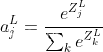前言
系列专栏:【深度学习:算法项目实战】✨︎
涉及医疗健康、财经金融、商业零售、食品饮料、运动健身、交通运输、环境科学、社交媒体以及文本和图像处理等诸多领域,讨论了各种复杂的深度神经网络思想,如卷积神经网络、循环神经网络、生成对抗网络、门控循环单元、长短期记忆、自然语言处理、深度强化学习、大型语言模型和迁移学习。
近来,机器学习得到了长足的发展,并引起了广泛的关注,其中语音和图像识别领域的成果最为显著。本研究论文分析了深度学习方法–长短期记忆神经网络(LSTM)–在A股市中的表现。论文显示,虽然这种技术在语音识别等其他领域取得了不错的成绩,但在应用于金融数据时却表现不佳。事实上,金融数据的特点是噪声信号比高,这使得机器学习模型难以找到模式并预测未来价格。
本文不对LSTM模型过多介绍,只探讨Stacked LSTM在A股中的表现,以及模型调参与性能优化。本研究文章的结构如下。第一节介绍金融时间序列数据。第二部分介绍金融时间数据的特征过程。第三部分是构建模型、定义参数空间、损失函数与优化器。第四部分是模型评估与结果可视化。第五部分是预测下一个时间点的收盘价。
目录
- 1. 金融时间序列数据
- 1.1 获取股票每日价格数据
- 1.2 观察股票收盘价格趋势
- 2. 时间数据特征工程
- 2.1 构造序列数据
- 2.2 特征缩放(归一化)
- 2.3 数据集划分(TimeSeriesSplit)
- 3. 时间序列模型构建(Stacked LSTM)
- 3.1 构建模型
- 3.2 定义参数空间
- 3.3 验证损失与调参循环
- 3.4 最佳模型输出与保存
- 4. 模型评估与可视化
- 4.1 均方误差
- 4.2 反归一化
- 4.3 结果验证(可视化)
- 5. 模型预测
- 5.1 预测下一个时间点的收盘价
1. 金融时间序列数据
金融时间序列数据是指按照时间顺序记录的各种金融指标的数值序列,这些指标包括但不限于股票价格、汇率、利率等。这些数据具有以下几个显著特点:
- 时间连续性:数据按照时间的先后顺序排列,反映了金融市场的动态变化过程。
- 噪声和不确定性:金融市场受到多种复杂因素的影响,因此数据中存在大量噪声和不确定性。
- 非线性和非平稳性:金融时间序列数据通常呈现出明显的非线性和非平稳性特征。
import numpy as np
import pandas as pd
from pytdx.hq import TdxHq_API
import plotly.graph_objects as go
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import TimeSeriesSplit
from sklearn.model_selection import ParameterSampler
from keras.models import Sequential
from keras.layers import Input, Dense, LSTM, Dropout
from keras.metrics import RootMeanSquaredError
from keras.optimizers import Adam
1.1 获取股票每日价格数据
首先,让我们使用 TdxHq_API() 函数获取股票价格
api = TdxHq_API()
with api.connect('119.147.212.81', 7709):
df = api.to_df(api.get_security_bars(9, 1, '600584', 0, 800))
print(df)
open close high low vol amount year month day \
0 41.01 39.60 41.29 39.60 432930.0 1.735115e+09 2021 2 25
1 38.63 39.56 39.56 38.51 398273.0 1.553533e+09 2021 2 26
2 39.71 40.47 40.59 39.15 382590.0 1.530225e+09 2021 3 1
3 41.17 40.30 41.26 39.90 334984.0 1.358569e+09 2021 3 2
4 40.20 40.80 40.92 39.38 325774.0 1.306173e+09 2021 3 3
.. ... ... ... ... ... ... ... ... ...
