以前有过类似的文章,今天升级版分享重磅内容,Elastaticsearch与SpringBoot集成的互联网的实战。
一、需求分析:
起因是这样的,产品有这样一个需求:数据中的标题、内容、关键词等实现结构化搜索和半结构化搜索、数据时空检索、查询理解、意图识别、全拼音查询、拼音首字母查询、热点查询记录及推荐前N位关键字。如图显示:
1、拼音模糊查询:
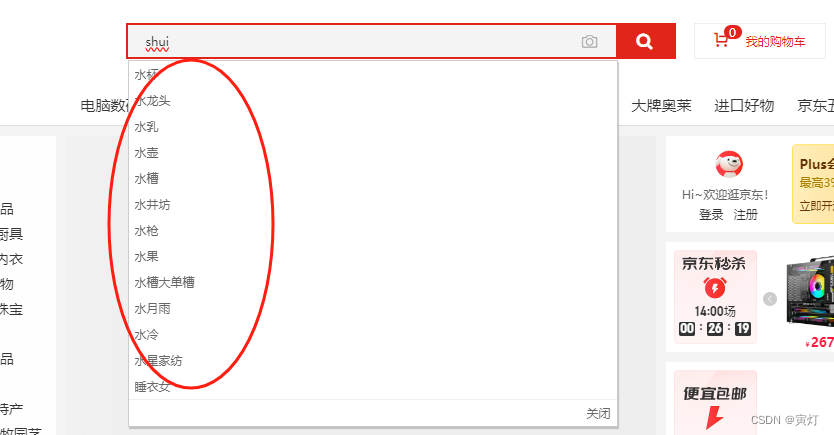
或者
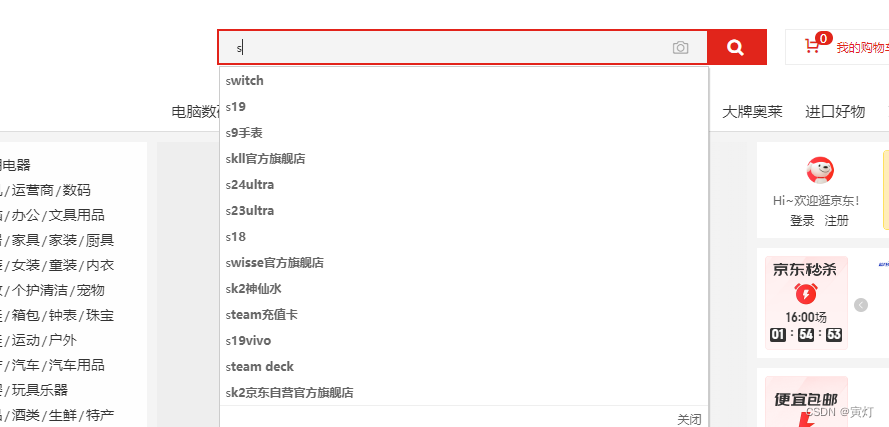
先根据拼音或者首字母模糊匹配查询前10名的关键字推荐查询,在选择关键字去查询想要的数据。
2、 查询理解
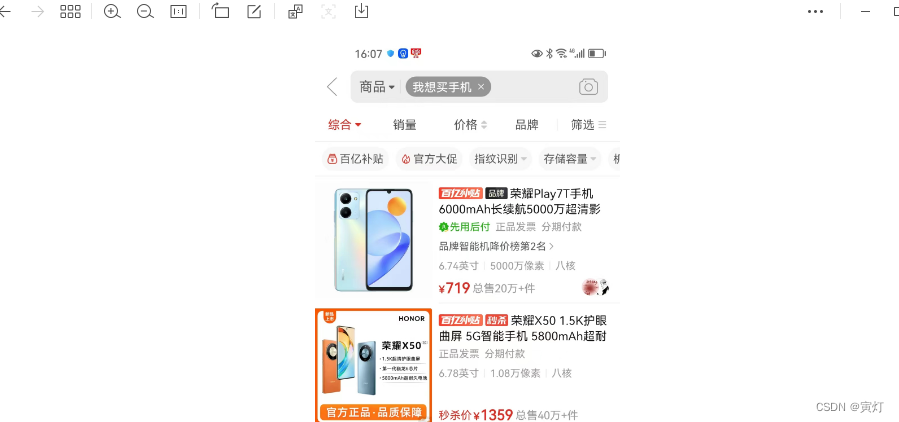
查询理解(Query Understanding)功能是指通过自然语言处理技术理解用户输入的查询意图,并将其转化为有效的搜索请求。在 Elasticsearch 中,我们可以通过结合自然语言处理(NLP)库和 Elasticsearch 的搜索能力来实现查询理解搜索功能。
3、意图识别
实现意图识别搜索功能通常需要结合自然语言处理(NLP)技术和 Elasticsearch 的搜索能力。在本示例中,我们将使用开源的自然语言处理工具 OpenNLP 来识别用户查询的意图,并基于识别结果执行相应的 Elasticsearch 搜索请求。此需求点需要进行模型训练。
4、数据时空检索
输入时间和经纬度信息查询数据:在处理和检索半结构化时空数据时,Elasticsearch 提供了地理空间(geo-spatial)和时间(temporal)相关的数据类型和查询能力。以下是通过 Java 语言实现半结构化时空数据检索的示例代码。
5、其他查询记录
还有简单的模糊查询、记录查询关键字等信息
二、技术选型
根据需求我们进行进行选型,首先ES版本需要支持NLP自然语言处理,有相应版本的ES分词插件、中文分词插件、拼音分词插件;结合JDK版本。刚开始准备用7.17.22版本,后来发现没有7.17.22版本的分词插件,最新的免费使用的是7.17.18版本,于是确定用此版本。
1、下载安装ES和Kibana
参考往期文章
把版本换成7.17.18就行。
2、下载安装中文分词插件
一定要下载相应版本的插件,否则启动报错,下载地址:参考
在elasticsearch安装目录的plugins文件夹下创建文件夹ik,复制压缩包内的文件到ik文件夹。
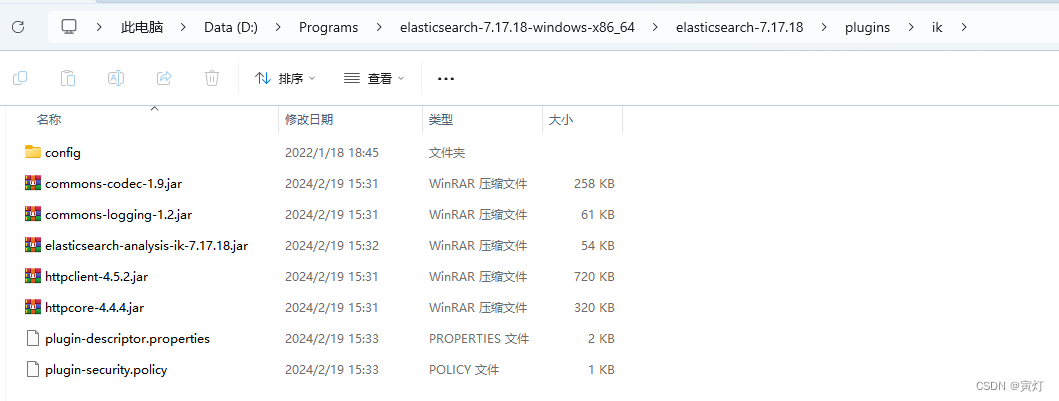
安装后重启es生效。
3、下载安装拼音分词插件
下载地址:参考;
或者所有版本
将解压后的内容手动复制到Elasticsearch的plugins目录elasticsearch-analysis-pinyin中
如图:
4、下载安装多语言分词插件
analysis-icu-7.17.18 版本
指定下载
将解压后的插件目录移动到Elasticsearch的plugins目录analysis-icu中
5、查询安装是否成功
1)ES服务器查询
es的bin目录下cmd,输入elasticsearch-plugin list可查看安装的插件
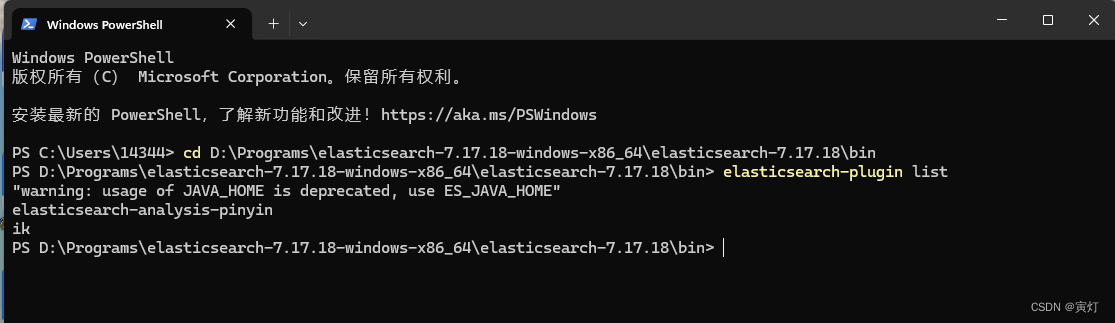
注意:必须将 Elasticsearch 安装目录的 bin 文件夹添加到系统的 PATH 环境变量中
2)Kibana客户端查询
GET /_cat/plugins?v3)浏览器
http://localhost:9200/_cat/plugins?v
4)服务器上通过API
curl -X GET "localhost:9200/_cat/plugins?v"
三、SpringBoot 集成ES
1、基础配置
参考往期文章
仅仅多了NLP包:
<!-- Apache OpenNLP -->
<dependency>
<groupId>org.apache.opennlp</groupId>
<artifactId>opennlp-tools</artifactId>
<version>1.9.3</version>
</dependency>2、理解查询需求
public boolean queryComprehendData(String userQuery ) throws IOException {
// 用户输入的查询
userQuery = "Find latest iPhone and Samsung phones";
// 使用 OpenNLP 进行简单的查询理解
SimpleTokenizer tokenizer = SimpleTokenizer.INSTANCE;
Span[] tokenSpans = tokenizer.tokenizePos(userQuery);
String[] tokens = Span.spansToStrings(tokenSpans, userQuery);
// 打印分词结果
for (String token : tokens) {
System.out.println(token);
}
// 构建 Elasticsearch 查询
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
for (String token : tokens) {
MatchQueryBuilder matchQuery = QueryBuilders.matchQuery("description", token);
boolQuery.should(matchQuery);
}
// 创建搜索请求
SearchRequest searchRequest = new SearchRequest("products");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(boolQuery);
