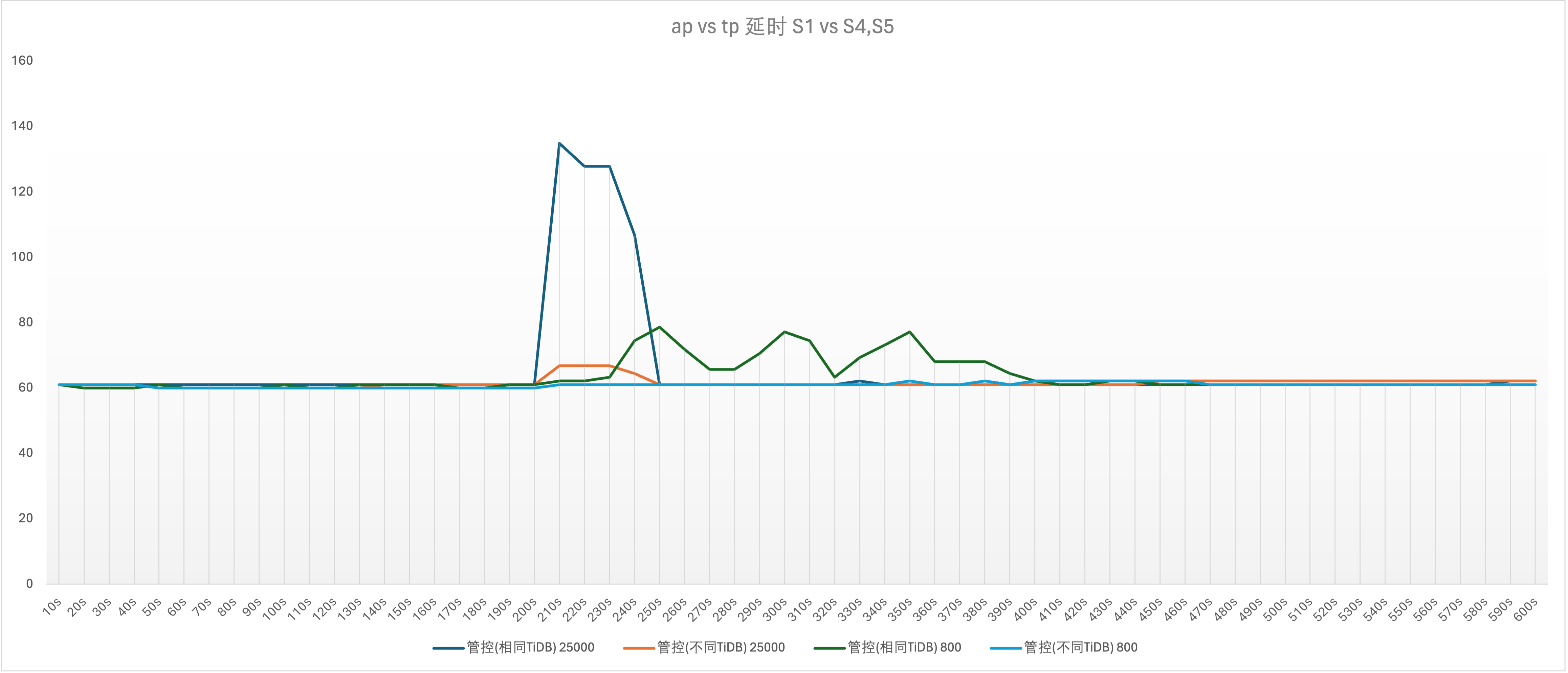
由上图可以观察到,最糟糕的情况就是 TP 业务和 AP 业务同时在一个计算节点上,延时几乎翻倍(当然也要看是什么类型的 SQL),其次是相同 TIDB 下的对 AP 业务进行 RU 限制,总体来说响应延时增加了 25%,接下来就是两个不同 TIDB 的不做限制(黄)和做限制(浅蓝),抖动可忽略不计
实验场景 t8_s2vss4、t8_s4vss2、t9_s2vss5、t9_s5vss2
