👀日报&周刊合集 | 🎡ShowMeAI官网 | 🧡 点赞关注评论拜托啦!
1. 为啥大模型做不好简单的数学计算?从大模型高考数学成绩不及格说起

司南评测体系 OpenCompass 选取 7 个大模型 (6 个开源模型+ GPT-4o),组织参与了 2024 年高考「新课标I卷」的语文、数学、英语考试,然后由经验丰富的判卷老师评判得分。
结果如上图所示,Qwen2-72B、GPT-4o及书生·浦语2.0文曲星 (InternLM2-20B-WQX) 成为本次大模型高考的前三甲,得分率均超过70%。

但是!参与测试的所有大模型,「数学」考试都没过及格线 (90分)。根据官方披露的原因,大模型在数学考试中失分的主要原因是:
- 主观题回答相对凌乱,且过程具有迷惑性,甚至出现过程错误但得到正确答案的情况。
- 公式记忆能力较强,但是无法在解题过程中灵活引用 ⋙ 了解详细报道 | OpenCompass 公开了所有评测细节

大语言模型 (LLM) 无法对数字进行准确运算的底层原因是什么? 这是知乎上最近讨论比较热门的话题,@张俊林、@苏剑林 等大佬的高赞回答&评论区互动,也都非常精彩!欢迎围观~
简单来说,LLM 不擅长数学运算,直接原因是 Tokenizer (分词) 的设计。(解释一下,Tokenizer (分词) 是 LLM 的核心组成部,负责将文本分割成一系列的 token。这些 token 是模型理解和生成文本的基本单元。)
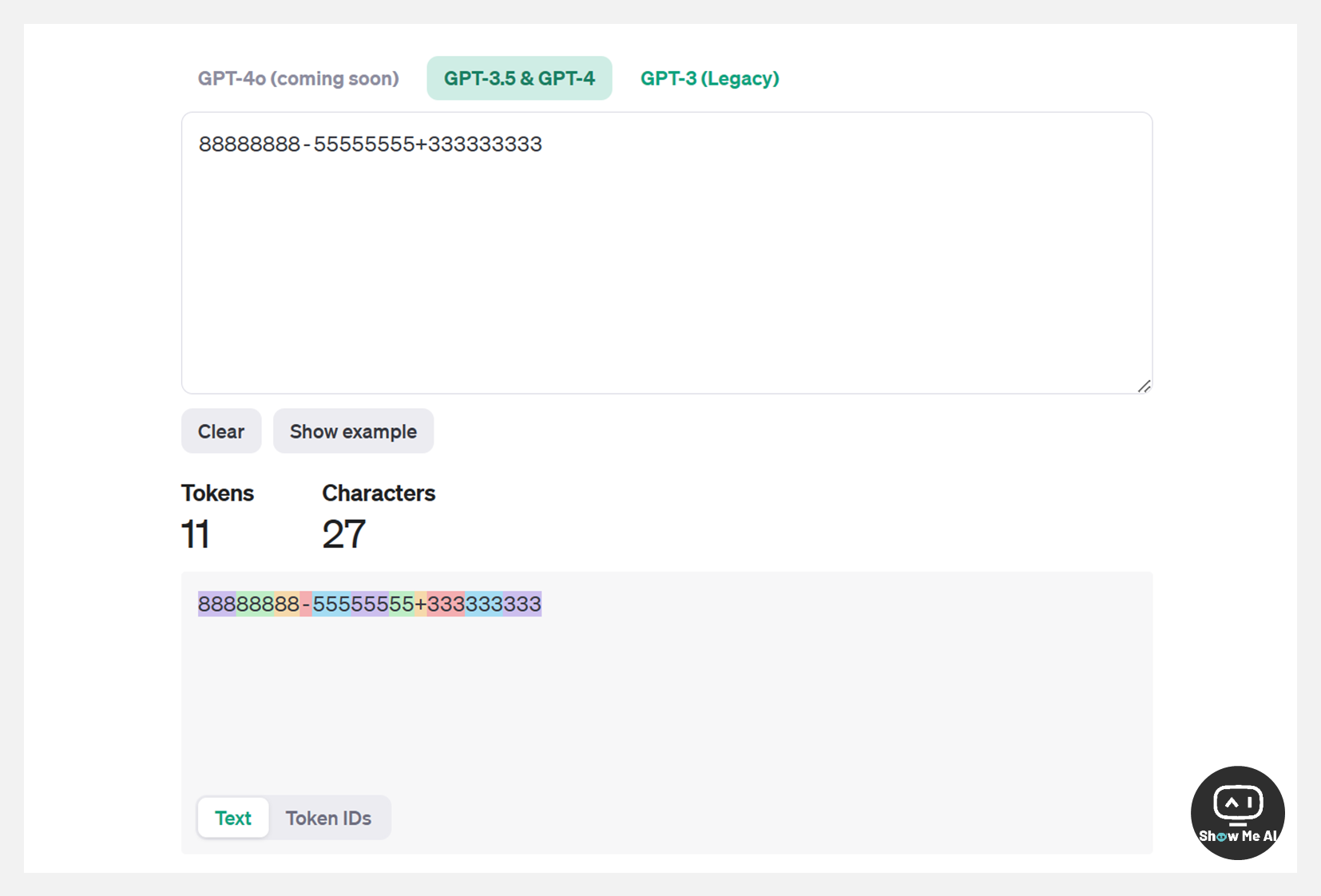
使用 OpenAI 官网提供的 Tokenizer 演示工具,可以看到 GPT-3.5 和 GPT-4 大模型在计算 88888888-55555555+333333333 过程中,把本该连续的字符串分成了彼此独立的 token,丧失了数学意义,自然也就没办法进行准确的数学运算。
OpenAI Tokenizer 演示网站 → https://platform.openai.com/tokenizer
知乎问题 (高赞回答很不错) → https://www.zhihu.com/question/654932431
2. 探索 AI 辅助阅读的新可能:不要只盯着要点总结,还纠结「不全or不准」啦!

对人类来说,阅读书籍 (读书) 往往是带有某种「光环」的。大部分人能轻松接受 AI 辅助写一段话、总结一篇文章、翻译一篇论文,却对「AI辅助读书」充满担忧:它不能替代我的阅读体验,它对这个话题的回答不全面,它这里生成的内容是错的……!!
