Stripe Radar 是 Stripe 提供的一项防欺诈服务,它利用机器学习技术来帮助商家检测和阻止信用卡欺诈行为。这篇文章是Stripe公司关于其反欺诈解决方案Stripe Radar的构建过程的介绍。文章从Stripe的防欺诈团队工程师的角度出发,详细讲述了Stripe Radar的工作原理、技术架构的演进、机器学习(ML)特征的重要性,以及如何提供交易欺诈决策的解释。
原文链接:https://stripe.com/blog/how-we-built-it-stripe-radar
文章开篇描述了Stripe Radar在用户点击“购买”到交易确认之间的极短时间内的工作流程。Stripe Radar通过评估超过1000个潜在交易特征来确定其欺诈可能性,准确率极高,错误阻止的合法交易仅占0.1%。
In that brief interval, Stripe Radar goes to work. Radar is Stripe’s fraud prevention solution. It assesses more than 1,000 characteristics of a potential transaction in order to determine the likelihood that it’s fraudulent, letting good transactions through and either blocking risky transactions or diverting them to additional security checks. It makes this decision, accurately, in less than 100 milliseconds. Out of the billions of legitimate payments made on Stripe, Radar incorrectly blocks just 0.1%.
Lesson 1: 不要对机器学习架构过于自满
Stripe Radar的构建始于相对简单的机器学习模型,随着Stripe网络的扩展和机器学习技术的进步,逐渐发展到更复杂的深度神经网络模型。2022年中期,Stripe从“Wide & Deep”模型迁移到了纯DNN模型,这一转变显著提升了模型的训练速度和扩展性。
