对于Fine-tuning是深度学习和机器学习领域一个特别重要的概念,并且每个企业的实践方式也会有所不同,今天我们就来聊一聊Fine-tuning。
什么是Fine-tuning
Fine-tuning指的是模型微调,通常是指在一个预训练模型的基础上,通过在特定任务的数据集上来进一步的训练调整模型参数,以提高模型在特定任务上的性能。这种方法特别适用于数据量不足以从头开始训练大型模型的情况,可以大大减少模型的训练时间和计算资源。
OpenAI GPT-3.5模型的强化学习微调过程
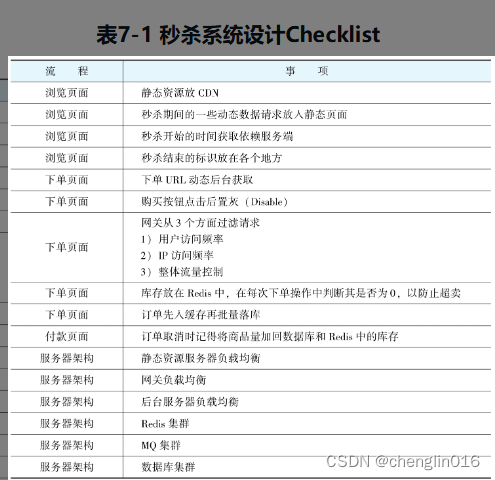
我们先来看看OpenAI是如何进行大模型微调的,参照下图所示:

图片
它这里分为了3个步骤:
步骤1、收集示范数据并训练监督策略
1.1、数据采集:从prompt数据集中选择一个prompt,例如“向六岁小孩解释什么是强化学习”。
1.2、标注答案:标注者会根据这个prompt给出一个理想的输出,好比给小孩解释“会使用奖励和惩罚来学习”。
1.3、监督学习:将上面收集到的数据用于对GPT-3.5模型进行微调,这一过程使用的是监督学习(Supervised Fine-Tuning, SFT),即模型学习模仿标注者给出的回答。
简单总结一下,这个步骤,主要就是采集数据的过程,针对每条要训练的数据,整理出一问一答,进行模型微调。
步骤1完成后,模型已经经过了一轮训练,但这是一个监督学习训练,其中模型被训练来模仿标注者给出的示例回答。在这个阶段,模型尝试学习如何根据输入的prompt生成正确和合理的输出。这可以被视作是微调过程中的第一步,因为它使用了预标注的数据来教导模型预期的输出格式和内容。
然而,这个训练后的模型通常还不是最终的产品。虽然它可能已经能够生成质量不错的输出,但这些输出可能还没有完全达到部署标准或者还不够适应复杂的现实世界任务。这就是为什么需要后面的步骤来优化和精细调整模型的表现。
步骤2、收集比较数据并训练奖励模型
2.1、采集比较数据:我们对大模型进行提问,对于同一个prompt,模型可能会给出多个不同的输出。
2.2、对输出进行排名:标注者会检查所有的输出,并根据输出质量从好到坏进行排名。(例如,D > C > A > B)。
2.3、训练奖励模型(RM):这个排名信息被用来训练一个奖励模型(Reward Model, RM),该模型学会如何根据标注者的偏好对输出进行评分,用于评价不同的输出并决定哪个是最好的。
总结一下,第二步主要是将第一步训练好的模型生成的输出结果被用来训练一个奖励模型,该奖励模型能够评估和区分不同输出的质量。
步骤3、使用PPO强化学习算法对策略进行优化
3.1、采样新的prompt:从数据集中选择一个新的prompt,比如“写一个关于水獭的故事”。
3.2、初始化PPO模型:使用之前的监督策略,初始化PPO(Proximal Policy Optimization)模型。
3.3、生成输出:PPO策略产生一个输出,例如开始输出回答“关于水獭的故事”。
3.4、奖励模型计算奖励:奖励模型评估这个输出,并给出一个奖励分数。
3.5、PPO优化:根据奖励模型的评分,使用PPO算法更新策略,以生成更好的输出。
总结一下,这三步主要做的事是使用PPO算法通过强化学习来优化一个基于奖励模型的策略,以此提升模型生成输出的质量。这一步骤的核心目标是通过反复迭代来细化模型的行为,使其能够生成更符合人类评价标准的文本。相当于整体又做了一轮强化学习。而所谓的模型微调,本质上就是把每个参数再动一动,一般第二大步骤和第三大步骤会循环几轮。
将上面三步整体总结:
1、用步骤一先训练一个有回答能力的基础模型。然后再基于步骤一的输出结果,训练一个奖励模型,也就是步骤二做的事。
2、对于当前基础模型给定的一个输出,奖励模型会进行评估,分配一个奖励值。PPO算法使用奖励模型提供的奖励值来更新基础模型的策略。如果生成的文本得到了高奖励,那么基础模型在未来会更倾向于产生类似的输出。如果奖励低,模型的策略会调整,以减少类似输出的生成。
3、这个生成-评估-更新的过程是迭代进行的(这个迭代过程也有专业说法,叫RLHF(Reinforcement Learning fromHuman Feedback),人类反馈强化学习)。在每一轮迭代中,模型都会尝试生成更好的文本以获得更高的奖励。随着迭代次数的增加,基础模型在奖励模型的指导下逐渐学习如何改善其输出。这导致生成的文本质量逐步提升,更加符合人类的偏好。
--------------
关于这一部分,有一个非常好的实践大家可以参考学习下,去年火遍全球,叫做Alpaca(羊驼),它就是套用GPT的输出数据作为训练数据,在LLaMA 7b模型上进行fine-tuning,仅用52k数据,训练出效果约等于GPT3.5。并且成本很低,一共不到600美元,其中使用OpenAI生成数据用了500美元,在8个80G A100显卡上训练了3个小时,100美元。包括去年的字节跳动也是也是那么干的,套用GPT数据用于训练自家的大模型,但是被OpenAI发现了把字节跳动账号给封了一阵。还有就是谷歌在Gemini-Pro在中文的训练数据上使用了百度文心一言,都是一样的道理,套用别的模型输出数据来训练自己的模型。
现在模型微调更方便了,比如现在大家可以考虑用Hugging Face训练框架对LLaMA模型进行微调。
--------------
Fine-tuning在垂直领域的最佳实践方式
1、根据你的业务数据,找几个人,花1~2个月,准备一问一答的高质量prompt数据集,比较小的业务规模可以准备几千条甚至上百条即可,因为OpenAI GPT-3.5第一步SFT阶段才准备了13k的prompt数据,第二步RM阶段,准备了33k条,第三步PPO阶段是31k条。
2、选取一个开源的模型,比如国内的ChatGLM或Meta的LLaMA,借助于Hugging Face进行Fine-tuning训练和本地私有化部署,完成第一轮的Fine-tuning。(这里我个人不推荐用一些公有云平台上的Fine-tuning的接口来训练自己的专属模型,虽然方便,但是会存在数据安全隐私问题,即使它一定会声称你的数据不会用于其他地方使用)
3、需要找几个人花时间,针对第一轮Fine-tuning好的基础模型,对输出结果进行标记排序,反复上面第二步和第三步的过程。最后经过几轮训练,参数就会越来约稳定,输出结果就会越来越靠谱。


![[问题记录]Qt QGraphicsItem 移动时出现残影](https://img-blog.csdnimg.cn/direct/ec04162f14e34ac48f9dd191f6293d20.png)