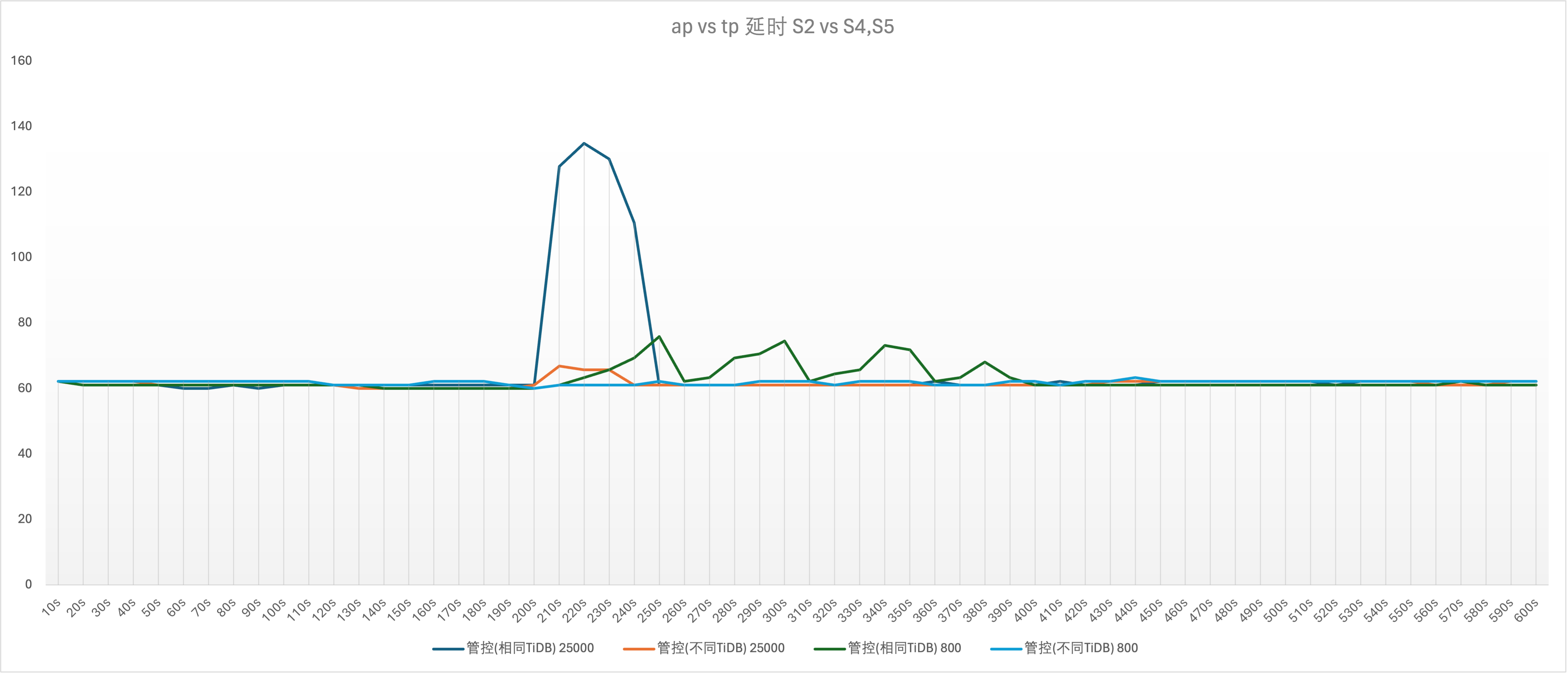
S1 和 S2 的图形基本相似
实验场景 t10_s2vss6、t10_s6vss2
说明:S6 的优先级为 Low
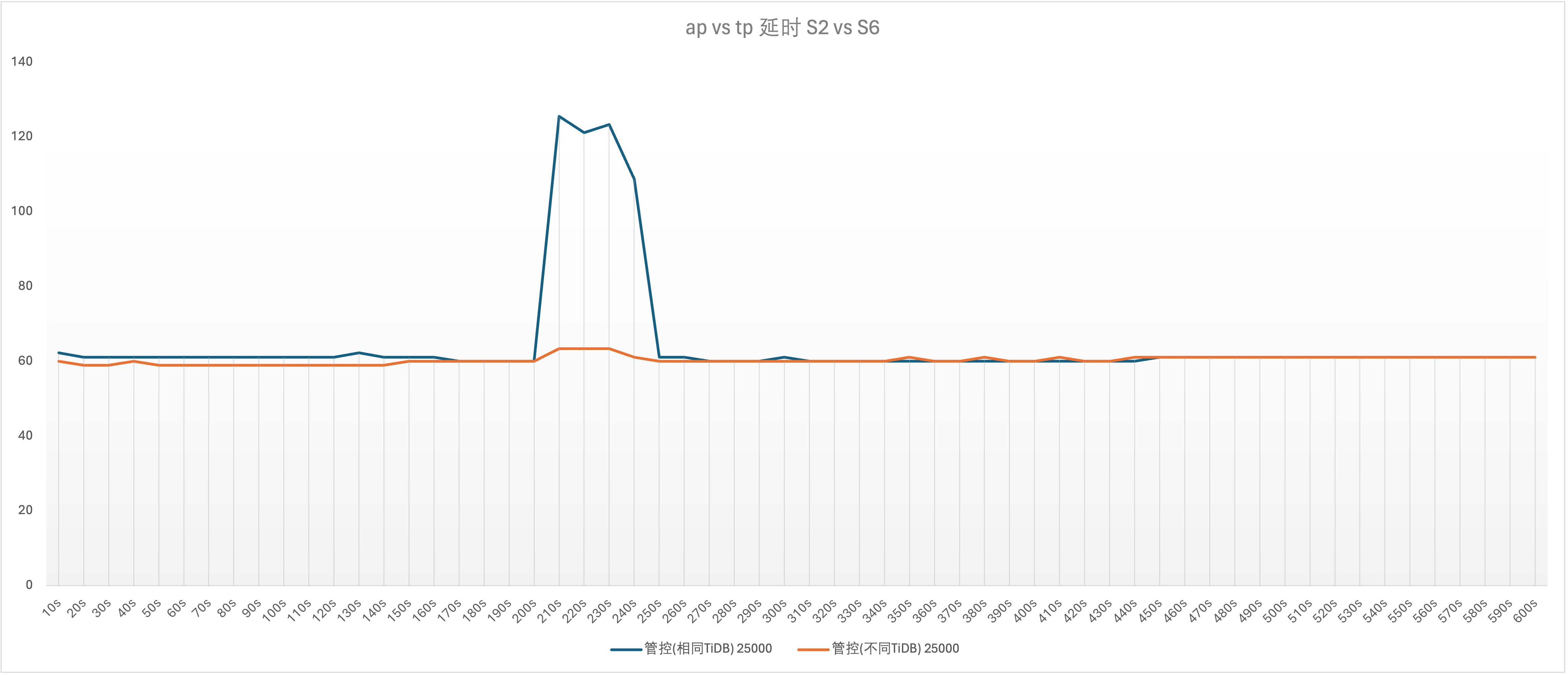
当初我还以为 low 的优先级不会影响 medium 的优先级,但是从图形来看并不是这样的