那有没有可能!这个辅助方向,它就是错的呢?!
Dan McKinley 分享了自己一次很特别的试验:看看在读书过程中 AI 能否「结合参考资料,深度探索某个观点」,俗称「读书搭子」。
事情的起源有点偶然:最近读书时偶然发现,作者就某个观点给出的索引资料,似乎不能提供很好的支持。他心血来潮,想看看最先进的大模型能否帮助自己深度探索一下。
🔔 Round 1:直接询问AI的看法
- 把书里这个观点 & 支持这个观点的相关引用,都提供给AI。然后,询问AI对这个索引资料的看法,包括一般性的看法 + 2个具体问题「你怎么评价这篇资料?」「你认为这篇资料能有效支撑这个观点吗?」。
- 结果:不太理想。AI基本上给出的都是相当正面且宽泛的评价。
🔔 Round 2:要求AI对给定的资料进行打分
- 为了进一步探索,作者下载了相关的所有资料,都提交给AI,并要求AI在1-10分的区间里给每篇资料的「可信任度」「对观点支持程度」分别进行评分。
- 结果:不太理想。几乎所有资料的得分都是 9 分或 10 分,完全没有区分度。
🔔 Round 3:要求AI对给定的资料进行排名
- 改变策略!既然都能拿高分,那就从排名看高低。作者要求AI对一组资料进行「可信任度」「对观点支持程度」两个指标的排名。
- 结果:好像可以,其实不行。第一次运行的确得到了排名榜单!但是多运行几次就会发现,这个榜单里的排名每次都不稳定,有些资料的排名似乎很随机。
🔔 Round 4:取多次的平均值
- 优化策略!看看多次的平均值,能否是一个稳定的平均分。
- 结果:还是不行。20次测试后,所有资料最终平均值都趋向于 5/10,也就是说得分像抛硬币一样是个随机分布……
🔔 Round 5:看看负面评价的排名
- 策略反转!既然正面评价看不出眉目,就看负面的!作者要求要求AI给出所有资料的负面评价排名。
- 结果:更糟糕了。
探索有点不成功 😅 不过思路还是很好的!这也提醒我们,使用AI工具时,要让它做那些我们不擅长的事情!而不是用AI替代那些人类完成度接近满分的场景,然后反过来挑剔AI不太行。
原文 → https://mcfunley.com/i-tried-to-use-ai-to-read-an-ai-book
3. 企业如何在这轮 GenAI 浪潮种获得胜利:Two ways. Gradually, then suddenly.