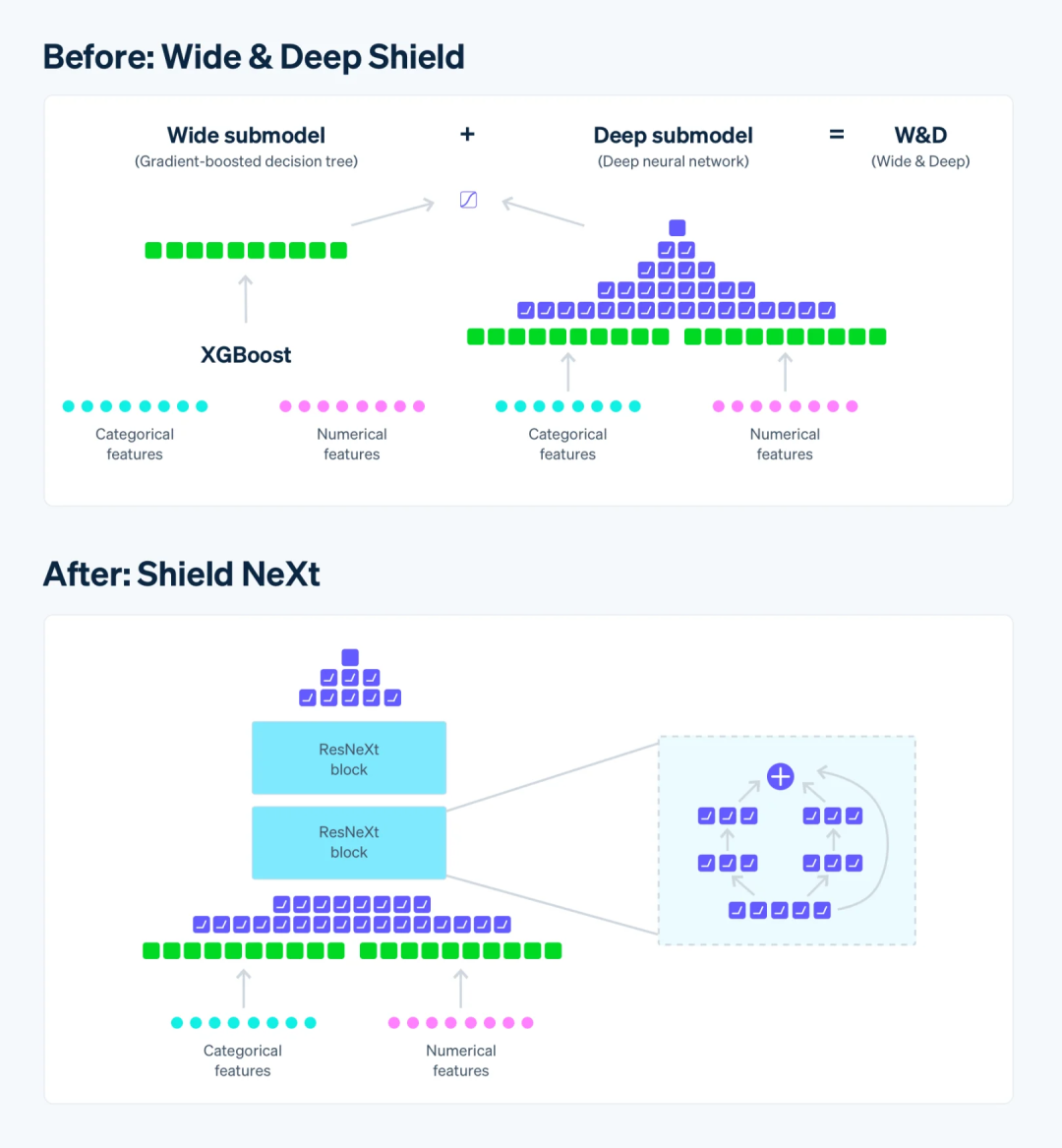
Stripe Radar原先的架构结合了XGBoost的记忆能力和深度神经网络(DNN)的泛化能力,虽然有效,但在扩展性上存在局限。XGBoost在大规模应用中与Stripe希望采用的更先进的机器学习技术(如迁移学习、嵌入和长时间训练)不兼容,并且由于其并行化程度不高,限制了模型的再训练速度和工程师们的实验速度。
尽管移除XGBoost组件可以简化架构,但这将导致召回率下降1.5%,这是不可接受的性能退步。为了在不牺牲DNN泛化能力的同时增加其记忆能力,Stripe探索了增加DNN的大小——深度和宽度,但同时也要避免过拟合的风险。
Stripe通过研究DNN架构的流行出版物,最终采用了受ResNeXt启发的多分支DNN架构。这种架构采用“Network-in-Neuron”策略,将计算分割成不同的线程或分支,每个分支可以视为一个小网络,最终将分支的输出汇总以产生最终输出,从而在不单纯增加深度或宽度的情况下提高准确性。
通过去除XGBoost组件,Stripe将模型的训练时间减少了85%以上,使得原本需要通宵运行的实验现在在一天之内可以多次完成,极大地提高了原型设计的能力。
Lesson 2: 永远不要停止寻找新的机器学习特征
Stripe Radar通过不断寻找和实现新的机器学习特征来提高模型性能。Stripe团队通过详细分析欺诈行为,识别出可能对模型性能有重大影响的特征,并快速实施和测试这些特征。
Stripe Radar通过细致分析欺诈尝试的共同行为,积累了对欺诈活动和趋势的深入理解。这种理解为Radar提供了一个重要优势:训练数据集规模的每次增加都能显著提高模型质量,这在XGBoost情况下并不明显。
Each increase in the size of Radar’s training data set creates outsized improvements in model quality, which wasn’t the case with XGBoost.
特征工程作为提升模型的关键,Stripe通过创建多个流程来赋能机器学习工程师,以识别和实施可能对模型性能产生重大影响的特征。通过详细回顾过去的欺诈攻击,构建调查报告,寻找支付中的信号,比如欺诈者可能用于快速设置多个账户的一次性电子邮件模式。