实验场景 t11_s1bvss6、t11_s6vss1b
说明:S1b 代表 S1 用户会突破自己的 RU 50000,采用 64 并发压测
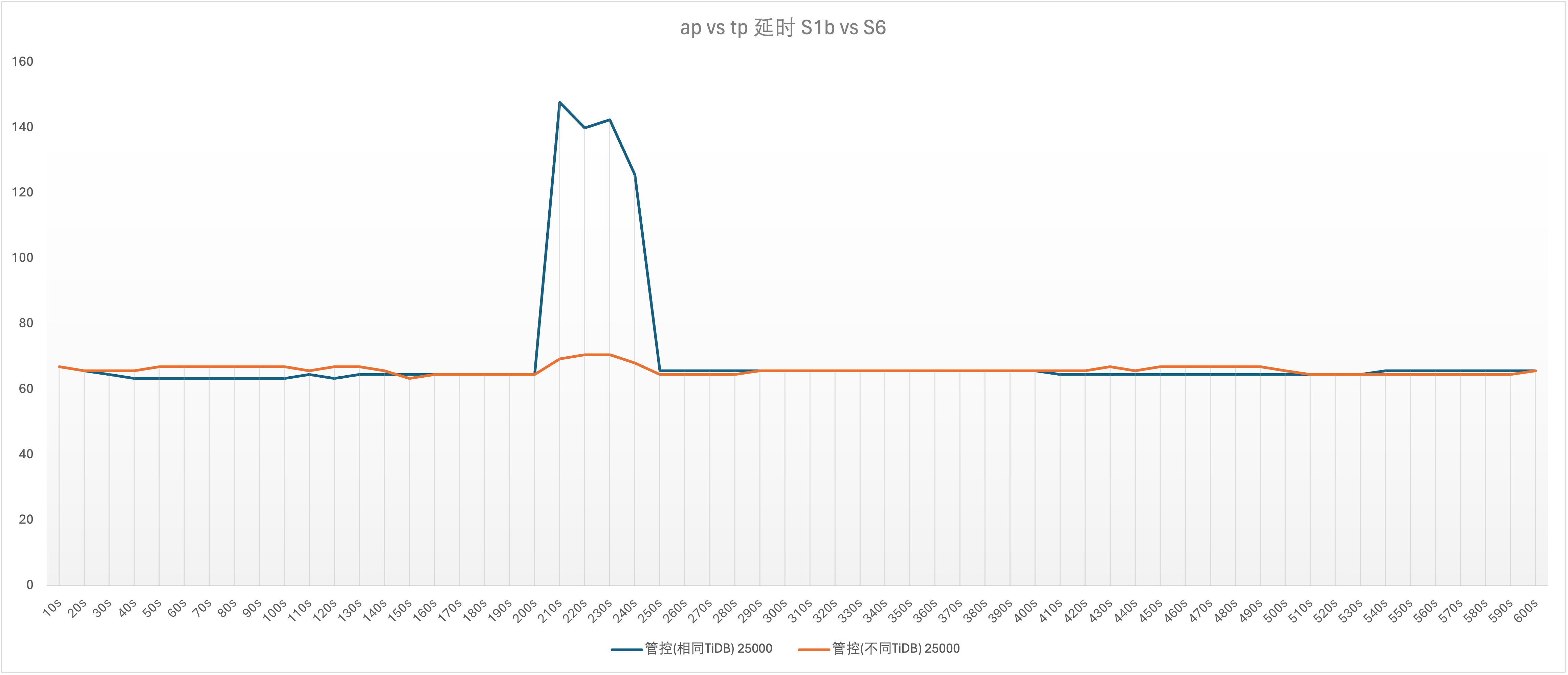
和上图基本相似
OLTP vs OLAP 的测试中,如果我们调转视角,从 OLAP 的角度,看 OLTP 是否影响了 OLAP 的响应时间,直接说结论(这里就不放图了),经过测试,影响的因素有两个,第一、是否在同一个 