Two ways. Gradually, then suddenly. 这句话出自海明威经典小说《太阳照常升起 (The Sun Also Rises)》,经常被引用形容事物的一种演变规律:在很长一段时间里,发展缓慢且不易察觉,但最终会突然爆发。
这是一份企业在 GenAI 时代的生存手册,从 8 个角度,详细阐述了企业会面临的挑战、详细的解决方案以及会遇到的阻碍。日报概述这 8 部分最核心的观点,非常推荐阅读原文或者查看完整报告!
- 逻辑 (The Logic):AI通过将工作任务从传统的人类服务中解绑,并重新整合进软件系统,从而转变了工作模式,提升了工作效率。
- 机遇 (The Opportunity):服务即软件 (Service-as-a-Software) 这一概念为企业提供了将复杂工作流程转化为软件解决方案的机会,开辟了创造新竞争优势的可能性。
- 企业环境 (The Enterprise Context):在2024年的企业环境中,性能的重要性超越了单纯的创新。企业需要深刻理解当前商业环境的要求,并探索如何利用AI技术来提升企业级性能。
- 工作流捕获 (Workflow Capture):捕获整个工作流程,而非单一任务的自动化,是企业AI成功的关键。这涉及到将工作流程从人工服务转变为软件驱动的过程。
- 商业模式优势 (Business Model Advantage):工作流的捕获为企业带来了新的商业模式优势,即基于服务性能的收费模式,这与传统的基于产品销售的模式形成了鲜明对比。
- 挑战与威胁 (Challenges and Threats):AI技术的快速发展带来了不连续性的改进,为企业带来了新的挑战和威胁。企业必须适应技术环境的快速变化,并准备应对新兴的竞争者。
- 竞争优势与企业账户扩展 (Competitive Advantage and Enterprise Account Expansion):企业需要构建防御机制,形成护城河,以抵御新兴竞争者的冲击,并利用AI技术来扩展其账户和市场份额,这包括对关键工作流程和决策点的控制。
- 胜者与败者 (Winners and Losers):企业AI的成功最终取决于企业适应AI技术发展的能力,以及它们是否能够利用这些技术获得市场竞争优势,并在市场中确立领导地位。
详细介绍 2 个文章提到的重点概念或实现路径。原文/原报告中此类信息很多,感兴趣拉到下方获取链接~
↑↑↑ 工作的拆解与重组
工作由一系列任务构成,这些任务既可以由人类服务完成,也可以由软件来执行。
GenAI 能够将工作分解为具体任务,并将这些任务重新组合为软件。这会显著改变企业的工作模式。