searchRequest.source(searchSourceBuilder);
// 执行搜索
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(searchResponse);
return true;
}这里我们是结合自然语言处理(NLP)库和 Elasticsearch 的搜索能力来实现查询理解搜索功能。
1)kibana创建索引和添加数据
PUT /products
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"description": {
"type": "text"
},
"price": {
"type": "double"
},
"category": {
"type": "keyword"
}
}
}
}
POST /products/_doc/1
{
"name": "Apple iPhone 13",
"description": "Latest model of Apple iPhone with A15 Bionic chip.",
"price": 999.99,
"category": "Electronics"
}
POST /products/_doc/2
{
"name": "Samsung Galaxy S21",
"description": "Latest model of Samsung Galaxy with Exynos 2100 chip.",
"price": 799.99,
"category": "Electronics"
}
POST /products/_doc/3
{
"name": "Sony WH-1000XM4",
"description": "Noise cancelling wireless headphones from Sony.",
"price": 349.99,
"category": "Electronics"
}
3、意图识别需求
// 简单的意图识别方法(示例)
private static String recognizeIntent(String[] tokens) {
for (String token : tokens) {
if (token.equalsIgnoreCase("find")) {
return "findProducts";
} else if (token.equalsIgnoreCase("under") || token.equalsIgnoreCase("below")) {
return "findCheaperProducts";
}
}
return "unknownIntent";
}
public boolean queryIntentRecognitionData(String indexName) throws IOException {
// 用户输入的查询
String userQuery = "Find latest smartphones under 1000 dollars";
// 使用 OpenNLP 进行句子检测和分词,训练的插件
InputStream modelIn = new FileInputStream("en-sent.bin");
SentenceModel model = new SentenceModel(modelIn);
SentenceDetectorME sentenceDetector = new SentenceDetectorME(model);
String[] sentences = sentenceDetector.sentDetect(userQuery);
// 获取第一个句子进行意图识别
String querySentence = sentences[0];
SimpleTokenizer tokenizer = SimpleTokenizer.INSTANCE;
Span[] tokenSpans = tokenizer.tokenizePos(querySentence);
String[] tokens = Span.spansToStrings(tokenSpans, querySentence);
// 打印分词结果
System.out.println("Tokens:");
for (String token : tokens) {
System.out.println(token);
}
// 识别意图
String intent = recognizeIntent(tokens);
// 构建 Elasticsearch 查询
SearchRequest searchRequest = new SearchRequest("products");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 根据意图构建查询
switch (intent) {
case "findProducts":
// 查询包含相关关键词的产品
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
for (String token : tokens) {
MatchQueryBuilder matchQuery = QueryBuilders.matchQuery("description", token);
boolQuery.should(matchQuery);
}
searchSourceBuilder.query(boolQuery);
break;
case "findCheaperProducts":
// 查询价格低于指定值的产品
searchSourceBuilder.query(QueryBuilders.rangeQuery("price").lte(1000));
break;
default:
System.out.println("Intent not recognized.");