Stripe探索了通过增加训练数据量来提升模型性能的方法。尽管训练时间随训练数据量线性增加,但由于切换到DNN架构后训练速度的提升,这不再是问题。实验结果显示,即使训练数据量增加了10倍,模型性能仍有显著提升,Stripe正在探索100倍的数据量扩展。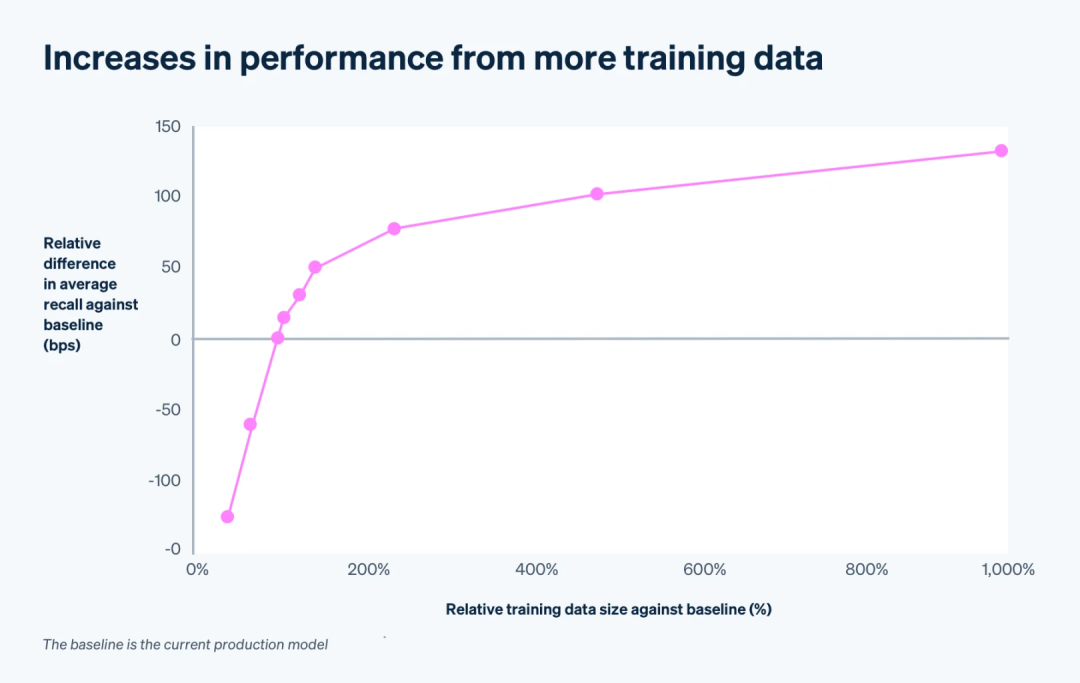
Lesson 3: 解释的重要性不亚于检测
除了检测欺诈,Stripe Radar还重视向用户解释欺诈决策的原因。尽管机器学习模型通常难以解释,Stripe的工程师们已经开发了多种方法来提高透明度。这是一个挑战。所有的机器学习模型在某种程度上都是黑箱,深度神经网络比其他类型的模型更是如此。向用户解释为什么Radar会以这种方式对交易进行评分是困难的。这是我们在决定使用DNN而不是更简单、更传统的机器学习技术时不得不接受的另一个权衡。但我们的工程师对系统非常了解,并已经开发了一系列方法来帮助用户理解发生了什么。
2020年推出的风险洞察功能允许用户了解哪些交易特征导致了交易被拒绝,并通过地图和Elasticsearch等工具提供更多上下文信息,帮助用户更好地理解交易评分背后的逻辑。这些改进展示了Stripe在提高模型可解释性方面的持续努力和投资。
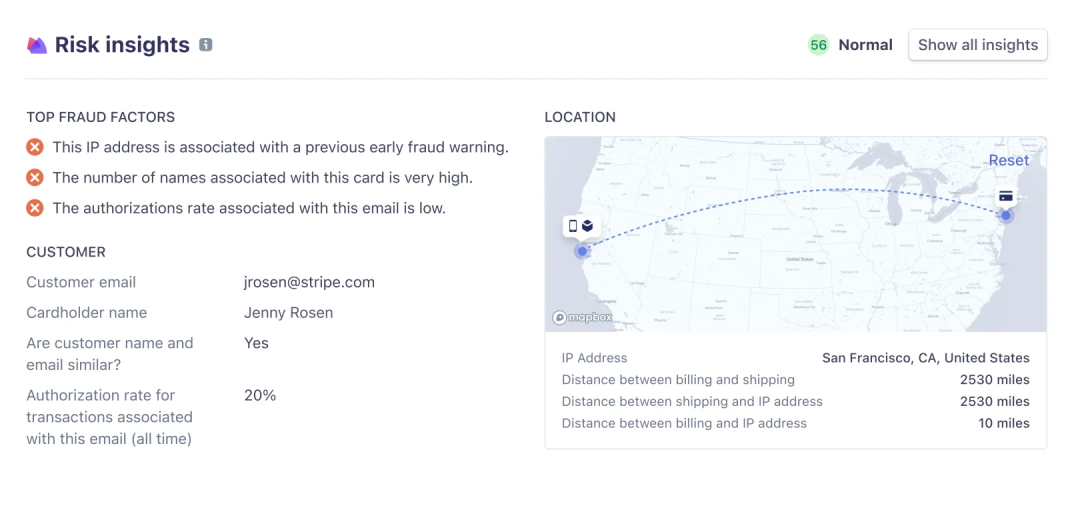
比如,可能包括持卡人姓名是否与提供的电子邮件匹配,以及之前与IP地址关联的卡的数量。卡片数量多可能表明可疑行为,例如一个不良行为者尝试使用多个被盗信用卡。然而,这也可能存在合理的理由,我们的模型会在所有信号的背景下评估这个特征,理解它们之间可能存在的相关性,以准确区分欺诈和正当支付。
Summary
Radar与我们最初开始时的产品已经大不相同。我们已经彻底改革了我们使用的模型,我们利用Stripe网络中的交易数据的方式,以及我们与用户的互动方式。在同一时期,欺诈模式也发生了显著变化,从主要是盗用信用卡欺诈到今天传统银行卡欺诈和高速卡片测试攻击的日益混合。




![[图解]建模相关的基础知识-17](https://img-blog.csdnimg.cn/direct/1c9adc33ce66458b9697a71419eff3e6.png)