↑↑↑ 服务主导 → 软件主导
顺着上面一条说,企业工作模式的改变,会导致内部工作流从「服务主导」转向「软件主导」,也就是关键知识和管理工作,被AI接手了。上图分五步展示了这个过程:
- 服务主导的工作流:初始阶段,工作流主要依赖人类决策和手动操作,软件用于更简单的任务 (如数据处理或自动化)。
- 分解:AI执行特定任务的能力不断提高,工作流一步步被优化,逐步减少对人类手动工作的依赖。
- 组件化:把AI正式纳入当前工作流,而且某些特定任务被组件化,完全成为可被调用的软件模块。
- 重新组合:将工作流进行重新组合,按照新的决策序列完成重组。
- 软件主导的工作流:重组之后会出现一个软件主导的工作流,能更高效地执行任务。
原文 → https://platforms.substack.com/p/how-to-win-at-enterprise-ai-a-playbook
前往知识星球下载完整报告 (48页/英文) → https://t.zsxq.com/Lj4s1 资源编码【R270】
4. AI 项目失败的 6 个血泪教训:还是要尊重商业常识

我们在之前的日报,都在聊 AI 创业怎么成功。 👉 这期聊了如何获取创业 idea 👉 这期聊了AI应用的几种设计模式 今天来聊一些失败的经验教训。
🔔 问题定义不明确
- 教训:许多AI项目失败,是因为没能有效解决实际的商业问题。企业往往对新技术趋之若鹜,却忽略了先明确一个商业目标。
- 经验:从基础评估着手,确定需要解决的商业问题;与客户和员工深入交流,进行利益相关者访谈和市场分析,通过原型或试点项目进行迭代验证,并咨询AI领域专家等。
🔔 与现有系统的整合不充分
- 教训:到了实施阶段才发现,新的AI解决方案没办法与现有的操作系统进行无缝集成。主要原因是低估了这件事的复杂程度。
- 经验:一定要制定周密的集成计划,确保AI解决方案与现有软件协同工作,并确保用户在项目早期就参与进来。
🔔 需求收集不准确和缺乏成功指标
- 教训:战略规划还不充分,就急于实施AI。
- 经验:采取分阶段的方法,包括全面评估、概念验证 (PoC)、探索阶段,以确保项目与业务目标一致,并建立清晰的绩效指标。
🔔 对潜在风险认识不足
- 教训:随着AI的广泛应用,相关风险也在增加。
- 经验:制定包含风险评估的明确路线图,识别潜在风险,实施控制措施,并持续监控。
🔔 缺乏行业专业知识
- 教训:选择没有特定行业经验的AI技术供应商,可能导致项目面临重大挑战。
- 经验:优先选择在某行业中有成功案例的AI技术合作伙伴,确保他们了解并遵守相关行业法规和标准,并进行紧密的协作开发。