TiDB 上运行(差几秒 AP 类业务可忽略);第二、看 RU 设置的多少,其中第二为主要影响的因素。
OLAP vs OLAP
实验场景 t12_s4vsS6、t12_s6vsS4、t13_s4vsS6、t13_s6vsS4、t14_s4vsS6、t15_s6vsS4
说明:S4 和 S6 RU 都一样,只有优先级不一样,S4 是 medium,S6 是 low
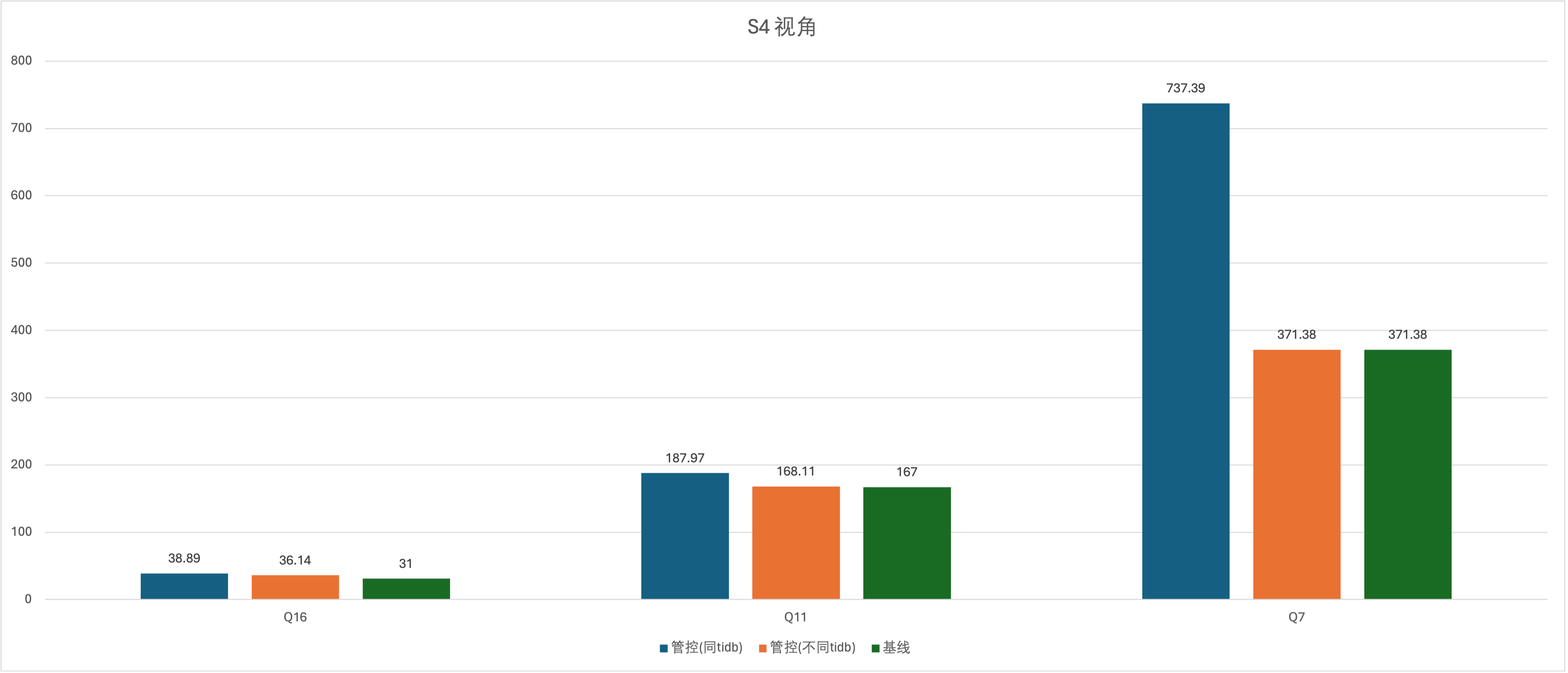