break;
}
// 设置搜索请求源并执行搜索
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
System.out.println("Search response:");
System.out.println(searchResponse);
return false;
}4、记录关键词查询的次数
public boolean saveKeywordAndPinYinQuery(String keyword) throws IOException {
/**
* 记录关键词查询次数
*/
// String INDEX_NAME = "my_pinyin_index";
String INDEX_NAME = "keyword_stats_3";
// 设置脚本参数
Map<String, Object> params = new HashMap<>();
params.put("increment", 1);
// 创建脚本
String scriptSource = "if (ctx._source.query_count == null) { ctx._source.query_count = params.increment } else { ctx._source.query_count += params.increment }";
Script script = new Script(ScriptType.INLINE, "painless", scriptSource, params);
// 更新请求
UpdateRequest updateRequest = new UpdateRequest(INDEX_NAME, keyword)
.script(script)
.upsert(Collections.singletonMap("query_count", 1));
// 执行更新
restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
/**
*查询某个关键词记录的次数
*/
// 创建获取请求
GetRequest getRequest = new GetRequest(INDEX_NAME, keyword);
// 执行获取请求
GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
// 检查文档是否存在并提取查询次数
if (getResponse.isExists()) {
Integer queryCount = (Integer) getResponse.getSource().get("query_count");
Integer queryCount1 = (Integer) getResponse.getSourceAsMap().get("query_count");
System.out.println(queryCount+":"+queryCount1);
// return queryCount != null ? queryCount : 0;
} else {
// return 0; // 如果文档不存在,则返回0
}
return false;
}1)设置索引和映射
PUT /keyword_stats
{
"mappings": {
"properties": {
"keyword": {
"type": "keyword"
},
"query_count": {
"type": "integer"
}
}
}
}
此索引不支持模糊查询因为"type": "keyword" 原因。
2)
3)
5、根据条件查询前几名的热点关键词
public boolean saveKeywordAndPinYinQuery(String keyword) throws IOException {
/**
*查询排名前10位的热点关键字
*/
// 创建搜索请求
SearchRequest searchRequest = new SearchRequest(INDEX_NAME);
// 构建搜索源
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.size(10); // 限制返回文档数
// searchSourceBuilder.query(QueryBuilders.matchQuery("content.pinyin","bei"));
// searchSourceBuilder.query(QueryBuilders.matchQuery("keyword","北"));
searchSourceBuilder.sort(SortBuilders.fieldSort("query_count").order(SortOrder.DESC));
// searchSourceBuilder.query(QueryBuilders.matchQuery("keyword", "北京"));//模糊搜索匹配查询ok了、还需要拼音查询,思路一样
searchSourceBuilder.query(QueryBuilders.matchQuery("keyword", "beijing"));
// searchSourceBuilder.query(QueryBuilders.matchQuery("keyword", queryKeyword));
searchRequest.source(searchSourceBuilder);
// 执行搜索请求
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 处理搜索结果
System.out.println("Top " + 10 + " hot keywords:");
for (SearchHit hit : searchResponse.getHits().getHits()) {