🔔 公司内部人员准备不足
- 教训:AI项目的成功不仅取决于技术设置和业务规范,还依赖于使用系统的人员的准备情况。
- 经验:提高员工对AI的认识,让他们参与实施过程,将AI目标与部门 KPI 联系起来,让员工参与软件测试,并提供持续的培训和支持。
原文 → https://dlabs.ai/blog/key-reasons-why-ai-projects-fail-and-how-to-avoid-them/
5. 手把手教你在美国搭建「百万卡」级别的 AI 数据中心 (bushi

我们在之前 👉 这期日报 整理过一期超棒播客的要点,即AI爆发导致的能源问题 & 解决方案,其中就提到美国高科技公司正在大规模建设 AI 数据中心。
这次!更内部和专业的分享来了!非常详细地介绍了 AI 数据中心的组成部分、当前在美国面临的严重电力限制、数据中心的关键评价指标 (能源效率和可靠性)、数据中心未来的发展趋势……
而且!文章细节非常丰富,各种数据和报告超链接咔咔甩,的确是非常专业。日报整理部分新内容,感兴趣强烈推荐看原文哦~
🔔 数据中心的组成要素

数据中心,这个词指的是一个简单的基本结构:一个包含计算机或其他IT设备的空间。
不过,我们所认为的现代数据中心,是专门建造的巨型建筑,用于容纳成千上万台被堆叠在大型机架上的计算机,以及其他操作它们所需的设备,如网络交换机、电源和备用电池等。
数据中心消耗了大量电力,意味着数据中心需要大型变压器、高容量的电力设备,如开关设备,有时甚至需要一个新的变电站来将它们连接到输电线路。这也意味着数据中心有超高的散热需求,也就需要同样强大的设备来迅速将热量排出,并通过庞大的冷却循环系统完成循环。
🔔 电力使用效率 PUE
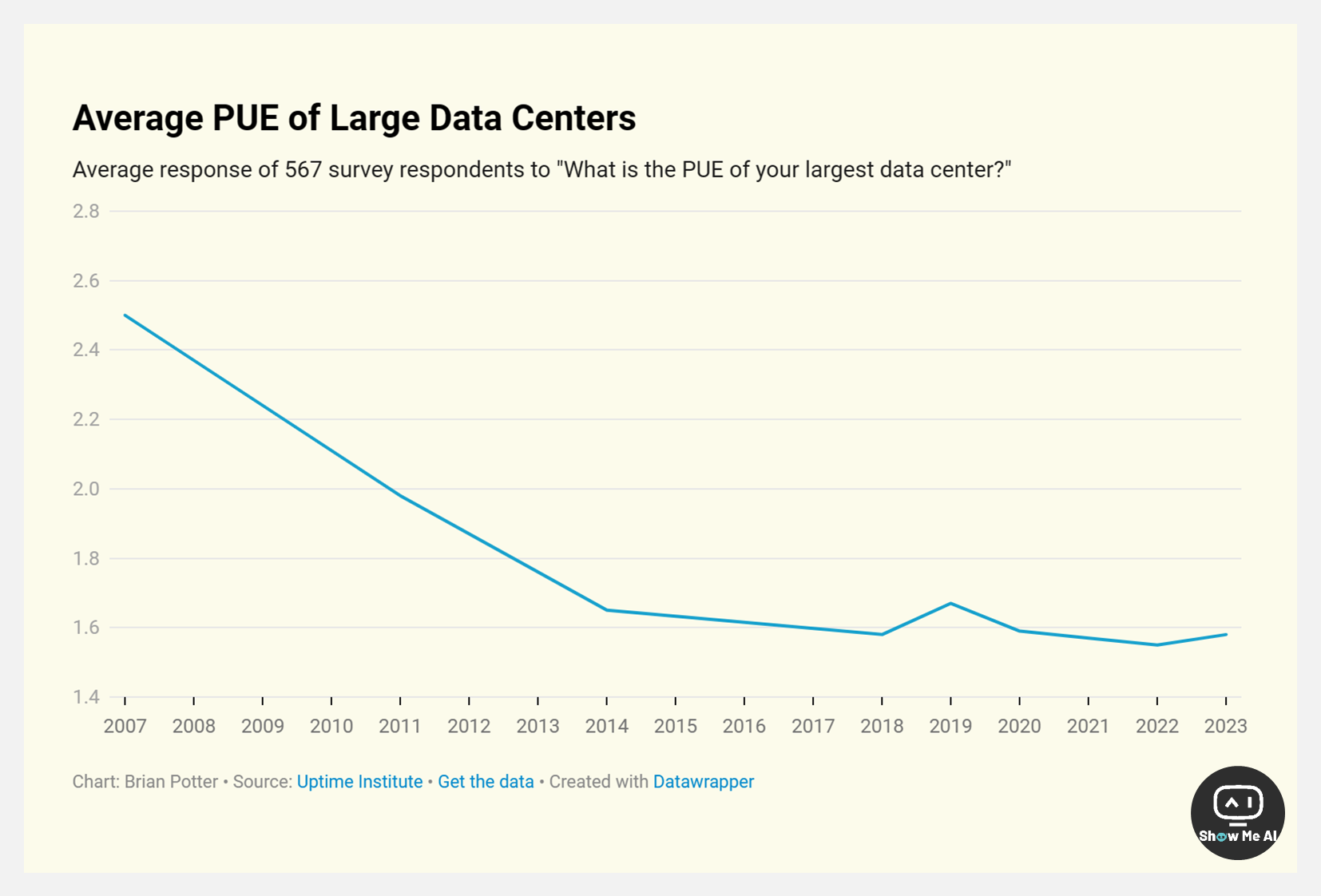
数据中心的一个常见性能指标是电力使用效率 (PUE) ,即数据中心消耗的总电力与IT设备消耗的电力之比。比率越低,用于运行计算机之外的事物的电力就越少,数据中心的效率就越高。
如上图所示,数据中心 PUE 随着时间的推移稳步下降,如今平均PUE已降至 1.5 左右。而且超级数据中心做得更好:Meta 平均数据中心PUE仅为1.09,Google 也在 1.1 附近。
PUE 数据得以改善的原因,是使用了更高效的组件 (例如具有更低转换损失的不间断电源系统) 、更好的数据中心架构 (改为热通道、冷通道布局) 以及在更高温度下运行数据中心以减少冷却需求等等。
🔔 数据中心可靠程度层级
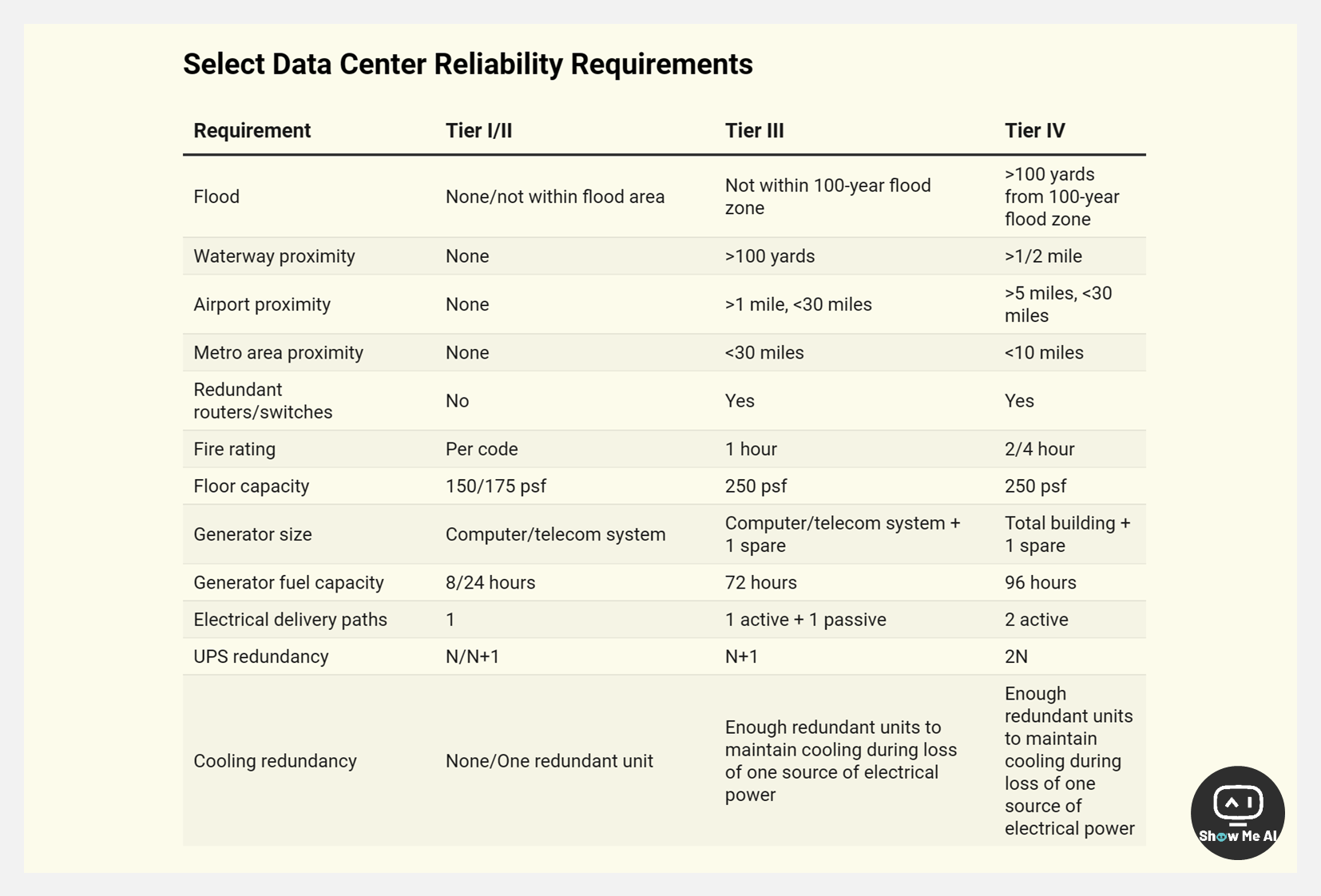