795 29.15 29.05 29.29 28.68 489791.0 1.418345e+09 2024 6 14
796 29.05 31.28 31.90 28.75 980331.0 2.989219e+09 2024 6 17
797 31.20 31.40 31.41 30.81 580956.0 1.811908e+09 2024 6 18
798 31.30 31.75 32.02 31.05 739795.0 2.341768e+09 2024 6 19
799 31.30 31.08 31.88 30.93 530154.0 1.660881e+09 2024 6 20
hour minute datetime
0 15 0 2021-02-25 15:00
1 15 0 2021-02-26 15:00
2 15 0 2021-03-01 15:00
3 15 0 2021-03-02 15:00
4 15 0 2021-03-03 15:00
.. ... ... ...
795 15 0 2024-06-14 15:00
796 15 0 2024-06-17 15:00
797 15 0 2024-06-18 15:00
798 15 0 2024-06-19 15:00
799 15 0 2024-06-20 15:00
[800 rows x 12 columns]
1.2 观察股票收盘价格趋势
接下来,使用 go.Scatter() 函数绘制股票价格趋势
fig = go.Figure([go.Scatter(x=df['datetime'], y=df['close'])])
fig.update_layout(
title={'text': 'Close Price History', 'font_size': 24, 'font_family': 'Comic Sans MS', 'font_color': '#454545'},
xaxis_title={'text': '', 'font_size': 18, 'font_family': 'Courier New', 'font_color': '#454545'},
yaxis_title={'text': 'Close Price CNY', 'font_size': 18, 'font_family': 'Lucida Console', 'font_color': '#454545'},
xaxis_tickfont=dict(color='#663300'), yaxis_tickfont=dict(color='#663300'), width=900, height=500,
plot_bgcolor='#F2F2F2', paper_bgcolor='#F2F2F2',
)
fig.show()

2. 时间数据特征工程
# 设置时间窗口大小
window_size = 180
2.1 构造序列数据
若在收盘之前运行,则最后一个测试price不准确,range中长度最好再减1
# 构造序列数据
def create_dataset(dataset, look_back=1):
X, Y = [], []
for i in range(len(dataset)-look_back):
a = dataset[i:(i+look_back), 0]
X.append(a)
Y.append(dataset[i + look_back, 0])
return np.array(X), np.array(Y)
2.2 特征缩放(归一化)
MinMaxScaler() 函数主要用于将特征数据按比例缩放到指定的范围。默认情况下,它将数据缩放到[0, 1]区间内,但也可以通过参数设置将数据缩放到其他范围。在机器学习中,MinMaxScaler()函数常用于不同尺度特征数据的标准化,以提高模型的泛化能力
# 归一化数据
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_data = scaler.fit_transform(df['close'].values.reshape(-1, 1))
# 创建数据集
X, y = create_dataset(scaled_data, look_back=window_size)
# 重塑输入数据为[samples, time steps, features]
X = np.reshape(X, (X.shape[0], X.shape[1], 1))
2.3 数据集划分(TimeSeriesSplit)
TimeSeriesSplit() 函数与传统的交叉验证方法不同,TimeSeriesSplit 特别适用于需要考虑时间顺序的数据集,因为它确保测试集中的所有数据点都在训练集数据点之后,并且可以分割多个训练集和测试集。
# 使用TimeSeriesSplit划分数据集,根据需要调整n_splits
tscv = TimeSeriesSplit(n_splits=3, test_size=30)
# 遍历所有划分进行交叉验证
for i, (train_index, test_index) in enumerate(tscv.split(X)):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# print(f"Fold {i}:")
# print(f" Train: index={train_index}")
# print(f" Test: index={test_index}")
这里我们使用最后一个 fold
X_train.shape, X_test.shape, y_train.shape, y_test.shape
((590, 180, 1), (30, 180, 1), (590,), (30,))
3. 时间序列模型构建(Stacked LSTM)
Stacked LSTM,即堆叠长短期记忆网络,是一种深度学习的模型架构,由多个LSTM层堆叠而成。这种架构使得模型能够学习并提取输入序列数据的不同级别的特征,从而提高预测的准确性。
3.1 构建模型
# 定义模型构建函数
def LSTMRegressor(lstm_units, dropout_rate, learning_rate):
model = Sequential()
model.add(Input(shape=(X_train.shape[1], X_train.shape[2])))
model.add(LSTM(lstm_units, return_sequences=True))
model.add(Dropout(dropout_rate))
model.add(LSTM(lstm_units, return_sequences=True))
model.add(Dropout(dropout_rate))
model.add(LSTM(lstm_units))
model.add(Dropout(dropout_rate))
model.add(Dense(60))
model.add(Dropout(dropout_rate))
model.add(Dense(1)) # 线性回归层