String keyword2 = hit.getId();
String keyword1 = (String) hit.getSourceAsMap().get("keyword");
Integer queryCount1 = (Integer) hit.getSourceAsMap().get("query_count");
// Integer queryCount = (Integer) getResponse.getSource().get("query_count");
System.out.println("Keyword: " + keyword1 +":queryCount1:"+queryCount1);
}
return false;
}1)用Kibana查询
POST /keyword_stats_3/_search
{
"size": 0,
"query": {
"match": {
"keyword": "bei"
}
},
"aggs": {
"top_keywords": {
"terms": {
"field": "keyword.raw",
"order": {
"sum_query_count": "desc"
},
"size": 10
},
"aggs": {
"sum_query_count": {
"sum": {
"field": "query_count"
}
}
}
}
}
}2)kibana创建测试数据
POST /keyword_stats_3/_doc/1
{
"keyword": "北京",
"query_count": 10
}
POST /keyword_stats_3/_doc/2
{
"keyword": "北京包邮",
"query_count": 8
}
POST /keyword_stats_3/_doc/3
{
"keyword": "美丽北京",
"query_count": 5
}
POST /keyword_stats_3/_doc/4
{
"keyword": "昌平打印",
"query_count": 12
}
POST /keyword_stats_3/_doc/5
{
"keyword": "big machine learning_big",
"query_count": 7
}
POST /keyword_stats_3/_doc/6
{
"keyword": "杯子",
"query_count": 7
}3) kibana创建索引和配置
PUT /keyword_stats_3
{
"settings": {
"analysis": {
"analyzer": {
"pinyin_analyzer": {
"tokenizer": "my_pinyin",
"filter": [
"lowercase"
]
}
},
"tokenizer": {
"my_pinyin": {
"type": "pinyin",
"first_letter": "none",
"padding_char": " "
}
}
}
},
"mappings": {
"properties": {
"keyword": {
"type": "text",
"analyzer": "pinyin_analyzer",
"search_analyzer": "pinyin_analyzer",
"fields": {
"raw": {
"type": "keyword"
}
}
},
"query_count": {
"type": "integer"
}
}
}
}keyword 字段被定义为 text 类型,并且具有一个名为 raw 的 keyword 类型子字段。
4)不支持拼音的索引和配置
PUT /keyword_stats
{
"settings": {
"analysis": {
"analyzer": {
"default": {
"type": "standard"
}
}
}
},
"mappings": {
"properties": {
"keyword": {
"type": "text",
"fields": {
"raw": {
"type": "keyword"
}
}
},
"query_count": {
"type": "integer"
}
}
}
}
或者
PUT /keyword_stats
{
"mappings": {
"properties": {
"keyword": {
"type": "text",
"fields": {
"raw": {
"type": "keyword"
}
}
},
"query_count": {
"type": "integer"
}
}
}
}
kibana增加查询次数
POST /keyword_stats/_update_by_query
{
"script": {
"source": "ctx._source.query_count += params.count",
"lang": "painless",
"params": {
"count": 1
}
},
"query": {
"term": {
"keyword.raw": "java"
}
}
}
对应的查询:
POST /keyword_stats/_search
{
"size": 0,
"query": {
"match": {
"keyword": "your_search_keyword"
}
},
"aggs": {
"top_keywords": {
"terms": {
"field": "keyword.raw", // 使用 keyword 字段的 keyword 类型子字段
"order": {
"sum_query_count": "desc"
},
"size": 10
},
"aggs": {
"sum_query_count": {
"sum": {
"field": "query_count"
}
}
}
}