大型数据中心可能服务于数百万客户,服务中断会轻易造成每分钟数万美元的损失。因此数据中心被设计为最小化停机风险。
如上图所示,数据中心的可靠性根据分层系统进行评级,从Tier I 到Tier IV,等级越高表示可靠性越高。大多数美国的大数据中心位于Tier III和Tier IV之间。它们拥有备份柴油发电机、防止单点故障的冗余组件、电力和冷却的多个独立路径等。
Tier IV数据中心理论上将实现99.995%的正常运行时间,尽管实际上人为错误往往会降低这种可靠性水平。一个2N冗余电源系统,其中每个电源组件 (公用事业供电、发电机、UPS等) 都有完整的备份。
原文 (其他话题也解释得非常详细,包括AI数据中心得全球选址、英伟达芯片的发展方向、冷却方式的进一步进化等) → https://www.construction-physics.com/p/how-to-build-an-ai-data-center
6. 一份技术大大的「LLM 资源清单」:从入门到入行,从上手到上道

这份 LLM 主题的资源清单有点不一样!它出自一位技术同学之手,非常全面地反映了一位 AI 开发者的日常:
- 🛠️ Projects 做项目
- 📺 Youtube channels 看油管
- 📚 Books/Textbooks/Blogs 看书/文档/播客
- 🪐 Important projects you should probably be aware of 跟进重大项目进展
- ⏰ Projects I need to try 试试新项目
- 👨💻 Discord servers 社交
- 👨👨👦👦 Meetup groups 社交
- 📝 Research Papers 读很多很多很多论文
- 🧰 Tools, Libraries, Platforms 工具库
- ✅ Trusted sources 逛各种更新
清单有点长,日报选两个有趣、通用的介绍一下。都是国外的资料,感兴趣可以前往原文获取超链接~
🔔 YouTube频道
CGP Grey:作者最喜爱的频道之一,这条「How AIs, like ChatGPT, Learn」视频被作者认为是AI领域的最佳入门视频。
Computerphile:与 Numberphile 和 Sixty Symbols 一样,都是由 Brady Haran 创建的视频频道。推荐 Mike Pound 和 Robert Miles 的视频,可以帮助打开数据科学、机器学习和人工智能的大门。