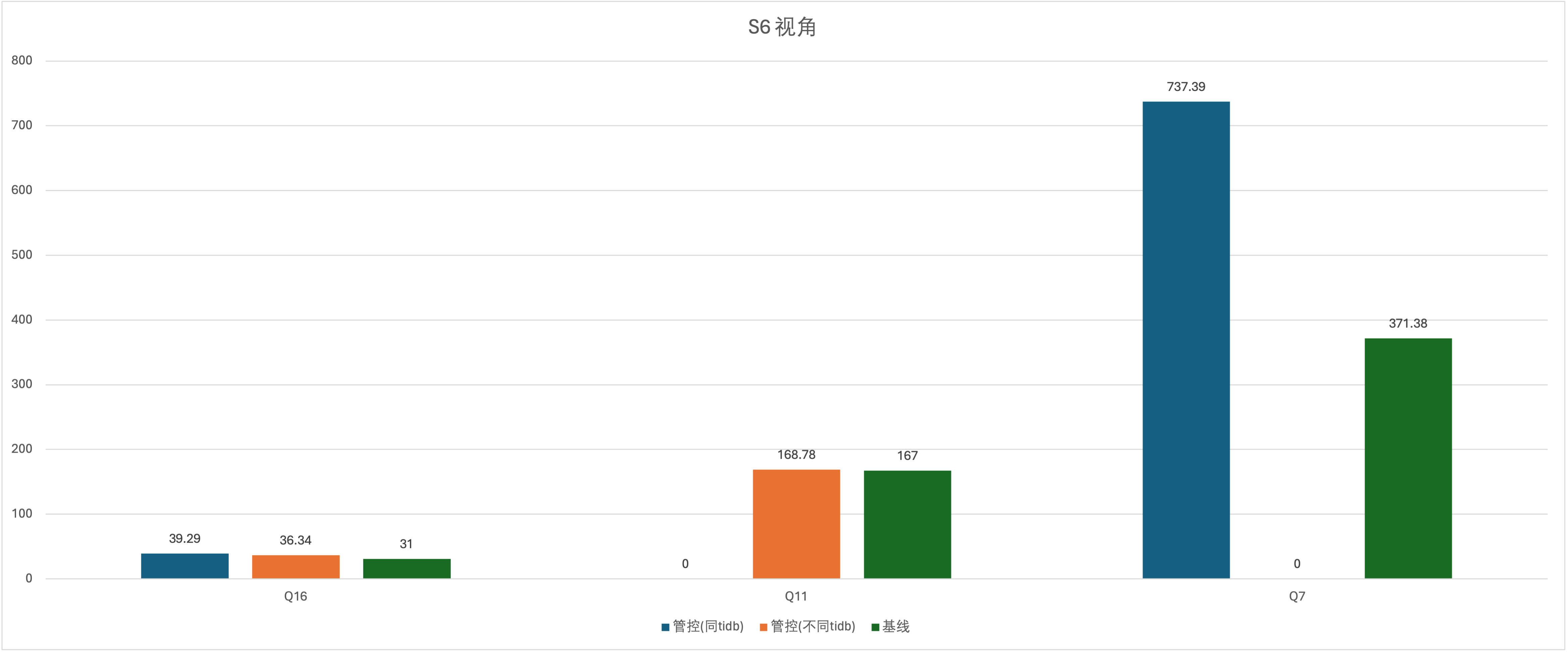
从优先级角度来说,返回速度不到明显的差异,还有 S6 视角有两个 0 ,出现在 Q11 和 Q7,这次都没有出结果,Q11的报错:Exceeded resource group quota limitation ,Q7 的报错 Query execution was interrupted,不确定这两个没有出结果的测试是否和 