}
}
6、空间数据查询
public boolean queryGeoDoc(String indexName) throws IOException {
// 创建搜索请求
SearchRequest searchRequest = new SearchRequest("spatial_data");
// 构建查询
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
// 时间范围查询
RangeQueryBuilder rangeQuery = QueryBuilders.rangeQuery("timestamp")
.from("2023-03-15T00:00:00Z")
.to("2023-03-16T23:59:59Z");
boolQuery.must(rangeQuery);
// 地理空间查询
GeoBoundingBoxQueryBuilder geoQuery = QueryBuilders.geoBoundingBoxQuery("location")
.setCorners(40.9176, -73.7004, 40.4774, -74.2591); // 纽约市边界
boolQuery.must(geoQuery);
// 构建搜索请求源
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(boolQuery);
searchRequest.source(sourceBuilder);
// 执行搜索
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(searchResponse);
return false;
}在 Elasticsearch 中,使用 geo_point 类型来表示地理位置,使用 date 类型来表示时间。
时间范围查询:使用 RangeQueryBuilder 构建时间范围查询,查询指定时间段内的数据。
地理空间查询:使用 GeoBoundingBoxQueryBuilder 构建地理空间查询,查询位于指定地理边界内的数据。
组合查询:使用 BoolQueryBuilder 将时间范围查询和地理空间查询组合在一起。
1)kibana创建索引
PUT /spatial_data
{
"mappings": {
"properties": {
"location": {
"type": "geo_point"
},
"timestamp": {
"type": "date"
},
"data": {
"type": "text"
}
}
}
}
2)java代码插入时空数据
IndexRequest request = new IndexRequest("spatial_data");
String jsonString = "{" +
"\"location\": {\"lat\": 40.7128, \"lon\": -74.0060}," +
"\"timestamp\": \"2023-03-16T12:00:00Z\"," +
"\"data\": \"Example data\"" +
"}";
request.source(jsonString, XContentType.JSON);
client.index(request, RequestOptions.DEFAULT);7、拼音查询
public boolean queryPYDoc(String indexName) throws IOException {
// 查询文档数据
SearchRequest searchRequest = new SearchRequest("pinyin_index");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("name", indexName)); // 查询拼音首字母
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
searchResponse.getHits().forEach(hit -> System.out.println(hit.getSourceAsString()));
return false;
}要在 Elasticsearch 中实现拼音查询功能,需要借助于 Elasticsearch 的分词器和分析器来处理中文文本,并使用支持拼音转换的插件或库。在这个示例中,我们将使用 Elasticsearch 的中文分析器和 ICU Analyzer 插件来实现拼音查询功能。
1)java语言创建索引
import org.apache.http.HttpHost;
import org.elasticsearch.client.Request;
import org.elasticsearch.client.Response;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
public class PinyinIndexConfig {
public static void main(String[] args) {
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http")));
try {
// 创建索引并配置映射
Request request = new Request("PUT", "/pinyin_index");
String jsonString = "{\n" +
" \"settings\": {\n" +
" \"analysis\": {\n" +
" \"analyzer\": {\n" +
" \"pinyin_analyzer\": {\n" +
" \"type\": \"custom\",\n" +
" \"tokenizer\": \"my_pinyin\",\n" +