Robert Miles:创作者是一名AI安全研究员,他的 GPT-2 和 「Attention is all you need」论文解读视频,对作者的影响尤其深远。
3Blue1Brown:最佳的数学教育资源,特别是线性代数和神经网络系列。
Andrej Karpathy:大佬的「zero to hero」播放列表,为语言模型的普及教育做出了非常重要的贡献。
Machine Learning Street Talk:技术播客,采访了机器学习领域各种各样的从业者,非常有趣。
Dwarkesh Patel:目前最受欢迎的播客节目,对话式的播客格式,还有对AI主题的深入探讨。
Yannic Kilcher:主要阅读优秀的机器学习论文阅读,Discord 社区也很活跃。
Linus Lee:Notion AI负责人,可以通过他的演示来关注未来 UX 设计的变化,尤其是与模型的交互方式。
🔔 工具、库和平台
Ollama:一个允许在本地运行大型语言模型的工具,使用Go语言编写,并通过cgo与llama.cpp交互。
Hugging Face:一个共享机器学习模型的平台,提供了丰富的教程和社区支持,可以看作是机器学习领域的GitHub。
Langchain:提供了代理协调功能,但作者计划将来可能会使用Swarms替代,因为Swarms提供了更优秀的多代理协调。
Perplexity:一个搜索引擎,提供了比传统搜索引擎更清洁的搜索结果,没有广告干扰。
cursor.sh:Visual Studio Code的一个分支,集成了更强大的AI功能,特别是对于代码生成和理解。
Google AI Studio:提供了低廉的按令牌成本和更优化的代码生成界面,作者认为它在生成代码方面优于标准界面。
Arc Browser:一个浏览器,具有AI搜索功能和直接访问ChatGPT的选项,极大地提升了作者的浏览体验。
Google scholar chrome extension:一个浏览器插件,可以方便地查看论文的参考文献,通过悬停元素直接链接到引用的论文。
Myst:一个工具,用于制作精美的Jupyter笔记本,可以导出为PDF等格式,作者考虑将其用于代码相关的博客文章。
原文 (尤其论文清单,那叫一个详细和全面啊) → https://joshcarp.notion.site/LLM-resources-fe118332b84f49c286b8045922c7f5a2

◉ 点击 👀日报&周刊合集,订阅话题 #ShowMeAI日报,一览AI领域发展前沿,抓住最新发展机会!
◉ > 前往 🎡ShowMeAI,获取结构化成长路径和全套资料库,用知识加速每一次技术进步!