opt = Adam(learning_rate=learning_rate)
model.compile(optimizer=opt, loss='mean_squared_error')
return model
3.2 定义参数空间
使用 ParameterSampler 可以为随机搜索定义参数的分布,却不像网格搜索那样指定所有可能的参数组合。
# 定义参数空间
param_grid = {
'lstm_units': [32, 64, 128],
'dropout_rate': [0.2, 0.3, 0.4],
'learning_rate': [0.001, 0.0001]
}
# 使用ParameterSampler生成参数组合
param_list = list(
ParameterSampler(
param_grid,
n_iter=len(
param_grid['lstm_units']
) *
len(
param_grid['dropout_rate']
) *
len(
param_grid['learning_rate']
),
random_state=42
)
)
3.3 验证损失与调参循环
# 初始化最佳验证损失和最佳模型
best_val_loss = float('inf')
best_model = None
# 调参循环
for params in param_list:
print(f"Trying parameters: {params}")
model = LSTMRegressor(**params)
# 训练模型(这里仅使用一部分epoch作为示例)
history = model.fit(X_train, y_train, epochs=10, batch_size=32, validation_data=(X_test, y_test), verbose=0)
# 计算验证集上的损失
val_loss = history.history['val_loss'][-1]
# 如果当前模型的验证损失比之前的好,则更新最佳模型和最佳验证损失
if val_loss < best_val_loss:
best_val_loss = val_loss
best_model = model
print(f"Found better model with validation loss: {best_val_loss}")
# 输出最佳模型的参数
print(f"Best model parameters: {param_list[param_list.index(params)]}")
Trying parameters: {'lstm_units': 32, 'learning_rate': 0.001, 'dropout_rate': 0.2}
Found better model with validation loss: 0.007122963201254606
Trying parameters: {'lstm_units': 64, 'learning_rate': 0.001, 'dropout_rate': 0.2}
Found better model with validation loss: 0.006877976469695568
Trying parameters: {'lstm_units': 128, 'learning_rate': 0.001, 'dropout_rate': 0.2}
Found better model with validation loss: 0.003105488372966647
Trying parameters: {'lstm_units': 32, 'learning_rate': 0.0001, 'dropout_rate': 0.2}
Trying parameters: {'lstm_units': 64, 'learning_rate': 0.0001, 'dropout_rate': 0.2}
Trying parameters: {'lstm_units': 128, 'learning_rate': 0.0001, 'dropout_rate': 0.2}
Trying parameters: {'lstm_units': 32, 'learning_rate': 0.001, 'dropout_rate': 0.3}
Trying parameters: {'lstm_units': 64, 'learning_rate': 0.001, 'dropout_rate': 0.3}
Trying parameters: {'lstm_units': 128, 'learning_rate': 0.001, 'dropout_rate': 0.3}
Trying parameters: {'lstm_units': 32, 'learning_rate': 0.0001, 'dropout_rate': 0.3}
Trying parameters: {'lstm_units': 64, 'learning_rate': 0.0001, 'dropout_rate': 0.3}
Trying parameters: {'lstm_units': 128, 'learning_rate': 0.0001, 'dropout_rate': 0.3}
Trying parameters: {'lstm_units': 32, 'learning_rate': 0.001, 'dropout_rate': 0.4}
Trying parameters: {'lstm_units': 64, 'learning_rate': 0.001, 'dropout_rate': 0.4}
Trying parameters: {'lstm_units': 128, 'learning_rate': 0.001, 'dropout_rate': 0.4}
Trying parameters: {'lstm_units': 32, 'learning_rate': 0.0001, 'dropout_rate': 0.4}
Trying parameters: {'lstm_units': 64, 'learning_rate': 0.0001, 'dropout_rate': 0.4}
Trying parameters: {'lstm_units': 128, 'learning_rate': 0.0001, 'dropout_rate': 0.4}
Best model parameters: {'lstm_units': 128, 'learning_rate': 0.0001, 'dropout_rate': 0.4}
3.4 最佳模型输出与保存
best_model.summary()
Model: "sequential_2"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━┩