" \"filter\": [\n" +
" \"word_delimiter\"\n" +
" ]\n" +
" }\n" +
" },\n" +
" \"tokenizer\": {\n" +
" \"my_pinyin\": {\n" +
" \"type\": \"pinyin\",\n" +
" \"keep_first_letter\": true,\n" +
" \"keep_separate_first_letter\": false,\n" +
" \"keep_full_pinyin\": true,\n" +
" \"keep_original\": false,\n" +
" \"limit_first_letter_length\": 16,\n" +
" \"lowercase\": true,\n" +
" \"trim_whitespace\": true\n" +
" }\n" +
" }\n" +
" }\n" +
" },\n" +
" \"mappings\": {\n" +
" \"properties\": {\n" +
" \"name\": {\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"pinyin_analyzer\",\n" +
" \"search_analyzer\": \"pinyin_analyzer\"\n" +
" }\n" +
" }\n" +
" }\n" +
"}";
request.setJsonEntity(jsonString);
Response response = client.getLowLevelClient().performRequest(request);
System.out.println(response.getStatusLine().getStatusCode());
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
client.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
Kibana创建索引
PUT /my_pinyin_index
{
"settings": {
"analysis": {
"analyzer": {
"pinyin_analyzer": {
"tokenizer": "my_pinyin",
"filter": [
"lowercase"
]
}
},
"tokenizer": {
"my_pinyin": {
"type": "pinyin",
"first_letter": "none",
"padding_char": " "
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "pinyin_analyzer",
"search_analyzer": "pinyin_analyzer"
}
}
}
}
2)java语言添加数据
IndexRequest request = new IndexRequest("pinyin_index");
request.id("1");
String jsonString = "{ \"name\": \"张三\" }";
request.source(jsonString, XContentType.JSON);
IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);
System.out.println(indexResponse.getResult().name());Kibana 添加数据
POST /my_pinyin_index/_doc/1
{
"name": "张三"
}
POST /my_pinyin_index/_doc/2
{
"name": "李四"
}
POST /my_pinyin_index/_doc/3
{
"name": "王五"
}
Kibana 查询数据
GET /my_pinyin_index/_search
{
"query": {
"match": {
"name": "zhangsan"
}
}
}
9、关键字进行匹配查询
String userInput = "北京 天安门 广场";
// 构建搜索请求
SearchRequest searchRequest = new SearchRequest("articles");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 使用标准分析器进行查询构建
searchSourceBuilder.query(QueryBuilders.matchQuery("content", userInput));
// 设置搜索请求源并执行搜索
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
// 处理搜索结果
System.out.println("Search results:");
System.out.println(searchResponse);String userInput = "北京 天安门 广场"; 定义了用户输入的查询语句,包含了关键字 "北京"、"天安门" 和 "广场"。
searchSourceBuilder.query(QueryBuilders.matchQuery("content", userInput)); 使用 matchQuery 查询构建器,在 content 字段上进行关键字匹配查询。
到此,es实战应用场景分析完毕,后期会有更加精彩的技术点,敬请期待!









![[spring] Spring MVC Thymeleaf(下)](https://img-blog.csdnimg.cn/direct/8165dc29c60f44ed8f80c7ddabed6b6f.png)