S6 用户的 low 有关,顺带说一句 Q11 和 Q7 这两个大 SQL,把没有 tiflash 的集群的 tidb 网卡直接跑满了,这肯定会影响其他业务的,可见资源管控对网卡的控制(或者说 RU 的计算)有待加强。
实验场景 t12_s4vsS6_f、t12_s6vsS4_f、t13_s4vsS6_f、t13_s6vsS4_f、t14_s4vsS6_f、t15_s6vsS4_f
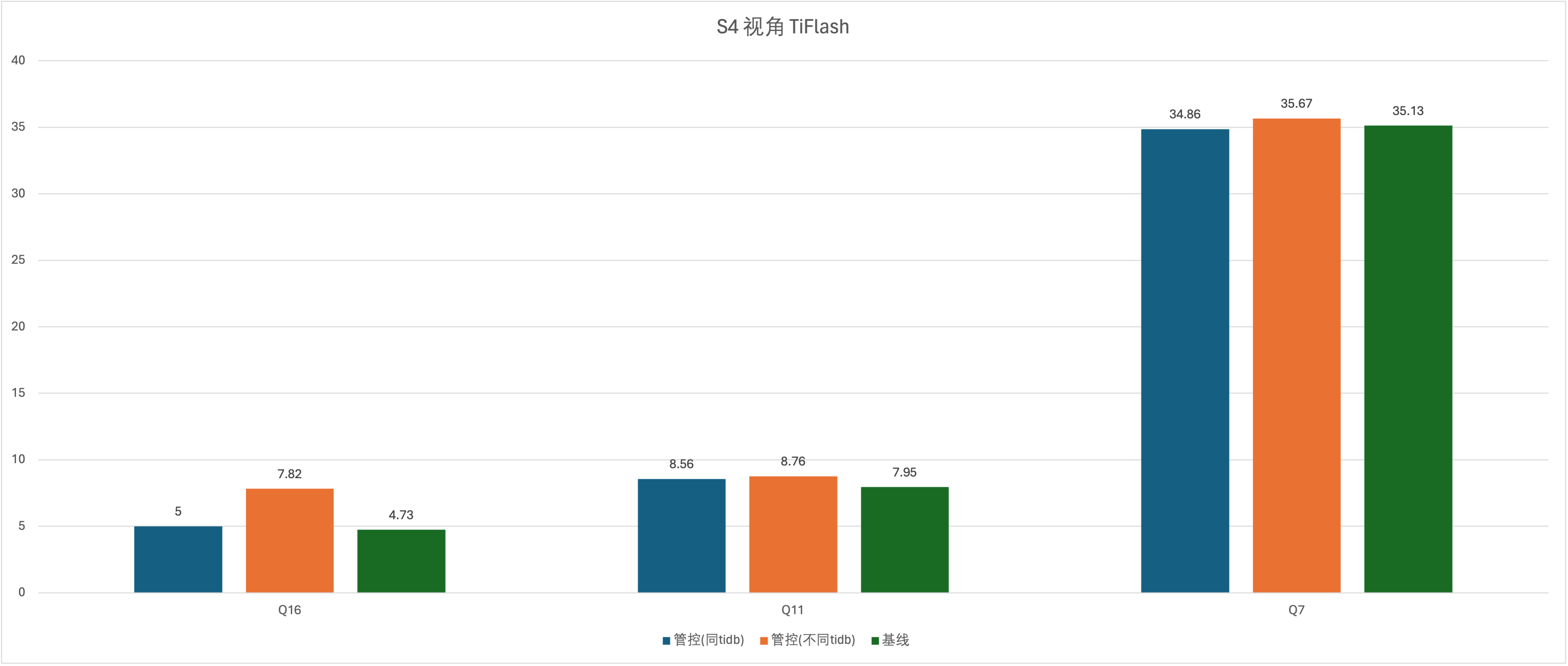
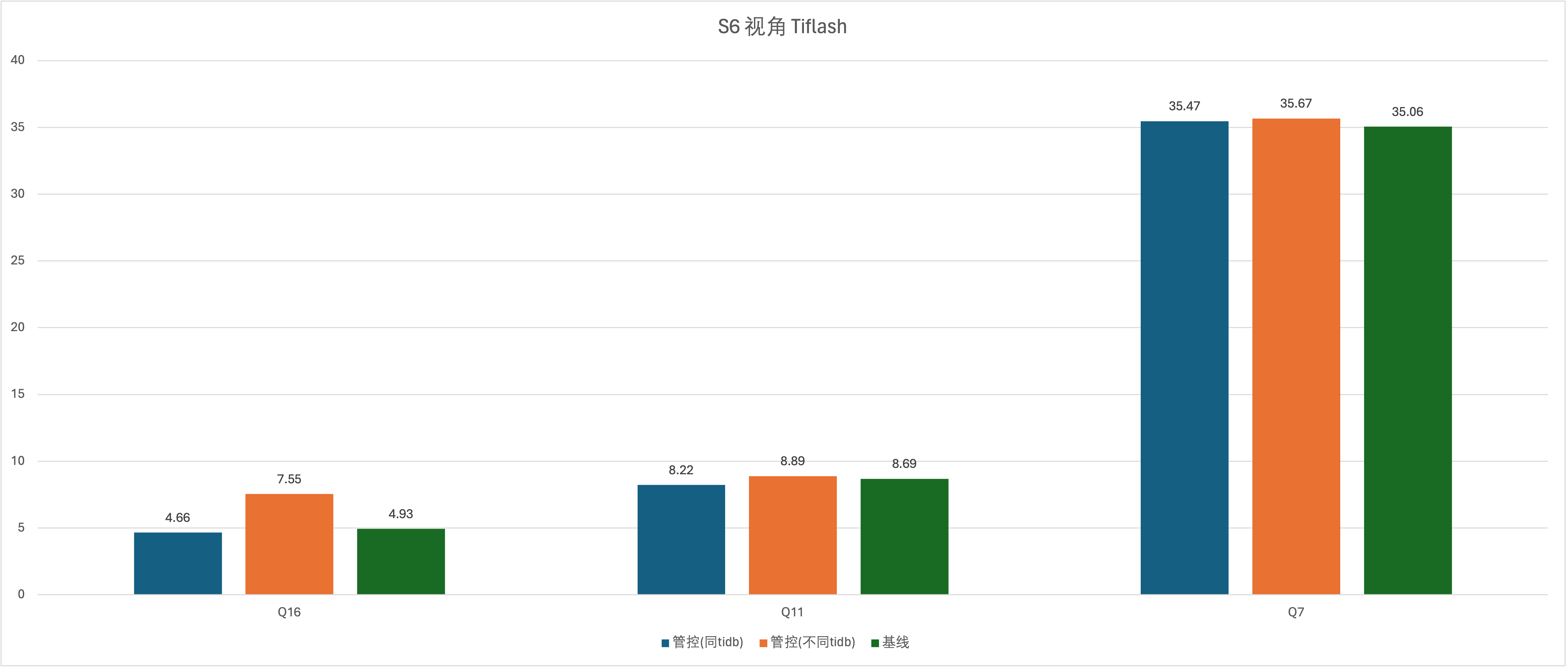
好消息是把 AP 的表加入到 TiFlash 中没有出现 SQL 无法跑出结果的情况,大部分 SQL 的结果大致相似,在运维层面,这几个 SQL 明显是走了 TiFLash 的,但是在 grafana 监控中,只有 RU(max)的监控有 SQL 资源组的消耗情况,RU 并没有,希望补充一下