│ lstm_6 (LSTM) │ (None, 180, 128) │ 66,560 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dropout_8 (Dropout) │ (None, 180, 128) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ lstm_7 (LSTM) │ (None, 180, 128) │ 131,584 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dropout_9 (Dropout) │ (None, 180, 128) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ lstm_8 (LSTM) │ (None, 128) │ 131,584 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dropout_10 (Dropout) │ (None, 128) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_4 (Dense) │ (None, 60) │ 7,740 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dropout_11 (Dropout) │ (None, 60) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_5 (Dense) │ (None, 1) │ 61 │
└──────────────────────────────────────┴─────────────────────────────┴─────────────────┘
Total params: 1,012,589 (3.86 MB)
Trainable params: 337,529 (1.29 MB)
Non-trainable params: 0 (0.00 B)
Optimizer params: 675,060 (2.58 MB)
使用 .save() 函数保存最佳模型
# 保存最佳模型
# best_model.save('best_model.h5')
4. 模型评估与可视化
4.1 均方误差
使用均方误差 mean_squared_error() 评估模型性能
from sklearn.metrics import mean_squared_error
# 使用最佳模型进行预测
trainPredict = best_model.predict(X_train)
testPredict = best_model.predict(X_test)
mse = mean_squared_error(y_test, testPredict)
print(f"Test MSE: {mse}")
19/19 ━━━━━━━━━━━━━━━━━━━━ 2s 105ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 94ms/step
Test MSE: 0.0031054877469655923
4.2 反归一化
# 反归一化预测结果
trainPredict = scaler.inverse_transform(trainPredict)
y_train = scaler.inverse_transform([y_train])
testPredict = scaler.inverse_transform(testPredict)
y_test = scaler.inverse_transform([y_test])
4.3 结果验证(可视化)
# 计算绘图数据
train = df[:X_train.shape[0]+X_train.shape[1]]
valid = df[X_train.shape[0]+X_train.shape[1]:]
valid = valid.assign(predictions=testPredict)
# 可视化数据
fig = go.Figure([go.Scatter(x=train['datetime'], y=train['close'],name='Train')])
fig.add_trace(go.Scatter(x=valid['datetime'],y=valid['close'],name='Test'))
fig.add_trace(go.Scatter(x=valid['datetime'],y=valid['predictions'], name='Prediction'))
fig.update_layout(
title={'text': 'Close Price Validation', 'font_size': 24, 'font_family': 'Comic Sans MS', 'font_color': '#454545'},
xaxis_title={'text': '', 'font_size': 18, 'font_family': 'Courier New', 'font_color': '#454545'},
yaxis_title={'text': 'Close Price CNY', 'font_size': 18, 'font_family': 'Lucida Console', 'font_color': '#454545'},
xaxis_tickfont=dict(color='#663300'), yaxis_tickfont=dict(color='#663300'), width=900, height=500,
plot_bgcolor='#F2F2F2', paper_bgcolor='#F2F2F2',
)
fig.show()

从上图我们可以观察到预测价格存在滞后性,关于如何缓解滞后性请参考连接。1
5. 模型预测
5.1 预测下一个时间点的收盘价
# 使用模型预测下一个时间点的收盘价
# 假设latest_closes是一个包含最新window_size个收盘价的列表或数组
latest_closes = df['close'][-window_size:].values
latest_closes = latest_closes.reshape(-1, 1)
scaled_latest_closes = scaler.fit_transform(latest_closes)
latest_closes_reshape = scaled_latest_closes.reshape(1, window_size, 1)
next_close_pred = best_model.predict(latest_closes_reshape)
next_close_pred = scaler.inverse_transform(next_close_pred)
next_close_pred
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 31ms/step
array([[30.284128]], dtype=float32)
本文仅用于深度学习科学实验和教育目的,并非投资建议
LSTM从理论基础到代码实战 5 关于lstm预测滞后性的讨论 ↩︎